在【LLM】LLM 中 token 简介与 bert 实操解读一文中对 LLM 基础定义进行了介绍,本文会对 LLM 中增量解码与模型推理进行解读。
一、LLM 中增量解码定义
增量解码(Incremental Decoding)是指在自回归文本生成过程中,模型每次只计算并生成一个新的 token,并且会利用之前计算得到的中间结果,而不需要重新计算整个序列的表示,以此来提高生成效率和减少计算资源消耗。
在 GPT 系列模型生成对话回复、文章续写等场景中广泛应用了增量解码。
二、增量解码工作过程
- 初始输入:在生成文本时,首先输入一个初始的文本序列(比如一个问题或者提示词 ),模型通过 Prefill 阶段计算这个初始序列的隐藏状态,同时生成并缓存与注意力机制相关的键(Key)和值(Value)矩阵,即 KV 缓存(KV Cache) 。
- 逐个生成 token:接下来进入解码阶段,模型会基于上一步生成的 token 和缓存的 KV 矩阵,计算当前位置的隐藏状态,然后预测下一个 token。例如,在生成第一个 token 后,将其与之前缓存的 KV 矩阵结合,计算得到第二个 token 的隐藏状态,进而预测第二个 token 。每生成一个新的 token,模型就更新相关的计算状态,但不需要重新计算整个输入序列的隐藏状态,只是在之前计算结果的基础上增量式地进行计算。
- 循环直至结束:重复上述步骤,直到达到预设的结束条件,比如生成了特定的结束标记、达到了最大文本长度限制或者满足了其他停止生成的条件 。 总之,增量解码通过复用计算结果和 KV 缓存,可以有效提升自回归模型文本生成的效率和性能。
注意:当 KV cache 的长度超出阈值(例如 1024KB)会进行清理,清理策略取决于大模型的处理策略,有滑动窗口(清理最早的)和全部清理等。
三、新 token 选择
模型在生成新 token 时,从可能的下一个词表(token)中选择一个特定的词。词表中有多个词,词的个数可以理解为 vocab size,其中每个位置的大小表示选取这个 token 的概率,如何基于这个信息选择合适的 token 作为本次生成的 token。
- 贪婪采样(Greedy Sampling) 在每一步,模型选择概率最高的词作为下一个词。这种方法快速且计算成本低,但它可能导致重复。
- 随机采样(Random Sampling) 模型根据概率分布随机选择下一个词。这种方法能够引入随机性,从而生成更多样化的文本。但是,随机性也可能导致文本质量下降,因为模型可能选择低概率但不相关的词。
- Top-k 采样(Top-k Sampling) 这种方法首先选择 k 个最可能的词,然后从这个子集中随机选择下一个词。这种方法旨在平衡贪婪采样的确定性和随机采样的多样性。
四、Prompt(提示词)
Prompt 是用户与 LLM 交互的入口,Prompt 进入 Prefill 阶段处理,并成为生成后续内容的"上下文语境"。其核心作用是引导模型生成特定类型、风格或内容的输出。简单来说,Prompt 就是你告诉模型 "要做什么" 的一段话。
在大模型推理中,Prompt 是用户与模型交互的起点,它在 Prefill 阶段被模型处理,作为生成后续内容的基础。例如:
Plain
Prompt: "请写一首关于秋天的诗。"LLM 根据此提示生成对应内容。
设计优质 Prompt 是激发 LLM 能力的关键,需要明确任务、约束条件和期望输出,例如:明确任务指令/给出格式规范/提供上下文例子
五、模型推理:Prefill 与 Decode
LLM 推理分为两个阶段:
- Prefill 阶段(批量处理)
- 输入 token 序列一次性通过所有层。
- 并行计算生成每个 token 的 Key-Value (KV) 缓存,用于后续的高效生成。
- Decode 阶段(自回归处理)
- 每次生成一个新 token,需要经过模型所有层。
- 依赖 Prefill 阶段生成的 KV 缓存。
- 推理过程是串行的,需等待前一个 token 生成完毕。
通过 KV Cache,避免了重复计算,提高生成效率。
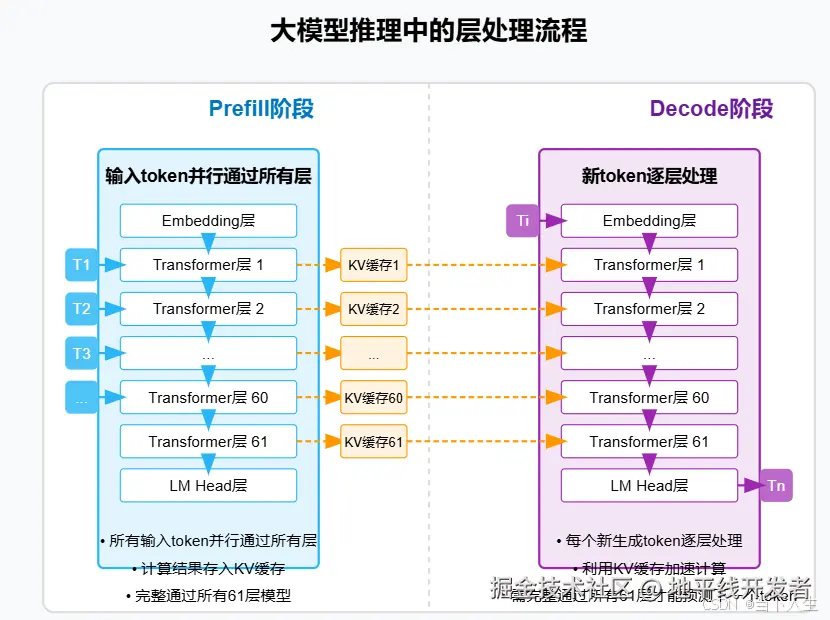
prefill 与 decode 的关系类似于接力赛:Prefill 阶段跑完第一棒,然后 Decode 阶段接过接力棒,一个接一个地完成余下的路程。
以查询 "介绍一下爱因斯坦" 为例,其核心流程如下:
5.1 初始化阶段(Prefill)
- 输入完整 prompt:"介绍一下爱因斯坦"
- 模型处理输入并生成初始 KV 缓存(存储注意力机制的键值对)
- 生成第一个输出 token:"爱"
5.2 循环迭代解码阶段(Deocde)
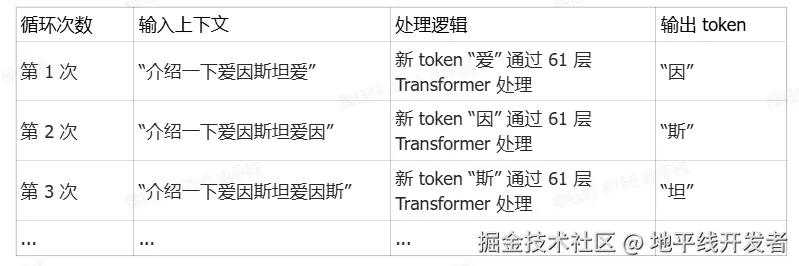
- 关键机制:每次循环仅处理单个新 token,复用之前缓存的 KV 矩阵,计算复杂度从 O(N^2) 降至 O(N)。
- 输出连贯性:新 token 的生成依赖于历史所有 token (原始输入+已生成内容)的语义信息,确保上下文逻辑一致。
5.3 小结

未来会再介绍 LLM 中评价指标与训练部署~
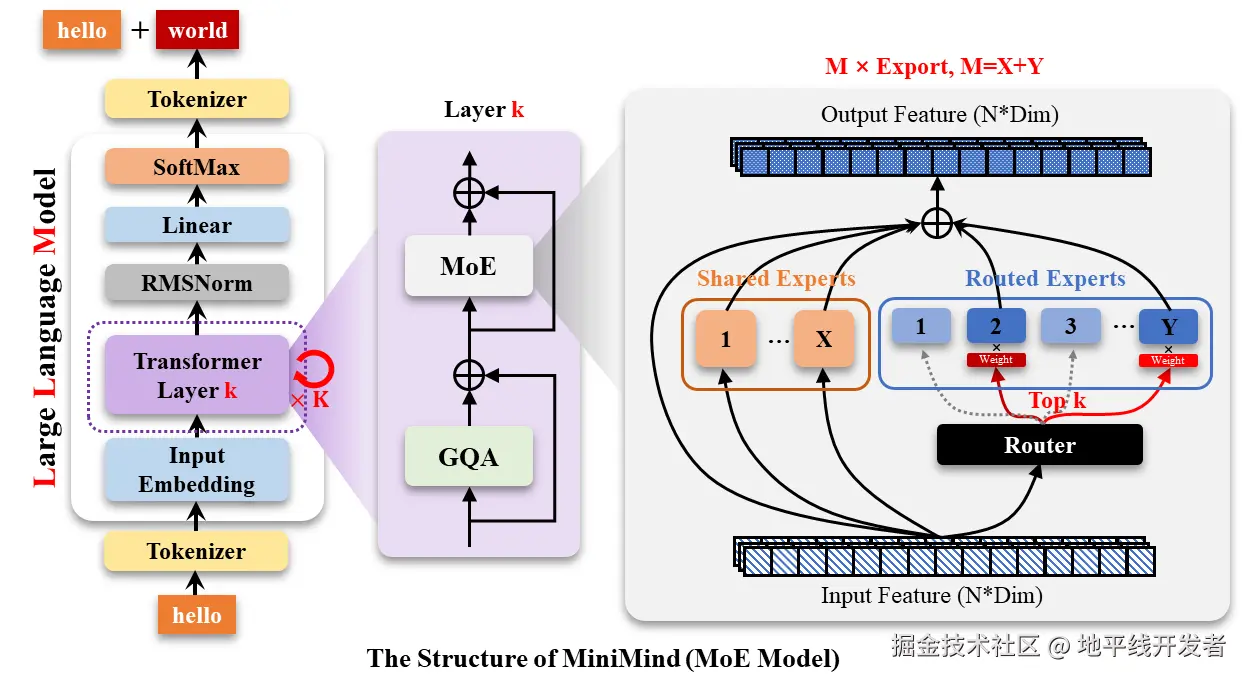
六、MoE 简介
一般来说,一个 MoE layer 包含 N 个 Experts(FFN 网络)和一个 Gating Network。其中 Gating Network 可以将一个 token routing(Token 路由)到少数的专家进行计算。可参考下图:
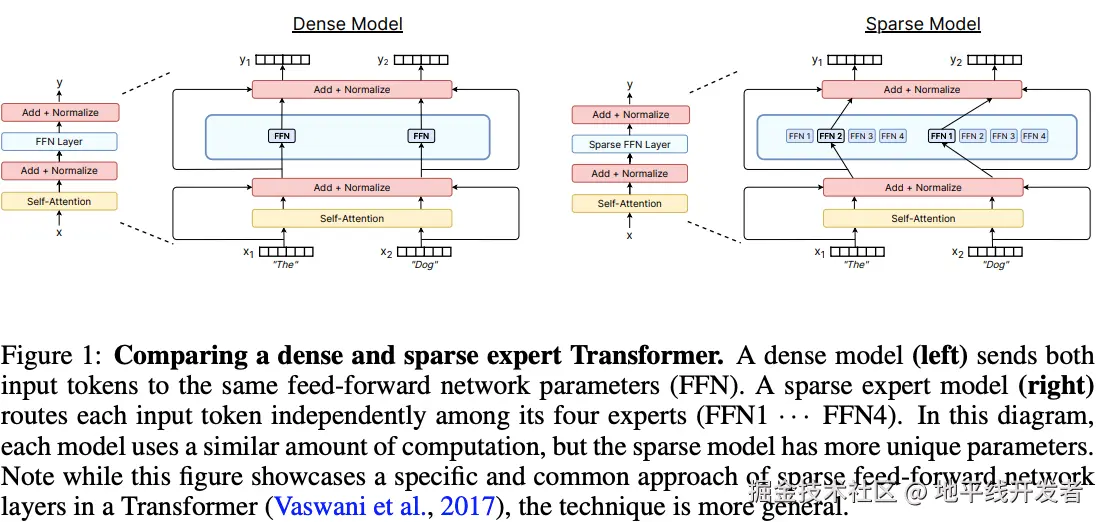
- 把不同领域专家模型(比如数学专家 LLM、编程专家 LLM ),抽象成 "专家 Token" 塞进一个 "元模型(meta LLM)" 的词表。
- 用户输入问题时,元模型生成特殊 Token 来 "路由"(决定调用哪个专家模型 )。比如遇到数学题,就触发 "数学专家 Token",让数学专家 LLM 处理;遇到编程问题,调用 "编程专家 Token"。
总结:Token routing 就是给不同重要性、不同功能的 Token,规划调用不同专家模型,让大模型更聪明分配算力、协同专家能力,最终实现 "又快又准又省资源" 的推理。
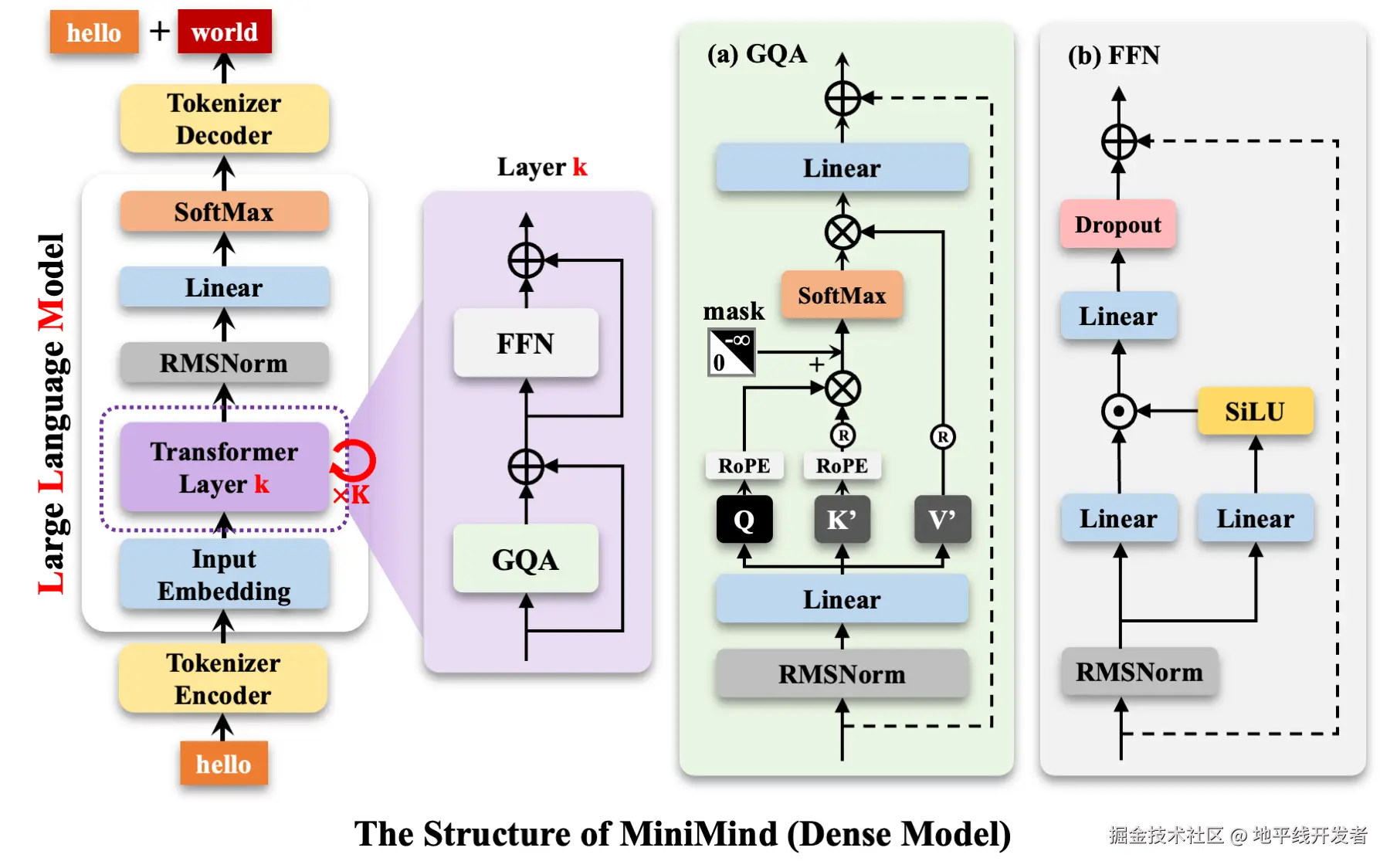
从整体看,MoE 在 LLM 模型的什么位置呢?如下图:
以上就是本文的全部介绍啦~