会把端到端自动驾驶相关的或者我感兴趣的部分摘要整理输出。
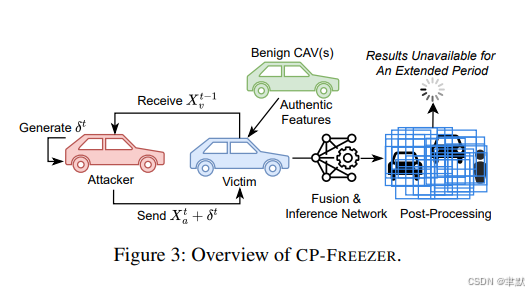
1.《CP-FREEZER: Latency Attacks against Vehicular Cooperative Perception》
https://arxiv.org/pdf/2508.01062
协同感知(CP)通过交换和融合来自多个智能体的信息,提升了网联自动驾驶车辆(CAV)的环境态势感知能力。先前的研究已探讨了旨在降低感知准确性的对抗性完整度攻击,但人们对于协同感知在对抗时效性(或称可用性)攻击方面的鲁棒性知之甚少------而时效性恰恰是自动驾驶的关键安全要求。本文提出了 CP-FREEZER,这是首个通过V2V消息注入对抗性扰动,以最大化协同感知算法计算延迟的延迟攻击。我们的攻击克服了若干独特挑战,包括点云预处理操作的不可微性、因传输延迟导致的受害者输入异步性,并采用了一种新颖的损失函数,能有效最大化协同感知流程的执行时间。大量实验表明,CP-FREEZER 能将端到端协同感知时延提升 90 倍以上,在我们的真实车辆测试平台上,以 100% 的成功率 将每帧处理时间延长至 3 秒以上。我们的研究结果揭示了协同感知系统可用性面临的严峻威胁,凸显了构建鲁棒防御机制的亟需性。
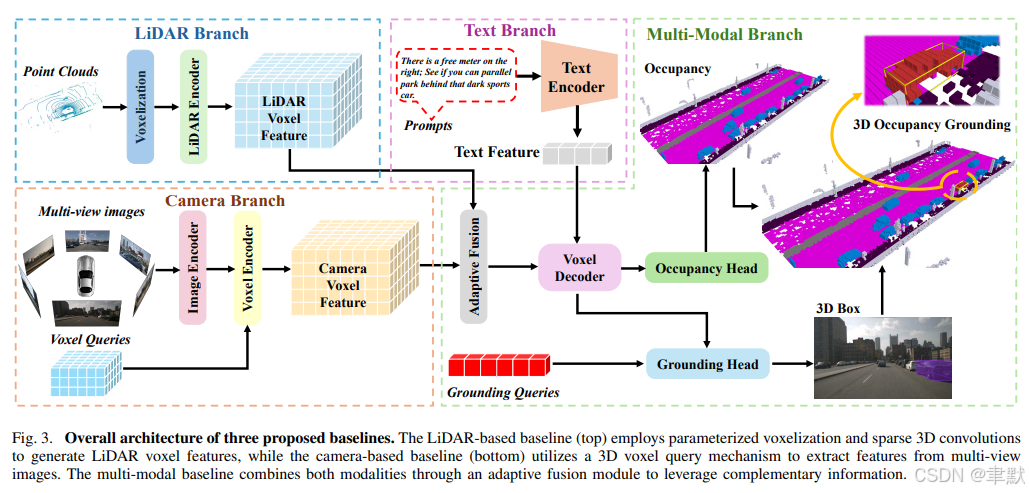
2.《A Coarse-to-Fine Approach to Multi-Modality 3D Occupancy Grounding》
https://arxiv.org/pdf/2508.01197
为具有挑战性的室外场景引入了一个3D占据空间定位(3D occupancy grounding) 的基准(benchmark) 。该基准基于 nuScenes 数据集 构建,将自然语言与**体素级(voxel-level)占据标注(occupancy annotations)**相融合,相比传统的定位任务,提供了更精确的物体感知。
此外,我们提出了 GroundingOcc ,一个专为通过多模态学习(multimodal learning) 实现3D占据空间定位而设计的端到端(end-to-end) 模型。它结合了视觉、文本和点云特征,以**从粗到精(coarse to fine)**的方式预测物体的位置和占据信息。
GroundingOcc 包含:
-
一个多模态编码器(Multimodal Encoder):用于特征提取。
-
一个占据头(Occupancy Head) :用于进行逐体素预测(voxel-wise predictions)。
-
一个定位头(Grounding Head) :用于精炼定位结果(refining localization)。
此外,一个2D定位模块(2D grounding module) 和一个深度估计模块(depth estimation module) 被引入,以增强几何理解(geometric understanding),从而提升模型性能。
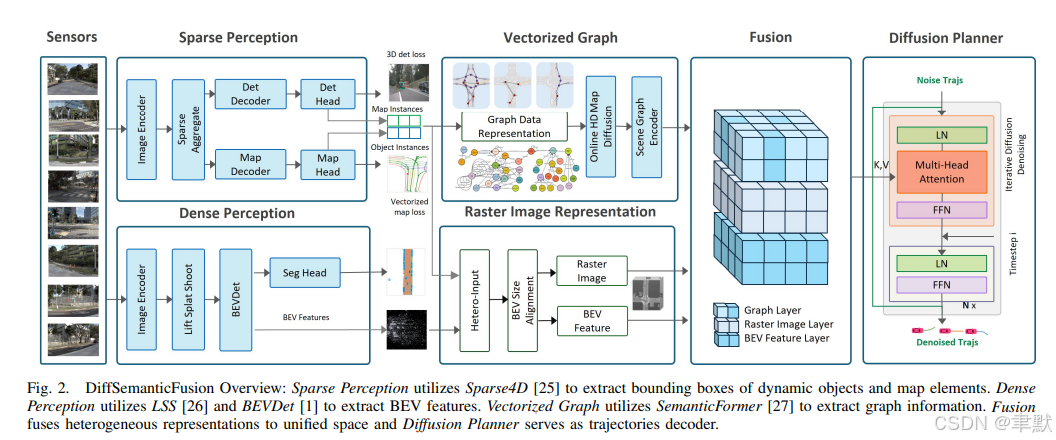
3.《DiffSemanticFusion: Semantic Raster BEV Fusion for Autonomous Driving via Online HD Map Diffusion》
基于在线高清地图扩散的自动驾驶语义光栅BEV融合,端到端的自动驾驶规划任务,出轨迹。其中目标检测由Sparse4D,Dense Perception提取特征,后面跟Vectoried Graph在线建图,融合到统一特征表示空间,Diffusion Planner规划处轨迹信息。
https://arxiv.org/pdf/2508.01778
https://github.com/SunZhigang7/DiffSemanticFusion_MaplessQCNet
自动驾驶需要精确的场景理解,包括道路几何结构、交通参与者及其语义关系。在在线高精地图(HD Map)生成 场景中,基于栅格的表示(raster-based representations) 虽然非常适合视觉模型,但缺乏几何精度;而基于图结构的表示(graph-based representations) 能保留结构细节,但在没有精确地图的情况下会变得不稳定。
为了利用这两种表示的互补优势,我们提出了 DiffSemanticFusion ------ 一个用于多模态轨迹预测与规划 的融合框架。我们的方法在一个语义栅格融合的鸟瞰图(BEV)空间(semantic raster--fused BEV space) 上进行推理,并通过一个地图扩散模块(map diffusion module) 进行增强,该模块提升了在线高精地图表示的稳定性 和表达能力(expressiveness)。
我们在两个下游任务上验证了该框架:
-
轨迹预测(Trajectory prediction)
-
面向规划的端到端自动驾驶(Planning-oriented end-to-end autonomous driving)
在真实世界自动驾驶基准数据集 nuScenes 和 NAVSIM 上的实验表明,其性能优于多种前沿(SOTA) 方法:
-
在 nuScenes 的预测任务中,我们将 DiffSemanticFusion 与融合在线高精地图信息的 QCNet 结合,实现了 5.1% 的性能提升。
-
在 NAVSIM 的端到端自动驾驶任务中,DiffSemanticFusion 取得了 SOTA 结果 ,在 NavHard 场景 中获得了 15% 的性能增益。
此外,广泛的消融实验和敏感性研究表明,我们的地图扩散模块可以无缝集成(seamlessly integrated) 到其他基于矢量的方法(vector-based approaches) 中,以提升其性能。
4.《StreamAgent: Towards Anticipatory Agents for Streaming Video Understanding》
StreamAgent:面向流媒体视频理解的预期代理
https://arxiv.org/pdf/2508.01875
5.《Mapillary Vistas Validation for Fine-Grained Traffic Signs: A Benchmark Revealing Vision-Language Model Limitations》
细粒度交通标志的Mapillary视觉验证:揭示视觉语言模型局限性的基准
https://arxiv.org/pdf/2508.02047
6.《Context-aware Risk Assessment and Its Application in Autonomous Driving》
情境感知风险评估及其在自动驾驶中的应用
https://arxiv.org/pdf/2508.02919
7.《LiDARCrafter: Dynamic 4D World Modeling from LiDAR Sequences》
LiDARCrafter:基于LiDAR序列的动态4D世界建模
https://arxiv.org/pdf/2508.03692
8.《DistillDrive: End-to-End Multi-Mode Autonomous Driving Distillation by Isomorphic Hetero-Source Planning Model》
DistillDrive:基于同构异构源规划模型的端到端多模式自主驱动蒸馏
https://arxiv.org/pdf/2508.05402
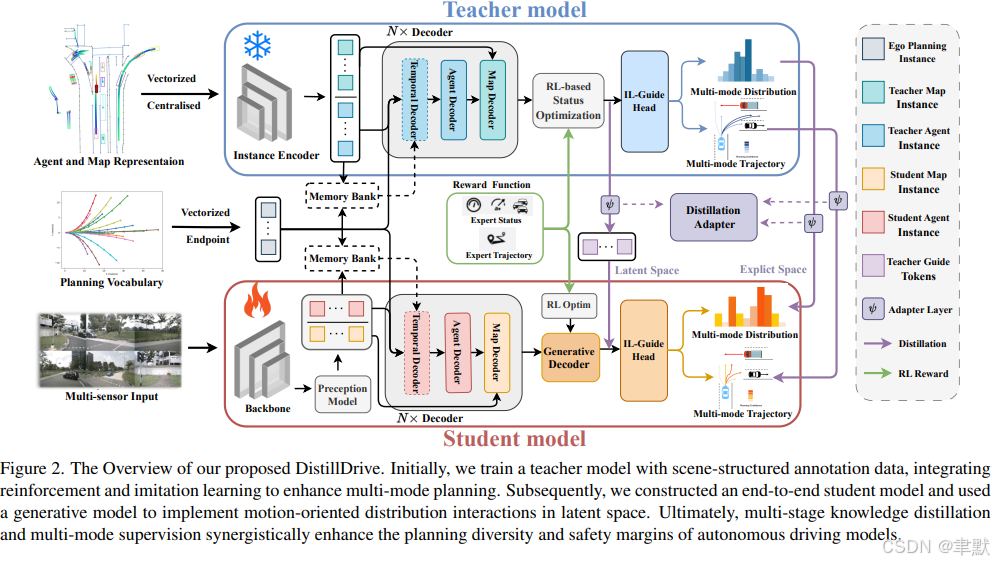
端到端自动驾驶技术近来发展迅猛,对工业界和学术界均产生了深远影响。然而,现有工作过度聚焦于自车状态(ego-vehicle status) 作为其唯一的学习目标,缺乏面向规划的理解(planning-oriented understanding) ,这限制了整体决策过程的鲁棒性(robustness)。
本工作中,我们提出了 DistillDrive ,一个基于知识蒸馏(knowledge distillation) 的端到端自动驾驶模型,它利用多样化实例模仿(diversified instance imitation) 来增强多模式运动特征学习(multi-mode motion feature learning)。具体而言:
-
教师模型(Teacher Model) :我们采用一个基于结构化场景表征(structured scene representations) 的规划模型作为教师模型。
-
学习目标(Learning Targets) :利用教师模型生成的多样化规划实例(diversified planning instances) 作为端到端模型的多目标学习目标(multi-objective learning targets)。
-
强化学习优化(Reinforcement Learning Optimization) :引入强化学习(reinforcement learning) 来增强状态到决策映射(state-to-decision mappings) 的优化。
-
生成式建模构建实例(Generative Modeling for Instances) :运用生成式建模(generative modeling) 来构建面向规划的实例(planning-oriented instances) ,促进潜在空间(latent space) 内的复杂交互。
我们在 nuScenes 和 NAVSIM 数据集上验证了模型性能:
-
相比基线模型(baseline model),实现了 50% 的碰撞率降低(collision rate reduction)。
-
在闭环性能(closed-loop performance) 上提升了 3 个点(3-point improvement)。
代码和模型已在 https://github.com/YuruiAI/DistillDrive 公开。
9.《ME3-BEV: Mamba-Enhanced Deep Reinforcement Learning for End-to-End Autonomous Driving with BEV-Perception》
ME3-BEV:Mamba增强的深度强化学习,用于端到端自动驾驶,具有BEV感知能力
https://arxiv.org/pdf/2508.06074
自动驾驶系统在复杂环境感知与实时决策领域面临严峻挑战。传统模块化方案虽具可解释性,但存在误差传播与协同缺陷;端到端学习架构虽简化设计却遭遇计算瓶颈。本文提出融合鸟瞰图(BEV)感知的深度强化学习(DRL)新范式,创新性构建Mamba-BEV模型 ------基于BEV感知与Mamba时序建模的高效时空特征提取网络,实现:
1)统一坐标系 下车辆环境与道路特征编码
2)长程依赖精准建模
在此基础上提出ME³-BEV框架 ,以Mamba-BEV作为端到端DRL的特征输入,在动态城市驾驶场景中实现卓越性能。通过语义分割可视化高维特征增强模型可解释性,揭示学习表征的内在逻辑。在CARLA仿真平台的实验表明:ME³-BEV在碰撞率、轨迹精度等多项指标超越现有模型,为实时自动驾驶提供创新解决方案。
10.《GMF-Drive: Gated Mamba Fusion with Spatial-Aware BEV Representation for End-to-End Autonomous Driving》
GMF Drive:具有空间感知BEV表示的门控Mamba融合,用于端到端自动驾驶
https://arxiv.org/pdf/2508.06113
11.《MetAdv: A Unified and Interactive Adversarial Testing Platform for Autonomous Driving》
MetAdv:一个统一的交互式自动驾驶对抗测试平台
https://arxiv.org/abs/2508.06534
自动驾驶系统的对抗鲁棒性评估与保障是亟待解决的关键挑战。本文提出创新对抗测试平台MetAdv ,通过虚拟仿真与物理车辆反馈的深度集成,实现真实动态交互式评估。其核心技术架构包含:
1)构建虚实融合沙盒环境 ,设计具备动态对抗演化的三层闭环测试体系
2)建立端到端对抗评估链路 :
• 高层:统一对抗样本生成
• 中层:基于仿真的动态交互
• 底层:物理车辆执行反馈
3)支持全栈自动驾驶任务及算法范式(模块化深度学习/端到端学习/视觉语言模型等)
平台核心优势:
✓ 灵活3D车辆建模与虚实环境无缝切换
✓ 原生兼容Apollo/Tesla等商业平台
✓ 创新人因在环能力 :
- 实时采集驾驶员生理信号与行为反馈
- 解析对抗条件下人机信任机制
- 支持可定制化环境配置
MetAdv为对抗评估提供可扩展的统一框架,为提升自动驾驶安全性开辟新路径。
12.《IRL-VLA: Training an Vision-Language-Action Policy via Reward World Model》
IRL-VLA:通过奖励世界模型训练视觉语言行动策略
https://arxiv.org/pdf/2508.06571
13.《Nonlinear Photonic Neuromorphic Chips for Spiking Reinforcement Learning》
用于尖峰强化学习的非线性光子神经形态芯片
https://arxiv.org/pdf/2508.06962
14.《Decoupled Functional Evaluation of Autonomous Driving Models via Feature Map Quality Scoring》
基于特征图质量评分的自动驾驶模型解耦功能评价
https://arxiv.org/pdf/2508.07552
15.《Progressive Bird's Eye View Perception for Safety-Critical Autonomous Driving: A Comprehensive Survey》
安全关键型自动驾驶的渐进式鸟瞰感知:一项综合调查(综述)
https://arxiv.org/pdf/2508.07560
鸟瞰图(BEV)感知已成为自动驾驶的基础范式,其构建的统一空间表征支撑着鲁棒的多传感器融合与多智能体协同。随着自动驾驶车辆从受控环境转向真实道路部署,如何在遮挡、恶劣天气、动态交通等复杂场景下确保BEV感知的安全性与可靠性仍是核心挑战。本文首次从安全攸关视角对BEV感知进行系统性综述,通过三阶段渐进框架剖析前沿技术:
-
单模态车端感知
-
多模态车端感知
-
多智能体协同感知
同时深度考察涵盖车端、路侧及协同场景的公共数据集,评估其安全鲁棒性价值。针对开放世界的核心挑战------包括开放集识别 、大规模无标注数据 、传感器退化 及跨智能体通信延迟------提出未来研究方向:
-
端到端自动驾驶系统集成
-
具身智能赋能
-
大语言模型融合
16.《Risk Map As Middleware: Towards Interpretable Cooperative End-to-end Autonomous Driving for Risk-Aware Planning》
风险地图作为中间件:迈向可解释的合作端到端自动驾驶,以实现风险意识规划
https://arxiv.org/pdf/2508.07686
端到端范式已成为自动驾驶的重要发展方向,但现有单智能体端到端方案常受限于遮挡与感知范围不足,导致驾驶风险。其黑箱特性更使驾驶行为缺乏可解释性,形成不可信系统。针对上述缺陷,我们创新性地引入风险地图中间件(RiskMM) ,提出可解释协同端到端驾驶框架。该框架通过三大技术突破:
1)风险地图中间件 :直接从驾驶数据学习,将上游感知信息及主车与环境交互转化为可解释时空表征 供下游规划使用
2)多智能体时空表征构建 :基于统一Transformer架构构建跨车辆时空表征
3)风险感知建模:通过注意力机制建模环境交互关系生成风险感知表征
这些表征输入至学习型模型预测控制(MPC)规划器,其独特优势在于:
-
原生兼容物理约束与多车型适配
-
通过比对学习参数与显式MPC元素实现决策可解释
在真实V2XPnP-Seq数据集上的验证表明:RiskMM在风险感知轨迹规划中实现更优越且稳健的性能,显著提升协同驾驶框架的可解释性。代码库将开源以促进领域研究。
17.《CBDES MoE: Hierarchically Decoupled Mixture-of-Experts for Functional Modules in Autonomous Driving》
CBDES MoE:自动驾驶功能模块的分层解耦专家混合
https://arxiv.org/pdf/2508.07838
基于多传感器特征融合的鸟瞰图(BEV)感知系统 已成为端到端自动驾驶的基石。然而现有多模态BEV方法普遍面临三大局限:输入适应性受限、建模能力不足、泛化性能欠佳。为此,我们创新性地提出功能模块级层次化解耦的混合专家架构 ------计算脑演化系统混合专家(CBDES MoE)。该架构通过两大核心技术突破:
1)集成结构异构的专家网络群
2)采用轻量级自注意力路由门控机制(SAR)
实现动态专家路径选择与稀疏输入感知的高效推理 。据我们所知,这是自动驾驶领域首个在功能模块粒度构建的模块化混合专家框架。在nuScenes真实数据集上的广泛评估表明:CBDES MoE在3D目标检测任务中持续超越固定单专家基线,相较最强单专家模型实现mAP提升1.6个百分点,NDS提高4.1个百分点,充分验证了该方案的效能与实用优势。
18.《ReconDreamer-RL: Enhancing Reinforcement Learning via Diffusion-based Scene Reconstruction》
ReconDreamer RL:通过基于扩散的场景重建增强强化学习
https://arxiv.org/pdf/2508.08170
19.《VLM-3D:End-to-End Vision-Language Models for Open-World 3D Perception》
VLM-3D:开放世界3D感知的端到端 视觉语言模型
https://arxiv.org/pdf/2508.09061
复杂交通环境下的开放集感知 是自动驾驶系统的核心挑战,尤其在识别未知物体类别方面对安全保障至关重要。视觉语言模型(VLMs)凭借丰富的世界知识与强大语义推理能力,为解决该任务提供了新思路。然而现有方案通常仅利用VLMs提取视觉特征并与传统目标检测器耦合,导致多阶段误差传播 问题,制约感知精度突破。为此,我们提出首个端到端框架VLM-3D ,使VLMs具备自动驾驶场景的三维几何感知能力 。该框架创新性融合:
1)采用低秩自适应(LoRA) 以极小计算开销高效适配驾驶任务
2)设计联合语义-几何损失函数 :
• 训练前期施加语义token级损失 确保稳定收敛
• 训练后期引入3D IoU损失 精调边界框预测精度
在nuScenes数据集上的实验表明,VLM-3D的联合损失设计带来12.8%的感知精度提升,充分验证了方案的有效性与先进性。
20.《EvaDrive: Evolutionary Adversarial Policy Optimization for End-to-End Autonomous Driving》
EvaDrive:端到端自动驾驶的进化对抗策略优化
https://arxiv.org/pdf/2508.09158
21.《Holistic Heterogeneous Scheduling for Autonomous Applications using Fine-grained, Multi-XPU Abstraction》
使用细粒度、多XPU抽象的自治应用程序的整体异构调度
https://arxiv.org/pdf/2508.09503
22.《SpaRC-AD: A Baseline for Radar-Camera Fusion in End-to-End Autonomous Driving》
SpaRC AD:端到端 自动驾驶雷达摄像头融合的基准
https://arxiv.org/pdf/2508.10567
端到端自动驾驶系统承诺通过统一优化感知、运动预测与规划实现更强性能。然而基于视觉的方案在恶劣天气、局部遮挡及精准测速方面存在固有局限------这些安全敏感场景中的关键挑战,要求系统必须具备精确运动理解与长时程轨迹预测能力以实现碰撞规避。为此,我们提出SpaRC-AD :基于查询机制的端到端相机-雷达融合框架,专为规划导向的自动驾驶设计。通过稀疏3D特征对齐 与多普勒测速 技术,构建强大的三维场景表征以优化交通参与者锚点、地图折线及运动建模。本方法在多项自动驾驶任务中显著超越纯视觉基线:3D检测(mAP +4.8%)、多目标跟踪(AMOTA +8.3%)、在线建图(mAP +1.8%)、运动预测(mADE -4.0%)、轨迹规划(L2误差 -0.1m,TPC -9%)。在nuScenes真实开环场景、长时程T-nuScenes及闭环仿真Bench2Drive等挑战性基准测试中,均展现出优异的空间一致性 与时序连贯性。实验验证了雷达融合在安全关键场景的有效性------当精确运动理解与长时程轨迹预测成为碰撞规避的关键时,本方案展现出独特优势
23.《ImagiDrive: A Unified Imagination-and-Planning Framework for Autonomous Driving》
Imagindrive:自动驾驶的统一想象 和规划框架
https://arxiv.org/pdf/2508.11428
自动驾驶需具备丰富的环境理解能力和精准的预测推理能力,方能在动态复杂场景中安全行驶。视觉语言模型(VLMs)与驾驶世界模型(DWMs)作为两大关键技术路径,分别从不同维度应对这一挑战:VLMs凭借多模态上下文理解能力提供可解释的行为预测,DWMs则擅长生成逼真细致的未来驾驶场景以支撑前瞻性规划。将二者整合既能发挥行为预测与场景生成的互补优势,又是极具潜力却尚未充分探索的研究方向。然而,这种融合面临显著挑战------如何有效连接动作级决策与高保真像素级预测,并维持计算效率。
为此,本文提出创新性端到端自动驾驶框架ImagiDrive,通过融合VLM驾驶智能体与DWM场景想象器构建统一的想象-规划循环 。该框架运行机制为:驾驶智能体基于多模态输入预测初始轨迹,引导场景想象器生成对应未来场景;继而利用想象场景迭代优化驾驶决策。针对融合过程中的效率与预测精度挑战,创新性引入早停机制 与轨迹优选策略。在nuScenes和NAVSIM数据集上的大量实验表明,ImagiDrive在开环与闭环场景下均显著优于现有方案。
24.《EvoPSF: Online Evolution of Autonomous Driving Models via Planning-State Feedback》
EvoPSF:通过规划状态反馈实现自动驾驶模型的在线演化
https://arxiv.org/pdf/2508.11453
25.《Perception in Plan: Coupled Perception and Planning for End-to-End Autonomous Driving》
计划中的感知:端到端 自动驾驶的耦合感知和规划
https://arxiv.org/pdf/2508.11488
端到端自动驾驶技术近年来取得显著突破。现有方法主要遵循感知-规划范式,即在完全可微分的框架内顺序执行感知与规划,实现规划导向的优化。本研究通过"规划中感知 "的框架设计进一步推进该范式,将感知深度融入规划流程。该设计通过动态演进的规划目标引导实现目标导向的感知,最终提升规划性能。基于此,我们提出VeteranAD------面向端到端自动驾驶的感知规划耦合框架:首先引入多模态锚定轨迹作为规划先验,感知模块据此专门采集轨迹沿线交通要素,实现全面精准的感知;随后结合感知结果与规划先验生成规划轨迹。为使感知完全服务于规划,采用自回归策略逐步预测未来轨迹,并在每一步聚焦关键区域进行目标感知。凭借这一简洁高效的设计,VeteranAD充分释放了规划导向端到端方法的潜力,生成更精准可靠的驾驶行为。在NAVSIM和Bench2Drive数据集上的大量实验表明,本框架实现了领先性能。
26.《LMAD: Integrated End-to-End Vision-Language Model for Explainable Autonomous Driving》
LMAD:用于可解释自动驾驶的集成端到端视觉语言模型
https://arxiv.org/pdf/2508.12404
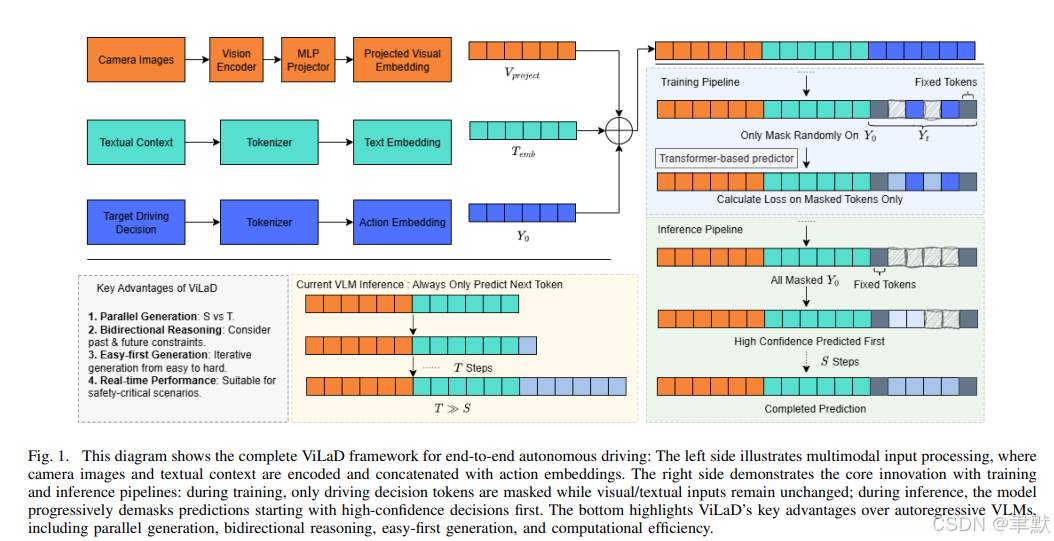
27.《ViLaD: A Large Vision Language Diffusion Framework for End-to-End Autonomous Driving》
ViLaD:端到端自动驾驶的大视觉语言扩散框架
https://arxiv.org/pdf/2508.12603
基于视觉语言模型(Vision Language Models, VLMs) 构建的端到端自动驾驶系统已展现出显著潜力,但其对自回归架构(autoregressive architectures) 的依赖给现实应用带来了一些限制。这些模型逐标记(token-by-token) 的顺序生成(sequential generation) 过程导致了高推理延迟(high inference latency) ,并且无法进行双向推理(cannot perform bidirectional reasoning),使其不适用于动态的、安全关键的环境。
为了克服这些挑战,我们提出了 ViLaD ,一种用于端到端自动驾驶的新型大规模视觉语言扩散框架(Large Vision Language Diffusion, LVLD) ,这代表了一种范式转变(paradigm shift) 。ViLaD 利用一种掩码扩散模型(masked diffusion model) ,能够并行生成(parallel generation) 整个驾驶决策序列,从而显著降低计算延迟(significantly reducing computational latency) 。此外,其架构支持双向推理(supports bidirectional reasoning) ,使模型能够同时考虑过去和未来信息,并支持渐进式易先生成(progressive easy-first generation),以迭代地提升决策质量。
我们在 nuScenes 数据集 上进行了全面的实验。结果表明,ViLaD 在规划精度(planning accuracy) 和推理速度(inference speed) 方面均优于前沿(state-of-the-art) 的自回归 VLM 基线模型,同时实现了接近零的故障率(near-zero failure rate) 。此外,我们通过在真实自动驾驶车辆上部署 ViLaD 执行交互式泊车任务(interactive parking task) ,验证了该框架的实际可行性(practical viability) ,证实了其在实际应用中的有效性(effectiveness) 和稳健性(soundness)。