我们想要解决的问题
让我们深入一个现实场景:
设想你负责汇总多个销售点系统产生的大量数据。这些数据需要被实时处理并在高级分析仪表板上展示,以提供全面的洞察。
在数据处理领域,速度至关重要。ClickHouse 作为速度之王,
它从不减速且异常迅速。其在并发处理方面的高效性以及成本效益使其成为构建快速数据洞察的首选。
这就引出了一个简单的解决方案:
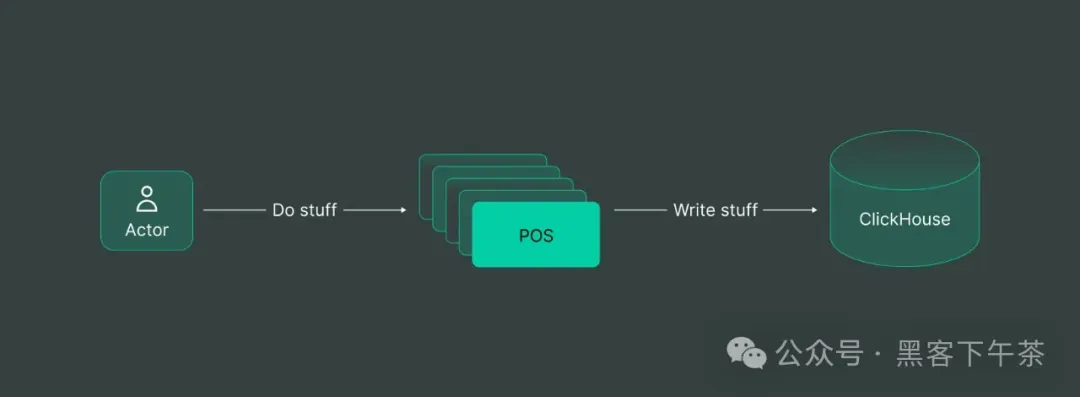
对于每个销售点,我们添加一段终端代码,将数据插入到 ClickHouse 中。
💡 简单吗?
是的。
💡 能用吗?
不行。
为何向 ClickHouse 写入数据如此困难
这种简单的解决方案让你踏入了 ClickHouse 的第一个致命误区:这里有一系列的误区。
当你插入数据时经常会遇到这个错误,它会出现在 ClickHouse 的日志中或对 INSERT 请求的响应中。为了理解这个错误,用户需要基本了解 ClickHouse 中"部分"(part)的概念:
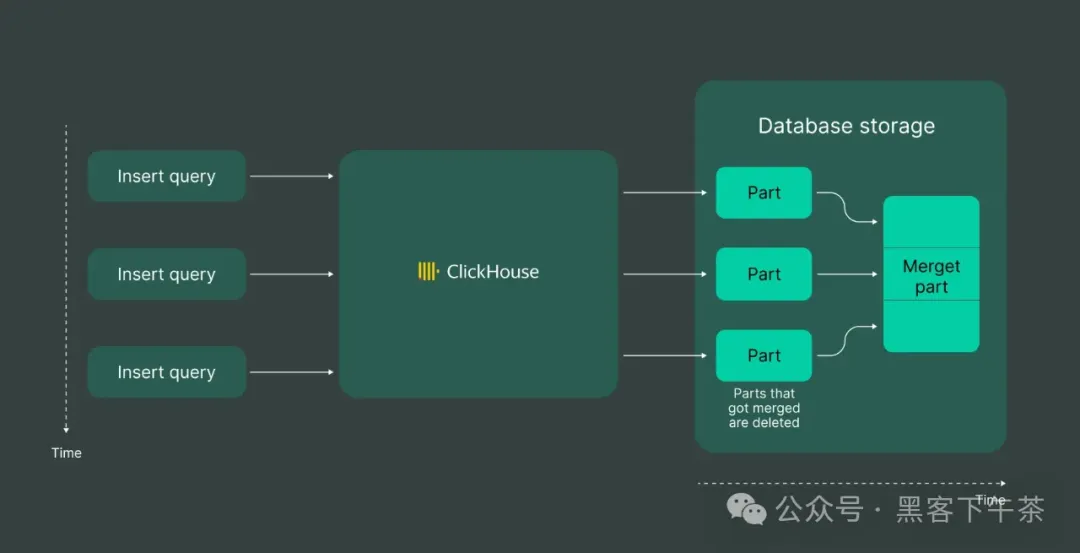
我们不必深入技术细节;只需认识到这一点即可。向 ClickHouse 写入数据时,控制速度和并行性至关重要。ClickHouse 喜欢这样的数据摄入过程:
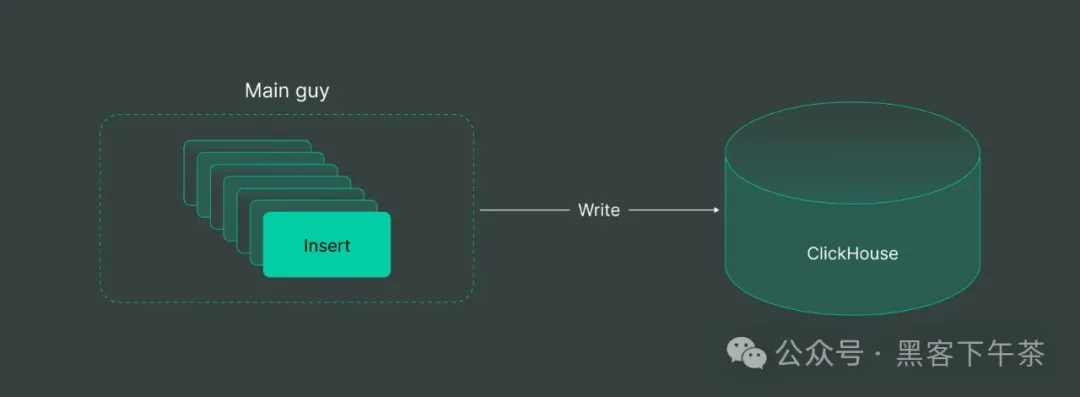
理想情况下,一个主要的数据源可以以任意速度插入所有数据,但需要有控制的平行性和缓冲。这与 ClickHouse 的偏好完美契合。
因此,在实践中,通常会在 ClickHouse 前面引入一个缓冲区:
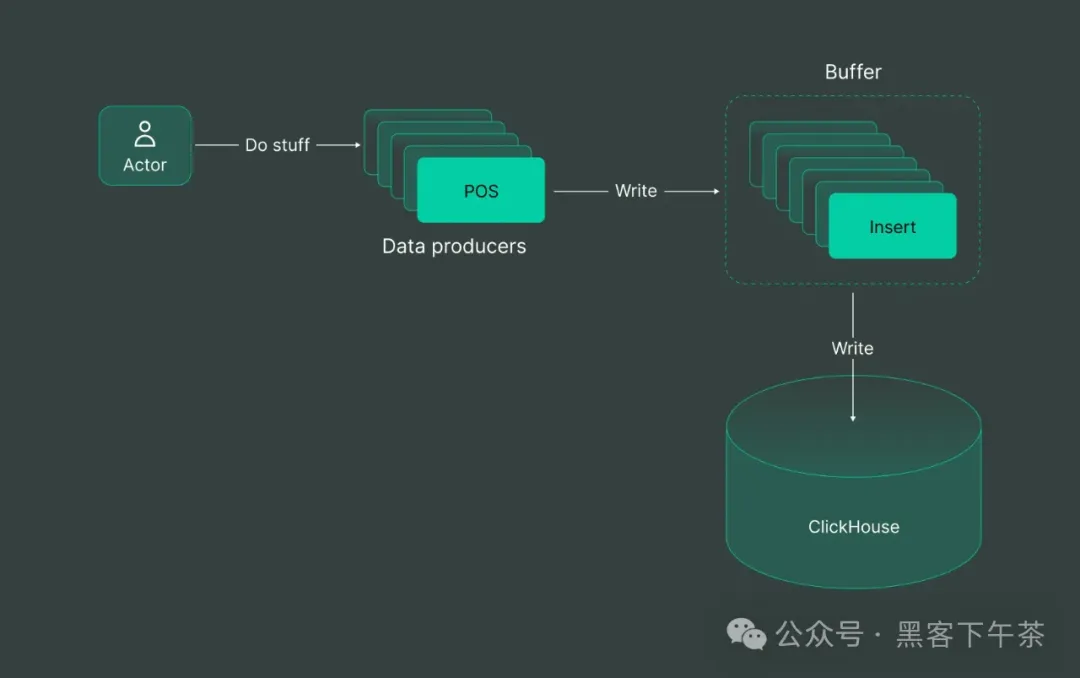
这时我们就引入了 Kafka,它是数据缓冲解决方案的灯塔。由于 Kafka 无缝地充当缓冲区的能力,它成为了 ClickHouse 强大的最佳拍档。经过迭代后,我们的解决方案如下所示:

我们在销售点系统中加入一些代码来将数据写入 Kafka,然后设置从 Kafka 到 ClickHouse 的传输。在这个流程图中还有一些魔法般的操作,因为从 Kafka 到 ClickHouse 的传输本身就是一项挑战,但我们稍后会详细讨论。
💡 强大吗?
是的。
💡 可扩展吗?
当然。
💡 简单吗?
并不简单。
如何实现 Kafka 与 ClickHouse 之间的数据传输
从 Kafka 向 ClickHouse 传输数据的关键阶段包括读取 Kafka 主题、将数据转换为 ClickHouse 兼容的格式以及将这些格式化的数据写入 ClickHouse 表中。这里的权衡在于决定在何处执行每个阶段。
每个阶段都会消耗一些资源:
读取阶段 :这一初始阶段会消耗 CPU 和网络带宽来从 Kafka 主题拉取数据。转换过程 :转换数据需要 CPU 和内存使用。这是一个直接的资源利用阶段,计算能力重塑数据以符合 ClickHouse 的规范。写入阶段:最后一步涉及将数据写入 ClickHouse 表中,这也需要 CPU 功率和网络带宽。这是一个常规的过程,确保数据按照分配的资源找到其在 ClickHouse 存储中的位置。
每种集成方法都有其自身的权衡,因此你应该明智选择。
让我们探索实现 Kafka 与 ClickHouse 之间连接的不同选项:
ClickHouse Kafka 引擎
利用 Kafka 内置的 ClickHouse 引擎将数据直接写入 ClickHouse 表中。从高层次来看,它是这样的:
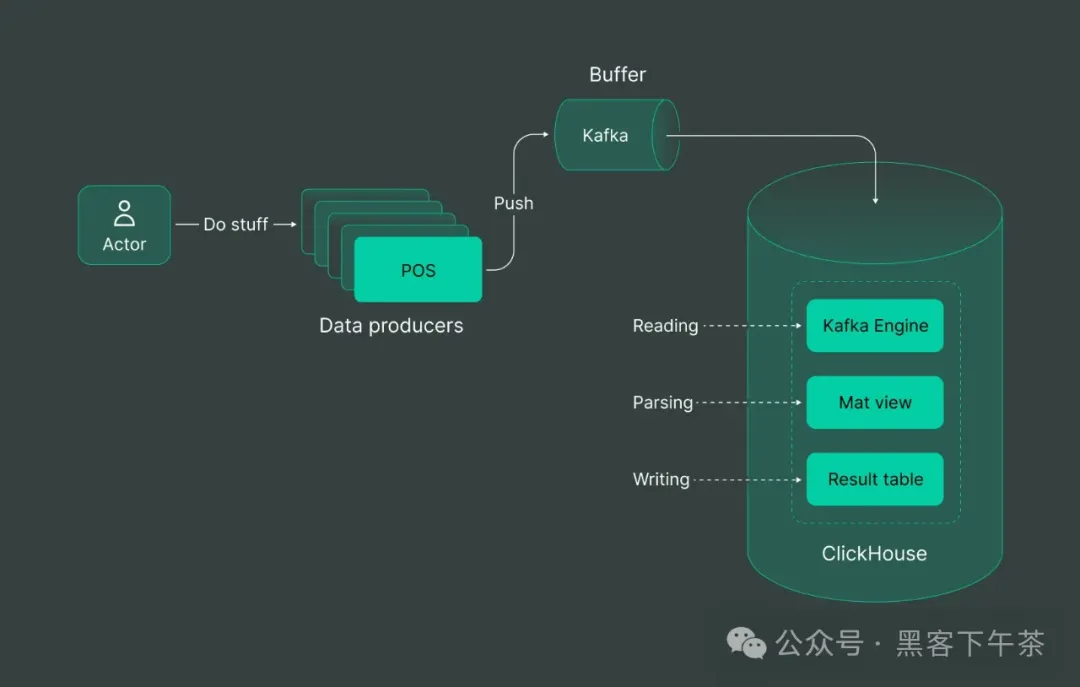
假设我们的销售点终端生成带有新行分隔符的 JSON 数据。
sh
{"user_ts": "SOME_DATE", "id": 123, "message": "SOME_TEXT"}
{"user_ts": "SOME_DATE", "id": 1234, "message": "SOME_TEXT"}让我们来实现这个 Kafka 引擎:
首先,我们需要通过 Kafka 引擎在 ClickHouse 中为该主题创建一个包装器:example kafka_stream_engine.sql
sh
-- Clickhouse queue wrapper
CREATE TABLE demo_events_queue ON CLUSTER '{cluster}' (
-- JSON content schema
user_ts String,
id UInt64,
message String
) ENGINE = Kafka SETTINGS kafka_broker_list = 'KAFKA_HOST:9091',
kafka_topic_list = 'TOPIC_NAME',
kafka_group_name = 'uniq_group_id',
kafka_format = 'JSONEachRow';在这个查询中,我们设置了三个主要的内容:
- 数据 schema:一个包含 3 列的表。
- 数据格式:JSON 每行。
- Kafka host + Kafka topic。
接下来,我们需要指定将承载结果数据的目标表:/example_projects/clickstream/kafka_stream_engine.sql#L12-L23
sh
-- Table to store data
CREATE TABLE demo_events_table ON CLUSTER '{cluster}' (
topic String,
offset UInt64,
partition UInt64,
timestamp DateTime64,
user_ts DateTime64,
id UInt64,
message String
) Engine = ReplicatedMergeTree('/clickhouse/tables/{shard}/{database}/demo_events_table', '{replica}')
PARTITION BY toYYYYMM(timestamp)
ORDER BY (topic, partition, offset);这张表以 ReplicatedMergeTree 的形式保存相同的数据,但增加了一些额外的列。这些列将从 KafkaEngine 的元数据中获取。
/example_projects/clickstream/kafka_stream_engine.sql#L25-L34
sh
-- Delivery pipeline
CREATE MATERIALIZED VIEW readings_queue_mv TO demo_events_table AS
SELECT
-- kafka engine virtual column
_topic as topic,
_offset as offset,
_partition as partition,
_timestamp as timestamp,
-- example of complex date parsing
toDateTime64(parseDateTimeBestEffort(user_ts), 6, 'UTC') as user_ts,
id,
message
FROM demo_events_queue;作为最后一步,创建一个物化视图,将 KafkaEngine 表与目标表连接起来。
所有这些步骤结合起来产生最终的结果:
sh
SELECT count(*)
FROM demo_events_table
Query id: f2637cee-67a6-4598-b160-b5791566d2d8
┌─count()─┐
│ 6502 │
└─────────┘
1 row in set. Elapsed: 0.336 sec.在这种选项中,所有三个阶段都在 ClickHouse 内部完成。这对于较小的工作负载是合适的,但在大规模下可能会导致不可靠的性能。此外,当面临资源短缺时,ClickHouse 倾向于优先处理查询工作负载而非非查询工作负载,这可能在高负载下造成额外的交付延迟。
虽然 KafkaEngine 的使用是强大的,但它也带来了一些未解决的挑战:
-
Offset(偏移量)管理:如果 Kafka 中出现格式错误的数据,ClickHouse 可能会变得无响应,直到管理员手动删除偏移量,这是一项固有的劳动密集型任务。
-
有限的 Observability(可观测性):监控成为一个挑战,因为所有操作都在 ClickHouse 内部进行,需要依赖 ClickHouse 日志作为了解系统活动的唯一途径。
-
Scalability(可扩展性)问题:在 ClickHouse 集群内部处理解析和读取可能会妨碍在需求高峰期读写操作的无缝扩展,可能导致 CPU 和 I/O 并发问题。
在 Kafka Connect 内部
另一方面,Kafka Connect 改变了剧本,将复杂性从 ClickHouse 转移到 Kafka。
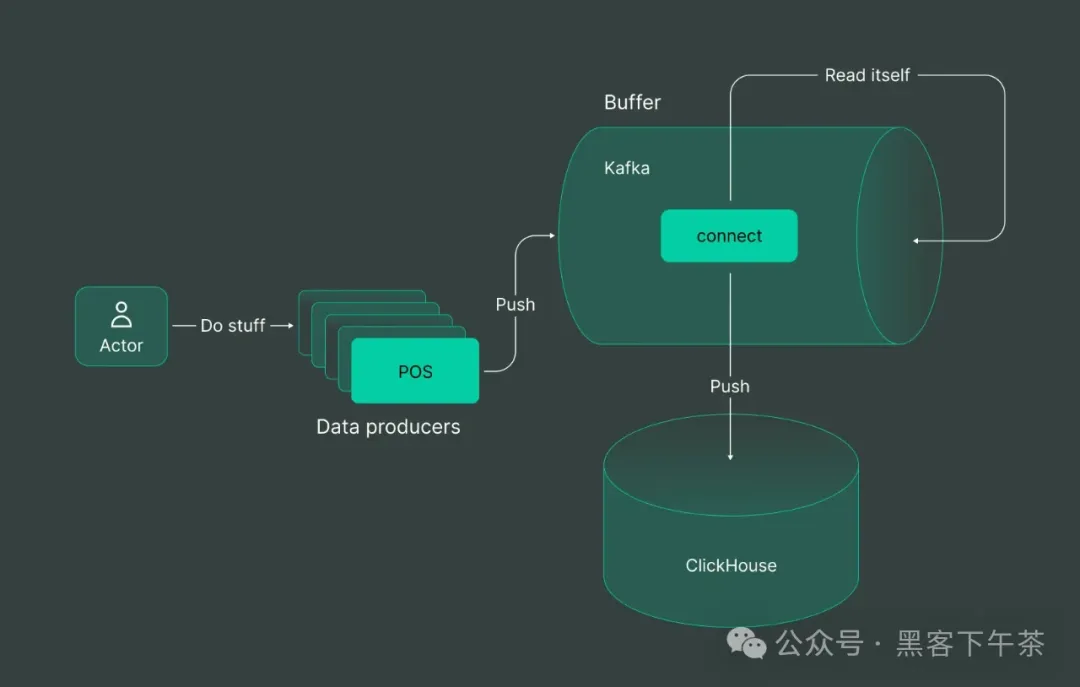
这是一种策略游戏,决定在哪里安置数据管理的复杂性。我们将读取/解析/写入的努力放在 Kafka Connect 内部,而 Kafka Connect 本身由 Kafka 托管。
这里的优缺点基本上是一样的,只是将额外的负载从存储转移到缓冲区一侧。你可以在这里查看如何连接的一个示例:这里。
外部 Writer(写入器)
对于愿意投资的人来说,External Writer 选项成为顶级选择,承诺以额外的成本换取无与伦比的性能。一个过度简化的解决方案可能看起来像这样:
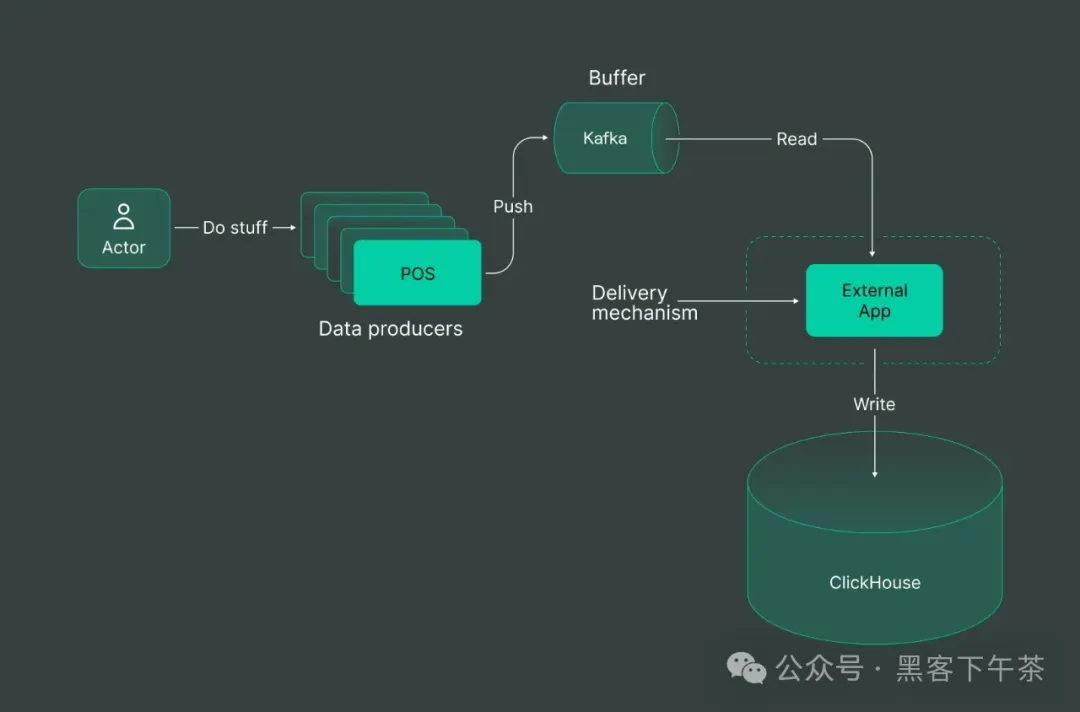
让我们尝试使用 DoubleCloud 数据传输 来建立这个传输。
资源模型由两个端点(源和目标)和一个传输组成。为了创建它们,我们将使用 Terraform provider。
配置中的关键部分是源端点的解析规则:/example_projects/clickstream/transfer.tf#L16-L43
tf
parser {
json {
schema {
fields {
field {
name = "user_ts"
type = "datetime"
key = false
required = false
}
field {
name = "id"
type = "uint64"
key = false
required = false
}
field {
name = "message"
type = "utf8"
key = false
required = false
}
}
}
null_keys_allowed = false
add_rest_column = true
}
}这个解析器类似于我们在 ClickHouse 中通过 DDL 指定的内容。
一旦我们创建了源端点,添加目标数据库就是一个简单的过程:
/example_projects/clickstream/transfer.tf#L54-L63
tf
clickhouse_target {
clickhouse_cleanup_policy = "DROP"
connection {
address {
cluster_id = doublecloud_clickhouse_cluster.target-clickhouse.id
}
database = "default"
user = "admin"
}
}最后,将它们链接在一起形成一个传输:/example_projects/clickstream/transfer.tf#L67-L75
sh
resource "doublecloud_transfer" "clickstream-transfer" {
name = "clickstream-transfer"
project_id = var.project_id
source = doublecloud_transfer_endpoint.clickstream-source[count.index].id
target = doublecloud_transfer_endpoint.clickstream-target[count.index].id
type = "INCREMENT_ONLY"
activated = true
}就这样!您的传输已经启动并运行了。
我们在 DoubleCloud 设计了自己的强大 EL (t) 引擎,Transfer,其中有一个关键特性:Queue Engine -> ClickHouse 传输。在开发这种传输机制时,我们积极应对了持续存在的挑战:
-
自动偏移量管理:我们实现了自动未解析表,简化了处理损坏数据的过程,并消除了在偏移量管理中需要人工干预的需求。
-
增强的可观察性:为了克服 ClickHouse 固有的有限可见性问题,我们开发了专用的仪表板和警报,可以实时洞察特定的传输指标。这包括对数据延迟、已传输行数和已传输字节数的全面监控。
-
动态可扩展性:Transfer 在 Kubernetes、EC2 或 GCP 实例中外部部署传输作业,允许独立于 ClickHouse 集群进行扩展。这确保了在不牺牲性能的情况下满足不同需求的最佳可扩展性。
此外,Transfer 还提供了开箱即用的支持:
-
自动 scheme 演变:向后兼容的模式更改会自动同步到目标存储。
-
自动死信队列:任何损坏的数据都会由 Transfer 处理,并组织到 DLQ ClickHouse 表中。
通过 ClickPipes 的外部写入器
ClickPipes 是一个托管集成平台,它使得从多样化的数据源中摄取数据变得像点击几下那么简单。专为最苛刻的工作负载设计,ClickPipes 强大且可扩展的架构确保了一致的性能和可靠性。
我不会复制设置此写入器的完整说明,但您可以在此处找到全面的指南:这里。
此写入器类似于任何 DoubleCloud Transfer,但没有自动 scheme 演变功能。
总结
但是在这一系列可能性的迷宫中,如何选择正确的路径呢?
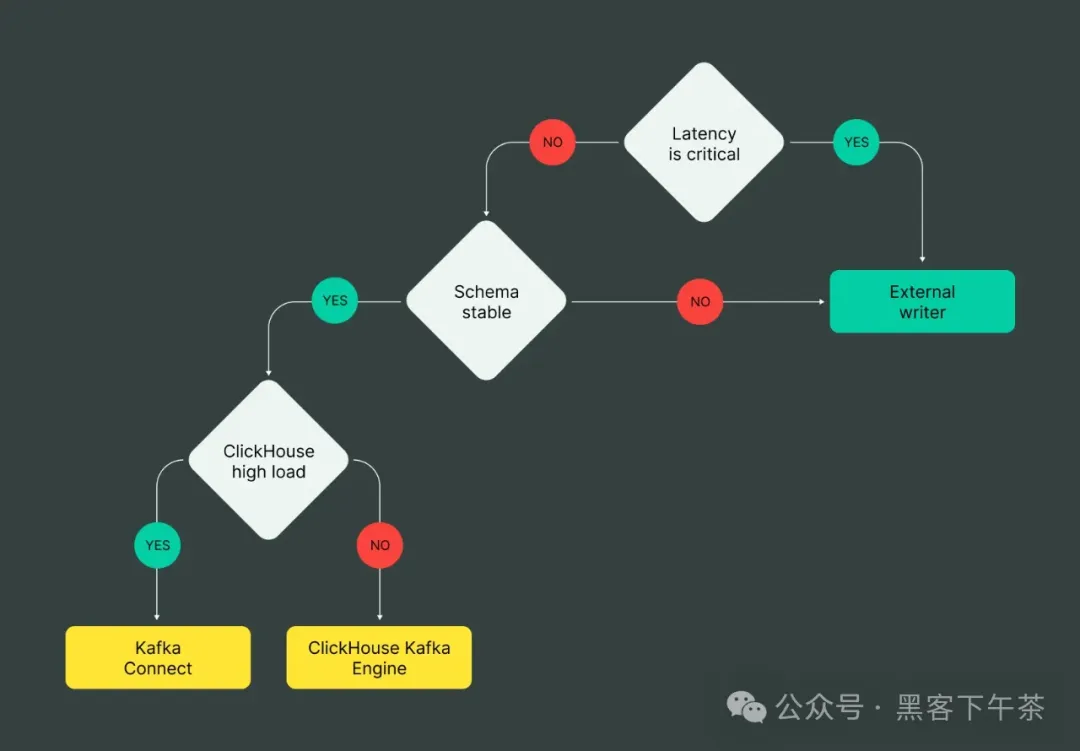
Cue the Graph 是您在这个选择景观中的可靠指南针。可视化优缺点、权衡和收益,图表成为您的指路明星,照亮适合您特定需求的理想路线。
在这份全面的指南中,我们将探索 Kafka-ClickHouse 组合的各个方面,深入研究细节,突出潜在陷阱,并提供做出关键决策的路线图。准备好揭开这对动态组合背后的秘密吧,随着我们探索快节奏的数据传输和处理世界。
要探索 Kafka + Clickhouse 的强大功能,请自由探索 DoubleCloud 堆栈,我们有一些很好的 Terraform 示例。