Redis持久化
文章目录
什么是持久化
众所周知Redis是跑在内存中的,当程序重启或者服务器崩溃时,数据就会丢失。如果业务需要重启后数据还在,那就需要持久化,把数据保存到磁盘中。
持久化方式
Redis有两种持久化方式:RDB和AOF
RDB
RDB(Redis Database Backup),记录Redis某个时刻的全部数据,本质就是数据快照,直接保存到磁盘中,后序通过加载RDB文件恢复数据。
AOF
AOF(Append Only File),记录执行的每条写操作命令,重启之后通过重放命令来恢复数据,AOF本质是记录操作日志,后序通过日志重放恢复数据。

RDB和AOF区别
RDB是快照恢复,AOF是日志恢复
- 相同数据量下,RDB体积小,因为它记录的是二进制紧凑型数据
- RDB是快照恢复,可以直接加载,恢复速度快;AOF是日志重放,恢复速度慢
- AOF记录的是每条日志,RDB是间隔一段时间记录一次,所以AOF数据更完整
使用RDB还是使用AOF
还是根据使用场景:
1.如果本身只是作为一个缓存并且不是一个海量访问,就可以不使用持久化。
2.如果对数据很重视,可以同时开启RDB和AOF,但是这种情况RDB只是一个备份,实际恢复还是使用AOF(目的是开启AOF表明对数据的一致性要求高)。
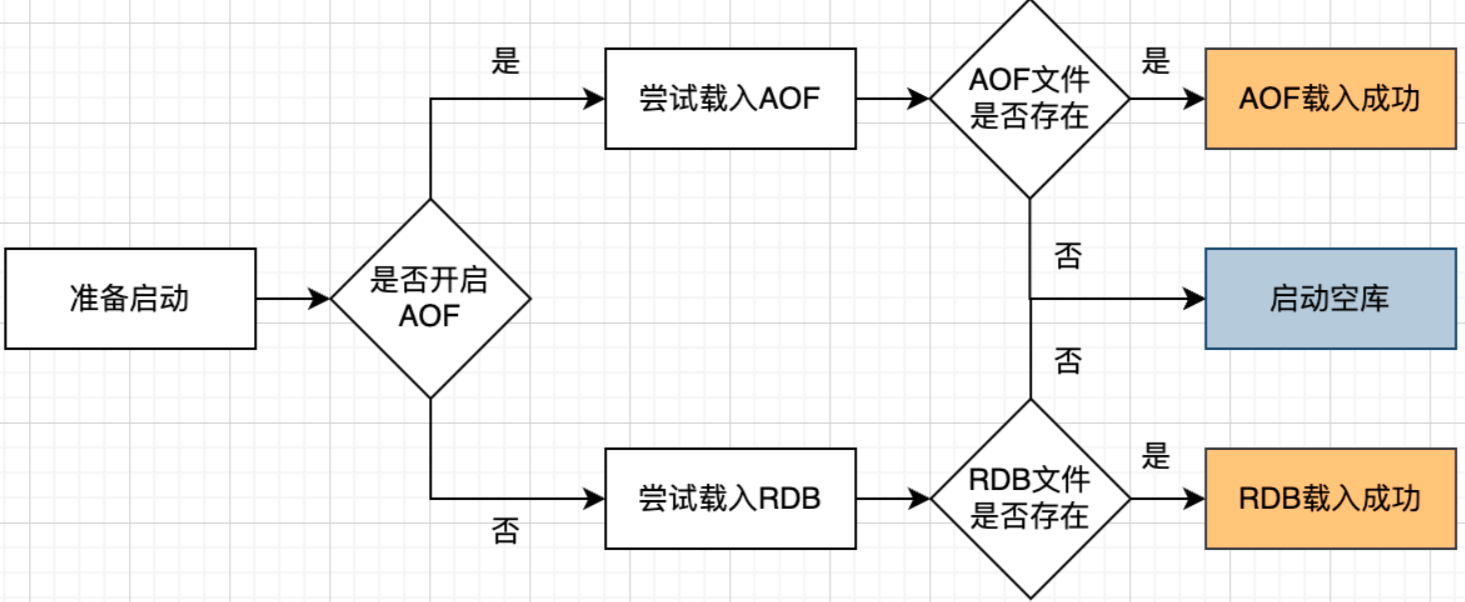
3.如果可以接受几分钟级别的数据丢失,建议只开启RDB。
保存镜像是数据库领域最有效的方法,所以RDB是Redis默认打开的。

RDB为什么是几分钟持久化一次
因为是Redis主线程fork出一个子进程来做全量快照,如果一秒一次,会导致巨大的性能开销,可能上一秒的快照还没完成,下一秒又fork出一个子进程做快照。综上,RDB触发时间间隔一般是几分钟以上。
RDB详解
Redis默认配置:
go
save 900 1
save 300 10
save 60 10000这里的语法是 save interval num,表示每隔interval秒,至少num条数据写操作,就会激活RDB持久化。(写操作指增加、删除、更新)
这三种条件是一个并集,满足其一就会进行持久化。这里的save当然是bgsave命令,如果是save命令,会时不时阻塞主线程。
RDB时机
1.主动执行save
2.主动执行bgsave
3.满足默认三个条件之一
4.程序正常关闭时:在关闭时,Redis会启动一次阻塞式持久化,以记录更全的数据
RDB的流程
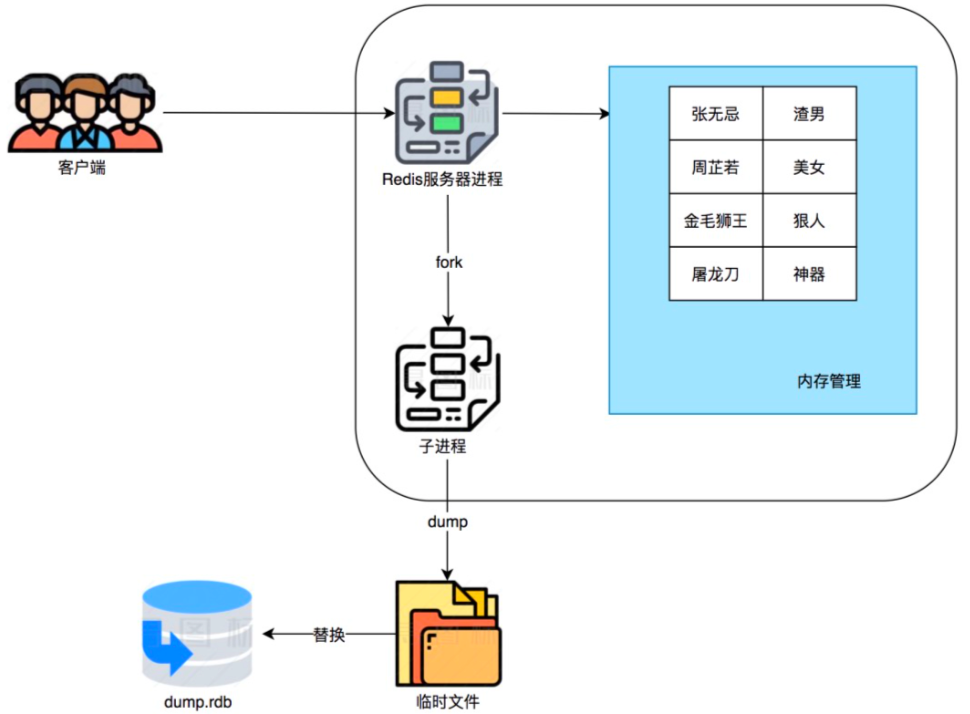
1.Fork出一个子进程专门做持久化
2.子进程写到临时的RDB文件
3.新的RDB文件替代旧的RDB文件
RDB的写时拷贝
其实RDB过程中,Redis是继续处理操作命令的,也就是数据是能被修改的。
fork创建出子进程之后,会复制父进程的页表,此时两个页表指向的是同一块物理内存。
当父进程出现新的数据后,物理内存才会被复制一份。
主进程和子进程
Redis使用bgsave对内存的数据做快照,这个操作是由bgsave子进程在后台完成的,执行时不会阻塞父进程的主线程,使的主线程还可以继续修改数据。这目的就是减少创建子进程时的消耗,加快创建子进程的速度,毕竟子进程创建时是可能阻塞主线程的。
由于写时拷贝,只有发生写操作,主进程才会复制一份内存,在这个内存上进行修改数据,子进程一直持久化的是之前的数据。
AOF详解
打开AOF
redis.conf文件中:
go
appendonly no
appendfilename "appendonly.aof"将appendonly设置为yes,即可打开AOF。
AOF的流程
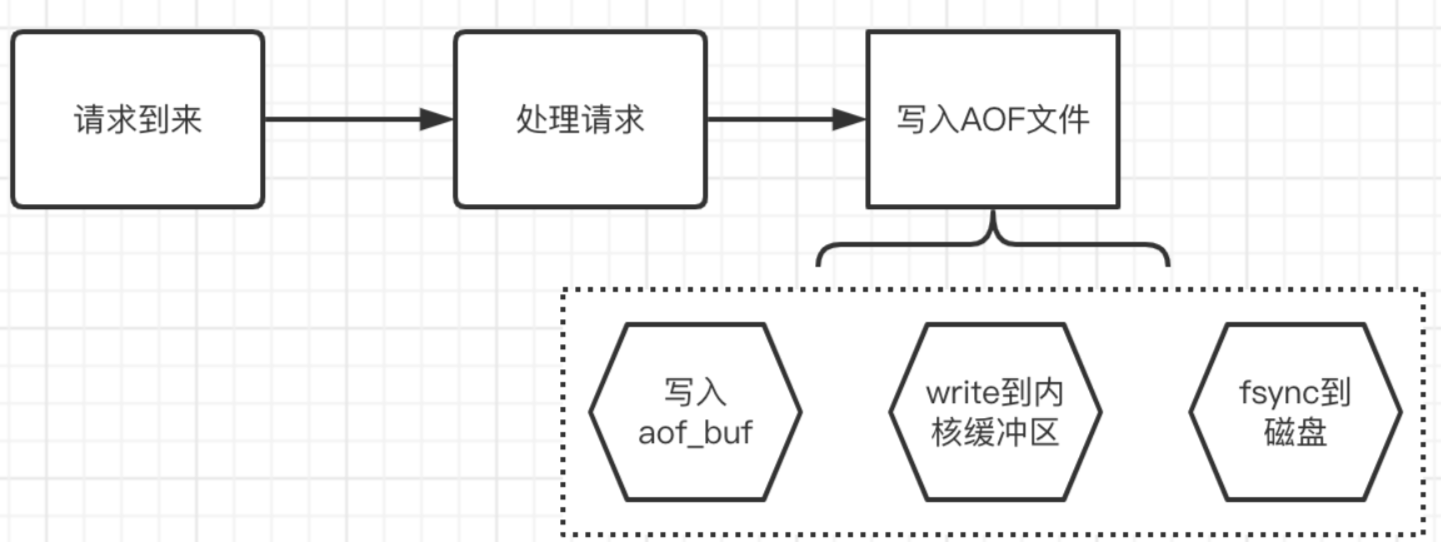
核心流程分为:1.请求到来 2.处理请求 3.写入AOF文件
由于每条操作都会记录进AOF,所以有可能会影响Redis的执行性能。
于是,Redis通过提供3种刷盘策略减小影响:
1.appendfsync always:每次请求都刷入AOF,非常慢,但是数据非常安全
2.appendfsync everysec:每秒刷盘一次,速度足够快,在崩溃场景下会损失1秒的数据
3.appendfsync no:从不主动刷盘,让操作系统刷盘,一般Linux30秒刷盘一次,在崩溃场景下损失30秒的数据
三种方案选择也是根据业务场景:一般都是2和3,比如简单的缓存,使用方案3,追求高性能;大部分场景都可以使用方案2
AOF写入示意图
AOF重写
AOF一直写下去会造成aof文件体积庞大的问题。
Redis针对AOF文件体积过大时,会自动在后台fork一个子进程,对AOF进行重写。也就是针对相同的key,进行合并,比如相同key的set操作,后面的set操作覆盖前面的set操作。
但是重写过程中,新插入的数据呢?
所以在重写的过程中,Redis把新的操作记录在原来的AOF缓冲区,还记录在AOF重写缓冲区。等新的AOF文件创建完毕,Redis把重写缓冲区中的数据,追加到新的AOF文件中,再用新的AOF文件替换旧的AOF文件。
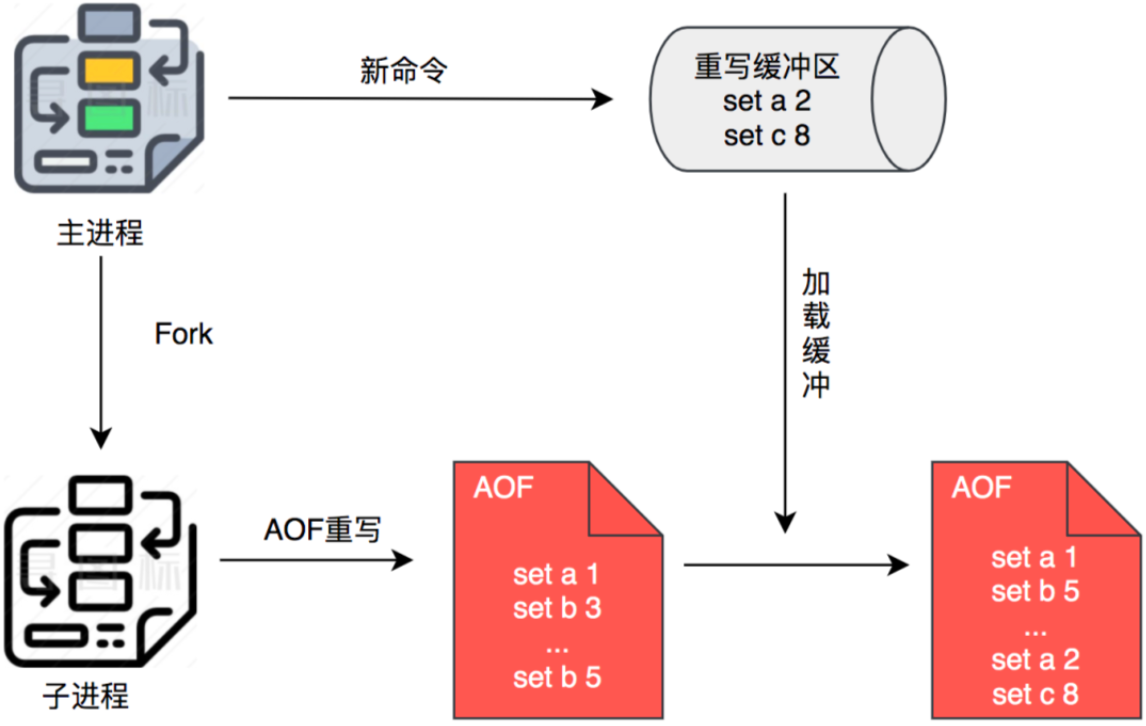
一般这个体积过大,体积指的是配置文件中的:
go
#比上次重写时数据增长100%
auto-aof-rewrite-percent 100
#超过
auto-aof-rewrite-min-size 64mb超过64M时,比上次重写的数据大一倍,则进行重写。
AOF优化-混合持久化
混合持久化并不是同时开启RDB和AOF,是实际发生AOF重写时,将当前的状态存为RDB二进制内容,写入新的AOF文件,再把重写缓冲区中的AOF文件,替代原有的AOF文件。
其实混合持久化的本质还是AOF,是一种对AOF的优化。
开启混合持久化
redis.conf:
go
aof-use-preambleRedis5.0版本之后是默认开启的,只有5.0版本后打开AOF,默认就是混合持久化。
如何区别是否开启混合持久化:在AOF文件中找以"REDIS"为文件名开头的文件即可。