FlARG
Paper : Active Retrieval Augmented Generation
Author :Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu,Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig
Affiliation : Language Technologies Institute, Carnegie Mellon University,Sea AI Lab ,FAIR, Meta
Publication : EMNLP 2023
Code :[GitHub - jzbjyb/FLARE: Forward-Looking Active REtrieval-augmented generation (FLARE)](https://github.com/jzbjyb/FLARE)(https://github.com/oneal2000/DRAGIN/tree/main)
提出FLARG,主动检索增强生成
迭代地使用对即将出现的句子的预测来预测未来的内容,然后将其用作查询来检索相关文档,以便在句子包含低置信度标记时重新生成句子。
0 前景
尽管LLM能力强大,但是会产生幻觉,RAG是一个有效的解决方案。检索增强型 LM 通常使用检索和生成设置,其中它们根据用户的输入检索文档,然后根据检索到的文档生成完整的答案。单次检索增强型 LM 的表现优于纯参数 LM,特别是对于简短的知识密集型生成任务,例如事实性问答 (QA),其中信息需求在用户的输入中很明确,仅根据输入检索一次相关知识就足够了。
功能越来越强大的大型 LM 还展示了在更复杂的任务中的能力,这些任务涉及生成长篇输出,例如长篇问答 、开放域摘要 和 (思维链;CoT) 推理 。与短篇生成相比,**长篇生成需要复杂的信息需求,而这些信息需求并不总是仅从输入中就能看出。**与人类在创作论文、散文或书籍等内容时逐渐收集信息的方式类似,使用 LM 进行长篇生成需要在整个生成过程中收集多条知识。例如,要生成关于特定主题的摘要,基于主题名称 arX 的初始检索可能无法涵盖所有方面和细节。在生成过程中,根据需要检索额外信息至关重要,例如在生成某个方面(例如,乔·拜登的教育历史)或特定细节(例如,乔·拜登总统竞选公告的日期)时。
在整个生成过程中,人们进行了多次检索尝试包括使用过去上下文以固定间隔检索额外信息 的方法,这些方法可能无法准确反映 LM 未来想要生成的内容或在不合适的时间点进行检索。 多跳 QA 中的一些工作将完整问题分解为子问题,每个子问题都用于检索额外信息。
1 动机
我们提出以下问题:我们能否创建一个简单而通用的检索增强型 LM,在整个生成过程中主动决定何时检索什么,并适用于各种长篇生成任务?
2方法
FLARE 适用于任何现有的 LM,在推理时无需额外训练。
我们的直觉是:(1) 语言模型应该只在没有必要知识时检索信息,以避免不必要或不适当的检索;(2) **检索查询应该反映未来一代的意图。**我们提出了两种前瞻性的主动检索增强生成 (FLARE) 方法来实现主动检索增强生成框架。第一种方法提示语言模型在必要时生成检索查询,同时使用检索鼓励指令生成答案,表示为 FLAREinstruct。第二种方法直接使用语言模型的生成作为搜索查询,表示为 FLAREdirect,它迭代地生成下一个句子以深入了解未来的主题,如果存在不确定的标记,则检索相关文档以重新生成下一个句子。
为了帮助长格式生成进行检索,我们提出了主动检索增强生成。这是一个通用框架,可以在生成过程中主动决定何时检索以及检索什么,使检索和生成交错。正式地,在步骤 t(t ≥ 1)时,检索查询 qt 基于用户输入 x 和之前生成的输出 y<t = y0, ..., yt−1 制定:

其中 qry(·) 是查询公式函数。在开始时 (t = 1),上一代为空 (y<1 = ∅),用户输入用作初始查询 (q1 = x)。给定检索到的文档 Dqt,LM 不断生成答案,直到触发下一次检索或到达结尾:

其中 yt 表示当前步骤 t 生成的标记,而 LM 的输入是检索到的文档 Dqt、用户输入 x 和上一代 y<t 的串联。我们丢弃之前检索到的文档 ∪t ′ < tDqt ′,仅使用当前步骤中检索到的文档来调节下一代,以防止达到 LM 的输入长度限制。

2.1 FLARE with Retrieval Instructions

受 Toolformer的启发,表达检索信息需求的一种直接方式是在需要附加信息时生成"Search(query)"。比如 " 加纳国旗上的颜色有以下含义。红色代表搜索(加纳国旗红色含义)烈士的鲜血,..." 在使用 GPT-3.5 模型时仅提供 API 访问,我们通过少量提示来引发此类行为。

具体来说,对于下游任务,我们将与搜索相关的说明和范例放在开头作为技巧 1,然后将下游任务的说明和范例放在后面作为技巧 2。给定一个测试用例,我们要求 LM 结合技巧 1 和 2 来在执行任务时生成搜索查询。 提示的结构如提示 3.1 所示,完整详细信息可在提示 D.3 中找到。
如图 2 所示,当 LM 生成"搜索(查询)"(以灰色斜体显示)时,我们停止生成并使用查询词来检索相关文档,这些文档被添加到用户输入之前以帮助将来的生成,直到生成下一个搜索查询或到达末尾。 附录 A 中包含了其他实现细节

2.2 Direct FLARE
由于我们无法对黑盒语言模型进行微调,我们发现 FLAREinstruct 通过检索指令生成的查询可能不可靠。因此,我们提出了一种更直接的前瞻性主动检索方法,即使用下一个句子来决定何时检索什么。
2.2.1 Confidence-based Active Retrieval
如图 1 所示,在步骤 t 中,我们首先生成一个临时的下一个句子 \\hat{s}*t = LM(\[x, y* {\
由于 LM 往往经过良好校准,低概率/置信度通常表示缺乏知识,因此,如果 s ^ t \hat{s}_t s^t的任何 token 的概率低于阈值 θ ∈ 0, 1,我们就会主动触发检索。θ = 0 表示永远不会触发检索,而 θ = 1 表示每个句子都会触发检索。

其中查询 qt 是基于 s ^ t \hat{s}_t s^t 制定的。
2.2.2 Confidence-based Query Formulation
执行检索的一种方法是直接使用下一个句子 sˆt 作为查询 qt 。这与使用 LM 生成的假设标题或段落作为检索查询或证据的方法有着相似的精神。我们将这些技术推广到需要主动信息访问的长篇生成。 我们发现使用下一个句子检索比使用前一个上下文检索的效果要好得多。 然而,它有延续其中的错误的风险。例如,如果 LM 生成句子"Joe Biden 就读于宾夕法尼亚大学"而不是正确的事实"他就读于特拉华大学",使用这个错误的句子作为查询可能会得到误导性的信息。我们提出了两种简单的方法来解决这个问题,如图 3 所示。

- Masked sentences as implicit queries.
第一种方法会屏蔽掉 s ^ t \hat{s}_t s^t中概率低于阈值 β ∈ 0, 1 的低置信度标记,其中 β 值越高,屏蔽越积极。这可以消除句子中的潜在干扰,从而提高检索准确率。
- Generated questions as explicit queries.
另一种方法是生成针对 s ^ t \hat{s}_t s^t 中低置信 span 的明确问题。例如,如果 LM 不确定"宾夕法尼亚大学",那么"乔·拜登就读于哪所大学?"这样的问题可以帮助检索相关信息。Self-ask 通过手动将后续问题插入下游任务范例实现了这一点,如后面的提示 D.2 中所示,这需要针对特定任务的注释工作。相反,我们开发了一种通用方法,无需额外注释即可生成针对低置信跨度的问题。具体来说,我们首先从 s ^ t \hat{s}t s^t中提取概率低于 β 的所有跨度。对于每个提取的跨度 z,我们提示 gpt-3.5-turbo 生成一个可以用跨度回答的问题 q t , z q{t,z} qt,z:

我们使用每个生成的问题进行检索,并将返回的文档交错成一个排名列表,以帮助后代。综上所述,查询 qt 基于 s ^ t \hat{s}_t s^t 制定如下:

2.3 Implementation Details
2.3.1 base LM
通过迭代查询其 API 在最先进的 GPT-3.5 LM 之一 text-davinci-003 上验证了我们的方法。
2.3.2 Document corpus and retrievers.
由于我们专注于检索和生成的集成,我们使用现成的检索器,将查询作为输入并返回相关文档列表。 对于主要依赖维基百科知识的数据集,我们使用 Karpukhin 等人 (2020) 的维基百科转储并使用 BM25 (Robertson and Zaragoza, 2009) 作为检索器。对于依赖开放网络知识的数据集,我们使用 Bing 搜索引擎作为我们的检索器。
2.3.3 Retrieved document formatting.
根据排序对多个检索到的文档进行线性化,然后使用 Prompt D.1 将其添加到用户输入的开头。 其他实施细节(如句子标记和效率)包含在附录 A 中。

3 Multi-time Retrieval Baselines
现有的被动多时间检索增强型 LM 也可以使用我们的框架来制定。在本节中,我们根据检索时间和内容引入了三个基线类别。这些基线并非相应论文的精确复制,因为许多设计选择不同,这使得直接比较变得不可能。我们使用相同的设置实现了它们,唯一的变化是检索时间和内容。
- 窗口
前一个窗口方法每 l 个 token 触发一次检索,其中 l 表示窗口大小。 前一个窗口生成的 token 用作查询:

这一类别中的一些现有方法是 RETRO,IC-RALM,每隔几个 token 检索一次,并且KNNLM检索每个标记。我们遵循 Ram 等人(2023)的做法,使用窗口大小 l = 16。
- 句子
前一句方法触发每个句子的检索并使用前一句作为查询,IRCoT属于此类别:
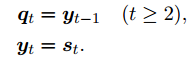
- 问题分解
问题分解方法手动注释特定于任务的样本,以指导 LM 在生成输出的同时生成分解的子问题。例如,self-ask是此类别中的一种方法,它使用 Prompt D.2 手动将子问题插入样本中。对于测试用例,每当模型生成子问题时,都会动态触发检索。

上述方法可以在生成时检索其他信息。但是,它们有明显的缺点:
(1)使用以前生成的标记作为查询可能无法反映 LM 将来打算生成的内容。
(2)以固定间隔检索信息可能效率低下,因为它可能发生在不合适的时间点。
(3)问题分解方法需要特定于任务的提示工程,这限制了它们在新任务中的通用性。
4 Experimental Setup
我们使用少样本上下文学习评估了 FLARE 在 4 种不同的知识密集型任务上的有效性。由于运行实验的成本较高,我们遵循以前的研究从每个数据集中抽取最多 500 个示例。数据集、指标和设置总结在附录 B 的表 7 中。FLARE 的超参数是根据开发集选择的,并在表 9 中列出。如果没有特别说明,FLARE 指的是 FLAREdirect。
- Multihop QA
多跳问答的目标是通过信息检索和推理来回答复杂问题。我们使用 2WikiMultihopQA (Ho et al, 2020),其中包含 来自维基百科文章的需要组合、比较或推理的2 跳复杂问题,例如"Versus 的创始人为什么死了?"
我们遵循 Wang 等人 (2022) 来生成思路链和最终答案。实验设置细节包含在附录 B 中。 我们**++使用正则表达式从输出中提取最终答案++**,并使用精确匹配 (EM) 和 tokenlevel F1、精度和召回率将其与参考答案进行比较。
- Commonsense reasoning
常识推理需要世界知识和常识知识来生成答案。我们使用 StrategyQA,它是众包是非问题的集合,例如"梨会沉入水中吗?"我们遵循 Wei 等人的方法生成思路链和最终是非答案。 详细信息包含在附录 B 中。
我们提取最终答案并使用精确匹配将其与黄金答案进行匹配。
- Long-form QA
长篇问答旨在为寻求复杂信息的问题生成全面的答案。我们使用 ASQA作为我们的测试平台,其中输入是具有多种解释的模糊问题,输出应涵盖所有问题。例如,"费城老鹰队在哪里进行主场比赛?"可能是在询问城市、体育中心或体育场。 我们发现在很多情况下,即使是人类也很难确定问题的哪个方面是模棱两可的。因此,我们创建了另一个设置(ASQA 提示),在其中我们提供了一个简短的提示,以指导 LM 在生成答案时保持正轨。上述案例的提示是"这个问题在提到哪个特定位置或场地方面是模棱两可的。"实验设置细节包含在附录 B 中。
我们使用 Stelmakh 等人 (2022) 的指标,包括 EM、基于 RoBERTa 的 QA 分数 (DisambigF1)、ROUGE (Lin, 2004) 以及结合 Disambig-F1 和 ROUGE (DR) 的总体分数。
- Open-domain summarization
开放域摘要的目标是通过从开放网络收集信息来生成有关某个主题的全面摘要。我们使用 WikiAsp,旨在生成有关 Wikipedia 中 20 个域的实体的基于方面的摘要,例如,"生成有关 Echo School(俄勒冈州)的摘要,包括以下方面:学术、历史。"实验设置细节包含在附录 B 中。
指标包括 ROUGE、基于命名实体的 F1 和 UniEval (Zhong et al, 2022),用于测量事实一致性。
5 Experimental Results
我们首先报告 4 个任务/数据集的总体结果,并将 FLARE 的性能与第 4 节中介绍的所有基线进行比较。然后,我们进行消融实验来研究我们方法的各种设计选择的有效性.
5.1 Comparison with Baselines
-
Overall results.
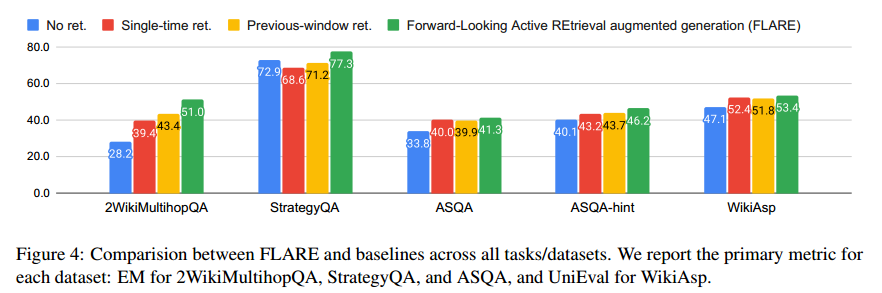
图 4 报告了 FLARE 和基线在所有任务/数据集上的整体性能。FLARE 在所有任务/数据集上的表现都优于所有基线,这表明 FLARE 是一种通用方法,可以在整个生成过程中有效地检索额外信息。 在各种任务中,多跳 QA 显示出最显著的改进。这主要是因为该任务的定义明确,并且通过 2 跳推理过程产生最终答案的特定目标,这使得 LM 更容易生成主题输出。
相比之下,ASQA 和 WikiAsp 更加开放,这增加了生成和评估的难度。ASQA-hint 的改进比 ASQA 更大,因为在许多情况下,即使对于人类来说,识别模棱两可的方面也是一项挑战,而提供通用提示有助于 LM 保持主题。
-
Thorough comparisons with baselines.

表 1 报告了 2WikiMultihopQA 上所有基线的性能。FLARE 的表现远超所有基线,这证实了前瞻性主动检索非常有效。 大多数多时间检索增强方法的表现优于单时间检索,但具有不同的差距。使用前一句话进行检索的改进相对较小,我们假设这主要是因为前一句话通常描述的实体或关系与 2WikiMultihopQA 中的下一句话不同。 而前一个窗口方法可能会使用句子的前半部分来检索可能有助于生成后半部分的信息。 在所有基线中,问题分解方法(Press et al, 2022)取得了最佳表现。这并不奇怪,因为用分解的子问题手动注释的上下文示例(提示 D.2)指导 LM 生成与未来世代的主题/意图一致的子问题。FLARE 的表现优于该基线,表明手动示例注释对于有效的未来感知检索不是必需的。FLAREinstruct 和问题分解之间的差距很大,这表明教 LM 使用任务通用检索指令和示例生成搜索查询具有挑战性。
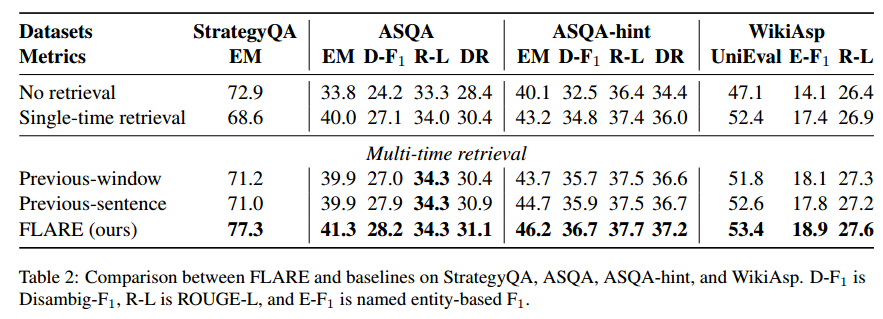
我们在表 2 中报告了其他数据集的所有指标。FLARE 在所有指标方面都优于基线。使用先前的窗口在 ASQA 上的单次检索表现不佳,我们推测这是因为前一个窗口不能准确反映未来意图。由于我们专注于评估事实性,因此强调事实内容的指标(例如 EM、Disambig-F1、UniEval)比针对所有标记计算的指标(ROUGE-L)更可靠。
5.2 Ablation Study
-
Importance of forward-looking retrieval.


我们首先验证了前瞻性检索比基于过去语境的检索更有效。我们在 2WikiMultihopQA 和 ASQA-hint 上进行了消融实验,比较了使用前一句和后一句的检索。具体来说,这两种方法都检索了每个句子,并直接使用完整的前一句/后一句作为查询。如表 3 所示,使用下一句进行检索明显优于使用前一句,证实了我们的假设。 我们还使用不同数量的过去标记作为查询运行了前一个窗口方法。如表 4 所示,过去的经历损害了表现,进一步证实了我们的假设,即以前的背景可能与后代的意图无关。
-
Importance of active retrieval.
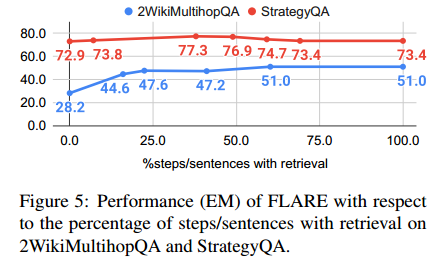
接下来,我们研究主动检索阈值 θ 如何影响性能。为了将我们的方法从不检索改为检索每个句子,我们将决定何时触发检索的置信度阈值 θ 从 0 调整为 1。然后,我们计算激活检索的步骤/句子的比例,并在此基础上呈现性能。如图 5 所示,在 2WikiMultihopQA 上,当检索百分比超过 60% 时,性能达到稳定水平,这表明当 LM 有信心时,检索是不必要的。在 StrategyQA 上,当检索百分比超过 50% 时,性能会下降,这表明不必要的检索会引入噪音并阻碍原始生成过程。我们发现触发 40%-80% 的句子的检索通常会在任务/数据集上带来良好的性能。
-
Effectiveness of different query formulation methods

我们研究了通过掩码形成隐式查询,通过问题生成形成的显示查询。在表 5 中,我们比较了使用不同掩蔽阈值 β的 FLARE 的性能。直接用完整句子检索(β = 0)比用低概率屏蔽标记更差,证实了我们的假设,即低置信度错误标记会分散检索者的注意力。我们在表 6 中比较了隐式和显式查询制定方法。两种方法的性能相似,表明两种方法都可以有效地反映信息需求。

6 限制
我们还对 Wizard of Wikipedia和 ELI5进行了实验,发现 FLARE 并没有带来显著的收益。Wizard of Wikipedia 是一个知识密集型对话生成数据集,其输出相对较短(平均约 20 个标记),因此可能不需要检索多个不同的信息。ELI5是一个长篇 QA 数据集,需要对开放式问题进行深入回答。由于 Krishna 等人中提到的问题,例如难以在检索和评估中建立生成基础,单次检索和 FLARE 都没有比不使用检索带来显著的收益。 从工程角度来看,使用简单的实现交错生成和检索会增加开销和生成成本。 LM 需要多次激活(每次检索激活一次),并且无缓存实现还需要在每次检索后重新计算上一次激活。这个问题可以通过特殊的架构设计来缓解,这些设计可以独立编码检索到的文档 Dqt 和输入/生成 (x/y<t)。
7 结论
进行深入回答。由于 Krishna 等人中提到的问题,例如难以在检索和评估中建立生成基础,单次检索和 FLARE 都没有比不使用检索带来显著的收益。 从工程角度来看,使用简单的实现交错生成和检索会增加开销和生成成本。 LM 需要多次激活(每次检索激活一次),并且无缓存实现还需要在每次检索后重新计算上一次激活。这个问题可以通过特殊的架构设计来缓解,这些设计可以独立编码检索到的文档 Dqt 和输入/生成 (x/y<t)。
7 结论
为了通过检索增强功能帮助长格式生成,我们提出了一个主动检索增强生成框架,该框架决定在生成过程中何时检索以及检索什么。我们通过前瞻性主动检索实现此框架,如果即将到来的句子包含低置信度标记,则迭代地使用即将到来的句子来检索相关信息并重新生成下一个句子。在 4 个任务/数据集上的实验结果证明了我们方法的有效性。未来的方向包括更好的主动检索策略和开发用于主动信息集成的高效 LM 架构。