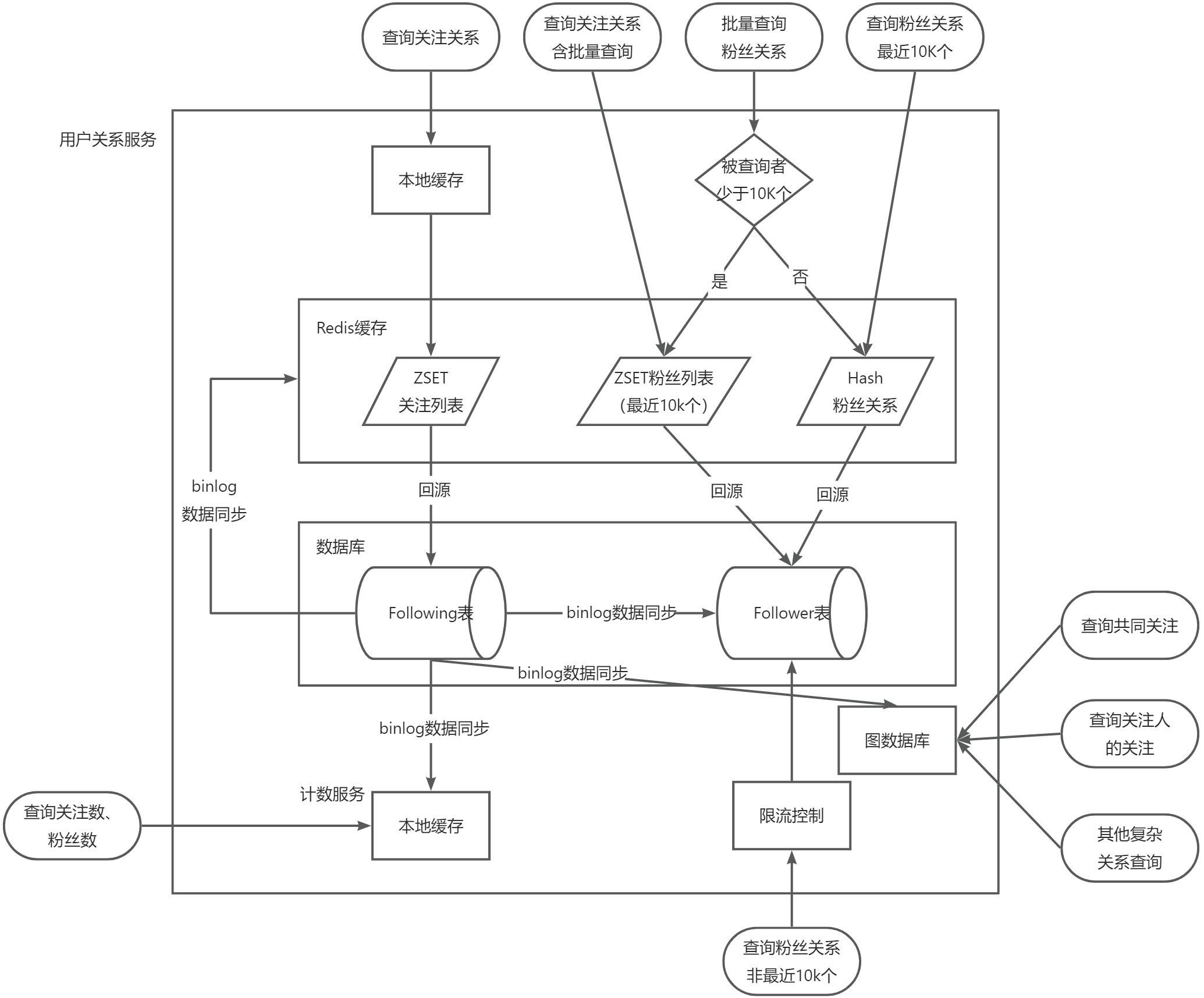
用户关系服务
内容总结自《亿级流量系统架构设计与实战》
一、概述
1、功能
任何注重用户互动的互联网应用,都会将用户之间的关注功能作为产品的重要功能之一,因此它允许用户订阅其他用户的动态,以便获取用户的更新和动态。关注功能对互联网应用的重要性体现如下:
- 促进社交互动
- 个性化推荐
- 增加用户粘性
2、能力
用户关系服务负责处理用户之间的关注行为,其提供的相关接口应该包含如下能力:
- 关注与取消关注的接口
- 查询用户关注列表的接口
- 查询用户粉丝列表的接口
- 查询用户的关注数与粉丝数的接口
- 查询用户关系的接口
二、设计
1、Redis ZSET设计
使用两个ZSET对象分别维护其关注列表和粉丝列表
- following_{用户id}:Member为被关注的用户id,对应的Score为关注行为发生时间
- follower_{用户id}:Member为粉丝用户id,对应的Score为用户被关注行为发生的时间
当数据量大时,内存资源成本会很高,。所以ZSET方案仅适用于社交属性不强,或者用户量级不大的小型应用,并不适合拥有海量用户、社交属性强的应用。
2、关系型数据库设计
数据模型:user_relation
| 字段名 | 类型 | 含义 |
|---|---|---|
| id | bigint | 主键 |
| from_user_id | bigint | 关注者用户ID |
| to_user_id | bigint | 被关注者用户ID |
| type | int | 关注类型,1正在关注2取消关注 |
| update_time | date | 修改时间 |
索引:
- idx_from_user_id
- idx_to_user_id
此种方式仅限于能用,这种关注天然就具备大量数量的特性,当数据量上来以后势必会遇到分表,此时会遇到该以什么维度分的问题,显然这个问题是无解的。
3、分库分表设计
可以创建两张user_relation表,分别为Following、Follower,其结构和user_relation一模一样。当其中一张表数据更新时,通过binlog日志完成数据同步
Following、Follower表:
| 字段名 | 类型 | 含义 |
|---|---|---|
| id | bigint | 主键 |
| from_user_id | bigint | 关注者用户ID |
| to_user_id | bigint | 被关注者用户ID |
| type | int | 关注类型,1正在关注2取消关注 |
| update_time | date | 修改时间 |
这里唯一要考虑的是,建立索引的方式。基于用户关系服务需要提供的能力,以及MySQL查询时的聚簇索引和非聚簇索引的特点,新建索引如下:
Following表
- idx_following(from_user_id,to_user_id)
- idx_following_list(from_user_id,type,update_time)
Follower表
- idx_follower(to_user_id,form_user_id)
- idx_follower_list(to_user_id,type,update_time)
4、关注数和粉丝数
虽然可以利用数据库的count函数,但是还是更推荐使用计数器实现。即借助Reids的int或者hash完成。
5、缓存查询
在海量用户的应用中,读取用户的关注列表和粉丝数量列表,以及查询用户之间的关注关系都属于高并发读场景。
1)关注列表缓存
大部分互联网应用在设计关注功能是,都会限制关注的最大数量,防止用户滥用关注进行非法操作。以微博为例,一个用户最多关注2k人。在这样的限制下,意味用户关注列表长度不会超过2k人,因此我们可以把用户的关注列表全部缓存到Redis中。存储模型与前面保持一致
2)粉丝数缓存
粉丝列表不同,用户对粉丝数量是没有限制的。但是在真实的业务场景中,粉丝列表数百万及以上的人,Redis无法全量缓存这些数量,好在用户会专门耗费大量时间去查询全部粉丝。所以对于粉丝的缓存,可以只缓存最近的10k粉丝。对于查询最近10k粉丝的用户请求,会全部命中Redis缓存。对于查询10k之外的用户,才会查询到数据库。注意针对命中数据库的这部分流量,一定要做好限流,避免大量情况进入数据库,冲垮数据库
6、本地缓存
大V的关注列表曝光率远远大于普通用户,很多用户都会关心大V关注了那些人,并且大V的关注用户时相对谨慎,即数据相对固定。此时针对这种请求量巨大的场景,可以考虑使用本地缓存进行缓存,继而满足高并发的读场景。
7、整体流程图
用户服务整体流程图:
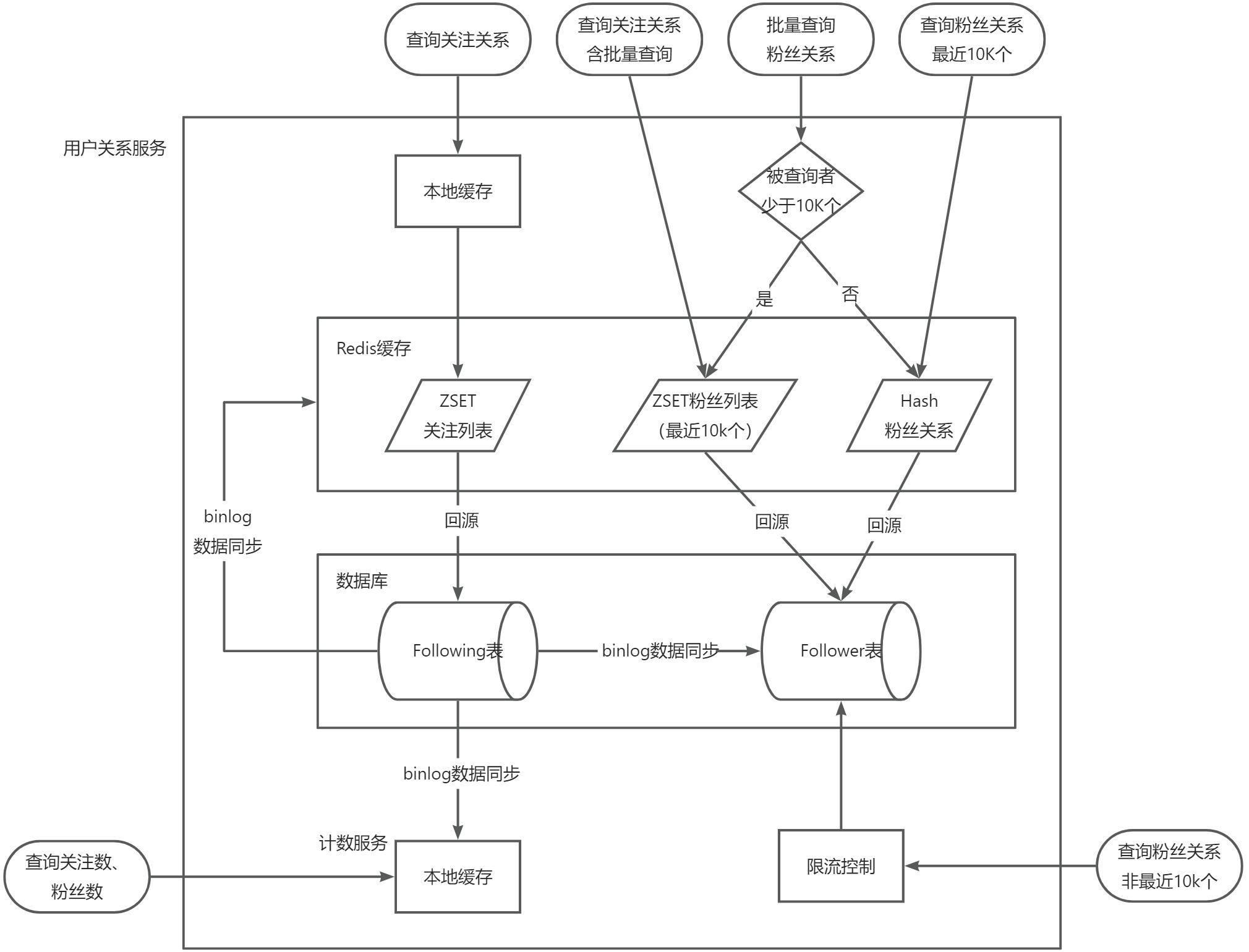
三、图数据库
使用数据库与缓存结合实现高并发的用户关系服务是一种合格的传统方案,数据库、以及缓存技术都非常成熟。服务设计成本不是很高,所以运用广泛。
但图数据库可以更加高效的描述和查询实体的关系。而用户关系服务就是图数据库的典型应用场景之一
但是尽管图数据库具有许多优点,如高效的查询性能、灵活的数据模型和可扩展性,但是目前它还没有得到真正的广泛运用,一些公司对全量推广图数据库的态度也是相对保守的
图数据库添加后查询流程图: