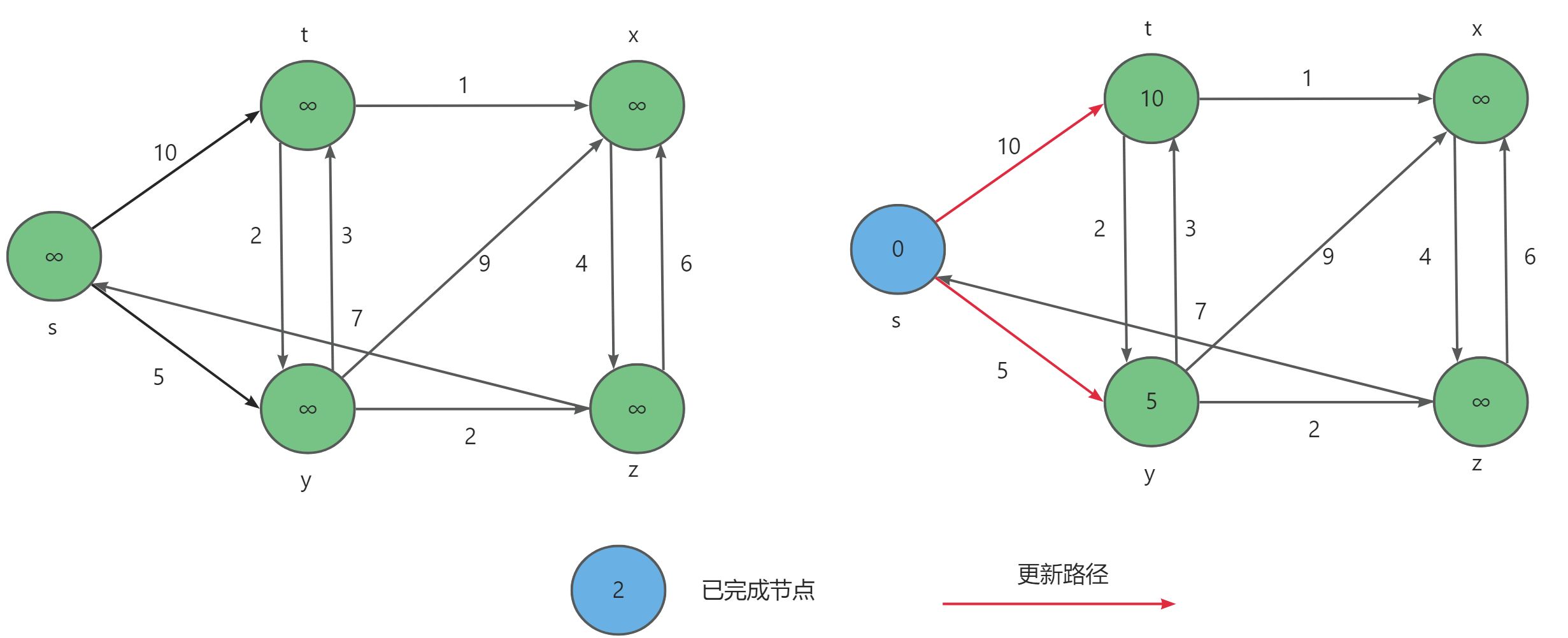
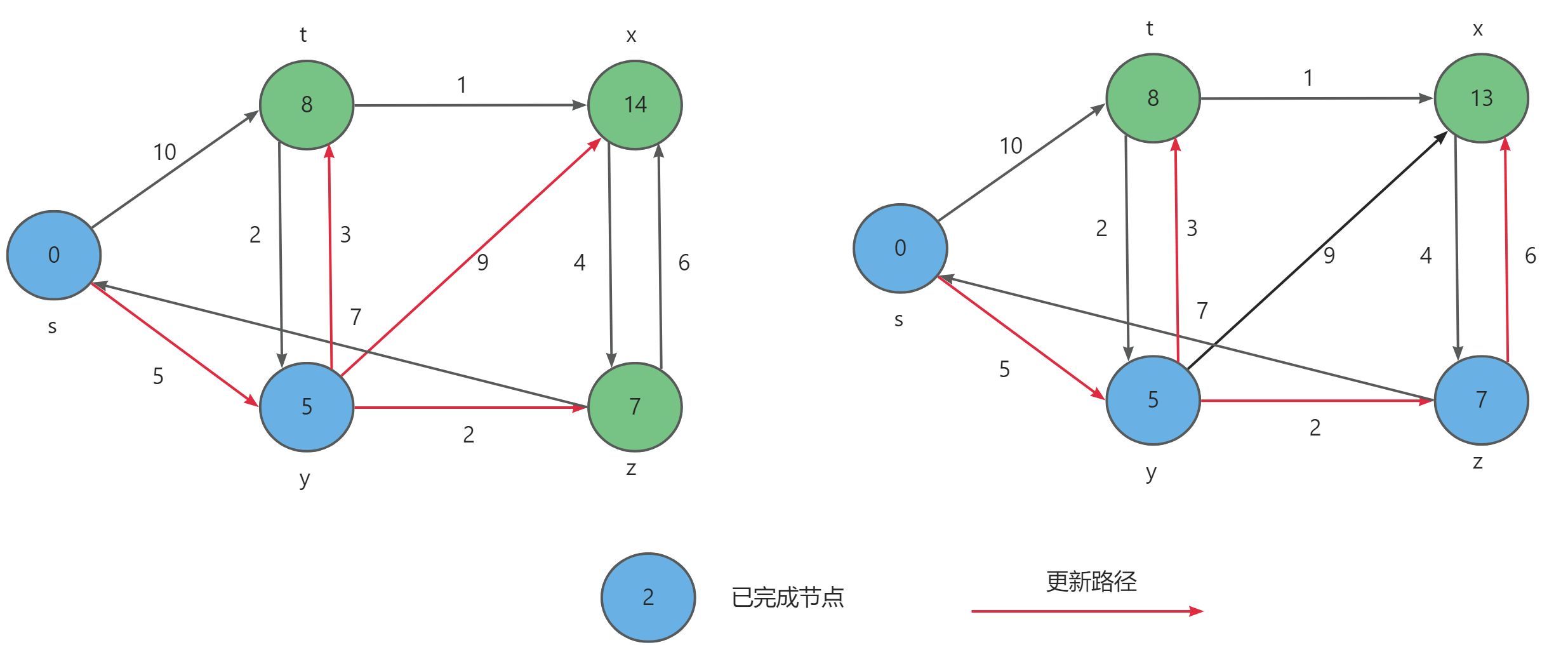
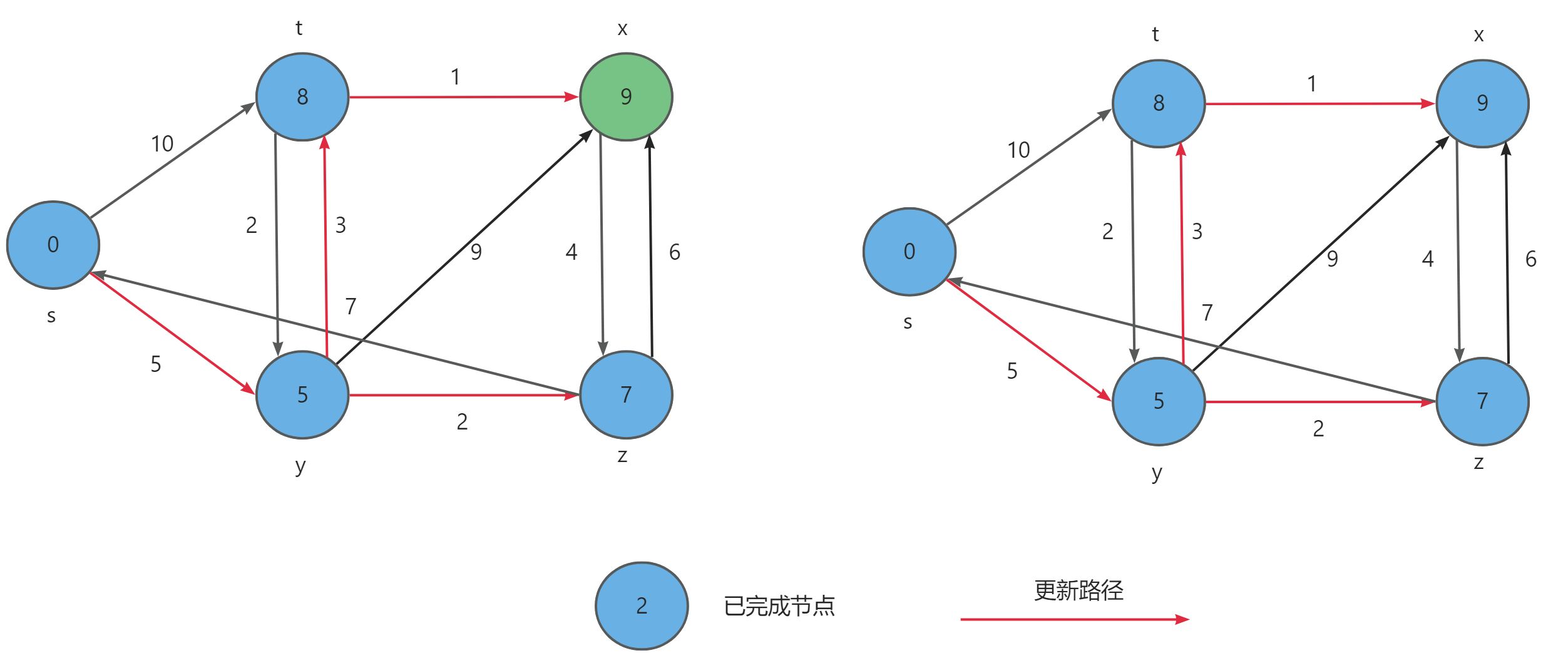
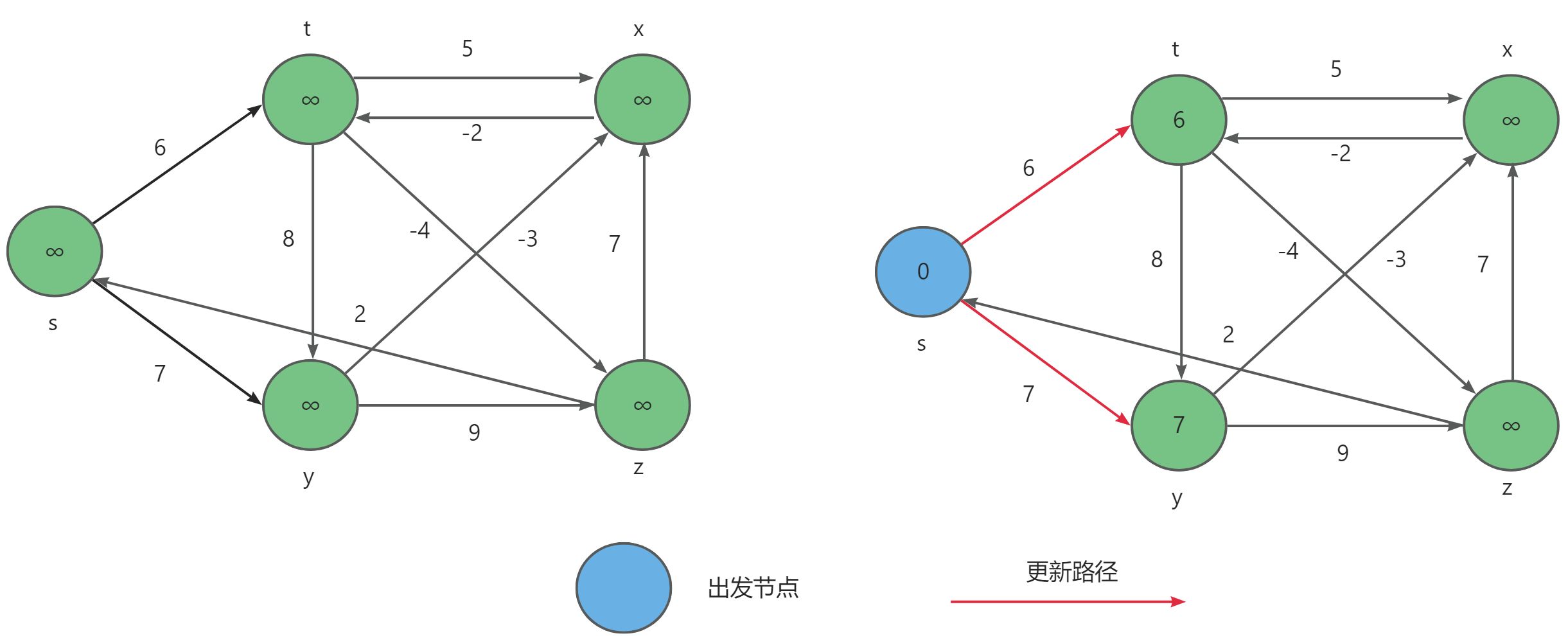
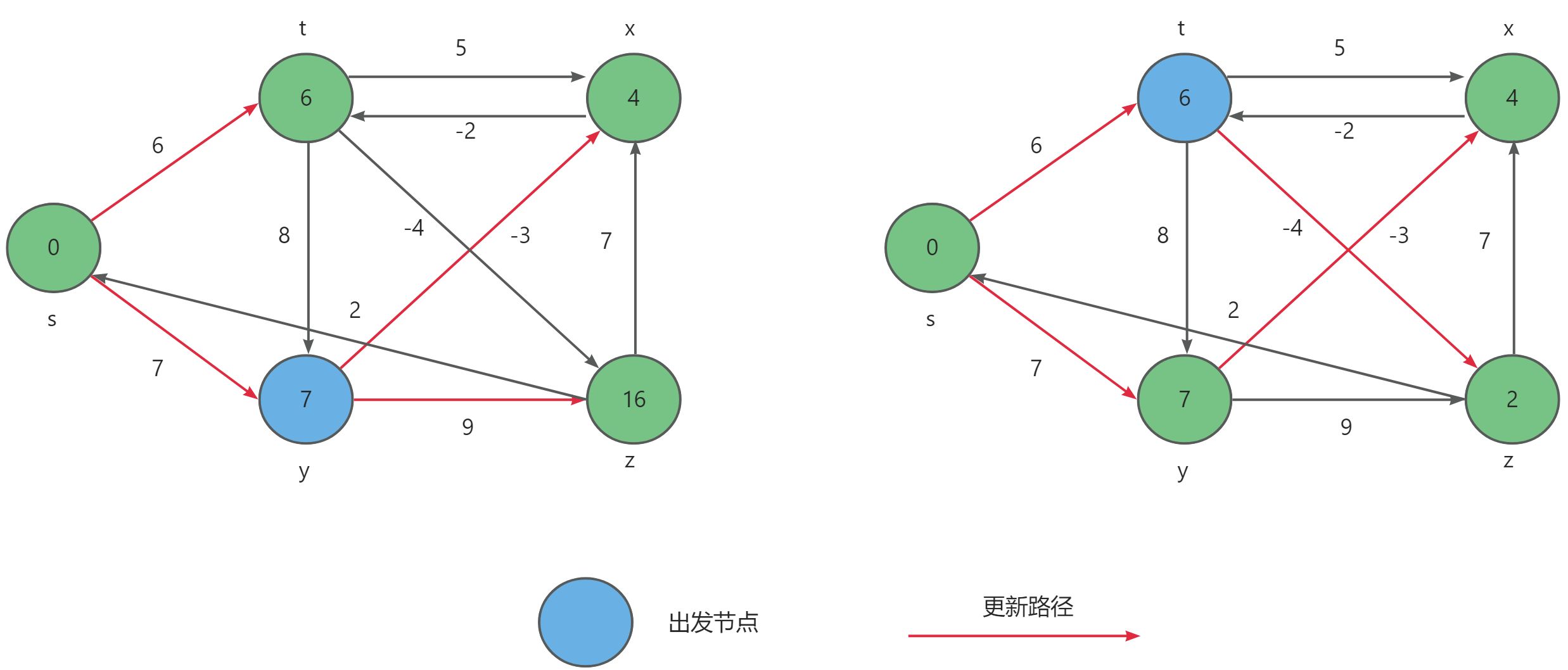
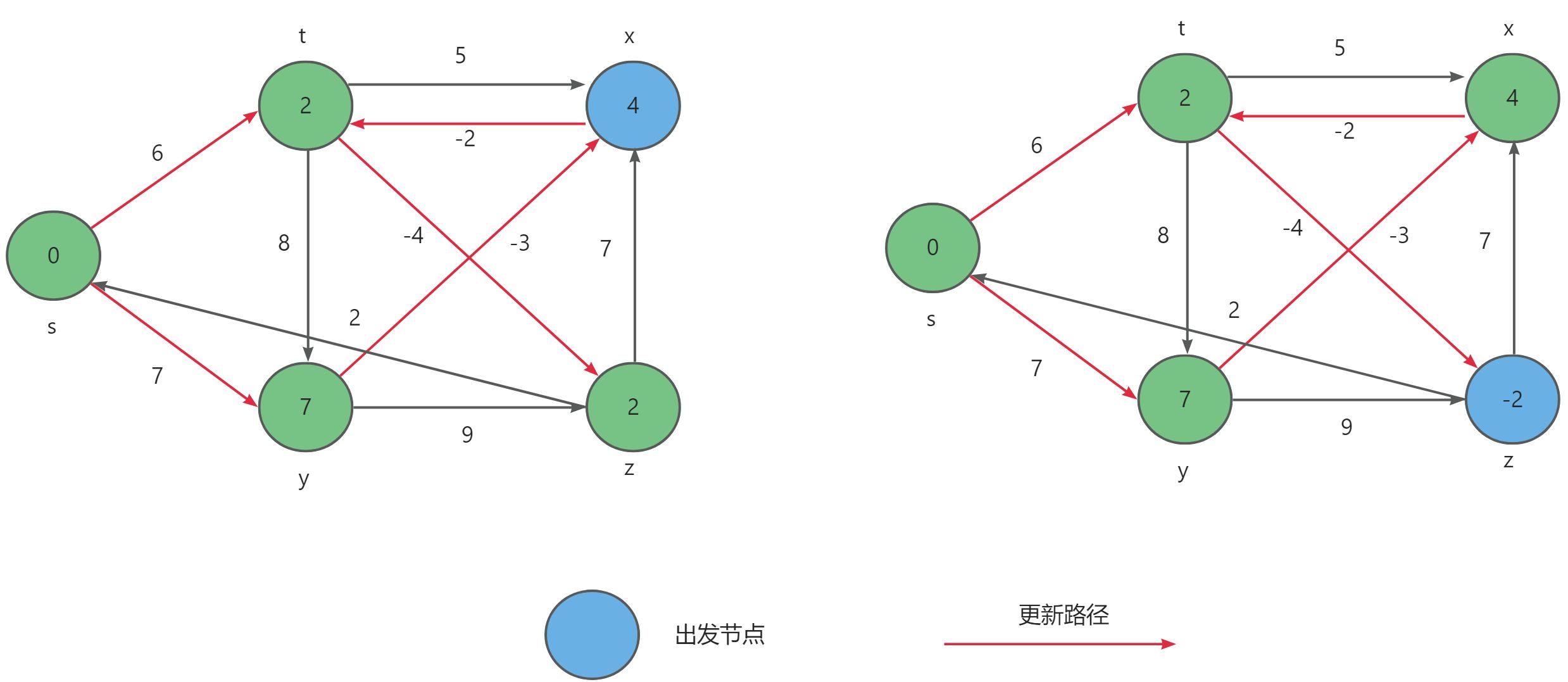
Floyd-Warshall算法的原理基于动态规划。设 D i j D_{ij} Dij 为从 i i i 到 j j j 只以 1.. k 1..k 1..k集合中的节点为中间节点的最短路径长度。
若最短路径经过点 k k k,则 D i , j , k = D i , k , k − 1 + D k , j , k − 1 D_{i,j,k} = D_{i,k,k-1} + D_{k,j,k-1} Di,j,k=Di,k,k−1+Dk,j,k−1 ;
若最短路径不经过点 k k k ,则 D i , j , k = D i , j , k − 1 D_{i,j,k} = D_{i,j,k-1} Di,j,k=Di,j,k−1 。
因此, D i , j , k = min ( D i , j , k − 1 , D i , k , k − 1 + D k , j , k − 1 ) D_{i,j,k} = \min(D_{i,j,k-1},D_{i,k,k-1} + D_{k,j,k-1}) Di,j,k=min(Di,j,k−1,Di,k,k−1+Dk,j,k−1) 。在实际算法中,为节约空间,可直接在原空间迭代,空间可降至二维。
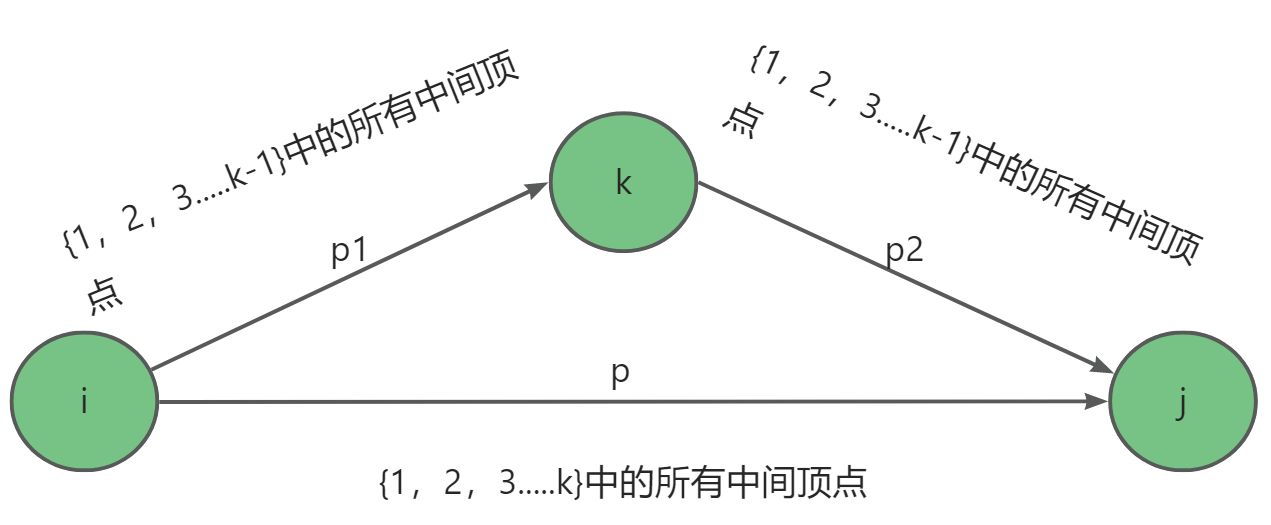
路径 p p p是从结点 i i i到结点 j j j的一条最短路径,结点 k k k是路径 p p p上编号最大的中间结点。路径 p 1 p1 p1是路径 p p p上从结点 i i i到结点 k k k之间的一段,其所有中间结点取自集合 ( 1 , 2 , ... , k − 1 ) (1,2,...,k - 1) (1,2,...,k−1)。从结点 k k k到结点 j j j的路径 p 2 p2 p2也遵守同样的规则。 算法步骤:
初始化:
构建两个二维数组,一个用于存储最短路径长度估计值 D i j D_{ij} Dij,初始时,若两点之间有直接边则为边的权值,否则为无穷大;另一个数组用于记录路径的前驱节点。
动态更新:
对于每个中间顶点 k k k,遍历所有的顶点对 i i i 和 j j j。如果 D i k + D k j < D i j D_{ik} + D_{kj} < D_{ij} Dik+Dkj<Dij,则更新 D i j D_{ij} Dij 为 D i k D_{ik} Dik + D k j D_{kj} Dkj,并更新前驱节点。
//FloydWarshall
void FloydWarshall(vector<vector<W>>& dist, vector<vector<int>>& pPath)
{
//初始化
int n = _vertexs.size();
dist.resize(n, vector<W>(n, MAX_W));
pPath.resize(n, vector<int>(n, -1));
//初始化直接相连的边
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (_matrix[i][j] != MAX_W)
{
dist[i][j] = _matrix[i][j];
pPath[i][j] = i;
}
//顶点本身
if (i == j)
{
dist[i][j] = W();
}
}
}
//依次取每个顶点作为中间节点
for (int k = 0; k < n; k++)
{
//起始顶点
for (int i = 0; i < n; i++)
{
//结束顶点
for (int j = 0; j < n; j++)
{
// i->k + k->j 比 i->j前面更新的距离更短,则更新
if (dist[i][k] != MAX_W && dist[k][j] != MAX_W &&
dist[i][k] + dist[k][j] < dist[i][j])
{
dist[i][j] = dist[i][k] + dist[k][j];
pPath[i][j] = pPath[k][j];
}
}
}
}
}
2. 复杂度分析
2.1 Dijkstra
时间复杂度:
时间复杂度为 O ( N 2 ) O(N^2) O(N2),这里的 N N N 代表图中顶点的数量。具体原因如下:
使用邻接矩阵存储图时,每次从未确定最短距离的顶点中找到距离最小的顶点需要 O ( N ) O(N) O(N)的时间,而总共要进行 N N N次这样的操作。对于每个确定了最短距离的顶点,更新其邻接顶点的距离也需要 O ( N ) O(N) O(N)的时间,因为需要遍历所有顶点。所以总的时间复杂度为 O ( N 2 ) O(N^2) O(N2)。
空间复杂度:
空间复杂度为 O ( N ) O(N) O(N)。主要原因是需要存储每个顶点到源点的距离以及该顶点是否已确定最短距离等信息。对于有 N N N 个顶点的图,这些信息总共需要 O ( N ) O(N) O(N) 的空间。具体来说:
需要一个标记数组来记录每个顶点是否已确定最短距离,这个数组的大小也为 N N N。
需要一个数组来存储每个顶点到源点的距离,这个数组的大小为 N N N。
2.2 Bellman-Ford
时间复杂度:
总体时间复杂度为 O ( N × E ) O(N\times E) O(N×E),其中 N N N 是图中顶点的数量, E E E 是图中边的数量。
分析:Bellman-Ford算法需要对图中的边进行 N − 1 N - 1 N−1 轮遍历,每一轮遍历所有的边,以松弛操作来更新最短路径。对于每一轮,遍历所有边的时间复杂度为 O ( E ) O(E) O(E),而总共进行 N − 1 N - 1 N−1 轮,所以时间复杂度为 O ( N × E ) O(N\times E) O(N×E)。
当使用邻接矩阵实现时,遍历图中的所有边的时间复杂度变为 O ( N 2 ) O(N^2) O(N2),从而导致上述代码的时间复杂度变为 O ( N 3 ) O(N^3) O(N3)。
空间复杂度:
空间复杂度为 O ( N ) O(N) O(N)。
分析:主要需要存储每个顶点到源点的最短距离,以及一些辅助信息,这些信息总共需要 O ( N ) O(N) O(N) 的空间。对于有 N N N 个顶点的图,存储每个顶点的最短距离需要 N N N 个空间,同时可能还需要一些额外的空间来存储中间状态等信息,但在整体空间复杂度中,占主导地位的仍然是存储顶点最短距离的空间,所以空间复杂度为 O ( N ) O(N) O(N)。
2.3 Floyd-Warshall
时间复杂度:
总体时间复杂度为 O ( N 3 ) O(N^3) O(N3),其中 N N N 是图中顶点的数量。
分析:Bellman-Ford算法需要对图中的边进行 N − 1 N - 1 N−1 轮遍历,每一轮遍历所有的边,以松弛操作来更新最短路径。对于每一轮,遍历所有边的时间复杂度为 O ( E ) O(E) O(E),而总共进行 N − 1 N - 1 N−1 轮,所以时间复杂度为 O ( N × E ) O(N\times E) O(N×E)。
当使用邻接矩阵实现时,遍历图中的所有边的时间复杂度变为 O ( N 2 ) O(N^2) O(N2),从而导致上述代码的时间复杂度变为 O ( N 3 ) O(N^3) O(N3)。
空间复杂度:
空间复杂度为 O ( N ) O(N) O(N)。
分析:主要需要存储每个顶点到源点的最短距离,以及一些辅助信息,这些信息总共需要 O ( N ) O(N) O(N) 的空间。对于有 N N N 个顶点的图,存储每个顶点的最短距离需要 N N N 个空间,同时可能还需要一些额外的空间来存储中间状态等信息,但在整体空间复杂度中,占主导地位的仍然是存储顶点最短距离的空间,所以空间复杂度为 O ( N ) O(N) O(N)。