本文是【训练LLM系列】的第一篇,主要重点介绍NanoGPT代码以及中文、英文预训练实践。最新版参见我的知乎:https://zhuanlan.zhihu.com/p/716442447
除跑通原始NanoGPT代码之外,分别使用了《红楼梦》、四大名著和几十本热门网络小说,进行了字符级、自行训练tokenizer以及使用Qwen2的Tokenizer的中文GPT训练尝试,并展示了续写的效果。
可供快速预训练中文GPT使用。
第二篇会通过debug分析的方式来学习NanoGPT。后续还会介绍一些开源小LLM训练项目,也是实践+代码分析的思路。

码字不易,转载请注明出处:LeonYi
0、前言
当下开源效果每过一段时间就越来越好,大模型已被头部大厂垄断,绝大多数人都不会有训练LLM的需要
大部分场景是偏应用工作中因向业务效果看齐,更多时间会花在提示词优化、数据+各种任务LoRA微调,连领域微调或全参微调的时间都越来越少或没有。
学习小LLM训练的目的,是为了掌握原理,也可以为训练自己的LLM提供指导经验:
-
项目积累的是实战落地经验,但深入LLM训练原理也很重要,这可以为设计更可行和靠谱的方案提供支撑。实战和原理互为补充。
-
就算跑过小模型预训练和增量预训练开源LLM,还是差点什么。原因在于没有深入到具体的训练过程、吃透原理。
预训练过程属于整数据和启动脚本,调参空间实在有限。只能算跑通
-
目前进展日新月异,ToDoList越来越多,与其更多的时间精力跟踪前沿,不如花时间吃透基础。模型算法千变万化但不离其宗,掌握基础可以不变应万变。
稳定且能够迁移的一些基本原理: 基础模型算法、分词器、优化器、Pytorch底层原理、算法涉及的统计、矩阵、微积分等数学、高性能计算和计算机系统原理。
使用开源的LLM有时像黑盒,但自己掌握原理实践训练出小的LLM,大模型的黑盒就被解开了。
尤其是,准备数据SFT自己训练好的Base模型,在回答问题时,是一种非常特殊的感觉。
总之,最近对小规模LLM训练实践了一番。学习的思路: 先跑项目,再学习代码,然后改动实践。
1、NanoGPT介绍
NanoGPT是karpathy在23年开源的复现GPT2规模LLM的项目:https://github.com/karpathy/nanoGPT。
项目无特别依赖,给定语料本地笔记本即可快速训练自己的小规模的因果语言模型。
1.1 项目解析
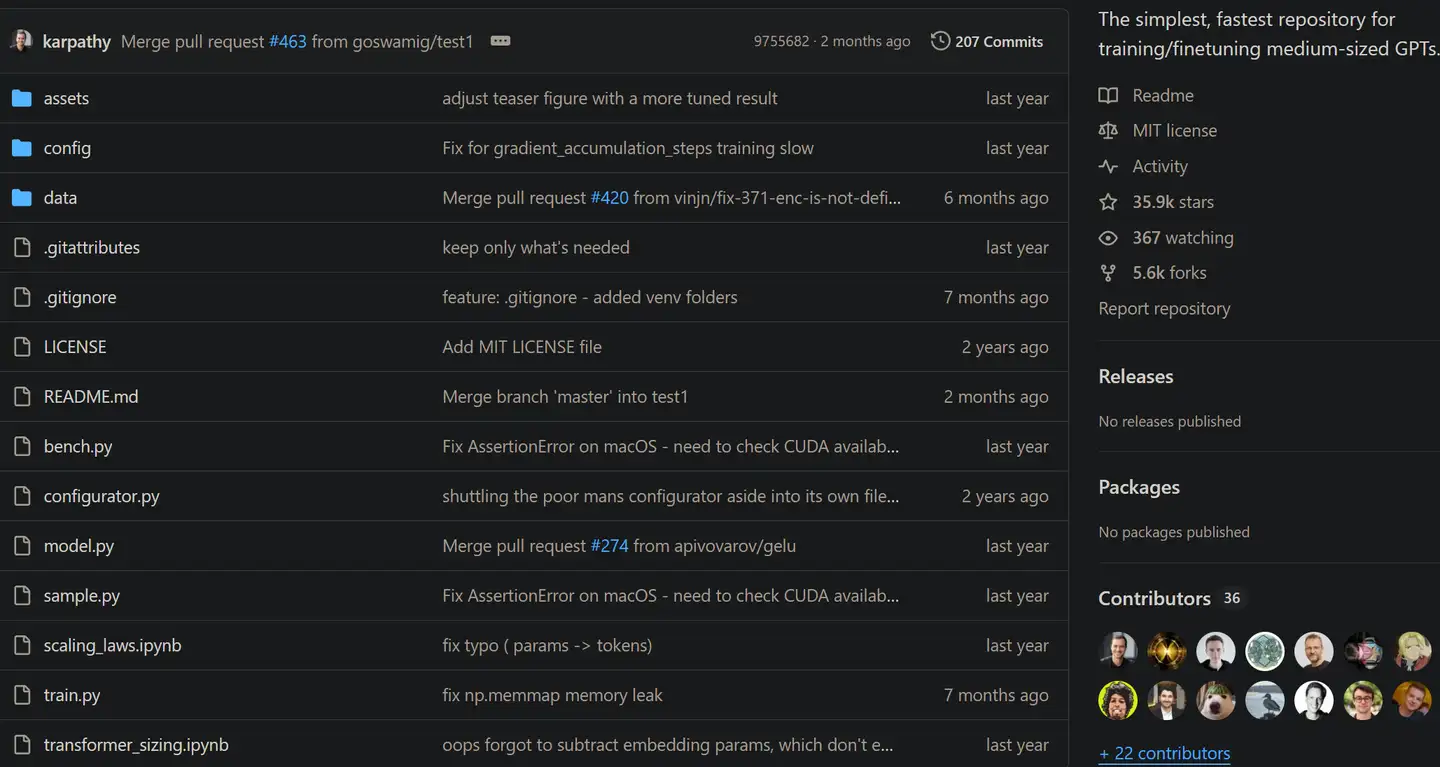
项目主要代码:
-
data
- 存放原始数据,以及预处理Tokenize的数据
- 预处理Tokenize代码(支持非常简单的字符级分词,和tiktoken的GPT2分词)。
- 预处理代码的逻辑:划分训练和验证数据,然后分词后,保存为numpy的int格式,持久化为bin文件,用于在训练时基于numpy的memmap分batch读取硬盘上的大的tokenized文件,供mini-batch的训练。 这里非常容易就可以用Transformers的tokenizers训练一个自己的分词器或直接用Qwen2等现有tokenizer
-
config
- 存放训练和微调gpt2,以及评估open gpt2的代码 这里可以自定义模型配置,以及训练的超参数
-
- 实现了GPT
-
- GPT训练代码。支持PyTorch Distributed Data Parallel (DDP)的进行单机多卡和多机多卡分布式训练。
-
- GPT推理
特性:
- 特别适合在Pycharm上debug每一步训练过程,深入理解TransformerDecoder的训练步骤。
- 适合对代码进行魔改(直接把model.py换成modeling_qwen.py,或一步步修改model.py的GPT模型结构)
接下来,对代码做个简要介绍。
实际上GPT模型结构的代码,和之前我的一篇numpy实现GPT文章:https://zhuanlan.zhihu.com/p/679330102 非常类似,只不过从numpy迁移到torch.
1.2 NanoGPT的模型代码实现
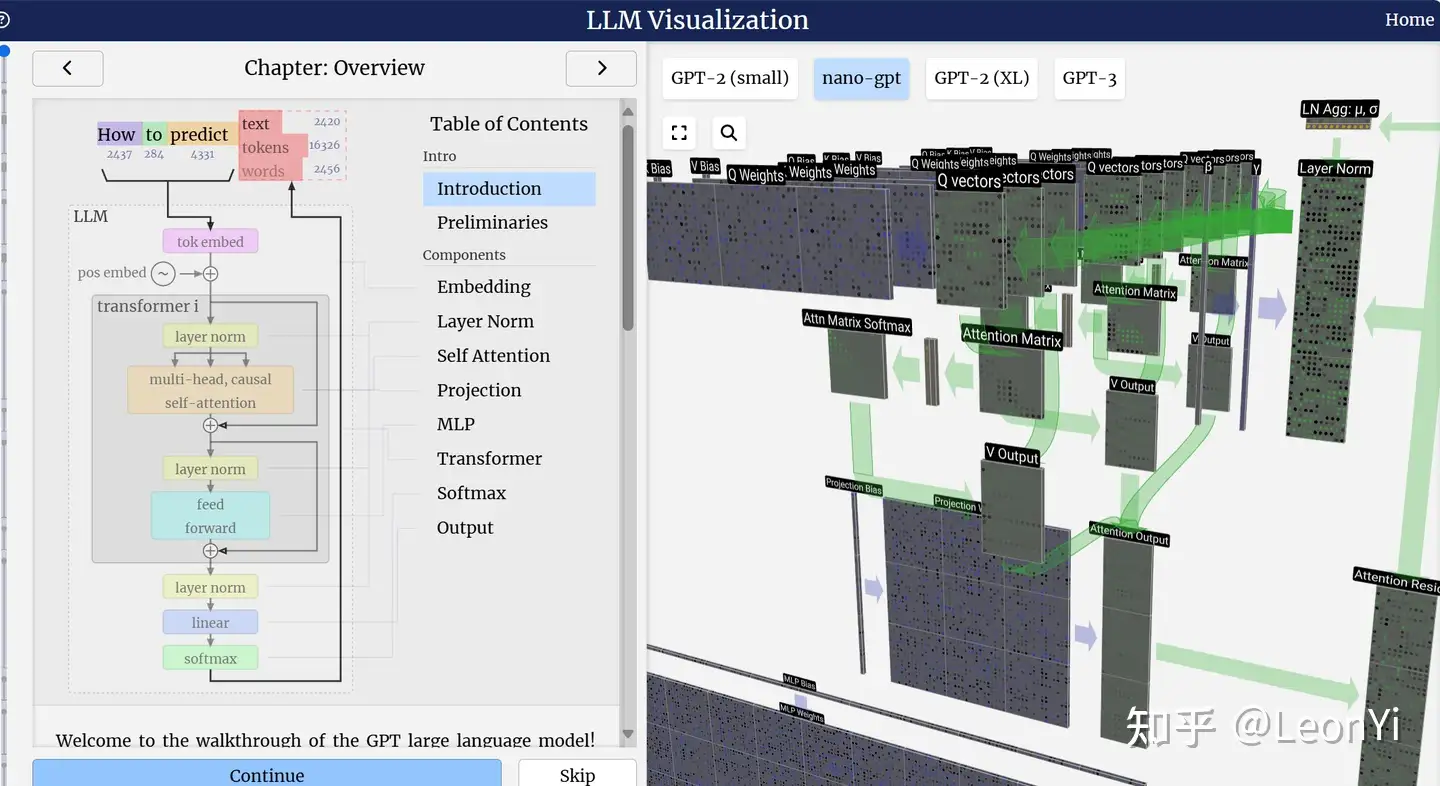
LLM-visualization项目: https://bbycroft.net/llm
可同时结合LLM-visualization和Pycharm Debug NanoGPT的代码,效果最佳。
GPT核心是CausalSelfAttention+LayerNorm+MLP 构成的TransformerDecoder, 即下面代码中的Block。
python
import math
import inspect
from dataclasses import dataclass
import torch
import torch.nn as nn
from torch.nn import functional as F
class LayerNorm(nn.Module):
""" LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False """
def __init__(self, ndim, bias):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, input):
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=config.bias)
self.gelu = nn.GELU()
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
x = self.c_fc(x) # 升维变化, (B, T, C) -> (B, T, 4*C)
x = self.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return x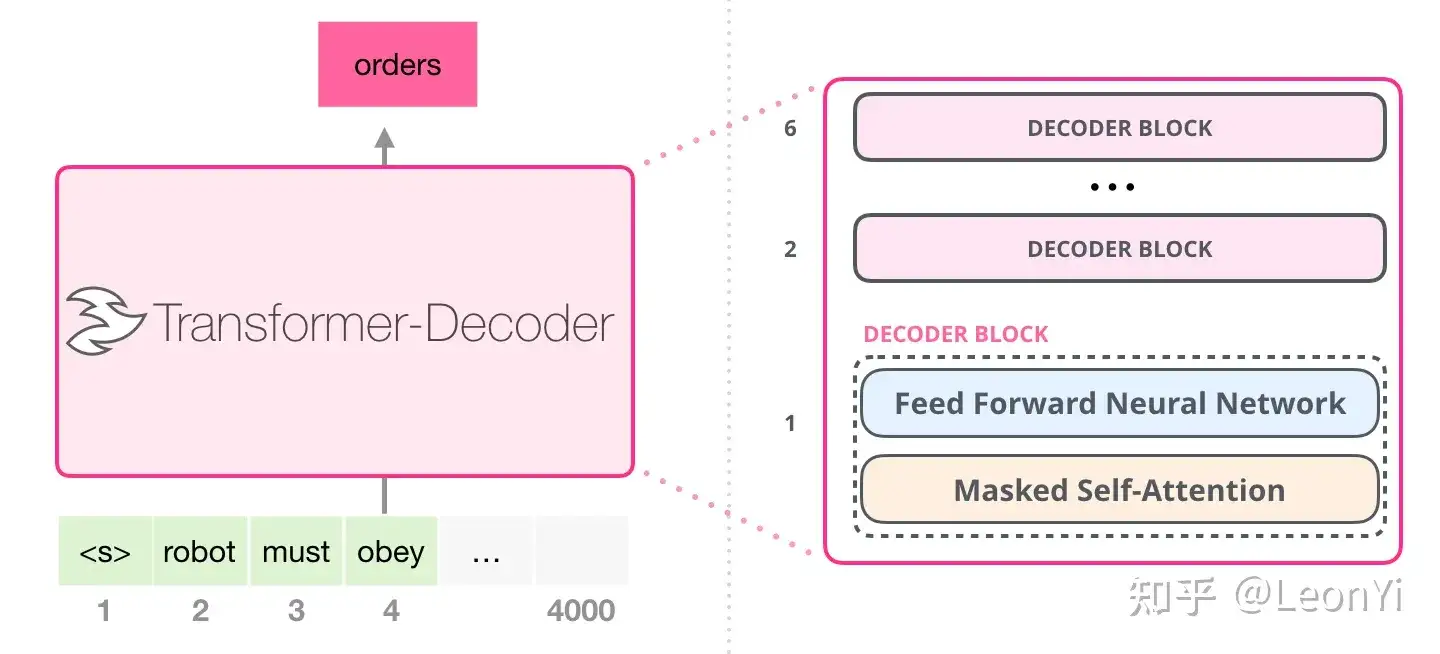
\ \\mathbf{H} = \\mathrm{softmax}\\left(\\frac{\\mathbf Q \\mathbf K\^\\top }{\\sqrt{d}}\\right) \\mathbf V \\in \\mathbb{R}\^{T\\times d} \\
python
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
if not self.flash:
print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
else:
# manual implementation of attention
## 1、计算注意力得分
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1))) # (B, nh, T, hs) x (B, nh, hs, T)
## 2、注意力得分加入因果掩码上三角矩阵
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf')) # (B, nh, T, T)
## 3、Softmax计算注意力系数
att = F.softmax(att, dim=-1) # (B, nh, T, T)
## 4、Attention Dropout
att = self.attn_dropout(att)
## 5、计算注意力结果(基于因果注意力系数进行加权求和,每个位置对当前位置及其之前的值向量加权求和)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
# re-assemble all head outputs side by side, nh个头的结果合到一起,然后变换一下
y = y.transpose(1, 2).contiguous().view(B, T, C) # (B, T, nh, hs) -> (B, T, C), view重组了tensor的shape
# output projection
y = self.resid_dropout(self.c_proj(y)) # 输出头变换, transformer的代码早在20年就调包了,但是用错了地方,GAT/序列
return y
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)
self.attn = CausalSelfAttention(config)
self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return xGPT网络结构配置和GPT实现
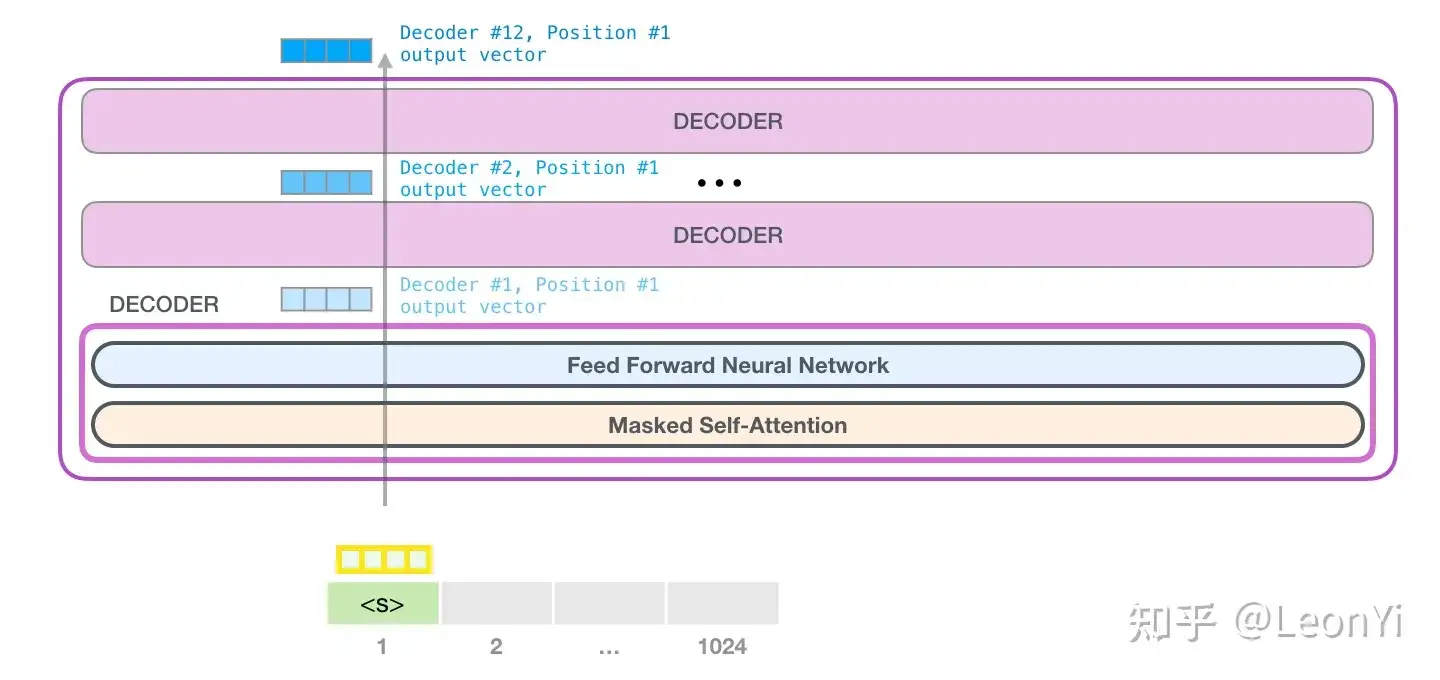
python
@dataclass
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50304 # GPT2的vocab_size为50257, 将vocab_size填充为64的倍数以提升训练效率(据说可以提升+30%)
n_layer: int = 12
n_head: int = 12
n_embd: int = 768
dropout: float = 0.0 # 预训练dropout为0,微调时可以设置小的dropout值
bias: bool = True # True: bias in Linears and LayerNorms, like GPT-2. False: a bit better and faster
class GPT(nn.Module):
def __init__(self, config):
super().__init__()
assert config.vocab_size is not None
assert config.block_size is not None
self.config = config
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
drop = nn.Dropout(config.dropout),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = LayerNorm(config.n_embd, bias=config.bias),
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.transformer.wte.weight = self.lm_head.weight # https://paperswithcode.com/method/weight-tying
# init all weights,对nn.module的map方法
self.apply(self._init_weights)
# apply special scaled init to the residual projections, per GPT-2 paper
for pn, p in self.named_parameters():
if pn.endswith('c_proj.weight'):
torch.nn.init.normal_(p, mean=0.0, std=0.02/math.sqrt(2 * config.n_layer))
# report number of parameters
print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size() # shape (b, t)
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device) # shape (t)
# forward the GPT model itself
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (t, n_embd)
x = self.transformer.drop(tok_emb + pos_emb)
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
if targets is not None:
# 如果有targets标签信息
# x, shape(b, t, d), 和lm_head, shape(d, vocab_size)做矩阵乘法(内积打分)
logits = self.lm_head(x)
# target为输入token的词表id向右偏移一个位置,即下一个token预测(还可以偏移多个呢,multi-token预测,第2个token预测🤣)
# 训练的时候,输出输入序列每一个位置的预测logit得分(极端多分类), torch计算交叉熵使用unnormalized logits(内部会归一化)
# 将每一个label对应的这个和传统的序列预测就没啥区别了。
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# 推理模式,当然只需要计算最后一个position的logits,即预测下一个token的概率
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, lossGPT预测代码
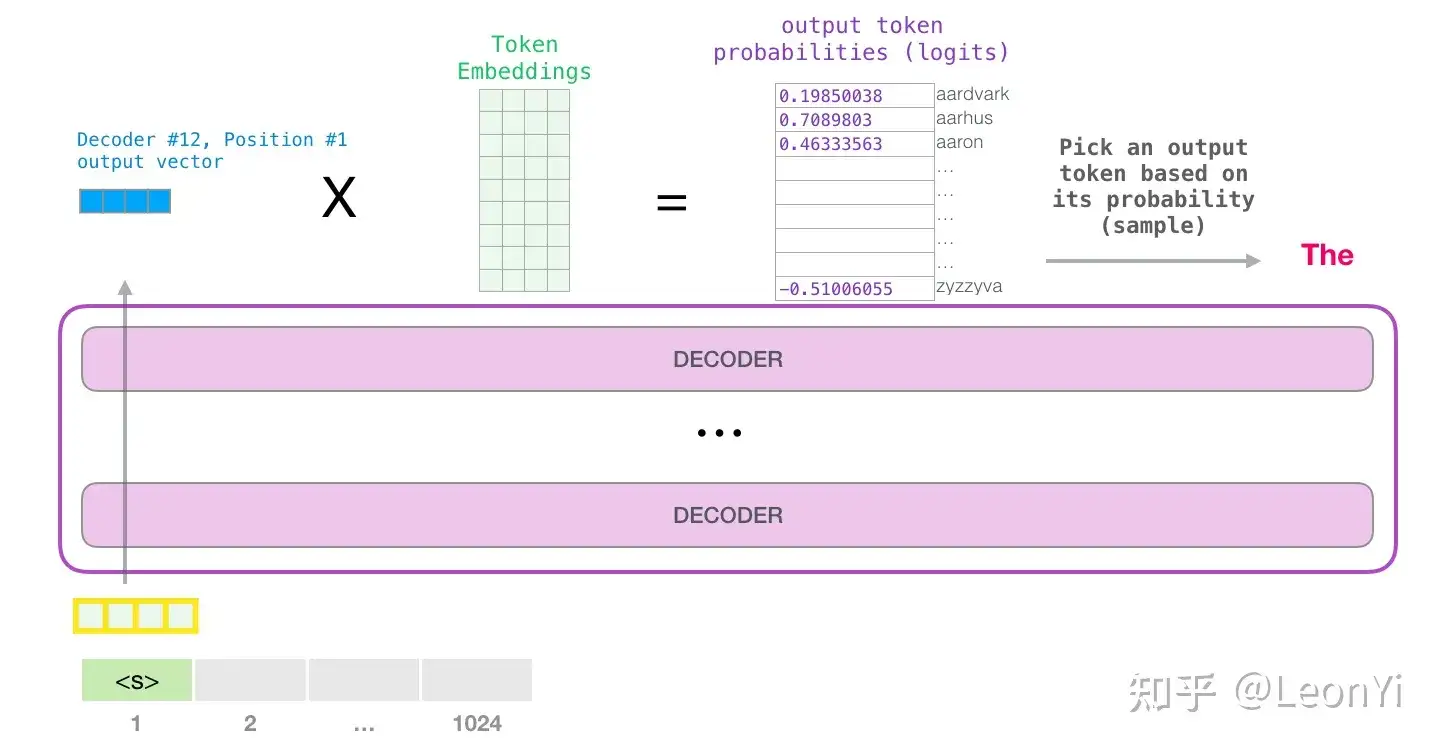
python
@torch.no_grad()
def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None):
"""
Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and complete
the sequence max_new_tokens times, feeding the predictions back into the model each time.
Most likely you'll want to make sure to be in model.eval() mode of operation for this.
"""
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.config.block_size else idx[:, -self.config.block_size:]
# 调用模型的forward预测输入序列对应位置的分类logits
logits, _ = self(idx_cond)
# Softmax前的logits之temperature概率分布缩放
logits = logits[:, -1, :] / temperature
# top-k截断
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
# 类别分布采样(多项式分布,次数为1时)
# 原理即先根据随机种子用伪随机算法生成近似均匀分布的数,然后看数落在按概率划分的连续1维空间的区域,来判断类别
idx_next = torch.multinomial(probs, num_samples=1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
return idx主要难理解一点的就是,具体的torch的3维或4维tensor的拆分和合并操作,实际GPT实现紧凑不超过150行。
这个GPT模型结构的代码,和之前我的一篇讲解picoGPT的numpy实现文章基本没啥区别,就是换成了torch代码可以自动微分计算。
https://zhuanlan.zhihu.com/p/679330102
1.3 NanoGPT训练代码
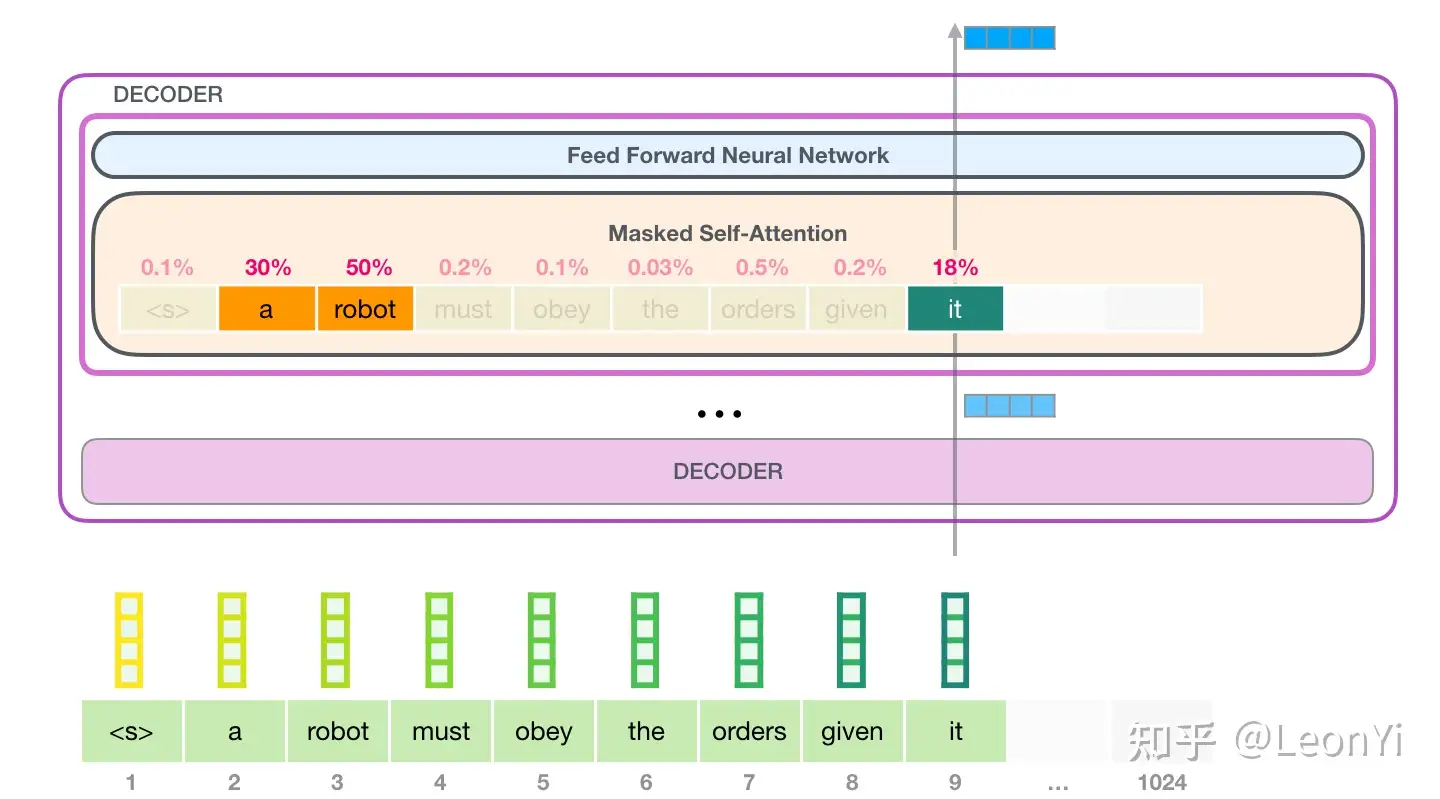
三种模型初始化方式:
- 1、scratch从头开始时训练
- 2、加载之前训练的checkpoint继续训练(即用在微调上)
- 3、基于OpenAI GPT-2的预训练权重继续训
python
model_args = dict(n_layer=n_layer, n_head=n_head, n_embd=n_embd, block_size=block_size,
bias=bias, vocab_size=None, dropout=dropout) # start with model_args from command line
if init_from == 'scratch':
# init a new model from scratch
print("Initializing a new model from scratch")
# determine the vocab size we'll use for from-scratch training
if meta_vocab_size is None:
print("defaulting to vocab_size of GPT-2 to 50304 (50257 rounded up for efficiency)")
model_args['vocab_size'] = meta_vocab_size if meta_vocab_size is not None else 50304
gptconf = GPTConfig(**model_args)
model = GPT(gptconf)
elif init_from == 'resume':
print(f"Resuming training from {out_dir}")
# resume training from a checkpoint.
ckpt_path = os.path.join(out_dir, 'ckpt.pt')
checkpoint = torch.load(ckpt_path, map_location=device)
checkpoint_model_args = checkpoint['model_args']
# force these config attributes to be equal otherwise we can't even resume training
# the rest of the attributes (e.g. dropout) can stay as desired from command line
for k in ['n_layer', 'n_head', 'n_embd', 'block_size', 'bias', 'vocab_size']:
model_args[k] = checkpoint_model_args[k]
# create the model
gptconf = GPTConfig(**model_args)
model = GPT(gptconf)
state_dict = checkpoint['model']
# fix the keys of the state dictionary :(
# honestly no idea how checkpoints sometimes get this prefix, have to debug more
unwanted_prefix = '_orig_mod.'
for k,v in list(state_dict.items()):
if k.startswith(unwanted_prefix):
state_dict[k[len(unwanted_prefix):]] = state_dict.pop(k)
model.load_state_dict(state_dict)
iter_num = checkpoint['iter_num']
best_val_loss = checkpoint['best_val_loss']
elif init_from.startswith('gpt2'):
print(f"Initializing from OpenAI GPT-2 weights: {init_from}")
# initialize from OpenAI GPT-2 weights
override_args = dict(dropout=dropout)
model = GPT.from_pretrained(init_from, override_args)
# read off the created config params, so we can store them into checkpoint correctly
for k in ['n_layer', 'n_head', 'n_embd', 'block_size', 'bias', 'vocab_size']:
model_args[k] = getattr(model.config, k)训练代码

python
optimizer = model.configure_optimizers(weight_decay, learning_rate, (beta1, beta2), device_type)
X, Y = get_batch('train') # fetch the very first batch
t0 = time.time()
local_iter_num = 0 # number of iterations in the lifetime of this process
raw_model = model.module if ddp else model # unwrap DDP container if needed
while True:
# determine and set the learning rate for this iteration
lr = get_lr(iter_num) if decay_lr else learning_rate
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# evaluate the loss on train/val sets and write checkpoints
if iter_num % eval_interval == 0 and master_process:
losses = estimate_loss()
print(f"step {iter_num}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
if losses['val'] < best_val_loss or always_save_checkpoint:
best_val_loss = losses['val']
if iter_num > 0:
checkpoint = {
'model': raw_model.state_dict(),
'optimizer': optimizer.state_dict(),
'model_args': model_args,
'iter_num': iter_num,
'best_val_loss': best_val_loss,
'config': config,
}
print(f"saving checkpoint to {out_dir}")
torch.save(checkpoint, os.path.join(out_dir, 'ckpt.pt'))
if iter_num == 0 and eval_only:
break
# forward backward update, with optional gradient accumulation to simulate larger batch size
# and using the GradScaler if data type is float16
for micro_step in range(gradient_accumulation_steps):
if ddp:
model.require_backward_grad_sync = (micro_step == gradient_accumulation_steps - 1)
with ctx:
logits, loss = model(X, Y) # 前向传播
loss = loss / gradient_accumulation_steps # scale the loss to account for gradient accumulation
# immediately async prefetch next batch while model is doing the forward pass on the GPU
X, Y = get_batch('train')
# backward pass, with gradient scaling if training in fp16
scaler.scale(loss).backward() # 反向传播
# 裁减gradient
if grad_clip != 0.0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
# 更新optimizer和scaler
scaler.step(optimizer)
scaler.update()
# 模型gradients清零并解除memory占用
optimizer.zero_grad(set_to_none=True)
# 最大训练step次数,结束训练
if iter_num > max_iters:
break2、项目实战
NanoGPT的代码(推广到任何GPT torch代码)本身对于用什么分词器是无感知的,毕竟只要求输入是int类型的token id序列。
无论输入是什么模态数据(时序、音频、图片、视频、用户点击行为序列等),只要tokenize后就能训练。
所以,无论是这套代码,还是其他的项目,本质上的模型以外的改动就是修改分词器作用于预处理encode和推理预测时decode的过程。
2.1 莎士比亚字符级shakespeare_char
这边先把tinyshakespeare的文本下下来,按下面3步走即可复现
sh
python data/shakespeare_char/prepare.py
python train.py config/train_shakespeare_char.py
python sample.py --out_dir=out-shakespeare-char配置展示
sh
root@eais-bjyo5z6grbpbqo36a86q-85b696d67f-zhx46:/mnt/workspace/nanoGPT-master# python train.py config/train_shakespeare_char.py
Overriding config with config/train_shakespeare_char.py:
# train a miniature character-level shakespeare model
# good for debugging and playing on macbooks and such
out_dir = 'out-shakespeare-char'
eval_interval = 250 # keep frequent because we'll overfit
eval_iters = 200
log_interval = 10 # don't print too too often
# we expect to overfit on this small dataset, so only save when val improves
always_save_checkpoint = False
wandb_log = False # override via command line if you like
wandb_project = 'shakespeare-char'
wandb_run_name = 'mini-gpt'
dataset = 'shakespeare_char'
gradient_accumulation_steps = 1
batch_size = 64
block_size = 256 # context of up to 256 previous characters
# baby GPT model :)
# n_layer = 6
# n_head = 6
# n_embd = 384
##### debug ####
n_layer = 2
n_head = 4
n_embd = 128
###############
dropout = 0.2
learning_rate = 1e-3 # with baby networks can afford to go a bit higher
max_iters = 5000
lr_decay_iters = 5000 # make equal to max_iters usually
min_lr = 1e-4 # learning_rate / 10 usually
beta2 = 0.99 # make a bit bigger because number of tokens per iter is small
warmup_iters = 100 # not super necessary potentially
# on macbook also add
device = 'cpu' # run on cpu only
compile = False # do not torch compile the model
tokens per iteration will be: 16,384
found vocab_size = 65 (inside data/shakespeare_char/meta.pkl)
Initializing a new model from scratch
number of parameters: 0.40M
/usr/local/lib/python3.10/site-packages/torch/amp/grad_scaler.py:131: UserWarning: torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.
warnings.warn(
num decayed parameter tensors: 10, with 434,304 parameters
num non-decayed parameter tensors: 5, with 640 parameters
using fused AdamW: False
step 0: train loss 4.1860, val loss 4.1832
iter 0: loss 4.1887, time 38322.89ms, mfu -100.00%
iter 10: loss 3.9036, time 417.94ms, mfu 0.04%
iter 20: loss 3.6104, time 400.67ms, mfu 0.04%
iter 30: loss 3.4437, time 452.36ms, mfu 0.04%
iter 40: loss 3.2072, time 445.09ms, mfu 0.04%
iter 50: loss 2.9770, time 397.14ms, mfu 0.04%
iter 60: loss 2.8188, time 482.85ms, mfu 0.04%
iter 70: loss 2.7120, time 426.90ms, mfu 0.04%
iter 80: loss 2.6770, time 434.85ms, mfu 0.04%
iter 90: loss 2.6223, time 410.70ms, mfu 0.04%
iter 100: loss 2.5966, time 444.17ms, mfu 0.04%
iter 110: loss 2.5599, time 378.64ms, mfu 0.04%
iter 120: loss 2.5563, time 459.60ms, mfu 0.04%
iter 130: loss 2.5470, time 482.69ms, mfu 0.04%训练了200step的预测结果,英文字符不太连续:
python
root@eais-bjyo5z6grbpbqo36a86q-85b696d67f-zhx46:/mnt/workspace/nanoGPT-master# python sample.py --out_dir=out-shakespeare-char --device=cpu
Overriding: out_dir = out-shakespeare-char
Overriding: device = cpu
number of parameters: 0.40M
Loading meta from data/shakespeare_char/meta.pkl...
HWAF heve wabeacar
F s sele in
WAnd hur stout arined ato ce h, tofow, couriourtheald ath as and mathise m tetil f chom, s ke ar tanetr ieaifo he s mat y dsakthe go irsten ar:
Anoupat he, pit thinougaris inge veeathed 'oilithangis, wey, ored sh toe t,
Thende me m pon.
I me beng wed timy youlre tshofundt,
And t corst thand?
MENSTUDUCWIO:
Pane mashele he y hayouthe.
Y I w INIxpare fetodis be mimicos w INILARY we atidses fand s h andathe tofery dad ge wn withisthatod br fr anfanor hith, he shat t
---------------
BEENoo arot, toth ly whond wistore thou hed we che tif d win chathere he clomapal ond br t inde heeronghen'theathowng ourat ads the maimes one shiten he ove whese thitha mbath fr ir thanore acheit t hes d inoce t whinkert sackitrmome t ond hend ind,
And n t s areroras y eethit fass ad foueld se nout as ce oore aldeath nchitherds w om y owin d hasing spllore
We thoururake,
An be mame tipy ine rar, m.
I burisorthe ng ce
MENEROLENCEN:
Achollamucais y the co as sererrury by s yodounor theer itorean2.2《红楼梦》字符级GPT
很简单,直接下载《红楼梦》,将文件重命名为input.txt下再按shakespeare_char的3步即可训练。
因为,shakespeare_char/prepare.py是按字符级别分词,这里即按中文字粒度分词,分词后词表大致4千多。
展示部分字符级别token
python
length of dataset in characters: 875,372
all the unique characters:
!"()-.:<>?---―''""...─ 、。《》〔〕ㄚㄠ一丁七万丈三上下不与丐丑专且世丘丙业丛东丝丞丢两严丧个丫中丰串临丸丹为主丽举乃久么义之乌乍乎乏乐乔乖乘乙乜九乞也习乡书乩买乱乳乾了予争事二于亏云互五井亘些亡亢交亥亦产亩享京亭亮亲亵亸人亿什仁仃仄仅仆仇今介仍从仓仔仕他仗付仙代令以仪们仰仲仵件价任份仿伊伍伏伐休众优伙会伞伟传伤伦伫伯估伴伶伸伺似伽但位低住佐佑体何余佚佛作佞你佣佩佯佳佻使侃侄侈例侍侑供依侠侥侧侪侬侮侯侵便促俄俊俏俐俑俗俘俚保俞俟信俦俨俩俭修俯俱俵俸騄马驭驮驯驰驱驳驴驸驹驻驼驾驿骂骄骆骇骊验骑骓骗骘骚骛骡骢骤骥骨骯骰骷骸髅髓高髟髯髻鬅鬒鬓鬟鬼魁魂魄魆魇魏魔鮹鱼鲁鲍鲔鲛鲜鲞鲟鲫鲸鳅鳇鳌鳏鳖鳞鳷鶒鸂鸟鸠鸡鸣鸥鸦鸩鸪鸭鸮鸯鸰鸳鸷鸹鸽鸾鸿鹃鹄鹅鹉鹊鹌鹑鹔鹘鹞鹡鹤鹥鹦鹧鹭鹰鹾鹿麀麈麋麒麝麟麦麻麾黄黉黍黎黏黑默黛黜黥黧黹黻黼黾鼋鼎鼐鼒鼓鼠鼻鼾齁齐齑齿龄龙龛龟︰﹐﹒﹔﹕﹗!(),.:;?¥
vocab size: 4,432
train has 787,834 tokens
val has 87,538 tokens训练配置
python
tokens per iteration will be: 16,384
found vocab_size = 4432 (inside data/shakespeare_char/meta.pkl)
Initializing a new model from scratch
number of parameters: 0.96M
num decayed parameter tensors: 10, with 993,280 parameters
num non-decayed parameter tensors: 5, with 640 parameters
using fused AdamW: False训练了250step的续写预测结果,不太连续且叠词会重复多次预测:
python
python sample.py --out_dir=out-shakespeare-char --device=cpu --start=黛玉见了宝玉便说
sh
Overriding: out_dir = out-shakespeare-char
Overriding: device = cpu
Overriding: start = 黛玉见了宝玉便说
number of parameters: 0.96M
Loading meta from data/shakespeare_char/meta.pkl...
黛玉见了宝玉便说:"你为这的!"宝玉听了衣服,便不着袭人忙道:"你有意思定是他也不成?"黛玉笑道:
一口,我一回来了她了一回来,在园里笑道:"你们不是我说:"我等她的?今日,是,把你们的奶奶奶奶奶,我要请你一个金桂又要骂宝玉悄悄悄道:"你不好话。"宝玉忙在还没趣,不用些'这么倒好,她,就难道:"你们还得!"
香菱道:"我原来的,再是我们吃了。如今年实喝着,不得了。"
说:"我自己笑道'什么?"宝玉。"宝蟾笑笑道:"奶奶家来。"宝玉看了这原来。
宝玉听了。
其里,又说着,便说着你哥哥哥哥哥哥哥哥哥哥妹妹妹妹妹妹妹姊妹妹回身忙笑道:"这里。"凤姐道:"我们。"说道:"他只见那里头的事,果然若有些东西。"凤姐道:"林姑娘回来看着黛钗道:"宝玉道:"好了。你在家里头无法儿笑道:"这里有声,便问道:"我们不好巧你疼你有一般,还好姐儿,也不知道,只得你去了他的,只怕得?哪里们就叫你还不是这些歹,你说是:"拿来,急了,不得,你竟是什么样,叫我没没不说?"晴雯道:"你们那里罢了。"茗烟下呢?"宝玉、宝钗听着,便问什么意思。"宝玉说:"还没作什么样儿,就是这个人笑道:"我不知,道:"你们一阵,便笑来。"湘云往这一个也不
---------------
黛玉见了宝玉便说个小厮呢,便向宝玉笑道:"他会子,我可强说着咱们们是我很是你叫我也没是东西,你得好的的,我在我。当出来好歹气好说得知道,你们什么你我见人听了。"薛姨妈笑道:"没有什么好说话,叫嗳哟,还不许你们着我也没去快上去了来,我等。"此说得你拿我这里打笑道:"这,快倒是奴里倒是我是这个人也好笑道:"你们来,可是有。"宝玉道:"嗳?你这么样意就算你太太太太太太太太太跟了,也说见你们又拿个我这会子把我又是没罢。"司棋才答应,你们和我又不敢叫我们知说,又不知道:"你这么!你也不能得说,有不得吃,便道我说。"湘云:"你老爷太的话,又拿了一把这是什么?我去。"又不是只是怎么!"薛姨妈道:"竟没奶奶奶奶奶一边身子一把什么不得了,你还不是他坐话,这么去罢了一不如今不得不着,无人道:'况且也不知道:"你,好事倒是我到过去!"说,也没人都打听见奶叫你们我当时,只是了。"贾母道:"你们婆子,也不过来,只是我只拣,宝钗等你也再求了这里的的我们的做老太太都想起身上不好,看了。"凤姐二爷说个姑娘的,只要你们也才在心里,自己向道:"你来了来回去。"贾琏便从我只管哥哥哥哥,没有'不过说:"那里来的方娘和我们有好些玩,叫人忙道:更改模型配置,多训练了一会儿。结果看起来通顺多了
python
batch_size = 32
block_size = 256 # context of up to 256 previous characters
n_layer = 24
n_head = 8
n_embd = 64 * n_head
step 0: train loss 8.4835, val loss 8.4883
...
step 2250: train loss 1.2916, val loss 4.3947
iter 2470: loss 1.4080, time 446.68ms, mfu 1.51%
iter 2480: loss 1.3687, time 447.08ms, mfu 1.51%
iter 2490: loss 1.4792, time 447.05ms, mfu 1.51%
root@eais-bjsrvif50zbuisrd5dfe-64847b6ff7-496mt:/mnt/workspace/buildLLM/nan
oGPT-master# python sample.py --out_dir=out-tonestory-char
Overriding: out_dir = out-tonestory-char
number of parameters: 40.03M
Loading meta from data/shakespeare_char/meta.pkl...
这尤氏执意不想尤氏过来叫:"嗳哟,这可倒是你们的命儿?"尤氏笑道:"我不信儿,是宝丫头是宝兄弟。"尤氏笑道:"可不是,你们只管说话了。是小子,可不是不是?"尤氏笑道:"如今因小儿,你说不是'金玉''金''金''了','金'蕙香",凤姐儿笑问道:"谁?不要与你也是见过,告诉你老太太。如今除了你家的,是你老人家,到了这里,没的东西。"尤氏笑道:"什么东西?"尤氏笑道:"我不和你。你又不起,并不是这样,只管说准了。你们商议论到了房里,倒有人。"凤姐儿道:"老太太说了,我常说了,不过是要的。"
因说道:"这个女孩子,主子们问她是什么福气。我听见说你们说,我们实疑惑的。"一壁走,一面坐着,一面又打发一个丫头走来,却是一个婆子们走。尤氏便说:"嫂子,你别抱怨。"王夫人听了,心中又是喜,因问:"老太太不知道。"王夫人笑道:"我们的话倒不怕。你们这小,那里知道。"
正说话之间,只见王夫人的两个就往凤姐儿房里来。凤姐儿便打发彩霞和一个婆子来回报说:"这里一个丫头们,都得了。"周瑞家的道:"你们的规矩,我们只当着众人也不是,别和平儿说话,没法儿的。"周瑞家的因问:"这会子哪里请大老爷?"周瑞家的道:"你们
---------------
这日正是,只听一阵雨村笑。进来,忽见宝玉进来,便提起黛玉,笑道:"你好好个鬼,我往哪里去?"宝玉听说,便叫:"林姐姐姐说的这话,你怎么不烦恼了?"宝玉听了,方知是何意思,心下疑惑。
忽听院门上人说:"林妹妹哪里去了?"宝玉听了,心下实犹豫。急得里想着,原来是:"林妹妹妹忽然有人来是那几个丫头。回来我病了,不敢睡,睡了一夜,懒待接,大家散了。"便出去。要知端的,且听下回分解。
第十一百八回 痴痴女子杜撰芙蓉癖 痴公子悲深 痴痴情
话说宝玉心 潇湘云偶感重心
话说宝钗出嫁惜春薨逝 潇潇湘云病
话说宝玉想来,见宝玉回来,方出来,便作辞,不是没话。宝玉此时心中疑惑,和他说话也不敢答,便出门走到王夫人房中,赶过来,叫人问:"宝兄弟叫我去。"宝玉听了,又命人来:"太太请出来。"回头一面去后,一面来回了贾母。贾母又见了贾母,问她哥的玉好,然后过入园落在园中,不在话下。
正是回去,只见周瑞走进来,一面走来问:"家的嫂子,她哪里想起我来的?"周瑞、周瑞家的道:"你们和小孩儿怎么说得周瑞的?"周瑞家的冷笑道:"今儿家大走了,你们看见了这银子,她们就认得!"周瑞家的到周瑞家的家的丫头处来,见她娘回至房中
---------------
有一个小丫头捧盒子,笑道:"这个是老婆,我不知哪里的,拿着这个钱快拿了来!"小丫头不理,只得拿了钱来,递与他小丫头,说:"我就不得!完了,快请你们去罢。老太太也不知道。"
贾母因问,那巧姐儿不好意思,只得跟着,忽见一个婆子出来回说:"奶奶不大了。"贾母听了便下拔下一个小丫头来,一边说:"太太可打发人送了人来。"又说:"什么东西?我们两家姑娘们又比不同,还得空儿。"回头命人取了出去,说着一个婆子来,进来,辞。
这里凤姐方才要进屋里头,见了进来,见凤姐儿正疑惑不甚差,便说道:"我的话不称,即刻叫我听见。"凤姐儿听了不自禁,说:"你不用忙,就是这样的,我就管不得很。"平儿道:"不好看,我想着了,已经去了,我才看你了。"平儿道:"你来了,我已经过去了,我也要请你回老太安。"凤姐听了,即起身让,又说:"你只别来了。"平儿一儿便命:"去告诉二奶奶,别略站一歇就进去。"平儿答应着出去了,刚要走来,只见丫头走来,说:"大奶奶的屋里这里用,我们问问明白。"贾母因问:"那丫头家的人不好,只管说有些什么事。"平儿听了笑道:"你不信,告诉你老太太。"平儿听了,又说道:"这是凤丫头那里的人,还有什么事呢。"平儿
---------------
吃得,宝玉因问道:"不得了,袭人姐姐的手,那里的胭笋香甜,只管沏些,又炸了。"宝玉笑道:"不好,什么吃,只管醒得去了。"袭人道:"这些东西,我们叫她好送去罢。"袭人笑道:"我们给她这个。"袭人道:"这里不是什么。"宝玉道:"你不用提起来,只是跟着,我就不要了。"袭人笑道:"你去自然也罢。"袭人道:"你不去,我不信。他也不去,不必烦他来了。"袭人道:"你别生气,我也得一点儿。"袭人道:"好姐姐,我才睡下了,睡了倒了。"宝玉道:"你怎么样?"袭人道:"在屋里等着呢。"袭人道:"明儿再来,有话说是老太太赏上去。"袭人道:"袭人姐也不必说那一个。"宝玉道:"昨儿在这里,夜已四更,到老太太安歇晌,老太太安歇歇去,不在这里,还得咱们了。"袭人道:"你只管放心,你睡罢。"袭人道:"这会子睡了,仔细说了。"袭人道:"我不要出去回去,大家来逛逛逛逛去。"宝玉道:"明儿再睡罢。"袭人道:"你不必去。"袭人道:"既是懒的,只是你也该放心了。"袭人道:"我不困,你就该睡了。"袭人道:"我也睡下了,咱们再睡下了。"袭人道:"睡不用睡,又迟一歇。"袭人道:"已是了,又好。"宝玉道:"你也睡下了,天又睡得了。"袭人
---------------
一日,只见王夫人的言语着泪痕,把东西都忘了。众人听了,都唬了,于是忙忙问:"你这话怎么样?"王夫人道:"你知道外头女儿也不是那一个说话儿?"贾母道:"我昨儿又听见有个女儿在那里。"黛玉道:"叫做什么?"宝玉道:"我吆喝酒,你们到南里来。"又伸手搬住。贾母又道:"不用,你们在外头混说了。你们这里又不好气,不用说话儿,早晚上回来了。"史湘云道:"不是。"宝玉笑道:"不是,还有什么话,咱们昨儿一班大摆酒,都摆喝酒。"贾母因问:"这个话?"贾母道:"你们家多坐,你们还大吃饭。"鸳鸯道:"那里头屋子也不吃饭,我们的饭都摆酒。"鸳鸯笑道:"不必。昨儿说了,我说该赏螃蟹去。"鸳鸯答应了。鸳鸯又道:"今儿一来的,你们说话,各人吃了,不吃饭,咱们的喝一杯。"鸳鸯笑道:"那里是前儿在园子里,都唱了。"鸳鸯早飞洗了手,依言贾母道:"你们只管请,我们就来了。"贾母道:"你们这里也不用过去逛,不然;我们又不大笑。"鸳鸯道:"是。"鸳鸯道:"赏了,赏你们吃这些。"鸳鸯道:"上一个螃蟹,我们吃了两。"鸳鸯答应着,带着便走出来。鸳鸯因问道:"太太问不敢吃,我们说,只管带回去。"鸳鸯道:"今儿才回来,说那边没吃饭,不必
---------------
这时,只见一个人往日中一日,都像从哪里去了。宝玉笑道:"我听见说太太的话,还是呢?"袭人忙道:"你听见林姑娘,这样黑心细,我为什么病,我就过去了。"宝玉道:"林姑娘昨儿才老爷叫雪雁告诉雪雁,才刚告诉雪雁呢。"探春道:"你知道你二哥和平儿说,告诉我,我病着了。"探春道:"不许和你老人告诉二奶说,只怕我不敢说。"说着便命人到探春房中来。平儿见她这般,心中想不到自己心,便死了,自己便说道:"幸而善了,人家也不知,过了作消息。"平儿慌了,便回头向平儿道:"姐姐姐这么着,大奶奶再出去请安,又打发人来瞧去。"平儿含泪道:"她当着不是个要事,她也是小事。哪里是她?既这么说,你们又不要她去,不许累她去了,先告诉人还。"平儿听了,诧异道:"自然,你倒这么个胡涂,也就过去了。"探春道:"你说,我们自然也不快,不知是她这里的,不如何肯和她说了?"平儿道:"不是,也是她们找不着。"探春道:"人家学里话,太太说的是太屋里住着呢。"平儿忙答应了,果然一言解。探春只得又去了,要同着平儿至里间,探春又来陪笑。平儿笑道:"你吃了饭,只管告诉你。"平儿道:"平丫头虽在老太太那里,还不知是什么原故?"平儿道:"怎么不回家去2.3 基于BBPE tokenizer的中文GPT
这个操作也简单,自己写一个prepare.py,设定词表的大小,先基于tokenizers的byte-level byte pair encoding(BBPE)直接训练分词器后,保存下词表和配置,在sample推理时再使用。
然后,在基于这个训练好的tokenizer对数据分词。
这边分别尝试了基于**《红楼梦》、四大名著以及几十本热门网络小说**,并在不同的模型配置上(参照最新的MobileLLM的深而窄模型架构设定)进行了单卡或多卡训练
使用torchrun跑pytorch的自带的单机多卡DDP训练,小模型上和Deepspeed没啥区别。
shell
torchrun --standalone --nproc_per_node=8 train.py config/train_gpt2.py训练经验:
- 这边训练时主要追求过拟合,验证集的损失参考意义不大(懒得划分数据集了)
- 使用Adam优化器,其在check-point中占了2倍模型的空间(一阶和二阶的梯度信息)
- 在相对大语料自己训练的分词器生成的结果会比字符级分词流畅一些,估计时词表比字符集普遍大,压缩率更大。不过没有详细对比
- 续写能力:
- 提及单个小说的人物能够拟合续写。
- 在只用四大名著训练时,勉强可以把不同人物混在一起续写,出现林冲和黛玉
- 在网络小说语料上,强行将不同小说的人物混在一起,续写时模型基本理解不了😅
把各种语料
2.4 基于Qwen2 tokenizer的GPT
参照第3个自己训练的BBPE tokenizer,这边直接使用Qwen2 tokenize。
1、训练结果基本输出是乱码的💔
无论是在《红楼梦》还是在接近一亿字的网络小说语料上都是这种结果。估计语料太少了,而Qwen2的词表15万左右,太少训练语料、且语料仅涵盖单一类型,大部分token的embedding没有训练到,导致模型train不好。
2.5 基于openwebtext dataset复现GPT2
这边就是直接参考原项目操作。难点是数据怎么搞。因为openwebtext和tiktoken的gpt2墙内下不了。
这边选择在kaggle上找了个NanoGPT的项目,把它处理好的train.bin(6.76GB)和test.bin下来,直接训练。
Kaggle项目链接:https://www.kaggle.com/code/carrot1500/nanogpt-trained-on-openwebtext
bash
python3 train.py config/train_gpt2.py --wandb_log=False \
--max_iters=1000 \
--log_interval=1 \
--eval_interval=200 \
--eval_iters=20 \
--learning_rate="0.0001" \
--gradient_accumulation_steps=4 \
--batch_size=12 \
--n_layer=8 \
--n_head=8 \
--n_embd=512 \
--compile=False \
--out_dir=out
bash
Overriding config with config/train_gpt2.py:
# config for training GPT-2 (124M) down to very nice loss of ~2.85 on 1 node of 8X A100 40GB
# launch as the following (e.g. in a screen session) and wait ~5 days:
# $ torchrun --standalone --nproc_per_node=8 train.py config/train_gpt2.py
wandb_log = True
wandb_project = 'owt'
wandb_run_name='gpt2-124M'
# these make the total batch size be ~0.5M
# 12 batch size * 1024 block size * 5 gradaccum * 8 GPUs = 491,520
batch_size = 12
block_size = 1024
gradient_accumulation_steps = 5 * 8
# this makes total number of tokens be 300B
max_iters = 600000
lr_decay_iters = 600000
# eval stuff
eval_interval = 1000
eval_iters = 200
log_interval = 10
# weight decay
weight_decay = 1e-1
Overriding: wandb_log = False
Overriding: max_iters = 1000
Overriding: log_interval = 1
Overriding: eval_interval = 200
Overriding: eval_iters = 20
Overriding: learning_rate = 0.0001
Overriding: gradient_accumulation_steps = 4
Overriding: batch_size = 12
Overriding: n_layer = 8
Overriding: n_head = 8
Overriding: n_embd = 512
Overriding: compile = False
Overriding: out_dir = out
tokens per iteration will be: 49,152
Initializing a new model from scratch
defaulting to vocab_size of GPT-2 to 50304 (50257 rounded up for efficiency)
number of parameters: 50.93M
num decayed parameter tensors: 34, with 51,445,760 parameters
num non-decayed parameter tensors: 17, with 8,704 parameters
using fused AdamW: True
step 0: train loss 10.8790, val loss 10.8800
iter 0: loss 10.8837, time 12969.53ms, mfu -100.00%
iter 1: loss 10.8779, time 2646.03ms, mfu -100.00%
iter 2: loss 10.8718, time 2645.71ms, mfu -100.00%
iter 3: loss 10.8618, time 2647.04ms, mfu -100.00%
iter 4: loss 10.8776, time 2643.33ms, mfu -100.00%
iter 5: loss 10.8743, time 2644.41ms, mfu 2.12%
...
iter 996: loss 6.2718, time 2657.69ms, mfu 2.11%
iter 997: loss 6.2626, time 2654.19ms, mfu 2.11%
iter 998: loss 6.3724, time 2657.96ms, mfu 2.11%
iter 999: loss 6.1987, time 2657.67ms, mfu 2.11%
step 1000: train loss 6.3108, val loss 6.2706
saving checkpoint to out
iter 1000: loss 6.3944, time 13053.12ms, mfu 1.94%3、总结
代码基本是现成,但训练好一个小规模实际可用的LLM并不容易。
调研决定模型架构,需要多少数据,再进行数据准备、数据配比、数据去重筛选清洗、数据增强,收集、清洗、标注和生成SFT数据,以及对齐。
ToDo
- 后续,会把修改的代码放到git上。
- NanoGPT只是经典GPT-2的实现,其结构和现在的LLM还是有差异,如;
- 旋转位置编码ROPE,长上下文建模的关键
- GQA分组注意力
- RMSprop,只有中心化,而非标准化的Layernorm操作
- SwiGLU
如果您需要引用本文,请参考:
LeonYi. (Aug. 25, 2024). 《【LLM训练系列】NanoGPT源码详解和中文GPT训练实践》.
@online{title={【LLM训练系列】NanoGPT源码详解和中文GPT训练实践},
author={LeonYi},
year={2024},
month={Aug},
url={https://www.cnblogs.com/justLittleStar/p/18379771},
}
参考资料
【1】配图大部分来自,https://jalammar.github.io/illu