全参数微调
1.显存占用分析:
如果微调一个3B的模型:
-
模型参数本身的显存:
-
模型有30亿个参数:3B = 3 * billion
-
不同精度下的显存占用:
- FP32(每个参数4字节):3B * 4 = 12GB
- FP16(每个参数2字节):3B * 2 = 6GB
-
-
梯度存储:
- 梯度张量与权重同形状,每个参数对应一个梯度 。如果FP16:3B * 2 = 6GB
-
优化器状态:
- 常见优化器,如Adam、AdamW,需要存储主权重,并会为每个参数存储一阶动量m和二阶动量v ,通常以FP32存储:3B*3 * 4(4字节)=36 GB
-
中间激活值:
前向计算激活值显存占用计算公式:
激活占用显存(全部重计算的激活内存) = 模型层数 * batch_size * seq_len * hidden_size *单参数字节数
比如,24层、batch_size=8、seq_len=1024、hidden_dim=2048:
24 * 8 * 1024 * 2048 * 2(FP16) = 16GB
- 其他(临时缓冲、通信、CUDA kernel): 大约5--10% 得额外开销。
优化手段:
- 用低精度优化器:如用8bit Adam,优化器占用显存节省一半。
- 梯度检查点: 减少激活值显存,代价是计算量增加了。
- ZeRO优化(如DeepSpeed):将参数/梯度/优化器状态拆分到多卡中。
- 混合精度训练:减半模型参数和激活值的显存占用。
Prefix-tuning-V2
- 基础知识:
PT方法是一种针对大模型的soft-prompt方法。是受到语言模型 In-context Learning 的启发:即只要有合适的上下文就可以很好的解决自然语言问题。但是对于特定的任务找到离token需要花费很长时间,PT提出使用连续的 virtual token embedding 来替换离散token。
在训练的时候只更新Predix部分的参数,而 LLM 中其他部分参数固定。
P-Tuning:仅仅对大模型的embedding加入新的参数。
P-Tuning-V2:将大模型的embedding层和每一层都加上新的参数。
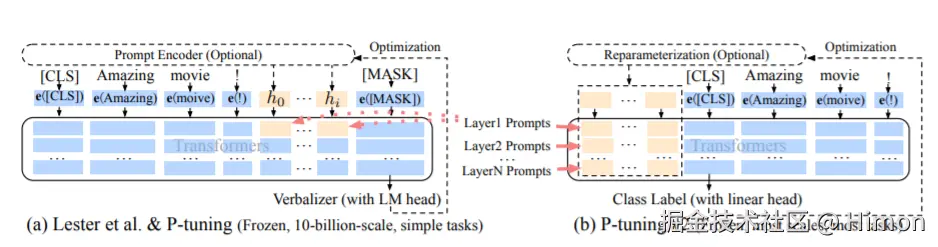
具体来说,PT-V2就是对于transformers的每一层,都在句子表征前面插入可训练的 virtual token embedding 。 对于自回归模型(GPT系列),在句子前添加连续前缀,即
。对于Encoder-Decoder模型(T5),则在Ecoder和Decoder前都添加连续前缀,即
。添加前缀的过程如上图所示。
具体实现:token插入在 attention 模块的Key、Value向量上面。代码层面:
ini
if kv_cache is not None:
cache_k, cache_v = kv_cache
key_layer = torch.cat((cache_k, key_layer), dim=0)
value_layer = torch.cat((cache_v, value_layer), dim=0)
if use_cache:
kv_cache = (key_layer, value_layer)
else:
kv_cache = NoneSelf-Attention的公式是: softmax(dk Q⋅KT)⋅V,将token向量加入到K和V中shape是不变的:
原来的:Q=[m,n],K=[m,n],V=[m,n],计算之后:[m,n]
P-tuning-V2: Q=[m,n], k=[m+k,n], V=[m+k,n],计算之后:[m,n]
LoRA
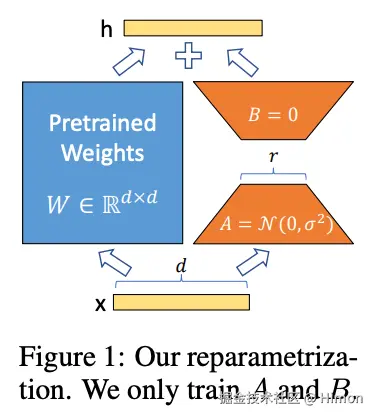
1.技术原理
在大模型上,对每个Transformer块中插入额外的可训练低秩矩阵,并且可以只对指定层(权重矩阵),比如只对query_key_value权重矩阵。并在训练过程中,冻结预训练模型的权重,仅仅需要训练更新低秩矩阵的参数。当"秩值"远小于原始参数维度时,新增的低秩矩阵参数量也就很小。
训练完成后,我们仅仅会得到一个约3MB大小的权重文件,实现用非常低的成本来微调大模型。
详细一点讲:
LoRA的思想也很简单,再原始Pretrained Weights旁边增加一个旁路,做一个降纬再升纬 的操作。训练是固定Pretrained Weights,只训练降纬矩阵A 和升纬矩阵B 。初始化时,用随机高斯分布初始化A,用0矩阵初始化B 。前向计算时,模型的每一层输入和输出纬度保持不变,输出是将Pretrained Weights的输出和BA的输出叠加(相加) 。
具体的,假设Pretrained Weights的权重矩阵为: W0∈Rd∗k,
它的更新过程为: W0+△W=W0+BA,B∈Rd∗r,A∈Rr∗k, 其中秩 r << min(d,k)。
每一层的输出: h=W0x
它的前向计算为: h=W0x+△Wx=W0X+BAx=(W0+BA)x
也就是可以把左右两部分的参数先相加再去乘以x。
这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟full finetuning的过程。
在生产部署时,LoRA可以不引入推理延迟,只需要将Pretrained Weight参数和LoRA参数BA 进行合并即可得到微调后的模型参数,即合并后的模型参数为: W=W0+BA,在推理时,微调前是计算: h=W0x,现在是计算 h=Wx,参数纬度没有改变,因此没有任何额外延迟 。同时,不向通过Prefix-tuning微调后的模型,需要固定输入的序列长度,通过LoRA没有这个限制。
2.超参:
- 秩r:
作用:秩决定了LoRA的参数的数量和表达能力。
选择策略:并不是越大越好,通常4、5即可。
- lora_alpha:
公式: W0+△W=W0+rloraalphaBA
作用:用于控制LoRA模块输出的缩放因子。过大的alpha会使LoRA更新幅度更大,意味着模型会更快的适应特定任务,但是可能导致过拟合。过小的alpha会使更新更温和,有助于模型的稳定性和泛化能力,但是需要更多训练步骤。
选择策略:先选择与r相同的,再看情况调整。
3.执行细节
ini
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
# 需要训练的模型层的名字,主要就是 attention部分的层
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩,就是经过降纬矩阵之后的维度
lora_alpha=32, # Lora alaph,归一化系数
lora_dropout=0.1# Dropout 比例
)- 显存占用分析
FP16+LoRA:显存大概16GB,单卡A100足够。
4.代码实现:
ini
# Dense result, 原始权重的结果,图1蓝色
dense_result = self.matmul(input_tensor, weight)
if self.has_bias:
bias = self.cast(self.bias, self.dtype)
dense_result = self.bias_add(dense_result, bias)
# LoRA result, LoRA权重的结果,图1橘色
input_tensor = self.lora_dropout(input_tensor)
input_tensor = self.lora_a_matmul(input_tensor, lora_a)
input_tensor = self.lora_b_matmul(input_tensor, lora_b)
input_tensor = self.mul(input_tensor, scaling)
# 将两部分叠加
dense_result = self.add(dense_result, input_tensor)参考:
LoRA优化-DyLoRA
DyLoRA通过动态调整低秩适配器的秩,解决了传统LoRA在秩选择和动态调整方面的局限性。
AdapterFusion
此方法是多任务的思路引入到Adapter学习中。为了整合来自多个任务的知识,通常有两种方法,一个是按一定顺序微调,这个问题是需要先验来确定顺序,且模型容易出现"灾难遗忘"现象。二是采用多任务学习(Multi-task learning),但这种方法的问题是不同的任务会相互影响,也难以平衡数据集大小差距很大的任务。
而之前的工作,Adapter Tuning的一个优势就是不用更新预训练模型的参数,而是插入比较少的新的参数就可以很好地学会一个任务。此时,Adapter 的参数某种程度上就表达了解决这个任务需要的知识。
因此,AdapterFusion是想把多任务和Adapter-Tuning结合起来,可以利用多个任务来做大模型的微调。具体的,AdapterFusion分为两个阶段:
- 知识提取阶段:
在不同任务下引入各自的Adapter模块,用于学习特定任务的信息。在这一阶段有两种训练方式:
- Single-Task Adapters(ST-A):对于N个任务,模型都分别独立进行优化,各个任务之间互不干扰,互不影响。
- Multi-Task Adapters(MT-A):N个任务通过多任务学习的方式,进行联合优化。
- 知识组合阶段:
将预训练模型参数与特定任务的Adapter参数固定,引入新的模型参数AdapterFusion来学习组合多个Adapter中的知识。具体实现如下:
AdapterFusion的结构就是一个attention,他的参数包括query,key和value矩阵参数。在transformer的每一层都存在。他的query就是transformer每一层的输出结果 ,key和value是N的任务Adapter的输出 。通过AdapterFusion层,模型可以为不同任务对应的Adapter分配不同的权重,聚合N个任务的信息。
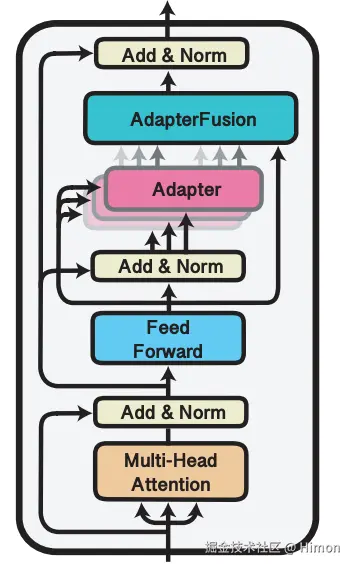
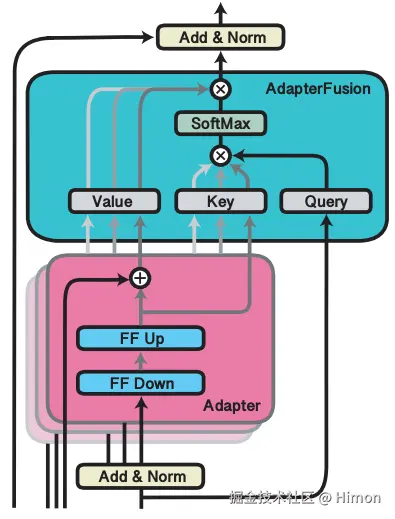
AdapterDrop
大量预训练的 Transformer 模型的微调计算成本高,推理速度慢,并且具有大量存储要求。最近的方法通过训练较小的模型、动态减小模型大小以及训练轻量级适配器来解决这些缺点。在本文中,我们提出了 AdapterDrop,在训练和推理期间从较低的转换器层中移除适配器,它结合了所有三个方向的概念。论文中表明,当同时对多个任务执行推理时,AdapterDrop 可以动态减少计算开销,而任务性能的降低最小。AdapterDrop进一步修剪来自 AdapterFusion 的适配器,这提高了推理效率,同时完全保持了任务性能。
对Adapter Tuning的改造
下图是比较标准的Adapter和Adapter-Drop的微调过程,左边每一层都包含Adapter模块,右边在第一层drop掉了Adapter(红色方块)。箭头表示模型训练时计算前传和梯度Backward的流转方向:
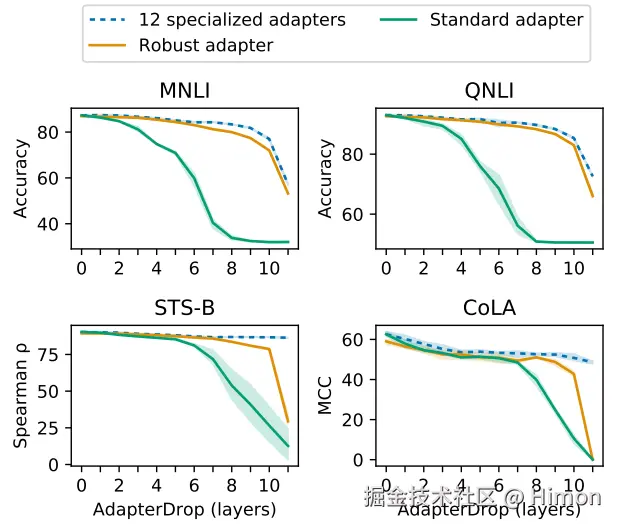
上面实验表明,从较低的 Transformer 层中删除Adapter可以显著提高多任务设置中的推理速度。 例如,将前五个Transformer层中的Adapter丢弃,在对 8 个任务进行推理时,速度提高了 39%。并且即使有多个丢弃层,AdapterDrop 也能保持良好的结果。
对AdapterFusion的改造
下图是标准的AdapterFusion和采用AdapterFusion-Drop的微调过程,AdapterFusion是与多任务的思路结合起来,每个任务采用一个Adapter。图中左边图是标准的AdapterFusion,采用三个adapter(红色、蓝色、黄色格子),右边是AdapterFusion-Drop,在每一层中随机的drop一些adapter。
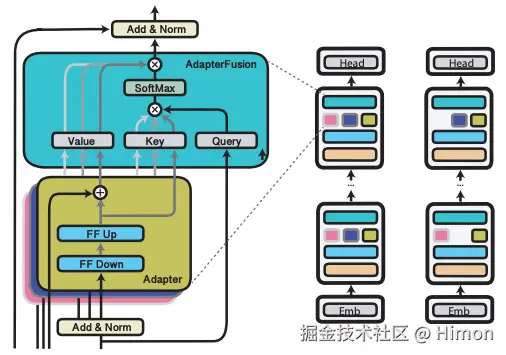
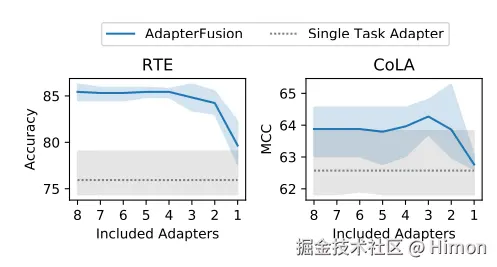
上面实验表明,可以移除 AdapterFusion 中的大多数Adapter而不影响任务性能。使用剩余的两个Adapter,实现了与具有八个Adapter的完整 AdapterFusion 模型相当的结果,并将推理速度提高了 68%。
因此,作者建议在实际部署这些模型之前执行 AdaperFusion-Drop。 这是一种简单而有效的技术,即使在完全保持性能的情况下也能实现效率提升。总之,AdapterDrop 通过从较低的 Transformer 层删除可变数量的Adaper来提升推理速度。 当对多个任务执行推理时,动态地减少了运行时的计算开销,并在很大程度上保持了任务性能。
QLoRA
LoRA+量化