大家好,我是python222_小锋老师,看到一个不错的【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts),分享下哈。
项目视频演示
【免费】【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts+爬虫) Python毕业设计_哔哩哔哩_bilibili
项目介绍
随着社交媒体的快速发展,微博作为一种重要的公共信息平台,承载着大量的社会舆论和民众情感。如何有效地从微博平台获取并分析海量的舆情数据,成为了当前信息社会中的重要课题。本论文基于自然语言处理(NLP)技术,结合Flask、Pandas、ECharts和爬虫技术,设计并实现了一套微博舆情分析可视化系统。
该系统首先利用Python中的爬虫技术从微博平台实时抓取相关舆情数据,包括微博内容、评论、转发等信息。通过对抓取数据的清洗和预处理,使用Pandas进行数据分析,提取关键词、情感倾向和舆情热度等信息。接着,通过NLP技术对微博内容进行情感分析,识别出用户的情感态度(如正面、负面、中立)。最后,系统使用ECharts进行数据的可视化展示,为用户提供直观、动态的舆情分析图表,帮助决策者实时掌握舆情走向。
系统不仅能够有效地获取和分析微博上的实时舆情信息,还提供了良好的交互性和可操作性,用户可以根据需要进行舆情趋势分析、情感分布展示及关键词云等操作。通过对实际案例的分析验证,系统具有较高的准确性和实用性,能够帮助相关部门及时识别网络舆论的动态变化,并做出相应的应对措施。
本论文的研究成果为基于Python的舆情分析系统提供了一种新的实现思路,具有广泛的应用前景,尤其在公共事务管理、品牌舆情监控以及社会热点事件的监测中具有重要的实际意义。
系统展示
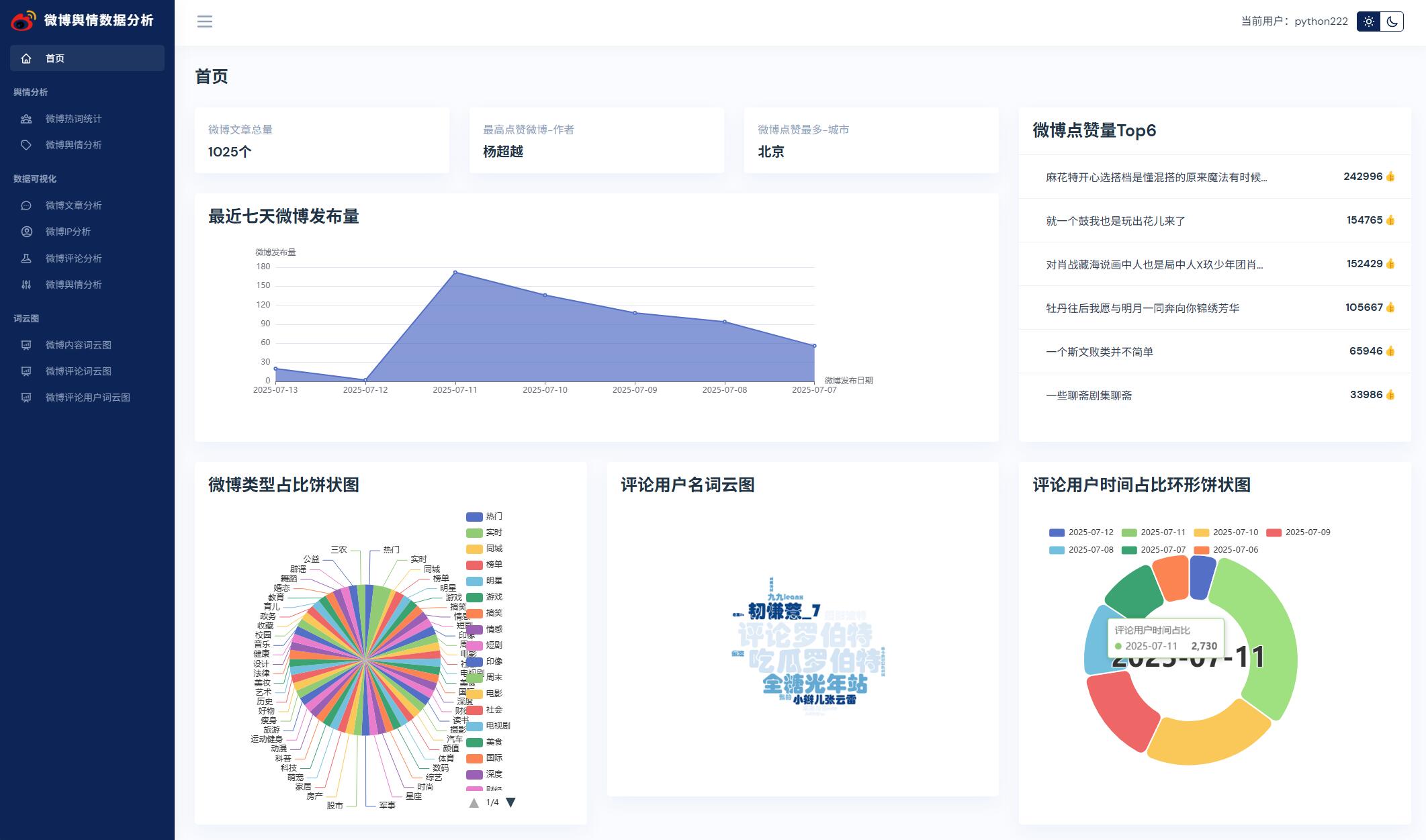
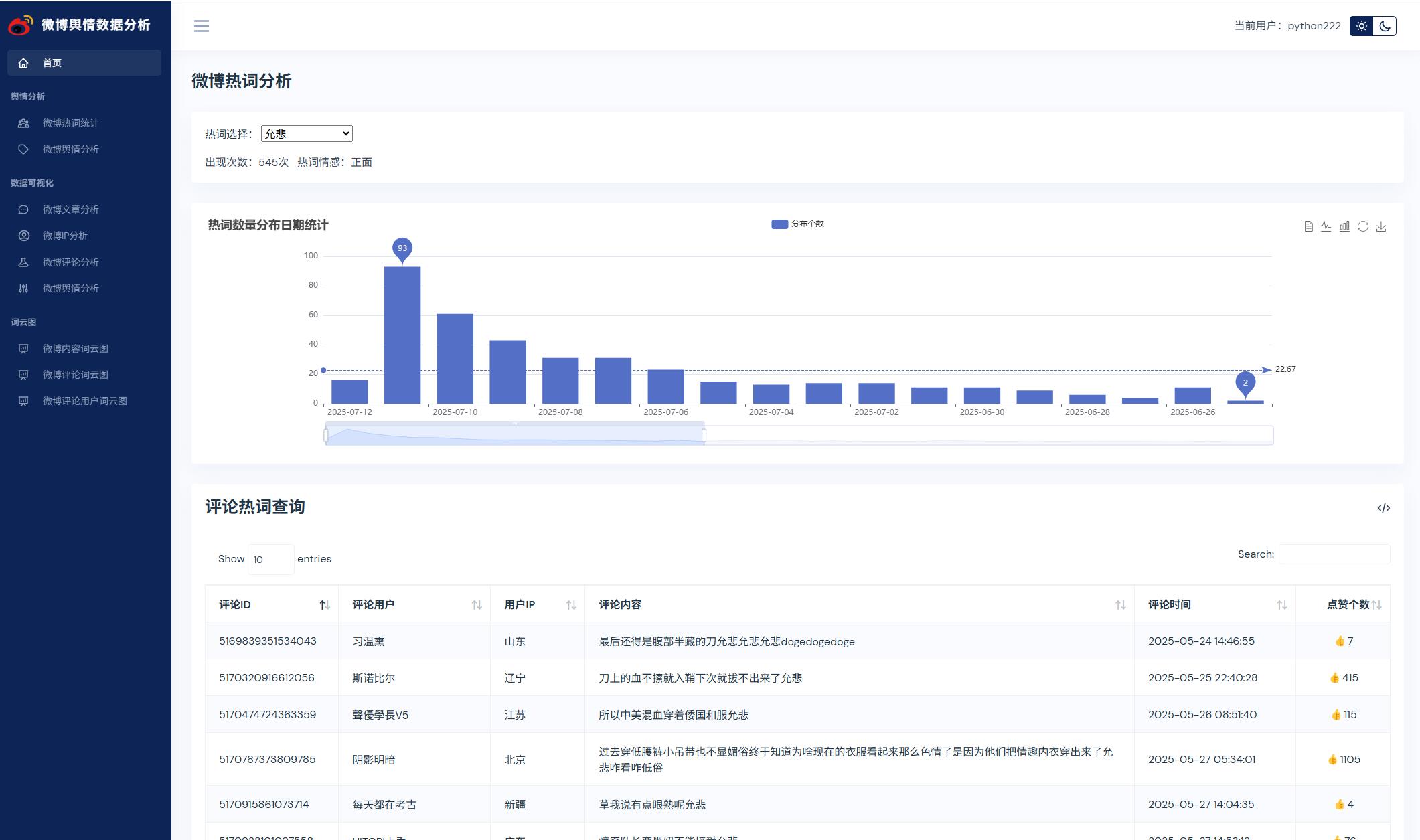
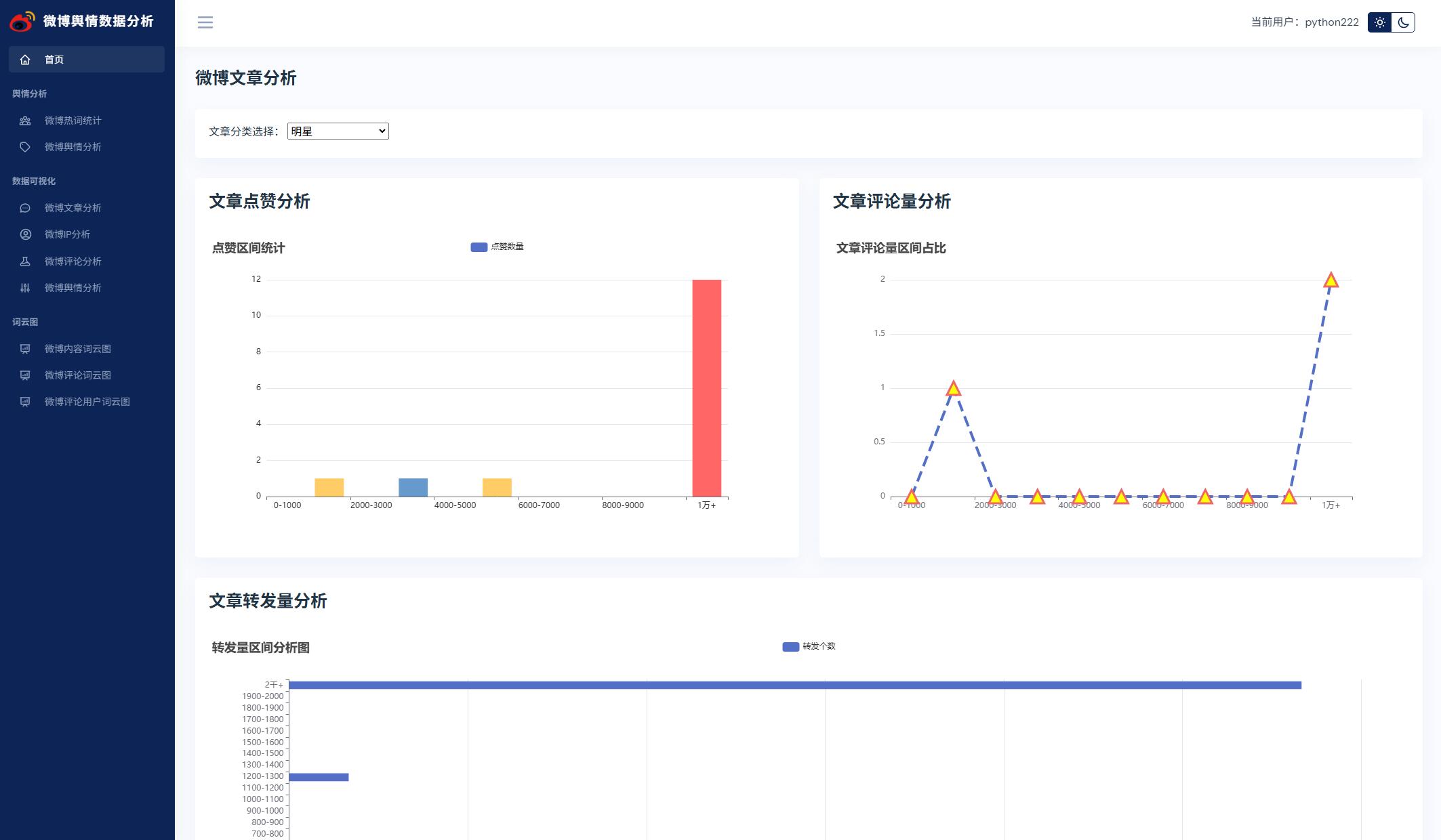
部分代码
python
import pandas as pd
from flask import Blueprint, render_template, jsonify, request
from snownlp import SnowNLP
from dao import articleDao, commentDao
from util import wordcloudUtil, mapUtil
pb = Blueprint('page', __name__, url_prefix='/page', template_folder='templates')
@pb.route('/home')
def home():
"""
进入主页面,获取相应的数据,带到页面去
:return:
"""
articleData = articleDao.get7DayArticle()
xAxis7ArticleData = []
yAxis7ArticleData = []
for article in articleData:
xAxis7ArticleData.append(article[0])
yAxis7ArticleData.append(article[1])
# 获取帖子类别数量
arcTypeData = []
articleTypeAmountList = articleDao.getArticleTypeAmount()
for arcType in articleTypeAmountList:
arcTypeData.append({'value': arcType[1], 'name': arcType[0]})
# 获取top50评论用户名
top50CommentUserList = commentDao.getTopCommentUser()
top50CommentUserNameList = [cu[0] for cu in top50CommentUserList]
str = ' '.join(top50CommentUserNameList)
wordcloudUtil.genWordCloudPic(str, 'comment_mask.jpg', 'comment_user_cloud.jpg')
# 获取7天评论数量
commentData = []
commentAmountList = commentDao.getCommentAmount()
for comment in commentAmountList:
commentData.append({'value': comment[1], 'name': comment[0]})
return render_template('index.html',
xAxis7ArticleData=xAxis7ArticleData,
yAxis7ArticleData=yAxis7ArticleData,
arcTypeData=arcTypeData,
commentData=commentData)
@pb.route('homePageData')
def getHomePageData():
"""
获取主页数据 ajax异步交互 前端每隔5分钟请求一次 实时数据
:return:
"""
totalArticle = articleDao.getTotalArticle()
topAuthor = articleDao.getTopAuthor()
topRegion = articleDao.getTopRegion()
topArticles = articleDao.getArticleTopZan()
return jsonify(totalArticle=totalArticle, topAuthor=topAuthor, topRegion=topRegion, topArticles=topArticles)
@pb.route('hotWord')
def hotWord():
"""
热词分析统计
:return:
"""
hotwordList = []
# 只读取前100条
df = pd.read_csv('./fenci/comment_fre.csv', nrows=100)
for value in df.values:
hotwordList.append(value[0])
# 获取请求参数,如果没有获取到,给个默认值 第一个列表数据
defaultHotWord = request.args.get('word', default=hotwordList[0])
hotwordNum = 0 # 出现次数
for value in df.values:
if defaultHotWord == value[0]:
hotwordNum = value[1]
# 情感分析
sentiments = ''
stc = SnowNLP(defaultHotWord).sentiments
if stc > 0.6:
sentiments = '正面'
elif stc < 0.2:
sentiments = '负面'
else:
sentiments = '中性'
commentHotWordData = commentDao.getCommentHotWordAmount(defaultHotWord)
xAxisHotWordData = []
yAxisHotWordData = []
for comment in commentHotWordData:
xAxisHotWordData.append(comment[0])
yAxisHotWordData.append(comment[1])
commentList = commentDao.getCommentByHotWord(defaultHotWord)
return render_template('hotWord.html',
hotwordList=hotwordList,
defaultHotWord=defaultHotWord,
hotwordNum=hotwordNum,
sentiments=sentiments,
xAxisHotWordData=xAxisHotWordData,
yAxisHotWordData=yAxisHotWordData,
commentList=commentList)
@pb.route('articleData')
def articleData():
"""
微博舆情分析
:return:
"""
articleOldList = articleDao.getAllArticle()
articleNewList = []
for article in articleOldList:
article = list(article)
# 情感分析
sentiments = ''
stc = SnowNLP(article[1]).sentiments
if stc > 0.6:
sentiments = '正面'
elif stc < 0.2:
sentiments = '负面'
else:
sentiments = '中性'
article.append(sentiments)
articleNewList.append(article)
return render_template('articleData.html', articleList=articleNewList)
@pb.route('articleDataAnalysis')
def articleDataAnalysis():
"""
微博数据分析
:return:
"""
arcTypeList = []
df = pd.read_csv('./spider/arcType_data.csv')
for value in df.values:
arcTypeList.append(value[0])
# 获取请求参数,如果没有获取到,给个默认值 第一个列表数据
defaultArcType = request.args.get('arcType', default=arcTypeList[0])
articleList = articleDao.getArticleByArcType(defaultArcType)
xDzData = [] # 点赞x轴数据
xPlData = [] # 评论x轴数据
xZfData = [] # 转发x轴数据
rangeNum = 1000
rangeNum2 = 100
for item in range(0, 10):
xDzData.append(str(rangeNum * item) + '-' + str(rangeNum * (item + 1)))
xPlData.append(str(rangeNum * item) + '-' + str(rangeNum * (item + 1)))
for item in range(0, 20):
xZfData.append(str(rangeNum2 * item) + '-' + str(rangeNum2 * (item + 1)))
xDzData.append('1万+')
xPlData.append('1万+')
xZfData.append('2千+')
yDzData = [0 for x in range(len(xDzData))] # 点赞y轴数据
yPlData = [0 for x in range(len(xPlData))] # 评论y轴数据
yZfData = [0 for x in range(len(xZfData))] # 转发y轴数据
for article in articleList:
for item in range(len(xDzData)):
if int(article[4]) < rangeNum * (item + 1):
yDzData[item] += 1
break
elif int(article[4]) > 10000:
yDzData[len(xDzData) - 1] += 1
break
if int(article[3]) < rangeNum * (item + 1):
yPlData[item] += 1
break
elif int(article[3]) > 10000:
yPlData[len(xDzData) - 1] += 1
break
for article in articleList:
for item in range(len(xZfData)):
if int(article[2]) < rangeNum2 * (item + 1):
yZfData[item] += 1
break
elif int(article[2]) > 2000:
yZfData[len(xZfData) - 1] += 1
break
return render_template('articleDataAnalysis.html',
arcTypeList=arcTypeList,
defaultArcType=defaultArcType,
xDzData=xDzData,
yDzData=yDzData,
xPlData=xPlData,
yPlData=yPlData,
xZfData=xZfData,
yZfData=yZfData)
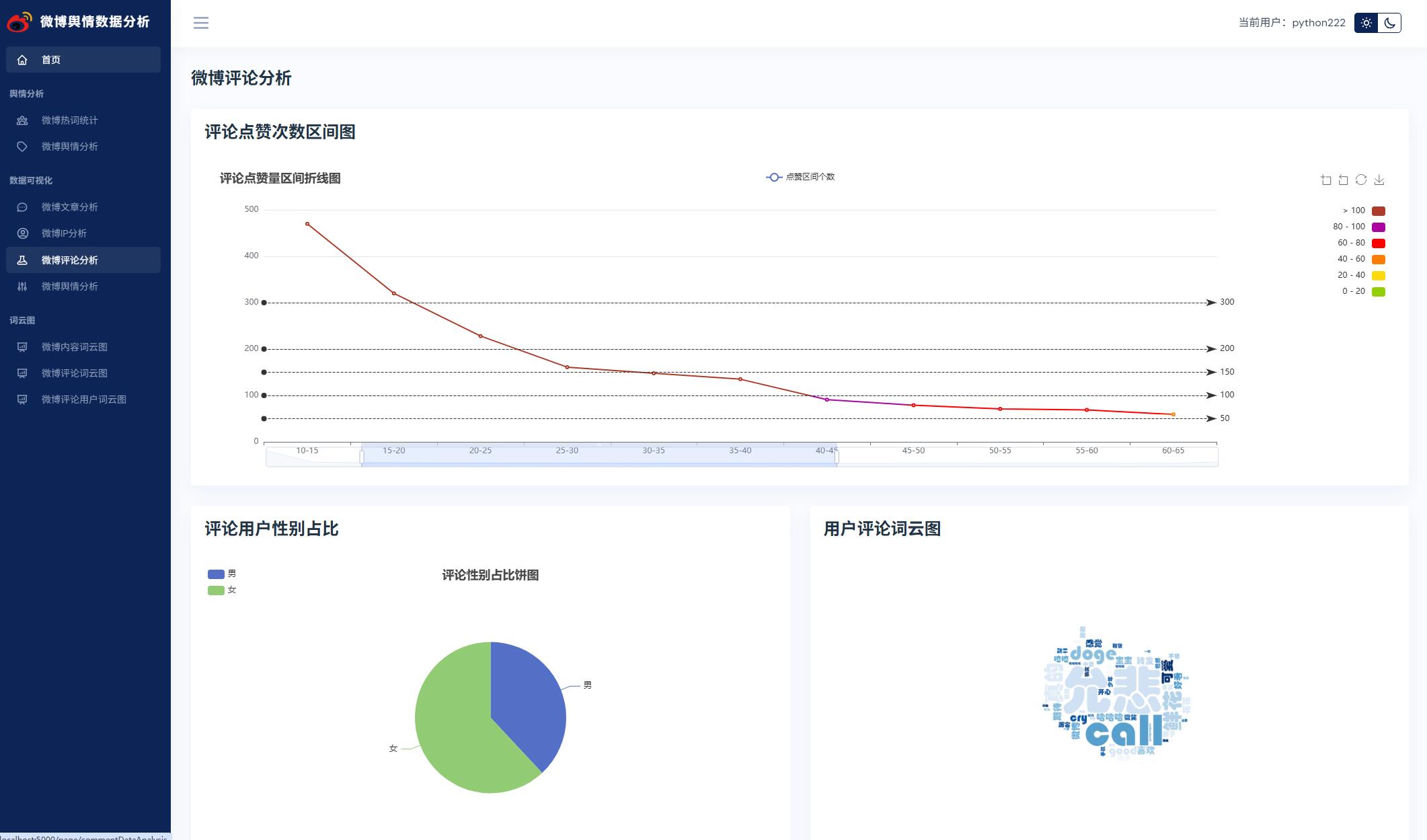
@pb.route('commentDataAnalysis')
def commentDataAnalysis():
"""
微博评论数据分析
:return:
"""
commentList = commentDao.getAllComment()
xDzData = [] # 点赞X轴数据
rangeNum = 5
for item in range(0, 20):
xDzData.append(str(rangeNum * item) + '-' + str(rangeNum * (item + 1)))
xDzData.append('1百+')
yDzData = [0 for x in range(len(xDzData))] # 点赞y轴数据
genderDic = {'男': 0, '女': 0}
for comment in commentList:
for item in range(len(xDzData)):
if int(comment[4]) < rangeNum * (item + 1):
yDzData[item] += 1
break
elif int(comment[4]) > 100:
yDzData[len(xDzData) - 1] += 1
break
if genderDic.get(comment[8], -1) != -1:
genderDic[comment[8]] += 1
genderData = [{'name': x[0], 'value': x[1]} for x in genderDic.items()]
# 只读取前50条数据
df = pd.read_csv('./fenci/comment_fre.csv', nrows=50)
hotCommentwordList = [x[0] for x in df.values]
str2 = ' '.join(hotCommentwordList)
wordcloudUtil.genWordCloudPic(str2, 'comment_mask.jpg', 'comment_cloud.jpg')
return render_template('commentDataAnalysis.html',
xDzData=xDzData,
yDzData=yDzData,
genderData=genderData)
@pb.route('articleCloud')
def articleCloud():
"""
微博内容词云图
:return:
"""
# 只读取前50条数据
df = pd.read_csv('./fenci/article_fre.csv', nrows=50)
hotArticlewordList = [x[0] for x in df.values]
str2 = ' '.join(hotArticlewordList)
wordcloudUtil.genWordCloudPic(str2, 'article_mask.jpg', 'article_cloud.jpg')
return render_template('articleCloud.html')
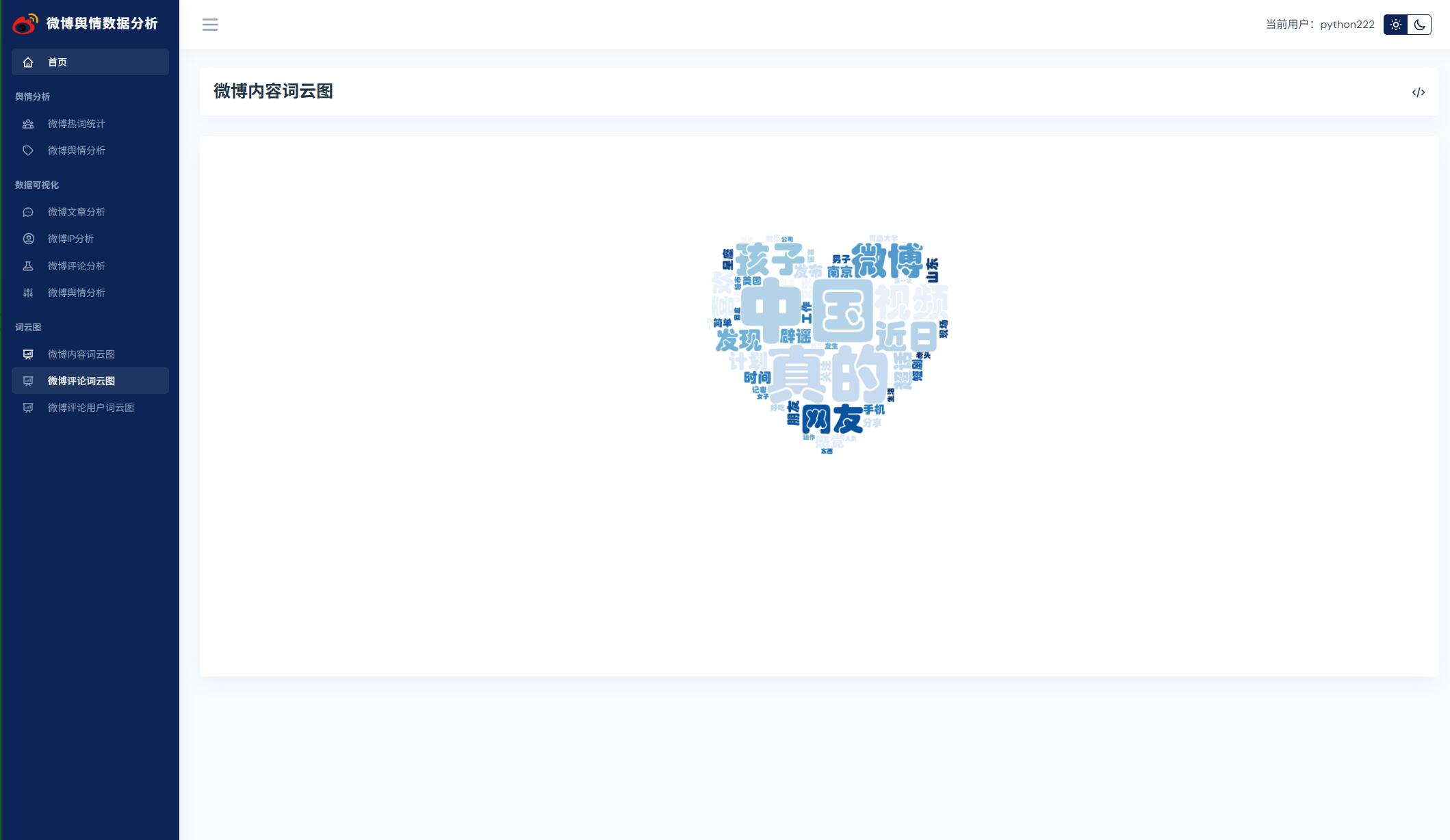
@pb.route('commentCloud')
def commentCloud():
"""
微博评论词云图
:return:
"""
# 只读取前50条数据
df = pd.read_csv('./fenci/comment_fre.csv', nrows=50)
hotCommentwordList = [x[0] for x in df.values]
str2 = ' '.join(hotCommentwordList)
wordcloudUtil.genWordCloudPic(str2, 'comment_mask.jpg', 'comment_cloud.jpg')
return render_template('commentCloud.html')
@pb.route('commentUserCloud')
def commentUserCloud():
"""
微博评论用户词云图
:return:
"""
# 获取top50评论用户名
top50CommentUserList = commentDao.getTopCommentUser()
top50CommentUserNameList = [cu[0] for cu in top50CommentUserList]
str = ' '.join(top50CommentUserNameList)
wordcloudUtil.genWordCloudPic(str, 'comment_mask.jpg', 'comment_user_cloud.jpg')
return render_template('commentUserCloud.html')
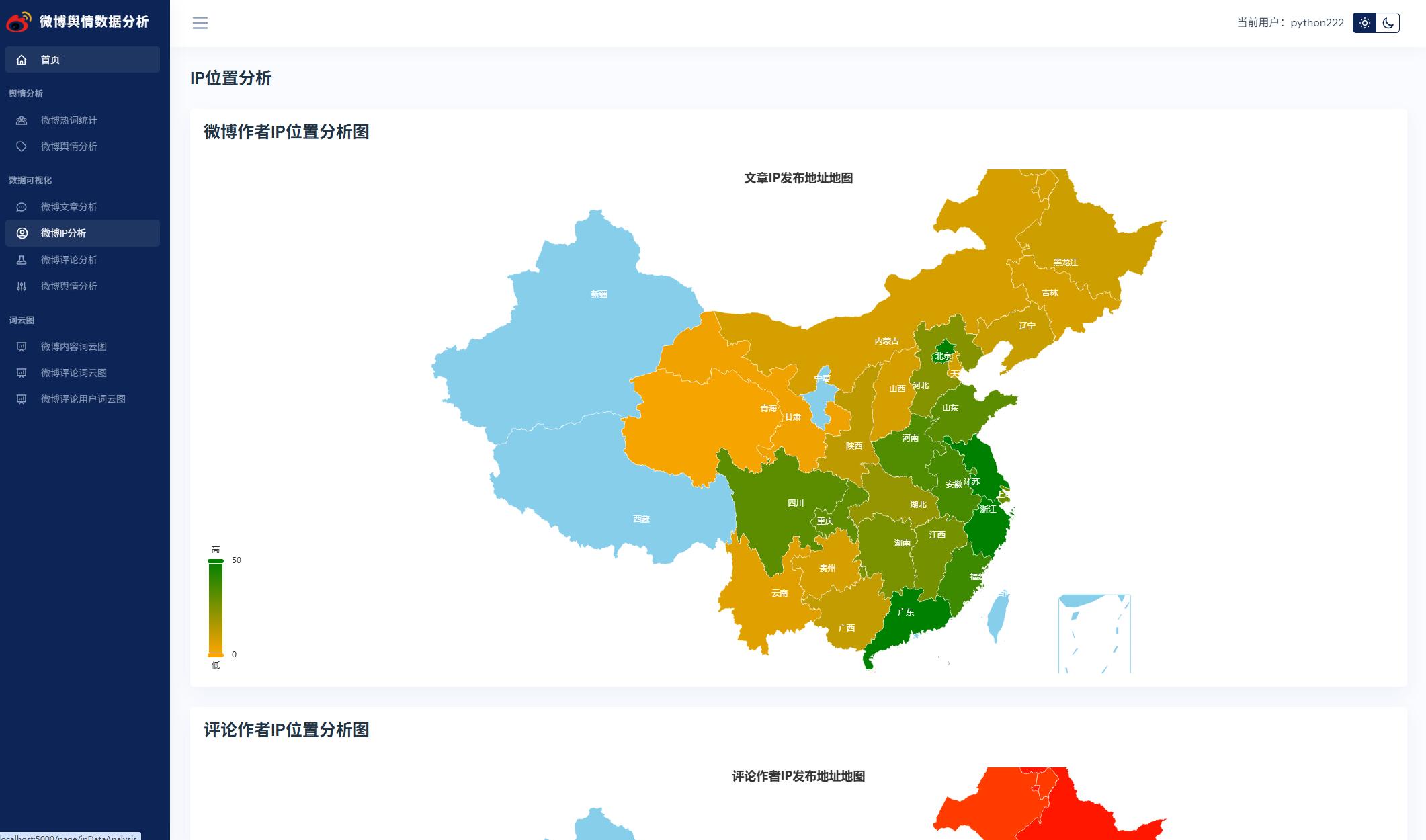
@pb.route('ipDataAnalysis')
def ipDataAnalysis():
"""
IP地址数据分析
:return:
"""
cityDic = {} # 微博文章作者IP
cityList = mapUtil.cityList
articleList = articleDao.getAllArticle()
for article in articleList:
if article[5]:
for city in cityList:
if city['province'].find(article[5]) != -1:
if cityDic.get(city['province'], -1) == -1:
cityDic[city['province']] = 1
else:
cityDic[city['province']] += 1
articleCityDicList = [{'name': x[0], 'value': x[1]} for x in cityDic.items()]
cityDic2 = {} # 微博评论作者IP
commentList = commentDao.getAllComment()
for comment in commentList:
if comment[3]:
for city in cityList:
if city['province'].find(comment[3]) != -1:
if cityDic2.get(city['province'], -1) == -1:
cityDic2[city['province']] = 1
else:
cityDic2[city['province']] += 1
commentCityDicList = [{'name': x[0], 'value': x[1]} for x in cityDic2.items()]
return render_template('ipDataAnalysis.html',
articleCityDicList=articleCityDicList,
commentCityDicList=commentCityDicList)
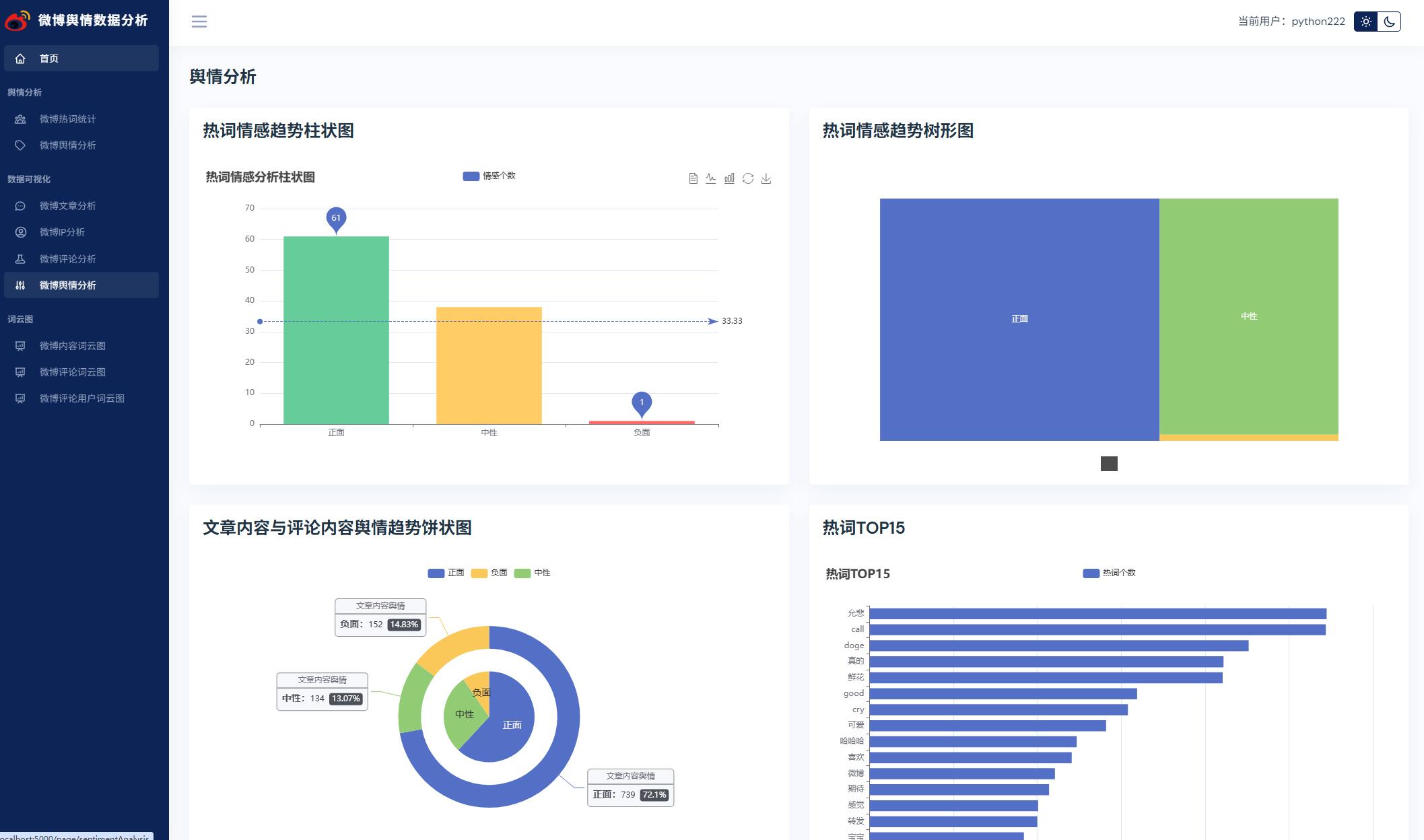
@pb.route('sentimentAnalysis')
def sentimentAnalysis():
"""
舆情数据分析
:return:
"""
xHotBarData = ['正面', '中性', '负面']
yHotBarData = [0, 0, 0]
# 只读取前100条
df = pd.read_csv('./fenci/comment_fre.csv', nrows=100)
for value in df.values:
# 情感分析
stc = SnowNLP(value[0]).sentiments
if stc > 0.6:
yHotBarData[0] += 1
elif stc < 0.2:
yHotBarData[2] += 1
else:
yHotBarData[1] += 1
hotTreeMapData = [{
'name': xHotBarData[0],
'value': yHotBarData[0]
}, {
'name': xHotBarData[1],
'value': yHotBarData[1]
}, {
'name': xHotBarData[2],
'value': yHotBarData[2]
}]
commentPieData = [{
'name': '正面',
'value': 0
}, {
'name': '中性',
'value': 0
}, {
'name': '负面',
'value': 0
}]
articlePieData = [{
'name': '正面',
'value': 0
}, {
'name': '中性',
'value': 0
}, {
'name': '负面',
'value': 0
}]
commentList = commentDao.getAllComment()
for comment in commentList:
# 情感分析
stc = SnowNLP(comment[1]).sentiments
if stc > 0.6:
commentPieData[0]['value'] += 1
elif stc < 0.2:
commentPieData[2]['value'] += 1
else:
commentPieData[1]['value'] += 1
articleList = articleDao.getAllArticle()
for article in articleList:
# 情感分析
stc = SnowNLP(article[1]).sentiments
if stc > 0.6:
articlePieData[0]['value'] += 1
elif stc < 0.2:
articlePieData[2]['value'] += 1
else:
articlePieData[1]['value'] += 1
df2 = pd.read_csv('./fenci/comment_fre.csv', nrows=15)
xhotData15 = [x[0] for x in df2.values][::-1]
yhotData15 = [x[1] for x in df2.values][::-1]
return render_template('sentimentAnalysis.html',
xHotBarData=xHotBarData,
yHotBarData=yHotBarData,
hotTreeMapData=hotTreeMapData,
commentPieData=commentPieData,
articlePieData=articlePieData,
xhotData15=xhotData15,
yhotData15=yhotData15)
python
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<title>用户登录</title>
<link rel="shortcut icon" href="{{ url_for('static', filename='favicon.ico') }}" type="image/x-icon">
<link rel="stylesheet" href="/static/css/backend-plugin.min.css">
<link rel="stylesheet" href="/static/css/backend.css">
</head>
<body class=" ">
<!-- loader Start -->
<div id="loading">
<div id="loading-center">
</div>
</div>
<!-- loader END -->
<div class="wrapper">
<section class="login-content">
<div class="container h-100">
<div class="row align-items-center justify-content-center h-100">
<div class="col-md-5">
<div class="card p-3">
<div class="card-body">
<div class="auth-logo">
<img src="/static/picture/logo.png" class="img-fluid rounded-normal darkmode-logo"
alt="logo">
<img src="/static/picture/logo-dark.png" class="img-fluid rounded-normal light-logo"
alt="logo">
</div>
<h3 class="mb-3 font-weight-bold text-center">用户登录</h3>
<div class="mb-5">
<p class="line-around text-secondary mb-0"><span
class="line-around-1">微博舆情分析管理系统</span>
</p>
</div>
<form>
<div class="row">
<div class="col-lg-12">
<div class="form-group">
<label class="text-secondary">用户名:</label>
<input class="form-control" id="username" name="username" type="text"
placeholder="请输入用户名...">
</div>
</div>
<div class="col-lg-12 mt-2">
<div class="form-group">
<div class="d-flex justify-content-between align-items-center">
<label class="text-secondary">密码:</label>
</div>
<input class="form-control" id="password" name="password" type="password"
placeholder="请输入密码...">
</div>
</div>
</div>
<button type="button" class="btn btn-primary btn-block mt-2" onclick="submitForm()">
登录
</button>
<div class=" col-lg-12 mt-3">
<p class="mb-0 text-center"><font id="info" color="red"></font> 还没有账号?
<a
href="/user/register">用户注册</a></p>
</div>
</form>
</div>
</div>
</div>
</div>
</div>
</section>
</div>
<script>
function submitForm() {
let username = $("#username").val()
let password = $("#password").val()
if (username == "") {
$("#info").text("用户名不能为空!")
return false;
}
if (password == "") {
$("#info").text("密码不能为空!")
return false;
}
$.post('/user/login', {
'username': username,
'password': password
}, function (result) {
if (result.error) {
$("#info").text(result.info)
} else {
window.location.href = '/page/home';
}
})
}
</script>
<!-- Backend Bundle JavaScript -->
<script src="/static/js/backend-bundle.min.js"></script>
<!-- Chart Custom JavaScript -->
<script src="/static/js/customizer.js"></script>
<script src="/static/js/sidebar.js"></script>
<!-- Flextree Javascript-->
<script src="/static/js/flex-tree.min.js"></script>
<script src="/static/js/tree.js"></script>
<!-- Table Treeview JavaScript -->
<script src="/static/js/table-treeview.js"></script>
<!-- SweetAlert JavaScript -->
<script src="/static/js/sweetalert.js"></script>
<!-- Vectoe Map JavaScript -->
<script src="/static/js/vector-map-custom.js"></script>
<!-- Chart Custom JavaScript -->
<script src="/static/js/chart-custom.js"></script>
<script src="/static/js/01.js"></script>
<script src="/static/js/02.js"></script>
<!-- slider JavaScript -->
<script src="/static/js/slider.js"></script>
<!-- Emoji picker -->
<script src="/static/js/index.js" type="module"></script>
<!-- app JavaScript -->
<script src="/static/js/app.js"></script>
</body>
</html>源码下载
链接:https://pan.baidu.com/s/1piPhytu4YuKRBPHva2RQQg
提取码:1234
