

自2018年推出以来,BERT 彻底改变了自然语言处理领域。它在情感分析、问答、语言推理等任务中表现优异。借助双向训练和基于Transformer的自注意力机制 ,BERT 开创了理解文本中单词关系的新范式。然而,尽管成绩斐然,BERT 仍存在局限------在计算效率、长文本处理和可解释性方面面临挑战。这推动了 ModernBERT 的研发,该模型专为解决这些痛点而生:它提升了处理速度、优化了长文本处理能力,还为开发者提供了更高透明度。本文将探索如何用 ModernBERT 开展情感分析,重点展现其特性与对 BERT 的改进。
学习目标
- BERT 简介与 ModernBERT 诞生背景
- 理解 ModernBERT 的核心特性
- 通过情感分析示例实践 ModernBERT 的落地
- ModernBERT 的局限性
- [什么是 BERT?](#什么是 BERT?)
- [什么是 ModernBERT?](#什么是 ModernBERT?)
- [BERT vs ModernBERT](#BERT vs ModernBERT)
- [理解 ModernBERT 的特性](#理解 ModernBERT 的特性)
- [使用 ModernBERT 进行情感分析](#使用 ModernBERT 进行情感分析)
- [ModernBERT 的局限性](#ModernBERT 的局限性)
- 结论
- 常见问题
什么是 BERT?
BERT(Bidirectional Encoder Representations from Transformers 的缩写)自 2018 年由谷歌推出后,彻底改写了自然语言处理的规则。它引入双向训练理念,让模型能通过"全方位观察上下文单词"理解语义。这一创新让 BERT 在问答、情感分析、语言推理等 NLP 任务中表现飞跃。
BERT 的架构基于"仅编码器"的 Transformer:借助自注意力机制衡量句子中单词的影响权重,且只有编码器(只负责理解、编码输入,不生成/重建输出)。正因如此,BERT 能精准捕捉文本的上下文关系,成为近年最具影响力、应用最广的 NLP 模型之一。
什么是 ModernBERT?
尽管 BERT 取得了突破性成功,但其局限性也不容忽视:
- 计算资源:BERT 是计算与内存"双密集"型模型,对实时应用或缺乏强大算力的场景极不友好。
- 上下文长度:BERT 的上下文窗口长度固定,处理长文档等"长输入"时力不从心。
- 可解释性:模型复杂度远高于简单模型,调试与迭代难度大。
- 常识推理:BERT 缺乏常识推理能力,难以理解字面外的上下文、细微差别与逻辑关系。
BERT vs ModernBERT
| BERT | ModernBERT |
|---|---|
| 固定位置嵌入 | 采用旋转位置嵌入(RoPE) |
| 标准自注意力 | Flash Attention 提升效率 |
| 上下文窗口长度固定 | 局部 - 全局交替注意力支持更长文本 |
| 复杂且可解释性弱 | 可解释性增强 |
| 主要基于英文文本训练 | 主要基于英文与代码数据训练 |
ModernBERT 通过整合Flash Attention 、Local - Global Alternating Attention 等高效算法,优化内存占用并提速;还引入旋转位置嵌入(RoPE) 等技术,更高效处理长文本。
它通过"更透明、更易用"的设计增强可解释性,降低开发者调试与适配门槛;同时融入常识推理能力,更擅长理解"显性信息外"的上下文与逻辑。此外,ModernBERT 适配 NVIDIA T4、A100、RTX 4090 等主流 GPU。
训练数据方面,ModernBERT 覆盖网页文档、代码、科学论文等英文源,基于2 万亿个唯一标记训练(远超传统编码器的 20 - 40 次重复训练)。
发布版本包含:
- ModernBERT - base:22 层,1.49 亿参数
- ModernBERT - large:28 层,3.95 亿参数
理解 ModernBERT 的特性
Flash Attention
这是为加速 Transformer 注意力机制而研发的新算法,通过重排计算流程 + 分块(tiling) + 重计算(recomputation) 优化时间与内存:
- 分块:将大数据拆分为可处理的小单元;
- 重计算:按需复用中间结果,减少内存占用。
这让注意力的"二次方级内存消耗"降至"线性级",长序列处理效率飙升;计算开销也显著降低,速度比传统注意力快 2 - 4 倍。Flash Attention 同时加速训练与推理。
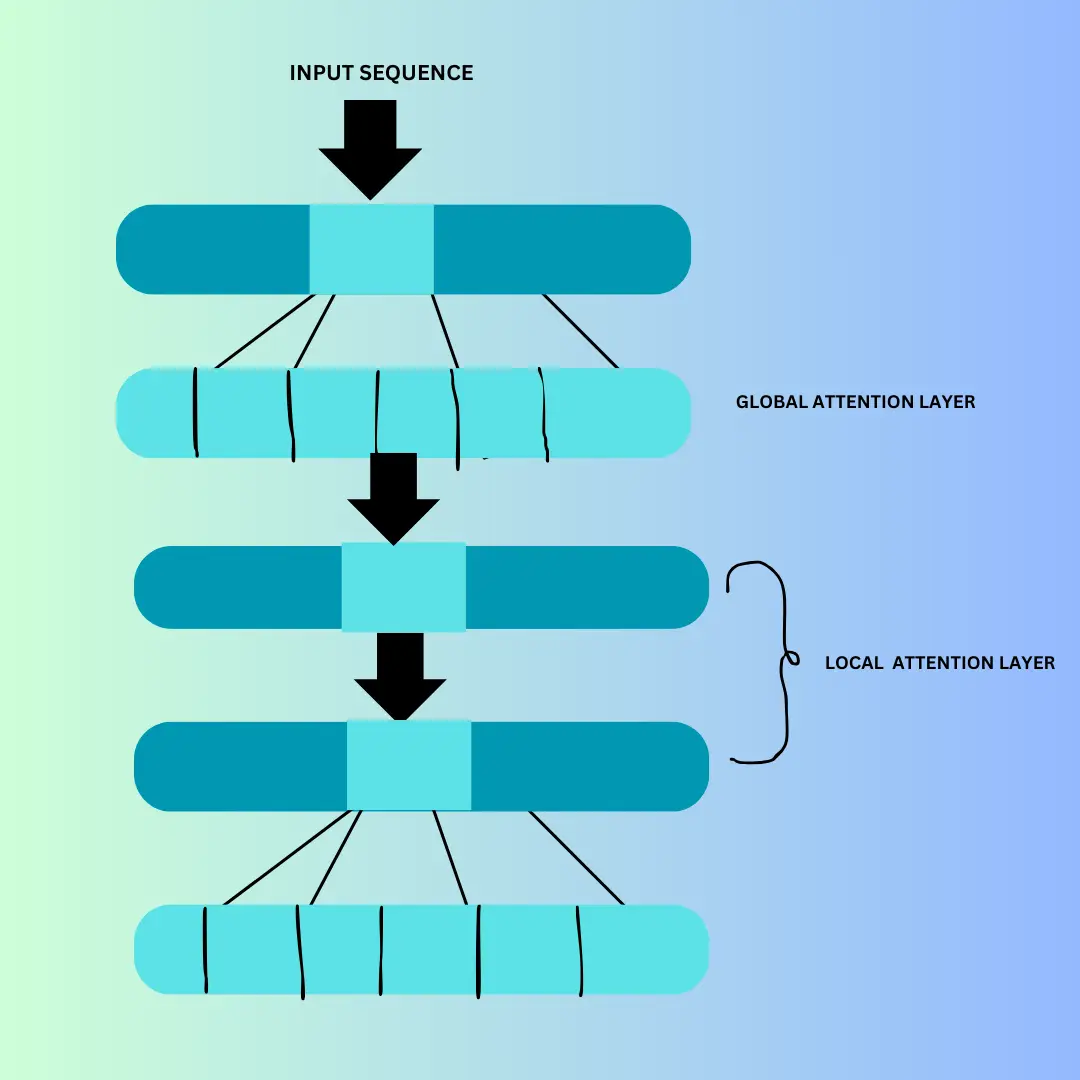
局部 - 全局交替注意力(Local - Global Alternating Attention)
ModernBERT 最具创新性的设计之一是交替注意力(而非全全局注意力):
- 每 3 层后,对"完整输入"执行全局注意力;
- 其余层采用滑动窗口局部注意力:每个标记仅关注"最近 128 个标记"。
旋转位置嵌入(RoPE)
RoPE(Rotary Positional Embeddings)是 Transformer 的位置编码技术:用旋转矩阵编码标记位置,同时整合"绝对 + 相对位置信息",让注意力机制理解标记的"顺序与距离"。
去填充与序列打包(Unpadding and Sequencing)
这两项技术专为优化内存与计算效率设计:
- 去填充:传统"填充"为对齐序列长度会添加无意义标记,增加无效计算;去填充则移除冗余填充标记,减少算力浪费。
- 序列打包:将文本批次重组为紧凑形式,把短序列分组以最大化硬件利用率。
使用 ModernBERT 进行情感分析
我们将实战"用 ModernBERT 做情感分析"------情感分析是文本分类的子任务,目标是将文本(如影评)分为"正面/负面"。
数据集:IMDb 电影评论数据集(分类影评情感)
注意:
- 我在 Google Colab 中使用 A100 GPU 加速训练,更多细节参考: answerdotai/ModernBERT - base(https://huggingface.co/answerdotai/ModernBERT - base)*。
- 训练需 wandb API 密钥,可在 Weight and Biases* 生成。
步骤 1:安装必要库
安装 Hugging Face Transformers 生态工具:
python
# 安装库
!pip install git+https://github.com/huggingface/transformers.git datasets accelerate scikit-learn -Uqq
!pip install -U transformers>=4.48.0
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, AutoModelForMaskedLM, AutoConfig
from datasets import load_dataset
步骤 2:加载 IMDb 数据集
用 load_dataset 加载数据集,imdb["test"][0] 会打印测试集第一条样本(影评 + 标签):
python
# 加载数据集
from datasets import load_dataset
imdb = load_dataset("imdb")
# 打印第一个测试样本
imdb["test"][0]
(打印第一个测试样本)
步骤 3:标记化(Tokenization)
用预训练的 ModernBERT - base 标记器,将文本转成模型可理解的数值输入。tokenized_test_dataset[0] 会打印标记化后测试集首条样本(含输入 ID、标签等):
python
# 初始化标记器和模型
tokenizer = AutoTokenizer.from_pretrained("answerdotai/ModernBERT-base")
model = AutoModelForMaskedLM.from_pretrained("answerdotai/ModernBERT-base")
# 定义标记器函数
def tokenizer_function(example):
return tokenizer(
example["text"],
padding="max_length",
truncation=True,
max_length=512, ## 最大长度可修改
return_tensors="pt"
)
# 标记化训练集与测试集
tokenized_train_dataset = imdb["train"].map(tokenizer_function, batched=True)
tokenized_test_dataset = imdb["test"].map(tokenizer_function, batched=True)
# 打印标记化后测试集第一个样本
print(tokenized_test_dataset[0])
(标记化数据集的第一个样本)
步骤 4:初始化情感分类模型
python
# 初始化模型配置与模型
config = AutoConfig.from_pretrained("answerdotai/ModernBERT-base")
model = AutoModelForSequenceClassification.from_config(config)步骤 5:准备数据集
删除冗余列(如文本)、重命名标签列为 labels:
python
# 数据准备
train_dataset = tokenized_train_dataset.remove_columns(['text']).rename_column('label', 'labels')
test_dataset = tokenized_test_dataset.remove_columns(['text']).rename_column('label', 'labels')步骤 6:定义评估指标(F1 分数)
用 f1_score 衡量模型性能,定义函数处理预测与真实标签:
python
import numpy as np
from sklearn.metrics import f1_score
# 指标计算函数
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
score = f1_score(
labels, predictions, labels=labels, pos_label=1, average="weighted"
)
return {"f1": float(score) if score == 1 else score}步骤 7:设置训练参数(Training Arguments)
用 TrainingArguments 定义超参数(批量大小、学习率、轮数等):
python
# 定义训练参数
train_bsz, val_bsz = 32, 32
lr = 8e-5
betas = (0.9, 0.98)
n_epochs = 2
eps = 1e-6
wd = 8e-6
training_args = TrainingArguments(
output_dir=f"fine_tuned_modern_bert",
learning_rate=lr,
per_device_train_batch_size=train_bsz,
per_device_eval_batch_size=val_bsz,
num_train_epochs=n_epochs,
lr_scheduler_type="linear",
optim="adamw_torch",
adam_beta1=betas[0],
adam_beta2=betas[1],
adam_epsilon=eps,
logging_strategy="epoch",
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
bf16=True,
bf16_full_eval=True,
push_to_hub=False,
)步骤 8:模型训练
用 Trainer 类封装模型、参数、数据集与评估函数,执行训练:
python
# 创建 Trainer 实例
trainer = Trainer(
model=model, # 预训练模型
args=training_args, # 训练参数
train_dataset=train_dataset, # 标记化训练集
eval_dataset=test_dataset, # 标记化测试集
compute_metrics=compute_metrics, # (重要!否则无 F1 分数输出)
)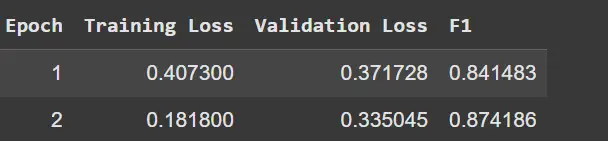
(损失结果与 F1 分数)
步骤 9:模型评估
在测试集上评估训练后模型:
python
# 评估模型
evaluation_results = trainer.evaluate()
print("评估结果:", evaluation_results)

步骤 10:保存微调模型
保存模型与标记器,便于后续复用:
python
# 保存模型与标记器
model.save_pretrained("./saved_model")
tokenizer.save_pretrained("./saved_model")步骤 11:预测新文本情感
0 = 负面,1 = 正面。示例中 "这部电影很无聊" 应输出 0,"精彩绝伦" 输出 1:
python
# 示例输入
new_texts = ["这部电影很无聊", "精彩绝伦"]
# 标记化输入
inputs = tokenizer(new_texts, padding=True, truncation=True, return_tensors="pt")
# 设备对齐 + 推理模式
inputs = inputs.to(model.device)
model.eval()
# 推理
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predictions = torch.argmax(logits, dim=1)
print("预测结果:", predictions.tolist())
(新示例的预测结果)
ModernBERT 的局限性
尽管 ModernBERT 对 BERT 有诸多改进,仍存在不足:
- 训练数据偏差:仅基于英文与代码数据训练,对其他语言/非代码文本的适配性差。
- 复杂度:Flash Attention、RoPE 等技术让模型更复杂,落地与微调门槛升高。
- 推理速度:Flash Attention 虽提升了推理效率,但使用 8192 长度的完整窗口时,速度仍有瓶颈。
结论
ModernBERT 以 BERT 为基石,在处理速度、长文本支持、可解释性上实现突破。尽管仍面临"训练数据偏差""复杂度"等挑战,它仍是 NLP 领域的重大飞跃------为情感分析、文本分类等任务打开新可能,让前沿语言理解更高效、更易触达。
关键要点
- ModernBERT 针对性解决 BERT 的"低效""上下文受限"等痛点。
- 依托 Flash Attention、RoPE 实现"更快处理 + 更长文本支持"。
- 是情感分析、文本分类等任务的优质选择。
- 仍存在"英文/代码数据偏向"等局限。
- Hugging Face、wandb 等工具降低了落地门槛。