这一期在我们的系统里集成词云组件,开发的功能是景区精选评论的词云展示功能。
这个界面的逻辑是这样的:
在数据框里输入城市,可以是模糊搜索的,选择城市;
选择城市后,发往后台去查询该城市的精选评论,由于一个城市会有很多景点,所以精选评论也有很多,采用TF-IDF算法,计算关键词,返回给前端,使用echarts词云组件进行可视化;
再次输入城市,可以切换城市,同时词云会重新渲染。
1 词云页面开发
首先前端安装词云,(注意这边的echarts必须是v5+,如果是4就要使用echarts-wordcloud 1.0版本)
bash
npm install echarts-wordcloud@2然后在main.js中引入
jsx
Vue.component('v-chart', ECharts);
import "echarts-wordcloud"创建一个WordCloud.vue组件,组件的高度和数据从外部传入
jsx
<template>
<v-chart
style="width:100%; "
:option="chartOption"
:style="{ height: height }"
autoresize
/>
</template>
<script>
export default {
name: 'WordCloud',
props: {
words: {
type: Array,
required: true
},
height: {
type: String,
required: true
},
},
watch: {
words: {
immediate: true,
handler() {
this.initChart();
}
}
},
data() {
return {
chartOption: {},
maskImage: new Image(),
data: [],
};
},
async mounted() {
// this.initChart()
},
methods: {
initChart() {
// this.maskImage.src = require('@/assets/rensen.png')
console.log('init wordcloud...')
console.log(this.words)
setTimeout(() => {
this.chartOption = this.buildChartOption();
// console.log(this.chartOption)
}, 1000)
},
buildChartOption() {
// console.log(this.maskImage)
const option = {
// background: '#FFFFFF',
tooltip: {
formatter: '{b}<br/> 出现频次:{c} '
},
series: [ {
// maskImage: this.maskImage,
type: 'wordCloud',
gridSize: 2,
sizeRange: [20, 80],
// shape: 'heart',
layoutAnimation: true,
textStyle:{
textBorderColor: 'rgba(255,255,255,0.3)',
textBorderWidth: 1,
color: ()=>{
return 'rgb(' + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(',') + ')';
},
emphasis: {
fontSize: 20,
shadowBlur: 10,
shadowColor: 'rgba(255,255,255,.1)'
}
},
data: this.words
} ]
};
return option;
},
}
};
</script>创建Word.vue 词云组件页面,这个组件集成了el-autocomplete组件,可以远程搜索城市,这个在上一篇博文里有说过怎么开发了,这边主要是集成WordCloud.vue组件,通过get_wordcloud 方法来从后端加载精选评论词频分析数据。
jsx
<template>
<div>
<el-row :gutter="20">
<!-- 输入框放在图表上方 -->
<el-autocomplete
v-model="city"
:fetch-suggestions="querySearch"
placeholder="请输入城市名称"
@select="handleSelect"
style="width: 300px; margin-left: 10px;"
clearable
>
</el-autocomplete>
<!-- Top chart -->
<el-col :span="24">
<div class="chart" :style="{ height: parentHeight }">
<word-cloud :height="childHeight" :words="words"/>
</div>
</el-col>
</el-row>
</div>
</template>
<script>
import {getCities, get_wordcloud} from "@/api/tour";
import WordCloud from "@/components/WordCloud.vue";
export default {
name: 'Dashboard',
data(){
return{
city: '',
words: [],
}
},
components: {
WordCloud
},
mounted() {
get_wordcloud(this.city).then(res=>{
this.words = res.data.data
})
},
computed: {
parentHeight() {
return `calc(100vh - 140px)`; // 父组件高度
},
childHeight() {
return `calc(100vh - 140px)`; // 子组件高度
}
},
methods: {
// el-autocomplete组件的cb 为回调函数需要把后端返回的值传给它
querySearch(queryString, cb) {
// 发送请求到Flask后端获取模糊搜索结果
getCities(queryString).then(res=>{
// console.log(res.data.data.map(i=>{return i.value}))
cb(res.data.data)
})
},
// el-autocomplete组件选择
handleSelect(item) {
this.city = item.value; // 选择后将城市名存储在city变量中
console.log('选择了:', this.city);
this.$message('加载'+this.city+'数据成功', 'success', 3000)
get_wordcloud(this.city).then(res=>{
this.words = res.data.data
})
},
},
};
</script>
<style scoped>
.chart {
/*display: flex;*/
align-items: center;
justify-content: center;
margin-top: 10px;
color: white;
font-size: 20px;
border-radius: 10px;
background-color: #f4eeee;
}
</style>添加一个方法:
jsx
// 词云
export function get_wordcloud(keyword){
return request({
url: `/tour/wordcloud`,
method: 'get',
params:{ keyword: keyword }
});
}2 后端接口开发
后端接口根据前端传递过来关键词去查询该城市下的所有精选评论数据,然后使用jieba分词进行中文分析,过滤2个字以下的内容,然后创建TF-IDF向量化器计算每个词的TF-IDF词,排序之后,获取前100的重要词返回给前端。
python
# 词云接口
@main.route('/tour/wordcloud', methods=['GET'])
def get_wordcloud():
keyword = request.args.get('keyword', '')
if keyword=='':
keyword = '东京'
try:
# 查询符合条件的 Tour
comments = db.session.query(Tour.select_comment).filter(Tour.city == keyword).all()
# 提取评论文本
comments_text = [comment[0] for comment in comments if comment[0] is not None]
# 使用 jieba 分词
def jieba_tokenizer(text):
return [word for word in jieba.cut(text) if len(word) >= 2]
# 创建 TF-IDF 向量化器
vectorizer = TfidfVectorizer(tokenizer=jieba_tokenizer, stop_words=None) # 可以根据需要添加停用词
tfidf_matrix = vectorizer.fit_transform(comments_text)
# 获取词汇表
feature_names = vectorizer.get_feature_names_out()
# 计算每个词的 TF-IDF 值
tfidf_sum = tfidf_matrix.sum(axis=0).A1 # 将稀疏矩阵转换为数组
tfidf_dict = dict(zip(feature_names, tfidf_sum))
# 按 TF-IDF 值排序,提取前 100 个重要词
sorted_tfidf = sorted(tfidf_dict.items(), key=lambda x: x[1], reverse=True)[:100]
# TF-IDF 值 取整了
top_100_words = [{"name": word, "value": int(score)} for word, score in sorted_tfidf]
# print(top_100_words)
return make_response(code=0, data=top_100_words)
except Exception as e:
return make_response(code=1, message=str(e))3 效果
3.1 东京景区评论词云

3.2 可以搜索选择其他城市
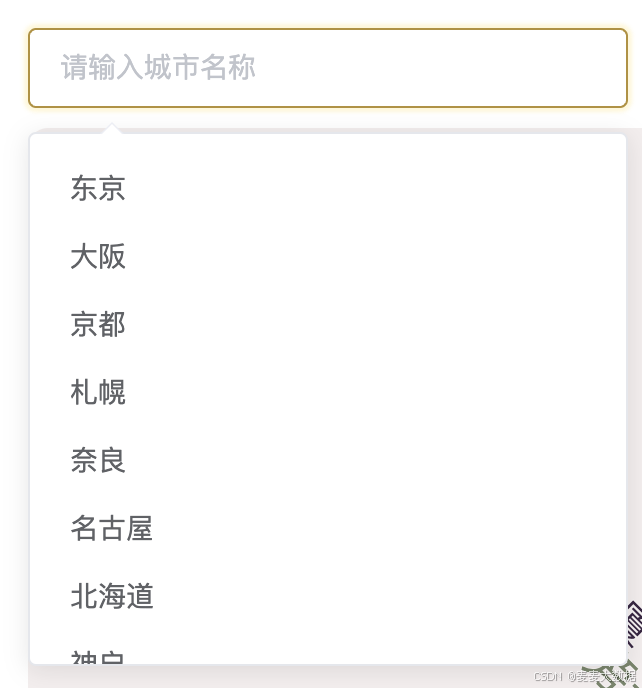
3.3 切换城市,例如名古屋
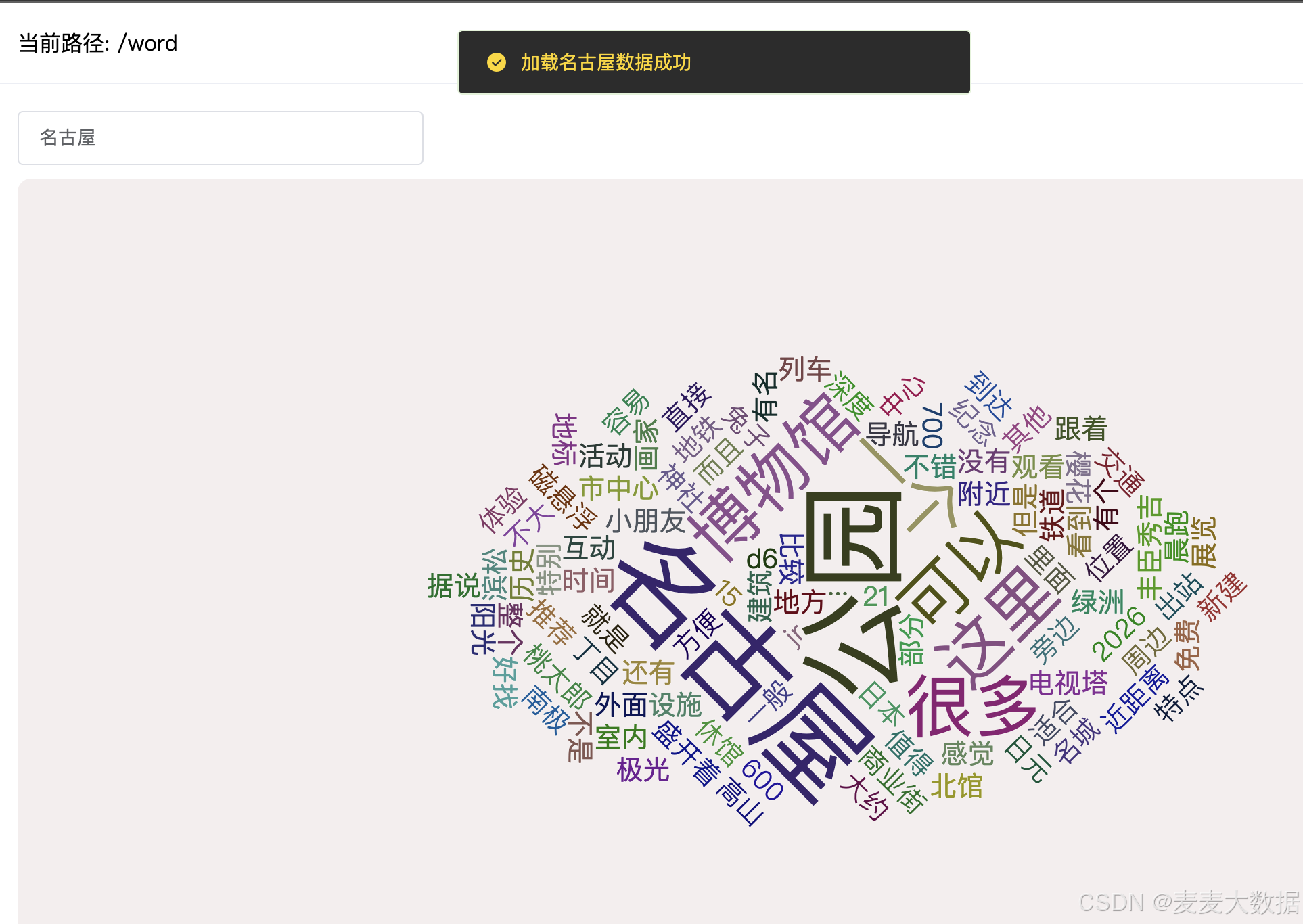
4 补充TF-IDF介绍
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的权重计算方法。 它旨在评估一个词在一篇文档中的重要性,具体而言:
1. **词频(Term Frequency, TF)**:表示一个词在文档中出现的频率。频率越高,表示该词对文档的贡献越大。
2. **逆文档频率(Inverse Document Frequency, IDF)**:表示一个词在所有文档中的稀有程度。IDF 值通过总文档数除以包含该词的文档数,然后取对数来计算。# - 公式为 IDF(w) = log(总文档数 / (包含词 w 的文档数 + 1))# - 一个常见的词(如"的"、"是")在许多文档中出现,IDF 值较低,表示它的区分能力弱。#
3. **TF-IDF 值**:通过将词频和逆文档频率相乘得到。TF-IDF 值高的词在特定文档中重要性较高,且在其他文档中较少出现。## 在文本分析中,TF-IDF 常用于特征提取,以帮助识别关键词和主题。