目录
- 一、安装并配置JDK
- 二、安装并配置Hadoop
- 三、安装过程中遇到的问题总结
一、安装并配置JDK
Linux上一般会安装Open JDK,关于OpenJDK和JDK的区别:http://www.cnblogs.com/sxdcgaq8080/p/7487369.html
准备Open JDK 1.8
查询可安装的java版本
bash
yum -y list java*安装jdk1.8,由于我是M1 ARM系统,因此
bash
yum install -y java-1.8.0-openjdk.aarch64java -version查看已安装的jdk版本
java的安装目录为:/usr/lib/jvm
在/etc/profile下配置环境变量(这里已经配置了完整的环境变量,包括Hadoop)
bash
# set java environment
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-1.el8_4.aarch64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/opt/hadoop-1.2.1
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin二、安装并配置Hadoop
使用wget下载Hadoop压缩包
bash
wget https://archive.apache.org/dist/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz将hadoop压缩包移动至/opt目录下,并且解压
bash
mv hadoop-1.2.1.tar.gz /opt/
cd /opt
tar -zxvf hadoop-1.2.1.tar.gz可以在hadoop目录中配置conf目录下的文件
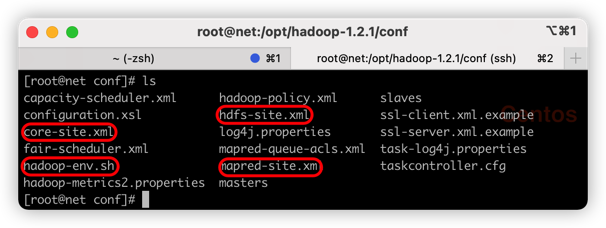
hadoop-env.sh
修改JAVA_HOME环境变量
bash
# The java implementation to use. Required.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-1.el8_4.aarch64core-site.xml
xml
<configuration>
<!-- hadoop工作目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
<!-- 元数据目录-->
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
<!--文件系统访问路径-->
<property>
<name>fs.default.name</name>
<value>hdfs://imooc:900</value>
</property>
</configuration>hdfs-site.xml
xml
<configuration>
<!-- 文件系统数据存放目录-->
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data</value>
</property>
</configuration>mapred-site.xml
xml
<configuration>
<!-- 任务调度器访问路径-->
<property>
<name>mapred.job.tracker</name>
<value>imooc:9001</value>
</property>
</configuration>在/etc/profile下,配置Hadoop环境变量
shell
export HADOOP_HOME=/opt/hadoop-1.2.1并且修改export PATH
shell
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin在hadoop的bin目录下,对Hadoop的namenode进行格式化操作
shell
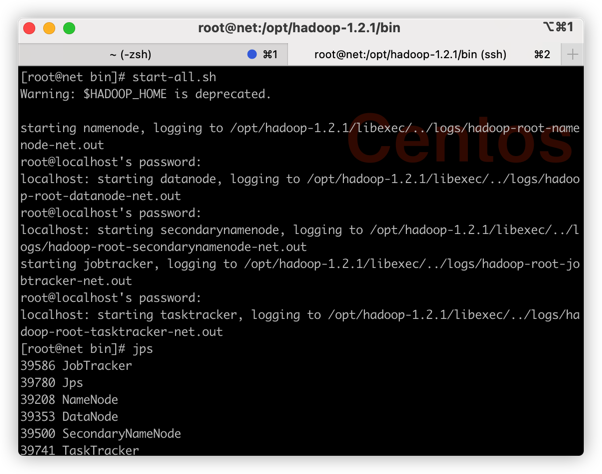
hadoop namenode -format并在bin目录启动hadoop,使用jps命令查看hadoop是否正常运行
使用其命令,查看hadoop下的文件
bash
hadoop fs -ls /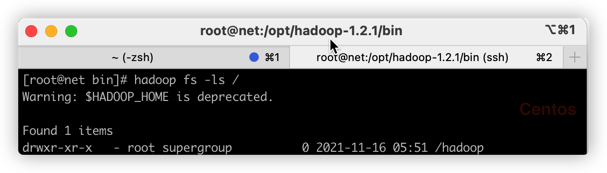
可以看到有一个 Hadoop文件
三、安装过程中遇到的问题总结
1、ssh免密
运行staet-all.sh出现The authenticity of host 'localhost (::1)' can't be established,需要设置ssh免密
bash
ssh -o StrictHostKeyChecking=no 192.168.2.100(本机IP)2、hostname错误
运行staet-all.sh出现Exception in thread "main" java.net.UnknownHostException: unknown host: xxx
注意:hdfs://net:9000中的net是linux的主机名,可以通过echo $HOSTNAME查询主机
3、jps缺少
输入jps命令后,只有jps,那就说明配置有误,按照上文配置进行检查
4、warn信息
在输入一些hadoop命令时,可以看到如下的警告信息,但是不影响运行
Warning: $HADOOP_HOME is deprecated.
需在/etc/profile中添加
shell
export HADOOP_HOME_WARN_SUPPRESS=0