目录
[一、数组 / 字符串](#一、数组 / 字符串)
[1.合并两个有序数组 (简单)](#1.合并两个有序数组 (简单))
[2.移除元素 (简单)](#2.移除元素 (简单))
[3.删除有序数组中的重复项 (简单)](#3.删除有序数组中的重复项 (简单))
[4.删除有序数组中的重复项 II(中等)](#4.删除有序数组中的重复项 II(中等))
[6.轮转数组 (中等)](#6.轮转数组 (中等))
[8.买卖股票的最佳时机 II (中等)](#8.买卖股票的最佳时机 II (中等))
[10.跳跃游戏 II(中等)](#10.跳跃游戏 II(中等))
[11.H 指数(中等)](#11.H 指数(中等))
[12.O(1) 时间插入、删除和获取随机元素(中等)](#12.O(1) 时间插入、删除和获取随机元素(中等))
[16.接雨水 (困难)](#16.接雨水 (困难))
[22.Z 字形变换(中等)](#22.Z 字形变换(中等))
[23.找出字符串中第一个匹配项的下标 (简单)](#23.找出字符串中第一个匹配项的下标 (简单))
[27.两数之和 II - 输入有序数组(中等)](#27.两数之和 II - 输入有序数组(中等))
[37.矩阵置零 (中等)](#37.矩阵置零 (中等))
[46.存在重复元素 II(简单)](#46.存在重复元素 II(简单))
[61.反转链表 II(中等)](#61.反转链表 II(中等))
[62.K 个一组翻转链表 (困难)](#62.K 个一组翻转链表 (困难))
[63.删除链表的倒数第 N 个结点(中等)](#63.删除链表的倒数第 N 个结点(中等))
[64.删除排序链表中的重复元素 II(中等)](#64.删除排序链表中的重复元素 II(中等))
[67.LRU 缓存(中等)](#67.LRU 缓存(中等))
[73. 从中序与后序遍历序列构造二叉树(中等)](#73. 从中序与后序遍历序列构造二叉树(中等))
[74.填充每个节点的下一个右侧节点指针 II(中等)](#74.填充每个节点的下一个右侧节点指针 II(中等))
[78.二叉树中的最大路径和 (困难)](#78.二叉树中的最大路径和 (困难))
[87.二叉搜索树中第 K 小的元素(中等)](#87.二叉搜索树中第 K 小的元素(中等))
[94.课程表 II(中等)](#94.课程表 II(中等))
[98.实现 Trie (前缀树)(中等)](#98.实现 Trie (前缀树)(中等))
[99.添加与搜索单词 - 数据结构设计(中等)](#99.添加与搜索单词 - 数据结构设计(中等))
[100.单词搜索 II(困难)](#100.单词搜索 II(困难))
[102.组合 (中等)](#102.组合 (中等))
[105.N 皇后 II(困难)](#105.N 皇后 II(困难))
[111.合并 K 个升序链表 (困难)](#111.合并 K 个升序链表 (困难))
[十七、Kadane 算法](#十七、Kadane 算法)
[112.最大子数组和 (中等)](#112.最大子数组和 (中等))
[120.寻找两个正序数组的中位数 (困难)](#120.寻找两个正序数组的中位数 (困难))
[123.查找和最小的 K 对数字(中等)](#123.查找和最小的 K 对数字(中等))
[129.只出现一次的数字 II(中等)](#129.只出现一次的数字 II(中等))
[133. 阶乘后的零(中等)](#133. 阶乘后的零(中等))
[134.x 的平方根 (中等)](#134.x 的平方根 (中等))
[135.Pow(x, n)(中等)](#135.Pow(x, n)(中等))
[139.单词拆分 (中等)](#139.单词拆分 (中等))
[141.最长递增子序列 (中等)](#141.最长递增子序列 (中等))
[144.不同路径 II(中等)](#144.不同路径 II(中等))
[148.买卖股票的最佳时机 III(困难)](#148.买卖股票的最佳时机 III(困难))
[149.买卖股票的最佳时机 IV(困难)](#149.买卖股票的最佳时机 IV(困难))
干货分享,感谢您的阅读!

一、数组 / 字符串
1.合并两个有序数组 (简单)
题目描述
给你两个按 非递减顺序 排列的整数数组
nums1和nums2,另有两个整数m和n,分别表示nums1和nums2中的元素数目。请你 合并
nums2到nums1中,使合并后的数组同样按 非递减顺序 排列。注意: 最终,合并后数组不应由函数返回,而是存储在数组
nums1中。为了应对这种情况,nums1的初始长度为m + n,其中前m个元素表示应合并的元素,后n个元素为0,应忽略。nums2的长度为n。示例 1:输入: nums1 = 1,2,3,0,0,0, m = 3, nums2 = 2,5,6, n = 3 输出: 1,2,2,3,5,6 解释: 需要合并 1,2,3 和 2,5,6 。 合并结果是 ***1*** ,***2*** ,2,***3***,5,6 ,其中斜体加粗标注的为 nums1 中的元素。
示例 2:输入: nums1 = 1, m = 1, nums2 = \[\], n = 0 输出: 1 **解释:**需要合并 1 和 \[\] 。 合并结果是 1 。
示例 3:输入: nums1 = 0, m = 0, nums2 = 1, n = 1 输出: 1 **解释:**需要合并的数组是 \[\] 和 1 。 合并结果是 1 。 注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
提示:
nums1.length == m + nnums2.length == n0 <= m, n <= 2001 <= m + n <= 200-<= nums1[i], nums2[j] <=进阶: 你可以设计实现一个时间复杂度为
O(m + n)的算法解决此问题吗?
解题思路
为了合并两个有序数组 nums1 和 nums2,并保持合并后的数组依然有序,可以使用双指针 从后向前的方式合并数组。因为 nums1 数组的末尾已经预留了足够的空间(m + n 大小),可以避免在合并过程中移动大量元素。
-
指针初始化 :初始化三个指针,
p1指向nums1的有效元素的最后一个位置(即m - 1),p2指向nums2的最后一个元素(即n - 1),p指向合并后数组的最后一个位置(即m + n - 1)。 -
从后向前比较 :从数组的末尾开始,比较
nums1[p1]和nums2[p2]的大小,将较大的值放在nums1[p]处,然后移动对应的指针;重复上述步骤,直到其中一个数组的所有元素都已被合并。 -
处理剩余元素 :如果
nums2中还有未合并的元素,需要将它们全部复制到nums1的前部。这是因为nums1中的前部位置可能已经填满了所有来自nums1的元素,剩余位置应由nums2的元素填充。
复杂度分析
该算法的时间复杂度为 O(m + n),因为我们只需遍历两个数组各一次,即可完成合并。空间复杂度为 O(1),因为合并过程是在 nums1 原地进行的,没有使用额外的空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 合并两个有序数组
* @author: zhangyanfeng
* @create: 2024-08-24 19:43
**/
public class Merge {
public void merge(int[] nums1, int m, int[] nums2, int n) {
// 初始化三个指针
int p1 = m - 1; // 指向nums1的有效元素末尾
int p2 = n - 1; // 指向nums2的末尾
int p = m + n - 1; // 指向合并后数组的末尾
// 从后向前遍历合并
while (p1 >= 0 && p2 >= 0) {
// 比较nums1[p1]和nums2[p2],将较大值放在nums1[p]
if (nums1[p1] > nums2[p2]) {
nums1[p] = nums1[p1];
p1--; // 移动指针p1
} else {
nums1[p] = nums2[p2];
p2--; // 移动指针p2
}
p--; // 移动指针p
}
// 如果nums2还有剩余元素,则将其复制到nums1前部
while (p2 >= 0) {
nums1[p] = nums2[p2];
p2--;
p--;
}
}
public static void main(String[] args) {
Merge solution = new Merge();
int[] nums1 = {1, 2, 3, 0, 0, 0};
int m = 3;
int[] nums2 = {2, 5, 6};
int n = 3;
solution.merge(nums1, m, nums2, n);
// 输出合并后的nums1
for (int num : nums1) {
System.out.print(num + " ");
}
// 输出结果应为: 1 2 2 3 5 6
}
}2. 移除元素 (简单)
题目描述
给你一个数组
nums和一个值val,你需要 原地 移除所有数值等于val的元素。元素的顺序可能发生改变。然后返回nums中与val不同的元素的数量。假设
nums中不等于val的元素数量为k,要通过此题,您需要执行以下操作:
- 更改
nums数组,使nums的前k个元素包含不等于val的元素。nums的其余元素和nums的大小并不重要。- 返回
k。用户评测:
评测机将使用以下代码测试您的解决方案:
int[] nums = [...]; // 输入数组 int val = ...; // 要移除的值 int[] expectedNums = [...]; // 长度正确的预期答案。 // 它以不等于 val 的值排序。 int k = removeElement(nums, val); // 调用你的实现 assert k == expectedNums.length; sort(nums, 0, k); // 排序 nums 的前 k 个元素 for (int i = 0; i < actualLength; i++) { assert nums[i] == expectedNums[i]; }如果所有的断言都通过,你的解决方案将会 通过。
示例 1:输入: nums = 3,2,2,3, val = 3 输出: 2, nums = 2,2,_,_ 解释: 你的函数函数应该返回 k = 2, 并且 nums中的前两个元素均为 2。 你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)。
示例 2:输入: nums = 0,1,2,2,3,0,4,2, val = 2 输出: 5, nums = 0,1,4,0,3,_,_,_ **解释:**你的函数应该返回 k = 5,并且 nums 中的前五个元素为 0,0,1,3,4。 注意这五个元素可以任意顺序返回。 你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)。
提示:
0 <= nums.length <= 1000 <= nums[i] <= 500 <= val <= 100
解题思路
直接见数组知识及编程练习总结-CSDN博客中第17题。
3. 删除有序数组中的重复项 (简单)
题目描述
给你一个 非严格递增排列 的数组
nums,请你******原地****** 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回nums中唯一元素的个数。考虑
nums的唯一元素的数量为k,你需要做以下事情确保你的题解可以被通过:
- 更改数组
nums,使nums的前k个元素包含唯一元素,并按照它们最初在nums中出现的顺序排列。nums的其余元素与nums的大小不重要。- 返回
k。判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = [...]; // 输入数组 int[] expectedNums = [...]; // 长度正确的期望答案 int k = removeDuplicates(nums); // 调用 assert k == expectedNums.length; for (int i = 0; i < k; i++) { assert nums[i] == expectedNums[i]; }如果所有断言都通过,那么您的题解将被 通过。
示例 1:输入: nums = 1,1,2 输出: 2, nums = 1,2,_ 解释: 函数应该返回新的长度
2,并且原数组 nums 的前两个元素被修改为1,2。不需要考虑数组中超出新长度后面的元素。示例 2:输入: nums = 0,0,1,1,1,2,2,3,3,4 输出: 5, nums = 0,1,2,3,4 解释: 函数应该返回新的长度
5, 并且原数组 nums 的前五个元素被修改为0,1,2,3,4。不需要考虑数组中超出新长度后面的元素。提示:
1 <= nums.length <= 3 *-<= nums[i] <=nums已按 非严格递增 排列
解题思路
这道题要求在原地删除数组中重复出现的元素,使得每个元素只出现一次,且要求返回删除重复元素后数组的新长度。由于 nums 数组已经是按非严格递增排序的,我们可以通过双指针法来解决这个问题。
- 双指针法 :
- 快指针(
fast):用于遍历整个数组。 - 慢指针(
slow):用于记录不重复元素的位置。
- 快指针(
具体步骤如下:
- 初始化
slow指针指向数组的第一个元素,fast指针从第二个元素开始遍历数组。 - 如果
nums[fast]与nums[slow]不相等,说明遇到了新的元素,我们将slow向前移动一位,并将fast指针指向的值复制到slow位置。 - 不断重复上述过程,直到快指针遍历完整个数组。
最终,慢指针的值加1(即 slow + 1)就是数组中不重复元素的数量,也就是我们需要返回的长度。
复杂度分析
- 时间复杂度:O(n),其中 n 是数组的长度。每个元素最多只被遍历一次。
- 空间复杂度:O(1),我们只用了常数级别的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 删除有序数组中的重复项
* @author: zhangyanfeng
* @create: 2024-08-24 20:27
**/
public class RemoveDuplicates {
public int removeDuplicates(int[] nums) {
// 如果数组为空,直接返回0
if (nums.length == 0) {
return 0;
}
// 初始化慢指针
int slow = 0;
// 快指针从1开始遍历
for (int fast = 1; fast < nums.length; fast++) {
// 如果当前元素和慢指针元素不同
if (nums[fast] != nums[slow]) {
// 慢指针前移
slow++;
// 将快指针的值赋给慢指针当前位置
nums[slow] = nums[fast];
}
}
// 返回不重复元素的数量
return slow + 1;
}
}4. 删除有序数组中的重复项 II(中等)
题目描述
给你一个有序数组
nums,请你******原地****** 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。不要使用额外的数组空间,你必须在 ****原地****修改输入数组并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以**「引用」**方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 int len = removeDuplicates(nums); // 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }示例 1:输入: nums = 1,1,1,2,2,3 输出: 5, nums = 1,1,2,2,3 解释: 函数应返回新长度 length =
5, 并且原数组的前五个元素被修改为1, 1, 2, 2, 3。 不需要考虑数组中超出新长度后面的元素。示例 2:输入: nums = 0,0,1,1,1,1,2,3,3 输出: 7, nums = 0,0,1,1,2,3,3 解释: 函数应返回新长度 length =
7, 并且原数组的前七个元素被修改为0, 0, 1, 1, 2, 3, 3。不需要考虑数组中超出新长度后面的元素。提示:
1 <= nums.length <= 3 *-<= nums[i] <=nums已按升序排列
解题思路
这道题要求我们在有序数组中原地删除重复出现次数超过两次的元素,使每个元素最多保留两次,并返回新的数组长度。
由于数组已经是有序的,我们可以使用双指针法来解决这个问题,类似于之前删除重复元素的题目。但这里的区别在于,我们允许每个元素最多出现两次。
具体步骤如下:
-
初始化指针 :使用
slow指针来标记不重复元素的位置。使用fast指针来遍历数组。 -
遍历数组:
- 从数组的第三个元素开始(索引 2),因为前两个元素无论如何都要保留。
- 对于每一个
nums[fast],我们检查它是否大于nums[slow - 2]。如果是,则说明nums[fast]可以保留在数组中(即它出现的次数不会超过两次)。 - 若满足条件,将
nums[fast]复制到slow位置,然后slow向前移动。
-
返回结果 :最终,
slow指针的值就是新数组的长度。
复杂度分析
- 时间复杂度:O(n),其中 n 是数组的长度。我们只遍历了一次数组。
- 空间复杂度:O(1),我们只用了常数级别的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: RemoveDuplicates
* @author: zhangyanfeng
* @create: 2024-08-24 20:32
**/
public class RemoveDuplicates2 {
public int removeDuplicates(int[] nums) {
// 如果数组长度小于等于2,则不需要处理,直接返回数组长度
if (nums.length <= 2) {
return nums.length;
}
// 初始化慢指针指向第二个元素
int slow = 2;
// 快指针从第三个元素开始遍历
for (int fast = 2; fast < nums.length; fast++) {
// 如果当前元素大于slow-2位置的元素,说明它可以被保留
if (nums[fast] > nums[slow - 2]) {
// 将fast指针的值赋给slow指针,并将slow指针向前移动
nums[slow] = nums[fast];
slow++;
}
}
// 最终slow的位置就是数组的有效长度
return slow;
}
}5. 多数元素(简单)
题目描述
给定一个大小为
n的数组nums,返回其中的多数元素。多数元素是指在数组中出现次数 大于⌊ n/2 ⌋的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:输入: nums = 3,2,3 **输出:**3
示例 2:输入: nums = 2,2,1,1,1,2,2 **输出:**2
提示:
n == nums.length1 <= n <= 5 * 104-109 <= nums[i] <= 109**进阶:**尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
解题思路
可见LeetCode 热题 100 回顾-CSDN博客中第97题。
或数学思维编程练习总结_编程中的数学思维-CSDN博客中第1题。
6.轮转数组 (中等)
题目描述
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
示例 1:输入: nums = 1,2,3,4,5,6,7, k = 3 输出: 5,6,7,1,2,3,4 解释: 向右轮转 1 步: 7,1,2,3,4,5,6 向右轮转 2 步: 6,7,1,2,3,4,5 向右轮转 3 步: 5,6,7,1,2,3,4
示例 2:输入:nums = -1,-100,3,99, k = 2 输出:3,99,-1,-100 解释: 向右轮转 1 步: 99,-1,-100,3 向右轮转 2 步: 3,99,-1,-100
提示:
1 <= nums.length <= \(10^{5}\)
-\(2^{31}\) <= numsi <= \(2^{31}\) - 1
0 <= k <= \(10^{5}\)
进阶:
尽可能想出更多的解决方案,至少有 三种 不同的方法可以解决这个问题。
你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
解题思路
可见LeetCode 热题 100 回顾-CSDN博客中第15题。
7. 买卖股票的最佳时机 (简单)
题目描述
给定一个数组 prices ,它的第 i 个元素 pricesi 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:输入:7,1,5,3,6,4 输出:5 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:输入:prices = 7,6,4,3,1 输出:0 解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
1 <= prices.length <=
0 <= pricesi <=
解题思路
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第77题。
也可见动态规划相关高频笔试汇总_动态规划编程题-CSDN博客中的第18题。
8. 买卖股票的最佳时机 II (中等)
题目描述
给你一个整数数组
prices,其中prices[i]表示某支股票第i天的价格。在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:输入: prices = 7,1,5,3,6,4 输出: 7 **解释:**在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4。 随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3。 最大总利润为 4 + 3 = 7 。
示例 2:输入: prices = 1,2,3,4,5 输出: 4 **解释:**在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4。 最大总利润为 4 。
示例 3:输入: prices = 7,6,4,3,1 输出: 0 **解释:**在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0。
提示:
1 <= prices.length <= 3 *0 <= prices[i] <=
解题思路
要解决这个问题,我们可以利用贪心算法的思想来实现最优解。具体来说,我们只要在价格上升的每一天都买入并卖出股票,这样可以确保获得最大的利润。假设我们在第 i 天买入股票,并在第 i+1 天卖出,如果 prices[i+1] > prices[i],那么我们就赚取了 prices[i+1] - prices[i] 的利润。
复杂度分析
- 时间复杂度:O(n),其中
n是数组prices的长度。我们只需遍历一次数组即可计算出最大利润。 - 空间复杂度:O(1),我们只使用了常数级别的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 买卖股票的最佳时机 II
* @author: zhangyanfeng
* @create: 2024-08-25 08:54
**/
public class MaxProfit {
public int maxProfit(int[] prices) {
// 初始化最大利润为0
int maxProfit = 0;
// 遍历价格数组,从第二天开始计算
for (int i = 1; i < prices.length; i++) {
// 如果今天的价格比昨天的高,计算利润
if (prices[i] > prices[i - 1]) {
// 累加利润
maxProfit += prices[i] - prices[i - 1];
}
}
// 返回计算的最大利润
return maxProfit;
}
// 测试用例
public static void main(String[] args) {
MaxProfit solution = new MaxProfit();
// 示例1
int[] prices1 = {7, 1, 5, 3, 6, 4};
System.out.println("最大利润: " + solution.maxProfit(prices1)); // 输出应为7
// 示例2
int[] prices2 = {1, 2, 3, 4, 5};
System.out.println("最大利润: " + solution.maxProfit(prices2)); // 输出应为4
// 示例3
int[] prices3 = {7, 6, 4, 3, 1};
System.out.println("最大利润: " + solution.maxProfit(prices3)); // 输出应为0
}
}9. 跳跃游戏 (中等)
题目描述
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:输入:nums = 2,3,1,1,4 输出:true 解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
示例 2:输入:nums = 3,2,1,0,4 输出:false 解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
提示:
1 <= nums.length <=
0 <= numsi <= 10
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第78题。
10. 跳跃游戏 II (中等)
题目描述
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums0。
每个元素 numsi 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 numsi 处,你可以跳转到任意 numsi + j 处:
0 <= j <= numsi
i + j < n
返回到达 numsn - 1 的最小跳跃次数。生成的测试用例可以到达 numsn - 1。
示例 1:输入: nums = 2,3,1,1,4 输出: 2 解释: 跳到最后一个位置的最小跳跃数是 2。 从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
示例 2:输入: nums = 2,3,0,1,4 输出: 2
提示:
1 <= nums.length <= 104
0 <= numsi <= 1000
题目保证可以到达 numsn-1
具体可见LeetCode 热题 100 回顾-CSDN博客中的第79题。
11. H 指数 (中等)
题目描述
给你一个整数数组
citations,其中citations[i]表示研究者的第i篇论文被引用的次数。计算并返回该研究者的h指数。根据维基百科上 h 指数的定义:
h代表"高引用次数" ,一名科研人员的h指数 是指他(她)至少发表了h篇论文,并且 至少 有h篇论文被引用次数大于等于h。如果h有多种可能的值,h指数是其中最大的那个。示例 1:输入:
citations = [3,0,6,1,5]输出: 3 解释: 给定数组表示研究者总共有5篇论文,每篇论文相应的被引用了3, 0, 6, 1, 5次。 由于研究者有3篇论文每篇 至少 被引用了3次,其余两篇论文每篇被引用 不多于3次,所以她的 h 指数是3。示例 2:输入: citations = 1,3,1 **输出:**1
提示:
n == citations.length1 <= n <= 50000 <= citations[i] <= 1000
解题思路
要计算研究者的 h 指数,我们可以利用排序和线性扫描来解决。h 指数的定义是某位研究者发表的论文中有至少 h 篇论文被引用了至少 h 次。如果 h 有多种可能值,则选择最大的那个 h。解决思路:
- 排序 :首先将论文的引用次数数组
citations按照引用次数从大到小进行排序。 - 线性扫描 :扫描排序后的数组,并找到最大的
h,使得至少有h篇论文的引用次数大于等于h。
复杂度分析
- 时间复杂度 :排序的时间复杂度为
O(n log n),其中n是数组citations的长度。线性扫描的时间复杂度为O(n),因此整体时间复杂度为O(n log n)。 - 空间复杂度 :我们只需要常数级别的额外空间,因此空间复杂度为
O(1)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
import java.util.Arrays;
/**
* @program: zyfboot-javabasic
* @description: H 指数
* @author: zhangyanfeng
* @create: 2024-08-25 09:13
**/
public class HIndex {
public int hIndex(int[] citations) {
// 对数组进行从大到小的排序
Arrays.sort(citations);
int n = citations.length;
// 线性扫描排序后的数组,寻找最大的 h
for (int i = 0; i < n; i++) {
int h = n - i;
// 如果 citations[i] >= h,说明至少有 h 篇论文被引用了至少 h 次
if (citations[i] >= h) {
return h;
}
}
// 如果未找到合适的 h,返回 0
return 0;
}
// 测试用例
public static void main(String[] args) {
HIndex solution = new HIndex();
// 示例1
int[] citations1 = {3, 0, 6, 1, 5};
System.out.println("h指数: " + solution.hIndex(citations1)); // 输出应为3
// 示例2
int[] citations2 = {1, 3, 1};
System.out.println("h指数: " + solution.hIndex(citations2)); // 输出应为1
}
}12. O(1) 时间插入、删除和获取随机元素 (中等)
题目描述
实现
RandomizedSet类:
RandomizedSet()初始化RandomizedSet对象bool insert(int val)当元素val不存在时,向集合中插入该项,并返回true;否则,返回false。bool remove(int val)当元素val存在时,从集合中移除该项,并返回true;否则,返回false。int getRandom()随机返回现有集合中的一项(测试用例保证调用此方法时集合中至少存在一个元素)。每个元素应该有 相同的概率 被返回。你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为
O(1)。示例:输入 "RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom" \[, 1, 2, 2, \[\], 1, 2, \[\]] 输出 null, true, false, true, 2, true, false, 2 解释 RandomizedSet randomizedSet = new RandomizedSet(); randomizedSet.insert(1); // 向集合中插入 1 。返回 true 表示 1 被成功地插入。 randomizedSet.remove(2); // 返回 false ,表示集合中不存在 2 。 randomizedSet.insert(2); // 向集合中插入 2 。返回 true 。集合现在包含 1,2 。 randomizedSet.getRandom(); // getRandom 应随机返回 1 或 2 。 randomizedSet.remove(1); // 从集合中移除 1 ,返回 true 。集合现在包含 2 。 randomizedSet.insert(2); // 2 已在集合中,所以返回 false 。 randomizedSet.getRandom(); // 由于 2 是集合中唯一的数字,getRandom 总是返回 2 。
提示:
-<= val <=- 1- 最多调用
insert、remove和getRandom函数2 *次
- 在调用
getRandom方法时,数据结构中 至少存在一个 元素。
解题思路
要实现 RandomizedSet 类,我们需要支持插入、删除和随机获取元素的操作,并且所有操作的平均时间复杂度要求为 O(1)。为此,我们可以利用以下两种数据结构:
- 哈希表(HashMap) :用于存储每个元素的值和它在数组中的索引位置。这样可以在
O(1)时间内查找元素是否存在并删除元素。 - 动态数组(ArrayList) :用于保存当前集合中的所有元素。我们可以通过索引随机获取元素,并且在删除操作时,可以通过交换元素来保持
O(1)时间的删除操作。
解决思路:
-
插入操作 :如果元素不存在于集合中,将其添加到数组的末尾,并将该元素及其对应的索引位置存入哈希表中。如果元素已经存在,则直接返回
false。 -
删除操作 :如果元素存在于集合中,将其与数组的最后一个元素交换位置,然后移除最后一个元素。同时更新哈希表中被交换的元素的位置,并移除待删除元素的哈希表记录。如果元素不存在,则直接返回
false。 -
随机获取元素:直接从数组中随机选择一个索引并返回该索引对应的元素。
复杂度分析
- 插入操作 :平均时间复杂度为
O(1),因为哈希表的插入和查找操作都是O(1)。 - 删除操作 :平均时间复杂度为
O(1),因为通过交换最后一个元素可以保持删除的O(1)操作。 - 随机获取元素 :时间复杂度为
O(1),因为从数组中随机选择一个元素是O(1)操作。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
import java.util.*;
/**
* @program: zyfboot-javabasic
* @description: O(1) 时间插入、删除和获取随机元素
* @author: zhangyanfeng
* @create: 2024-08-25 09:18
**/
public class RandomizedSet {
// 动态数组用于存储集合中的元素
private List<Integer> nums;
// 哈希表用于存储每个元素对应在动态数组中的索引
private Map<Integer, Integer> valToIndex;
private Random rand;
// 构造函数,初始化动态数组和哈希表
public RandomizedSet() {
nums = new ArrayList<>();
valToIndex = new HashMap<>();
rand = new Random();
}
// 插入操作
public boolean insert(int val) {
// 如果元素已存在,返回false
if (valToIndex.containsKey(val)) {
return false;
}
// 在数组末尾添加新元素,并在哈希表中记录其索引
nums.add(val);
valToIndex.put(val, nums.size() - 1);
return true;
}
// 删除操作
public boolean remove(int val) {
// 如果元素不存在,返回false
if (!valToIndex.containsKey(val)) {
return false;
}
// 获取待删除元素的索引
int index = valToIndex.get(val);
// 将待删除元素与数组的最后一个元素交换位置
int lastElement = nums.get(nums.size() - 1);
nums.set(index, lastElement);
valToIndex.put(lastElement, index);
// 删除数组的最后一个元素,并移除哈希表中的记录
nums.remove(nums.size() - 1);
valToIndex.remove(val);
return true;
}
// 随机获取元素操作
public int getRandom() {
// 从数组中随机选择一个元素并返回
return nums.get(rand.nextInt(nums.size()));
}
// 测试用例
public static void main(String[] args) {
RandomizedSet randomizedSet = new RandomizedSet();
System.out.println(randomizedSet.insert(1)); // true
System.out.println(randomizedSet.remove(2)); // false
System.out.println(randomizedSet.insert(2)); // true
System.out.println(randomizedSet.getRandom()); // 1 or 2
System.out.println(randomizedSet.remove(1)); // true
System.out.println(randomizedSet.insert(2)); // false
System.out.println(randomizedSet.getRandom()); // 2
}
}13. 除自身以外数组的乘积 (中等)
题目描述
给你一个整数数组 nums,返回 数组 answer ,其中 answeri 等于 nums 中除 numsi 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法,且在 O(n) 时间复杂度内完成此题。
示例 1:输入: nums = 1,2,3,4 输出: 24,12,8,6
示例 2:输入: nums = -1,1,0,-3,3 输出: 0,0,9,0,0
提示:
2 <= nums.length <=
-30 <= numsi <= 30
保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内
进阶:你可以在 O(1) 的额外空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组 不被视为 额外空间。)
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第16题。
也可见LeetCode 精选 75 回顾-CSDN博客中的第7题。
也可见数组知识及编程练习总结-CSDN博客中的第19题。
14. 加油站 (中等)
题目描述
在一条环路上有
n个加油站,其中第i个加油站有汽油gas[i]升。你有一辆油箱容量无限的的汽车,从第
i个加油站开往第i+1个加油站需要消耗汽油cost[i]升。你从其中的一个加油站出发,开始时油箱为空。给定两个整数数组
gas和cost,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回-1。如果存在解,则 保证 它是 唯一 的。示例 1:输入: gas = 1,2,3,4,5, cost = 3,4,5,1,2 输出: 3 **解释:**从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。 因此,3 可为起始索引。
示例 2:输入: gas = 2,3,4, cost = 3,4,3 输出: -1 **解释:**你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。 我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油 开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油 开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油 你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。 因此,无论怎样,你都不可能绕环路行驶一周。
提示:
gas.length == ncost.length == n1 <= n <=0 <= gas[i], cost[i] <=
解题思路
目标是找到一个出发的加油站,使得从这个加油站出发后,能够顺利绕环路一圈,最终回到这个加油站。如果无法做到,返回 -1。关键点:
- 如果
gas[i] - cost[i]的总和小于0,则无论从哪个加油站出发,汽车都不可能完成一圈,因为汽油总量不够。 - 如果某个加油站作为起点能够顺利完成一圈,那么从这个加油站之前的任何一个加油站出发都不能完成一圈,因为它们的剩余油量在到达这个加油站之前已经不足了。
解题思路:
- 遍历两次 :一次遍历计算总油量和总消耗量。如果总油量小于总消耗量,则返回
-1。 - 选择起点:从第一个加油站开始,逐个加油站计算从该站出发后的剩余油量。如果在某个加油站剩余油量为负,则将起点移动到下一个加油站,并重新计算剩余油量。
复杂度分析
- 时间复杂度:
O(n),只需要遍历数组一次即可完成计算。 - 空间复杂度:
O(1),仅使用了常数级别的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 加油站
* @author: zhangyanfeng
* @create: 2024-08-25 09:44
**/
public class CanCompleteCircuit {
public int canCompleteCircuit(int[] gas, int[] cost) {
int totalGas = 0; // 总油量
int totalCost = 0; // 总消耗
int start = 0; // 起点
int tank = 0; // 当前油箱剩余油量
// 遍历所有加油站
for (int i = 0; i < gas.length; i++) {
totalGas += gas[i];
totalCost += cost[i];
tank += gas[i] - cost[i];
// 如果当前油量不足以到达下一个加油站
if (tank < 0) {
// 将起点设为下一个加油站
start = i + 1;
// 重置油箱
tank = 0;
}
}
// 判断是否可以绕环一圈
return totalGas >= totalCost ? start : -1;
}
public static void main(String[] args) {
CanCompleteCircuit solution = new CanCompleteCircuit();
// 测试用例 1
int[] gas1 = {1, 2, 3, 4, 5};
int[] cost1 = {3, 4, 5, 1, 2};
System.out.println(solution.canCompleteCircuit(gas1, cost1)); // 输出: 3
// 测试用例 2
int[] gas2 = {2, 3, 4};
int[] cost2 = {3, 4, 3};
System.out.println(solution.canCompleteCircuit(gas2, cost2)); // 输出: -1
}
}15. 发糖果 (困难)
题目描述
n个孩子站成一排。给你一个整数数组ratings表示每个孩子的评分。你需要按照以下要求,给这些孩子分发糖果:
- 每个孩子至少分配到
1个糖果。- 相邻两个孩子评分更高的孩子会获得更多的糖果。
请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目 。
示例 1:输入: ratings = 1,0,2 输出: 5 **解释:**你可以分别给第一个、第二个、第三个孩子分发 2、1、2 颗糖果。
示例 2:输入: ratings = 1,2,2 输出: 4 **解释:**你可以分别给第一个、第二个、第三个孩子分发 1、2、1 颗糖果。 第三个孩子只得到 1 颗糖果,这满足题面中的两个条件。
提示:
n == ratings.length1 <= n <= 2 *0 <= ratings[i] <= 2 *
解题思路
理解这道题的关键在于如何满足所有孩子的评分条件,同时尽量减少分配的糖果数量。
双向扫描法:
- 左到右扫描: 首先从左到右遍历数组。我们可以假设如果一个孩子的评分高于前一个孩子,那么这个孩子应该比前一个孩子多获得一颗糖果。这样我们可以确保在从左到右的方向上,所有评分更高的孩子都比左边的孩子获得更多糖果。
- 右到左扫描: 然后从右到左遍历数组。这个步骤与前一步类似,但我们需要确保对于右侧的孩子,如果评分高于左边的孩子,糖果数量也要比左边的多。这个步骤是为了修正左到右扫描时可能未考虑到的情况。
糖果数量的确定 :对于每个孩子,最终分配的糖果数量是两次扫描中各自确定的糖果数量的最大值。即,如果在左到右扫描时确定的糖果数量为 left[i],在右到左扫描时确定的糖果数量为 right[i],那么最终该孩子获得的糖果数量为 max(left[i], right[i])。
最终结果:将所有孩子的糖果数量累加,得到最少需要的糖果数。
复杂度分析
- 时间复杂度 :
O(n),我们对数组进行了两次扫描。 - 空间复杂度 :
O(n),我们使用了两个额外的数组来保存每个孩子从左到右和从右到左扫描时的糖果数量。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
import java.util.Arrays;
/**
* @program: zyfboot-javabasic
* @description: 分发糖果
* @author: zhangyanfeng
* @create: 2024-08-25 09:51
**/
public class Candy {
public int candy(int[] ratings) {
int n = ratings.length;
int[] candies = new int[n];
// 每个孩子至少给一颗糖果
Arrays.fill(candies, 1);
// 从左到右遍历,确保评分更高的孩子获得更多的糖果
for (int i = 1; i < n; i++) {
if (ratings[i] > ratings[i - 1]) {
candies[i] = candies[i - 1] + 1;
}
}
// 从右到左遍历,确保评分更高的孩子获得更多的糖果
for (int i = n - 2; i >= 0; i--) {
if (ratings[i] > ratings[i + 1]) {
candies[i] = Math.max(candies[i], candies[i + 1] + 1);
}
}
// 计算糖果总数
int totalCandies = 0;
for (int candy : candies) {
totalCandies += candy;
}
return totalCandies;
}
}16. 接雨水 (困难)
题目描述
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:
输入:height = 0,1,0,2,1,0,1,3,2,1,2,1
输出:6
解释:上面是由数组 0,1,0,2,1,0,1,3,2,1,2,1 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:输入:height = 4,2,0,3,2,5 输出:9
提示:
n == height.length
1 <= n <= 2 *
0 <= heighti <=

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第7题。
也可见栈知识及编程练习总结-CSDN博客中的第6题。
17. 罗马数字转整数(简单)
题目描述
罗马数字包含以下七种字符:
I,V,X,L,C,D和M。
字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。 通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV 。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。给定一个罗马数字,将其转换成整数。
示例 1:输入: s = "III" 输出: 3
示例 2:输入: s = "IV" 输出: 4
示例 3:输入: s = "IX" 输出: 9
示例 4:输入: s = "LVIII" 输出: 58 解释: L = 50, V= 5, III = 3.
示例 5:输入: s = "MCMXCIV" 输出: 1994 解释: M = 1000, CM = 900, XC = 90, IV = 4.
提示:
1 <= s.length <= 15s仅含字符('I', 'V', 'X', 'L', 'C', 'D', 'M')- 题目数据保证
s是一个有效的罗马数字,且表示整数在范围[1, 3999]内- 题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
- IL 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
- 关于罗马数字的详尽书写规则,可以参考 罗马数字 - 百度百科。
解题思路
可见数学思维编程练习总结_编程中的数学思维-CSDN博客中的第10题。
18. 整数转罗马数字 (中等)
题目描述
七个不同的符号代表罗马数字,其值如下:
符号 值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 罗马数字是通过添加从最高到最低的小数位值的转换而形成的。将小数位值转换为罗马数字有以下规则:
- 如果该值不是以 4 或 9 开头,请选择可以从输入中减去的最大值的符号,将该符号附加到结果,减去其值,然后将其余部分转换为罗马数字。
- 如果该值以 4 或 9 开头,使用 减法形式 ,表示从以下符号中减去一个符号,例如 4 是 5 (
V) 减 1 (I):IV,9 是 10 (X) 减 1 (I):IX。仅使用以下减法形式:4 (IV),9 (IX),40 (XL),90 (XC),400 (CD) 和 900 (CM)。- 只有 10 的次方(
I,X,C,M)最多可以连续附加 3 次以代表 10 的倍数。你不能多次附加 5 (V),50 (L) 或 500 (D)。如果需要将符号附加4次,请使用 减法形式。给定一个整数,将其转换为罗马数字。
示例 1:输入: num = 3749 输出: "MMMDCCXLIX"
解释:
3000 = MMM 由于 1000 (M) + 1000 (M) + 1000 (M) 700 = DCC 由于 500 (D) + 100 (C) + 100 (C) 40 = XL 由于 50 (L) 减 10 (X) 9 = IX 由于 10 (X) 减 1 (I) 注意:49 不是 50 (L) 减 1 (I) 因为转换是基于小数位示例 2:输入: num = 58 输出:"LVIII"
解释:
50 = L 8 = VIII示例 3:输入: num = 1994 输出:"MCMXCIV"
解释:
1000 = M 900 = CM 90 = XC 4 = IV提示:
1 <= num <= 3999
解题思路
要将一个整数转换为罗马数字,我们需要按照罗马数字的规则逐步构建字符串。罗马数字是通过添加或减去特定的符号来表示不同的值,步骤:
-
准备罗马数字符号及其对应的值:建立两个数组,一个存储罗马数字的符号,另一个存储这些符号对应的整数值。数组按从大到小的顺序排列。
-
逐步匹配:
遍历这些值,检查当前数字
num是否大于或等于当前的值。如果是,则减去该值,并将对应的罗马符号添加到结果字符串中。如果num以 4 或 9 为开头,直接匹配减法形式的罗马符号。 -
终止条件 :当
num减为 0 时,所有的罗马符号都已经添加完毕。
复杂度分析
- 时间复杂度 :
O(1)。虽然我们在遍历不同的罗马符号,但是由于罗马数字有固定的符号个数和最大数值,所以整体的操作次数是有限的。因此时间复杂度为常数级别。 - 空间复杂度 :
O(1)。使用了少量的额外空间来存储符号和结果字符串,因此空间复杂度也为常数级别。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 整数转罗马数字
* @author: zhangyanfeng
* @create: 2024-08-25 10:05
**/
public class IntegerToRoman {
public String intToRoman(int num) {
// 罗马数字符号和对应的值
int[] values = {1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1};
String[] symbols = {"M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"};
StringBuilder roman = new StringBuilder();
// 遍历所有符号值
for (int i = 0; i < values.length; i++) {
// 每次找到最大值,减少num
while (num >= values[i]) {
num -= values[i];
roman.append(symbols[i]); // 添加符号到结果
}
}
return roman.toString();
}
public static void main(String[] args) {
IntegerToRoman converter = new IntegerToRoman();
// 测试用例
System.out.println(converter.intToRoman(3749)); // 输出: MMMDCCXLIX
System.out.println(converter.intToRoman(58)); // 输出: LVIII
System.out.println(converter.intToRoman(1994)); // 输出: MCMXCIV
}
}19. 最后一个单词的长度(简单)
题目描述
给你一个字符串
s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:输入: s = "Hello World" 输出: 5 **解释:**最后一个单词是"World",长度为 5。
示例 2:输入: s = " fly me to the moon " 输出: 4**解释:**最后一个单词是"moon",长度为 4。
示例 3:输入: s = "luffy is still joyboy" 输出: 6 **解释:**最后一个单词是长度为 6 的"joyboy"。
提示:
1 <= s.length <=s仅有英文字母和空格' '组成s中至少存在一个单词
解题思路
要计算字符串中最后一个单词的长度,可以从字符串末尾开始扫描,找到最后一个单词并计算其长度。考虑到字符串中可能包含前导或尾随空格,我们需要跳过这些空格来定位最后一个单词。
-
从后向前遍历:
从字符串的末尾开始,跳过所有的尾随空格。一旦找到一个非空格字符,开始计数,直到遇到下一个空格或到达字符串的开头。计数器的值就是最后一个单词的长度。
-
终止条件:遍历到字符串的开始处时,结束循环。
复杂度分析
- 时间复杂度 :
O(n),其中n是字符串的长度。我们只需从字符串末尾向前遍历一次。 - 空间复杂度 :
O(1),只使用了常数级的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 最后一个单词的长度
* @author: zhangyanfeng
* @create: 2024-08-25 10:09
**/
public class LastWordLength {
public int lengthOfLastWord(String s) {
int length = 0;
int index = s.length() - 1;
// 从后向前跳过空格
while (index >= 0 && s.charAt(index) == ' ') {
index--;
}
// 计算最后一个单词的长度
while (index >= 0 && s.charAt(index) != ' ') {
length++;
index--;
}
return length;
}
public static void main(String[] args) {
LastWordLength solution = new LastWordLength();
// 测试用例
System.out.println(solution.lengthOfLastWord("Hello World")); // 输出: 5
System.out.println(solution.lengthOfLastWord(" fly me to the moon ")); // 输出: 4
System.out.println(solution.lengthOfLastWord("luffy is still joyboy")); // 输出: 6
}
}20. 最长公共前缀(简单)
题目描述
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串
""。示例 1:输入: strs = "flower","flow","flight" 输出:"fl"
示例 2:输入: strs = "dog","racecar","car" 输出: "" **解释:**输入不存在公共前缀。
提示:
1 <= strs.length <= 2000 <= strs[i].length <= 200strs[i]仅由小写英文字母组成
解题思路
要查找字符串数组中的最长公共前缀,可以使用常用且直观的解法,即 纵向扫描法:
- 从第一个字符开始,依次检查每个字符串在相同位置的字符是否相同。
- 如果在某个位置的字符不匹配,或者到达了某个字符串的末尾,就停止比较,并返回当前找到的最长公共前缀。
- 如果全部字符都匹配,则继续检查下一列字符。
复杂度分析
- 时间复杂度 :
O(S),其中S是所有字符串中字符数量的总和。在最坏情况下,需要检查每个字符。 - 空间复杂度 :
O(1),只使用了常数级的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 最长公共前缀
* @author: zhangyanfeng
* @create: 2024-08-25 10:15
**/
public class LongestCommonPrefix {
public String longestCommonPrefix(String[] strs) {
if (strs == null || strs.length == 0) {
return "";
}
// 从第一个字符串的第一个字符开始比较
for (int i = 0; i < strs[0].length(); i++) {
char c = strs[0].charAt(i);
for (int j = 1; j < strs.length; j++) {
// 如果在当前位置字符不匹配或已到达其他字符串的末尾
if (i >= strs[j].length() || strs[j].charAt(i) != c) {
return strs[0].substring(0, i);
}
}
}
// 如果第一个字符串本身是最长公共前缀
return strs[0];
}
public static void main(String[] args) {
LongestCommonPrefix solution = new LongestCommonPrefix();
// 测试用例
System.out.println(solution.longestCommonPrefix(new String[]{"flower", "flow", "flight"})); // 输出: "fl"
System.out.println(solution.longestCommonPrefix(new String[]{"dog", "racecar", "car"})); // 输出: ""
}
}21. 反转字符串中的单词 (中等)
题目描述
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:输入:s = "the sky is blue" 输出:"blue is sky the"
示例 2:输入:s = " hello world " 输出:"world hello" 解释:反转后的字符串中不能存在前导空格和尾随空格。
示例 3:输入:s = "a good example" 输出:"example good a" 解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。
提示:
1 <= s.length <=
s 包含英文大小写字母、数字和空格 ' '
s 中 至少存在一个 单词
进阶:如果字符串在你使用的编程语言中是一种可变数据类型,请尝试使用 O(1) 额外空间复杂度的 原地 解法。
解题思路
具体可见LeetCode 精选 75 回顾-CSDN博客中的第6题。
类似反转还有字符串高频编程笔试汇总_字符串专题复习-CSDN博客中的第22题。
22. Z 字形变换 (中等)
题目描述
将一个给定字符串
s根据给定的行数numRows,以从上往下、从左到右进行 Z 字形排列。比如输入字符串为
"PAYPALISHIRING"行数为3时,排列如下:
P A H N A P L S I I G Y I R之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:
"PAHNAPLSIIGYIR"。请你实现这个将字符串进行指定行数变换的函数:
string convert(string s, int numRows);示例 1:输入: s = "PAYPALISHIRING", numRows = 3 输出:"PAHNAPLSIIGYIR"
示例 2:输入: s = "PAYPALISHIRING", numRows = 4 输出: "PINALSIGYAHRPI" 解释: P I N A L S I G Y A H R P I
示例 3:输入: s = "A", numRows = 1 输出:"A"
提示:
1 <= s.length <= 1000s由英文字母(小写和大写)、','和'.'组成1 <= numRows <= 1000
解题思路
具体可见字符串高频编程笔试汇总_字符串专题复习-CSDN博客中的第23题。
23. 找出字符串中第一个匹配项的下标 (简单)
题目描述
给你两个字符串
haystack和needle,请你在haystack字符串中找出needle字符串的第一个匹配项的下标(下标从 0 开始)。如果needle不是haystack的一部分,则返回-1。示例 1:输入: haystack = "sadbutsad", needle = "sad" 输出: 0 解释:"sad" 在下标 0 和 6 处匹配。 第一个匹配项的下标是 0 ,所以返回 0 。
示例 2:输入: haystack = "leetcode", needle = "leeto" 输出: -1 解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
提示:
1 <= haystack.length, needle.length <= 104haystack和needle仅由小写英文字符组成
解题思路
这个问题可以通过字符串匹配算法来解决。最直接的方法是使用暴力匹配法,从 haystack 的每个字符开始,逐一匹配 needle,直到找到匹配项或遍历完 haystack。暴力匹配法:
- 从
haystack的第一个字符开始,检查needle是否与haystack从当前字符开始的子串匹配。 - 如果匹配成功,则返回匹配的起始索引。
- 如果遍历完
haystack仍未找到匹配项,则返回-1。
复杂度分析
- 时间复杂度:O((N-M+1) * M),其中 N 是
haystack的长度,M 是needle的长度。最坏情况下,需要对每个位置都进行 M 次比较。 - 空间复杂度:O(1),只需要常数级的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 找出字符串中第一个匹配项的下标
* @author: zhangyanfeng
* @create: 2024-08-25 10:27
**/
public class StrIndex {
public int strStr(String haystack, String needle) {
// 获取 haystack 和 needle 的长度
int n = haystack.length();
int m = needle.length();
// 遍历 haystack 的每个位置,尝试匹配 needle
for (int i = 0; i <= n - m; i++) {
// 取出 haystack 中的子串
String substring = haystack.substring(i, i + m);
// 检查子串是否与 needle 相等
if (substring.equals(needle)) {
return i; // 如果匹配,返回起始位置
}
}
// 如果没有找到匹配,返回 -1
return -1;
}
}24. 文本左右对齐 (困难)
题目描述
给定一个单词数组
words和一个长度maxWidth,重新排版单词,使其成为每行恰好有maxWidth个字符,且左右两端对齐的文本。你应该使用 "贪心算法 " 来放置给定的单词;也就是说,尽可能多地往每行中放置单词。必要时可用空格
' '填充,使得每行恰好有 maxWidth 个字符。要求尽可能均匀分配单词间的空格数量。如果某一行单词间的空格不能均匀分配,则左侧放置的空格数要多于右侧的空格数。
文本的最后一行应为左对齐,且单词之间不插入额外的空格。
注意:
- 单词是指由非空格字符组成的字符序列。
- 每个单词的长度大于 0,小于等于 maxWidth。
- 输入单词数组
words至少包含一个单词。示例 1:输入: words = "This", "is", "an", "example", "of", "text", "justification.", maxWidth = 16 输出: "This is an", "example of text", "justification. "
示例 2:输入: words = "What","must","be","acknowledgment","shall","be", maxWidth = 16 输出: "What must be", "acknowledgment ", "shall be " **解释:**注意最后一行的格式应为 "shall be " 而不是 "shall be", 因为最后一行应为左对齐,而不是左右两端对齐。 第二行同样为左对齐,这是因为这行只包含一个单词。
示例 3:输入: words = "Science","is","what","we","understand","well","enough","to","explain","to","a","computer.","Art","is","everything","else","we","do",maxWidth = 20 输出: "Science is what we", "understand well", "enough to explain to", "a computer. Art is", "everything else we", "do "
提示:
1 <= words.length <= 3001 <= words[i].length <= 20words[i]由小写英文字母和符号组成1 <= maxWidth <= 100words[i].length <= maxWidth
解题思路
贪心分配单词 :从单词数组中逐个取出单词,并将它们放置在当前行中,直到当前行无法再放置更多单词(即放置当前单词后总长度超过 maxWidth)。
-
计算行内空格:
一旦确定了当前行应包含的所有单词,我们需要计算如何在这些单词之间分配空格。对于每行文本,除最后一行外,其它行都需要左右对齐。计算行中单词之间的空格数。平均分配空格,如果有多余的空格,优先分配到靠左的空隙中。
-
格式化每行:将计算得到的空格插入到单词之间,形成需要的格式。对于最后一行,单词左对齐,剩余的空格填充在行尾。
复杂度分析
- 时间复杂度 :O(n),其中
n是单词数组words的长度。每个单词只被处理一次,因此整体时间复杂度是线性的。 - 空间复杂度:O(n),用于存储结果和处理每行的单词列表。
代码实现
java
package org.zyf.javabasic.letcode.jd150.stringarray;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 文本左右对齐
* @author: zhangyanfeng
* @create: 2024-08-25 10:31
**/
public class FullJustify {
public List<String> fullJustify(String[] words, int maxWidth) {
List<String> result = new ArrayList<>();
List<String> currentLine = new ArrayList<>();
int numOfLetters = 0;
for (String word : words) {
// 如果当前行可以容纳这个单词
if (numOfLetters + word.length() + currentLine.size() <= maxWidth) {
currentLine.add(word);
numOfLetters += word.length();
} else {
// 如果当前行满了,处理当前行的文本
result.add(justifyLine(currentLine, numOfLetters, maxWidth, false));
currentLine = new ArrayList<>();
currentLine.add(word);
numOfLetters = word.length();
}
}
// 处理最后一行,左对齐
result.add(justifyLine(currentLine, numOfLetters, maxWidth, true));
return result;
}
private String justifyLine(List<String> words, int numOfLetters, int maxWidth, boolean isLastLine) {
// 如果是最后一行或只有一个单词,左对齐
if (isLastLine || words.size() == 1) {
StringBuilder sb = new StringBuilder();
for (String word : words) {
sb.append(word).append(" ");
}
sb.deleteCharAt(sb.length() - 1); // 删除最后一个空格
while (sb.length() < maxWidth) {
sb.append(" ");
}
return sb.toString();
}
// 计算每个空格的数量
int totalSpaces = maxWidth - numOfLetters;
int spacesBetweenWords = totalSpaces / (words.size() - 1);
int extraSpaces = totalSpaces % (words.size() - 1);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < words.size(); i++) {
sb.append(words.get(i));
if (i < words.size() - 1) {
// 每个空格的基础数量
for (int j = 0; j < spacesBetweenWords; j++) {
sb.append(" ");
}
// 分配多余的空格
if (extraSpaces > 0) {
sb.append(" ");
extraSpaces--;
}
}
}
return sb.toString();
}
}二、双指针
25. 验证回文串(简单)
题目描述
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串
s,如果它是 回文串 ,返回true;否则,返回false。示例 1:输入: s = "A man, a plan, a canal: Panama" 输出: true 解释:"amanaplanacanalpanama" 是回文串。
示例 2:输入: s = "race a car" 输出: false 解释:"raceacar" 不是回文串。
示例 3:输入: s = " " 输出: true **解释:**在移除非字母数字字符之后,s 是一个空字符串 "" 。 由于空字符串正着反着读都一样,所以是回文串。
提示:
1 <= s.length <= 2 *s仅由可打印的 ASCII 字符组成
解题思路
可见字符串高频编程笔试汇总_字符串专题复习-CSDN博客中第6题。
26. 判断子序列(简单)
题目描述
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,
"ace"是"abcde"的一个子序列,而"aec"不是)。进阶:
如果有大量输入的 S,称作 S1, S2, ... , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
示例 1:输入: s = "abc", t = "ahbgdc" **输出:**true
示例 2:输入: s = "axc", t = "ahbgdc" **输出:**false
提示:
0 <= s.length <= 1000 <= t.length <= 10^4- 两个字符串都只由小写字符组成。
解题思路
可见LeetCode 精选 75 回顾-CSDN博客中的第11题。
27. 两数之和 II - 输入有序数组 (中等)
题目描述
给你一个下标从 1 开始的整数数组
numbers,该数组已按非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数target的两个数。如果设这两个数分别是numbers[index1]和numbers[index2],则1 <= index1 < index2 <= numbers.length。以长度为 2 的整数数组
[index1, index2]的形式返回这两个整数的下标index1和index2。你可以假设每个输入 只对应唯一的答案 ,而且你 不可以 重复使用相同的元素。
你所设计的解决方案必须只使用常量级的额外空间。
示例 1:输入: numbers = ***2*** ,***7*** ,11,15, target = 9 输出: 1,2 **解释:**2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。返回 1, 2 。
示例 2:输入: numbers = ***2*** ,3,***4*** , target = 6 输出: 1,3 **解释:**2 与 4 之和等于目标数 6 。因此 index1 = 1, index2 = 3 。返回 1, 3 。
示例 3:输入: numbers = ***-1*** ,***0*** , target = -1 输出: 1,2 解释:-1 与 0 之和等于目标数 -1 。因此 index1 = 1, index2 = 2 。返回 1, 2 。
提示:
2 <= numbers.length <= 3 *-1000 <= numbers[i] <= 1000numbers按 非递减顺序 排列-1000 <= target <= 1000- 仅存在一个有效答案
解题思路
如果是无序数组的话,可见数组知识及编程练习总结-CSDN博客中的第1题。
由于数组 numbers 是按非递减顺序排列的,我们可以利用这一点来设计一个高效的解法。具体来说,我们可以使用"双指针"方法来找到满足条件的两个数。这种方法的优势在于其时间复杂度为 O(n),同时只使用常量级的额外空间。双指针法的步骤
-
初始化指针 :使用两个指针
left和right。left指针从数组的起始位置开始,right指针从数组的末尾位置开始。 -
遍历数组:
- 计算
numbers[left]和numbers[right]的和。 - 如果和等于目标值
target,返回这两个指针的位置(加 1,因为题目要求返回的是从 1 开始的下标)。 - 如果和小于
target,说明我们需要更大的数,因此将left指针向右移动一步。 - 如果和大于
target,说明我们需要更小的数,因此将right指针向左移动一步。
- 计算
-
终止条件 :当
left指针不再小于right指针时,算法结束。
这种方法利用了数组的有序性,使得每一步都可以排除掉一些不必要的元素,从而保证了时间复杂度为 O(n)。
复杂度分析
- 时间复杂度 :O(n),其中 n 是数组
numbers的长度。每个元素最多只被访问一次,因此整体时间复杂度是线性的。 - 空间复杂度:O(1),只使用了常量级的额外空间用于存储指针和变量。
代码实现
java
package org.zyf.javabasic.letcode.jd150.twopoints;
/**
* @program: zyfboot-javabasic
* @description: 两数之和 II - 输入有序数组
* @author: zhangyanfeng
* @create: 2024-08-25 10:43
**/
public class TwoSum {
public int[] twoSum(int[] numbers, int target) {
int left = 0; // 左指针
int right = numbers.length - 1; // 右指针
// 遍历直到两个指针重合
while (left < right) {
int sum = numbers[left] + numbers[right]; // 计算当前指针指向的两个数的和
if (sum == target) {
// 如果和等于目标值,返回下标(加 1,因为题目要求从 1 开始)
return new int[] {left + 1, right + 1};
} else if (sum < target) {
// 如果和小于目标值,左指针向右移动
left++;
} else {
// 如果和大于目标值,右指针向左移动
right--;
}
}
// 如果没有找到符合条件的两个数(题目保证有唯一解,这里只是为了编译器完整性)
return new int[] {-1, -1};
}
}28. 盛最多水的容器 (中等)
题目描述
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, heighti) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明:你不能倾斜容器。
示例 1:
输入:1,8,6,2,5,4,8,3,7
输出:49
解释:图中垂直线代表输入数组 1,8,6,2,5,4,8,3,7。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
示例 2:输入:height = 1,1 输出:1
提示:
n == height.length
2 <= n <=
0 <= heighti <=

解题思路
可见LeetCode 精选 75 回顾-CSDN博客中的第12题。
也可见LeetCode 热题 100 回顾-CSDN博客中的第5题。
29. 三数之和 (中等)
题目描述
给你一个整数数组
nums,判断是否存在三元组[nums[i], nums[j], nums[k]]满足i != j、i != k且j != k,同时还满足nums[i] + nums[j] + nums[k] == 0。请你返回所有和为0且不重复的三元组。**注意:**答案中不可以包含重复的三元组。
示例 1:输入: nums = -1,0,1,2,-1,-4 输出: \[-1,-1,2,-1,0,1] 解释: nums0 + nums1 + nums2 = (-1) + 0 + 1 = 0 。 nums1 + nums2 + nums4 = 0 + 1 + (-1) = 0 。 nums0 + nums3 + nums4 = (-1) + 2 + (-1) = 0 。 不同的三元组是 -1,0,1 和 -1,-1,2 。 注意,输出的顺序和三元组的顺序并不重要。
示例 2:输入: nums = 0,1,1 输出: \[\] **解释:**唯一可能的三元组和不为 0 。
示例 3:输入: nums = 0,0,0 输出: \[0,0,0] **解释:**唯一可能的三元组和为 0 。
提示:
3 <= nums.length <= 3000-<= nums[i] <=
解题思路
可见LeetCode 热题 100 回顾-CSDN博客中的第6题。
也可见数组知识及编程练习总结-CSDN博客中的第2题。
三、滑动窗口
30. 长度最小的子数组 (中等)
题目描述
给定一个含有
n个正整数的数组和一个正整数target。找出该数组中满足其总和大于等于
target的长度最小的子数组
[numsl, numsl+1, ..., numsr-1, numsr],并返回其长度**。** 如果不存在符合条件的子数组,返回0。示例 1:输入: target = 7, nums = 2,3,1,2,4,3 输出: 2 解释: 子数组
[4,3]是该条件下的长度最小的子数组。示例 2:输入: target = 4, nums = 1,4,4 **输出:**1
示例 3:输入: target = 11, nums = 1,1,1,1,1,1,1,1 **输出:**0
提示:
1 <= target <= 1091 <= nums.length <= 1051 <= nums[i] <= 105
解题思路
为了找到满足总和大于等于 target 的最小长度子数组,我们可以使用滑动窗口(双指针)的方法:
-
初始化变量 :
left指针表示当前子数组的起始位置。right指针表示当前子数组的结束位置。currentSum用于记录当前子数组的总和。minLength用于记录找到的最小长度,初始值设为无穷大(Integer.MAX_VALUE)。 -
扩展窗口 :使用
right指针从头到尾遍历数组,同时将当前元素加入currentSum。 -
收缩窗口 :每次
currentSum大于等于target时,更新minLength并将left指针向右移动以尝试缩小窗口,同时更新currentSum。 -
终止条件 :遍历结束后,如果
minLength仍为无穷大,说明没有找到符合条件的子数组,返回0。
这种方法的时间复杂度是 O(n),因为每个元素最多被访问两次(一次被 right 指针访问,一次被 left 指针访问),空间复杂度是 O(1)。
复杂度分析
- 时间复杂度 :O(n),其中 n 是数组
nums的长度。每个元素最多被访问两次,因此整体时间复杂度为线性。 - 空间复杂度:O(1),只使用了常量级的额外空间用于存储指针和变量。
代码实现
java
package org.zyf.javabasic.letcode.jd150.window;
/**
* @program: zyfboot-javabasic
* @description: 长度最小的子数组
* @author: zhangyanfeng
* @create: 2024-08-25 10:58
**/
public class MinSubArrayLen {
public int minSubArrayLen(int target, int[] nums) {
int left = 0; // 左指针
int currentSum = 0; // 当前子数组的总和
int minLength = Integer.MAX_VALUE; // 记录最小长度
// 遍历数组
for (int right = 0; right < nums.length; right++) {
currentSum += nums[right]; // 扩展窗口
// 收缩窗口,直到 currentSum 小于 target
while (currentSum >= target) {
minLength = Math.min(minLength, right - left + 1); // 更新最小长度
currentSum -= nums[left++]; // 收缩窗口
}
}
// 如果 minLength 未更新,说明没有找到符合条件的子数组
return minLength == Integer.MAX_VALUE ? 0 : minLength;
}
}31. 无重复字符的最长子串 (中等)
题目描述
给定一个字符串
s,请你找出其中不含有重复字符的 最长 子串 的长度。示例 1:输入: s = "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是
"abc",所以其长度为 3。示例 2:输入: s = "bbbbb" 输出: 1 解释: 因为无重复字符的最长子串是
"b",所以其长度为 1。示例 3:输入: s = "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是
"wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke"是一个*子序列,*不是子串。提示:
0 <= s.length <= 5 * 104s由英文字母、数字、符号和空格组成
解题思路
可见LeetCode 热题 100 回顾-CSDN博客中的第8题。
可见字符串高频编程笔试汇总_字符串专题复习-CSDN博客中的第18题。
可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第1题。
32. 串联所有单词的子串 (困难)
题目描述
给定一个字符串
s和一个字符串数组words。words中所有字符串 长度相同。
s中的 串联子串 是指一个包含words中所有字符串以任意顺序排列连接起来的子串。
- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。返回所有串联子串在
s中的开始索引。你可以以 任意顺序 返回答案。示例 1:输入: s = "barfoothefoobarman", words = "foo","bar" 输出:
[0,9]**解释:**因为 words.length == 2 同时 wordsi.length == 3,连接的子字符串的长度必须为 6。 子串 "barfoo" 开始位置是 0。它是 words 中以 "bar","foo" 顺序排列的连接。 子串 "foobar" 开始位置是 9。它是 words 中以 "foo","bar" 顺序排列的连接。 输出顺序无关紧要。返回 9,0 也是可以的。示例 2:输入: s = "wordgoodgoodgoodbestword", words = "word","good","best","word" 输出:
[]解释: 因为words.length == 4 并且 wordsi.length == 4,所以串联子串的长度必须为 16。 s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。 所以我们返回一个空数组。示例 3:输入: s = "barfoofoobarthefoobarman", words = "bar","foo","the" 输出: 6,9,12 **解释:**因为 words.length == 3 并且 wordsi.length == 3,所以串联子串的长度必须为 9。 子串 "foobarthe" 开始位置是 6。它是 words 中以 "foo","bar","the" 顺序排列的连接。 子串 "barthefoo" 开始位置是 9。它是 words 中以 "bar","the","foo" 顺序排列的连接。 子串 "thefoobar" 开始位置是 12。它是 words 中以 "the","foo","bar" 顺序排列的连接。
提示:
1 <= s.length <= 1041 <= words.length <= 50001 <= words[i].length <= 30words[i]和s由小写英文字母组成
解题思路
给定的解法使用了滑动窗口和哈希表来解决寻找字符串中所有串联子串的起始位置的问题:
-
初始化和基本参数设置 :
m是words数组中的单词数量。n是每个单词的长度。ls是字符串s的长度。遍历字符串s中的每一个可能的起始位置(从i = 0到i < n),以保证覆盖所有可能的窗口起始位置。 -
预处理:
对于每个起始位置
i,检查从i开始的长度为m * n的子串是否是words中所有单词的排列。使用differ哈希表记录当前窗口的单词及其计数。初始化时,将子串中的每个单词加入differ表中。 -
滑动窗口处理:
将窗口向右滑动,每次滑动一个单词的长度
n。更新differ哈希表,加入新的单词并移除旧的单词。检查differ是否为空。如果为空,说明当前窗口中的单词完全匹配了words中的单词,记录当前的起始位置。
复杂度分析
-
时间复杂度:
- 遍历每个可能的起始位置
i。由于窗口滑动的步长是n,所以i的最大范围是n。 - 对于每个起始位置,滑动窗口遍历的次数是
O(ls / n),其中ls是字符串s的长度。 - 更新哈希表操作的时间复杂度为
O(m),其中m是words中单词的数量。 - 总的时间复杂度为
O(n * (ls / n) * m) = O(ls * m)。
- 遍历每个可能的起始位置
-
空间复杂度:
differ哈希表的大小最多为m,因为differ记录了words中的所有单词及其计数。- 总的空间复杂度为
O(m)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.window;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: findSubstring
* @author: zhangyanfeng
* @create: 2024-08-25 11:05
**/
public class FindSubstring {
public List<Integer> findSubstring(String s, String[] words) {
List<Integer> res = new ArrayList<Integer>(); // 结果列表
int m = words.length; // 单词数量
int n = words[0].length(); // 每个单词的长度
int ls = s.length(); // 字符串 s 的长度
// 遍历所有可能的起始位置
for (int i = 0; i < n; i++) {
if (i + m * n > ls) {
break; // 如果剩余长度不足以容纳所有单词,则结束
}
// 记录当前窗口内的单词及其计数
Map<String, Integer> differ = new HashMap<String, Integer>();
for (int j = 0; j < m; j++) {
String word = s.substring(i + j * n, i + (j + 1) * n); // 当前窗口中的单词
differ.put(word, differ.getOrDefault(word, 0) + 1); // 计数
}
// 从 words 中移除所有单词的计数,准备验证
for (String word : words) {
differ.put(word, differ.getOrDefault(word, 0) - 1);
if (differ.get(word) == 0) {
differ.remove(word); // 移除计数为零的单词
}
}
// 滑动窗口
for (int start = i; start < ls - m * n + 1; start += n) {
if (start != i) {
// 更新窗口:添加新单词,移除旧单词
String word = s.substring(start + (m - 1) * n, start + m * n);
differ.put(word, differ.getOrDefault(word, 0) + 1);
if (differ.get(word) == 0) {
differ.remove(word);
}
word = s.substring(start - n, start);
differ.put(word, differ.getOrDefault(word, 0) - 1);
if (differ.get(word) == 0) {
differ.remove(word);
}
}
// 检查是否所有单词都匹配
if (differ.isEmpty()) {
res.add(start); // 记录符合条件的起始位置
}
}
}
return res; // 返回结果
}
}33. 最小覆盖子串 (困难)
题目描述
给你一个字符串
s、一个字符串t。返回s中涵盖t所有字符的最小子串。如果s中不存在涵盖t所有字符的子串,则返回空字符串""。注意:
- 对于
t中重复字符,我们寻找的子字符串中该字符数量必须不少于t中该字符数量。- 如果
s中存在这样的子串,我们保证它是唯一的答案。示例 1:输入: s = "ADOBECODEBANC", t = "ABC" 输出: "BANC" **解释:**最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。
示例 2:输入: s = "a", t = "a" 输出: "a" **解释:**整个字符串 s 是最小覆盖子串。
示例 3:输入: s = "a", t = "aa" 输出: "" 解释: t 中两个字符 'a' 均应包含在 s 的子串中, 因此没有符合条件的子字符串,返回空字符串。
提示:
m == s.lengthn == t.length1 <= m, n <= 105s和t由英文字母组成
解题思路
可见LeetCode 热题 100 回顾-CSDN博客中的第12题。
可见字符串高频编程笔试汇总_字符串专题复习-CSDN博客中的第21题。
可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第3题。
四、矩阵
34. 有效的数独 (中等)
题目描述
请你判断一个
9 x 9的数独是否有效。只需要根据以下规则 ,验证已经填入的数字是否有效即可。
- 数字
1-9在每一行只能出现一次。- 数字
1-9在每一列只能出现一次。- 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。(请参考示例图)注意:
- 一个有效的数独(部分已被填充)不一定是可解的。
- 只需要根据以上规则,验证已经填入的数字是否有效即可。
- 空白格用
'.'表示。示例 1:
输入:board = [["5","3",".",".","7",".",".",".","."] ,["6",".",".","1","9","5",".",".","."] ,[".","9","8",".",".",".",".","6","."] ,["8",".",".",".","6",".",".",".","3"] ,["4",".",".","8",".","3",".",".","1"] ,["7",".",".",".","2",".",".",".","6"] ,[".","6",".",".",".",".","2","8","."] ,[".",".",".","4","1","9",".",".","5"] ,[".",".",".",".","8",".",".","7","9"]] 输出:true示例 2:
输入:board = [["8","3",".",".","7",".",".",".","."] ,["6",".",".","1","9","5",".",".","."] ,[".","9","8",".",".",".",".","6","."] ,["8",".",".",".","6",".",".",".","3"] ,["4",".",".","8",".","3",".",".","1"] ,["7",".",".",".","2",".",".",".","6"] ,[".","6",".",".",".",".","2","8","."] ,[".",".",".","4","1","9",".",".","5"] ,[".",".",".",".","8",".",".","7","9"]] 输出:false 解释:除了第一行的第一个数字从 5 改为 8 以外,空格内其他数字均与 示例1 相同。 但由于位于左上角的 3x3 宫内有两个 8 存在, 因此这个数独是无效的。提示:
board.length == 9board[i].length == 9board[i][j]是一位数字(1-9)或者'.'

解题思路
具体可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第2题。
35.螺旋矩阵(中等)
题目描述
给你一个
m行n列的矩阵matrix,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]示例 2:
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]] 输出:[1,2,3,4,8,12,11,10,9,5,6,7]提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 10-100 <= matrix[i][j] <= 100
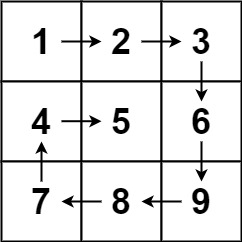

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第19题。
36.旋转图像(中等)
题目描述
给定一个 n × n 的二维矩阵
matrix表示一个图像。请你将图像顺时针旋转 90 度。你必须在********原地******** 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。
示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] 输出:[[7,4,1],[8,5,2],[9,6,3]]示例 2:
输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]] 输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]提示:
n == matrix.length == matrix[i].length1 <= n <= 20-1000 <= matrix[i][j] <= 1000

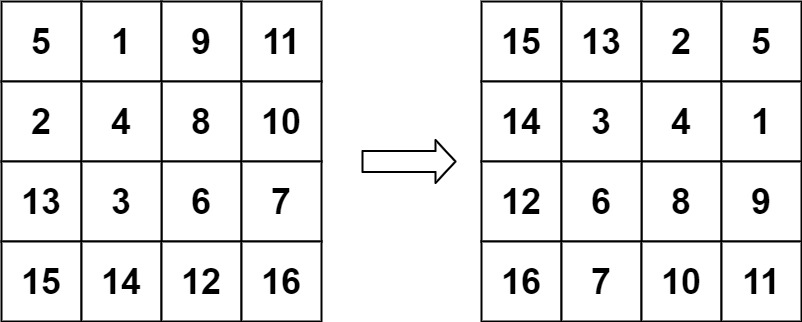
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第20题。
37.矩阵置零 (中等)
题目描述
给定一个 m
xn 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法**。**示例 1:
输入:matrix = [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]]示例 2:
输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]] 输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]提示:
m == matrix.lengthn == matrix[0].length1 <= m, n <= 200-<= matrix[i][j] <=- 1进阶:
- 一个直观的解决方案是使用
O(m n)的额外空间,但这并不是一个好的解决方案。- 一个简单的改进方案是使用
O(m+n)的额外空间,但这仍然不是最好的解决方案。- 你能想出一个仅使用常量空间的解决方案吗?

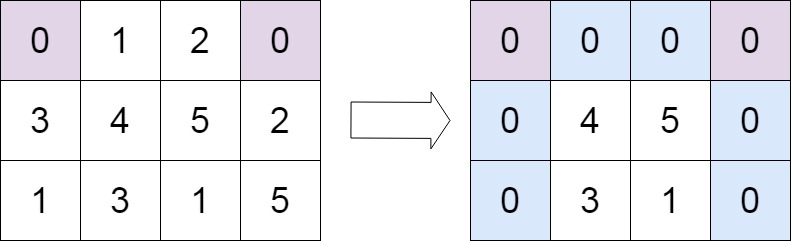
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第18题。
38. 生命游戏(中等)
题目描述
根据 百度百科 , 生命游戏 ,简称为 生命 ,是英国数学家约翰·何顿·康威在 1970 年发明的细胞自动机。
给定一个包含
m × n个格子的面板,每一个格子都可以看成是一个细胞。每个细胞都具有一个初始状态:1即为 活细胞 (live),或0即为 死细胞 (dead)。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律:
- 如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡;
- 如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活;
- 如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡;
- 如果死细胞周围正好有三个活细胞,则该位置死细胞复活;
下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。给你
m x n网格面板board的当前状态,返回下一个状态。示例 1:
输入:board = [[0,1,0],[0,0,1],[1,1,1],[0,0,0]] 输出:[[0,0,0],[1,0,1],[0,1,1],[0,1,0]]示例 2:
输入:board = [[1,1],[1,0]] 输出:[[1,1],[1,1]]提示:
m == board.lengthn == board[i].length1 <= m, n <= 25board[i][j]为0或1进阶:
- 你可以使用原地算法解决本题吗?请注意,面板上所有格子需要同时被更新:你不能先更新某些格子,然后使用它们的更新后的值再更新其他格子。
- 本题中,我们使用二维数组来表示面板。原则上,面板是无限的,但当活细胞侵占了面板边界时会造成问题。你将如何解决这些问题?

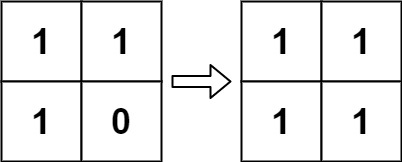
解题思路
链接:https://leetcode.cn/problems/game-of-life/solutions/179750/sheng-ming-you-xi-by-leetcode-solution/
先根据下面的图片理解题目中描述的细胞遵循的生存定律:


这个问题看起来很简单,但有一个陷阱,如果你直接根据规则更新原始数组,那么就做不到题目中说的 同步 更新。假设你直接将更新后的细胞状态填入原始数组,那么当前轮次其他细胞状态的更新就会引用到当前轮已更新细胞的状态,但实际上每一轮更新需要依赖上一轮细胞的状态,是不能用这一轮的细胞状态来更新的。

如上图所示,已更新细胞的状态会影响到周围其他还未更新细胞状态的计算。一个最简单的解决方法就是复制一份原始数组,复制的那一份永远不修改,只作为更新规则的引用。这样原始数组的细胞值就不会被污染了。

算法
-
复制一份原始数组;
-
根据复制数组中邻居细胞的状态来更新
board中的细胞状态。
复杂度分析
-
时间复杂度:O(mn),其中 m 和 n 分别为
board的行数和列数。 -
空间复杂度:O(mn),为复制数组占用的空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.window;
/**
* @program: zyfboot-javabasic
* @description: gameOfLife
* @author: zhangyanfeng
* @create: 2024-08-25 11:50
**/
public class GameOfLife {
public void gameOfLife(int[][] board) {
// 定义邻居位置的偏移量
int[] neighbors = {0, 1, -1};
// 获取网格的行数和列数
int rows = board.length;
int cols = board[0].length;
// 创建与原始网格大小相同的复制网格
int[][] copyBoard = new int[rows][cols];
// 将原始网格的状态复制到复制网格中
for (int row = 0; row < rows; row++) {
for (int col = 0; col < cols; col++) {
copyBoard[row][col] = board[row][col];
}
}
// 遍历每个细胞,更新网格状态
for (int row = 0; row < rows; row++) {
for (int col = 0; col < cols; col++) {
// 统计当前细胞的八个邻居中的活细胞数量
int liveNeighbors = 0;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
// 排除自己
if (!(neighbors[i] == 0 && neighbors[j] == 0)) {
int r = row + neighbors[i];
int c = col + neighbors[j];
// 确保邻居在网格范围内并且是活细胞
if (r >= 0 && r < rows && c >= 0 && c < cols && copyBoard[r][c] == 1) {
liveNeighbors++;
}
}
}
}
// 根据活邻居数和当前状态更新细胞状态
if (copyBoard[row][col] == 1) { // 当前细胞是活的
if (liveNeighbors < 2 || liveNeighbors > 3) {
board[row][col] = 0; // 死亡
}
} else { // 当前细胞是死的
if (liveNeighbors == 3) {
board[row][col] = 1; // 复活
}
}
}
}
}
}五、哈希表
39. 赎金信(简单)
题目描述
给你两个字符串:
ransomNote和magazine,判断ransomNote能不能由magazine里面的字符构成。如果可以,返回
true;否则返回false。
magazine中的每个字符只能在ransomNote中使用一次。示例 1:输入: ransomNote = "a", magazine = "b" **输出:**false
示例 2:输入: ransomNote = "aa", magazine = "ab" **输出:**false
示例 3:输入: ransomNote = "aa", magazine = "aab" **输出:**true
提示:
1 <= ransomNote.length, magazine.length <= 105ransomNote和magazine由小写英文字母组成
解题思路
要解决这个问题,我们需要判断 ransomNote 是否可以由 magazine 中的字符构成。每个字符在 magazine 中只能使用一次:
-
统计字符频率 :使用两个频率数组或哈希表来统计
magazine和ransomNote中每个字符的出现次数。 -
检查字符是否足够 :对于
ransomNote中的每个字符,检查在magazine中是否有足够的字符来满足需求。
复杂度分析
-
时间复杂度 :统计
magazine和ransomNote中每个字符的频率都需要 O(n) 时间,其中 n 是字符串的长度。因此总时间复杂度为 O(m + n),其中 m 是ransomNote的长度,n 是magazine的长度。 -
空间复杂度:需要两个频率数组或哈希表来存储字符的出现次数。因为字符集有限(26 个小写字母),空间复杂度为 O(1)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.hash;
import java.util.HashMap;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 赎金信
* @author: zhangyanfeng
* @create: 2024-08-25 11:56
**/
public class CanConstruct {
public boolean canConstruct(String ransomNote, String magazine) {
// 使用 HashMap 统计 magazine 中每个字符的频率
Map<Character, Integer> magazineCount = new HashMap<>();
// 遍历 magazine 统计每个字符的出现次数
for (char c : magazine.toCharArray()) {
magazineCount.put(c, magazineCount.getOrDefault(c, 0) + 1);
}
// 遍历 ransomNote 检查是否有足够的字符
for (char c : ransomNote.toCharArray()) {
// 如果 magazine 中没有字符 c,或字符 c 的数量不足
if (!magazineCount.containsKey(c) || magazineCount.get(c) == 0) {
return false; // 无法构造 ransomNote
}
// 使用一个字符 c,减少其在 magazine 中的频率
magazineCount.put(c, magazineCount.get(c) - 1);
}
// 如果遍历完 ransomNote 中的所有字符后,没有问题,则返回 true
return true;
}
}40. 同构字符串(简单)
题目描述
给定两个字符串
s和t,判断它们是否是同构的。如果
s中的字符可以按某种映射关系替换得到t,那么这两个字符串是同构的。每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
示例 1:输入: s =
"egg", t ="add"**输出:**true示例 2:输入: s =
"foo", t ="bar"**输出:**false示例 3:输入: s =
"paper", t ="title"**输出:**true提示:
1 <= s.length <= 5 * 104t.length == s.lengths和t由任意有效的 ASCII 字符组成
解题思路
具体可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第19题。
41. 单词规律(简单)
题目描述
给定一种规律
pattern和一个字符串s,判断s是否遵循相同的规律。这里的 遵循 指完全匹配,例如,
pattern里的每个字母和字符串s中的每个非空单词之间存在着双向连接的对应规律。示例1:输入: pattern =
"abba", s ="dog cat cat dog"输出: true示例 2:输入: pattern =
"abba", s ="dog cat cat fish"输出: false示例 3:输入: pattern =
"aaaa", s ="dog cat cat dog"输出: false提示:
1 <= pattern.length <= 300pattern只包含小写英文字母1 <= s.length <= 3000s只包含小写英文字母和' 's不包含 任何前导或尾随对空格s中每个单词都被 单个空格分隔
解题思路
具体可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第13题。
42. 有效的字母异位词(简单)
题目描述
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意: 若 s 和 t中每个字符出现的次数都相同,则称 s 和 t互为字母异位词。
示例 1:输入: s = "anagram", t = "nagaram" 输出: true
示例 2:输入: s = "rat", t = "car" **输出:**false
提示:
1 <= s.length, t.length <= 5 * 104s和t仅包含小写字母**进阶:**如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
解题思路
具体可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第5题。
43. 字母异位词分组(中等)
题目描述
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
示例 1:输入: strs =
["eat", "tea", "tan", "ate", "nat", "bat"]输出:\["bat","nat","tan","ate","eat","tea"]示例 2:输入: strs =
[""]输出:\[""]示例 3:输入: strs =
["a"]输出:\["a"]提示:
1 <= strs.length <= 1040 <= strs[i].length <= 100strs[i]仅包含小写字母
解题思路
具体可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第4题。
具体可见LeetCode 热题 100 回顾-CSDN博客中的第2题。
44. 两数之和(简单)
题目描述
给定一个整数数组
nums和一个整数目标值target,请你在该数组中找出 和为目标值target的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
示例 1:输入: nums = 2,7,11,15, target = 9 输出: 0,1 **解释:**因为 nums0 + nums1 == 9 ,返回 0, 1 。
示例 2:输入: nums = 3,2,4, target = 6 输出:1,2
示例 3:输入: nums = 3,3, target = 6 输出:0,1
提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
进阶: 你可以想出一个时间复杂度小于
O(n2)的算法吗?
解题思路
具体可见数组知识及编程练习总结-CSDN博客中的第1题。
具体可见LeetCode 热题 100 回顾-CSDN博客中的第1题。
45. 快乐数(简单)
题目描述
编写一个算法来判断一个数
n是不是快乐数。「快乐数」 定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
- 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
- 如果这个过程 结果为 1,那么这个数就是快乐数。
如果
n是 快乐数 就返回true;不是,则返回false。示例 1:输入: n = 19 输出: true **解释:**12 + 92 = 82 82 + 22 = 68 62 + 82 = 100 12 + 02 + 02 = 1
示例 2:输入: n = 2 **输出:**false
提示:
1 <= n <= 231 - 1
解题思路
具体可见数学思维编程练习总结_编程中的数学思维-CSDN博客中的第3题。
也可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第10题。
46. 存在重复元素 II(简单)
题目描述
给你一个整数数组
nums和一个整数k,判断数组中是否存在两个 不同的索引i和j,满足nums[i] == nums[j]且abs(i - j) <= k。如果存在,返回true;否则,返回false。示例 1:输入: nums = 1,2,3,1, k= 3 **输出:**true
示例 2:输入: nums = 1,0,1,1, k=1 **输出:**true
示例 3:输入: nums = 1,2,3,1,2,3, k=2 **输出:**false
提示:
1 <= nums.length <= 105-109 <= nums[i] <= 1090 <= k <= 105
解题思路
也可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中的第12题。
47. 最长连续序列(中等)
题目描述
给定一个未排序的整数数组
nums,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。请你设计并实现时间复杂度为
O(n)的算法解决此问题。示例 1:输入: nums = 100,4,200,1,3,2 输出: 4 **解释:**最长数字连续序列是 1, 2, 3, 4。它的长度为 4。
示例 2:输入: nums = 0,3,7,2,5,8,4,6,0,1 **输出:**9
提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第3题。
六、区间
48. 汇总区间(简单)
题目描述
给定一个 无重复元素 的 有序 整数数组
nums。返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表 。也就是说,
nums的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于nums的数字x。列表中的每个区间范围
[a,b]应该按如下格式输出:
"a->b",如果a != b"a",如果a == b示例 1:输入: nums = 0,1,2,4,5,7 输出: "0-\>2","4-\>5","7" **解释:**区间范围是: 0,2 --> "0->2" 4,5 --> "4->5" 7,7 --> "7"
示例 2:输入: nums = 0,2,3,4,6,8,9 输出: "0","2-\>4","6","8-\>9" **解释:**区间范围是: 0,0 --> "0" 2,4 --> "2->4" 6,6 --> "6" 8,9 --> "8->9"
提示:
0 <= nums.length <= 20-231 <= nums[i] <= 231 - 1nums中的所有值都 互不相同nums按升序排列
解题思路
为了找到最小的有序区间范围列表,我们可以使用以下思路:
- 遍历数组:我们从数组的第一个元素开始,逐个检查元素。
- 确定区间:对于每个元素,检查它是否与下一个元素连续。如果是,则继续扩展当前区间。如果不是,则结束当前区间并开始新的区间。
- 处理边界:当我们处理到数组的末尾时,要确保最后一个区间被正确处理。
- 格式化区间:对于每个区间,根据开始和结束值的关系,格式化为"a->b"或者"a"。
复杂度分析
- 时间复杂度 :O(n),其中 n 是数组
nums的长度。我们只需遍历一次数组来构建区间。 - 空间复杂度:O(n),用于存储区间范围列表的结果。
代码实现
java
package org.zyf.javabasic.letcode.jd150.ranges;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 汇总区间
* @author: zhangyanfeng
* @create: 2024-08-25 12:21
**/
public class FindRanges {
public List<String> findRanges(int[] nums) {
List<String> result = new ArrayList<>();
if (nums.length == 0) {
return result; // 如果数组为空,返回空列表
}
int start = nums[0]; // 区间起始值
int end = nums[0]; // 区间结束值
for (int i = 1; i < nums.length; i++) {
if (nums[i] == end + 1) {
// 如果当前元素与结束值连续,扩展当前区间
end = nums[i];
} else {
// 否则,结束当前区间,添加到结果中,并开始新的区间
result.add(formatRange(start, end));
start = nums[i];
end = nums[i];
}
}
// 处理最后一个区间
result.add(formatRange(start, end));
return result;
}
private String formatRange(int start, int end) {
// 格式化区间为字符串
if (start == end) {
return String.valueOf(start);
} else {
return start + "->" + end;
}
}
public static void main(String[] args) {
FindRanges sol = new FindRanges();
int[] nums1 = {0, 1, 2, 4, 5, 7};
int[] nums2 = {0, 2, 3, 4, 6, 8, 9};
System.out.println(sol.findRanges(nums1)); // 输出: ["0->2","4->5","7"]
System.out.println(sol.findRanges(nums2)); // 输出: ["0","2->4","6","8->9"]
}
}49. 合并区间(中等)
题目描述
以数组
intervals表示若干个区间的集合,其中单个区间为intervals[i] = [starti, endi]。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。示例 1:输入: intervals = \[1,3,2,6,8,10,15,18] 输出: \[1,6,8,10,15,18] **解释:**区间 1,3 和 2,6 重叠, 将它们合并为 1,6.
示例 2:输入: intervals = \[1,4,4,5] 输出: \[1,5] **解释:**区间 1,4 和 4,5 可被视为重叠区间。
提示:
1 <= intervals.length <= 104intervals[i].length == 20 <= starti <= endi <= 104
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第14题。
具体可见数组知识及编程练习总结-CSDN博客中的第14题。
50. 插入区间(中等)
题目描述
给你一个无重叠的 , 按照区间起始端点排序的区间列表
intervals,其中intervals[i] = [starti, endi]表示第i个区间的开始和结束,并且intervals按照starti升序排列。同样给定一个区间newInterval = [start, end]表示另一个区间的开始和结束。在
intervals中插入区间newInterval,使得intervals依然按照starti升序排列,且区间之间不重叠(如果有必要的话,可以合并区间)。返回插入之后的
intervals。注意 你不需要原地修改
intervals。你可以创建一个新数组然后返回它。示例 1:输入: intervals = \[1,3,6,9], newInterval = 2,5 输出:\[1,5,6,9]
示例 2:输入: intervals = \[1,2,3,5,6,7,8,10,12,16], newInterval = 4,8 输出: \[1,2,3,10,12,16] 解释: 这是因为新的区间
[4,8]与[3,5],[6,7],[8,10]重叠。提示:
0 <= intervals.length <= 104intervals[i].length == 20 <= starti <= endi <= 105intervals根据starti按 升序 排列newInterval.length == 20 <= start <= end <= 105
解题思路
-
初始化变量:
result:一个List<int[]>用于存储最终的结果。i:用于遍历intervals的指针。 -
处理新区间之前的区间 :遍历
intervals,将所有在newInterval之前且不与newInterval重叠的区间直接添加到result中。 -
合并新区间 :对于与
newInterval重叠的区间,更新newInterval的范围,以合并这些重叠区间。更新后的newInterval范围将包括所有与之重叠的区间。 -
处理新区间之后的区间 :将所有不与合并后的
newInterval重叠的区间添加到result中。 -
转换结果格式 :将
List<int[]>转换为int[][]并返回。
复杂度分析
- 时间复杂度 :O(n),其中 n 是
intervals的长度。我们只需遍历一次intervals来完成合并和插入操作。 - 空间复杂度 :O(n),用于存储结果列表
result。
代码实现
java
package org.zyf.javabasic.letcode.jd150.ranges;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 插入区间
* @author: zhangyanfeng
* @create: 2024-08-25 12:28
**/
public class InsertInterval {
public List<List<Integer>> insertInterval(List<List<Integer>> intervals, List<Integer> newInterval) {
List<List<Integer>> result = new ArrayList<>();
int i = 0;
int n = intervals.size();
// 添加所有在 newInterval 之前且不重叠的区间
while (i < n && intervals.get(i).get(1) < newInterval.get(0)) {
result.add(intervals.get(i++));
}
// 合并所有与 newInterval 重叠的区间
while (i < n && intervals.get(i).get(0) <= newInterval.get(1)) {
newInterval.set(0, Math.min(newInterval.get(0), intervals.get(i).get(0)));
newInterval.set(1, Math.max(newInterval.get(1), intervals.get(i).get(1)));
i++;
}
result.add(newInterval);
// 添加所有在 newInterval 之后且不重叠的区间
while (i < n) {
result.add(intervals.get(i++));
}
return result;
}
public int[][] insert(int[][] intervals, int[] newInterval) {
List<int[]> result = new ArrayList<>();
int i = 0;
int n = intervals.length;
// 添加所有在 newInterval 之前且不重叠的区间
while (i < n && intervals[i][1] < newInterval[0]) {
result.add(intervals[i++]);
}
// 合并所有与 newInterval 重叠的区间
while (i < n && intervals[i][0] <= newInterval[1]) {
newInterval[0] = Math.min(newInterval[0], intervals[i][0]);
newInterval[1] = Math.max(newInterval[1], intervals[i][1]);
i++;
}
result.add(newInterval);
// 添加所有在 newInterval 之后且不重叠的区间
while (i < n) {
result.add(intervals[i++]);
}
// 将结果转换为 int[][] 并返回
return result.toArray(new int[result.size()][]);
}
public static void main(String[] args) {
InsertInterval sol = new InsertInterval();
int[][] intervals1 = {{1, 3}, {6, 9}};
int[] newInterval1 = {2, 5};
int[][] intervals2 = {{1, 2}, {3, 5}, {6, 7}, {8, 10}, {12, 16}};
int[] newInterval2 = {4, 8};
// 打印输出结果
printResult(sol.insert(intervals1, newInterval1)); // 输出: [[1, 5], [6, 9]]
printResult(sol.insert(intervals2, newInterval2)); // 输出: [[1, 2], [3, 10], [12, 16]]
}
private static void printResult(int[][] result) {
for (int[] interval : result) {
System.out.println("[" + interval[0] + ", " + interval[1] + "]");
}
}
}51. 用最少数量的箭引爆气球(中等)
题目描述
有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组
points,其中points[i] = [xstart, xend]表示水平直径在xstart和xend之间的气球。你不知道气球的确切 y 坐标。一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标
x处射出一支箭,若有一个气球的直径的开始和结束坐标为x``start,x``end, 且满足xstart ≤ x ≤ x``end,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。给你一个数组
points,返回引爆所有气球所必须射出的 最小 弓箭数。示例 1:输入: points = \[10,16,2,8,1,6,7,12] 输出: 2 **解释:**气球可以用2支箭来爆破: -在x = 6处射出箭,击破气球2,8和1,6。 -在x = 11处发射箭,击破气球10,16和7,12。
示例 2:输入: points = \[1,2,3,4,5,6,7,8] 输出: 4 **解释:**每个气球需要射出一支箭,总共需要4支箭。
示例 3:输入: points = \[1,2,2,3,3,4,4,5] **输出:**2 解释:气球可以用2支箭来爆破: - 在x = 2处发射箭,击破气球1,2和2,3。 - 在x = 4处射出箭,击破气球3,4和4,5。
提示:
1 <= points.length <= 105points[i].length == 2-231 <= xstart < xend <= 231 - 1
解题思路
具体可见LeetCode 精选 75 回顾-CSDN博客中的第73题。
七、栈
52. 有效的括号(简单)
题目描述
给定一个只包括
'(',')','{','}','[',']'的字符串s,判断字符串是否有效。有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:输入: s = "()" **输出:**true
示例 2:输入: s = "()\[\]{}" **输出:**true
示例 3:输入: s = "(]" **输出:**false
提示:
1 <= s.length <= 104s仅由括号'()[]{}'组成
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第69题。
也可见栈知识及编程练习总结-CSDN博客中的第1题。
53. 简化路径(中等)
题目描述
给你一个字符串
path,表示指向某一文件或目录的 Unix 风格 绝对路径 (以'/'开头),请你将其转化为更加简洁的规范路径。在 Unix 风格的文件系统中,一个点(
.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠'/'。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。请注意,返回的 规范路径 必须遵循下述格式:
- 始终以斜杠
'/'开头。- 两个目录名之间必须只有一个斜杠
'/'。- 最后一个目录名(如果存在)不能 以
'/'结尾。- 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含
'.'或'..')。返回简化后得到的 规范路径 。
示例 1:输入: path = "/home/" 输出: "/home" **解释:**应删除尾部斜杠。
示例 2:输入: path = "/home//foo/" 输出: "/home/foo" **解释:**多个连续的斜杠被单个斜杠替换。
示例 3:输入: path = "/home/user/Documents/../Pictures" 输出: "/home/user/Pictures" 解释:
两个点
".."表示上一级目录。示例 4:输入: path = "/../" 输出: "/" **解释:**不可能从根目录上升级一级。
示例 5:输入: path = "/.../a/../b/c/../d/./" 输出: "/.../b/d"解释:
"..."是此问题中目录的有效名称。提示:
1 <= path.length <= 3000path由英文字母,数字,'.','/'或'_'组成。path是一个有效的 Unix 风格绝对路径。
解题思路
可见栈知识及编程练习总结-CSDN博客中的第9题。
54. 最小栈(中等)
题目描述
设计一个支持
push,pop,top操作,并能在常数时间内检索到最小元素的栈。实现
MinStack类:
MinStack()初始化堆栈对象。void push(int val)将元素val推入堆栈。void pop()删除堆栈顶部的元素。int top()获取堆栈顶部的元素。int getMin()获取堆栈中的最小元素。示例 1:输入: "MinStack","push","push","push","getMin","pop","top","getMin" \[,-2,0,-3,\[\],\[\],\[\],\[\]] 输出: null,null,null,null,-3,null,0,-2 解释: MinStack minStack = new MinStack(); minStack.push(-2); minStack.push(0); minStack.push(-3); minStack.getMin(); --> 返回 -3. minStack.pop(); minStack.top(); --> 返回 0. minStack.getMin(); --> 返回 -2.
提示:
-231 <= val <= 231 - 1pop、top和getMin操作总是在 非空栈 上调用push,pop,top, andgetMin最多被调用3 * 104次
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第70题。
也可见栈知识及编程练习总结-CSDN博客中的第2题。
55. 逆波兰表达式求值(中等)
题目描述
给你一个字符串数组
tokens,表示一个根据 逆波兰表示法 表示的算术表达式。请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为
'+'、'-'、'*'和'/'。- 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
示例 1:输入: tokens = "2","1","+","3","\*" 输出: 9 **解释:**该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:输入: tokens = "4","13","5","/","+" 输出: 6 **解释:**该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:输入: tokens = "10","6","9","3","+","-11","\*","/","\*","17","+","5","+" 输出: 22 **解释:**该算式转化为常见的中缀算术表达式为: ((10 * (6 / ((9 + 3) * -11))) + 17) + 5 = ((10 * (6 / (12 * -11))) + 17) + 5 = ((10 * (6 / -132)) + 17) + 5 = ((10 * 0) + 17) + 5 = (0 + 17) + 5 = 17 + 5 = 22
提示:
1 <= tokens.length <= 104tokens[i]是一个算符("+"、"-"、"*"或"/"),或是在范围[-200, 200]内的一个整数逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
- 平常使用的算式则是一种中缀表达式,如
( 1 + 2 ) * ( 3 + 4 )。- 该算式的逆波兰表达式写法为
( ( 1 2 + ) ( 3 4 + ) * )。逆波兰表达式主要有以下两个优点:
- 去掉括号后表达式无歧义,上式即便写成
1 2 + 3 4 + *也可以依据次序计算出正确结果。- 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中
解题思路
可见栈知识及编程练习总结-CSDN博客中的第7题。
56. 基本计算器 (困难)
题目描述
给你一个字符串表达式
s,请你实现一个基本计算器来计算并返回它的值。注意:不允许使用任何将字符串作为数学表达式计算的内置函数,比如
eval()。示例 1: 输入: s = "1 + 1" **输出:**2
示例 2: 输入: s = " 2-1 + 2 " **输出:**3
示例 3: 输入: s = "(1+(4+5+2)-3)+(6+8)" **输出:**23
提示:
1 <= s.length <= 3 * 105s由数字、'+'、'-'、'('、')'、和' '组成s表示一个有效的表达式- '+' 不能用作一元运算(例如, "+1" 和
"+(2 + 3)"无效)- '-' 可以用作一元运算(即 "-1" 和
"-(2 + 3)"是有效的)- 输入中不存在两个连续的操作符
- 每个数字和运行的计算将适合于一个有符号的 32位 整数
解题思路
可见栈知识及编程练习总结-CSDN博客中的第8题。
八、链表
57.环形链表(简单)
题目描述
给你一个链表的头节点
head,判断链表中是否有环。如果链表中有某个节点,可以通过连续跟踪
next指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数pos来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos不作为参数进行传递。仅仅是为了标识链表的实际情况。如果链表中存在环 ,则返回
true。 否则,返回false。示例 1:
输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。示例 2:
输入:head = [1,2], pos = 0 输出:true 解释:链表中有一个环,其尾部连接到第一个节点。示例 3:
输入:head = [1], pos = -1 输出:false 解释:链表中没有环。提示:
- 链表中节点的数目范围是
[0, 104]-105 <= Node.val <= 105pos为-1或者链表中的一个 有效索引 。进阶: 你能用
O(1)(即,常量)内存解决此问题吗?
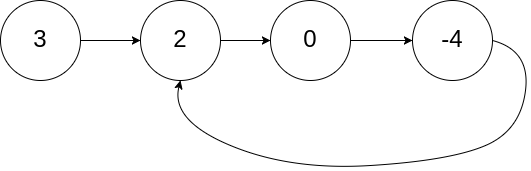
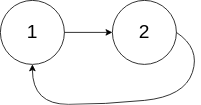

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第25题。
也可见链表知识及编程练习总结中第2题。
58.两数相加(中等)
题目描述
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
输入:l1 = [2,4,3], l2 = [5,6,4] 输出:[7,0,8] 解释:342 + 465 = 807.示例 2:输入: l1 = 0, l2 = 0 输出:0
示例 3:输入: l1 = 9,9,9,9,9,9,9, l2 = 9,9,9,9 输出:8,9,9,9,0,0,0,1
提示:
- 每个链表中的节点数在范围
[1, 100]内0 <= Node.val <= 9- 题目数据保证列表表示的数字不含前导零
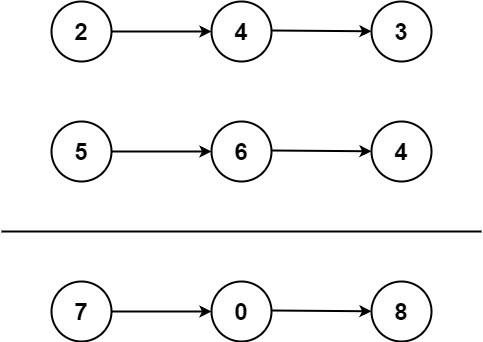
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第28题。
也可见链表知识及编程练习总结中第15题。
59.合并两个有序链表(简单)
题目描述
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]示例 2:输入: l1 = \[\], l2 = \[\] 输出:\[\]
示例 3:输入: l1 = \[\], l2 = 0 输出:0
提示:
- 两个链表的节点数目范围是
[0, 50]-100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
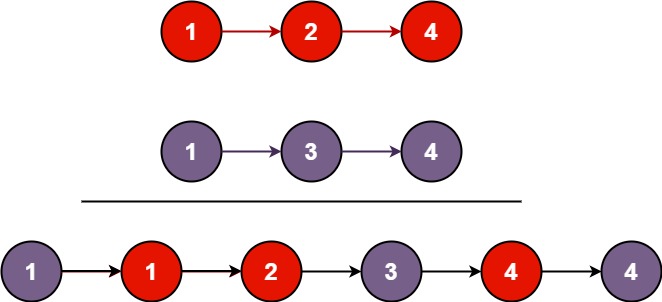
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第27题。
也可见链表知识及编程练习总结中第7题。
60.随机链表的复制(中等)
题目描述
给你一个长度为
n的链表,每个节点包含一个额外增加的随机指针random,该指针可以指向链表中的任何节点或空节点。构造这个链表的 深拷贝 。 深拷贝应该正好由
n个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的next指针和random指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点。例如,如果原链表中有
X和Y两个节点,其中X.random --> Y。那么在复制链表中对应的两个节点x和y,同样有x.random --> y。返回复制链表的头节点。
用一个由
n个节点组成的链表来表示输入/输出中的链表。每个节点用一个[val, random_index]表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。你的代码 只 接受原链表的头节点
head作为传入参数示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:
输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]示例 3:
输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]提示:
0 <= n <= 1000-104 <= Node.val <= 104Node.random为null或指向链表中的节点。
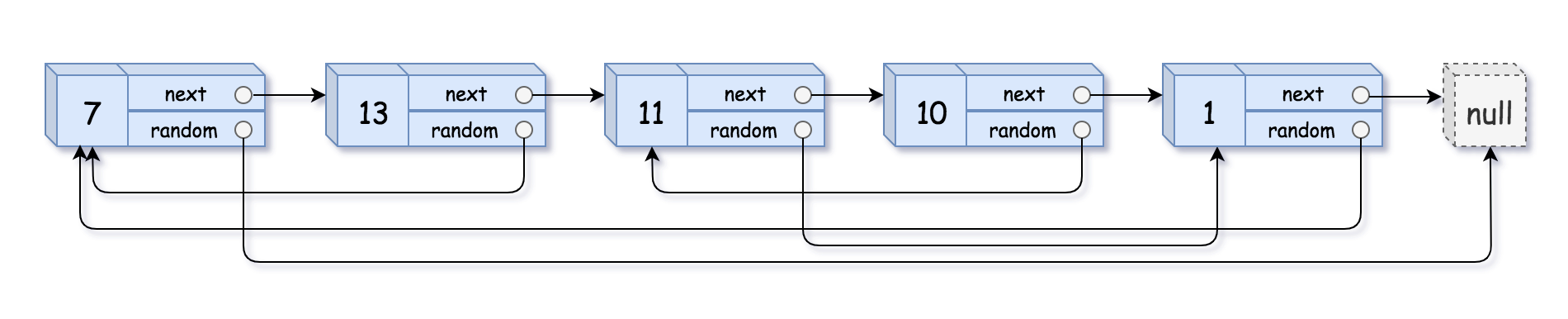


解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第32题。
61. 反转链表 II(中等)
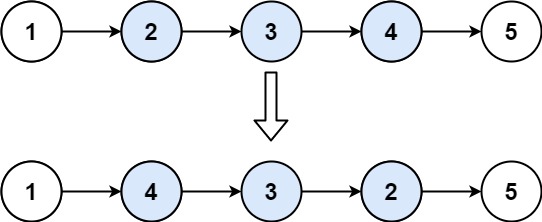
题目描述
给你单链表的头指针
head和两个整数left和right,其中left <= right。请你反转从位置left到位置right的链表节点,返回 反转后的链表 。示例 1:
输入:head = [1,2,3,4,5], left = 2, right = 4 输出:[1,4,3,2,5]示例 2:输入: head = 5, left = 1, right = 1 输出:5
提示:
- 链表中节点数目为
n1 <= n <= 500-500 <= Node.val <= 5001 <= left <= right <= n进阶: 你可以使用一趟扫描完成反转吗?
解题思路
可见链表知识及编程练习总结中第20题。
62.K 个一组翻转链表 (困难)
题目描述
给你链表的头节点
head,每k个节点一组进行翻转,请你返回修改后的链表。
k是一个正整数,它的值小于或等于链表的长度。如果节点总数不是k的整数倍,那么请将最后剩余的节点保持原有顺序。你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
输入:head = [1,2,3,4,5], k = 2 输出:[2,1,4,3,5]示例 2:
输入:head = [1,2,3,4,5], k = 3 输出:[3,2,1,4,5]提示:
- 链表中的节点数目为
n1 <= k <= n <= 50000 <= Node.val <= 1000进阶: 你可以设计一个只用
O(1)额外内存空间的算法解决此问题吗?


解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第31题。
也可见链表知识及编程练习总结中第10题。
63.删除链表的倒数第 N 个结点(中等)
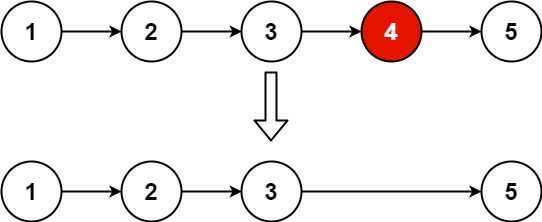
题目描述
给你一个链表,删除链表的倒数第
n个结点,并且返回链表的头结点。示例 1:
输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]示例 2:输入: head = 1, n = 1 输出:\[\]
示例 3:输入: head = 1,2, n = 1 输出:1
提示:
- 链表中结点的数目为
sz1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz**进阶:**你能尝试使用一趟扫描实现吗?
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第29题。
也可见链表知识及编程练习总结中第4题。
64. 删除排序链表中的重复元素 II(中等)
题目描述
给定一个已排序的链表的头
head, 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。示例 1:
输入:head = [1,2,3,3,4,4,5] 输出:[1,2,5]示例 2:
输入:head = [1,1,1,2,3] 输出:[2,3]提示:
- 链表中节点数目在范围
[0, 300]内-100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列


解题思路
可见链表知识及编程练习总结中第9题。
65. 旋转链表(中等)
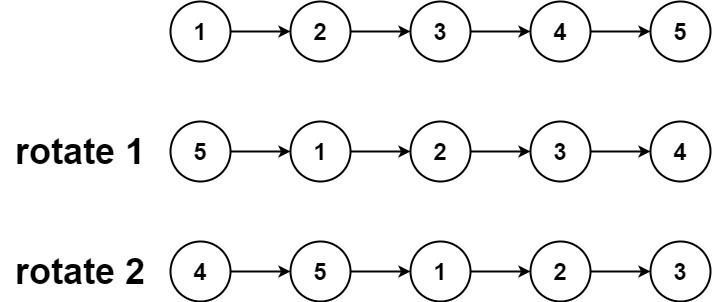
题目描述
给你一个链表的头节点
head,旋转链表,将链表每个节点向右移动k个位置。示例 1:
输入:head = [1,2,3,4,5], k = 2 输出:[4,5,1,2,3]示例 2:
输入:head = [0,1,2], k = 4 输出:[2,0,1]提示:
- 链表中节点的数目在范围
[0, 500]内-100 <= Node.val <= 1000 <= k <= 2 * 109

解题思路
可见链表知识及编程练习总结中第11题。
66. 分隔链表(中等)
题目描述
给你一个链表的头节点
head和一个特定值x,请你对链表进行分隔,使得所有 小于x的节点都出现在 大于或等于x的节点之前。你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
输入:head = [1,4,3,2,5,2], x = 3 输出:[1,2,2,4,3,5]示例 2:输入: head = 2,1, x = 2 输出:1,2
提示:
- 链表中节点的数目在范围
[0, 200]内-100 <= Node.val <= 100-200 <= x <= 200
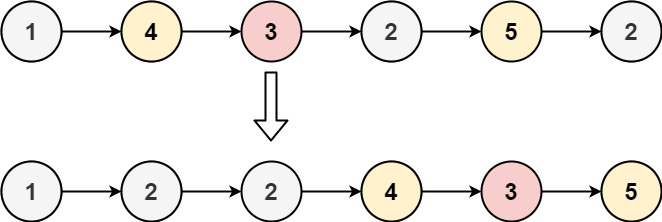
解题思路
可见链表知识及编程练习总结中第12题。
67.LRU 缓存(中等)
题目描述
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现
LRUCache类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。函数
get和put必须以O(1)的平均时间复杂度运行。示例:
输入 ["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"] [[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]] 输出 [null, null, null, 1, null, -1, null, -1, 3, 4] 解释 LRUCache lRUCache = new LRUCache(2); lRUCache.put(1, 1); // 缓存是 {1=1} lRUCache.put(2, 2); // 缓存是 {1=1, 2=2} lRUCache.get(1); // 返回 1 lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3} lRUCache.get(2); // 返回 -1 (未找到) lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3} lRUCache.get(1); // 返回 -1 (未找到) lRUCache.get(3); // 返回 3 lRUCache.get(4); // 返回 4提示:
1 <= capacity <= 30000 <= key <= 100000 <= value <= 105- 最多调用
2 * 105次get和put
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第35题。
也可见散列表相关知识及编程练习总结_散列函数 情景题-CSDN博客中第7题。
加强版可见聚焦新版综合编程能力面试考查汇总_关于编程有什么问题可以提问-CSDN博客中第7题。
九、二叉树
68.二叉树的最大深度(简单)
题目描述
给定一个二叉树
root,返回其最大深度。二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
示例 1:
输入:root = [3,9,20,null,null,15,7] 输出:3示例 2:输入: root = 1,null,2 **输出:**2
提示:
- 树中节点的数量在
[0, 104]区间内。-100 <= Node.val <= 100

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第37题。
也可见树相关知识及编程练习总结_树编程-CSDN博客中第2题。
69. 相同的树(简单)
题目描述
给你两棵二叉树的根节点
p和q,编写一个函数来检验这两棵树是否相同。如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1:
输入:p = [1,2,3], q = [1,2,3] 输出:true示例 2:
输入:p = [1,2], q = [1,null,2] 输出:false示例 3:
输入:p = [1,2,1], q = [1,1,2] 输出:false提示:
- 两棵树上的节点数目都在范围
[0, 100]内-104 <= Node.val <= 104


解题思路
要判断两棵二叉树是否相同,我们可以使用递归的方法逐节点进行比较:
- 基础情况 :
- 如果两个节点都为
null,则它们相同,返回true。 - 如果其中一个节点为
null而另一个不为null,则它们不同,返回false。 - 如果两个节点的值不相同,也返回
false。
- 如果两个节点都为
- 递归判断子树 :
- 递归比较左子树和右子树是否相同。
- 如果左子树和右子树都相同,则当前子树相同。
复杂度分析
-
时间复杂度:每个节点在递归时只访问一次,因此时间复杂度为 O(n),其中 n 是树中的节点数。
-
空间复杂度:最坏情况下(即树是链状的),递归栈的深度为 O(n),所以空间复杂度也是 O(n)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
/**
* @program: zyfboot-javabasic
* @description: 相同的树
* @author: zhangyanfeng
* @create: 2024-08-25 13:40
**/
public class SameTree {
public boolean isSameTree(TreeNode p, TreeNode q) {
// 如果两个节点都为 null,则两棵树相同
if (p == null && q == null) {
return true;
}
// 如果其中一个节点为 null 或者两个节点的值不同,则两棵树不相同
if (p == null || q == null || p.val != q.val) {
return false;
}
// 递归判断左右子树是否相同
return isSameTree(p.left, q.left) && isSameTree(p.right, q.right);
}
public static void main(String[] args) {
SameTree sol = new SameTree();
// 示例 1
TreeNode p1 = new TreeNode(1);
p1.left = new TreeNode(2);
p1.right = new TreeNode(3);
TreeNode q1 = new TreeNode(1);
q1.left = new TreeNode(2);
q1.right = new TreeNode(3);
// 示例 2
TreeNode p2 = new TreeNode(1);
p2.left = new TreeNode(2);
TreeNode q2 = new TreeNode(1);
q2.right = new TreeNode(2);
// 示例 3
TreeNode p3 = new TreeNode(1);
p3.left = new TreeNode(2);
p3.right = new TreeNode(1);
TreeNode q3 = new TreeNode(1);
q3.left = new TreeNode(1);
q3.right = new TreeNode(2);
System.out.println(sol.isSameTree(p1, q1)); // 输出: true
System.out.println(sol.isSameTree(p2, q2)); // 输出: false
System.out.println(sol.isSameTree(p3, q3)); // 输出: false
}
}70.翻转二叉树(简单)
题目描述
给你一棵二叉树的根节点
root,翻转这棵二叉树,并返回其根节点。示例 1:
输入:root = [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1]示例 2:
输入:root = [2,1,3] 输出:[2,3,1]示例 3:输入: root = \[\] 输出:\[\]
提示:
- 树中节点数目范围在
[0, 100]内-100 <= Node.val <= 100


解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第38题。
也可见树相关知识及编程练习总结_树编程-CSDN博客中第12题。
71.对称二叉树(简单)
题目描述
给你一个二叉树的根节点
root, 检查它是否轴对称。示例 1:
输入:root = [1,2,2,3,4,4,3] 输出:true示例 2:
输入:root = [1,2,2,null,3,null,3] 输出:false提示:
- 树中节点数目在范围
[1, 1000]内-100 <= Node.val <= 100**进阶:**你可以运用递归和迭代两种方法解决这个问题吗?
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第39题。
也可见树相关知识及编程练习总结_树编程-CSDN博客中第4题。
72.从前序与中序遍历序列构造二叉树(中等)
题目描述
给定两个整数数组
preorder和inorder,其中preorder是二叉树的先序遍历 ,inorder是同一棵树的中序遍历,请构造二叉树并返回其根节点。示例 1:
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7] 输出: [3,9,20,null,null,15,7]示例 2:输入: preorder = -1, inorder = -1 输出: -1
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第47题。
也可见树相关知识及编程练习总结_树编程-CSDN博客中第16题。
73. 从中序与后序遍历序列构造二叉树(中等)
题目描述
给定两个整数数组
inorder和postorder,其中inorder是二叉树的中序遍历,postorder是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。示例 1:
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3] 输出:[3,9,20,null,null,15,7]示例 2:输入: inorder = -1, postorder = -1 输出:-1
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历

解题思路
要根据中序遍历(inorder)和后序遍历(postorder)构造二叉树,可以利用后序遍历的特性:后序遍历的最后一个元素是树的根节点。
-
从后序遍历中找到根节点:后序遍历的最后一个元素是当前子树的根节点。
-
在中序遍历中定位根节点:在中序遍历中找到根节点的位置,这样可以将中序遍历划分为左子树和右子树。
-
递归构造左右子树:
递归地在左子树的中序和后序遍历中构造左子树。递归地在右子树的中序和后序遍历中构造右子树。
-
构造并返回根节点:将左右子树连接到根节点上,返回构造的树。
复杂度分析
- 时间复杂度:构建二叉树的时间复杂度为 O(n),其中 n 是树中的节点数。每个节点只处理一次。
- 空间复杂度:由于使用了递归,空间复杂度取决于递归调用的深度,即 O(h),其中 h 是树的高度。最坏情况下,树是线性的,此时空间复杂度为 O(n)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.HashMap;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 从中序与后序遍历序列构造二叉树
* @author: zhangyanfeng
* @create: 2024-08-25 13:50
**/
public class BuildTree {
private Map<Integer, Integer> inorderIndexMap;
public TreeNode buildTree(int[] inorder, int[] postorder) {
int n = inorder.length;
// 创建一个哈希映射以存储中序遍历中每个值的索引
inorderIndexMap = new HashMap<>();
for (int i = 0; i < n; i++) {
inorderIndexMap.put(inorder[i], i);
}
// 从后序遍历和中序遍历构建二叉树
return buildTreeHelper(postorder, 0, n - 1, 0, n - 1);
}
private TreeNode buildTreeHelper(int[] postorder, int postStart, int postEnd, int inStart, int inEnd) {
// 如果索引无效,返回 null
if (postStart > postEnd || inStart > inEnd) {
return null;
}
// 后序遍历的最后一个节点是当前子树的根节点
int rootVal = postorder[postEnd];
TreeNode root = new TreeNode(rootVal);
// 在中序遍历中找到根节点的位置
int inRootIndex = inorderIndexMap.get(rootVal);
int leftSubtreeSize = inRootIndex - inStart;
// 递归构建左子树
root.left = buildTreeHelper(postorder, postStart, postStart + leftSubtreeSize - 1, inStart, inRootIndex - 1);
// 递归构建右子树
root.right = buildTreeHelper(postorder, postStart + leftSubtreeSize, postEnd - 1, inRootIndex + 1, inEnd);
return root;
}
public static void main(String[] args) {
BuildTree sol = new BuildTree();
int[] inorder1 = {9, 3, 15, 20, 7};
int[] postorder1 = {9, 15, 7, 20, 3};
TreeNode root1 = sol.buildTree(inorder1, postorder1);
printPreorder(root1); // 输出前序遍历结果验证树的构造
}
private static void printPreorder(TreeNode node) {
if (node != null) {
System.out.print(node.val + " ");
printPreorder(node.left);
printPreorder(node.right);
}
}
}74. 填充每个节点的下一个右侧节点指针 II(中等)
题目描述
给定一个二叉树:
struct Node { int val; Node *left; Node *right; Node *next; }填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为
NULL。初始状态下,所有 next 指针都被设置为
NULL。示例 1:
输入:root = [1,2,3,4,5,null,7] 输出:[1,#,2,3,#,4,5,7,#] 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化输出按层序遍历顺序(由 next 指针连接),'#' 表示每层的末尾。示例 2:输入: root = \[\] 输出:\[\]
提示:
- 树中的节点数在范围
[0, 6000]内-100 <= Node.val <= 100进阶:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序的隐式栈空间不计入额外空间复杂度。

解题思路
采了逐层遍历二叉树的方法,不使用额外的空间,直接利用二叉树的 next 指针来遍历每一层。通过维护指向每一层最左侧节点的 start 指针,遍历该层节点,并同时建立下一层节点之间的 next 连接。具体步骤如下:
-
初始化指针 :
start:指向当前层的最左节点。last:指向当前层中已连接的最后一个节点。nextStart:指向下一层最左节点。 -
逐层处理:
对当前层的每个节点,分别处理其左子节点和右子节点,建立
next连接。更新nextStart,以确保下一层遍历从该层的第一个节点开始。
复杂度分析
- 时间复杂度:O(n),其中 n 为二叉树中的节点总数。每个节点仅访问一次。
- 空间复杂度:O(1),使用了常量级别的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
/**
* @program: zyfboot-javabasic
* @description: 填充每个节点的下一个右侧节点指针 II
* @author: zhangyanfeng
* @create: 2024-08-25 13:57
**/
public class Connect {
Node last = null; // 当前层已连接的最后一个节点
Node nextStart = null; // 下一层最左侧的起始节点
public Node connect(Node root) {
if (root == null) {
return null;
}
Node start = root; // 从根节点开始
while (start != null) {
last = null;
nextStart = null;
for (Node p = start; p != null; p = p.next) {
if (p.left != null) {
handle(p.left); // 处理左子节点
}
if (p.right != null) {
handle(p.right); // 处理右子节点
}
}
start = nextStart; // 转向下一层的最左节点
}
return root;
}
// 处理每个节点,连接next指针
public void handle(Node p) {
if (last != null) {
last.next = p; // 将上一个节点的next指向当前节点
}
if (nextStart == null) {
nextStart = p; // 记录下一层的起始节点
}
last = p; // 更新last为当前节点
}
public static void main(String[] args) {
Connect sol = new Connect();
// 示例测试
Node root = new Node(1);
root.left = new Node(2);
root.right = new Node(3);
root.left.left = new Node(4);
root.left.right = new Node(5);
root.right.right = new Node(7);
sol.connect(root);
printLevels(root);
}
// 辅助函数:按层打印节点的 next 连接结果
private static void printLevels(Node root) {
Node levelStart = root;
while (levelStart != null) {
Node current = levelStart;
while (current != null) {
System.out.print(current.val + " ");
current = current.next;
}
System.out.println("#");
levelStart = levelStart.left;
}
}
static class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, Node _left, Node _right, Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
}
}75.二叉树展开为链表(中等)
题目描述
给你二叉树的根结点
root,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。- 展开后的单链表应该与二叉树 先序遍历 顺序相同。
示例 1:
输入:root = [1,2,5,3,4,null,6] 输出:[1,null,2,null,3,null,4,null,5,null,6]示例 2:输入: root = \[\] 输出:\[\]
示例 3:输入: root = 0 输出:0
提示:
- 树中结点数在范围
[0, 2000]内-100 <= Node.val <= 100进阶: 你可以使用原地算法(
O(1)额外空间)展开这棵树吗?

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第46题。
76. 路径总和(简单)
题目描述
给你二叉树的根节点
root和一个表示目标和的整数targetSum。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和targetSum。如果存在,返回true;否则,返回false。叶子节点 是指没有子节点的节点。
示例 1:
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22 输出:true 解释:等于目标和的根节点到叶节点路径如上图所示。示例 2:
输入:root = [1,2,3], targetSum = 5 输出:false 解释:树中存在两条根节点到叶子节点的路径: (1 --> 2): 和为 3 (1 --> 3): 和为 4 不存在 sum = 5 的根节点到叶子节点的路径。示例 3:输入: root = \[\], targetSum = 0 输出: false **解释:**由于树是空的,所以不存在根节点到叶子节点的路径。
提示:
- 树中节点的数目在范围
[0, 5000]内-1000 <= Node.val <= 1000-1000 <= targetSum <= 1000


解题思路
也可见树相关知识及编程练习总结_树编程-CSDN博客中第7题。
要判断二叉树中是否存在一条从根节点到叶子节点的路径,使得路径上所有节点值的和等于给定的 targetSum,可以采用递归或深度优先搜索(DFS)的方式。具体步骤:
- 递归遍历 :从根节点开始,递归遍历每个节点的左右子树,同时将当前节点的值从
targetSum中减去。 - 叶子节点判断 :当到达叶子节点时,检查剩余的
targetSum是否等于该叶子节点的值。如果是,则找到了符合条件的路径;否则,继续在左右子树中查找。 - 边界条件 :如果节点为空,则直接返回
false;如果遍历到叶子节点并且targetSum恰好等于当前节点值,返回true。
复杂度分析
- 时间复杂度:O(n),其中 n 是树中的节点数。最坏情况下,需要遍历每个节点一次。
- 空间复杂度:O(h),其中 h 是树的高度。空间主要消耗在递归调用栈上,最坏情况下(例如完全不平衡树),递归深度等于树的高度。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
/**
* @program: zyfboot-javabasic
* @description: 路径总和
* @author: zhangyanfeng
* @create: 2024-08-25 14:07
**/
public class HasPathSum {
public boolean hasPathSum(TreeNode root, int targetSum) {
if (root == null) {
return false; // 如果当前节点为空,直接返回 false
}
// 如果当前节点是叶子节点,判断路径和是否等于 targetSum
if (root.left == null && root.right == null) {
return root.val == targetSum;
}
// 递归检查左右子树是否存在符合条件的路径
int remainingSum = targetSum - root.val;
return hasPathSum(root.left, remainingSum) || hasPathSum(root.right, remainingSum);
}
public static void main(String[] args) {
HasPathSum sol = new HasPathSum();
// 示例 1 测试
TreeNode root1 = new TreeNode(5);
root1.left = new TreeNode(4);
root1.right = new TreeNode(8);
root1.left.left = new TreeNode(11);
root1.left.left.left = new TreeNode(7);
root1.left.left.right = new TreeNode(2);
root1.right.left = new TreeNode(13);
root1.right.right = new TreeNode(4);
root1.right.right.right = new TreeNode(1);
System.out.println(sol.hasPathSum(root1, 22)); // 输出: true
// 示例 2 测试
TreeNode root2 = new TreeNode(1);
root2.left = new TreeNode(2);
root2.right = new TreeNode(3);
System.out.println(sol.hasPathSum(root2, 5)); // 输出: false
// 示例 3 测试
TreeNode root3 = null;
System.out.println(sol.hasPathSum(root3, 0)); // 输出: false
}
}77. 求根节点到叶节点数字之和(中等)
题目描述
给你一个二叉树的根节点
root,树中每个节点都存放有一个0到9之间的数字。每条从根节点到叶节点的路径都代表一个数字:
- 例如,从根节点到叶节点的路径
1 -> 2 -> 3表示数字123。计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
示例 1:
输入:root = [1,2,3] 输出:25 解释:从根到叶子节点路径 1->2 代表数字 12 从根到叶子节点路径 1->3 代表数字 13 因此,数字总和 = 12 + 13 = 25示例 2:
输入:root = [4,9,0,5,1] 输出:1026 解释: 从根到叶子节点路径 4->9->5 代表数字 495. 从根到叶子节点路径 4->9->1 代表数字 491 从根到叶子节点路径 4->0 代表数字 40 因此,数字总和 = 495 + 491 + 40 = 1026提示:
- 树中节点的数目在范围
[1, 1000]内0 <= Node.val <= 9- 树的深度不超过
10


解题思路
可见树相关知识及编程练习总结_树编程-CSDN博客中第18题。
78. 二叉树中的最大路径和 (困难)
题目描述
二叉树中的路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径至少包含一个节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点
root,返回其 最大路径和 。示例 1:
输入:root = [1,2,3] 输出:6 解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6示例 2:
输入:root = [-10,9,20,null,null,15,7] 输出:42 解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42提示:
- 树中节点数目范围是
[1, 3 * 104]-1000 <= Node.val <= 1000

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第50题。
79. 二叉搜索树迭代器(中等)
题目描述
实现一个二叉搜索树迭代器类
BSTIterator,表示一个按中序遍历二叉搜索树(BST)的迭代器:
BSTIterator(TreeNode root)初始化BSTIterator类的一个对象。BST 的根节点root会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。boolean hasNext()如果向指针右侧遍历存在数字,则返回true;否则返回false。int next()将指针向右移动,然后返回指针处的数字。注意,指针初始化为一个不存在于 BST 中的数字,所以对
next()的首次调用将返回 BST 中的最小元素。你可以假设
next()调用总是有效的,也就是说,当调用next()时,BST 的中序遍历中至少存在一个下一个数字。示例:
输入 ["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"] [[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []] 输出 [null, 3, 7, true, 9, true, 15, true, 20, false] 解释 BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]); bSTIterator.next(); // 返回 3 bSTIterator.next(); // 返回 7 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 9 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 15 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 20 bSTIterator.hasNext(); // 返回 False提示:
- 树中节点的数目在范围
[1, 105]内0 <= Node.val <= 106- 最多调用
105次hasNext和next操作进阶:
- 你可以设计一个满足下述条件的解决方案吗?
next()和hasNext()操作均摊时间复杂度为O(1),并使用O(h)内存。其中h是树的高度。

解题思路
二叉搜索树迭代器 (BSTIterator) 的目标是实现按中序遍历(从小到大)逐步返回二叉搜索树中的节点值。由于二叉搜索树(BST)的性质,中序遍历即为有序的节点值排列。
要实现一个高效的迭代器,考虑以下几点:
- 存储结构:可以使用栈来存储遍历路径上的节点,确保能够按顺序访问。
- 迭代过程 :每次调用
next()时,从栈中弹出一个节点,并将该节点的右子树的所有左子节点压栈,确保下次访问的是当前节点的后继。 - 时间复杂度 :
next()和hasNext()操作的均摊时间复杂度应为 O(1),因为每个节点仅进栈和出栈一次。 - 空间复杂度:需要 O(h) 的空间来存储栈,其中 h 是树的高度。
复杂度分析
- 时间复杂度 :
next(): O(1) 均摊时间复杂度。hasNext(): O(1)。
- 空间复杂度:O(h),其中 h 是树的高度。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.Stack;
/**
* @program: zyfboot-javabasic
* @description: 二叉搜索树迭代器
* @author: zhangyanfeng
* @create: 2024-08-25 14:24
**/
public class BSTIterator {
private Stack<TreeNode> stack;
// 初始化迭代器,压入左侧路径上的所有节点
public BSTIterator(TreeNode root) {
stack = new Stack<>();
pushLeftBranch(root);
}
// 检查是否有下一个节点
public boolean hasNext() {
return !stack.isEmpty();
}
// 返回下一个最小的节点值
public int next() {
TreeNode node = stack.pop(); // 弹出栈顶节点
int result = node.val;
pushLeftBranch(node.right); // 如果有右子树,将右子树的左侧路径压入栈中
return result;
}
// 将从当前节点开始的左侧路径上的所有节点压栈
private void pushLeftBranch(TreeNode node) {
while (node != null) {
stack.push(node); // 压入当前节点
node = node.left; // 向左移动
}
}
}80. 完全二叉树的节点个数(简单)
题目描述
给你一棵完全二叉树 的根节点
root,求出该树的节点个数。完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第
h层,则该层包含1~ 2h个节点。示例 1:
输入:root = [1,2,3,4,5,6] 输出:6示例 2:输入: root = \[\] **输出:**0
示例 3:输入: root = 1 **输出:**1
提示:
- 树中节点的数目范围是
[0, 5 * 104]0 <= Node.val <= 5 * 104- 题目数据保证输入的树是 完全二叉树
进阶: 遍历树来统计节点是一种时间复杂度为
O(n)的简单解决方案。你可以设计一个更快的算法吗?

解题思路
完全二叉树的定义是,除了最后一层之外,其他层都是满的。如果我们能够快速计算某个子树的高度,并且通过这种高度来判断该子树是否是完全的,那么我们就可以快速地计算出该子树的节点数量。
-
计算高度:
左子树的高度
leftHeight从根节点沿左子树路径一直走到叶子节点。右子树的高度rightHeight从根节点沿右子树路径一直走到叶子节点。 -
判断完全性:
如果
leftHeight == rightHeight,说明这个树是满的二叉树,高度为h,节点总数为2^h - 1。如果leftHeight != rightHeight,说明这个树的最后一层没有填满,此时我们需要递归地计算左右子树的节点数。 -
递归:
如果是满的子树,直接返回节点数。否则,递归地对左右子树求解,最终得到整个树的节点总数。
复杂度分析
由于高度计算是O(log n),而我们每次递归会减少一层,所以整体时间复杂度为O(log n * log n)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
/**
* @program: zyfboot-javabasic
* @description: 完全二叉树的节点个数
* @author: zhangyanfeng
* @create: 2024-08-25 14:29
**/
public class CountNodes {
public int countNodes(TreeNode root) {
// 如果根节点为空,直接返回0
if (root == null) {
return 0;
}
// 计算左子树高度
int leftHeight = getHeight(root.left);
// 计算右子树高度
int rightHeight = getHeight(root.right);
// 如果左子树高度等于右子树高度,说明左子树是满的
if (leftHeight == rightHeight) {
// 直接返回左子树节点数 + 右子树递归节点数 + 根节点1
return (1 << leftHeight) + countNodes(root.right);
} else {
// 否则,右子树是满的
// 直接返回右子树节点数 + 左子树递归节点数 + 根节点1
return (1 << rightHeight) + countNodes(root.left);
}
}
// 辅助函数,计算树的高度
private int getHeight(TreeNode root) {
int height = 0;
while (root != null) {
height++;
root = root.left;
}
return height;
}
}81.二叉树的最近公共祖先(中等)
题目描述
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:"对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。"
示例 1:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。示例 2:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出:5 解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。示例 3:输入: root = 1,2, p = 1, q = 2 **输出:**1
提示:
- 树中节点数目在范围
[2, 105]内。-109 <= Node.val <= 109- 所有
Node.val互不相同。p != qp和q均存在于给定的二叉树中。


解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第49题。
也可见树相关知识及编程练习总结_树编程-CSDN博客中第5题。
**十、**二叉树层次遍历
82.二叉树的右视图(中等)
题目描述
给定一个二叉树的 根节点
root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。示例 1:
输入: [1,2,3,null,5,null,4] 输出: [1,3,4]示例 2:输入: 1,null,3 输出: 1,3
示例 3:输入: \[\] 输出: \[\]
提示:
- 二叉树的节点个数的范围是
[0,100]-100 <= Node.val <= 100
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第45题。
也可见LeetCode 精选 75 回顾-CSDN博客中的第39题。
也可见树相关知识及编程练习总结_树编程-CSDN博客中第5题。
83. 二叉树的层平均值(简单)
题目描述
给定一个非空二叉树的根节点
root, 以数组的形式返回每一层节点的平均值。与实际答案相差10-5以内的答案可以被接受。示例 1:
输入:root = [3,9,20,null,null,15,7] 输出:[3.00000,14.50000,11.00000] 解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。 因此返回 [3, 14.5, 11] 。示例 2:
输入:root = [3,9,20,15,7] 输出:[3.00000,14.50000,11.00000]提示:
- 树中节点数量在
[1, 104]范围内-231 <= Node.val <= 231 - 1


解题思路
可见树相关知识及编程练习总结_树编程-CSDN博客中第11题。
84.二叉树的层序遍历(中等)
题目描述
给你二叉树的根节点
root,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。示例 1:
输入:root = [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]示例 2:输入: root = 1 输出:\[1]
示例 3:输入: root = \[\] 输出:\[\]
提示:
- 树中节点数目在范围
[0, 2000]内-1000 <= Node.val <= 1000

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第41题。
也可见树相关知识及编程练习总结_树编程-CSDN博客中第1题。
85. 二叉树的锯齿形层序遍历(中等)
题目描述
给你二叉树的根节点
root,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。示例 1:
输入:root = [3,9,20,null,null,15,7] 输出:[[3],[20,9],[15,7]]示例 2:输入: root = 1 输出:\[1]
示例 3:输入: root = \[\] 输出:\[\]
提示:
- 树中节点数目在范围
[0, 2000]内-100 <= Node.val <= 100
解题思路
锯齿形层序遍历(Zigzag Level Order Traversal)是二叉树的广度优先搜索(BFS)的变形。我们可以用一个队列来实现层序遍历,然后通过一个标志位来控制节点的访问顺序是从左到右还是从右到左。具体步骤如下:
- 使用队列进行层序遍历,将根节点加入队列。
- 初始化一个布尔变量
leftToRight表示当前层是否从左往右遍历。 - 对于每一层,先获取当前队列的大小
levelSize(表示这一层的节点数)。 - 初始化一个双端队列
Deque<Integer> level来存储当前层的结果。如果是从左到右遍历,则直接在level的尾部添加节点值;如果是从右到左遍历,则在level的头部添加节点值。 - 将当前层的节点值添加到
result列表中,并切换leftToRight的值。 - 重复上述步骤,直到队列为空。
复杂度分析
- 时间复杂度: O(n),其中 n 是二叉树的节点数。我们需要遍历每个节点一次。
- 空间复杂度: O(n),最坏情况下队列中需要存储 n/2 个节点。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.*;
/**
* @program: zyfboot-javabasic
* @description: 二叉树的锯齿形层序遍历
* @author: zhangyanfeng
* @create: 2024-08-25 14:44
**/
public class ZigzagLevelOrder {
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
// 定义结果列表
List<List<Integer>> result = new ArrayList<>();
// 如果树为空,直接返回空列表
if (root == null) {
return result;
}
// 初始化队列进行层序遍历
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
// 标志位,初始为从左到右
boolean leftToRight = true;
while (!queue.isEmpty()) {
// 当前层的节点数量
int levelSize = queue.size();
// 使用双端队列来存储当前层的节点值
Deque<Integer> level = new LinkedList<>();
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll();
if (leftToRight) {
// 从左到右,将节点值添加到队列的尾部
level.offerLast(node.val);
} else {
// 从右到左,将节点值添加到队列的头部
level.offerFirst(node.val);
}
// 将当前节点的左右子节点加入队列
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
// 将当前层的结果添加到结果列表
result.add(new LinkedList<>(level));
// 切换遍历方向
leftToRight = !leftToRight;
}
return result;
}
}十一、二叉搜索树
86. 二叉搜索树的最小绝对差(简单)
题目描述
给你一个二叉搜索树的根节点
root,返回 树中任意两不同节点值之间的最小差值 。差值是一个正数,其数值等于两值之差的绝对值。
示例 1:
输入:root = [4,2,6,1,3] 输出:1示例 2:
输入:root = [1,0,48,null,null,12,49] 输出:1提示:
- 树中节点的数目范围是
[2, 104]0 <= Node.val <= 105注意: 本题与 783 . - 力扣(LeetCode) 相同


解题思路
二叉搜索树(BST)具有一个重要性质:对于任意节点,其左子树的所有节点值都小于该节点值,右子树的所有节点值都大于该节点值。因此,BST 的中序遍历结果是一个递增的有序序列。
基于此性质,求任意两不同节点值之间的最小差值,可以通过以下步骤完成:
- 中序遍历:对 BST 进行中序遍历,得到一个有序的节点值列表。
- 计算最小差值:在有序列表中,任意两个相邻元素的差值是可能的最小差值。遍历这个列表,计算所有相邻元素的差值,并记录其中的最小值。
复杂度分析
- 时间复杂度: O(n),其中 n 是树中的节点数。中序遍历需要访问每个节点一次,后续的最小差值计算也是 O(n)。
- 空间复杂度: O(n),用于存储中序遍历的节点值列表。在最优的情况下,可以使用 O(h) 的空间,其中 h 是树的高度。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
/**
* @program: zyfboot-javabasic
* @description: 二叉搜索树的最小绝对差
* @author: zhangyanfeng
* @create: 2024-08-25 14:50
**/
public class MinDiffInBST {
// 记录上一个节点的值,初始为极小值
private Integer prev = null;
// 记录最小差值,初始为最大值
private int minDiff = Integer.MAX_VALUE;
public int minDiffInBST(TreeNode root) {
// 调用中序遍历的辅助函数
inOrder(root);
return minDiff;
}
private void inOrder(TreeNode node) {
if (node == null) {
return;
}
// 中序遍历左子树
inOrder(node.left);
// 处理当前节点
if (prev != null) {
// 计算当前节点与上一个节点值的差,并更新最小差值
minDiff = Math.min(minDiff, node.val - prev);
}
// 更新上一个节点值
prev = node.val;
// 中序遍历右子树
inOrder(node.right);
}
}87.二叉搜索树中第 K 小的元素(中等)
题目描述
给定一个二叉搜索树的根节点
root,和一个整数k,请你设计一个算法查找其中第k小的元素(从 1 开始计数)。示例 1:
输入:root = [3,1,4,null,2], k = 1 输出:1示例 2:
输入:root = [5,3,6,2,4,null,null,1], k = 3 输出:3提示:
- 树中的节点数为
n。1 <= k <= n <= 1040 <= Node.val <= 104进阶: 如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第
k小的值,你将如何优化算法?


解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第44题。
88.验证二叉搜索树(中等)
题目描述
给你一个二叉树的根节点
root,判断其是否是一个有效的二叉搜索树。有效 二叉搜索树定义如下:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:root = [2,1,3] 输出:true示例 2:
输入:root = [5,1,4,null,null,3,6] 输出:false 解释:根节点的值是 5 ,但是右子节点的值是 4 。提示:
- 树中节点数目范围在
[1, 104]内-231 <= Node.val <= 231 - 1


解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第43题。
十二、图
89.岛屿数量(中等)
题目描述
给你一个由
'1'(陆地)和'0'(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [ ["1","1","1","1","0"], ["1","1","0","1","0"], ["1","1","0","0","0"], ["0","0","0","0","0"] ] 输出:1示例 2:
输入:grid = [ ["1","1","0","0","0"], ["1","1","0","0","0"], ["0","0","1","0","0"], ["0","0","0","1","1"] ] 输出:3提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第51题。
也可见图论总结与编程练习_编程 图论-CSDN博客中的第3题。
90. 被围绕的区域(中等)
题目描述
给你一个
m x n的矩阵board,由若干字符'X'和'O'组成,捕获 所有 被围绕的区域:
- **连接:**一个单元格与水平或垂直方向上相邻的单元格连接。
- 区域:连接所有
'O'的单元格来形成一个区域。- 围绕: 如果您可以用
'X'单元格 连接这个区域 ,并且区域中没有任何单元格位于board边缘,则该区域被'X'单元格围绕。通过将输入矩阵
board中的所有'O'替换为'X'来 捕获被围绕的区域。示例 1:
**输入:**board = \["X","X","X","X","X","O","O","X","X","X","O","X","X","O","X","X"]
输出:\["X","X","X","X","X","X","X","X","X","X","X","X","X","O","X","X"]
解释:
在上图中,底部的区域没有被捕获,因为它在 board 的边缘并且不能被围绕。
**示例 2:输入:**board = \["X"]
输出:\["X"]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 200board[i][j]为'X'或'O'
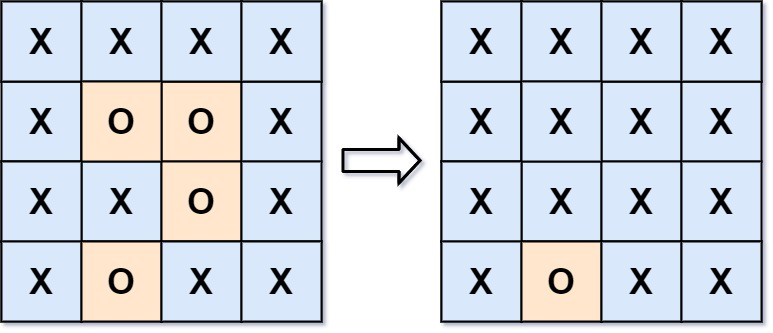
解题思路
要解决这个问题,我们可以使用以下步骤:
-
标记边缘的 'O' : 首先遍历矩阵的边缘(上下左右四条边),对所有边缘的 'O' 进行深度优先搜索(DFS)或广度优先搜索(BFS),将所有能够连接到边缘的 'O' 标记为特殊字符(例如
'#')。这些标记的 'O' 表示它们不被完全围绕。 -
替换内部的 'O': 遍历整个矩阵,将所有未被标记的 'O' 替换为 'X',因为这些 'O' 是被完全围绕的区域。
-
恢复边缘的 'O' : 将之前标记的
'#'恢复为 'O',以还原这些区域的原始状态。
复杂度分析
-
时间复杂度: O(m * n),其中 m 和 n 分别是矩阵的行数和列数。我们需要遍历矩阵的每个位置多次(标记、替换、恢复),每个位置操作的时间复杂度为 O(1)。
-
空间复杂度: O(m * n),主要用于存储矩阵和标记的临时空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.graph;
/**
* @program: zyfboot-javabasic
* @description: 被围绕的区域
* @author: zhangyanfeng
* @create: 2024-08-25 14:58
**/
public class Solve {
public void solve(char[][] board) {
if (board == null || board.length == 0 || board[0].length == 0) {
return;
}
int m = board.length;
int n = board[0].length;
// 使用 DFS 标记边缘的 'O'
for (int i = 0; i < m; i++) {
if (board[i][0] == 'O') {
dfs(board, i, 0);
}
if (board[i][n - 1] == 'O') {
dfs(board, i, n - 1);
}
}
for (int j = 0; j < n; j++) {
if (board[0][j] == 'O') {
dfs(board, 0, j);
}
if (board[m - 1][j] == 'O') {
dfs(board, m - 1, j);
}
}
// 将内部的 'O' 替换为 'X',恢复边缘的 'O'
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == 'O') {
board[i][j] = 'X';
} else if (board[i][j] == '#') {
board[i][j] = 'O';
}
}
}
}
private void dfs(char[][] board, int i, int j) {
int m = board.length;
int n = board[0].length;
if (i < 0 || i >= m || j < 0 || j >= n || board[i][j] != 'O') {
return;
}
// 标记为 '#'
board[i][j] = '#';
// 递归四个方向
dfs(board, i - 1, j);
dfs(board, i + 1, j);
dfs(board, i, j - 1);
dfs(board, i, j + 1);
}
}91. 克隆图(中等)
题目描述
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值
val(int) 和其邻居的列表(list[Node])。
class Node { public int val; public List<Node> neighbors; }测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(
val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝作为对克隆图的引用返回。
示例 1:
输入:adjList = [[2,4],[1,3],[2,4],[1,3]] 输出:[[2,4],[1,3],[2,4],[1,3]] 解释: 图中有 4 个节点。 节点 1 的值是 1,它有两个邻居:节点 2 和 4 。 节点 2 的值是 2,它有两个邻居:节点 1 和 3 。 节点 3 的值是 3,它有两个邻居:节点 2 和 4 。 节点 4 的值是 4,它有两个邻居:节点 1 和 3 。示例 2:
输入:adjList = [[]] 输出:[[]] 解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。示例 3:输入: adjList = \[\] 输出: \[\] **解释:**这个图是空的,它不含任何节点。
提示:
- 这张图中的节点数在
[0, 100]之间。1 <= Node.val <= 100- 每个节点值
Node.val都是唯一的,- 图中没有重复的边,也没有自环。
- 图是连通图,你可以从给定节点访问到所有节点。
解题思路
也可见图论总结与编程练习_编程 图论-CSDN博客中的第2题。
92.除法求值 (中等)
题目描述
给你一个变量对数组
equations和一个实数值数组values作为已知条件,其中equations[i] = [Ai, Bi]和values[i]共同表示等式Ai / Bi = values[i]。每个Ai或Bi是一个表示单个变量的字符串。另有一些以数组
queries表示的问题,其中queries[j] = [Cj, Dj]表示第j个问题,请你根据已知条件找出Cj / Dj = ?的结果作为答案。返回 所有问题的答案 。如果存在某个无法确定的答案,则用
-1.0替代这个答案。如果问题中出现了给定的已知条件中没有出现的字符串,也需要用-1.0替代这个答案。**注意:**输入总是有效的。你可以假设除法运算中不会出现除数为 0 的情况,且不存在任何矛盾的结果。
**注意:**未在等式列表中出现的变量是未定义的,因此无法确定它们的答案。
示例 1:输入: equations = \["a","b","b","c"], values = 2.0,3.0, queries = \["a","c","b","a","a","e","a","a","x","x"] 输出: 6.00000,0.50000,-1.00000,1.00000,-1.00000 解释: 条件:a / b = 2.0 , b / c = 3.0 问题:a / c = ? , b / a = ? , a / e = ? , a / a = ? , x / x = ? 结果:6.0, 0.5, -1.0, 1.0, -1.0 注意:x 是未定义的 => -1.0
示例 2:输入: equations = \["a","b","b","c","bc","cd"], values = 1.5,2.5,5.0, queries = \["a","c","c","b","bc","cd","cd","bc"] 输出:3.75000,0.40000,5.00000,0.20000
示例 3:输入: equations = \["a","b"], values = 0.5, queries = \["a","b","b","a","a","c","x","y"] 输出:0.50000,2.00000,-1.00000,-1.00000
提示:
1 <= equations.length <= 20equations[i].length == 21 <= Ai.length, Bi.length <= 5values.length == equations.length0.0 < values[i] <= 20.01 <= queries.length <= 20queries[i].length == 21 <= Cj.length, Dj.length <= 5Ai, Bi, Cj, Dj由小写英文字母与数字组成
解题思路
可见LeetCode 精选 75 回顾-CSDN博客中的第46题。
93.课程表(中等)
题目描述
你这个学期必须选修
numCourses门课程,记为0到numCourses - 1。在选修某些课程之前需要一些先修课程。 先修课程按数组
prerequisites给出,其中prerequisites[i] = [ai, bi],表示如果要学习课程ai则 必须 先学习课程bi。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。请你判断是否可能完成所有课程的学习?如果可以,返回
true;否则,返回false。示例 1:输入: numCourses = 2, prerequisites = \[1,0] 输出: true **解释:**总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:输入: numCourses = 2, prerequisites = \[1,0,0,1] 输出: false **解释:**总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第53题。
94. 课程表 II(中等)
题目描述
现在你总共有
numCourses门课需要选,记为0到numCourses - 1。给你一个数组prerequisites,其中prerequisites[i] = [ai, bi],表示在选修课程ai前 必须 先选修bi。
- 例如,想要学习课程
0,你需要先完成课程1,我们用一个匹配来表示:[0,1]。返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
示例 1:输入: numCourses = 2, prerequisites = \[1,0] 输出: 0,1 解释: 总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为
[0,1] 。示例 2:输入: numCourses = 4, prerequisites = \[1,0,2,0,3,1,3,2] 输出: 0,2,1,3 解释: 总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。 因此,一个正确的课程顺序是
[0,1,2,3]。另一个正确的排序是[0,2,1,3]。示例 3:输入: numCourses = 1, prerequisites = \[\] 输出:0
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= numCourses * (numCourses - 1)prerequisites[i].length == 20 <= ai, bi < numCoursesai != bi- 所有
[ai, bi]互不相同
解题思路
这个问题可以转化为 拓扑排序 问题,其中每门课程和其前置课程形成一个有向图,我们需要对这个有向图进行拓扑排序来确定课程的学习顺序。这里使用Kahn算法(基于入度的拓扑排序算法)来实现这一过程,步骤如下:
-
构建图:使用邻接表来表示图,其中每个节点(课程)指向它的后续课程。同时计算每个节点的入度(即有多少课程依赖于这个课程)。
-
初始化队列:将所有入度为 0 的节点(课程)加入队列,因为这些课程没有前置课程,可以直接学习。
-
执行拓扑排序:从队列中取出节点,并将其添加到拓扑排序结果中。对于每个出队的节点,减少其所有邻居节点的入度,并将入度变为 0 的邻居节点加入队列。
-
检查结果:如果拓扑排序结果中的节点数量等于总节点数量,说明可以完成所有课程,返回排序结果。如果节点数量不等于总节点数量,说明存在环,无法完成所有课程,返回空数组。
复杂度分析
-
时间复杂度:O(V + E),其中 V 是图中的节点数(课程数),E 是边数(先修关系)。构建图和计算入度的时间复杂度为 O(V + E),拓扑排序的时间复杂度也是 O(V + E)。
-
空间复杂度:O(V + E),用于存储图的邻接表、入度数组以及队列。
代码实现
java
package org.zyf.javabasic.letcode.jd150.graph;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 课程表 II
* @author: zhangyanfeng
* @create: 2024-08-25 17:33
**/
public class FindOrder {
public int[] findOrder(int numCourses, int[][] prerequisites) {
// 初始化图的邻接表和入度数组
List<Integer>[] graph = new ArrayList[numCourses];
int[] inDegree = new int[numCourses];
for (int i = 0; i < numCourses; i++) {
graph[i] = new ArrayList<>();
}
// 构建图和计算每个节点的入度
for (int[] pair : prerequisites) {
int dest = pair[0];
int src = pair[1];
graph[src].add(dest);
inDegree[dest]++;
}
// 初始化队列并将所有入度为0的节点入队
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (inDegree[i] == 0) {
queue.offer(i);
}
}
// 执行拓扑排序
List<Integer> result = new ArrayList<>();
while (!queue.isEmpty()) {
int node = queue.poll();
result.add(node);
for (int neighbor : graph[node]) {
inDegree[neighbor]--;
if (inDegree[neighbor] == 0) {
queue.offer(neighbor);
}
}
}
// 如果排序结果的节点数等于总课程数,则返回结果,否则返回空数组
if (result.size() == numCourses) {
return result.stream().mapToInt(i -> i).toArray();
} else {
return new int[0];
}
}
}十三、图的广度优先搜索
95. 蛇梯棋(中等)
题目描述
给你一个大小为
n x n的整数矩阵board,方格按从1到n2编号,编号遵循 转行交替方式,从左下角开始 (即,从board[n - 1][0]开始)每一行交替方向。玩家从棋盘上的方格
1(总是在最后一行、第一列)开始出发。每一回合,玩家需要从当前方格
curr开始出发,按下述要求前进:
- 选定目标方格
next,目标方格的编号符合范围[curr + 1, min(curr + 6, n2)]。
- 该选择模拟了掷 六面体骰子 的情景,无论棋盘大小如何,玩家最多只能有 6 个目的地。
- 传送玩家:如果目标方格
next处存在蛇或梯子,那么玩家会传送到蛇或梯子的目的地。否则,玩家传送到目标方格next。- 当玩家到达编号
n2的方格时,游戏结束。
r行c列的棋盘,按前述方法编号,棋盘格中可能存在 "蛇" 或 "梯子";如果board[r][c] != -1,那个蛇或梯子的目的地将会是board[r][c]。编号为1和n2的方格不是任何蛇或梯子的起点。注意,玩家在每回合的前进过程中最多只能爬过蛇或梯子一次:就算目的地是另一条蛇或梯子的起点,玩家也 不能 继续移动。
- 举个例子,假设棋盘是
[[-1,4],[-1,3]],第一次移动,玩家的目标方格是2。那么这个玩家将会顺着梯子到达方格3,但 不能 顺着方格3上的梯子前往方格4。返回达到编号为
n2的方格所需的最少移动次数,如果不可能,则返回-1。示例 1:
输入:board = [[-1,-1,-1,-1,-1,-1],[-1,-1,-1,-1,-1,-1],[-1,-1,-1,-1,-1,-1],[-1,35,-1,-1,13,-1],[-1,-1,-1,-1,-1,-1],[-1,15,-1,-1,-1,-1]] 输出:4 解释: 首先,从方格 1 [第 5 行,第 0 列] 开始。 先决定移动到方格 2 ,并必须爬过梯子移动到到方格 15 。 然后决定移动到方格 17 [第 3 行,第 4 列],必须爬过蛇到方格 13 。 接着决定移动到方格 14 ,且必须通过梯子移动到方格 35 。 最后决定移动到方格 36 , 游戏结束。 可以证明需要至少 4 次移动才能到达最后一个方格,所以答案是 4 。示例 2:输入: board = \[-1,-1,-1,3] **输出:**1
提示:
n == board.length == board[i].length2 <= n <= 20board[i][j]的值是-1或在范围[1, n2]内- 编号为
1和n2的方格上没有蛇或梯子

解题思路
要解决这个问题,我们可以将其建模为一个图的最短路径问题,使用广度优先搜索(BFS)来寻找从起点到终点的最短路径:
-
构建图表示 :将二维矩阵转换为一维的节点编号。处理从每个节点可以跳转到的目标节点,这些目标节点范围在
[curr + 1, min(curr + 6, n^2)]之间。 -
处理蛇和梯子:如果目标节点上有蛇或梯子,则移动到目标节点的实际位置,而不是目标节点的编号。
-
广度优先搜索(BFS) :使用 BFS 从起点节点(编号为 1)开始探索,记录每个节点的最短路径长度。每次从当前节点出发,考虑所有可能的掷骰子结果(最多 6 个节点)。将每个可能的节点入队,继续探索,直到找到目标节点(编号为
n^2)或队列为空。 -
终止条件 :如果到达编号为
n^2的节点,返回所需的最小移动次数。如果 BFS 结束时仍未找到,返回-1。
复杂度分析
- 时间复杂度:O(n^2),因为每个节点最多入队一次,每次操作都在 O(1) 时间内完成。
- 空间复杂度:O(n^2),用于存储 BFS 队列和已访问节点。
代码实现
java
package org.zyf.javabasic.letcode.jd150.graph;
import java.util.LinkedList;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 蛇梯棋
* @author: zhangyanfeng
* @create: 2024-08-25 17:38
**/
public class SnakesAndLadders {
public int snakesAndLadders(int[][] board) {
int n = board.length;
// 将二维坐标转换为一维坐标的映射
int[] flatBoard = new int[n * n + 1];
boolean leftToRight = true; // 矩阵从底行开始处理,方向交替
int index = 1;
for (int i = n - 1; i >= 0; i--) {
if (leftToRight) {
for (int j = 0; j < n; j++) {
flatBoard[index++] = board[i][j];
}
} else {
for (int j = n - 1; j >= 0; j--) {
flatBoard[index++] = board[i][j];
}
}
leftToRight = !leftToRight;
}
// BFS 初始化
Queue<Integer> queue = new LinkedList<>();
boolean[] visited = new boolean[n * n + 1];
queue.offer(1); // 从方格1开始
visited[1] = true;
int moves = 0;
// BFS 开始
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
int curr = queue.poll();
if (curr == n * n) return moves; // 到达终点
// 遍历所有可能的骰子结果
for (int dice = 1; dice <= 6; dice++) {
int next = curr + dice;
if (next > n * n) break; // 超过棋盘范围
// 处理蛇或梯子
if (flatBoard[next] != -1) {
next = flatBoard[next];
}
if (!visited[next]) {
visited[next] = true;
queue.offer(next);
}
}
}
moves++;
}
return -1; // 无法到达终点
}
}96. 最小基因变化(中等)
题目描述
基因序列可以表示为一条由 8 个字符组成的字符串,其中每个字符都是
'A'、'C'、'G'和'T'之一。假设我们需要调查从基因序列
start变为end所发生的基因变化。一次基因变化就意味着这个基因序列中的一个字符发生了变化。
- 例如,
"AACCGGTT" --> "AACCGGTA"就是一次基因变化。另有一个基因库
bank记录了所有有效的基因变化,只有基因库中的基因才是有效的基因序列。(变化后的基因必须位于基因库bank中)给你两个基因序列
start和end,以及一个基因库bank,请你找出并返回能够使start变化为end所需的最少变化次数。如果无法完成此基因变化,返回-1。注意:起始基因序列
start默认是有效的,但是它并不一定会出现在基因库中。示例 1:输入: start = "AACCGGTT", end = "AACCGGTA", bank = "AACCGGTA" **输出:**1
示例 2:输入: start = "AACCGGTT", end = "AAACGGTA", bank = "AACCGGTA","AACCGCTA","AAACGGTA" **输出:**2
示例 3:输入: start = "AAAAACCC", end = "AACCCCCC", bank = "AAAACCCC","AAACCCCC","AACCCCCC" **输出:**3
提示:
start.length == 8end.length == 80 <= bank.length <= 10bank[i].length == 8start、end和bank[i]仅由字符['A', 'C', 'G', 'T']组成
解题思路
要解决这个问题,我们可以将其建模为一个图的最短路径问题,其中每个基因序列是一个图中的节点,每次变化表示从一个节点到另一个节点的边。由于每次基因变化只允许一个字符的变化,因此图的边是通过改变一个字符来连接的:
-
建模为图:每个基因序列视为图中的一个节点。从一个基因序列到另一个基因序列的边存在,当且仅当这两个序列只有一个字符的差异。
-
使用广度优先搜索(BFS) :从
start基因序列开始,使用 BFS 遍历所有可能的基因变化。使用一个队列来存储当前基因序列及其变化次数。使用一个集合来记录已访问的基因序列,避免重复访问。 -
终止条件 :如果在 BFS 遍历过程中找到
end基因序列,返回当前的变化次数。如果 BFS 完成后未找到end基因序列,返回-1。
复杂度分析
- 时间复杂度:O(N * L * 4^L),其中 N 是基因库的大小,L 是基因序列的长度(在此问题中是 8)。对于每个基因序列,我们需要检查其所有可能的变种(4^L),并在队列中进行 BFS 操作。
- 空间复杂度:O(N),用于存储基因库和已访问集合。
代码实现
java
package org.zyf.javabasic.letcode.jd150.graph;
import java.util.*;
/**
* @program: zyfboot-javabasic
* @description: 最小基因变化
* @author: zhangyanfeng
* @create: 2024-08-25 17:42
**/
public class MinMutation {
public int minMutation(String start, String end, String[] bank) {
// 将基因库转为集合以便快速查找
Set<String> bankSet = new HashSet<>(Arrays.asList(bank));
// 如果目标基因序列不在基因库中,则直接返回 -1
if (!bankSet.contains(end)) {
return -1;
}
// 初始化 BFS 队列,起始基因序列和变化次数为 0
Queue<String> queue = new LinkedList<>();
queue.offer(start);
int mutations = 0;
// 进行 BFS
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
String curr = queue.poll();
// 如果当前基因序列等于目标基因序列,则返回变化次数
if (curr.equals(end)) {
return mutations;
}
// 尝试每个可能的变化
for (int j = 0; j < curr.length(); j++) {
char[] chars = curr.toCharArray();
for (char c = 'A'; c <= 'Z'; c++) {
if (chars[j] == c) continue; // 如果字符相同则跳过
chars[j] = c;
String next = new String(chars);
// 如果变换后的基因序列在基因库中,且未被访问过
if (bankSet.contains(next)) {
queue.offer(next);
bankSet.remove(next); // 标记为已访问
}
}
}
}
mutations++; // 增加变化次数
}
// 如果无法到达目标基因序列,返回 -1
return -1;
}
}97. 单词接龙(困难)
题目描述
字典
wordList中从单词beginWord到endWord的 转换序列 是一个按下述规格形成的序列beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中。注意,beginWord不需要在wordList中。sk == endWord给你两个单词
beginWord和endWord和一个字典wordList,返回 从beginWord到endWord的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回0。示例 1:输入: beginWord = "hit", endWord = "cog", wordList = "hot","dot","dog","lot","log","cog" 输出: 5 **解释:**一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:输入: beginWord = "hit", endWord = "cog", wordList = "hot","dot","dog","lot","log" 输出: 0 **解释:**endWord "cog" 不在字典中,所以无法进行转换。
提示:
1 <= beginWord.length <= 10endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有字符串 互不相同
解题思路
也可见图论总结与编程练习_编程 图论-CSDN博客中的第1题。
十四、字典树
98.实现 Trie (前缀树)(中等)
题目描述
Trie (发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。示例:
输入 ["Trie", "insert", "search", "search", "startsWith", "insert", "search"] [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]] 输出 [null, null, true, false, true, null, true] 解释 Trie trie = new Trie(); trie.insert("apple"); trie.search("apple"); // 返回 True trie.search("app"); // 返回 False trie.startsWith("app"); // 返回 True trie.insert("app"); trie.search("app"); // 返回 True提示:
1 <= word.length, prefix.length <= 2000word和prefix仅由小写英文字母组成insert、search和startsWith调用次数 总计 不超过3 * 104次
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第54题。
99. 添加与搜索单词 - 数据结构设计(中等)
题目描述
请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 。
实现词典类
WordDictionary:
WordDictionary()初始化词典对象void addWord(word)将word添加到数据结构中,之后可以对它进行匹配bool search(word)如果数据结构中存在字符串与word匹配,则返回true;否则,返回false。word中可能包含一些'.',每个.都可以表示任何一个字母。示例:输入: "WordDictionary","addWord","addWord","addWord","search","search","search","search" \[,"bad","dad","mad","pad","bad",".ad","b.."] 输出: null,null,null,null,false,true,true,true 解释: WordDictionary wordDictionary = new WordDictionary(); wordDictionary.addWord("bad"); wordDictionary.addWord("dad"); wordDictionary.addWord("mad"); wordDictionary.search("pad"); // 返回 False wordDictionary.search("bad"); // 返回 True wordDictionary.search(".ad"); // 返回 True wordDictionary.search("b.."); // 返回 True
提示:
1 <= word.length <= 25addWord中的word由小写英文字母组成search中的word由 '.' 或小写英文字母组成- 最多调用
104次addWord和search
解题思路
要实现一个支持添加单词和匹配单词的词典数据结构,我们可以使用Trie(前缀树):
设计思路
-
Trie 数据结构 :每个节点代表一个字符,节点的子节点表示继续匹配的字符。节点中保存一个布尔值
isEndOfWord来标记是否有单词在该节点结束。 -
支持通配符匹配 :使用递归函数来处理
.通配符,尝试匹配所有可能的字符。在递归过程中,当遇到.时,需要遍历该节点的所有子节点。
操作细节
-
添加单词 (
addWord) :遍历每个字符,将其插入到 Trie 中。最后一个字符的节点标记为isEndOfWord。 -
查找单词 (
search) :使用递归方法进行深度优先搜索(DFS)。对于每个字符,检查是否匹配,如果是.,尝试所有子节点。
复杂度分析
-
时间复杂度:
addWord操作的时间复杂度为 O(L),其中 L 是单词的长度。search操作的时间复杂度为 O(L * 4^L) 最坏情况下,其中 L 是单词的长度,因为每个.可能会展开到最多 4 种情况。
-
空间复杂度:
addWord操作的空间复杂度为 O(L * N),其中 N 是存储的单词数。search操作的空间复杂度为 O(L) 用于递归调用栈。
代码实现
java
package org.zyf.javabasic.letcode.jd150.trie;
import java.util.HashMap;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 添加与搜索单词 - 数据结构设计
* @author: zhangyanfeng
* @create: 2024-08-25 17:50
**/
public class WordDictionary {
private class TrieNode {
Map<Character, TrieNode> children;
boolean isEndOfWord;
TrieNode() {
children = new HashMap<>();
isEndOfWord = false;
}
}
private TrieNode root;
public WordDictionary() {
root = new TrieNode();
}
public void addWord(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
node = node.children.computeIfAbsent(c, k -> new TrieNode());
}
node.isEndOfWord = true;
}
public boolean search(String word) {
return searchInTrie(word, 0, root);
}
private boolean searchInTrie(String word, int index, TrieNode node) {
if (index == word.length()) {
return node.isEndOfWord;
}
char c = word.charAt(index);
if (c == '.') {
// 对于 '.', 遍历所有子节点
for (TrieNode child : node.children.values()) {
if (searchInTrie(word, index + 1, child)) {
return true;
}
}
return false;
} else {
// 对于普通字符, 只在子节点中查找
TrieNode child = node.children.get(c);
if (child == null) {
return false;
}
return searchInTrie(word, index + 1, child);
}
}
}100. 单词搜索 II(困难)
题目描述
给定一个
m x n二维字符网格board和一个单词(字符串)列表words, 返回所有二维网格上的单词 。单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中"相邻"单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"] 输出:["eat","oath"]示例 2:
输入:board = [["a","b"],["c","d"]], words = ["abcb"] 输出:[]提示:
m == board.lengthn == board[i].length1 <= m, n <= 12board[i][j]是一个小写英文字母1 <= words.length <= 3 * 1041 <= words[i].length <= 10words[i]由小写英文字母组成words中的所有字符串互不相同

解题思路
这个问题是经典的单词搜索问题,我们可以通过 Trie(前缀树)结合 DFS(深度优先搜索)来高效解决:
-
Trie(前缀树)构建:使用 Trie 数据结构存储所有单词,以支持高效的前缀匹配。每个 Trie 节点代表一个字符。将每个单词插入 Trie 中,在单词的最后一个节点处标记该单词。
-
DFS 搜索:在网格的每个单元格开始进行 DFS 搜索,尝试从当前单元格出发构建单词。通过检查当前单元格的字符是否存在于当前 Trie 节点的子节点中来决定是否继续搜索。使用回溯(将当前单元格的字符恢复为原始字符)来确保每个单元格在搜索过程中只被访问一次。
-
回溯和标记 :在 DFS 搜索过程中,将当前单元格标记为访问过(用特殊字符
'#'替代原字符),以避免重复使用。搜索完成后,将单元格状态恢复为原始字符。
复杂度分析
-
时间复杂度:
- 构建 Trie 的时间复杂度为 O(W⋅L)),其中 WWW 是单词的数量,L 是单词的平均长度。
- 在网格上进行 DFS 的时间复杂度为 O(m⋅n⋅4^L),其中 m 和 n 是网格的行列数,L 是单词的最大长度。每个单元格在 DFS 中最多有 4 个方向进行探索。
-
空间复杂度:
- Trie 的空间复杂度为 O(W⋅L)。
- DFS 递归栈的空间复杂度为 O(L),加上网格的访问标记空间 O(m⋅n)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.trie;
import java.util.*;
/**
* @program: zyfboot-javabasic
* @description: 单词搜索 II
* @author: zhangyanfeng
* @create: 2024-08-25 17:57
**/
public class FindWords {
// 定义四个方向(上下左右)
int[][] dirs = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
public List<String> findWords(char[][] board, String[] words) {
Trie trie = new Trie(); // 创建 Trie 树
// 将所有单词插入 Trie 中
for (String word : words) {
trie.insert(word);
}
Set<String> ans = new HashSet<>(); // 存储结果的集合
// 遍历网格的每一个单元格,进行 DFS 搜索
for (int i = 0; i < board.length; ++i) {
for (int j = 0; j < board[0].length; ++j) {
dfs(board, trie, i, j, ans);
}
}
return new ArrayList<>(ans); // 返回结果的列表
}
// 深度优先搜索函数
public void dfs(char[][] board, Trie now, int i1, int j1, Set<String> ans) {
// 如果当前字符不在 Trie 的子节点中,则返回
if (!now.children.containsKey(board[i1][j1])) {
return;
}
char ch = board[i1][j1]; // 当前字符
now = now.children.get(ch); // 移动到子节点
// 如果当前节点是一个单词的结束点,则将单词添加到结果集中
if (!"".equals(now.word)) {
ans.add(now.word);
}
// 标记当前单元格为访问过
board[i1][j1] = '#';
// 遍历四个方向进行 DFS 搜索
for (int[] dir : dirs) {
int i2 = i1 + dir[0], j2 = j1 + dir[1];
if (i2 >= 0 && i2 < board.length && j2 >= 0 && j2 < board[0].length) {
dfs(board, now, i2, j2, ans);
}
}
// 恢复单元格状态为原始字符
board[i1][j1] = ch;
}
// Trie(前缀树)实现
class Trie {
String word; // 存储单词
Map<Character, Trie> children; // 存储子节点
boolean isWord; // 标记是否是单词的结束
public Trie() {
this.word = "";
this.children = new HashMap<>();
}
// 将单词插入到 Trie 中
public void insert(String word) {
Trie cur = this;
for (int i = 0; i < word.length(); ++i) {
char c = word.charAt(i);
if (!cur.children.containsKey(c)) {
cur.children.put(c, new Trie());
}
cur = cur.children.get(c);
}
cur.word = word; // 设置单词结束标记
}
}
}十五、回溯
101.电话号码的字母组合(中等)
题目描述
给定一个仅包含数字
2-9的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
示例 1:输入: digits = "23" 输出:"ad","ae","af","bd","be","bf","cd","ce","cf"
示例 2:输入: digits = "" 输出:\[\]
示例 3:输入: digits = "2" 输出:"a","b","c"
提示:
0 <= digits.length <= 4digits[i]是范围['2', '9']的一个数字。

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第57题。
可见LeetCode 精选 75 回顾-CSDN博客中的第57题。
102. 组合 (中等)
题目描述
给定两个整数
n和k,返回范围[1, n]中所有可能的k个数的组合。你可以按 任何顺序 返回答案。
示例 1:输入: n = 4, k = 2 输出: \[2,4, 3,4, 2,3, 1,2, 1,3, 1,4, ]
示例 2:输入: n = 1, k = 1 输出:\[1]
提示:
1 <= n <= 201 <= k <= n
解题思路
这个问题要求我们从 [1, n] 范围内的数字中选取 k 个数的所有可能组合。解决这个问题可以使用 回溯法:
- 选择:从当前数字中选择一个数字加入当前组合。
- 探索:递归地继续选择下一个数字。
- 回溯:撤销上一步的选择,并继续尝试其他选择。
具体步骤如下:
- 初始化:开始时选择从 1 到 n 的数字作为起点。
- 递归选择 :在每一步递归中,从当前数字开始,尝试选择
k个数字中的下一个数字。 - 终止条件 :当选择的数字数量等于
k时,保存当前组合。 - 撤销选择:在回溯时,撤销上一步的选择以尝试其他组合。
复杂度分析
-
时间复杂度:
- 生成组合的总时间复杂度是
O(C(n, k)),其中C(n, k)是组合数,表示从n个元素中选择k个的组合数。 - 计算组合数
C(n, k)的公式为n! / (k! * (n - k)!)。
- 生成组合的总时间复杂度是
-
空间复杂度:
- 递归栈的空间复杂度为
O(k),因为在最坏情况下,递归深度为k。 - 存储所有组合的空间复杂度为
O(C(n, k) * k),因为我们需要存储所有的组合,每个组合的大小为k。
- 递归栈的空间复杂度为
代码实现
java
package org.zyf.javabasic.letcode.jd150.blacktracing;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 组合
* @author: zhangyanfeng
* @create: 2024-08-25 18:04
**/
public class Combine {
public List<List<Integer>> combine(int n, int k) {
List<List<Integer>> result = new ArrayList<>(); // 存储所有组合
List<Integer> combination = new ArrayList<>(); // 当前组合
backtrack(result, combination, n, k, 1); // 从数字1开始递归
return result;
}
// 回溯函数
private void backtrack(List<List<Integer>> result, List<Integer> combination, int n, int k, int start) {
// 如果当前组合的大小等于k,添加到结果列表中
if (combination.size() == k) {
result.add(new ArrayList<>(combination)); // 添加一份当前组合的副本
return;
}
// 从start开始尝试选择每个数字
for (int i = start; i <= n; i++) {
combination.add(i); // 选择当前数字
backtrack(result, combination, n, k, i + 1); // 递归选择下一个数字
combination.remove(combination.size() - 1); // 撤销选择,回溯
}
}
}103.全排列(中等)
题目描述
给定一个不含重复数字的数组
nums,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。示例 1:输入: nums = 1,2,3 输出:\[1,2,3,1,3,2,2,1,3,2,3,1,3,1,2,3,2,1]
示例 2:输入: nums = 0,1 输出:\[0,1,1,0]
示例 3:输入: nums = 1 输出:\[1]
提示:
1 <= nums.length <= 6-10 <= nums[i] <= 10nums中的所有整数 互不相同
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第55题。
104.组合总和(中等)
题目描述
给你一个 无重复元素 的整数数组
candidates和一个目标整数target,找出candidates中可以使数字和为目标数target的 所有不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。对于给定的输入,保证和为
target的不同组合数少于150个。示例 1:输入: candidates =
[2,3,6,7],target =7输出: \[2,2,3,7] 解释: 2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。 7 也是一个候选, 7 = 7 。 仅有这两种组合。示例 2:输入: candidates = 2,3,5
,target = 8 输出:\[2,2,2,2,2,3,3,3,5]示例 3:输入: candidates =
[2],target = 1 输出:\[\]提示:
1 <= candidates.length <= 302 <= candidates[i] <= 40candidates的所有元素 互不相同1 <= target <= 40
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第58题。
105. N 皇后 II(困难)
题目描述
n 皇后问题 研究的是如何将
n个皇后放置在n × n的棋盘上,并且使皇后彼此之间不能相互攻击。给你一个整数
n,返回 n 皇后问题 不同的解决方案的数量。示例 1:
输入:n = 4 输出:2 解释:如上图所示,4 皇后问题存在两个不同的解法。示例 2:输入: n = 1 **输出:**1
提示:
1 <= n <= 9

解题思路
n 皇后问题 的目标是将 n 个皇后放置在一个 n x n 的棋盘上,确保没有任何两个皇后在同一行、同一列或同一对角线上。每个皇后都可以攻击棋盘上与它处于同一行、列或对角线上的其他皇后。
要解决这个问题,我们可以使用 回溯法(Backtracking),这种方法通过逐步构建解,并在发现不满足条件时进行撤销,来逐步寻找所有可能的解。回溯法步骤
- 选择:逐行放置皇后,并在每一行中尝试放置皇后的位置。
- 约束:在尝试放置皇后时,确保它不与已放置的皇后冲突。
- 递归:对每一个合法的位置递归地放置下一个皇后。
- 回溯:当所有行都尝试完毕,或者发现当前放置导致冲突时,撤销当前选择,回到上一步继续尝试其他选择。
复杂度分析
-
时间复杂度 :在最坏情况下,时间复杂度为
O(N!),因为对于每一行,可能需要尝试N个位置,并且最多有N!种放置方案。 -
空间复杂度 :主要包括递归栈的深度,递归深度为
O(N),以及用于存储解决方案的空间,最多有O(N!)种解决方案。
代码实现
java
package org.zyf.javabasic.letcode.jd150.blacktracing;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: N 皇后 II
* @author: zhangyanfeng
* @create: 2024-08-25 18:11
**/
public class TotalNQueens {
public int totalNQueens(int n) {
List<List<String>> solutions = new ArrayList<>(); // 存储所有解决方案
backtrack(solutions, new ArrayList<>(), n, new boolean[n], new boolean[2 * n - 1], new boolean[2 * n - 1], 0);
return solutions.size(); // 返回解决方案的数量
}
private void backtrack(List<List<String>> solutions, List<String> board, int n, boolean[] cols, boolean[] diag1, boolean[] diag2, int row) {
// 递归终止条件:如果所有行都被处理完毕
if (row == n) {
solutions.add(new ArrayList<>(board)); // 记录当前有效的解决方案
return;
}
// 尝试在当前行的每一列放置皇后
for (int col = 0; col < n; col++) {
int d1 = row - col + (n - 1); // 主要对角线索引
int d2 = row + col; // 副对角线索引
// 检查当前位置是否安全
if (!cols[col] && !diag1[d1] && !diag2[d2]) {
char[] rowArray = new char[n];
for (int i = 0; i < n; i++) {
rowArray[i] = '.'; // 初始化当前行
}
rowArray[col] = 'Q'; // 放置皇后
board.add(new String(rowArray)); // 记录当前行的字符串形式
// 标记当前位置为占用
cols[col] = true;
diag1[d1] = true;
diag2[d2] = true;
// 递归处理下一行
backtrack(solutions, board, n, cols, diag1, diag2, row + 1);
// 撤销当前选择
board.remove(board.size() - 1);
cols[col] = false;
diag1[d1] = false;
diag2[d2] = false;
}
}
}
}106.括号生成(中等)
题目描述
数字
n代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的括号组合。示例 1:输入: n = 3 输出:"((()))","(()())","(())()","()(())","()()()"
示例 2:输入: n = 1 输出:"()"
提示:
1 <= n <= 8
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第59题。
107.单词搜索(中等)
题目描述
给定一个
m x n二维字符网格board和一个字符串单词word。如果word存在于网格中,返回true;否则,返回false。单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中"相邻"单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED" 输出:true示例 2:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE" 输出:true示例 3:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB" 输出:false提示:
m == board.lengthn = board[i].length1 <= m, n <= 61 <= word.length <= 15board和word仅由大小写英文字母组成进阶: 你可以使用搜索剪枝的技术来优化解决方案,使其在
board更大的情况下可以更快解决问题?


解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第60题。
**十六、**分治
108.将有序数组转换为二叉搜索树(简单)
题目描述
给你一个整数数组
nums,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树。示例 1:
输入:nums = [-10,-3,0,5,9] 输出:[0,-3,9,-10,null,5] 解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:示例 2:
输入:nums = [1,3] 输出:[3,1] 解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。提示:
1 <= nums.length <= 104-104 <= nums[i] <= 104nums按 严格递增 顺序排列


解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第42题。
109.排序链表(中等)
题目描述
给你链表的头结点
head,请将其按 升序 排列并返回 排序后的链表 。示例 1:
输入:head = [4,2,1,3] 输出:[1,2,3,4]示例 2:
输入:head = [-1,5,3,4,0] 输出:[-1,0,3,4,5]示例 3:输入: head = \[\] 输出:\[\]
提示:
- 链表中节点的数目在范围
[0, 5 * 104]内-105 <= Node.val <= 105进阶: 你可以在
O(n log n)时间复杂度和常数级空间复杂度下,对链表进行排序吗?

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第33题。
110. 建立四叉树(中等)
题目描述
给你一个
n * n矩阵grid,矩阵由若干0和1组成。请你用四叉树表示该矩阵grid。你需要返回能表示矩阵
grid的 四叉树 的根结点。四叉树数据结构中,每个内部节点只有四个子节点。此外,每个节点都有两个属性:
val:储存叶子结点所代表的区域的值。1 对应 True ,0 对应 False 。注意,当isLeaf为 False 时,你可以把 True 或者 False 赋值给节点,两种值都会被判题机制 接受 。isLeaf: 当这个节点是一个叶子结点时为 True ,如果它有 4 个子节点则为 False 。
class Node { public boolean val; public boolean isLeaf; public Node topLeft; public Node topRight; public Node bottomLeft; public Node bottomRight; }我们可以按以下步骤为二维区域构建四叉树:
- 如果当前网格的值相同(即,全为
0或者全为1),将isLeaf设为 True ,将val设为网格相应的值,并将四个子节点都设为 Null 然后停止。- 如果当前网格的值不同,将
isLeaf设为 False, 将val设为任意值,然后如下图所示,将当前网格划分为四个子网格。- 使用适当的子网格递归每个子节点。
如果你想了解更多关于四叉树的内容,可以参考 wiki 。
四叉树格式:
你不需要阅读本节来解决这个问题。只有当你想了解输出格式时才会这样做。输出为使用层序遍历后四叉树的序列化形式,其中
null表示路径终止符,其下面不存在节点。它与二叉树的序列化非常相似。唯一的区别是节点以列表形式表示
[isLeaf, val]。如果
isLeaf或者val的值为 True ,则表示它在列表[isLeaf, val]中的值为 1 ;如果isLeaf或者val的值为 False ,则表示值为 0。示例 1:
输入:grid = [[0,1],[1,0]] 输出:[[0,1],[1,0],[1,1],[1,1],[1,0]] 解释:此示例的解释如下: 请注意,在下面四叉树的图示中,0 表示 false,1 表示 True 。示例 2:
输入:grid = [[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,1,1,1,1],[1,1,1,1,1,1,1,1],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0]] 输出:[[0,1],[1,1],[0,1],[1,1],[1,0],null,null,null,null,[1,0],[1,0],[1,1],[1,1]] 解释:网格中的所有值都不相同。我们将网格划分为四个子网格。 topLeft,bottomLeft 和 bottomRight 均具有相同的值。 topRight 具有不同的值,因此我们将其再分为 4 个子网格,这样每个子网格都具有相同的值。 解释如下图所示:提示:
n == grid.length == grid[i].lengthn == 2x其中0 <= x <= 6



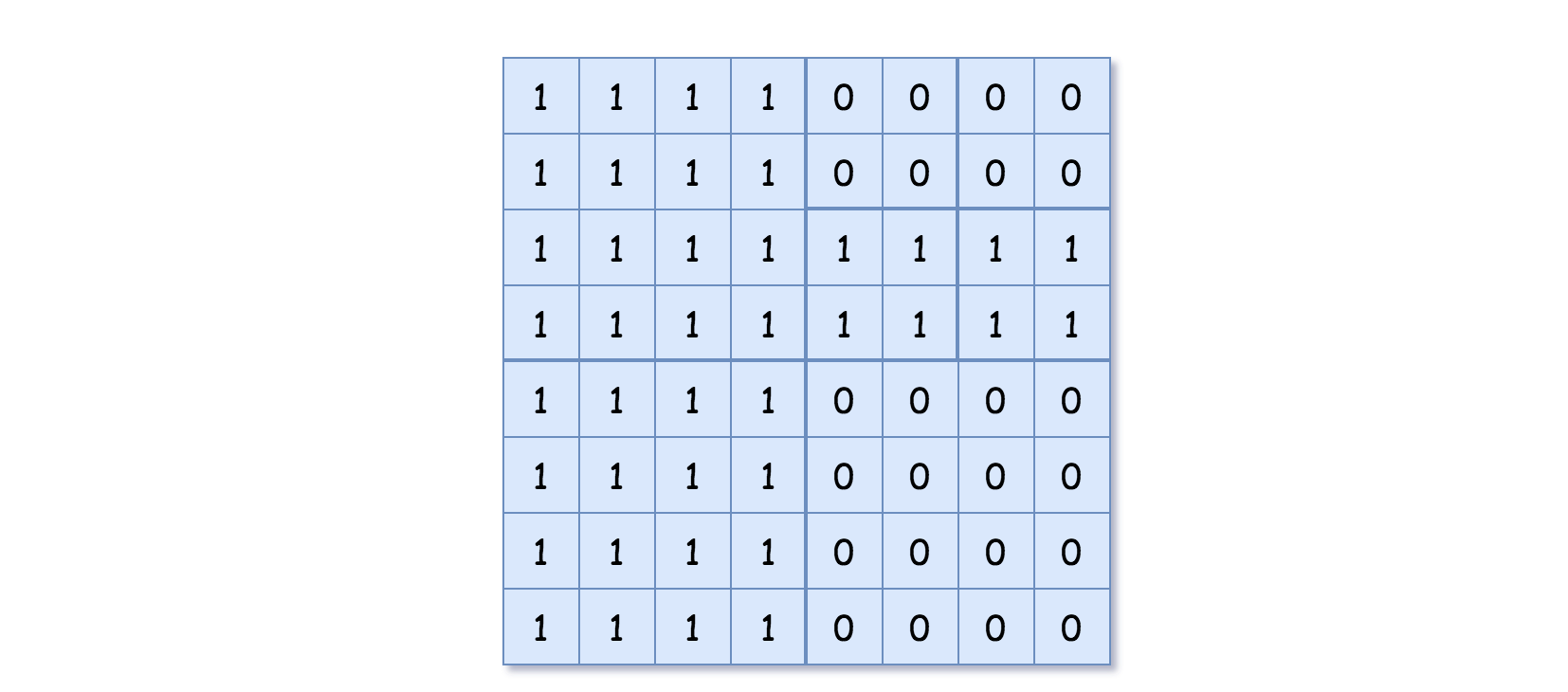

解题思路
要将一个 n x n 的矩阵转换为四叉树(QuadTree),四叉树是一种用于表示二维空间的树形结构,其中每个节点代表一个矩形区域。具体到这个问题:
-
检查当前矩形区域:
如果当前区域内所有的值都相同,则该区域可以直接作为一个叶子节点(
isLeaf为True),并将值(val)设置为这个区域的值。如果当前区域内的值不同,则需要将其划分为四个子区域,分别递归处理每个子区域。 -
递归构建四叉树:
将当前矩形区域分成四个子区域:
topLeft,topRight,bottomLeft,bottomRight。对每个子区域递归调用构建四叉树的过程。当递归处理完四个子区域后,将它们作为当前节点的四个子节点。
复杂度分析
-
时间复杂度 :最坏情况下,每个节点都需要将整个区域划分为四个子区域。这种情况下,总体复杂度是
O(N^2),其中N是矩阵的边长,因为每个节点的处理和递归需要O(N^2)时间。 -
空间复杂度 :递归调用栈的深度最大为
O(log(N))。空间复杂度主要由树的节点数量和递归栈深度决定,总体复杂度是O(N^2)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.tree;
/**
* @program: zyfboot-javabasic
* @description: 建立四叉树
* @author: zhangyanfeng
* @create: 2024-08-25 18:23
**/
public class BuildQuadTree {
public Node construct(int[][] grid) {
return buildQuadTree(grid, 0, 0, grid.length);
}
private Node buildQuadTree(int[][] grid, int row, int col, int size) {
// 创建当前节点
Node node = new Node();
// 检查当前区域是否为一个叶子节点
if (isUniform(grid, row, col, size)) {
node.isLeaf = true;
node.val = grid[row][col] == 1;
return node;
}
// 当前区域不是一个叶子节点,分为四个子区域
node.isLeaf = false;
int halfSize = size / 2;
node.topLeft = buildQuadTree(grid, row, col, halfSize);
node.topRight = buildQuadTree(grid, row, col + halfSize, halfSize);
node.bottomLeft = buildQuadTree(grid, row + halfSize, col, halfSize);
node.bottomRight = buildQuadTree(grid, row + halfSize, col + halfSize, halfSize);
return node;
}
private boolean isUniform(int[][] grid, int row, int col, int size) {
int firstValue = grid[row][col];
for (int r = row; r < row + size; r++) {
for (int c = col; c < col + size; c++) {
if (grid[r][c] != firstValue) {
return false;
}
}
}
return true;
}
class Node {
public boolean val;
public boolean isLeaf;
public Node topLeft;
public Node topRight;
public Node bottomLeft;
public Node bottomRight;
public Node() {
this.val = false;
this.isLeaf = false;
this.topLeft = null;
this.topRight = null;
this.bottomLeft = null;
this.bottomRight = null;
}
}
}111.合并 K 个升序链表 (困难)
题目描述
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6示例 2:输入: lists = \[\] 输出:\[\]
示例 3:输入: lists = \[] 输出:\[\]
提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第34题。
十七、Kadane 算法
112.最大子数组和 (中等)
题目描述
给你一个整数数组
nums,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。子数组 是数组中的一个连续部分。
示例 1:输入: nums = -2,1,-3,4,-1,2,1,-5,4 输出: 6 **解释:**连续子数组 4,-1,2,1 的和最大,为 6 。
示例 2:输入: nums = 1 **输出:**1
示例 3:输入: nums = 5,4,-1,7,8 **输出:**23
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 104进阶: 如果你已经实现复杂度为
O(n)的解法,尝试使用更为精妙的 分治法 求解。
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第13题。
113. 环形子数组的最大和
题目描述
给定一个长度为
n的环形整数数组nums,返回*nums的非空 子数组 的最大可能和*。环形数组 意味着数组的末端将会与开头相连呈环状。形式上,
nums[i]的下一个元素是nums[(i + 1) % n],nums[i]的前一个元素是nums[(i - 1 + n) % n]。子数组 最多只能包含固定缓冲区
nums中的每个元素一次。形式上,对于子数组nums[i], nums[i + 1], ..., nums[j],不存在i <= k1, k2 <= j其中k1 % n == k2 % n。示例 1:输入: nums = 1,-2,3,-2 输出: 3 **解释:**从子数组 3 得到最大和 3
示例 2:输入: nums = 5,-3,5 输出: 10 **解释:**从子数组 5,5 得到最大和 5 + 5 = 10
示例 3:输入: nums = 3,-2,2,-3 输出: 3 **解释:**从子数组 3 和 3,-2,2 都可以得到最大和 3
提示:
n == nums.length1 <= n <= 3 * 104-3 * 104 <= nums[i] <= 3 * 104
解题思路
为了解决环形数组的最大子数组和问题,我们可以通过以下步骤来处理:
-
非环形数组的最大子数组和: 使用 Kadane 算法计算非环形数组的最大子数组和。这是因为 Kadane 算法可以在 O(n)O(n)O(n) 时间复杂度内找到最大和的子数组。
-
环形数组的最大子数组和: 要找到环形数组的最大子数组和,我们可以考虑两种情况:
- 不包括环形部分:这就是普通的最大子数组和,已经在第一步中求出。
- 包括环形部分 :可以通过以下步骤计算:计算整个数组的总和
totalSum。使用 Kadane 算法计算数组的最小子数组和minSum。最大环形子数组和 =totalSum - minSum。这是因为要包括整个数组的环形部分,我们可以从totalSum减去数组的最小子数组和得到环形部分的最大和。
-
特殊情况处理:
如果整个数组只有一个元素,则最大和只能是该元素本身。如果所有元素都是负数,那么环形和不应该考虑,因为环形和会减去最小子数组和,而这是不需要的。
复杂度分析
- 时间复杂度:O(n),因为每个步骤(Kadane 算法,计算总和,计算最小子数组和)都需要 O(n) 时间。
- 空间复杂度:O(1),只使用了常量级的额外空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.kadane;
/**
* @program: zyfboot-javabasic
* @description: 环形子数组的最大和
* @author: zhangyanfeng
* @create: 2024-08-25 18:29
**/
public class MaxSubarraySumCircular {
public int maxSubarraySumCircular(int[] nums) {
// 计算数组的总和
int totalSum = 0;
for (int num : nums) {
totalSum += num;
}
// 求普通最大子数组和
int maxSum = kadane(nums, true);
// 求最小子数组和
int minSum = kadane(nums, false);
// 最大环形子数组和
int maxCircularSum = totalSum - minSum;
// 如果数组中所有元素都为负数,则 maxCircularSum 会是 0,这种情况需要特殊处理
if (maxCircularSum == 0) {
return maxSum;
}
// 返回最大值
return Math.max(maxSum, maxCircularSum);
}
// Kadane 算法变种,用于计算最大子数组和或最小子数组和
private int kadane(int[] nums, boolean findMax) {
int currentSum = nums[0];
int extremumSum = nums[0];
for (int i = 1; i < nums.length; i++) {
if (findMax) {
currentSum = Math.max(nums[i], currentSum + nums[i]);
extremumSum = Math.max(extremumSum, currentSum);
} else {
currentSum = Math.min(nums[i], currentSum + nums[i]);
extremumSum = Math.min(extremumSum, currentSum);
}
}
return extremumSum;
}
}十八、二分查找
114.搜索插入位置(简单)
题目描述
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为
O(log n)的算法。示例 1:输入: nums = 1,3,5,6, target = 5 输出: 2
示例 2:输入: nums = 1,3,5,6, target = 2 输出: 1
示例 3:输入: nums = 1,3,5,6, target = 7 输出: 4
提示:
1 <= nums.length <= 104-104 <= nums[i] <= 104nums为 无重复元素 的 升序排列数组-104 <= target <= 104
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第63题。
115.搜索二维矩阵(中等)
题目描述
给你一个满足下述两条属性的
m x n整数矩阵:
- 每行中的整数从左到右按非严格递增顺序排列。
- 每行的第一个整数大于前一行的最后一个整数。
给你一个整数
target,如果target在矩阵中,返回true;否则,返回false。示例 1:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3 输出:true示例 2:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13 输出:false提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 100-104 <= matrix[i][j], target <= 104
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第65题。
116.寻找峰值 (中等)
题目描述
峰值元素是指其值严格大于左右相邻值的元素。
给你一个整数数组
nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。你可以假设
nums[-1] = nums[n] = -∞。你必须实现时间复杂度为
O(log n)的算法来解决此问题。示例 1:输入: nums =
[1,2,3,1]输出: 2 **解释:**3 是峰值元素,你的函数应该返回其索引 2。示例 2:输入: nums =
[1,2,1,3,5,6,4] 输出: 1 或 5 **解释:**你的函数可以返回索引 1,其峰值元素为 2; 或者返回索引 5, 其峰值元素为 6。提示:
1 <= nums.length <= 1000-231 <= nums[i] <= 231 - 1- 对于所有有效的
i都有nums[i] != nums[i + 1]
解题思路
可见图论总结与编程练习_编程 图论-CSDN博客中的第55题。
117.搜索旋转排序数组(中等)
题目描述
整数数组
nums按升序排列,数组中的值 互不相同 。在传递给函数之前,
nums在预先未知的某个下标k(0 <= k < nums.length)上进行了 旋转 ,使数组变为[nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如,[0,1,2,4,5,6,7]在下标3处经旋转后可能变为[4,5,6,7,0,1,2]。给你 旋转后 的数组
nums和一个整数target,如果nums中存在这个目标值target,则返回它的下标,否则返回-1。你必须设计一个时间复杂度为
O(log n)的算法解决此问题。示例 1:输入: nums = [
4,5,6,7,0,1,2], target = 0 **输出:**4示例 2:输入: nums = [
4,5,6,7,0,1,2], target = 3 输出:-1示例 3:输入: nums = 1, target = 0 输出:-1
提示:
1 <= nums.length <= 5000-104 <= nums[i] <= 104nums中的每个值都 独一无二- 题目数据保证
nums在预先未知的某个下标上进行了旋转-104 <= target <= 104
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第66题。
118.在排序数组中查找元素的第一个和最后一个位置(中等)
题目描述
给你一个按照非递减顺序排列的整数数组
nums,和一个目标值target。请你找出给定目标值在数组中的开始位置和结束位置。如果数组中不存在目标值
target,返回[-1, -1]。你必须设计并实现时间复杂度为
O(log n)的算法解决此问题。示例 1:输入: nums = `5,7,7,8,8,10]`, target = 8 **输出:**\[3,4
示例 2:输入: nums = `5,7,7,8,8,10]`, target = 6 **输出:**\[-1,-1
示例 3:输入: nums = \[\], target = 0 输出:-1,-1
提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109nums是一个非递减数组-109 <= target <= 109
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第65题。
119.寻找旋转排序数组中的最小值(中等)
题目描述
已知一个长度为
n的数组,预先按照升序排列,经由1到n次 旋转 后,得到输入数组。例如,原数组nums = [0,1,2,4,5,6,7]在变化后可能得到:
- 若旋转
4次,则可以得到[4,5,6,7,0,1,2]- 若旋转
7次,则可以得到[0,1,2,4,5,6,7]注意,数组
[a[0], a[1], a[2], ..., a[n-1]]旋转一次 的结果为数组[a[n-1], a[0], a[1], a[2], ..., a[n-2]]。给你一个元素值 互不相同 的数组
nums,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。你必须设计一个时间复杂度为
O(log n)的算法解决此问题。示例 1:输入: nums = 3,4,5,1,2 输出: 1 **解释:**原数组为 1,2,3,4,5 ,旋转 3 次得到输入数组。
示例 2:输入: nums = 4,5,6,7,0,1,2 输出: 0 **解释:**原数组为 0,1,2,4,5,6,7 ,旋转 3 次得到输入数组。
示例 3:输入: nums = 11,13,15,17 输出: 11 **解释:**原数组为 11,13,15,17 ,旋转 4 次得到输入数组。
提示:
n == nums.length1 <= n <= 5000-5000 <= nums[i] <= 5000nums中的所有整数 互不相同nums原来是一个升序排序的数组,并进行了1至n次旋转
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第67题。
120.寻找两个正序数组的中位数 (困难)
题目描述
给定两个大小分别为
m和n的正序(从小到大)数组nums1和nums2。请你找出并返回这两个正序数组的 中位数 。算法的时间复杂度应该为
O(log (m+n))。示例 1:输入: nums1 = 1,3, nums2 = 2 输出: 2.00000 **解释:**合并数组 = 1,2,3 ,中位数 2
示例 2:输入: nums1 = 1,2, nums2 = 3,4 输出: 2.50000 **解释:**合并数组 = 1,2,3,4 ,中位数 (2 + 3) / 2 = 2.5
提示:
nums1.length == mnums2.length == n0 <= m <= 10000 <= n <= 10001 <= m + n <= 2000-106 <= nums1[i], nums2[i] <= 106
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第68题。
十九、堆
121.数组中的第K个最大元素(中等)
题目描述
给定整数数组
nums和整数k,请返回数组中第 k 个最大的元素。请注意,你需要找的是数组排序后的第
k个最大的元素,而不是第k个不同的元素。你必须设计并实现时间复杂度为
O(n)的算法解决此问题。示例 1:输入:
[3,2,1,5,6,4],k = 2 输出: 5示例 2:输入:
[3,2,3,1,2,4,5,5,6],k = 4 输出: 4提示:
1 <= k <= nums.length <= 105-104 <= nums[i] <= 104
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第74题。
122. IPO(困难)
题目描述
假设 力扣(LeetCode)即将开始 IPO 。为了以更高的价格将股票卖给风险投资公司,力扣 希望在 IPO 之前开展一些项目以增加其资本。 由于资源有限,它只能在 IPO 之前完成最多
k个不同的项目。帮助 力扣 设计完成最多k个不同项目后得到最大总资本的方式。给你
n个项目。对于每个项目i,它都有一个纯利润profits[i],和启动该项目需要的最小资本capital[i]。最初,你的资本为
w。当你完成一个项目时,你将获得纯利润,且利润将被添加到你的总资本中。总而言之,从给定项目中选择 最多
k个不同项目的列表,以 最大化最终资本 ,并输出最终可获得的最多资本。答案保证在 32 位有符号整数范围内。
示例 1:输入: k = 2, w = 0, profits = 1,2,3, capital = 0,1,1 输出: 4 **解释:**由于你的初始资本为 0,你仅可以从 0 号项目开始。 在完成后,你将获得 1 的利润,你的总资本将变为 1。 此时你可以选择开始 1 号或 2 号项目。 由于你最多可以选择两个项目,所以你需要完成 2 号项目以获得最大的资本。 因此,输出最后最大化的资本,为 0 + 1 + 3 = 4。
示例 2:输入: k = 3, w = 0, profits = 1,2,3, capital = 0,1,2 **输出:**6
提示:
1 <= k <= 1050 <= w <= 109n == profits.lengthn == capital.length1 <= n <= 1050 <= profits[i] <= 1040 <= capital[i] <= 109
解题思路
这个问题涉及到选择最多 k 个项目,使得最终资本最大化。由于项目有启动资本限制,我们需要在每个阶段选择当前资本 w 能够支持的、利润最高的项目。这就需要一种策略来动态选择项目。
-
项目按所需资本排序 :首先,我们将所有项目按照所需的资本
capital[i]进行排序。这样我们可以按顺序考虑可以启动的项目。 -
优先选择高利润项目:为了在每次选择项目时获得最大的利润,我们可以使用一个最大堆(大根堆)来存储当前资本范围内可启动项目的利润。
-
迭代选择项目:
初始化时,首先将当前资本
w能够启动的所有项目的利润放入最大堆中。然后从堆中选出利润最高的项目,更新资本w,并继续从剩余项目中添加能够启动的项目到堆中,重复k次或直到没有更多项目可以选择。
复杂度分析
- 时间复杂度 :项目排序的时间复杂度为 O(nlogn)O(n \log n)O(nlogn),每次从堆中选取项目并插入新项目的时间复杂度为 O(logn)O(\log n)O(logn),最多执行
k次,因此整体时间复杂度为 O(nlogn+klogn)O(n \log n + k \log n)O(nlogn+klogn)。 - 空间复杂度:由于需要使用堆存储项目的利润,空间复杂度为 O(n)O(n)O(n)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.heap;
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.PriorityQueue;
/**
* @program: zyfboot-javabasic
* @description: IPO
* @author: zhangyanfeng
* @create: 2024-08-25 18:43
**/
public class MaximizedCapital {
// 主方法,用于计算在选择最多 k 个项目后可以获得的最大资本
public int findMaximizedCapital(int k, int w, int[] profits, int[] capital) {
// 项目数
int n = profits.length;
// 项目列表(每个项目包括资本需求和利润)
int[][] projects = new int[n][2];
for (int i = 0; i < n; i++) {
projects[i][0] = capital[i]; // 资本需求
projects[i][1] = profits[i]; // 利润
}
// 按资本需求升序排序
Arrays.sort(projects, Comparator.comparingInt(a -> a[0]));
// 最大堆,用于存储当前资本 w 能够启动的项目利润
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());
int index = 0; // 用于遍历项目
// 选择最多 k 个项目
for (int i = 0; i < k; i++) {
// 将所有当前资本 w 能启动的项目的利润加入堆中
while (index < n && projects[index][0] <= w) {
maxHeap.offer(projects[index][1]);
index++;
}
// 如果堆中有可选项目,选择利润最大的项目
if (!maxHeap.isEmpty()) {
w += maxHeap.poll(); // 更新资本
} else {
break; // 如果没有更多可选项目,直接结束
}
}
return w; // 返回最终的资本
}
// 测试代码
public static void main(String[] args) {
MaximizedCapital solution = new MaximizedCapital();
int k = 2, w = 0;
int[] profits = {1, 2, 3};
int[] capital = {0, 1, 1};
int result = solution.findMaximizedCapital(k, w, profits, capital);
System.out.println(result); // 输出应为 4
}
}123. 查找和最小的 K 对数字(中等)
题目描述
给定两个以 非递减顺序排列 的整数数组
nums1和nums2, 以及一个整数k。定义一对值
(u,v),其中第一个元素来自nums1,第二个元素来自nums2。请找到和最小的
k个数对(u1,v1),(u2,v2)...(uk,vk)。示例 1:输入: nums1 = 1,7,11, nums2 = 2,4,6, k = 3 输出: 1,2,1,4,1,6 **解释:**返回序列中的前 3 对数: 1,2,1,4,1,6,7,2,7,4,11,2,7,6,11,4,11,6
示例 2:输入: nums1 = 1,1,2, nums2 = 1,2,3, k = 2 输出: 1,1,1,1 **解释:**返回序列中的前 2 对数: 1,1,1,1,1,2,2,1,1,2,2,2,1,3,1,3,2,3
提示:
1 <= nums1.length, nums2.length <= 105-109 <= nums1[i], nums2[i] <= 109nums1和nums2均为 升序排列1 <= k <= 104k <= nums1.length * nums2.length
解题思路
题目要求在两个有序数组 nums1 和 nums2 中找到和最小的 k 对数对 (u,v)。由于两个数组是有序的,因此可以利用最小堆(优先队列)来高效地找到这些数对。
-
初始堆构建 :将所有可能的数对中的前
k对数对放入最小堆中。具体来说,可以只考虑nums1中前k个元素与nums2第一个元素的配对(nums1[i], nums2[0])放入堆中,因为这些是可能的最小组合。 -
堆操作 :每次从堆中取出最小的数对
(nums1[i], nums2[j]),然后将其后继组合(nums1[i], nums2[j+1])入堆。这样可以确保找到最小的k个数对。 -
终止条件 :堆中取出
k个元素后停止,或者堆为空时停止。
复杂度分析
-
时间复杂度 :初始堆的构建需要
O(k log k)时间,而每次堆操作的插入和删除都是O(log k)。由于我们最多需要进行k次这样的操作,所以总时间复杂度为O(k log k)。 -
空间复杂度 :堆的空间复杂度为
O(k),因此总的空间复杂度为O(k)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.heap;
import java.util.ArrayList;
import java.util.List;
import java.util.PriorityQueue;
/**
* @program: zyfboot-javabasic
* @description: 查找和最小的K对数字
* @author: zhangyanfeng
* @create: 2024-08-25 18:47
**/
public class KSmallestPairs {
public List<List<Integer>> kSmallestPairs(int[] nums1, int[] nums2, int k) {
// 最小堆,用于存储数对的索引 [i, j]
PriorityQueue<int[]> pq = new PriorityQueue<>(k, (o1, o2) -> {
return nums1[o1[0]] + nums2[o1[1]] - nums1[o2[0]] - nums2[o2[1]];
});
// 结果列表
List<List<Integer>> ans = new ArrayList<>();
int m = nums1.length;
int n = nums2.length;
// 初始化堆,放入 nums1 的前 k 个元素与 nums2 第一个元素的组合
for (int i = 0; i < Math.min(m, k); i++) {
pq.offer(new int[]{i, 0});
}
// 取出最小的 k 个数对
while (k-- > 0 && !pq.isEmpty()) {
int[] idxPair = pq.poll(); // 取出最小和的数对索引
List<Integer> list = new ArrayList<>();
list.add(nums1[idxPair[0]]);
list.add(nums2[idxPair[1]]);
ans.add(list);
// 若 j + 1 还在数组范围内,继续将 (i, j+1) 放入堆中
if (idxPair[1] + 1 < n) {
pq.offer(new int[]{idxPair[0], idxPair[1] + 1});
}
}
return ans;
}
}124.数据流的中位数(困难)
题目描述
中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
- 例如
arr = [2,3,4]的中位数是3。- 例如
arr = [2,3]的中位数是(2 + 3) / 2 = 2.5。实现 MedianFinder 类:
MedianFinder()初始化MedianFinder对象。
void addNum(int num)将数据流中的整数num添加到数据结构中。
double findMedian()返回到目前为止所有元素的中位数。与实际答案相差10-5以内的答案将被接受。示例 1:输入 "MedianFinder", "addNum", "addNum", "findMedian", "addNum", "findMedian" \[, 1, 2, \[\], 3, \[\]] 输出 null, null, null, 1.5, null, 2.0 解释 MedianFinder medianFinder = new MedianFinder(); medianFinder.addNum(1); // arr = 1 medianFinder.addNum(2); // arr = 1, 2 medianFinder.findMedian(); // 返回 1.5 ((1 + 2) / 2) medianFinder.addNum(3); // arr1, 2, 3 medianFinder.findMedian(); // return 2.0
提示:
-105 <= num <= 105- 在调用
findMedian之前,数据结构中至少有一个元素- 最多
5 * 104次调用addNum和findMedian
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第76题。
**二十、**位运算
125. 二进制求和(简单)
题目描述
给你两个二进制字符串
a和b,以二进制字符串的形式返回它们的和。示例 1:输入: a = "11", b = "1" 输出:"100"
示例 2:输入: a = "1010", b = "1011" 输出:"10101"
提示:
1 <= a.length, b.length <= 104a和b仅由字符'0'或'1'组成- 字符串如果不是
"0",就不含前导零
解题思路
我们要对两个二进制字符串 a 和 b 进行逐位相加,并且考虑进位的问题。由于二进制只有 0 和 1,逻辑相对简单。我们从两个字符串的最低位(末尾)开始逐位相加,如果某一位的和大于等于 2,则产生一个进位。继续处理更高位,直到处理完所有位或者处理完进位。解题步骤:
-
初始化指针和进位 :使用两个指针
i和j分别指向字符串a和b的末尾。初始化进位carry为 0。初始化结果字符串StringBuilder result。 -
逐位相加 :从
i和j逐位向前遍历,计算当前位的和,并考虑前一次的进位carry。根据当前位的和,决定是否有新的进位,并将结果的当前位存储到result中。 -
处理剩余的进位:如果遍历完成后仍有进位,则将进位加到结果中。
-
返回结果 :由于
result是从低位开始构建的,最终需要将其反转后返回。
复杂度分析
-
时间复杂度 :
O(max(m, n)),其中m和n分别是字符串a和b的长度。我们最多需要遍历较长的字符串。 -
空间复杂度 :
O(max(m, n)),用于存储结果字符串的空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.binary;
/**
* @program: zyfboot-javabasic
* @description: 二进制求和
* @author: zhangyanfeng
* @create: 2024-08-25 18:54
**/
public class AddBinary {
public String addBinary(String a, String b) {
// 使用 StringBuilder 来存储结果
StringBuilder result = new StringBuilder();
// 初始化指针 i 和 j 分别指向 a 和 b 的末尾
int i = a.length() - 1;
int j = b.length() - 1;
// 初始化进位 carry
int carry = 0;
// 遍历 a 和 b
while (i >= 0 || j >= 0) {
// 获取当前位的值,如果指针已经超出字符串范围,则认为当前位为 0
int bitA = (i >= 0) ? a.charAt(i) - '0' : 0;
int bitB = (j >= 0) ? b.charAt(j) - '0' : 0;
// 计算当前位的和(包括进位)
int sum = bitA + bitB + carry;
// 计算新的进位(如果 sum >= 2 则有进位)
carry = sum / 2;
// 将 sum 的余数添加到结果中
result.append(sum % 2);
// 指针向前移动
i--;
j--;
}
// 如果遍历结束后仍有进位,则需要添加到结果中
if (carry != 0) {
result.append(carry);
}
// 最终需要将结果反转并返回
return result.reverse().toString();
}
}126. 颠倒二进制位(简单)
题目描述
颠倒给定的 32 位无符号整数的二进制位。
提示:
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
- 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在 示例 2 中,输入表示有符号整数
-3,输出表示有符号整数-1073741825。示例 1:输入: n = 00000010100101000001111010011100 输出: 964176192 (00111001011110000010100101000000) 解释: 输入的二进制串 00000010100101000001111010011100 表示无符号整数43261596 , 因此返回 964176192,其二进制表示形式为 00111001011110000010100101000000。
示例 2:输入: n = 11111111111111111111111111111101 输出: 3221225471 (10111111111111111111111111111111) 解释: 输入的二进制串 11111111111111111111111111111101 表示无符号整数 4294967293, 因此返回 3221225471 其二进制表示形式为 10111111111111111111111111111111 。
提示:
- 输入是一个长度为
32的二进制字符串进阶: 如果多次调用这个函数,你将如何优化你的算法?
解题思路
我们要颠倒一个32位无符号整数的二进制位,这意味着将最左边的位与最右边的位交换,依次向中间靠拢,直到完成整个二进制串的反转。可以使用位运算来完成这个任务。具体步骤如下:
-
初始化结果 :初始化一个变量
result,用于存储最终的反转结果。 -
逐位反转:
我们将输入整数
n的每一位取出,并将其加入到result的相应位置。具体来说,将n右移一位,并将n的最低位(取出)加入到result的最高位(通过左移操作)。重复这一过程32次。 -
返回结果 :返回
result即可得到反转后的二进制整数。
复杂度分析
- 时间复杂度 :
O(1)。虽然我们需要循环32次,但由于32是常数,因此时间复杂度为O(1)。 - 空间复杂度 :
O(1)。仅使用了几个额外的变量来存储中间结果和最终结果,空间复杂度为O(1)。
代码实现
java
package org.zyf.javabasic.letcode.jd150.binary;
/**
* @program: zyfboot-javabasic
* @description: 颠倒二进制位
* @author: zhangyanfeng
* @create: 2024-08-25 18:57
**/
public class ReverseBits {
// 颠倒32位无符号整数的二进制位
public int reverseBits(int n) {
// 初始化结果为0
int result = 0;
// 遍历32位
for (int i = 0; i < 32; i++) {
// 将result左移1位,为下一个反转位腾出空间
result <<= 1;
// 将n的最低位加到result的最低位
result |= (n & 1);
// 将n右移1位,处理下一个位
n >>= 1;
}
// 返回反转后的结果
return result;
}
}127. 位1的个数(简单)
题目描述
编写一个函数,获取一个正整数的二进制形式并返回其二进制表达式中 设置位 的个数(也被称为汉明重量)。
示例 1:输入: n = 11 输出: 3 解释: 输入的二进制串 1011
中,共有 3 个设置位。示例 2:输入: n = 128 输出: 1 解释: 输入的二进制串 10000000 中,共有 1 个设置位。
示例 3:输入: n = 2147483645 输出: 30 解释: 输入的二进制串 11111111111111111111111111111101 中,共有 30 个设置位。
提示:
1 <= n <= 231 - 1
解题思路
可见数学思维编程练习总结_编程中的数学思维-CSDN博客中的第11题。
可见剑指offer所有编程练习总结分析_currentsum -= small++-CSDN博客中的第36题。
128**.** 只出现一次的数字 (简单)
题目描述
给你一个 非空 整数数组
nums,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
示例 1 :输入: nums = 2,2,1 **输出:**1
示例 2 :输入: nums = 4,1,2,1,2 **输出:**4
示例 3 :输入: nums = 1 **输出:**1
提示:
1 <= nums.length <= 3 * 104-3 * 104 <= nums[i] <= 3 * 104- 除了某个元素只出现一次以外,其余每个元素均出现两次。
解题思路
可见LeetCode 精选 75 回顾-CSDN博客中的第68题。
129. 只出现一次的数字 II(中等)
题目描述
给你一个整数数组
nums,除某个元素仅出现 一次 外,其余每个元素都恰出现 **三次 。**请你找出并返回那个只出现了一次的元素。你必须设计并实现线性时间复杂度的算法且使用常数级空间来解决此问题。
示例 1:输入: nums = 2,2,3,2 **输出:**3
示例 2:输入: nums = 0,1,0,1,0,1,99 **输出:**99
提示:
1 <= nums.length <= 3 * 104-231 <= nums[i] <= 231 - 1nums中,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次
解题思路
对于一个整数,如果我们考虑它的每一位(0或1),那么对于出现了三次的元素来说,某一位上的1出现的次数必然是3的倍数。而对于仅出现一次的元素来说,其某些位上的1不会是3的倍数。因此,我们可以通过统计数组中每一位上1出现的次数,并对3取模,结果就是仅出现一次的元素在该位上的值。具体步骤
-
初始化两个变量
ones和twos用于记录位的状态。其中:ones表示在当前位出现了1次的数。twos表示在当前位出现了2次的数。 -
对数组中的每个数进行如下操作:更新
ones和twos的值,考虑当前位是否被当前数占用。 -
最终,
ones的值即为仅出现一次的元素。
复杂度分析
- 时间复杂度:O(n),其中 n 是数组的长度。我们仅需遍历数组一次。
- 空间复杂度:O(1),只使用了常数个额外变量。
代码实现
java
package org.zyf.javabasic.letcode.jd150.binary;
/**
* @program: zyfboot-javabasic
* @description: 只出现一次的数字 II
* @author: zhangyanfeng
* @create: 2024-08-25 19:05
**/
public class SingleNumber {
public int singleNumber(int[] nums) {
// ones记录出现1次的位,twos记录出现2次的位
int ones = 0, twos = 0;
for (int num : nums) {
// 更新ones,twos的值
ones = (ones ^ num) & ~twos;
twos = (twos ^ num) & ~ones;
}
// 返回ones,表示那个只出现一次的数
return ones;
}
}130. 数字范围按位与(中等)
题目描述
给你两个整数
left和right,表示区间[left, right],返回此区间内所有数字 按位与 的结果(包含left、right端点)。示例 1:输入: left = 5, right = 7 **输出:**4
示例 2:输入: left = 0, right = 0 **输出:**0
示例 3:输入: left = 1, right = 2147483647 **输出:**0
提示:
0 <= left <= right <= 231 - 1
解题思路
对于给定的区间 left,right,要求返回区间内所有数字的按位与的结果。按位与操作的特性决定了,如果区间范围较大,那么结果将会受到范围内的低位影响。我们可以通过找到 left 和 right 的公共前缀,来减少计算的复杂度。
-
关键观察:如果我们对连续的数字进行按位与操作,那么每次操作可能都会清除低位上的1。最终结果取决于 left 和 right 在高位的公共前缀。
-
具体做法:将 left 和 right 一直右移,直到它们相等。记录右移的次数 shift,最终将相等的值左移回原位置,即为结果。
具体步骤
- 初始化
shift为0,用来记录右移的次数。 - 不断右移
left和right,直到left == right。 - 将最终相等的
left左移shift次,即为最终结果。
复杂度分析
- 时间复杂度:O(log(right)),因为我们在计算过程中将数字右移,最多右移 O(log(right))次。
- 空间复杂度:O(1),只使用了常数个额外变量。
代码实现
java
package org.zyf.javabasic.letcode.jd150.binary;
/**
* @program: zyfboot-javabasic
* @description: 数字范围按位与
* @author: zhangyanfeng
* @create: 2024-08-25 19:11
**/
public class RangeBitwiseAnd {
public int rangeBitwiseAnd(int left, int right) {
int shift = 0;
// 不断右移left和right,直到它们相等
while (left < right) {
left >>= 1;
right >>= 1;
shift++;
}
// 将相等的left左移回原位置
return left << shift;
}
}二十一、数学
131. 回文数(简单)
题目描述
给你一个整数
x,如果x是一个回文整数,返回true;否则,返回false。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
- 例如,
121是回文,而123不是。示例 1:输入: x = 121 **输出:**true
示例 2:输入: x = -121 输出: false **解释:**从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
示例 3:输入: x = 10 输出: false **解释:**从右向左读, 为 01 。因此它不是一个回文数。
提示:
-231 <= x <= 231 - 1**进阶:**你能不将整数转为字符串来解决这个问题吗?
解题思路
具体可见数学思维编程练习总结_编程中的数学思维-CSDN博客中的第6题。
132. 加一(简单)
题目描述
给定一个由 整数 组成的非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:输入: digits = 1,2,3 输出: 1,2,4 **解释:**输入数组表示数字 123。
示例 2:输入: digits = 4,3,2,1 输出: 4,3,2,2 **解释:**输入数组表示数字 4321。
示例 3:输入: digits = 0 输出:1
提示:
1 <= digits.length <= 1000 <= digits[i] <= 9
解题思路
具体可见数组知识及编程练习总结-CSDN博客中的第8题。
133. 阶乘后的零(中等)
题目描述 给定一个整数
n,返回n!结果中尾随零的数量。提示
n! = n * (n - 1) * (n - 2) * ... * 3 * 2 * 1示例 1:输入: n = 3 输出: 0 **解释:**3! = 6 ,不含尾随 0
示例 2:输入: n = 5 输出: 1 **解释:**5! = 120 ,有一个尾随 0
示例 3:输入: n = 0 **输出:**0
提示:
0 <= n <= 104**进阶:**你可以设计并实现对数时间复杂度的算法来解决此问题吗?
解题思路
具体可见数学思维编程练习总结_编程中的数学思维-CSDN博客中的第20题。
134. x 的平方根(中等)
题目描述
给你一个非负整数
x,计算并返回x的 算术平方根 。由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意: 不允许使用任何内置指数函数和算符,例如
pow(x, 0.5)或者x ** 0.5。示例 1:输入: x = 4 **输出:**2
示例 2:输入: x = 8 输出: 2 **解释:**8 的算术平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。
提示:
0 <= x <= 231 - 1
解题思路
具体可见数学思维编程练习总结_编程中的数学思维-CSDN博客中的第22题。
135. Pow(x, n)(中等)
题目描述
实现 pow(x, n) ,即计算
x的整数n次幂函数(即,xn)。示例 1:输入: x = 2.00000, n = 10 **输出:**1024.00000
示例 2:输入: x = 2.10000, n = 3 **输出:**9.26100
示例 3:输入: x = 2.00000, n = -2 输出: 0.25000 **解释:**2-2 = 1/22 = 1/4 = 0.25
提示:
-100.0 < x < 100.0-231 <= n <= 231-1n是一个整数- 要么
x不为零,要么n > 0。-104 <= xn <= 104
解题思路
具体可见数学思维编程练习总结_编程中的数学思维-CSDN博客中的第23题。
136. 直线上最多的点数(困难)
题目描述
给你一个数组
points,其中points[i] = [xi, yi]表示 X-Y 平面上的一个点。求最多有多少个点在同一条直线上。示例 1:
输入:points = [[1,1],[2,2],[3,3]] 输出:3示例 2:
输入:points = [[1,1],[3,2],[5,3],[4,1],[2,3],[1,4]] 输出:4提示:
1 <= points.length <= 300points[i].length == 2-104 <= xi, yi <= 104points中的所有点 互不相同


解题思路
要找出在同一条直线上的最多点数,可以利用斜率的概念。具体思路如下:
-
固定一个点作为基准点 :对于每个点
i,计算它与其他点j(j ≠ i)之间的斜率。斜率相同的点必然在同一条直线上。 -
使用哈希表统计斜率 :用一个哈希表来记录当前基准点
i与其他点j之间的斜率出现的次数。相同斜率的点数越多,说明这些点与基准点在同一条直线上。 -
特殊情况处理:
重合点 :如果两个点坐标完全相同,需要单独计数。垂直线:当两点的 x 坐标相同,斜率为无穷大,此时用特定值来表示这种情况。
-
最大点数计算:对于每个基准点,找到斜率最多的那一组点,加上基准点本身以及任何重合的点数,就可以得到以该点为基准的最大点数。最终的结果是所有基准点下的最大值。
复杂度分析
- 时间复杂度 :
O(n^2),其中n是点的数量。每个点作为基准点时都要计算与其他n-1个点的斜率。 - 空间复杂度 :
O(n),用于存储斜率的哈希表。
代码实现
java
package org.zyf.javabasic.letcode.jd150.binary;
import java.util.HashMap;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 直线上最多的点数
* @author: zhangyanfeng
* @create: 2024-08-25 19:43
**/
public class MaxPoints {
public int maxPoints(int[][] points) {
int n = points.length;
if (n < 3) return n;
int maxPointsOnLine = 1;
for (int i = 0; i < n; i++) {
Map<String, Integer> slopeMap = new HashMap<>();
int duplicate = 0; // 记录与基准点重合的点数
int maxForCurrentPoint = 0;
for (int j = i + 1; j < n; j++) {
int deltaX = points[j][0] - points[i][0];
int deltaY = points[j][1] - points[i][1];
if (deltaX == 0 && deltaY == 0) {
// 基准点与某点重合
duplicate++;
continue;
}
// 化简分数形式的斜率
int gcd = gcd(deltaX, deltaY);
deltaX /= gcd;
deltaY /= gcd;
// 确保斜率的唯一性(处理垂直和水平的情况)
String slope = deltaX + "/" + deltaY;
slopeMap.put(slope, slopeMap.getOrDefault(slope, 0) + 1);
maxForCurrentPoint = Math.max(maxForCurrentPoint, slopeMap.get(slope));
}
// 计算基于当前基准点的最大点数
maxPointsOnLine = Math.max(maxPointsOnLine, maxForCurrentPoint + duplicate + 1);
}
return maxPointsOnLine;
}
// 计算最大公约数
private int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}
}二十二、一维动态规划
137.爬楼梯(简单)
题目描述
假设你正在爬楼梯。需要
n阶你才能到达楼顶。每次你可以爬
1或2个台阶。你有多少种不同的方法可以爬到楼顶呢?示例 1:输入: n = 2 输出: 2 **解释:**有两种方法可以爬到楼顶。 1. 1 阶 + 1 阶 2. 2 阶
示例 2:输入: n = 3 输出: 3 **解释:**有三种方法可以爬到楼顶。 1. 1 阶 + 1 阶 + 1 阶 2. 1 阶 + 2 阶 3. 2 阶 + 1 阶
提示:
1 <= n <= 45
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第81题。
138.打家劫舍(中等)
题目描述
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你不触动警报装置的情况下,一夜之内能够偷窃到的最高金额。
示例 1:输入: 1,2,3,1 输出: 4 **解释:**偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。 偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:输入: 2,7,9,3,1 输出: 12 **解释:**偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。 偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
1 <= nums.length <= 1000 <= nums[i] <= 400
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第83题。
139.单词拆分 (中等)
题目描述
给你一个字符串
s和一个字符串列表wordDict作为字典。如果可以利用字典中出现的一个或多个单词拼接出s则返回true。**注意:**不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:输入: s = "leetcode", wordDict = "leet", "code" 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:输入: s = "applepenapple", wordDict = "apple", "pen" 输出: true 解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。 注意,你可以重复使用字典中的单词。
示例 3:输入: s = "catsandog", wordDict = "cats", "dog", "sand", "and", "cat" 输出: false
提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅由小写英文字母组成wordDict中的所有字符串 互不相同
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第86题。
140.零钱兑换(中等)
题目描述
给你一个整数数组
coins,表示不同面额的硬币;以及一个整数amount,表示总金额。计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回
-1。你可以认为每种硬币的数量是无限的。
示例 1:输入: coins =
[1, 2, 5], amount =11输出:3**解释:**11 = 5 + 5 + 1示例 2:输入: coins =
[2], amount =3输出:-1示例 3:输入: coins = 1, amount = 0 **输出:**0
提示:
1 <= coins.length <= 121 <= coins[i] <= 231 - 10 <= amount <= 104
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第85题。
141.最长递增子序列 (中等)
题目描述
给你一个整数数组
nums,找到其中最长严格递增子序列的长度。子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,
[3,6,2,7]是数组[0,3,1,6,2,2,7]的子序列。示例 1:输入: nums = 10,9,2,5,3,7,101,18 输出: 4 **解释:**最长递增子序列是 2,3,7,101,因此长度为 4 。
示例 2:输入: nums = 0,1,0,3,2,3 **输出:**4
示例 3:输入: nums = 7,7,7,7,7,7,7 **输出:**1
提示:
1 <= nums.length <= 2500-104 <= nums[i] <= 104进阶: 你能将算法的时间复杂度降低到
O(n log(n))吗?
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第87题。
**二十三、**多维动态规划
142. 三角形最小路径和(中等)
题目描述
给定一个三角形
triangle,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标
i,那么下一步可以移动到下一行的下标i或i + 1。示例 1:
输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]] 输出:11 解释:如下面简图所示: 2 3 4 6 5 7 4 1 8 3 自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。示例 2:输入: triangle = \[-10] 输出:-10
提示:
1 <= triangle.length <= 200triangle[0].length == 1triangle[i].length == triangle[i - 1].length + 1-104 <= triangle[i][j] <= 104进阶:
- 你可以只使用
O(n)的额外空间(n为三角形的总行数)来解决这个问题吗?
解题思路
要解决三角形最小路径和的问题,可以采用动态规划(Dynamic Programming)的方法。该方法能够有效地在三角形结构中计算自顶向下的最小路径和。
-
自底向上动态规划:
我们可以从三角形的底部开始,逐行向上计算每个元素的最小路径和。对于每个元素
triangle[i][j],其最小路径和可以通过其下一行的两个相邻元素triangle[i+1][j]和triangle[i+1][j+1]的最小值来确定。状态转移方程:dp[i][j] = triangle[i][j] + min(dp[i+1][j], dp[i+1][j+1])。 -
空间优化:
我们可以直接在原三角形数组上进行修改,使得最终顶部元素保存的是从顶到底的最小路径和。这样,空间复杂度可以降到 O(n),其中 n 是三角形的行数。
复杂度分析
- 时间复杂度:O(n^2),其中 n 是三角形的行数。我们需要遍历整个三角形的每个元素一次。
- 空间复杂度:O(1),我们直接在原数组上进行操作,不需要额外的空间。
代码实现
java
package org.zyf.javabasic.letcode.jd150.dynamic;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 三角形最小路径和
* @author: zhangyanfeng
* @create: 2024-08-25 19:53
**/
public class MinimumTotal {
public int minimumTotal(List<List<Integer>> triangle) {
int n = triangle.size();
// 从倒数第二行开始,自底向上计算最小路径和
for (int i = n - 2; i >= 0; i--) {
for (int j = 0; j <= i; j++) {
// 当前元素加上下一行的两个相邻元素的最小值
triangle.get(i).set(j, triangle.get(i).get(j) +
Math.min(triangle.get(i + 1).get(j), triangle.get(i + 1).get(j + 1)));
}
}
// 最顶端元素即为最小路径和
return triangle.get(0).get(0);
}
}143.最小路径和(中等)
题目描述
给定一个包含非负整数的 m
xn 网格grid,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。**说明:**每次只能向下或者向右移动一步。
示例 1:
输入:grid = [[1,3,1],[1,5,1],[4,2,1]] 输出:7 解释:因为路径 1→3→1→1→1 的总和最小。示例 2:输入: grid = \[1,2,3,4,5,6] **输出:**12
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 2000 <= grid[i][j] <= 200

解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第92题。
144. 不同路径 II(中等)
题目描述
一个机器人位于一个
m x n网格的左上角 (起始点在下图中标记为 "Start" )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 "Finish")。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用
1和0来表示。示例 1:
输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]] 输出:2 解释:3x3 网格的正中间有一个障碍物。 从左上角到右下角一共有 2 条不同的路径: 1. 向右 -> 向右 -> 向下 -> 向下 2. 向下 -> 向下 -> 向右 -> 向右示例 2:
输入:obstacleGrid = [[0,1],[0,0]] 输出:1提示:
m == obstacleGrid.lengthn == obstacleGrid[i].length1 <= m, n <= 100obstacleGrid[i][j]为0或1


解题思路
要计算从网格的左上角到右下角的所有不同路径数量,考虑网格中可能存在的障碍物,我们可以使用动态规划(Dynamic Programming)来解决这个问题:
-
动态规划表格 :使用一个二维数组
dp,其中dp[i][j]表示从(0,0)到(i,j)的不同路径数量。 -
初始化 :
dp[0][0]初始化为 1,如果起点(0,0)处有障碍物,则dp[0][0]为 0,因为机器人不能从起点开始。如果网格的第一行或第一列有障碍物,后续的路径数也应该为 0。 -
状态转移 :对于每个位置
(i,j),如果obstacleGrid[i][j]为 0(无障碍物),那么dp[i][j]可以由上方(i-1,j)或左方(i,j-1)位置的路径数得出:dpij = (i > 0 ? dpi-1j : 0) + (j > 0 ? dpij-1 : 0);如果obstacleGrid[i][j]为 1(有障碍物),则dp[i][j]为 0。 -
结果 :最终的结果是
dp[m-1][n-1],即网格右下角的路径数量。
复杂度分析
- 时间复杂度:O(m * n),我们需要遍历整个网格。
- 空间复杂度:O(m * n),需要额外的二维数组来存储路径数量。
代码实现
java
package org.zyf.javabasic.letcode.jd150.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 不同路径 II
* @author: zhangyanfeng
* @create: 2024-08-25 20:00
**/
public class UniquePathsWithObstacles {
public int uniquePathsWithObstacles(int[][] obstacleGrid) {
int m = obstacleGrid.length; // 行数
int n = obstacleGrid[0].length; // 列数
// 创建一个二维数组 dp,用于存储从 (0,0) 到 (i,j) 的路径数量
int[][] dp = new int[m][n];
// 初始化 dp 数组
// 如果起点有障碍物,则直接返回 0
if (obstacleGrid[0][0] == 1) {
return 0;
}
dp[0][0] = 1; // 起点到起点的路径数为 1
// 填充第一行
for (int j = 1; j < n; j++) {
dp[0][j] = (obstacleGrid[0][j] == 0 && dp[0][j-1] == 1) ? 1 : 0;
}
// 填充第一列
for (int i = 1; i < m; i++) {
dp[i][0] = (obstacleGrid[i][0] == 0 && dp[i-1][0] == 1) ? 1 : 0;
}
// 填充其余的 dp 数组
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] == 0) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
} else {
dp[i][j] = 0; // 如果有障碍物,路径数为 0
}
}
}
// 返回右下角的路径数量
return dp[m-1][n-1];
}
}145.最长回文子串(中等)
题目描述
给你一个字符串
s,找到s中最长的 回文子串。示例 1:输入: s = "babad" 输出: "bab" 解释:"aba" 同样是符合题意的答案。
示例 2:输入: s = "cbbd" 输出:"bb"
提示:
1 <= s.length <= 1000s仅由数字和英文字母组成
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第93题。
146. 交错字符串(中等)
题目描述
给定三个字符串
s1、s2、s3,请你帮忙验证s3是否是由s1和s2交错组成的。两个字符串
s和t交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串:
s = s1 + s2 + ... + snt = t1 + t2 + ... + tm|n - m| <= 1- 交错 是
s1 + t1 + s2 + t2 + s3 + t3 + ...或者t1 + s1 + t2 + s2 + t3 + s3 + ...注意:
a + b意味着字符串a和b连接。示例 1:
输入:s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac" 输出:true示例 2:输入: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc" **输出:**false
示例 3:输入: s1 = "", s2 = "", s3 = "" **输出:**true
提示:
0 <= s1.length, s2.length <= 1000 <= s3.length <= 200s1、s2、和s3都由小写英文字母组成进阶: 您能否仅使用
O(s2.length)额外的内存空间来解决它?

解题思路
要验证字符串 s3 是否是由 s1 和 s2 交错组成的,可以使用动态规划(Dynamic Programming, DP)来实现。我们将定义一个二维数组 dp 来表示从 s1 和 s2 生成 s3 的可能性。解题思路:
-
定义状态 :使用一个二维布尔数组
dp,其中dp[i][j]表示s3的前i + j个字符是否可以由s1的前i个字符和s2的前j个字符交错组成。 -
初始化:
dp[0][0]=true,因为空字符串可以由两个空字符串交错组成。对于第一行(即i = 0),dp[0][j]取决于s2是否可以匹配s3的前j个字符。对于第一列(即j = 0),dp[i][0]取决于s1是否可以匹配s3的前i个字符。 -
状态转移:
对于每个位置
(i, j),如果dp[i][j]为true,则:如果j < len(s2)且s2[j]等于s3[i + j],则dp[i][j + 1]应该为true。如果i < len(s1)且s1[i]等于s3[i + j],则dp[i + 1][j]应该为true。 -
结果 :最终结果是
dp[len(s1)][len(s2)],即s1和s2是否能交错组成s3。
复杂度分析
- 时间复杂度 :O(m * n),其中
m和n分别是s1和s2的长度。需要遍历dp数组的每一个位置。 - 空间复杂度 :O(m * n),需要额外的二维数组
dp来存储中间结果。
代码实现
java
package org.zyf.javabasic.letcode.jd150.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 交错字符串
* @author: zhangyanfeng
* @create: 2024-08-25 20:05
**/
public class Interleave {
public boolean isInterleave(String s1, String s2, String s3) {
int m = s1.length();
int n = s2.length();
int l = s3.length();
// 如果 s1 和 s2 的长度之和不等于 s3 的长度,则不能交错组成 s3
if (m + n != l) {
return false;
}
// 创建 dp 数组
boolean[][] dp = new boolean[m + 1][n + 1];
// 初始化 dp 数组
dp[0][0] = true;
// 初始化第一行
for (int j = 1; j <= n; j++) {
dp[0][j] = dp[0][j - 1] && s2.charAt(j - 1) == s3.charAt(j - 1);
}
// 初始化第一列
for (int i = 1; i <= m; i++) {
dp[i][0] = dp[i - 1][0] && s1.charAt(i - 1) == s3.charAt(i - 1);
}
// 填充 dp 数组
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
dp[i][j] = (dp[i - 1][j] && s1.charAt(i - 1) == s3.charAt(i + j - 1)) ||
(dp[i][j - 1] && s2.charAt(j - 1) == s3.charAt(i + j - 1));
}
}
// 返回结果
return dp[m][n];
}
}147.编辑距离(中等)
题目描述
给你两个单词
word1和word2, 请返回将word1转换成word2所使用的最少操作数 。你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:输入: word1 = "horse", word2 = "ros" 输出: 3 解释: horse -> rorse (将 'h' 替换为 'r') rorse -> rose (删除 'r') rose -> ros (删除 'e')
示例 2:输入: word1 = "intention", word2 = "execution" 输出: 5 解释: intention -> inention (删除 't') inention -> enention (将 'i' 替换为 'e') enention -> exention (将 'n' 替换为 'x') exention -> exection (将 'n' 替换为 'c') exection -> execution (插入 'u')
提示:
0 <= word1.length, word2.length <= 500word1和word2由小写英文字母组成
解题思路
具体可见LeetCode 热题 100 回顾-CSDN博客中的第95题。
148. 买卖股票的最佳时机 III(困难)
题目描述
给定一个数组,它的第
i个元素是一支给定的股票在第i天的价格。设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔交易。
**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:输入: prices = 3,3,5,0,0,3,1,4 输出: 6 **解释:**在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。 随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。
示例 2:输入: prices = 1,2,3,4,5 输出: 4 **解释:**在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:输入: prices = 7,6,4,3,1 输出: 0 **解释:**在这个情况下, 没有交易完成, 所以最大利润为 0。
示例 4:输入: prices = 1 **输出:**0
提示:
1 <= prices.length <= 1050 <= prices[i] <= 105
解题思路
要在数组 prices 中计算最多可以完成两笔交易的最大利润,我们可以使用动态规划来解决这个问题。具体地,我们可以将问题拆分为两个子问题:进行第一次交易和进行第二次交易。
我们定义四个变量:
buy1:第一次购买股票时的最大利润。sell1:第一次出售股票时的最大利润。buy2:第二次购买股票时的最大利润。sell2:第二次出售股票时的最大利润。
动态规划转移方程

复杂度分析
- 时间复杂度 :O(n),因为我们只需要遍历一次
prices数组。 - 空间复杂度:O(1),因为我们只使用了常数个额外变量。
代码实现
java
package org.zyf.javabasic.letcode.jd150.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 买卖股票的最佳时机 III
* @author: zhangyanfeng
* @create: 2024-08-25 20:11
**/
public class MaxProfit {
public int maxProfit(int[] prices) {
int n = prices.length; // 获取价格数组的长度
// 初始化动态规划状态变量
int buy1 = -prices[0], sell1 = 0; // 第一次购买和出售的初始状态
int buy2 = -prices[0], sell2 = 0; // 第二次购买和出售的初始状态
// 遍历每一天的价格
for (int i = 1; i < n; ++i) {
// 更新第一次购买的最大利润
buy1 = Math.max(buy1, -prices[i]);
// 更新第一次出售的最大利润
sell1 = Math.max(sell1, buy1 + prices[i]);
// 更新第二次购买的最大利润
buy2 = Math.max(buy2, sell1 - prices[i]);
// 更新第二次出售的最大利润
sell2 = Math.max(sell2, buy2 + prices[i]);
}
// 返回最多完成两笔交易的最大利润
return sell2;
}
}149. 买卖股票的最佳时机 IV(困难)
题目描述
给你一个整数数组
prices和一个整数k,其中prices[i]是某支给定的股票在第i天的价格。设计一个算法来计算你所能获取的最大利润。你最多可以完成
k笔交易。也就是说,你最多可以买k次,卖k次。**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:输入: k = 2, prices = 2,4,1 输出: 2 **解释:**在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。
示例 2:输入: k = 2, prices = 3,2,6,5,0,3 输出: 7 **解释:**在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。 随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
提示:
1 <= k <= 1001 <= prices.length <= 10000 <= prices[i] <= 1000
解题思路
对于这个问题,我们可以使用动态规划来求解。主要思路是构建一个二维动态规划表,其中 dp[t][d] 表示在第 d 天完成 t 次交易的最大利润。
动态规划状态定义
dp[t][d]:在第d天完成t次交易的最大利润。dp[t][d]需要利用前一天的状态和当天的价格来更新。
动态规划转移方程

复杂度分析
- 时间复杂度 :O(k * n^2),其中
n是价格数组的长度。因为我们在每次交易中需要遍历所有之前的价格,导致时间复杂度为O(n^2),而总共要处理k次交易。 - 空间复杂度 :O(k * n),因为我们需要一个
k x n的 DP 表。
代码实现
java
package org.zyf.javabasic.letcode.jd150.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 买卖股票的最佳时机 IV
* @author: zhangyanfeng
* @create: 2024-08-25 20:14
**/
public class MaxProfit2 {
public int maxProfit(int k, int[] prices) {
int n = prices.length;
if (n == 0) return 0;
// 如果交易次数 k 大于等于天数的一半,意味着可以进行无限次交易
if (k >= n / 2) {
int maxProfit = 0;
for (int i = 1; i < n; ++i) {
if (prices[i] > prices[i - 1]) {
maxProfit += prices[i] - prices[i - 1];
}
}
return maxProfit;
}
// dp[t][d] 表示第 d 天完成 t 次交易的最大利润
int[][] dp = new int[k + 1][n];
// 遍历每次交易
for (int t = 1; t <= k; ++t) {
// 在第 t 次交易时,初始化最优利润
int maxDiff = -prices[0];
// 遍历每一天
for (int d = 1; d < n; ++d) {
// 更新 dp[t][d],考虑不进行交易和进行交易两种情况
dp[t][d] = Math.max(dp[t][d - 1], prices[d] + maxDiff);
// 更新 maxDiff,为下一天的交易准备
maxDiff = Math.max(maxDiff, dp[t - 1][d] - prices[d]);
}
}
// 返回最多完成 k 次交易的最大利润
return dp[k][n - 1];
}
}150. 最大正方形(中等)
题目描述
在一个由
'0'和'1'组成的二维矩阵内,找到只包含'1'的最大正方形,并返回其面积。示例 1:
输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]] 输出:4示例 2:
输入:matrix = [["0","1"],["1","0"]] 输出:1示例 3:输入: matrix = \["0"] **输出:**0
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 300matrix[i][j]为'0'或'1'

解题思路

复杂度分析
- 时间复杂度 :O(m * n),其中
m是矩阵的行数,n是矩阵的列数。我们需要遍历每一个矩阵位置一次。 - 空间复杂度 :O(m * n),需要额外的空间来存储
dp表。
代码实现
java
package org.zyf.javabasic.letcode.jd150.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 最大正方形
* @author: zhangyanfeng
* @create: 2024-08-25 20:18
**/
public class MaximalSquare {
public int maximalSquare(char[][] matrix) {
int m = matrix.length;
if (m == 0) return 0;
int n = matrix[0].length;
// dp[i][j] 表示以 matrix[i][j] 为右下角的最大正方形的边长
int[][] dp = new int[m][n];
int maxSide = 0; // 记录最大正方形的边长
// 遍历矩阵
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// 只有 matrix[i][j] 为 '1' 时才有可能形成正方形
if (matrix[i][j] == '1') {
// 如果在第一行或第一列,dp[i][j] 只能为 1
if (i == 0 || j == 0) {
dp[i][j] = 1;
} else {
// 更新 dp[i][j] 的值
dp[i][j] = Math.min(Math.min(dp[i-1][j], dp[i][j-1]), dp[i-1][j-1]) + 1;
}
// 更新最大边长
maxSide = Math.max(maxSide, dp[i][j]);
}
}
}
// 返回最大正方形的面积
return maxSide * maxSide;
}
}