一、MySQL部署
1.源码编译
实验环境为rhel7
安装依赖性
root@mysql-node1 \~# yum install cmake gcc-c++ openssl-devel \ ncurses-devel.x86_64 libtirpc-devel-1.3.3-8.el9_4.x86_64.rpm rpcgen.x86_64 -y
root@mysql-node1 \~# tar zxf mysql-boost-5.7.44.tar.gz
源码编译安装
[root@mysql-node1 mysql-5.7.44]# cmake \
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql \
-DMYSQL_DATADIR=/data/mysql \
-DMYSQL_UNIX_ADDR=/data/mysql/mysql.sock \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DWITH_EXTRA_CHARSETS=all \
-DDEFAULT_CHARSET=utf8mb4 \
-DDEFAULT_COLLATION=utf8mb4_unicode_ci \
-DWITH_BOOST=/root/mysql-5.7.44/boost/boost_1_59_0/root@mysql-node1mysql-5.7.44# make -j2
root@mysql-node1 mysql-5.7.44# make install
2.部署mysql
root@mysql-node2 mysql# useradd -s /sbin/nologin -M mysql
root@mysql-node2 mysql# mkdir /data/mysql -p
root@mysql-node2 mysql# chown mysql.mysql -R /data/mysql
root@mysql-node2 mysql# cd support-files/
root@mysql-node2 support-files# cp mysql.server /etc/init.d/mysqld
root@mysql-node2 support-files# vim /etc/my.cnf
修改环境变量
root@mysql-node2 support-files# vim ~/.bash_profile
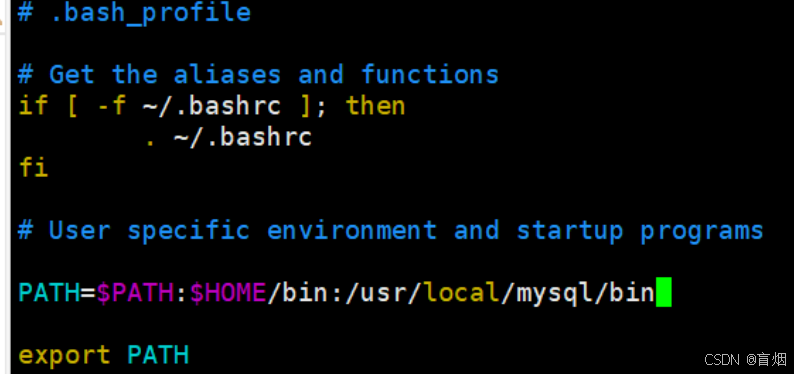
root@mysql-node2 support-files# source ~/.bash_profile
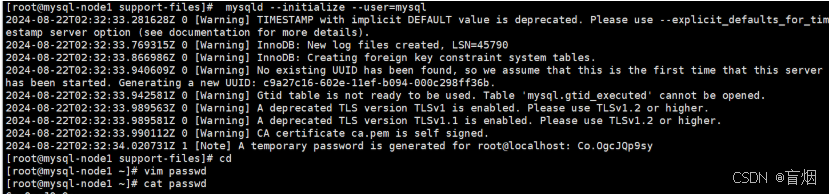
数据初始化
root@mysql-node2 support-files# mysqld --initialize --user=mysql
这里会生成一个初始化密码,保存该密码
root@mysql-node1 \~# /etc/init.d/mysqld start 启动mysql
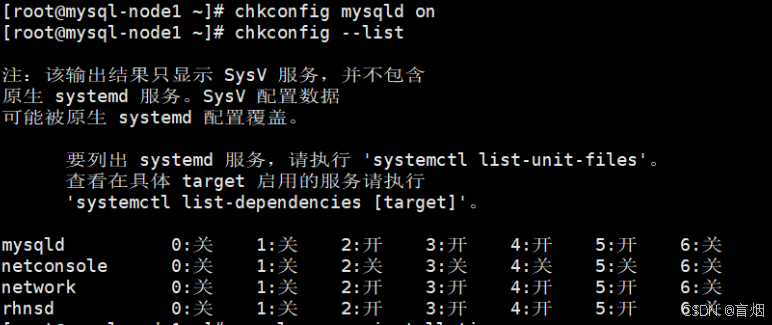
设置开机启动
root@mysql-node1 \~# chkconfig mysqld on
root@mysql-node1 \~# chkconfig --list
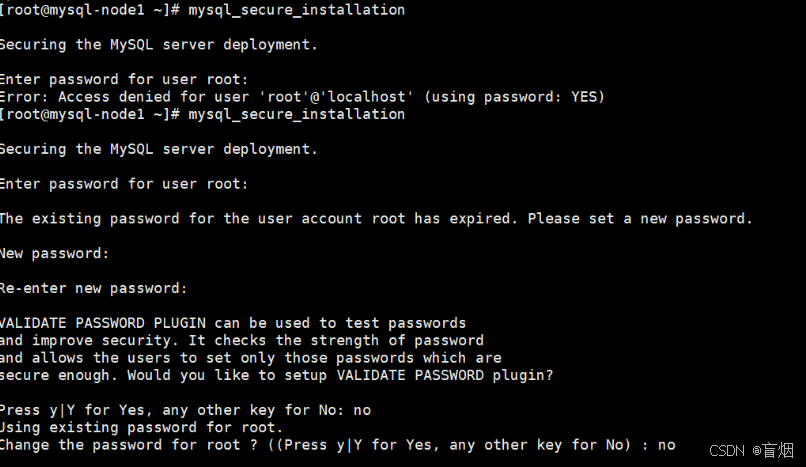
对mysql安全初始化
root@mysql-node1 \~# mysql_secure_installation
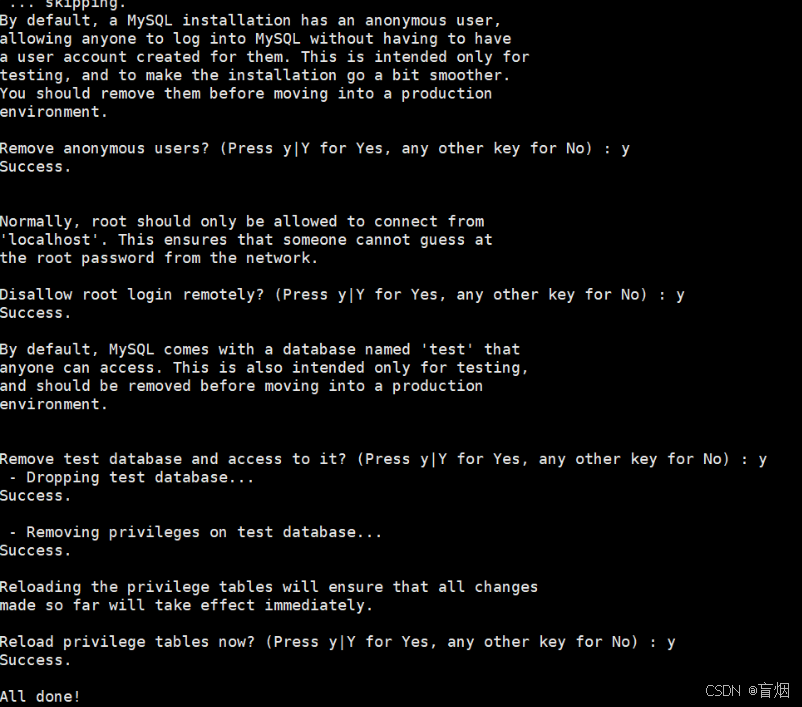
启动数据库
root@mysql-node1 \~# mysql -uroot -p
二、MySQL集群
1.组从复制
master配置
[root@mysql-node1 ~]# vim /etc/my.cnf
[root@mysql-node1 ~]# cat /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
symbolic-links=0
log-bin=mysql-bin
server-id=1
[root@mysql-node1 ~]# /etc/init.d/mysqld restart#进入数据库配置用户权限
root@mysql-node1 \~# mysql -p123
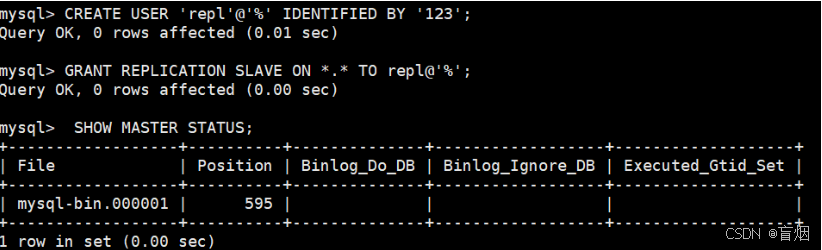
##生成专门用来做复制的用 户,此用户是用于slave端做认证用
##对这个用户进行授权
##查看master的状态
slave配置
[root@mysql-node2 ~]# vim /etc/my.cnf
[root@mysql-node2 ~]# cat /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
symbolic-links=0
server-id=2
[root@mysql-node2 ~]# /etc/init.d/mysqld restart
mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10',MASTER_USER='repl',MASTER_PASSWORD='123',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=595;
mysql> start slave;
mysql> SHOW SLAVE STATUS\G;连接状态正常

测试
在master主机进行以下操作
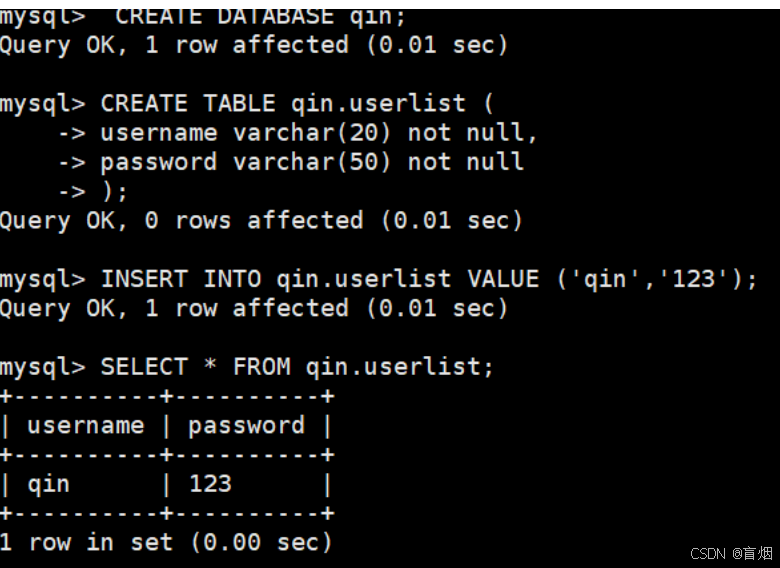
在slave中查看数据是否有同步过来 ,数据同步成功

2.延迟复制
延迟复制时用来控制sql线程的,和i/o线程无关
这个延迟复制不是i/o线程过段时间来复制,i/o是正常工作的
是日志已经保存在slave端了,那个sql要等多久进行回放
slave2
mysql> STOP SLAVE SQL_THREAD;
mysql> CHANGE MASTER TO MASTER_DELAY=60;
mysql> START SLAVE SQL_THREAD;
mysql> SHOW SLAVE STATUS\G;

测试
在master中写入数据
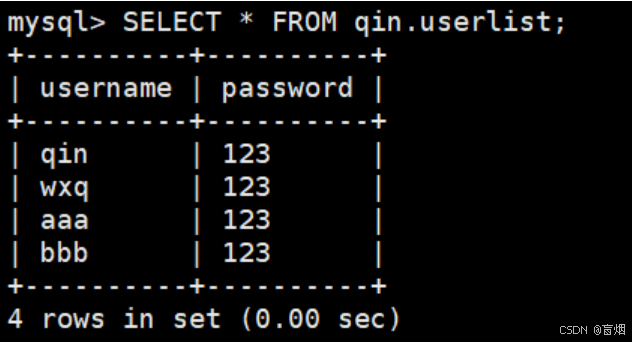
mysql> INSERT INTO qin.userlist VALUE ('bbb','123');
slave1中立即能查询到
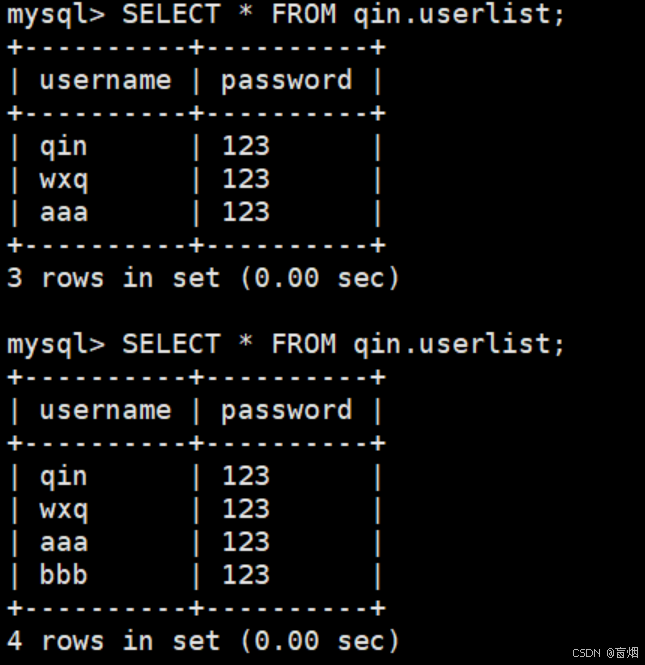
slave2中过了60s延迟时间才能被查询到
3.慢查询日志
当执行SQL超过long_query_time参数设定的时间阈值(默认10s)时,就被认为是慢查询,这个 SQL语句就是需要优化的,慢查询被记录在慢查询日志里,默认是不开启的。如果需要优化SQL语句,就可以开启这个功能,它可以让你很容易地知道哪些语句是需要优化的。
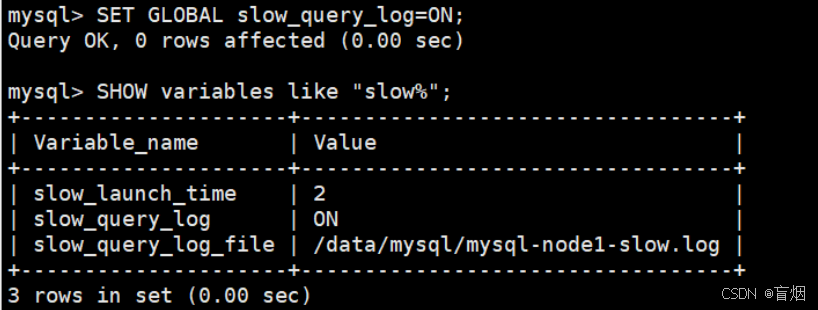
查看慢查询
mysql> SHOW variables like "slow%";
+---------------------+----------------------------------+
| Variable_name | Value |
+---------------------+----------------------------------+
| slow_launch_time | 2 |
| slow_query_log | OFF |
| slow_query_log_file | /data/mysql/mysql-node1-slow.log |
+---------------------+----------------------------------+
3 rows in set (0.00 sec)开启慢查询日志
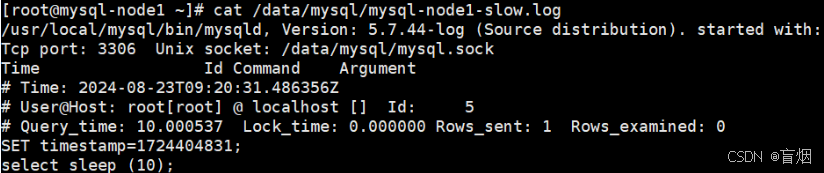
测试慢查询
mysql> SHOW variables like "long%";
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
mysql> select sleep (10);
+------------+
| sleep (10) |
+------------+
| 0 |
+------------+
1 row in set (10.00 sec)日志
4.并行复制
默认情况下slave中使用的是sql单线程回放,在master中时多用户读写,如果使用sql单线程回放那么会造成组从延迟严重,开启MySQL的多线程回放可以解决上述问题。
查看slave1线程信息
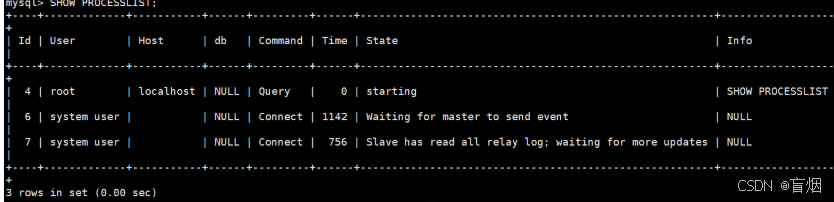
在slave1中设定
root@mysql-node2 mysql# vim /etc/my.cnf
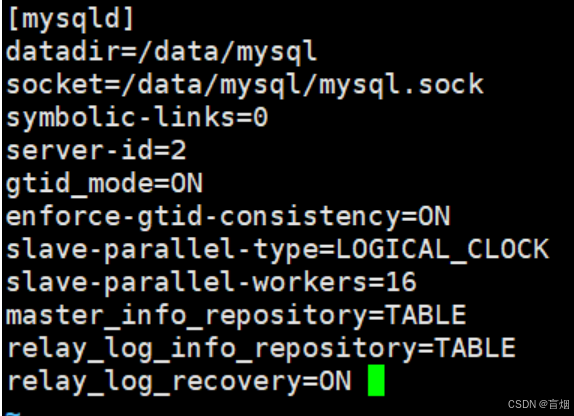
root@mysql-node2 mysql# /etc/init.d/mysqld restart
查看进程
此时sql线程转化为协调线程,16个worker负责处理sql协调线程发送过来的处理请求
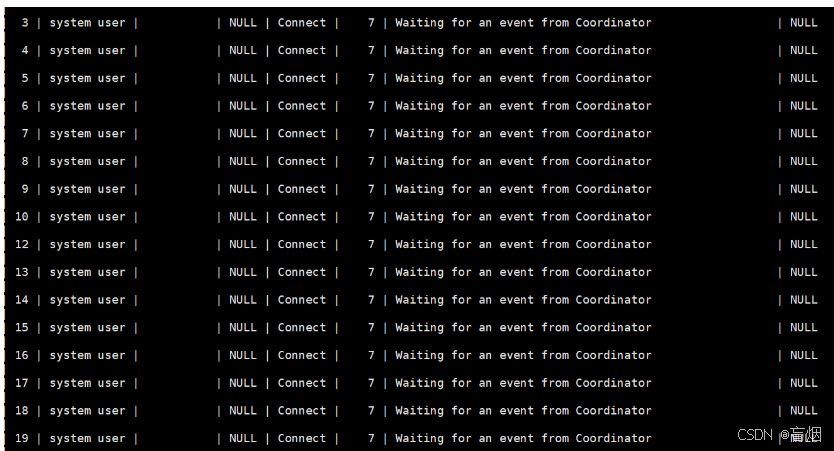
5.gtid日志模式
在master端的写入时多用户读写,在slave端的复制时单线程日志回放,所以slave端一定会延迟与 master端
这种延迟在slave端的延迟可能会不一致,当master挂掉后slave接管,一般会挑选一个和master延迟日 志最接近的充当新的master
那么为接管master的主机继续充当slave角色并会指向到新的master上,作为其slave
当激活GITD之后
当master出现问题后,slave2和master的数据最接近,会被作为新的master
slave1指向新的master,但是他不会去检测新的master的pos id,只需要继续读取自己gtid_next即可
设置gtid
在master端和slave2中开启gtid模式
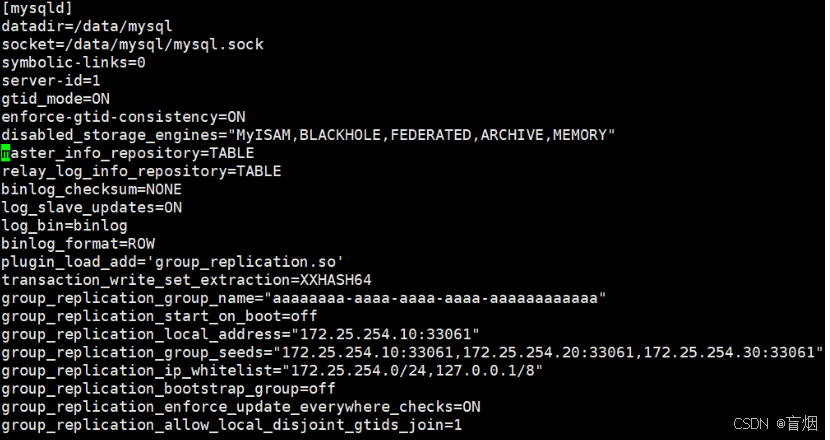
master
root@mysql-node1 \~# vim /etc/my.cnf
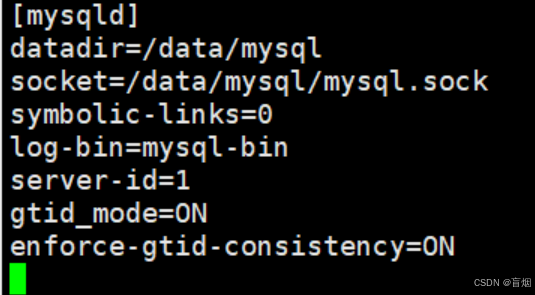
root@mysql-node1 \~# /etc/init.d/mysqld restart
slave2
root@mysql-node1 \~# vim /etc/my.cnf
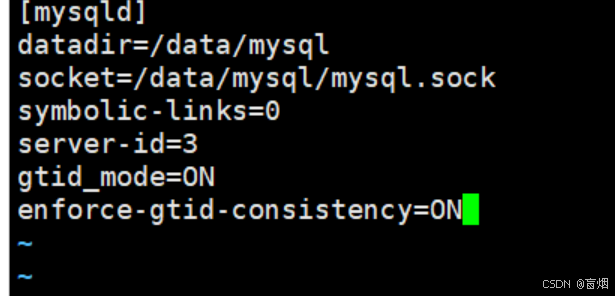
root@mysql-node3 \~# /etc/init.d/mysqld restart
在master端,gitd已开
停止slave端
root@mysql-node2 mysql# mysql -uroot -p
mysql> stop slave; Query OK, 0 rows affected (0.01 sec)
root@mysql-node3 \~# mysql -uroot -p
mysql> stop slave; Query OK, 0 rows affected (0.00 sec)
开启slave端的gtid
root@mysql-node2 mysql# mysql -uroot -p
mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_AUTO_POSITION=1; Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> start slave; Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G;
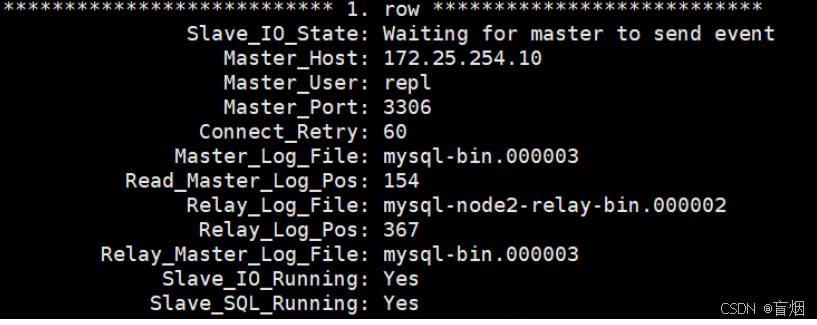
mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_AUTO_POSITION=1;
mysql> start slave;
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.25.254.10
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 154
Relay_Log_File: mysql-node3-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes6.半同步模式
master
在master端配置启用半同步模式
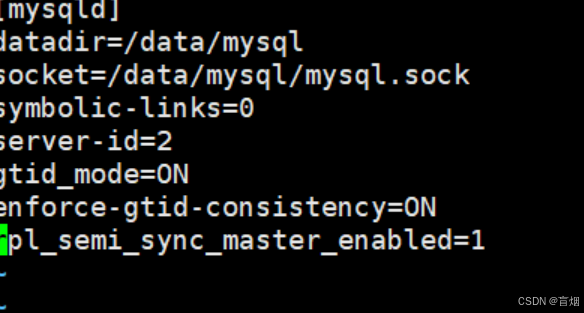
root@mysql-node1 \~# vim /etc/my.cnf

安装半同步插件
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
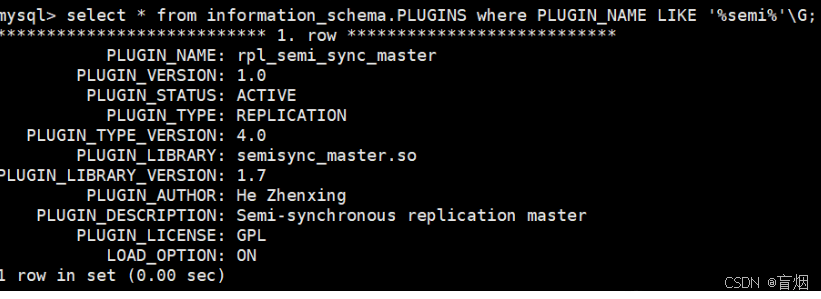
查看插件情况
mysql> select * from information_schema.PLUGINS where PLUGIN_NAME LIKE '%semi%'\G;
打开半同步功能
mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1;
查看半同步功能状态
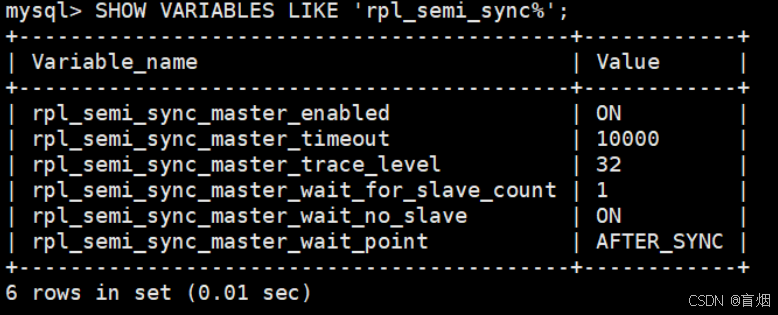
mysql> SHOW VARIABLES LIKE 'rpl_semi_sync%';
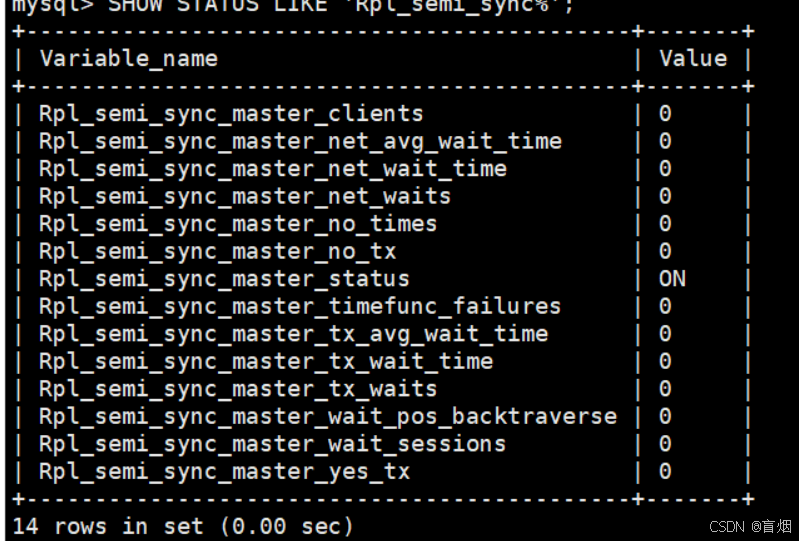
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
slave
slave端开启半同步功能
root@mysql-node2 mysql# vim /etc/my.cnf
安装半同步插件
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> SET GLOBAL rpl_semi_sync_slave_enabled =1;
重启io线程,半同步才能生效
mysql> STOP SLAVE IO_THREAD;
mysql> START SLAVE IO_THREAD;

测试
在slave端
mysql> STOP SLAVE IO_THREAD;
在master端插入数据
mysql> insert into qin.userlist values ('ccc','333');

#10s超时
7.高可用之组复制 (MGR)
node1
root@mysql-node1 \~# rm -fr /data/mysql/*
root@mysql-node1 \~# vim /etc/my.cnf
root@mysql-node \~# mysqld --user=mysql --initialize
root@mysql-node1 \~# /etc/init.d/mysqld start
root@mysql-node1 \~# mysql -uroot -p123 -e "alter user root@localhost identified by '123';"
配置sql
mysql> SET SQL_LOG_BIN=0;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE USER rpl_user@'%' IDENTIFIED BY '123';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
mysql> SET SQL_LOG_BIN=1;
Query OK, 0 rows affected (0.00 sec)
mysql> CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='123' FOR CHANNEL 'group_replication_recovery';
Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> SET GLOBAL group_replication_bootstrap_group=ON;
Query OK, 0 rows affected (0.00 sec)
mysql> START GROUP_REPLICATION;
Query OK, 0 rows affected, 1 warning (2.02 sec)
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;
Query OK, 0 rows affected (0.00 sec)
root@mysql-node1 mysql# scp /etc/my.cnf root@172.25.254.20:/etc/my.cnf
在node2和node3中
root@mysql-node2 \~# rm -fr /data/mysql/*
node2
root@mysql-node2 \~# vim /etc/my.cnf
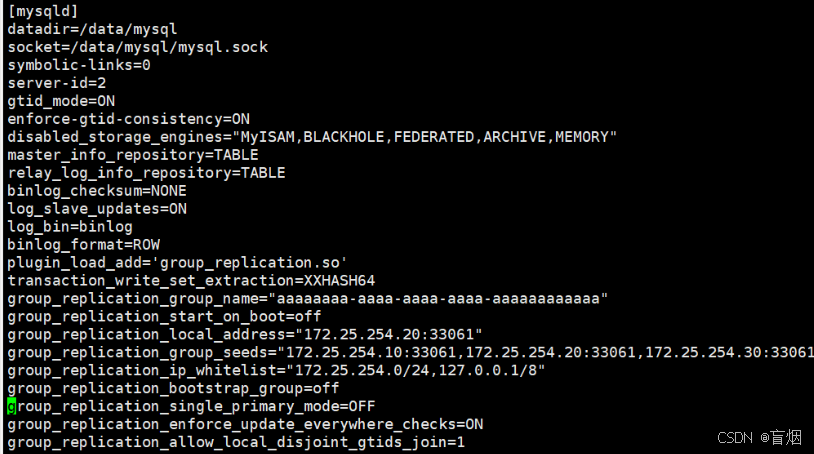
ps -ef | grep mysqld 查看是否有mysql进程在进行
root@mysql-node2 \~# /etc/init.d/mysqld start
root@mysql-node2 \~# mysqld --user=mysql --initialize
node3
root@mysql-node3 \~# vim /etc/my.cnf

root@mysql-node3 \~# /etc/init.d/mysqld start
root@mysql-node3 \~# mysqld --user=mysql --initialize
配置sql
在node2和node3配置sql
mysql> SET SQL_LOG_BIN=0;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE USER rpl_user@'%' IDENTIFIED BY '123';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
mysql> SET SQL_LOG_BIN=1;
Query OK, 0 rows affected (0.00 sec)
mysql> CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='123' FOR CHANNEL 'group_replication_recovery';
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> START GROUP_REPLICATION;
Query OK, 0 rows affected, 1 warning (3.12 sec)
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-----------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-----------------+-------------+--------------+
| group_replication_applier | 45062f5b-61ee-11ef-a2c4-000c298ff36b | mysql-node1 | 3306 | ONLINE |
| group_replication_applier | 7740643e-61e9-11ef-94ff-000c29c6310e | mysql-node2 | 3306 | ONLINE |
| group_replication_applier | 977c5d8d-61ea-11ef-a00e-000c2996b747 | mysql-node3.org | 3306 | ONLINE |
+---------------------------+--------------------------------------+-----------------+-------------+--------------+
3 rows in set (0.00 sec)
测试
在每个节点都可以完成续写
#在node1中
mysql> CREATE DATABASE qin;
Query OK, 1 row affected (0.01 sec)
mysql> CREATE TABLE qin.userlist(
-> username VARCHAR(10) PRIMARY KEY NOT NULL,
-> password VARCHAR(50) NOT NULL
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO qin.userlist VALUES ('wxq','123');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM qin.userlist;
+----------+----------+
| username | password |
+----------+----------+
| wxq | 123 |
+----------+----------+
1 row in set (0.00 sec)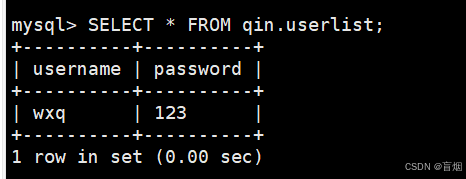
#在node2中插入数据
mysql> INSERT INTO qin.userlist values ('qin','456');
Query OK, 1 row affected (0.00 sec)
mysql> select * from qin.userlist;
+----------+----------+
| username | password |
+----------+----------+
| qin | 456 |
| wxq | 123 |
+----------+----------+
2 rows in set (0.00 sec)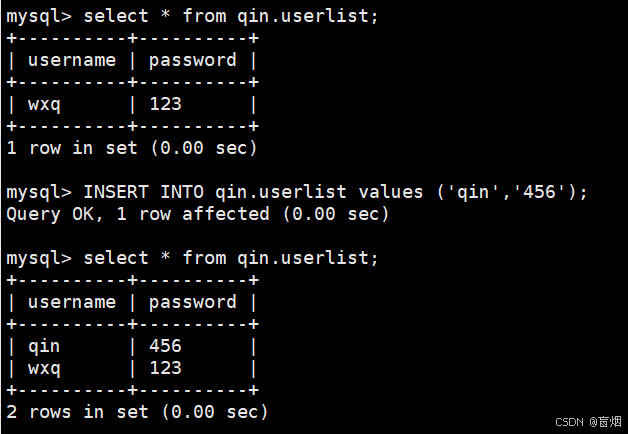
#mysql---node3中插入数据
mysql> INSERT INTO qin.userlist values ('cici','789');
Query OK, 1 row affected (0.01 sec)
mysql> select * from qin.userlist;
+----------+----------+
| username | password |
+----------+----------+
| cici | 789 |
| qin | 456 |
| wxq | 123 |
+----------+----------+
3 rows in set (0.00 sec)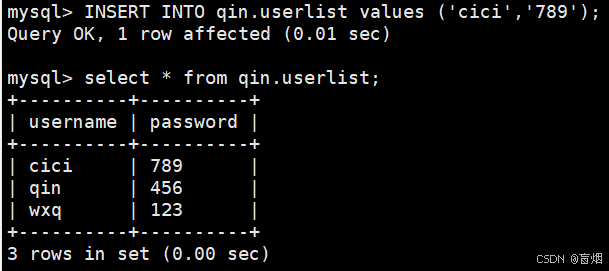
8.MHA部署
1.搭建主两从架构
在master中
root@mysql-node1 \~# /etc/init.d/mysqld stop
root@mysql-node1 \~# rm -fr /data/mysql/*
root@mysql-node1 \~# vim /etc/my.cnf
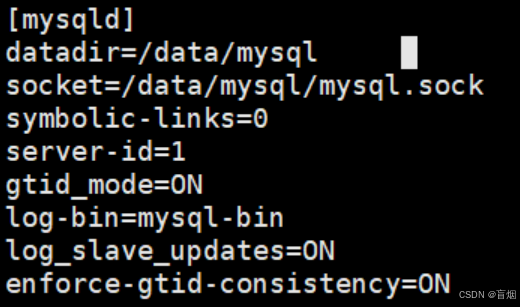
root@mysql-node1 \~# mysqld --user mysql --initialize
root@mysql-node1 \~# /etc/init.d/mysqld start
root@mysql-node1 \~# mysql_secure_installation
启动数据库
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY 'qin';
Query OK, 0 rows affected (0.01 sec)
mysql> GRANT REPLICATION SLAVE ON *.* TO repl@'%';
Query OK, 0 rows affected (0.01 sec)
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
Query OK, 0 rows affected (0.01 sec)
mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1;
Query OK, 0 rows affected (0.02 sec)在slave1和slave2中
root@mysql-node2 \~# /etc/init.d/mysqld stop
root@mysql-node2 \~# rm -fr /data/mysql/*
root@mysql-node2 \~# vim /etc/my.cnf
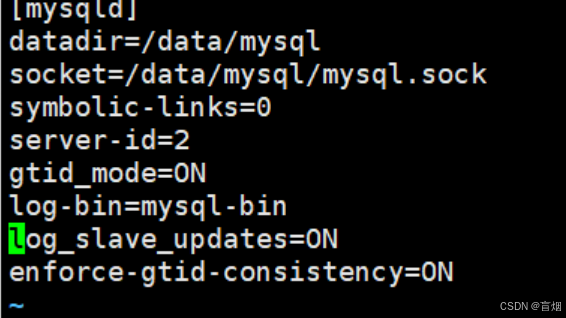
root@mysql-node2 \~# mysqld --user mysql --initialize
root@mysql-node2 \~# /etc/init.d/mysqld start
root@mysql-node2 \~# mysql_secure_installation
启动数据库
mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10', MASTER_USER='repl', MASTER_PASSWORD='qin', MASTER_AUTO_POSITION=1;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL rpl_semi_sync_slave_enabled =1;
Query OK, 0 rows affected (0.00 sec)
mysql> STOP SLAVE IO_THREAD;
Query OK, 0 rows affected (0.00 sec)
mysql> START SLAVE IO_THREAD;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
1 row in set (0.01 sec)2.安装mha所需要的软件
在mha中
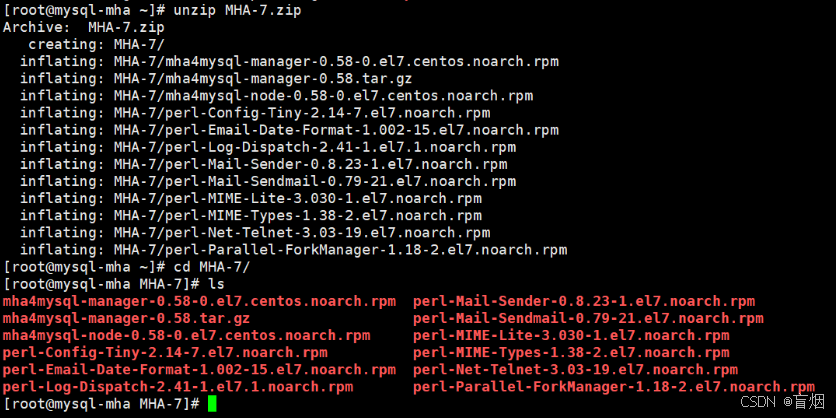
root@mysql-mha MHA-7# yum install *.rpm -y
root@mysql-mha MHA-7# scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@172.25.254.10:/mnt
root@mysql-mha MHA-7# scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@172.25.254.20:/mnt
root@mysql-mha MHA-7# scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@172.25.254.30:/mnt
在三台sql-node中
yum install /mnt/mha4mysql-node-0.58-0.el7.centos.noarch.rpm -y
3.配置mha的管理环境
#生成配置文件
root@mysql-mha MHA-7# mkdir /etc/masterha
root@mysql-mha MHA-7# tar zxf mha4mysql-manager-0.58.tar.gz
root@mysql-mha MHA-7# cd mha4mysql-manager-0.58/samples/conf/
root@mysql-mha conf# cat masterha_default.cnf app1.cnf > /etc/masterha/app1.cnf
#编辑配置文件
root@mysql-mha \~# vim /etc/masterha/app1.cnf
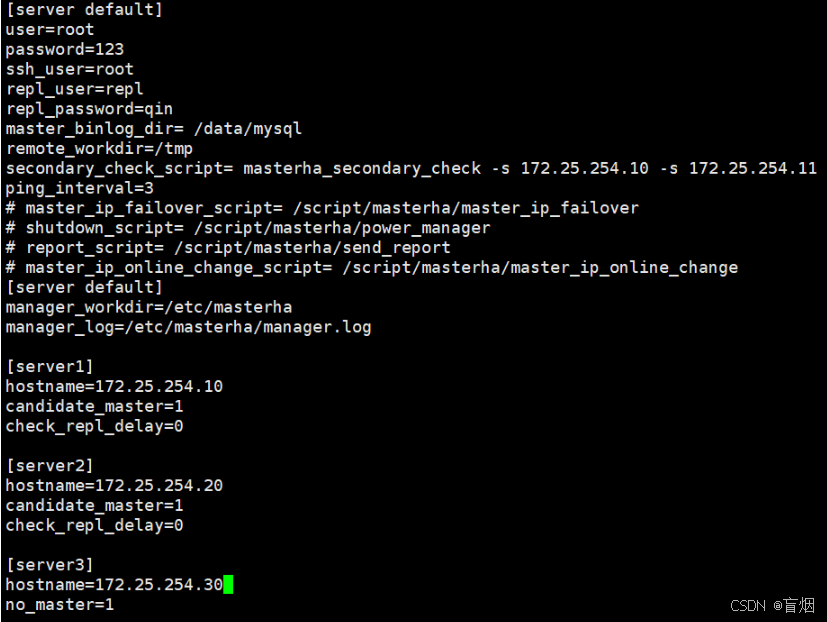
配置ssh免密
root@mysql-mha \~# ssh-keygen
root@mysql-mha \~# ssh-copy-id -i/root/.ssh/id_rsa.pub root@172.25.254.10
root@mysql-mha \~# ssh-copy-id -i/root/.ssh/id_rsa.pub root@172.25.254.20
root@mysql-mha \~# ssh-copy-id -i/root/.ssh/id_rsa.pub root@172.25.254.30
root@mysql-mha \~# scp /root/.ssh/id_rsa root@172.25.254.10:/root/.ssh/
root@mysql-mha \~# scp /root/.ssh/id_rsa root@172.25.254.20:/root/.ssh/
root@mysql-mha \~# scp /root/.ssh/id_rsa root@172.25.254.30:/root/.ssh/
检测网络及ssh免密
root@mysql-mha \~# masterha_check_ssh --conf=/etc/masterha/app1.cnf
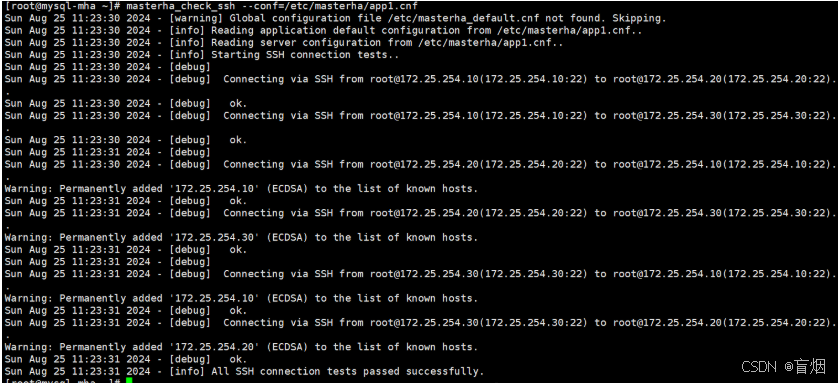
4.检测数据主从复制情况
#在数据节点master端
mysql> GRANT ALL ON . TO root@'%' identified by '123'; #允许root远程登陆
#执行检测
root@mysql-mha \~# masterha_check_repl --conf=/etc/masterha/app1.cnf
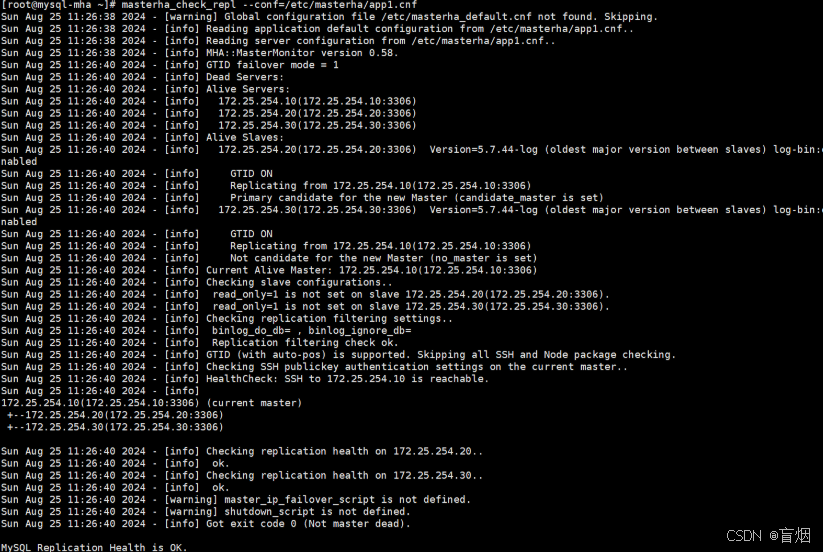
9.MHA的故障切换
MHA的故障切换过程 :
1.配置文件检查阶段,这个阶段会检查整个集群配置文件配置
2.宕机的master处理,这个阶段包括虚拟ip摘除操作,主机关机操作
3.复制dead master和最新slave相差的relay log,并保存到MHA Manger具体的目录下
4.识别含有最新更新的slave
5.应用从master保存的二进制日志事件(binlog events)
6.提升一个slave为新的master进行复制 7.使其他的slave连接新的master进行复制
1.master未出现故障手动切换
#在master数据节点还在正常工作情况下
[root@mysql-mha ~]# masterha_master_switch \
--conf=/etc/masterha/app1.cnf \ #指定配置文件
--master_state=alive \ #指定master节点状态
--new_master_host=172.25.254.20 \ #指定新master节点
--new_master_port=3306 \ #执行新master节点端口
--orig_master_is_new_slave \ #原始master会变成新的slave
--running_updates_limit=10000 #切换的超时时间切换过程如下
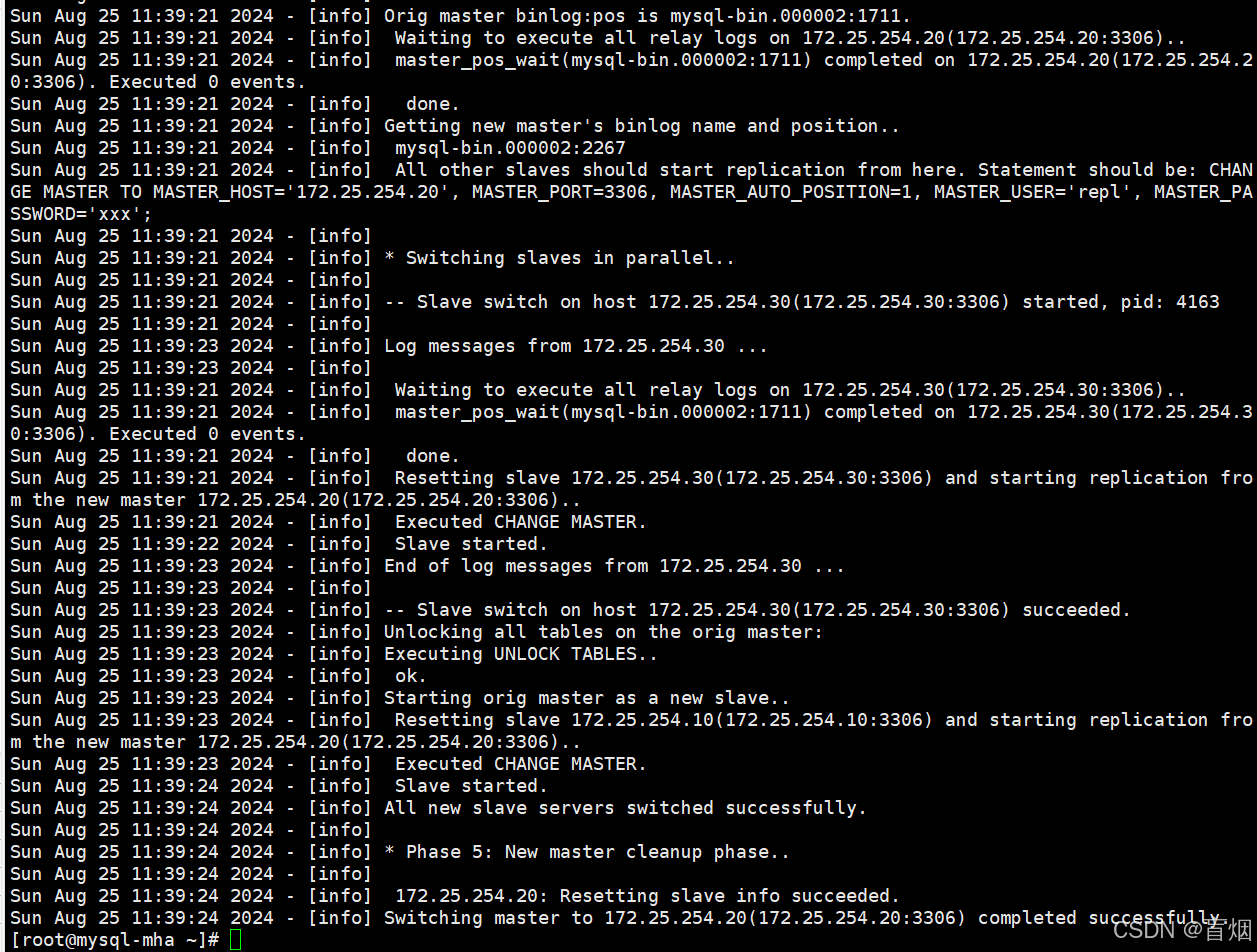
检测
root@mysql-mha \~# masterha_check_repl --conf=/etc/masterha/app1.cnf

2.master故障手动切换
#模拟master故障
root@mysql-node2 mysql# /etc/init.d/mysqld stop
#在MHA-master中做故障切换
root@mysql-mha \~# masterha_master_switch \
> --master_state=dead \
> --conf=/etc/masterha/app1.cnf \
> --dead_master_host=172.25.254.20 \
> --dead_master_port=3306 \
> --new_master_host=172.25.254.10 \
> --new_master_port=3306 \
> --ignore_last_failover
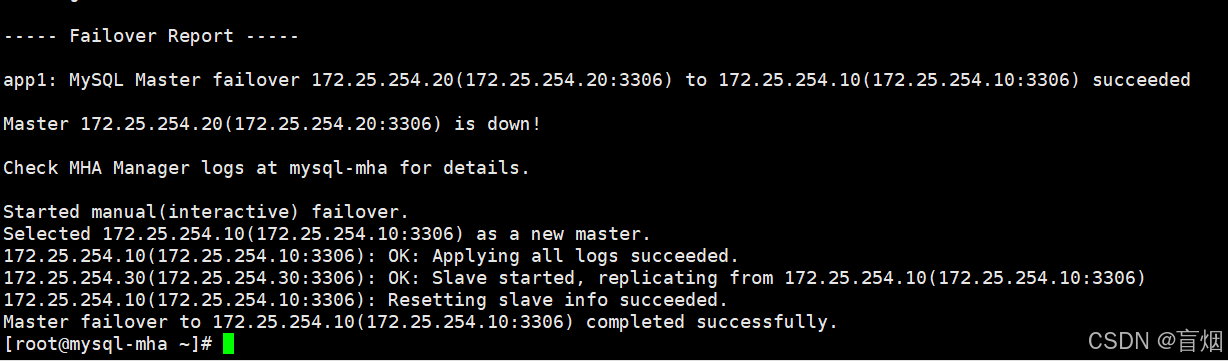
#恢复故障mysql节点
root@mysql-node2 \~# /etc/init.d/mysqld start
mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10',MASTER_USER='repl', MASTER_PASSWORD='qin', MASTER_AUTO_POSITION=1;
mysql> start slave;
mysql> SHOW SLAVE STATUS\G;
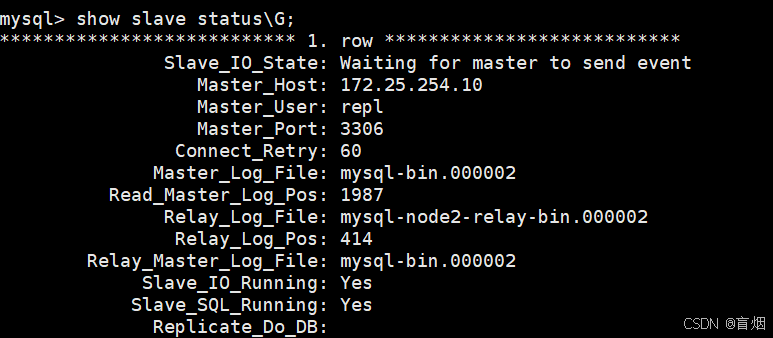
#测试一主两从是否正常
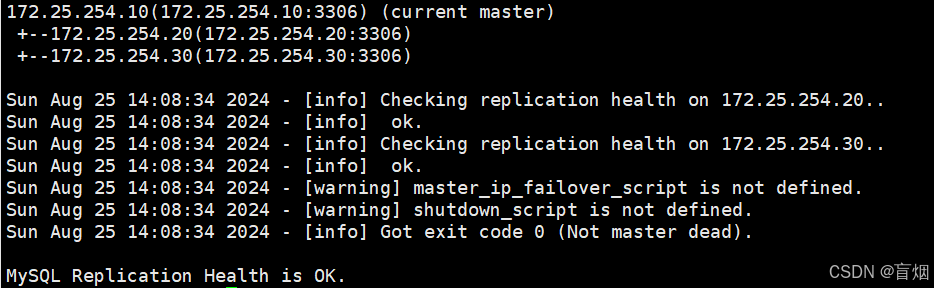
3.自动切换
#停止主服务器
root@mysql-node1 \~# /etc/init.d/mysqld stop
#删掉切换锁文件
root@mysql-mha masterha# rm -fr app1.failover.complete
#监控程序通过指定配置文件监控master状态,当master出问题后自动切换并退出避免重复做故障切换
root@mysql-mha masterha# masterha_manager --conf=/etc/masterha/app1.cnf
#20切换为主服务器
root@mysql-mha masterha# cat /etc/masterha/manager.log
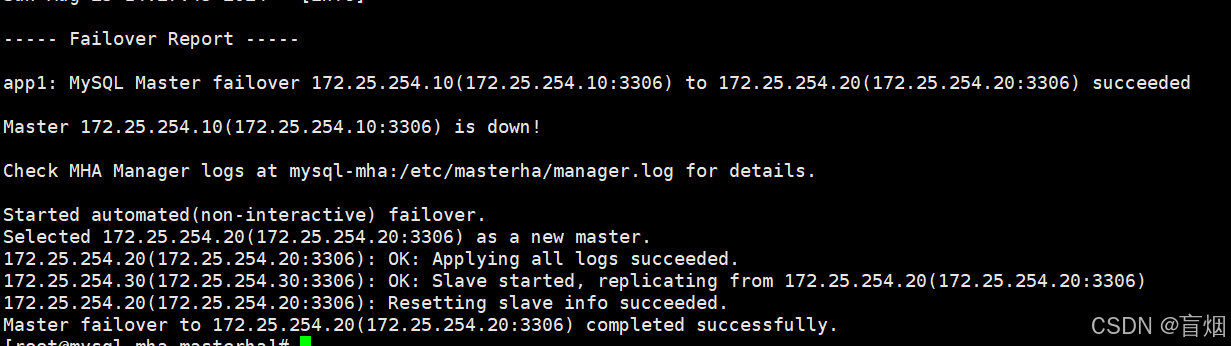
恢复故障节点
root@mysql-node1 \~# /etc/init.d/mysqld start
mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.20', MASTER_USER='repl', MASTER_PASSWORD='qin', MASTER_AUTO_POSITION=1;
mysql> start slave;
10.为MHA添加VIP功能
1.上传脚本
 root@mysql-mha \~# cp master_ip_failover master_ip_online_change /usr/local/bin/ root@mysql-mha \~# chmod +x /usr/local/bin/master_ip_*
root@mysql-mha \~# cp master_ip_failover master_ip_online_change /usr/local/bin/ root@mysql-mha \~# chmod +x /usr/local/bin/master_ip_*
2.修改脚本vip
root@mysql-mha \~# vim /usr/local/bin/master_ip_failover

root@mysql-mha \~# vim /usr/local/bin/master_ip_online_change

在master添加vip
root@mysql-node2 \~# ip a a 172.25.254.100/24 dev eth0
启动监控程序
root@mysql-mha masterha# masterha_manager --conf=/etc/masterha/app1.cnf
关闭主节点服务
root@mysql-node2 \~# /etc/init.d/mysqld stop
查看日志
root@mysql-mha masterha# cat manager.log
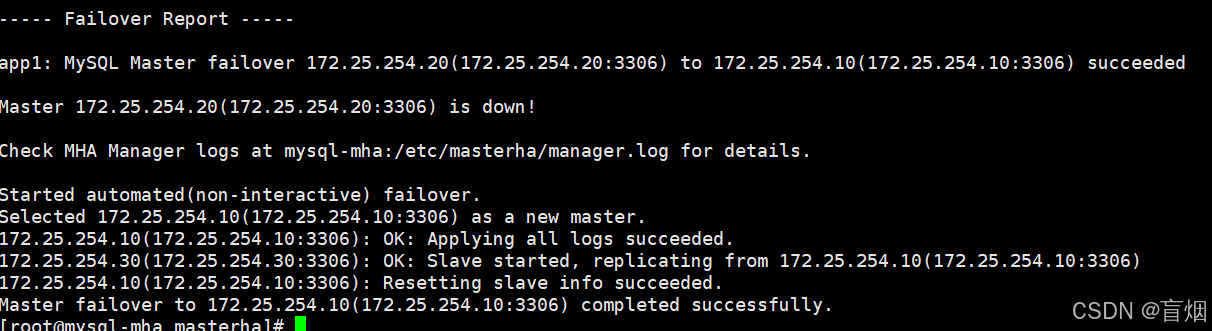
恢复故障主机
root@mysql-node2 \~# /etc/init.d/mysqld start
mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10', MASTER_USER='repl', MASTER_PASSWORD='qin', MASTER_AUTO_POSITION=1;
mysql> start slave;
root@mysql-mha masterha# rm -rf app1.failover.complete manager.log
3.手动切换后查看vip变化
root@mysql-mha masterha# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.254.10 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
root@mysql-node1 \~# ip a
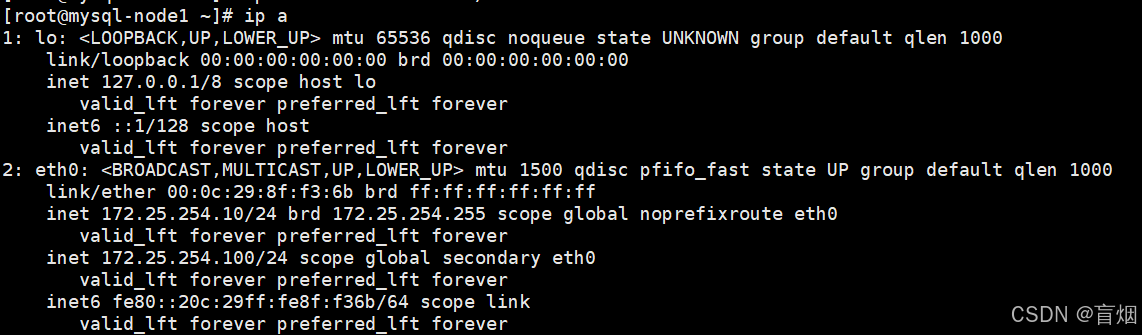
三、NoSql数据库Redis集群
redis部署
root@redis1 \~# tar zxf redis-7.4.0.tar.gz
root@redis1 \~# ls redis-7.4.0 redis-7.4.0.tar.gz
#安装编译工具
root@redis1 redis-7.4.0# dnf install make gcc initscripts-10.11.6- 1.el9.x86_64 -y
#执行编译命令
root@redis1 redis-7.4.0# make
root@redis1 redis-7.4.0# make install
#启动Redis
root@redis1 redis-7.4.0# cd utils/
root@redis1 utils# ./install_server.sh
#解决报错问题
root@redis1 utils# vim install_server.sh

root@redis1 utils# ./install_server.sh
#配置redis
root@redis1 utils# vim /etc/redis/6379.conf

#查看信息

redis主从
1.修改master节点的配置文件
在master、slave1和slave2中
root@redis1 \~# vim /etc/redis/6379.conf
root@redis1 \~# /etc/init.d/redis_6379 restart
2.配置slave节点
在slave1和slave2中
root@redis2 \~# vim /etc/redis/6379.conf

root@redis2 \~# /etc/init.d/redis_6379 restart
3.测试
#在master节点
root@redis1 \~# redis-cli
#在slave节点查看
root@redis2 \~# redis-cli
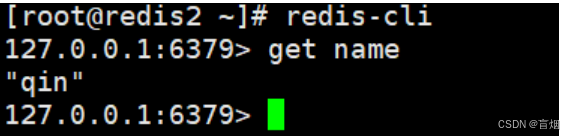
redis哨兵
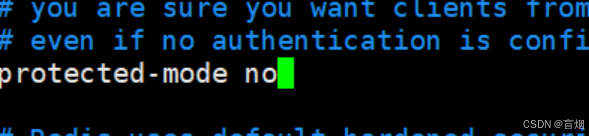
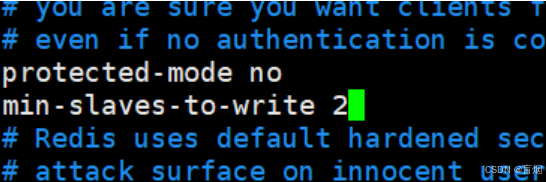
在所有阶段中关闭 protected-mode no
1.master节点
#编辑配置文件
root@redis1 \~# cd redis-7.4.0/
root@redis1 redis-7.4.0# cp sentinel.conf /etc/redis/
root@redis1 redis-7.4.0# vim /etc/redis/sentinel.conf

#复制配置文件到其他阶段
root@redis1 redis-7.4.0# scp /etc/redis/sentinel.conf root@172.25.254.20:/etc/redis/
root@redis1 redis-7.4.0# scp /etc/redis/sentinel.conf root@172.25.254.30:/etc/redis/
2.启动服务
root@redis1 redis-7.4.0# redis-sentinel /etc/redis/sentinel.conf
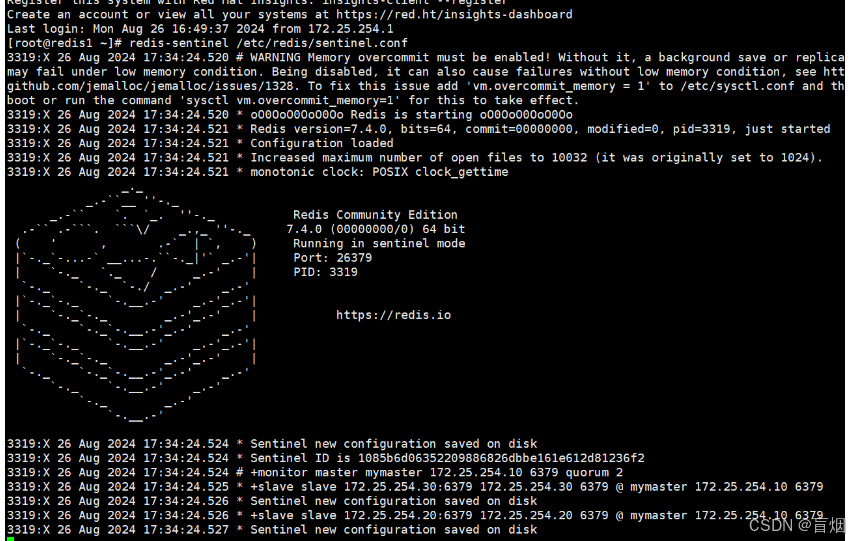
sentinel.conf文件被改变

3.测试
#再开一个master节点终端
root@redis1 redis# redis-cli
127.0.0.1:6379> SHUTDOWN
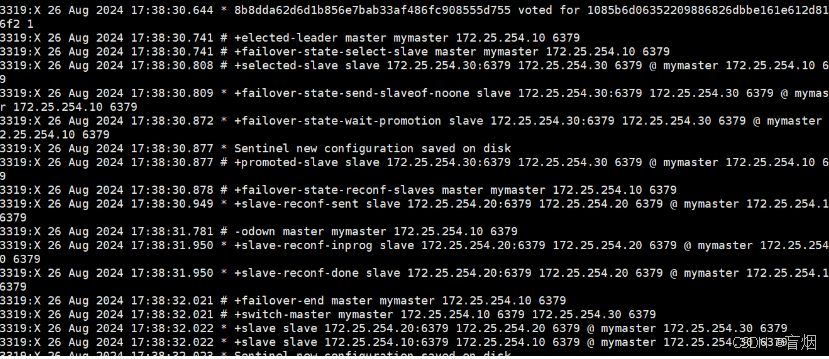
由日志可知 30转换为新的master
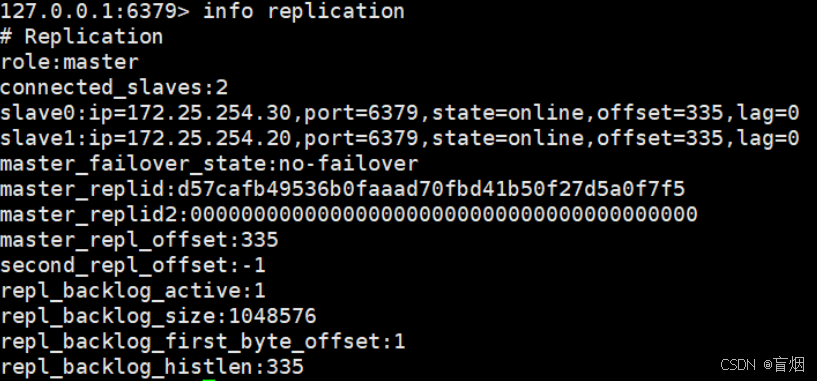
#在30主机中,查看主从信息
root@redis3 \~# redis-cli
127.0.0.1:6379> info replication
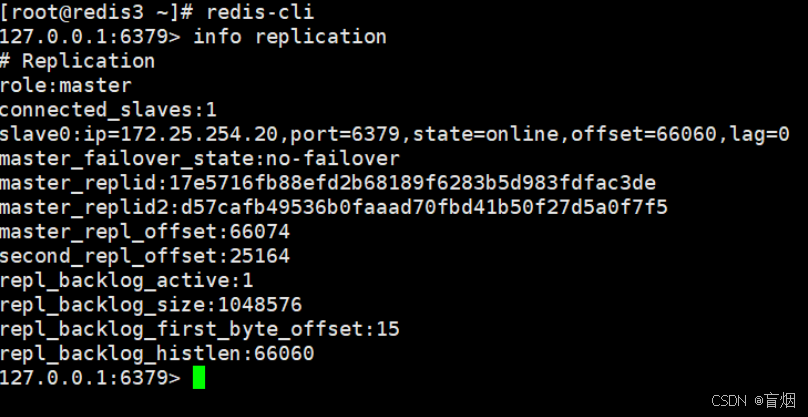
由于10已关闭,所以只有一个slave
4.可能会出现的问题
在生产环境中如果master和slave中的网络出现故障,由于哨兵的存在会把master提出去 当网络恢复后,master发现环境发生改变,master就会把自己的身份转换成slave。master变成slave后会把网络故障那段时间写入自己中的数据清掉,这样数据就丢失了。
解决: master在被写入数据时会持续连接slave,mater确保有2个slave可以写入我才允许写入 如果slave数量少于2个便拒绝写入
#在master中设定
root@redis3 \~# redis-cli
127.0.0.1:6379> CONFIG GET min-slaves-to-write
-
"min-slaves-to-write"
-
"0"
127.0.0.1:6379> CONFIG set min-slaves-to-write 2
OK
127.0.0.1:6379> CONFIG GET min-slaves-to-write
-
"min-slaves-to-write"
-
"2"
#永久保存
root@redis3 \~# vim /etc/redis/6379.conf
redis cluster集群
1.部署redis cluster
在所有redis主机中
root@redis1 \~# vim /etc/redis/redis.conf
bind * -::*
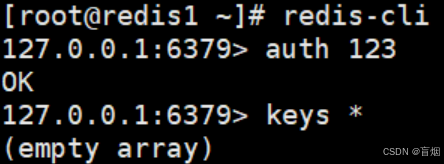
masterauth "123" #集群主从认证
requirepass "123" #redis登陆密码 redis-cli 命令连接redis后要 用"auth 密码"进行认证
cluster-enabled yes #开启cluster集群功能
cluster-config-file nodes-6379.conf #指定集群配置文件
cluster-node-timeout 15000 #节点加入集群的超时时间单位是ms
root@redis1 \~# systemctl enable --now redis
root@redis1 \~# for i in 20 30 110 120 130; do scp /etc/redis/redis.conf root@172.25.254.$i:/etc/redis/redis.conf; done
2.创建redis-cluster
#在master
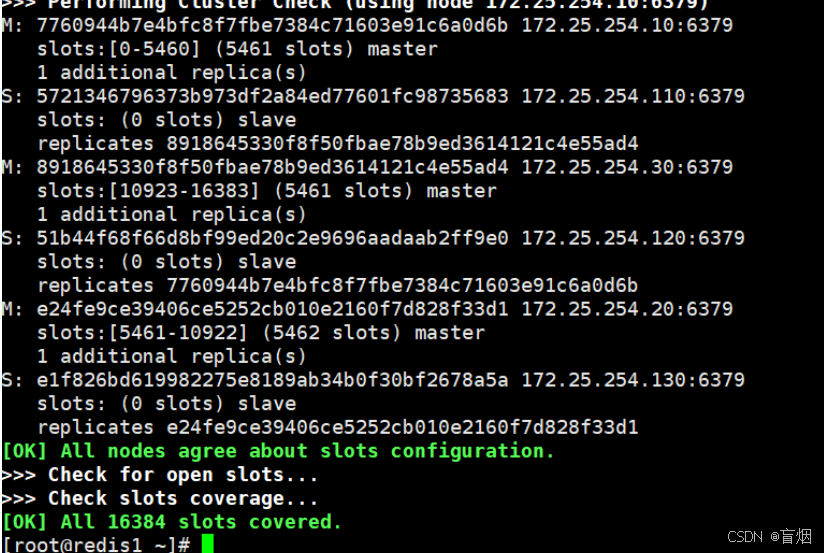
root@redis1 \~# redis-cli --cluster create -a 123 \
172.25.254.10:6379 172.25.254.20:6379 172.25.254.30:6379 \
172.25.254.110:6379 172.25.254.120:6379 172.25.254.130:6379 \
--cluster-replicas 1
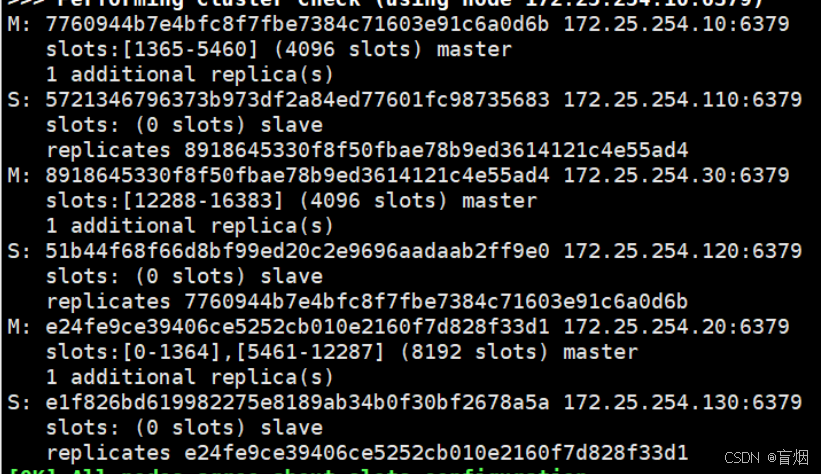
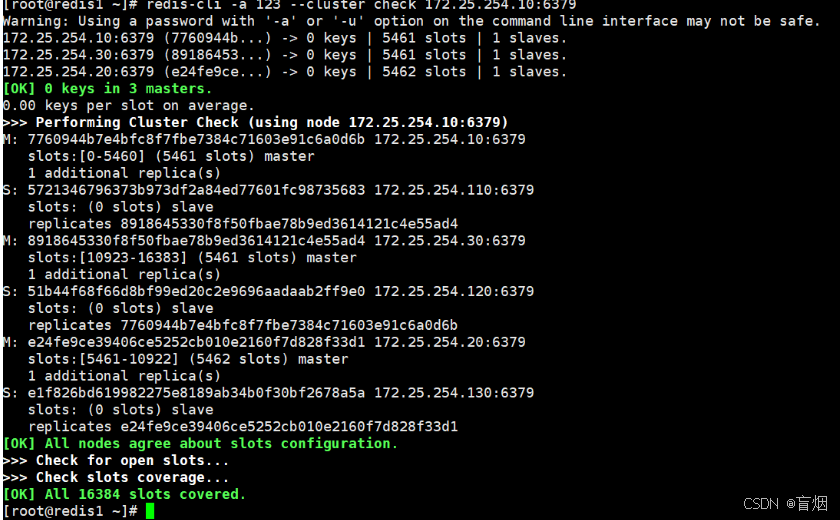
 3.检测cluster集群状态
3.检测cluster集群状态
#检测集群
root@redis1 \~# redis-cli -a 123 --cluster check 172.25.254.10:6379
#查看集群状态
root@redis1 \~# redis-cli -a 123 --cluster info 172.25.254.10:6379
写入数据
root@redis1 \~# redis-cli -a 123
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 127.0.0.1:6379> set name qin
(error) MOVED 5798 172.25.254.20:6379 #被分配到20的hash槽位上
root@redis2 \~# redis-cli -a 123
127.0.0.1:6379> set name qin
4.redis集群扩容
#添加master
root@redis2 \~# redis-cli -a 123 --cluster add-node 172.25.254.40:6379 172.25.254.20:6379
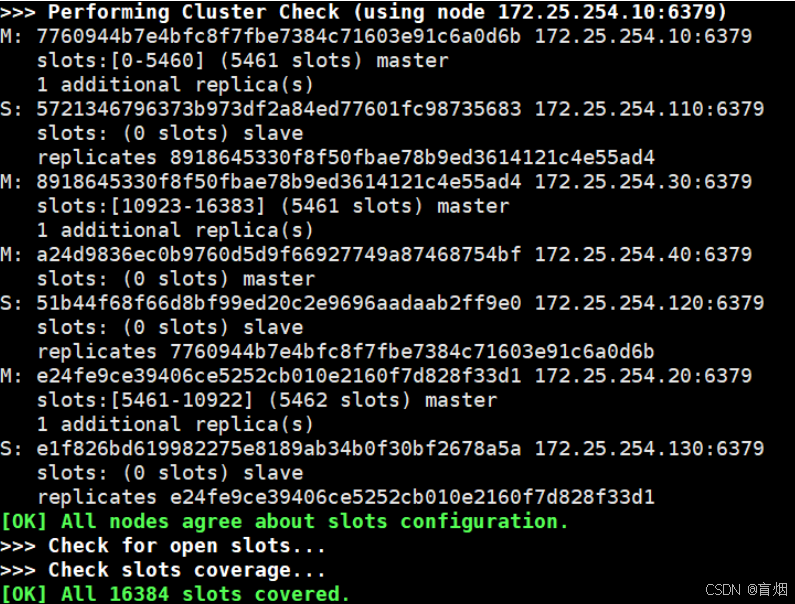 #分配槽位
#分配槽位
root@redis2 \~# redis-cli -a 123 --cluster reshard 172.25.254.20:6379
 #迁移后40上有槽位
#迁移后40上有槽位

#添加salve
root@redis2 \~# redis-cli -a 123 --cluster add-node 172.25.254.140:6379 172.25.254.10:6379 --cluster-slave --cluster-master-id a24d9836ec0b9760d5d9f66927749a87468754bf
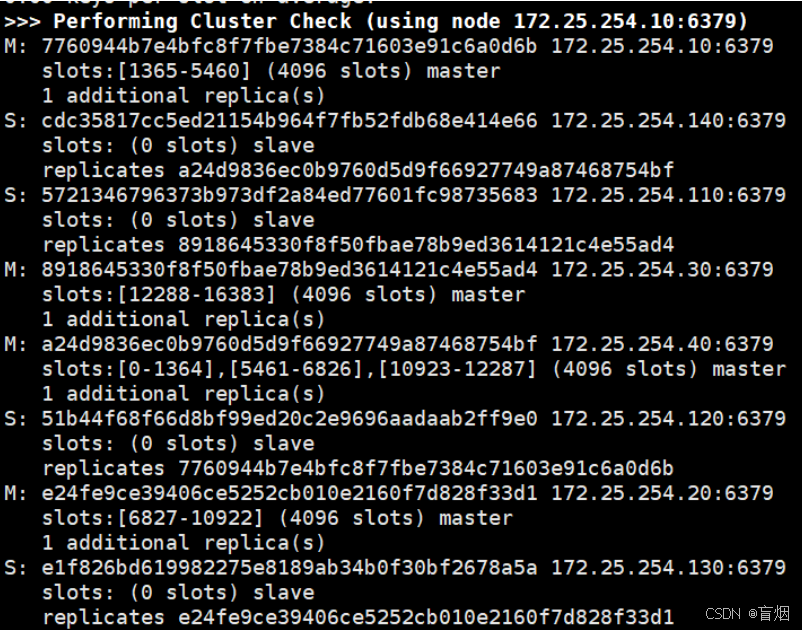
5.clsuter集群维护
#移除要下线主机的哈希槽位
root@redis2 \~# redis-cli -a 123 --cluster reshard 172.25.254.20:6379

#删除master
root@redis2 \~# redis-cli -a 123 --cluster del-node 172.25.254.140:6379 cdc35817cc5ed21154b964f7fb52fdb68e414e66
root@redis2 \~# redis-cli -a 123 --cluster check 172.25.254.10:6379