
文章目录
1、背景介绍
【python】OpenCV---Single Human Pose Estimation
本文以 COCO 格式为例,演示多人的关键点估计
鼻子- 0,脖子- 1,右肩- 2,右肘- 3,右腕- 4,左肩- 5,左肘- 6,
左腕- 7,右臀- 8,右膝盖- 9,右脚踝- 10,左臀部- 11,左膝- 12,
脚踝- 13,右眼- 14,左眼- 15,右耳- 16,左耳- 17,背景- 18
2、关键点检测模型
同单人检测 【python】OpenCV---Single Human Pose Estimation
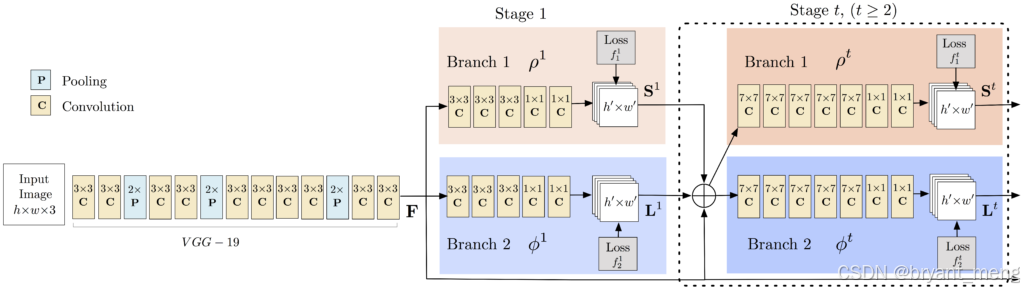
S 是关键点热力图,一类关键点一张热力图,包含所有 id,包含背景类别(18+1),输出特征图特征图通道是 0~18,例如下面展示了左键的热力图

L 是亲和度的2D向量场,用于编码关键点之间的关联程度,输出特征图通道 19~56(S 和 L concat 在一起了)
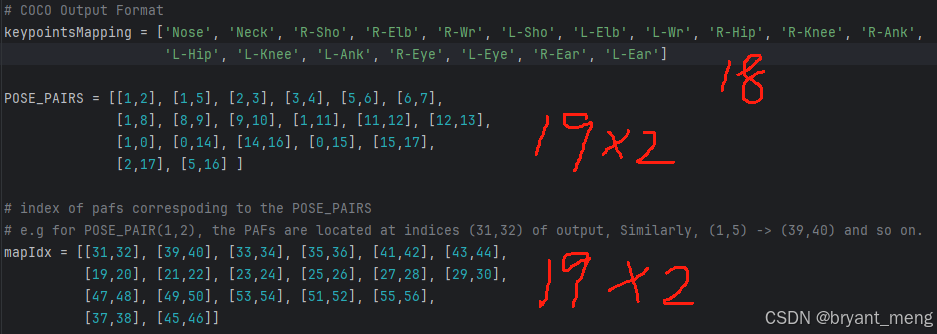
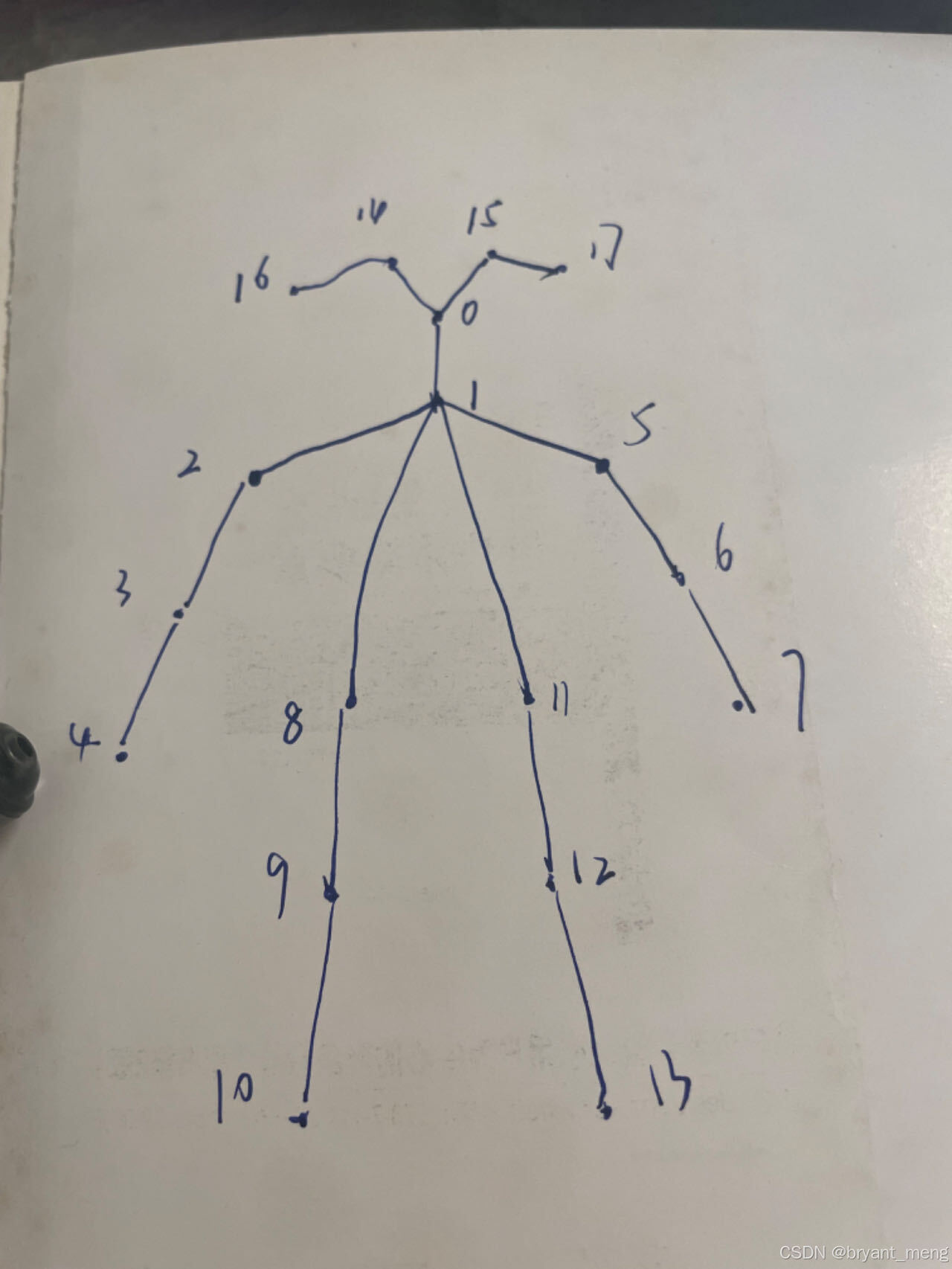
COCO 输出格式的模型


3、源码与结果
python
import cv2
import time
import numpy as np
from random import randint
import argparse
import matplotlib.pyplot as plt
parser = argparse.ArgumentParser(description='Run keypoint detection')
parser.add_argument("--device", default="gpu", help="Device to inference on")
parser.add_argument("--image_file", default="group.jpg", help="Input image")
args = parser.parse_args()
image1 = cv2.imread(args.image_file) # (415, 640, 3)
protoFile = "pose/coco/pose_deploy_linevec.prototxt"
weightsFile = "pose/coco/pose_iter_440000.caffemodel"
nPoints = 18
# COCO Output Format
keypointsMapping = ['Nose', 'Neck', 'R-Sho', 'R-Elb', 'R-Wr', 'L-Sho', 'L-Elb', 'L-Wr', 'R-Hip', 'R-Knee',
'R-Ank', 'L-Hip', 'L-Knee', 'L-Ank', 'R-Eye', 'L-Eye', 'R-Ear', 'L-Ear'] # 18
POSE_PAIRS = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7],
[1,8], [8,9], [9,10], [1,11], [11,12], [12,13],
[1,0], [0,14], [14,16], [0,15], [15,17],
[2,16], [5,17]] # 19
# index of pafs correspoding to the POSE_PAIRS
# e.g for POSE_PAIR(1,2), the PAFs are located at indices (31,32) of output, Similarly, (1,5) -> (39,40) and so on.
mapIdx = [[31,32], [39,40], [33,34], [35,36], [41,42], [43,44],
[19,20], [21,22], [23,24], [25,26], [27,28], [29,30],
[47,48], [49,50], [53,54], [51,52], [55,56],
[37,38], [45,46]] # 19
colors = [[0,100,255], [0,100,255], [0,255,255], [0,100,255], [0,255,255], [0,100,255],
[0,255,0], [255,200,100], [255,0,255], [0,255,0], [255,200,100], [255,0,255],
[0,0,255], [255,0,0], [200,200,0], [255,0,0], [200,200,0],
[0,0,0], [255,255,255]]
def getKeypoints(probMap, threshold=0.1, name=None, plotmask=False, ori=False):
"""
:param probMap:
:param threshold:
:param name: the name of keypoints
:param plotmask: only plot keypoints hot maps
:param ori: plot original image with keypoints hot maps
:return:
"""
mapSmooth = cv2.GaussianBlur(probMap,(3,3),0,0) # (415, 640)
mapMask = np.uint8(mapSmooth>threshold) # (415, 640)
if plotmask:
if ori:
plt.imshow(cv2.cvtColor(image1, cv2.COLOR_BGR2RGB))
plt.imshow(mapMask, alpha=0.6)
else:
plt.imshow(mapMask)
plt.title(name)
plt.axis("off")
plt.show()
keypoints = []
# find the blobs
contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# for each blob find the maxima
for cnt in contours:
blobMask = np.zeros(mapMask.shape)
blobMask = cv2.fillConvexPoly(blobMask, cnt, 1)
maskedProbMap = mapSmooth * blobMask
_, maxVal, _, maxLoc = cv2.minMaxLoc(maskedProbMap)
keypoints.append(maxLoc + (probMap[maxLoc[1], maxLoc[0]],))
return keypoints
# Find valid connections between the different joints of a all persons present
def getValidPairs(output): # (1, 57, 46, 71)
valid_pairs = []
invalid_pairs = []
n_interp_samples = 10
paf_score_th = 0.1
conf_th = 0.7
# loop for every POSE_PAIR
for k in range(len(mapIdx)): # 19
# A->B constitute a limb
pafA = output[0, mapIdx[k][0], :, :] # (46, 71) 预测出来的热力图
pafB = output[0, mapIdx[k][1], :, :] # # (46, 71)
pafA = cv2.resize(pafA, (frameWidth, frameHeight)) # 缩放到原始尺寸
pafB = cv2.resize(pafB, (frameWidth, frameHeight))
# Find the keypoints for the first and second limb
candA = detected_keypoints[POSE_PAIRS[k][0]] # 预测出来的关键点对之一
candB = detected_keypoints[POSE_PAIRS[k][1]]
nA = len(candA) # 5
nB = len(candB) # 5
# If keypoints for the joint-pair is detected
# check every joint in candA with every joint in candB
# Calculate the distance vector between the two joints
# Find the PAF values at a set of interpolated points between the joints
# Use the above formula to compute a score to mark the connection valid
if( nA != 0 and nB != 0):
valid_pair = np.zeros((0,3))
for i in range(nA): # 遍历关键点对,来锁定 id
max_j=-1
maxScore = -1
found = 0
for j in range(nB):
# Find d_ij
d_ij = np.subtract(candB[j][:2], candA[i][:2]) # array([-44, 1])
"""
candB[j][:2] (76, 213)
candA[i][:2] (120, 212)
"""
norm = np.linalg.norm(d_ij) # 44.01136216933077
if norm: # 归一化,单位向量,仅包含方向信息
d_ij = d_ij / norm # array([-0.99974184, 0.02272141])
else:
continue
# Find p(u) 可以理解为方向信息,细粒度为 n_interp_samples
interp_coord = list(zip(np.linspace(candA[i][0], candB[j][0], num=n_interp_samples),
np.linspace(candA[i][1], candB[j][1], num=n_interp_samples)))
"""interp_coord
[(120.0, 212.0),
(115.11111111111111, 212.11111111111111),
(110.22222222222223, 212.22222222222223),
(105.33333333333333, 212.33333333333334),
(100.44444444444444, 212.44444444444446),
(95.55555555555556, 212.55555555555554),
(90.66666666666666, 212.66666666666666),
(85.77777777777777, 212.77777777777777),
(80.88888888888889, 212.88888888888889),
(76.0, 213.0)]
"""
# Find L(p(u))
paf_interp = []
for k in range(len(interp_coord)): # 10,真实的热力图
paf_interp.append([pafA[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))],
pafB[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))]])
"""paf_interp
[[-0.7271141, 0.026046006],
[-0.7272271, 0.034134787],
[-0.7136169, 0.03712852],
[-0.6821976, 0.033510227],
[-0.64272165, 0.029791266],
[-0.637096, 0.027447203],
[-0.6130011, 0.03427602],
[-0.59634197, 0.047225572],
[-0.56582874, 0.03321767],
[-0.5306641, 0.013872173]]
"""
# Find E
paf_scores = np.dot(paf_interp, d_ij) # 乘以方向向量
"""
array([0.72751817, 0.72781494, 0.71427629, 0.68278285, 0.64323262,
0.63755515, 0.61362165, 0.59726104, 0.56643742, 0.53084228])
"""
avg_paf_score = sum(paf_scores)/len(paf_scores) # 0.644134241816446
# Check if the connection is valid
# If the fraction of interpolated vectors aligned with PAF is higher then threshold -> Valid Pair
if (len(np.where(paf_scores > paf_score_th)[0]) / n_interp_samples ) > conf_th :
# 70 % 的位置,预测的热力图与关键点对的方向向量得分高于 0.1 才统计
if avg_paf_score > maxScore:
max_j = j
maxScore = avg_paf_score
found = 1
# Append the connection to the list
if found: # 前两维度是 id,最后一个维度是匹配的最大得分
valid_pair = np.append(valid_pair, [[candA[i][3], candB[max_j][3], maxScore]], axis=0)
# Append the detected connections to the global list
valid_pairs.append(valid_pair)
else: # If no keypoints are detected
print("No Connection : k = {}".format(k))
invalid_pairs.append(k)
valid_pairs.append([])
return valid_pairs, invalid_pairs
# This function creates a list of keypoints belonging to each person
# For each detected valid pair, it assigns the joint(s) to a person
def getPersonwiseKeypoints(valid_pairs, invalid_pairs):
# the last number in each row is the overall score
"""
:param valid_pairs:
[array(
[[ 5. , 10. , 0.64413389],
[ 6. , 11. , 0.74945025],
[ 7. , 14. , 0.69439634],
[ 8. , 12. , 0.77380336],
[ 9. , 13. , 0.88797685]]),
array([[ 5. , 22. , 0.71357969],
[ 6. , 24. , 0.70100939],
[ 7. , 23. , 0.68946706],
[ 8. , 26. , 0.69886481],
[ 9. , 25. , 0.68914866]]),
array([[10. , 15. , 0.76443874],
[11. , 16. , 0.88026235],
[13. , 17. , 0.85884366],
[14. , 18. , 0.62773099]]),
array([[15. , 19. , 0.85153277],
[16. , 21. , 0.87127684],
[17. , 20. , 0.67454177]]),
array([[23. , 27. , 0.74397696],
[24. , 28. , 0.82822082],
[25. , 30. , 0.6818888 ],
[26. , 29. , 0.71478186]]),
array([[27. , 32. , 0.61767912],
[28. , 33. , 0.74895881],
[29. , 31. , 0.77105165],
[30. , 34. , 0.68680468]]),
array([[ 5. , 39. , 0.81562783],
[ 6. , 37. , 0.72100994],
[ 7. , 35. , 0.35518334],
[ 8. , 38. , 0.41633907],
[ 9. , 40. , 0.60830615]]),
[],
[],
array([[ 5. , 46. , 0.79543895],
[ 6. , 43. , 0.83959826],
[ 7. , 41. , 0.54028693],
[ 8. , 44. , 0.52806334],
[ 9. , 45. , 0.77960505]]),
[],
[],
array([[5. , 0. , 0.76778048],
[6. , 1. , 0.87967553],
[7. , 2. , 0.32408468],
[8. , 4. , 0.9326401 ],
[9. , 3. , 0.92137517]]),
array([[ 0. , 48. , 0.99980192],
[ 1. , 47. , 0.85538912],
[ 3. , 50. , 0.85749141],
[ 4. , 49. , 0.23465861]]),
array([[48. , 56. , 0.92556737]]),
array([[ 0. , 51. , 0.88774426],
[ 1. , 52. , 0.73518096],
[ 3. , 54. , 0.64213411],
[ 4. , 55. , 0.63751561]]),
array([[51. , 57. , 0.15763416],
[52. , 59. , 0.76725757],
[53. , 58. , 0.51270653],
[54. , 61. , 0.84404873],
[55. , 60. , 0.83550541]]),
array([], shape=(0, 3), dtype=float64),
array([], shape=(0, 3), dtype=float64)]
:param invalid_pairs:
[7, 8, 10, 11]
:return:
"""
personwiseKeypoints = -1 * np.ones((0, 19)) # array([], shape=(0, 19), dtype=float64), 一个人建立一个
for k in range(len(mapIdx)): # traverse 19 keypoints pairs
if k not in invalid_pairs:
partAs = valid_pairs[k][:,0] # array([5., 6., 7., 8., 9.]),有效的 id 之一,比如头
partBs = valid_pairs[k][:,1] # array([10., 11., 14., 12., 13.]) 有效的 id,比如颈,头颈配对
indexA, indexB = np.array(POSE_PAIRS[k]) # 1, 2 map keypoint pairs index
for i in range(len(valid_pairs[k])): # 遍历每个关键点的有效匹配对, eg 5
found = 0
person_idx = -1
for j in range(len(personwiseKeypoints)):
if personwiseKeypoints[j][indexA] == partAs[i]:
person_idx = j
found = 1
break
if found:
personwiseKeypoints[person_idx][indexB] = partBs[i]
personwiseKeypoints[person_idx][-1] += keypoints_list[partBs[i].astype(int), 2] + valid_pairs[k][i][2]
# if find no partA in the subset, create a new subset
# elif not found and k < 17:
elif not found:
row = -1 * np.ones(19)
"""
array([-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.,
-1., -1., -1., -1., -1., -1.])
"""
row[indexA] = partAs[i]
row[indexB] = partBs[i]
"""
array([-1., 5., 10., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.,
-1., -1., -1., -1., -1., -1.])
"""
# add the keypoint_scores for the two keypoints and the paf_score
row[-1] = sum(keypoints_list[valid_pairs[k][i,:2].astype(int), 2]) + valid_pairs[k][i][2]
"""point predict score sum + match score
valid_pairs[k][i,:2].astype(int)
array([ 5, 10])
keypoints_list[valid_pairs[k][i,:2].astype(int)
array([[120. , 212. , 0.70358133],
[ 76. , 213. , 0.62042749]])
sum(keypoints_list[valid_pairs[k][i,:2].astype(int), 2])
1.324008822441101
valid_pairs[k][i][2]
0.6441338935853772
"""
personwiseKeypoints = np.vstack([personwiseKeypoints, row])
return personwiseKeypoints
frameWidth = image1.shape[1] # 640
frameHeight = image1.shape[0] # 415
t = time.time()
net = cv2.dnn.readNetFromCaffe(protoFile, weightsFile)
if args.device == "cpu":
net.setPreferableBackend(cv2.dnn.DNN_TARGET_CPU)
print("Using CPU device")
elif args.device == "gpu":
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
print("Using GPU device")
# Fix the input Height and get the width according to the Aspect Ratio
inHeight = 368
inWidth = int((inHeight/frameHeight)*frameWidth) # input size of network 567
inpBlob = cv2.dnn.blobFromImage(image1, 1.0 / 255, (inWidth, inHeight),
(0, 0, 0), swapRB=False, crop=False) # (1, 3, 368, 567) n c h w
net.setInput(inpBlob)
output = net.forward() # (1, 57, 46, 71) = 1/8 input size
print("Time Taken in forward pass = {}".format(time.time() - t))
detected_keypoints = []
keypoints_list = np.zeros((0,3))
keypoint_id = 0
threshold = 0.1
for part in range(nPoints):
probMap = output[0, part, :, :] # (46, 71)
probMap = cv2.resize(probMap, (image1.shape[1], image1.shape[0])) # (415, 640)
keypoints = getKeypoints(probMap, threshold,
name=keypointsMapping[part], plotmask=False, ori=False)
print("Keypoints - {} : {}".format(keypointsMapping[part], keypoints))
keypoints_with_id = []
for i in range(len(keypoints)): # 关键点由横纵坐标加上预测的概率构成
keypoints_with_id.append(keypoints[i] + (keypoint_id,)) # [(139, 184, 0.9356266, 0)]
keypoints_list = np.vstack([keypoints_list, keypoints[i]]) # 仅保存关键点
keypoint_id += 1
"""keypoints_with_id
[(139, 184, 0.9356266, 0),
(283, 184, 0.7527172, 1),
(445, 167, 0.16425498, 2),
(185, 132, 0.70591646, 3),
(375, 130, 0.7945156, 4)]
"""
"""keypoints_list
array([[1.39000000e+02, 1.84000000e+02, 9.35626626e-01],
[2.83000000e+02, 1.84000000e+02, 7.52717197e-01],
[4.45000000e+02, 1.67000000e+02, 1.64254978e-01],
[1.85000000e+02, 1.32000000e+02, 7.05916464e-01],
[3.75000000e+02, 1.30000000e+02, 7.94515610e-01]])
"""
detected_keypoints.append(keypoints_with_id) # 18 个关键点,每个关键点对应的所有 id 都被记录
frameClone = image1.copy()
for i in range(nPoints): # 遍历 18 个人体关键点
for j in range(len(detected_keypoints[i])): # 遍历测出来不同人行的同一关键点
cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA)
cv2.imshow("Keypoints",frameClone)
valid_pairs, invalid_pairs = getValidPairs(output)
"""
[array([[ 5. , 10. , 0.64413424],
[ 6. , 11. , 0.74945011],
[ 7. , 14. , 0.6943966 ],
[ 8. , 12. , 0.77380386],
[ 9. , 13. , 0.88797636]]),
array([[ 5. , 22. , 0.71357939],
[ 6. , 24. , 0.70100994],
[ 7. , 23. , 0.68946742],
[ 8. , 26. , 0.69886411],
[ 9. , 25. , 0.6891473 ]]),
array([[10. , 15. , 0.76443843],
[11. , 16. , 0.8802623 ],
[13. , 17. , 0.85884367],
[14. , 18. , 0.6277308 ]]),
array([[15. , 19. , 0.85153193],
[16. , 21. , 0.87127656],
[17. , 20. , 0.67454165]]),
array([[23. , 27. , 0.74397703],
[24. , 28. , 0.82822096],
[25. , 30. , 0.68188799],
[26. , 29. , 0.71478433]]),
array([[27. , 32. , 0.61767981],
[28. , 33. , 0.74895897],
[29. , 31. , 0.77105275],
[30. , 34. , 0.68680353]]),
array([[ 5. , 39. , 0.81562713],
[ 6. , 37. , 0.72100932],
[ 7. , 35. , 0.35518329],
[ 8. , 38. , 0.41634064],
[ 9. , 40. , 0.60830599]]),
[],
[],
array([[ 5. , 46. , 0.79543855],
[ 6. , 43. , 0.83959791],
[ 7. , 41. , 0.54028693],
[ 8. , 44. , 0.52806448],
[ 9. , 45. , 0.77960484]]),
[],
[],
array([[5. , 0. , 0.76778028],
[6. , 1. , 0.87967585],
[7. , 2. , 0.3240864 ],
[8. , 4. , 0.93264036],
[9. , 3. , 0.92137502]]),
array([[ 0. , 48. , 0.99980176],
[ 1. , 47. , 0.8553895 ],
[ 3. , 50. , 0.8574917 ],
[ 4. , 49. , 0.234658 ]]),
array([[48. , 56. , 0.92556764]]),
array([[ 0. , 51. , 0.88774432],
[ 1. , 52. , 0.73518203],
[ 3. , 54. , 0.6421336 ],
[ 4. , 55. , 0.63751756]]),
array([[51. , 57. , 0.1576337 ],
[52. , 59. , 0.76725765],
[53. , 58. , 0.51270921],
[54. , 61. , 0.84404863],
[55. , 60. , 0.8355063 ]]),
array([], shape=(0, 3), dtype=float64),
array([], shape=(0, 3), dtype=float64)]
"""
personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs)
"""
array([[ 0. , 5. , 10. , 15. , 19. ,
22. , -1. , -1. , 39. , -1. ,
-1. , 46. , -1. , -1. , 48. ,
51. , 56. , 57. , 17.53852353],
[ 1. , 6. , 11. , 16. , 21. ,
24. , 28. , 33. , 37. , -1. ,
-1. , 43. , -1. , -1. , 47. ,
52. , -1. , 59. , 20.03402336],
[ 2. , 7. , 14. , 18. , -1. ,
23. , 27. , 32. , 35. , -1. ,
-1. , 41. , -1. , -1. , -1. ,
-1. , -1. , 60. , 9.25869337],
[ 4. , 8. , 12. , -1. , -1. ,
26. , 29. , 31. , 38. , -1. ,
-1. , 44. , -1. , -1. , 49. ,
55. , -1. , 60. , 13.42448598],
[ 3. , 9. , 13. , 17. , 20. ,
25. , 30. , 34. , 40. , -1. ,
-1. , 45. , -1. , -1. , 50. ,
54. , -1. , 61. , 19.15941422],
[-1. , -1. , -1. , -1. , -1. ,
-1. , -1. , -1. , -1. , -1. ,
-1. , -1. , -1. , -1. , -1. ,
53. , -1. , 58. , 1.52428411]])
"""
# for i in range(17):
for i in range(19): # 17->19 画出耳朵和肩膀的连接
for n in range(len(personwiseKeypoints)): # 遍历不同的人
index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] # array([ 5., 10.])
if -1 in index:
continue
B = np.int32(keypoints_list[index.astype(int), 0]) # array([120, 76])
A = np.int32(keypoints_list[index.astype(int), 1]) # array([212, 213])
cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA)
cv2.imshow("Detected Pose", frameClone)
# cv2.imwrite("output.jpg", frameClone)
cv2.waitKey(0)输入

输出


演示下全身的效果
输入

输出


皮一下
输入

输出

动漫人物没有怎么识别出来关键点,AI 生成的真人关键点检出率不错
4、源码解读------检测关键点
根据预测的热力图获取关键点 getKeypoints
1.首先找出与关键点对应的区域的所有轮廓。
2.为该区域创建掩码。
3.通过将probMap与此掩码相乘,提取该区域的probMap。
4.求这个区域的局部极大值。这是为每个轮廓(关键点区域)做的。


















5、源码解读------找到有效对
上面 getKeypoints 找出关键点后,所有 id 都混在了一起,需要进行关键点配对------getValidPairs


原理
- 将组成这一对的两点的连线分开(eg头和肩膀)。在这条直线上找到n个点(n=10)。
- 检查这些点上的PAF(部分关联映射 Part Affinity Maps,由网络后面的38个特征图预测出,共19对关键点对)是否与连接这对点的直线方向相同。
- 如果方向匹配到一定程度,则为有效对。
很巧妙,不是单独根据距离来,不过没有看论文,不知道训练的时候标签是怎么生成的,盲猜一手高斯分布,哈哈
输出代码中有添加详细注释

6、源码解读------组装个人关键点
getPersonwiseKeypoints 把属于同个人的所有关键点组装在一起
这里索引比较多,有点绕,建议 debug 多看看
我们首先创建空列表
personwiseKeypoints来存储每个人的关键点。然后我们检查每一对,检查这对的partA是否已经出现在任何列表中。如果它存在,则意味着关键点属于这个列表,这对中的partB也应该属于这个人。因此,将该对的partB添加到找到partA的列表中
如果在任何列表中都没有partA,则意味着该对属于不在列表中的新人员,因此创建了一个新列表。
7、涉及到的库
cv2.dnn.blobFromImage
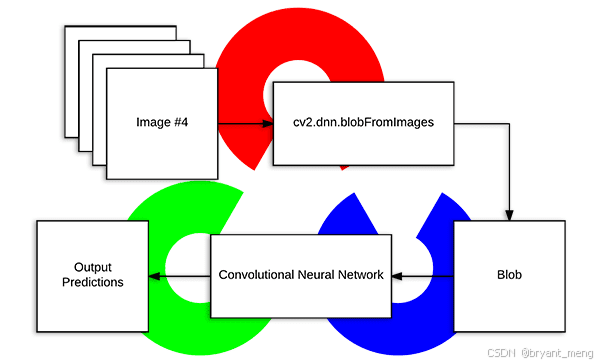
cv2.dnn.blobFromImage 是 OpenCV 库中用于深度学习模块(dnn)的一个非常有用的函数。这个函数的主要作用是将图像转换为网络可以处理的格式,即一个四维的 blob(批次、通道、高度、宽度)数据结构,通常还包含图像的归一化。这在将图像输入到深度学习模型(如使用 TensorFlow, PyTorch, Caffe 等训练的模型)之前是一个必要的步骤。
函数原型
python
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(300, 300), mean=(104.0, 117.0, 123.0), swapRB=True, crop=False)参数说明
- image: 输入图像,应为 numpy 数组格式(例如,通过 cv2.imread() 读取的图像)。
- scalefactor: 图像缩放比例。默认值为 1.0,表示不进行缩放。如果设置为其他值,比如 0.5,则图像会在宽度和高度上缩小到原来的一半(空间分辨率上的值,不是resize)。
- size: 输出 blob 的空间大小(宽度, 高度)。这个参数通常根据你要加载的模型的要求来设置。
- mean: 从图像中减去的平均值,通常针对每个通道(BGR)。这个参数取决于你训练的模型,很多预训练的模型(如使用 ImageNet 数据集训练的模型)会使用特定的平均值。
- swapRB: 一个布尔值,指示是否应该交换红色和蓝色通道。由于 OpenCV 默认以 BGR 格式读取图像,而许多预训练的模型(尤其是在 Caffe 中)期望输入图像为 RGB 格式,因此通常需要将此参数设置为 True。
- crop: 一个布尔值,如果设置为 True,则会在缩放图像时裁剪图像,以确保输出 blob 的尺寸完全匹配指定的尺寸。如果为 False,则通过缩放来尽可能接近目标尺寸,但可能不会完全匹配。
返回值
- blob: 转换后的图像数据,作为四维 numpy 数组返回,通常用于作为深度学习模型的输入。
使用示例
python
import cv2
# 加载图像
image = cv2.imread('path_to_image.jpg')
# 转换为 blob
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(300, 300), mean=(104.0, 117.0, 123.0), swapRB=True)
# 现在 blob 可以作为深度学习模型的输入了
# ...这个函数极大地简化了将图像数据预处理为深度学习模型所需格式的过程。
8、参考
参考学习来自
-
Code and model(单人)
链接:https://pan.baidu.com/s/1OoDWEc7bdwKbKBEqQ5oOdA
提取码:123a
-
Code(多人)
链接:https://pan.baidu.com/s/1Z5mRhYcKEJO5KkUE-yKCzw
提取码:123a