
语音克隆项目GPT-Sovits发布了V2版本,在早些时候做了V1版本的整合包,但是那个版本的整合包操作比较麻烦,上手难度高。正好趁着V2,一起更新了。
【GPT-SovitsV2,支持多语种,多音字优化,更好的音色,ZeroShot(WIN/MAC)】 https://www.bilibili.com/video/BV12MW2e4Ebx/?share_source=copy_web&vd_source=09316244e4ff3a9793930d67cf748288
更新内容
V2版本相对于V1版本更新了以下内容:
- 支持韩语及粤语,现在可5语种之间互相跨语种合成(跨语种合成,指训练集、参考音频语种和需要合成的语种不同)
- 更好的文本前端,持续迭代更新。v2中英文加入了多音字优化。
- 底模由2k小时扩展至5k小时,zero shot性能更好音色更像
- 对低音质参考音频(尤其是来源于网络的高频严重缺失、听着很闷的音频)合成出来音质更好
使用方法
其实跟V1版本的操作差不多,这里再重新介绍下。
主要分两大部分:数据集整理、模型训练与推理。
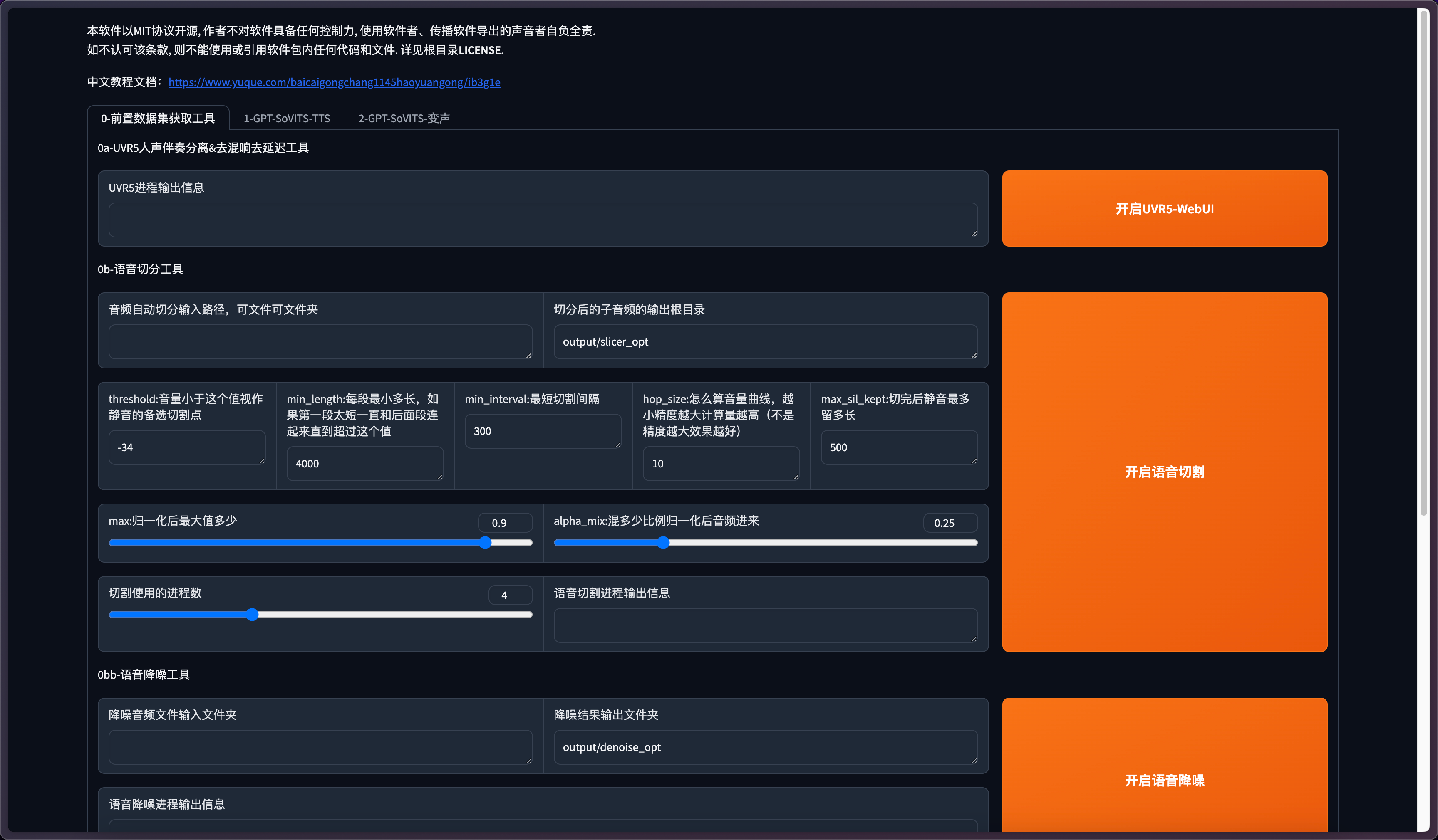
音频处理
UVR5人声伴奏分离
可选步骤,当音频有混响、伴奏等嘈杂的背景音,可以使用UVR5进行分离。
点击开启UVR5-WebUI

进入UVR5主界面
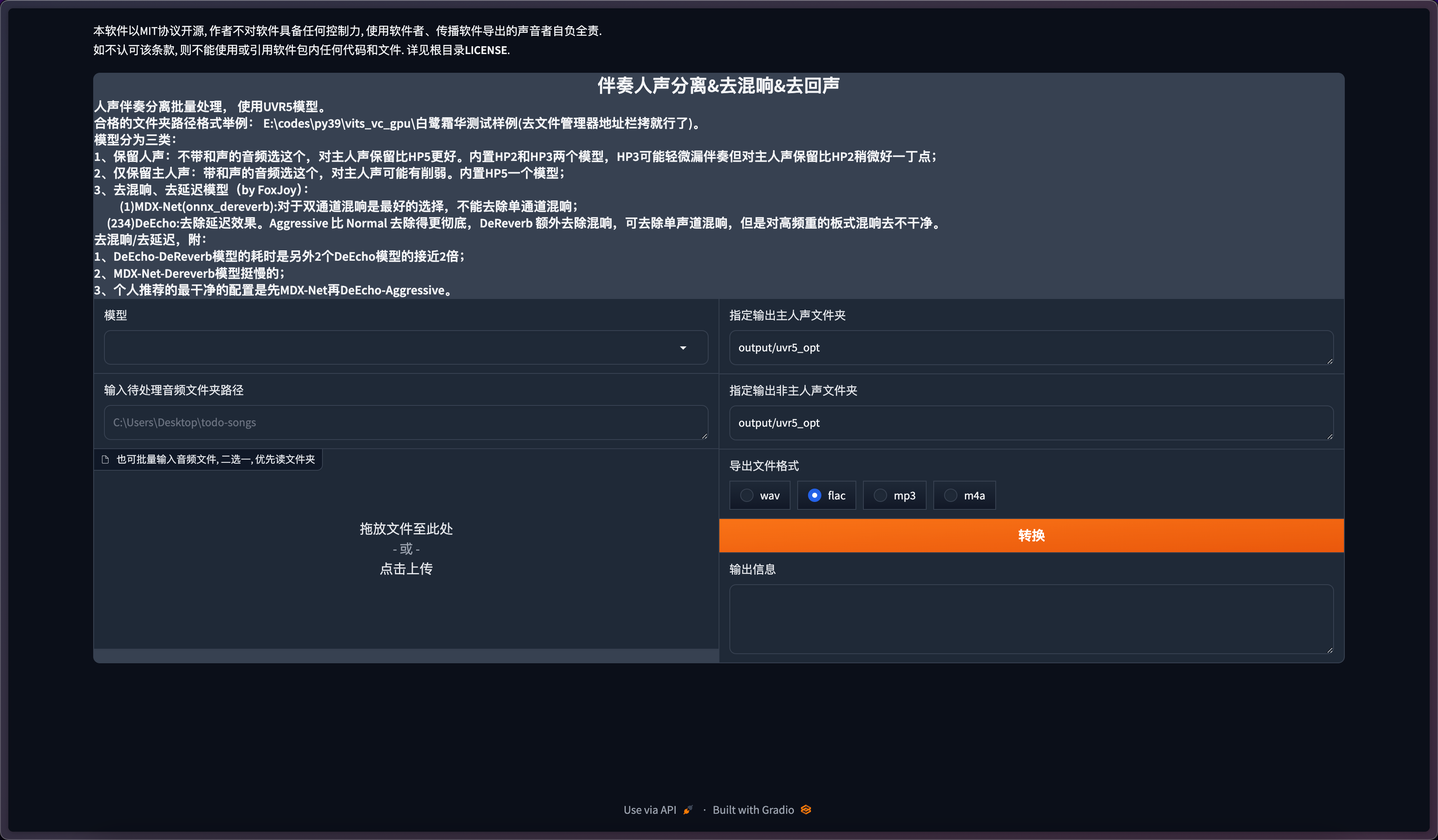
选择模型
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive 比 Normal 去除得更彻底,DeReverb 额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。
上传需要处理的音频或者是文件夹,导出格式选择wav,点击转换。
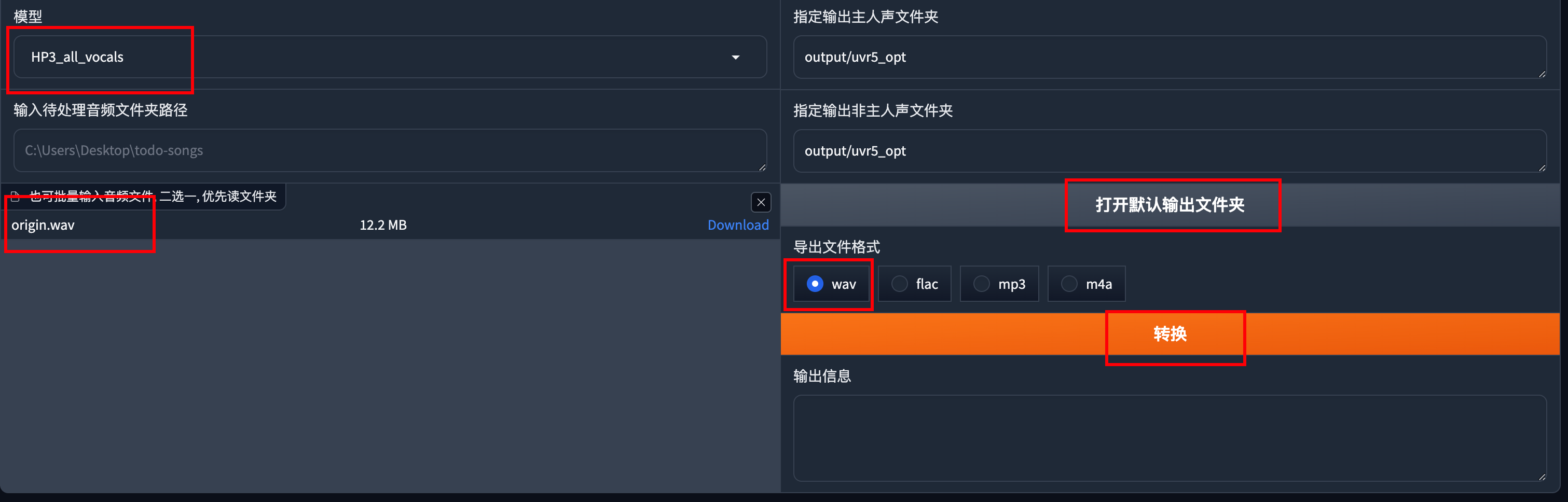
输出的文件在output/uvr5_opt
语音切分
必选步骤,将长音频进行切分处理
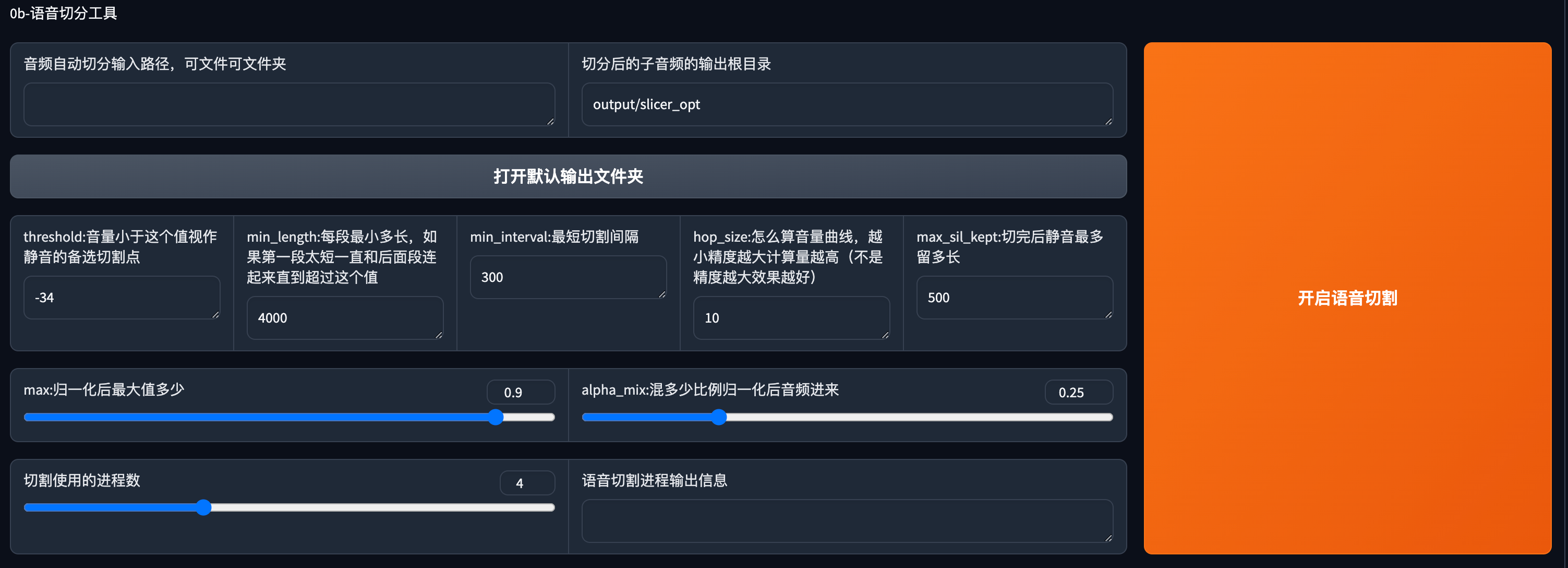
这一栏填入文件夹路径或者文件路径

举例:
Windows:
D:\RVC1006\xxx
Mac:
/Users/ccmahua/Downloads/DOC/Sound
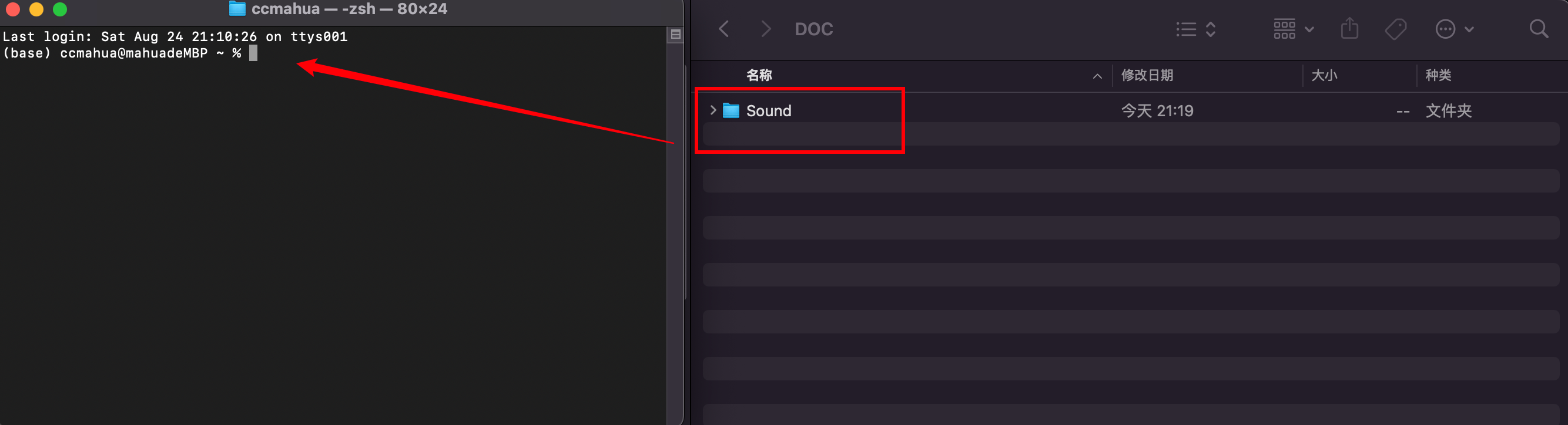
Mac上获取路径的方式
将文件夹拖入终端
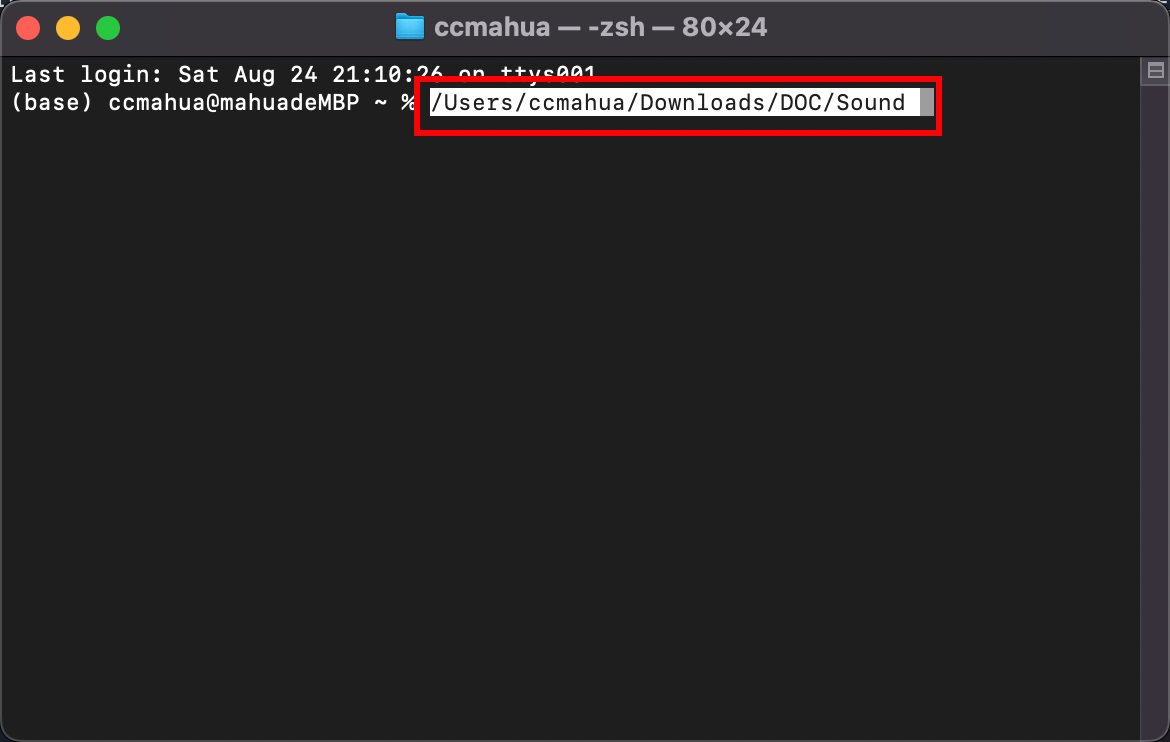
路径就会在终端内显示,将这个路径复制到GPT-Sovits中即可。
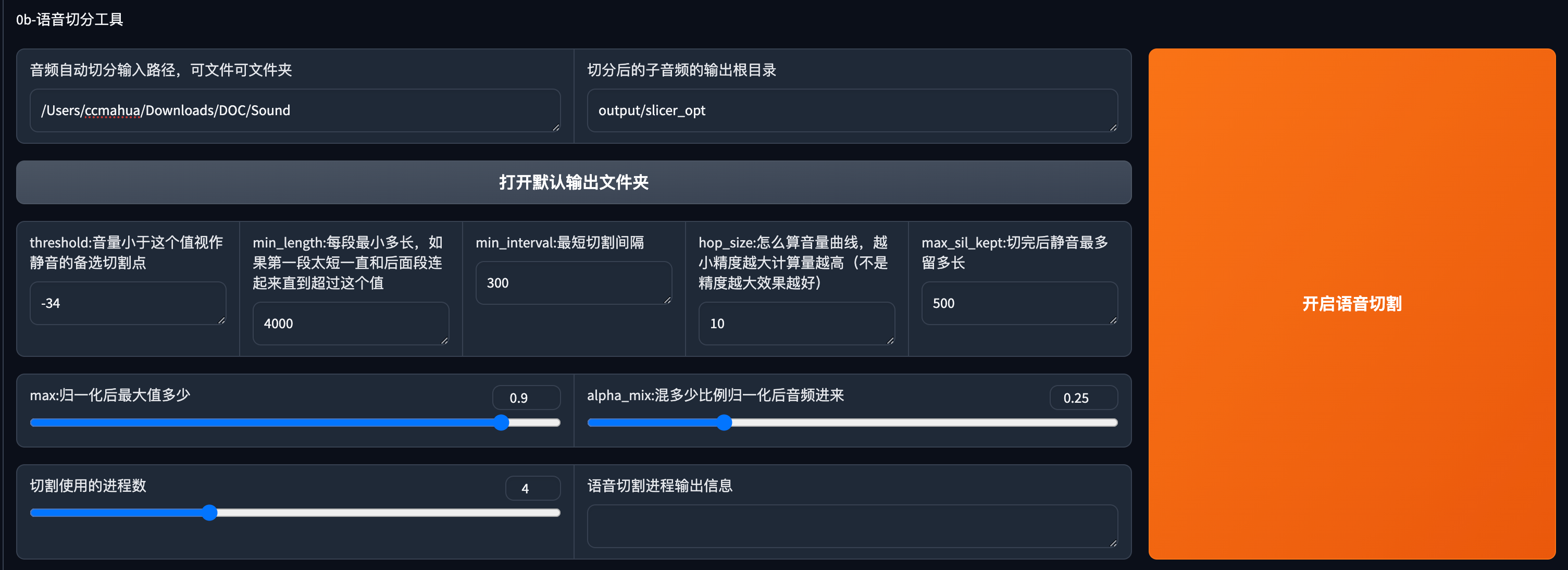
然后点击开启语音切割,输出目录可以不用改,默认的即可
等待切割结束

语音降噪
可选步骤,对切分好的音频进行降噪
默认的输入路径是刚才的切分文件夹目录,点击开启语音降噪
降噪需耐心等待一段时间
降噪完成
批量ASR
必选步骤,根据你处理的音频选择对应的asr处理方式。
默认是降噪输出的文件夹路径,如果你没执行降噪步骤,自行修改。

这里默认是中文的语种。

如果是其他语言,可设置ASR 模型为Faster Whisper
语言设置选择auto或者是其他的语言。(支持中、英、日、韩、粤)
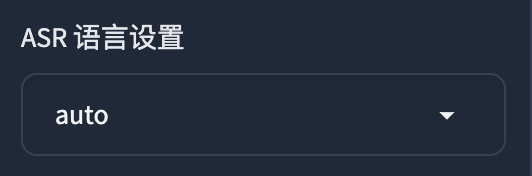
设置后点击开启离线批量ASR
处理完成


语音文本校对
这一步比较费时间,如果不追求极致效果,可以忽略这一步。
红框区域是根据音频生成对应的文字。黄框区域是对应的音频。这一步要做的是试听,然后根据音频来修改前面的文字和断句。
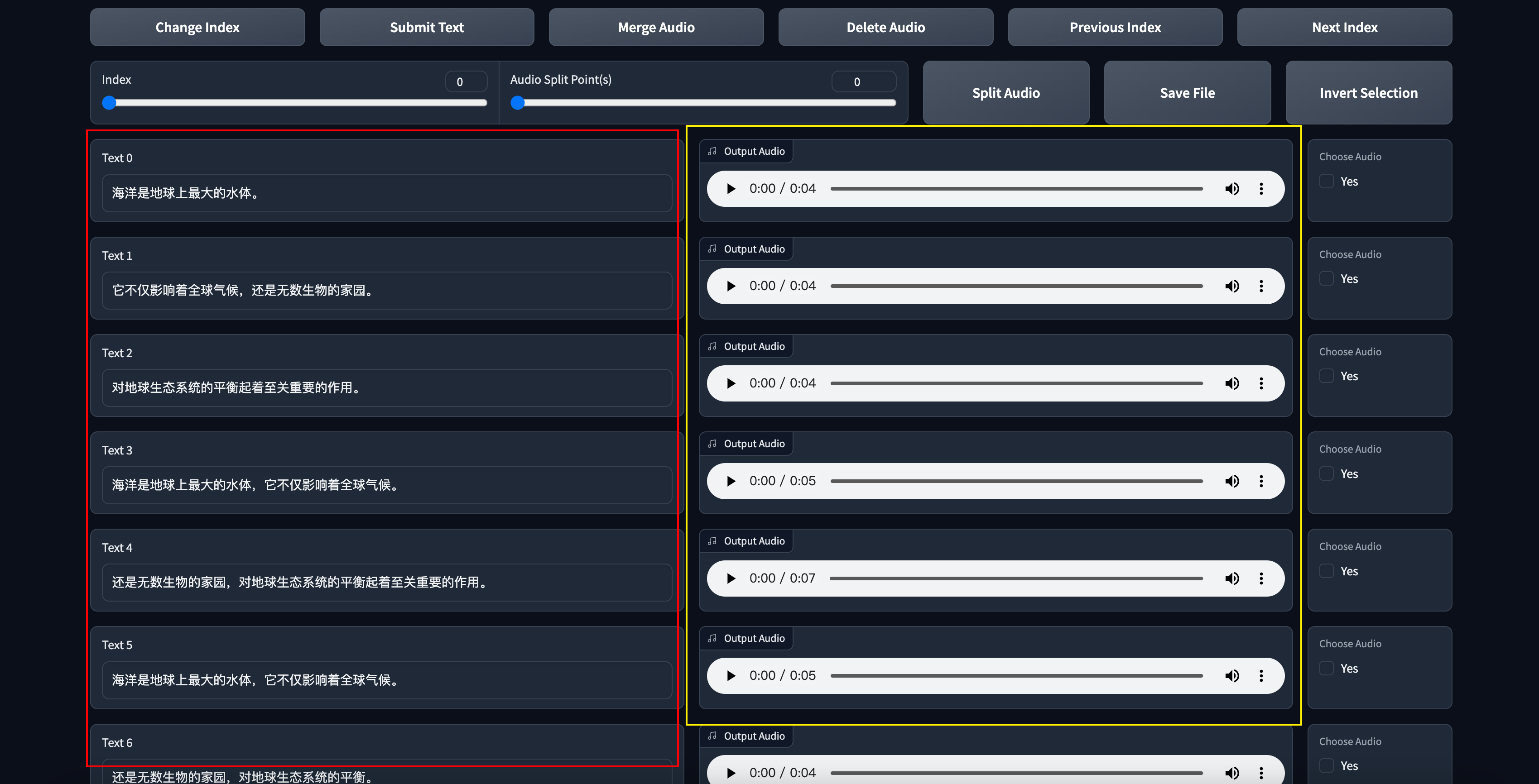
比如我们根据音频在句子中增加,来断句。
修改前:

修改后:

修改完后需要点击Submit Text和Save File来保存。

如果你的音频文件很长,你需要进行翻页操作对每句话进行校对,Previous Index 和 Next Index是上一页和下一页。

当你校对完成后,记得保存,随后关闭这个页面就可以了。回到主界面,关闭勾选。

数据集处理
点击GPT-SoVITS-TTS进入TTS界面。
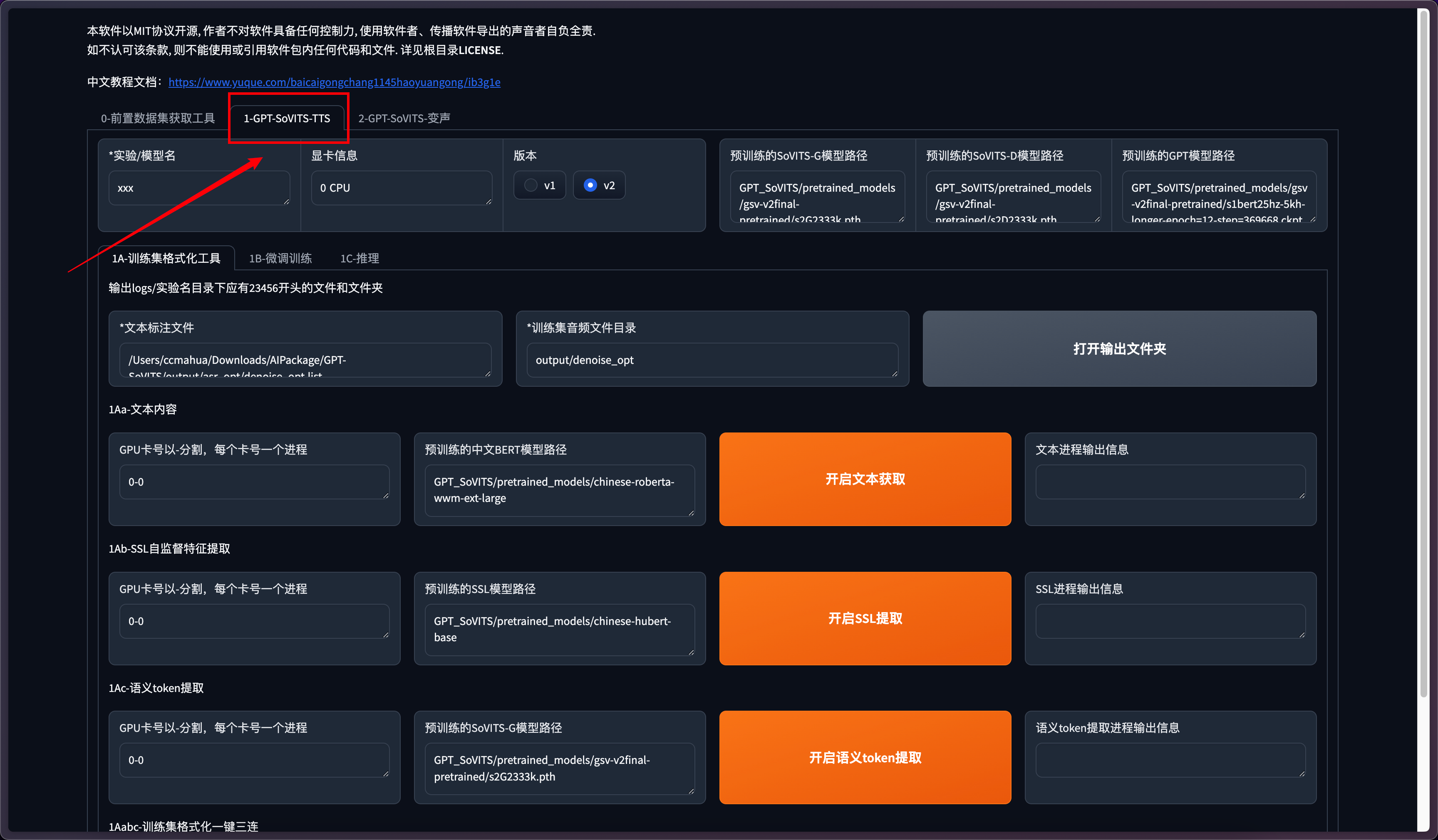
需要对模型的名称进行命名,默认是xxx,尽量避免中文命名(有可能会有些问题)
其他选项无需设置,保持默认的即可

选择训练格式化工具这一栏。在训练模型前需要对数据集进行处理。
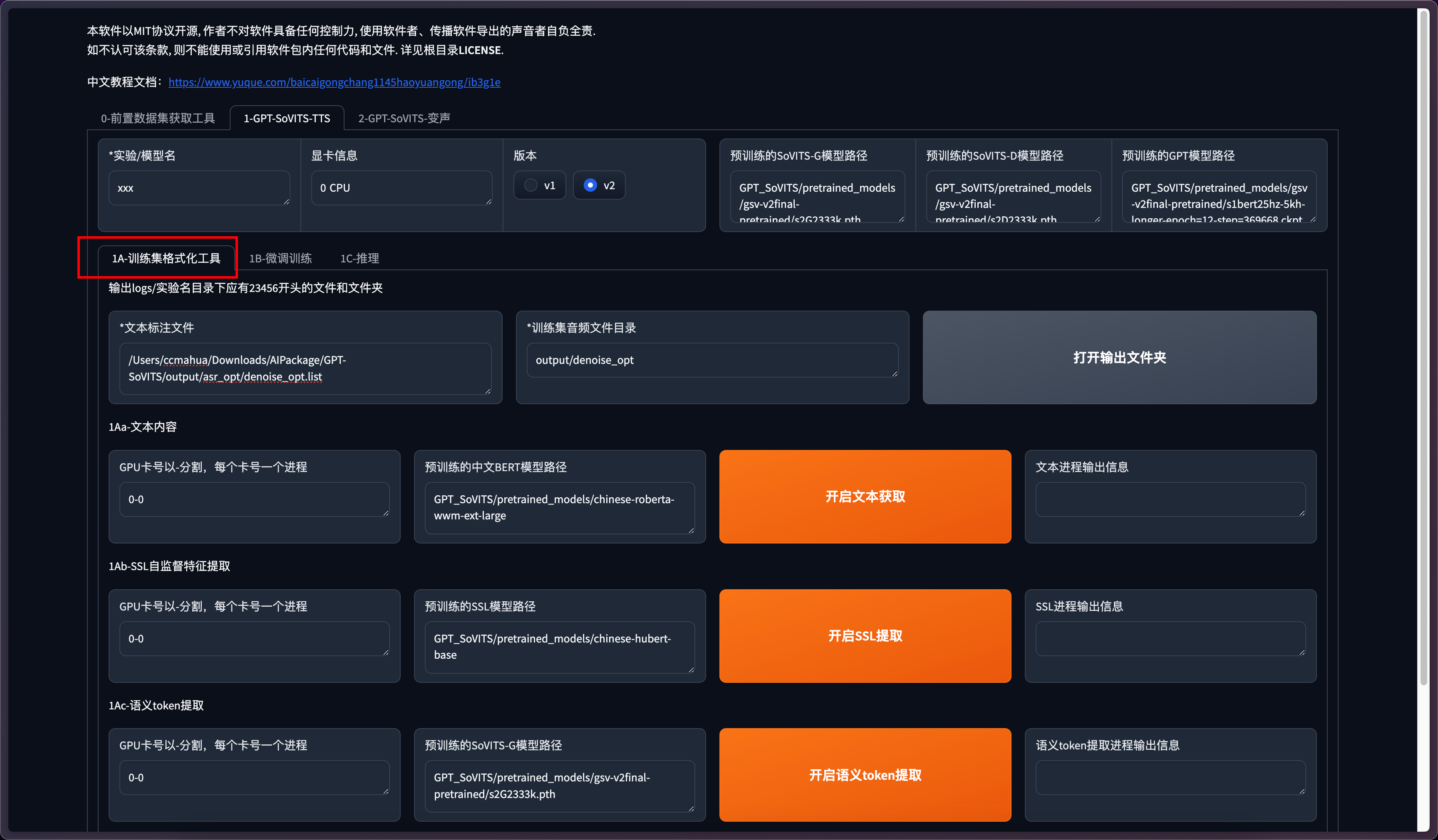
点击一键三连
其他开启文本获取、开启ssl提取、开启语义token提取选项不用执行。一键三连会自动执行上述步骤。
处理完成

打开输出文件夹
可以看到会生成对应名称的文件夹
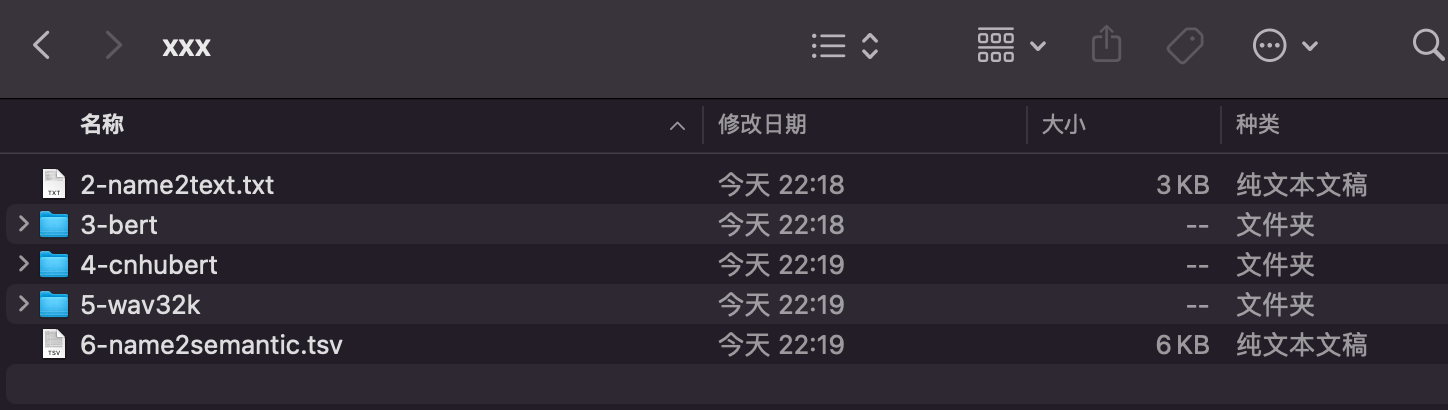
里面是一些数据集和其他配置文件
模型训练
接着进入训练模型的环节,点击微调训练
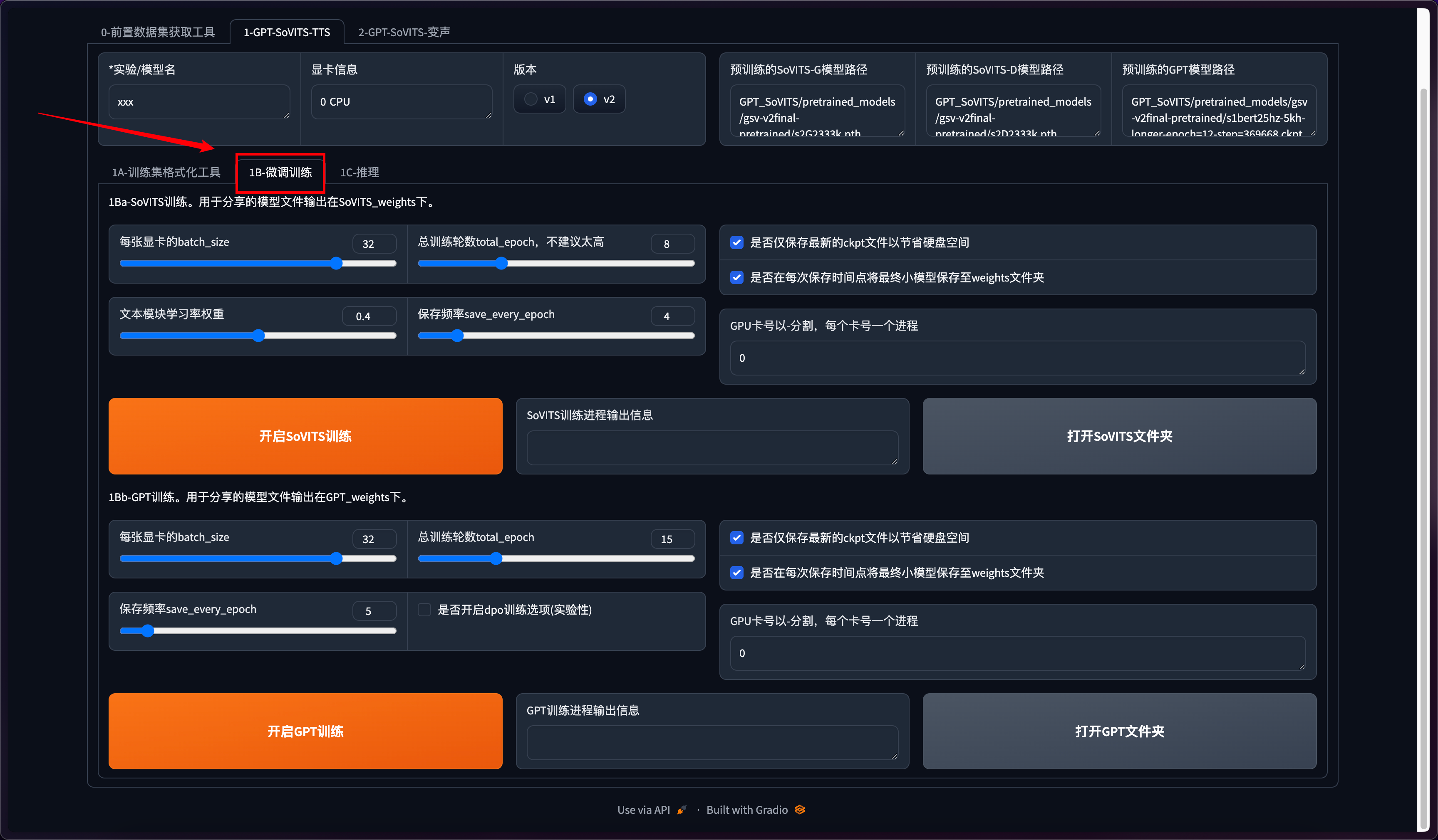
这里会看到两个训练,先点开启SoVITS训练,训练完后再点开启GPT训练,不可以一起训练(除非你有两张卡)!如果中途中断了,直接再点开始训练就好了,会从最近的保存点开始训练。
batch_size和总训练轮数这两个参数根据电脑配置来自行调整。训练轮数尽量别太高。其他选项为默认。
关于MAC上训练,需要注意的是用的是cpu,这里引用下官方的话。
在 Mac 上使用 GPU 训练的模型效果显著低于其他设备训练的模型,所以我们暂时使用 CPU 进行训练。
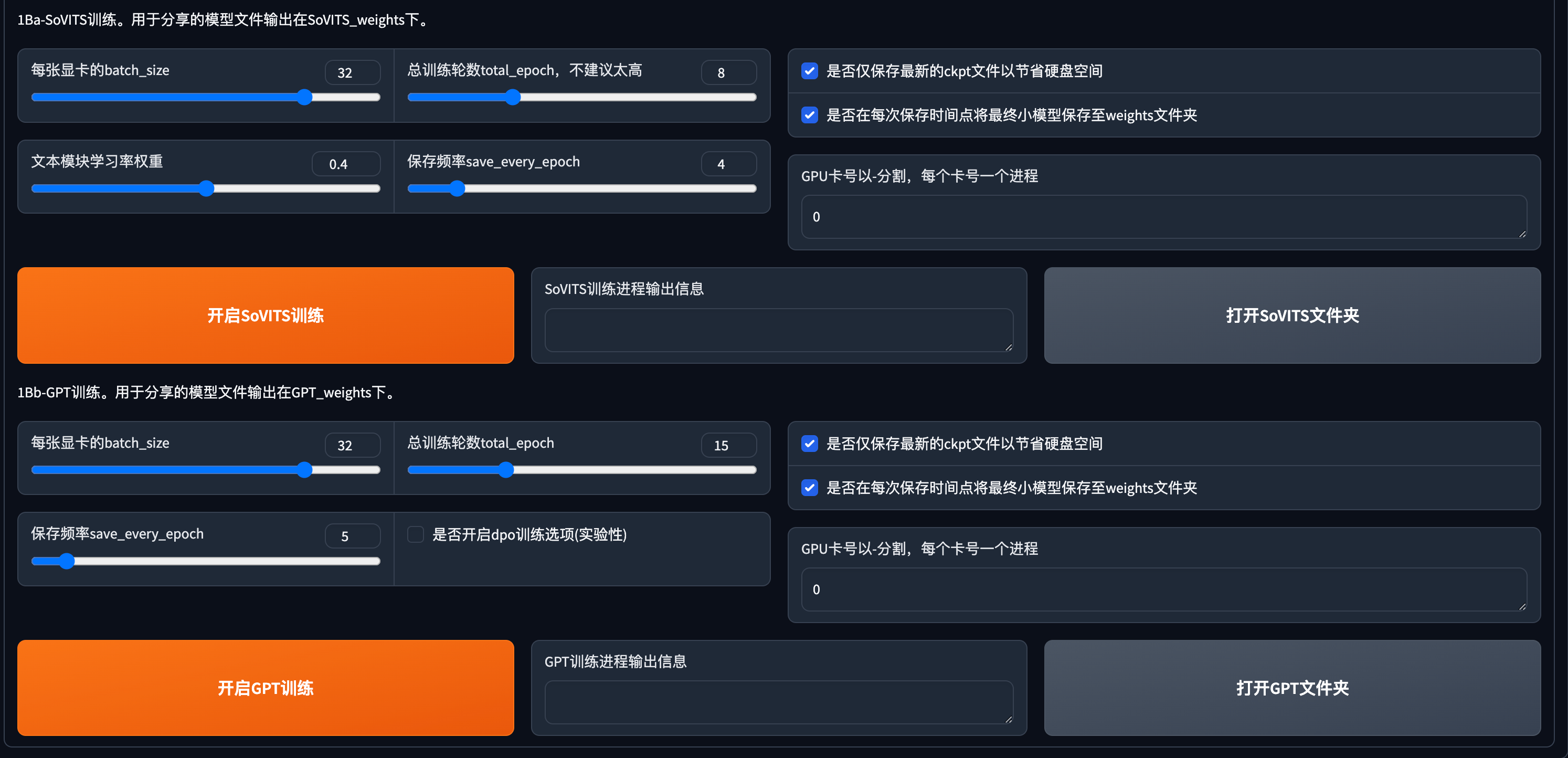
两个训练都完成后我们可以去模型文件夹确认下。两个训练生成的模型分别在整合包路径下/GPT_weights_v2 和 整合包路径下/SoVITS_weights_v2文件夹内。

推理
点击推理
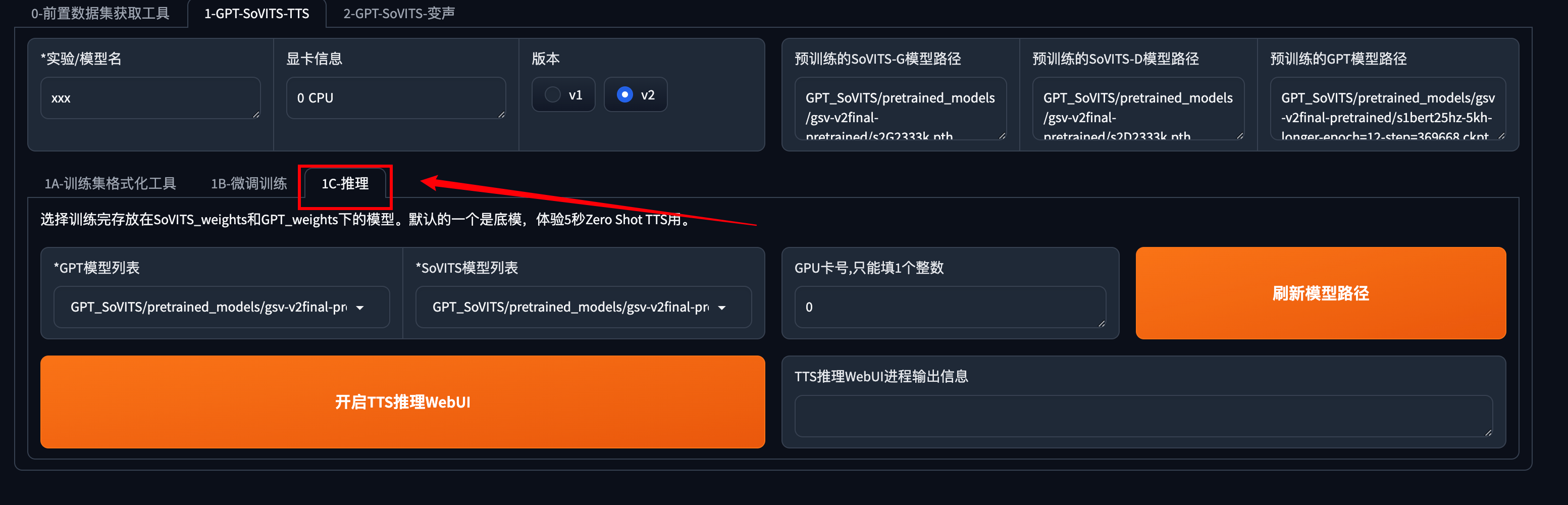
点击刷新模型路径
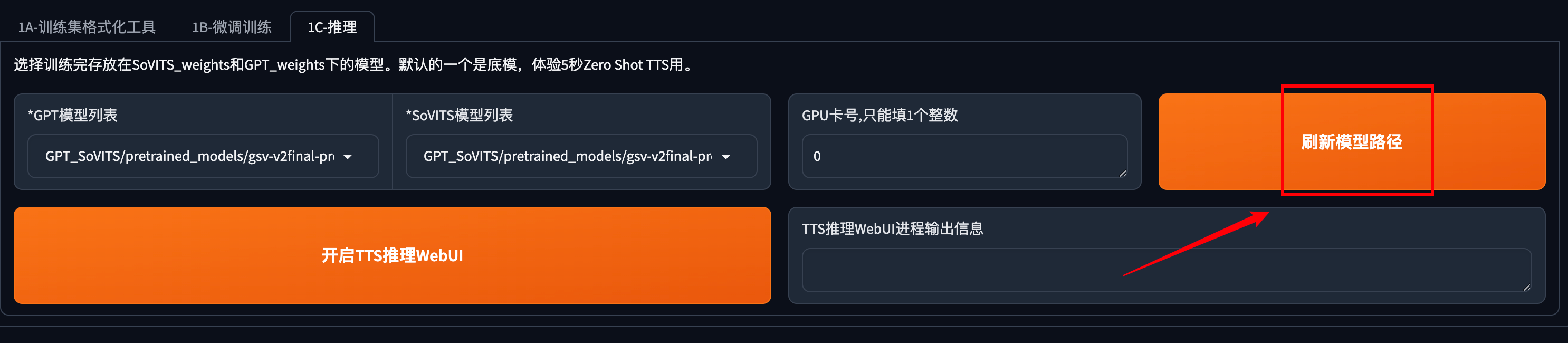
在左侧模型列表中选择你刚才训练好的模型
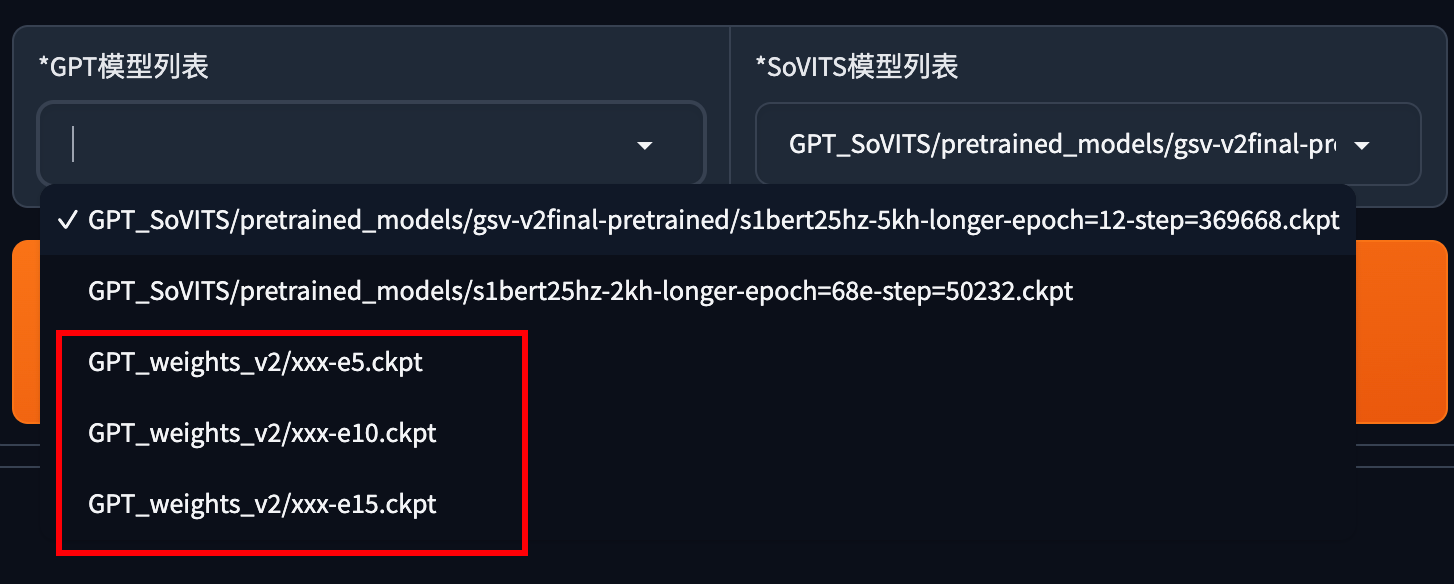
**e代表轮数,s代表步数。**不是轮数越高越好,这里我选择了e15进行推理。如果你选择轮数推理后的音频效果不理想,可以选择更高轮数的模型。
点击开启推理webui,进入推理界面。
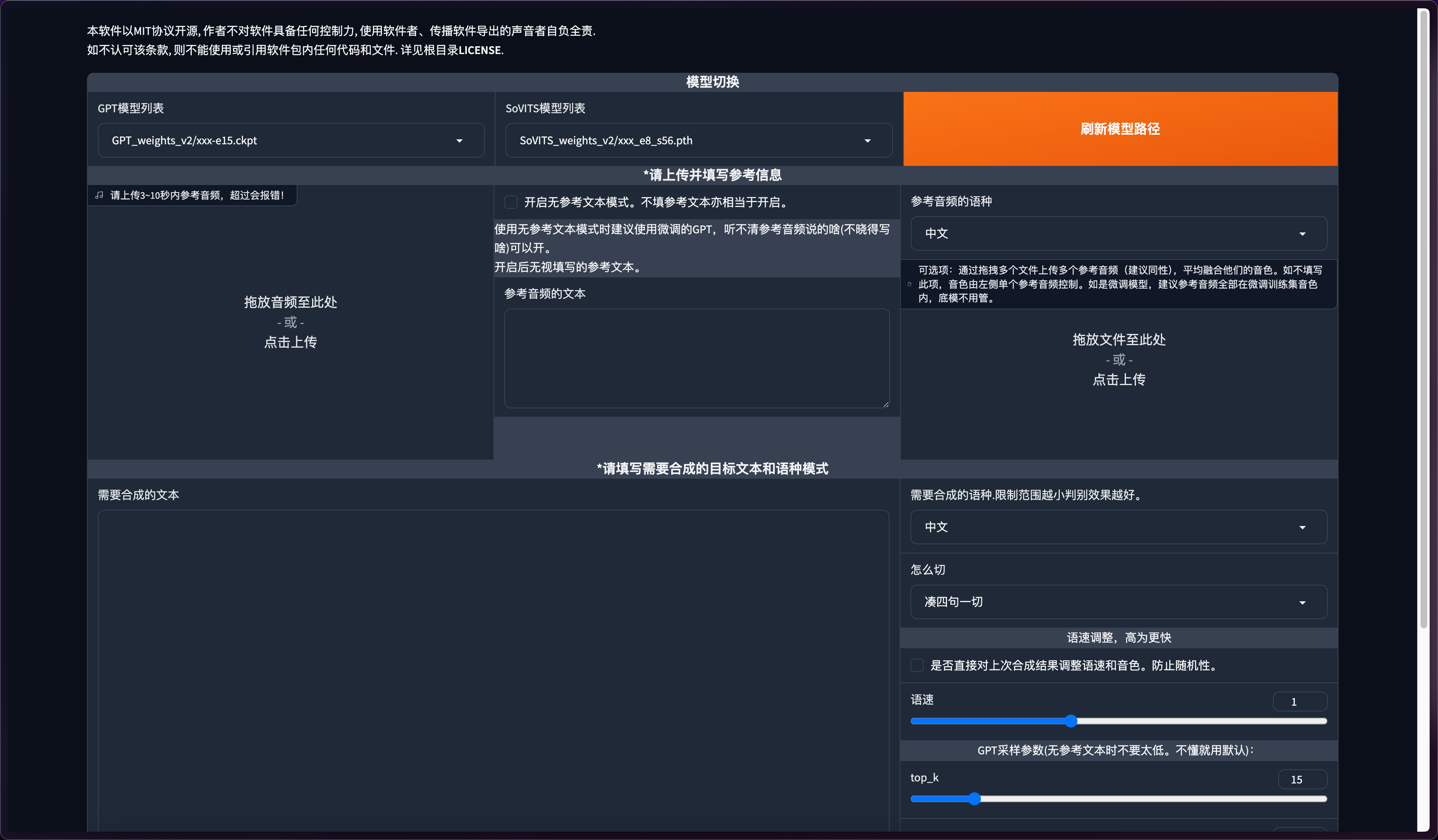
确认下模型是否跟刚才选的一样。

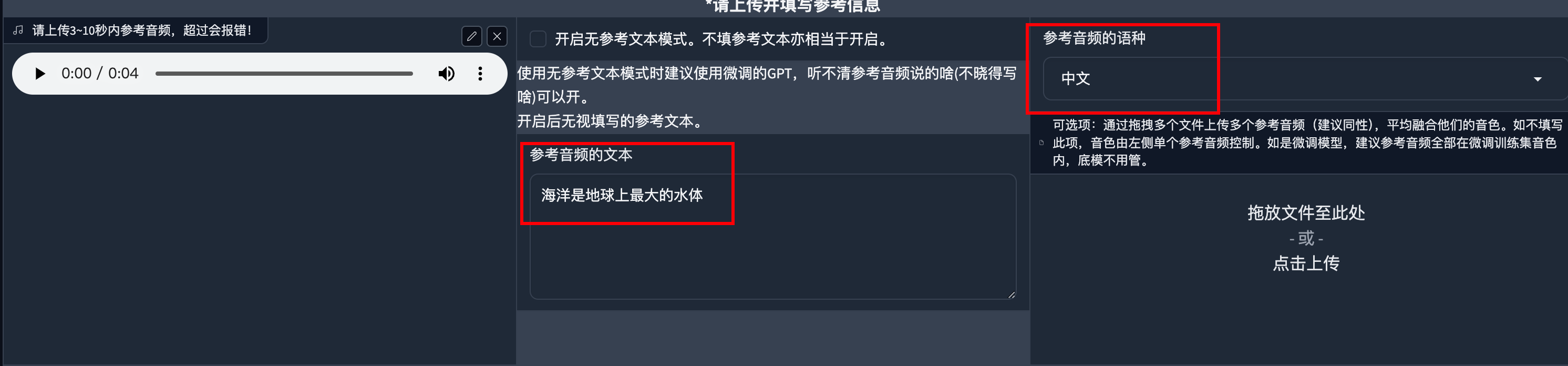
然后上传一段参考音频,建议是数据集中的音频。最好5秒。参考音频很重要!会学习语速和语气,请认真选择。
这里我选择的是降噪切分后的音频。
参考音频的文本是参考音频说什么就填什么,语种也要对应。
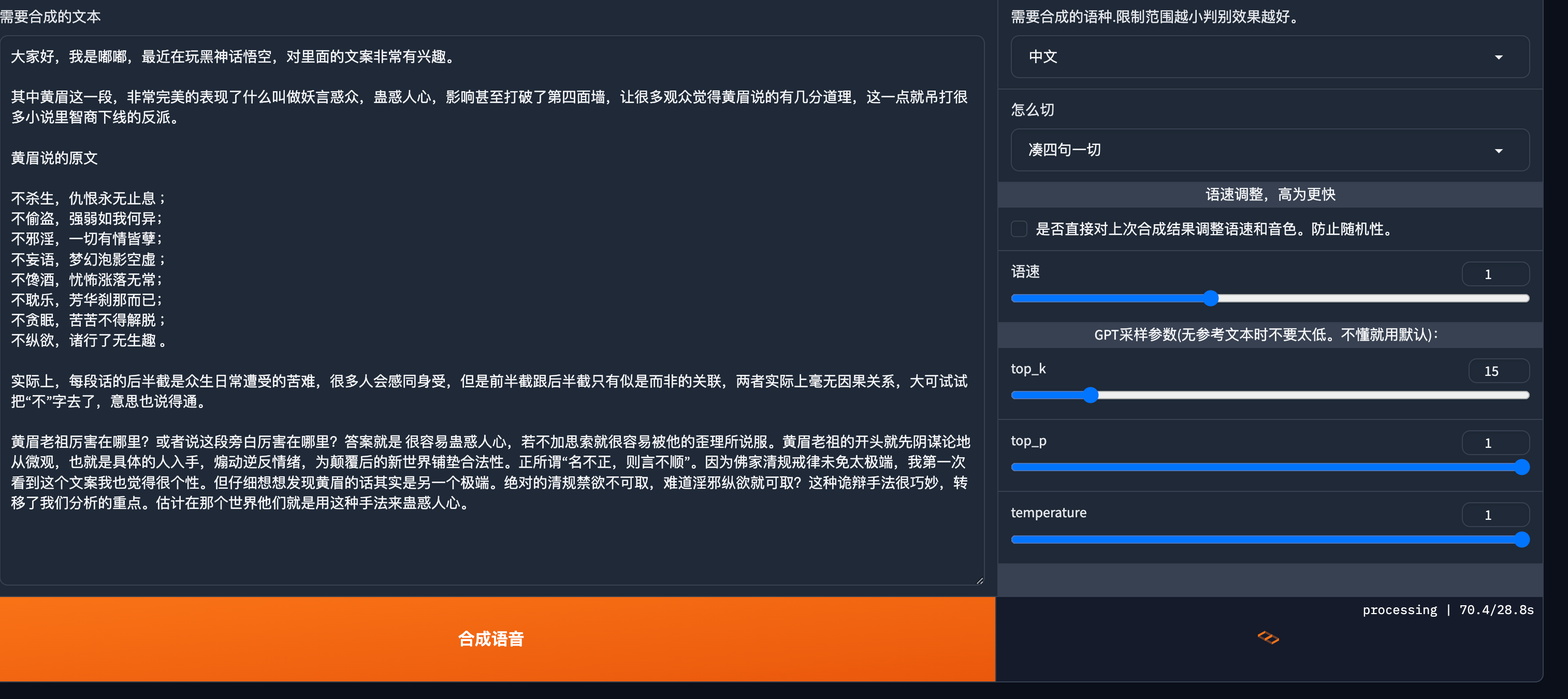
填入需要合成的文本,点击合成语音。
最后生成的音频
【GPT-SovitsV2,支持多语种,多音字优化,更好的音色,ZeroShot(WIN/MAC)】 https://www.bilibili.com/video/BV12MW2e4Ebx/?share_source=copy_web&vd_source=09316244e4ff3a9793930d67cf748288
到这里我们就训练好了一个模型,并且可以用它生成任意音频。
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
关注公众号,发送【GPT-SovitsV2】关键字获取整合包。
如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
【GPT-SovitsV2,支持多语种,多音字优化,更好的音色,ZeroShot(WIN/MAC)】 https://www.bilibili.com/video/BV12MW2e4Ebx/?share_source=copy_web&vd_source=09316244e4ff3a9793930d67cf748288
常见问题:
如何训练第二个模型?
将以下几个路径下的文件移走或者删除。否则第二次训练的时候会造成数据混淆。
标注文件夹整合包路径下/output/asr_opt
噪音音频切分文件夹整合包路径下/output/denoise_opt
音频切分文件夹整合包路径下/output/slicer_opt
如果你第二次不修改模型名字,那你需要将整合包路径下/logs/文件夹内的模型同名文件夹移走或删除。也可以直接修改模型名字。
如何分享我训练的模型?
将下面这两个路径下的文件粘贴到别人的同样的目录下即可。
整合包路径下/SoVITS_weightsV2
整合包路径下/GPT_weightsV2
怎么样才算训练好一个模型?
这个问题其实没有一个准确答案,模型的训练取决于你的数据集质量、时长,轮数,等因素。每次训练完成后听下看看是否满足你的心里预期。如果你的模型推理出来的效果一直不理想,你应该重点关注下你的数据集是否有问题。
最后感谢阳光老师提供的音频素材。
制作不易,如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!