中间件是介于操作系统和在其上运行的应用程序之间的软件,实现了分布式应用程序的通信和数据管理,用于协调不同的系统和组件之间的通信,是连接应用与底层资源之间的桥梁。因此,中间件的稳定与高可用对于整个业务系统的可靠性和性能至关重要。
北京智和信中间件监控运维方案通过对中间件的实时监控和编排运维,提高对中间件故障的感知、分析、解决能力,保障中间件持续稳定运行。
第1章 中间件监控范围与指标
智和信通方案通过构建对Tomcat、Jboss、WebLogic等中间件的关键指标的监控,实现对中间件性能和资源的实时追踪,识别并解决影响中间件性能的问题,保障中间件的高性能及高可用性,更全面地支撑业务及应用的稳定、持续运行,提升用户体验。
1.1.常见中间件监控模型及指标扩展
目前方案已实现对中间件包括Web中间件、数据库中间件、消息中间件、安全中间件、事务中间件、应用程序服务器中间件、分布式计算中间件等常见中间件的监控管理,涵盖的品牌包括Tomcat、Jboss、WebLogic、Nginx、Apache、RabbitMQ、Kafka、Redis、东方通、中创、宝蓝德、普元、金蝶天燕等国内外中间件。

同时采取用户自定义扩展中间件品牌、类型及其资源的方式,赋予用户强大的适配能力,其他中间件品牌也可通过灵活可配的模型库进行扩展适配,最大可能地实现对不同时期、不同品牌、不同型号中间件的管控;支持自定义中间件类型、中间件资源、故障监视器、性能监视器、TRAP监视器等。
1.2.常见中间件资源监测点和指标
本方案通过主动轮询和日志解析的方式对中间件的常见性能指标,如响应时间、吞吐量、JVM内存、执行线程、JDBC连接池、并发用户数等进行监控,同时除内置的常见指标外,其他资源和指标也可以通过模型库不断进行拓展。
|----------------|-------------------------------------------------------------------------------------------------------------------------------------------|
| 常见中间件监测点和指标 ||
| 资源 监测点 | 监测指标 |
| 基础信息 | 中间件品牌、名称、版本等 |
| Ping | 连接状态、响应时长、服务成功率等 |
| JVM信息 | 堆名称、JVM堆栈利用率、VM堆中内存、当前JVM堆中空闲内存数等 |
| 连接池 | 状态、名称、大小、总连接数、最大连接数、活动连接数、等待连接数、空闲连接数、已处理连接数、已接受连接数、平均每秒请求数、已关闭连接数、丢弃连接数、连接的最大客户数、池平均使用率等 |
| 线程池 | 线程池负载、线程池总大小、活动线程数、创建线程数、销毁线程数、ORB线程池利用率、Web线程池利用率、服务器线程池大小、死锁线程数等 |
| 会话信息 | 最大会话数、会话总数等 |
| 事务信息 | 并发活动全局事务数、已落实全局事务数、提交事务数、回滚事务数、超时事务数等 |
| 执行队列 | 队列名称、执行线程总数、当前空闲执行线程数、未处理请求最长时间(分钟)、队列中未处理的请求数、队列已经处理的请求数等 |
| Jms信息 | JMS连接总数、JMS当前连接总数、JMS最高连接数、JMS Server总数、当前JMS Server总数、JMS Server历史中最高总数、JMS Session总数、当前JMS Session数、最高JMS Session数、已接收JMS消息数、未处理JMS消息数等 |
第2章 中间件实时监控
通过建立全面的监控运维体系,北京智和信中间件监控运维方案实时监控中间件的各项关键性能指标,包括:CPU/内存使用率、实时流量/带宽、执行队列等。针对各类中间件特点深入监控其内部组件和整体运行状态,提升中间件可靠性,保障业务系统稳定运行。
2.1.自动发现中间件设备
智和信通具备独特的中间件自动发现技术,在网络可达范围内,仅需输入IP范围即可自动发现网络中的中间件及其他设备,识别中间件品牌、版本的信息,获取中间件内部资源,匹配故障与性能监视器,并自动发现中间件与其他设备的连接关系,生成可视化链路,通过可视拓扑动态展示中间件、链路的运行状态。
2.1.1.自动生成网络拓扑
方案以图形拓扑的形式展现中间件在网络中和其他设备间的拓扑关系,支持树形结构和平面结构的联动展示,也可以按片区、按地域、按层级等多种布局方式划分网络,在拓扑中以不同颜色图标、光效展现中间件的实时状态信息。

2.1.2.可视化展示中间件资源
在拓扑图的基础上,进一步展示中间件的内部细节,以图形方式展示中间件基础信息、CPU、内存、执行队列、线程池、JVM信息、连接池信息等关键指标,对中间件进行细化监控,实时告警,事前管理,降低故障发生率。

2.2.中间件性能态势感知
中间件的运行性能将直接影响业务系统的响应速度和稳定,同时定时监测中间件的相关性能情况,持续观测、多维管理,通过分析、展示中间件性能态势,实现对中间件设备的"可观、可管、可控"。
2.2.1.全面监控中间件性能
全面采集中间件的各项性能指标,如JVM堆栈利用率、JVM堆中内存、活动连接数、等待连接数、空闲连接数、执行线程总数、当前空闲执行线程数等,并可按照时间范围、资源类型、性能指标等多种维度,以图形、表格等多种形式进行展示。

2.2.2.实时、历史性能分析
对实时、历史性能数据进行统计分析,通过曲线图、柱状图或表格等形象化地展示,按天、星期、月查看性能指标变化。运维人员能随时把握中间件性能变化态势,防患于未然。
2.2.3.多中间件性能对比
支持选择多台中间件进行同维度性能数据分析,提供可视化性能对比视图,通过性能对比分析中间件性能变化趋势。

2.3.中间件自动巡检
可自定义中间件的巡检策略,预设时间自动执行中间件巡检,定期巡查中间件实时运行状态,并向指定邮箱发送结果报告,可自行选择要统计的中间件所属网络、中间件类型、中间件资源、中间件支撑的业务、中间件关联的链路等范围类型,生成巡检报表。

2.4.日志与事件管理
接收中间件主动发送如连接池泄露、连接失败、内存泄漏、线程死锁、创建连接失败、连接池已满、连接数据库超时、锁超时、服务器无响应等事件与日志消息,集中存储、解析处理后,将错误、告警、攻击行为等异常信息及时地通知用户。通过统一界面集中管理事件与日志,提高其完整性和可追溯性,帮助用户快速定位问题并采取相应的解决措施。
2.5.故障告警与智能收敛
搭载多种告警机制,自定义配置告警阈值,具备主动的故障监控功能,从众多的事件和状态中,系统地将零散的状态信息,总结成为当前状态,并对异常状态进行告警,第一时间获取准确的告警信息,快速标示已执行操作的告警,迅速定位产生告警的中间件,提升告警处理效率,极大降低因中间件故障带来的损失。
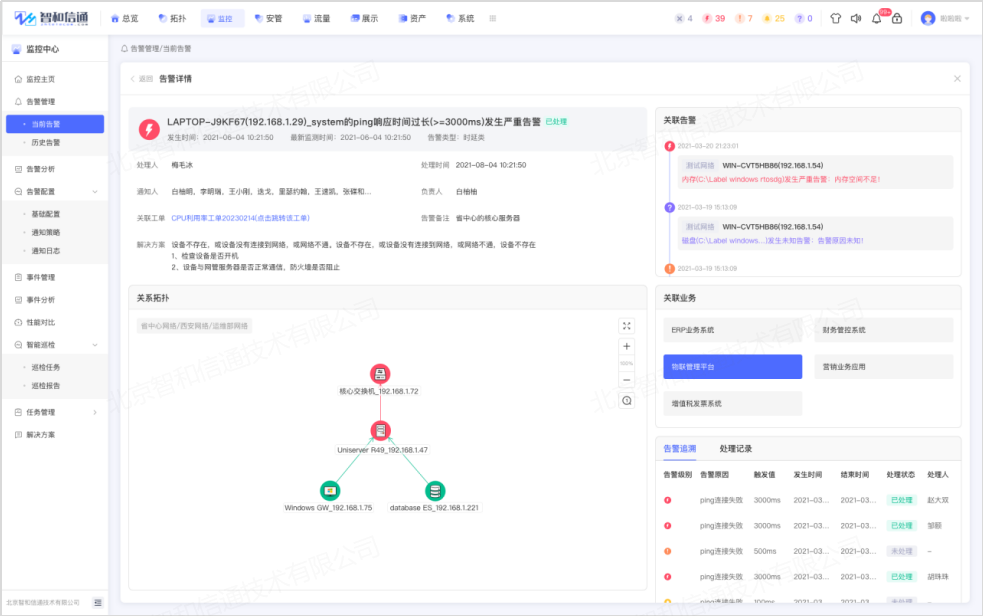
告警管理采用自动去重、风暴抑制、关联聚合、维护期时间屏蔽、依赖屏蔽等多种智能告降噪机制,通过AI算法,对各类告警进行自动压缩收敛,减少90%的无效告警,抑制告警风暴,有效避免误报和漏报,直达故障根因。
第3章 中间件承载的业务状态拨测
针对中间件所支撑的业务应用性能与用户体验进行检测分析,无需安装插件就可以为用户提供开箱即用的企业级主动拨测式业务监测。以拓扑形式展示每个业务流程中的每台相关设备,支持设备逻辑视图和面板视图,展示业务流程中涉及的所有的设备之间的链路关系,流程方向。
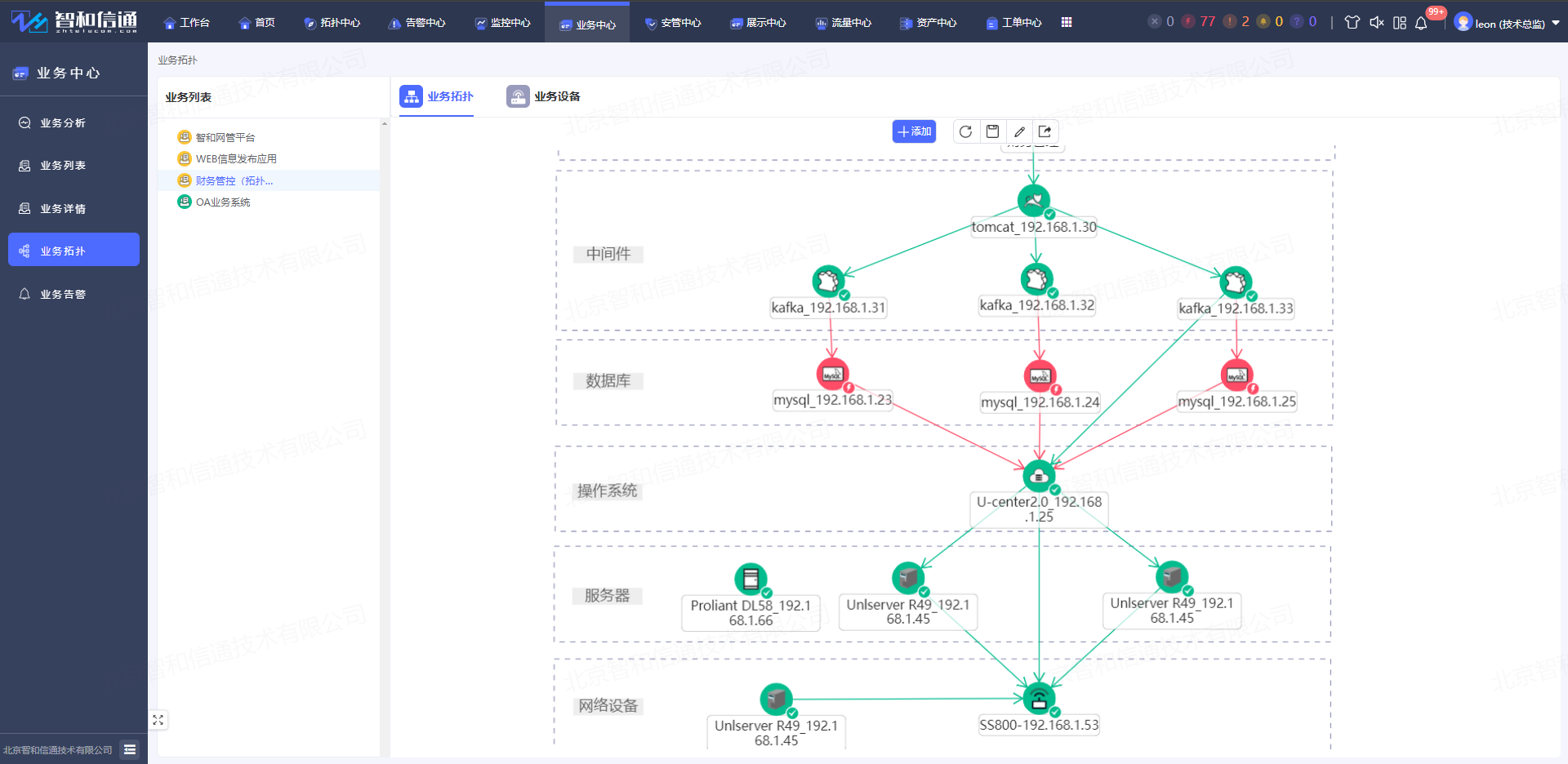
构建包含各业务整体流程的调用依赖关系图谱,展示业务部署中网络设备间多维度关系拓扑。对从业务的前台受理到真正完成的整个业务流程所依赖的业务应用、中间件、中间件、中间件、操作系统等进行实时监控分析,呈现业务各节点的实时运行状态,包括用户体验、节点可用性、节点负载等状态信息,快速定位业务瓶颈根因,并可根据用户自愈策略,触发自动运维实现故障自愈。
第4章 统计报表和大屏展示
通过定义中间件相关数据报表的能力,实现中间件性能和状态的灵活展现和统计分析,通过对比、TOPN等分析方式并结合报表排序规则、过滤规则等能力,周期自动生成报表,帮助用户更好地了解中间件的各项负载情况和运行态势,为优化资源配置和性能调整提供依据。

通过大屏展示核心运维数据态势,细粒度可达网络中中间件、中间件资源和链路。所有的网络故障与性能瓶颈都一目了然地呈现,大大降低了管理成本,同时也提高了运维人员处理故障的能力,节省的故障处理时间,为运维人员管理网络提供了可靠的保证。
第5章 中间件远程控制和编排式配置
方案提供中间件远程控制的能力,采用"监控+运维+控制"的方式,将不同类型、不同版本的中间件统一纳入控制管理。通过智能算法对中间件的资源配置进行智能动态调整,当中间件出现性能瓶颈时,自动调优资源配置,优化中间件运行环境,当中间件发生故障时,自动启动自愈机制,快速恢复中间件的正常运行。
5.1.中间件远程配置执行
将周期性、重复性、规律性的大量日常中间件配置工作,如启动/停止服务、定期备份中间件配置、修改JVM参数等运维工作,转化为依托于平台的自动执行工作流,实现对中间件的批量、定时自动化控制管理。
5.2.故障自愈以中间件离线重启为例
以中间件实时监控和日志、事件管理为基础,通过多指标聚合检测动态识别中间件异常,智能判断告警类型及级别,利用自动化故障诊断和修复能力,实现对中间件常规故障的自动处置,特殊告警触发升级与工单,最终实现故障恢复,减少人工干预,提高运维效率。
下面以中间件离线重启为例,介绍如何通过智和网管平台实现中间件故障自愈。
效果要求:当中间件掉线时,触发自动重启上线策略,恢复中间件运行。
第一步:将需要管理的中间件纳入平台进行监控,并设置中间件在线状态监视器,中间件离线进行告警。
第二步:进入安管模块的运维编排菜单,创建【中间件离线重启】策略。根据真实排障过程,通过进行策略节点拖拽编排的方式规划自愈流程。
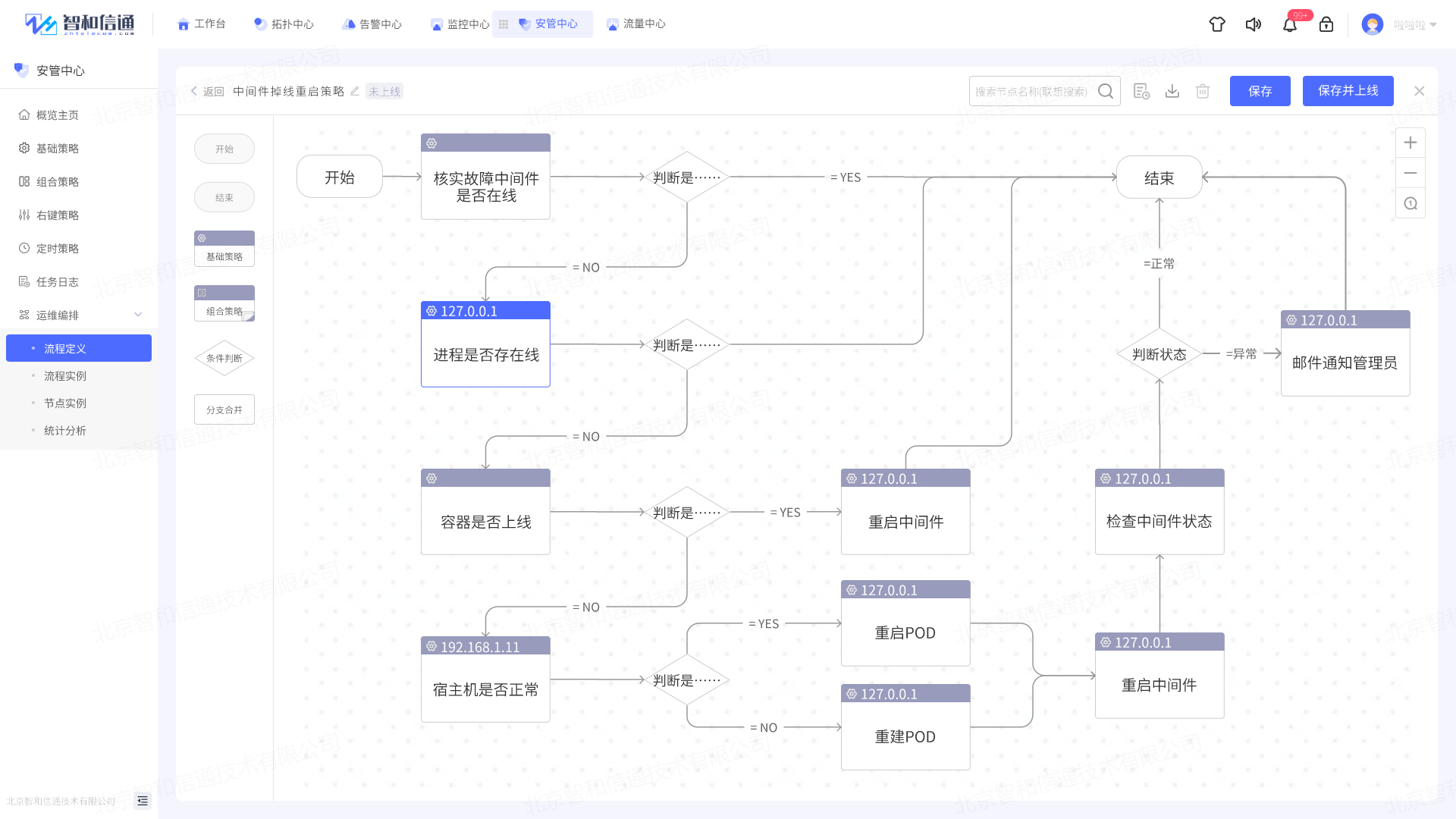
第三步:配置触发方式。方式支持通过告警触发和通过时间触发两种方式进行,为实现故障自愈的效果,我们选择通过匹配告警的方式触发策略。选定触发设备,并以在线状态为监控指标,当出现掉线告警时,自动触发自愈策略。

编排流程配置完成后,中间件出现掉线告警时,立即触发中间件自动重启作业流,自动执行编排内的操作,对故障进行校验和处置。并在执行过程中,对每一步处置操作进行记录形成日志,确保有迹可循。
5.3.配置备份、对比与恢复
支持中间件配置的批量备份、下载、周期性备份、查看等,对中间件的多个备份文件进行对比。定期自动对中间件配置进行巡检备份,并可进行对比分析,为用户管理网络做出合理的建议提供数据支撑,支持进行已备份配置间的对比分析和针对性的配置恢复。
第6章 应用价值
北京智和信通为用户提供高可用的中间件监控运维与故障自愈方案,通过监控中间件的运行状态和日志,迅速发现并诊断出现的异常问题,并提供详细的故障信息,协助运维人员快速定位故障源头。更值得一提的是,借助于自动化运维编排能力,可对常见中间件故障实现自愈。这意味着在很多情况下,系统可以自动修复问题,而无需人工干预,极大地提高了运维效率和系统的稳定性。
平台的告警和通知机制非常灵活,在中间件运行出现特定阈值或异常时,立即通知运维人员,通过智能降噪机制,更准确地识别与定位关键异常,从而在对关联业务影响最小的情况下进行故障处置。通过定时捕获和大数据分析等技术,识别潜在的性能瓶颈,并通过IT资源的调整和优化提升中间件的响应速度,也保障了整个业务系统的流畅运行。
对中间件进行实时监控和管理的同时,方案兼顾对网络设备、服务器、数据库、应用等整个IT基础设施的立体监测,不仅支持多源数据的统一收集与处理,还提供了直观的监控仪表板和定制化报告功能,让运维人员能够迅速把握IT系统全局运行态势,做出精准决策。