在接触AI应用开发的这段时间,我以为会像以前学.net,学java,学vue一样。先整个hello world,再一步一步学搭功能,学搭框架直到搭一个系统出来。然而,理想总是很丰满,现实很骨感。在实践的过程中各种千奇百怪的问题:
- **概念太多了。**你以为就GPT、LLM?太年轻了,huggingface、transformers、torch、tokenizers、langchain、modelscope、fastapi、CUDA、cuDNN、Conda、vLLM、ResNet-50、top_p等等等等....它们有些是工具,有些只是个库,有些甚至就是个参数名以及还有些我到现在都不知道是个啥。
- **运行代码时,经常莫名地各种报错。**以前学vue的时候,我以为前端的包已经够混乱了,直到开始接触AI,没有最混只有更混。
- **运行时间太长了而且结果不确定。**没有云上足够的算力和显卡,一个简单的代码运行少则10分钟,动则几小时,非常人能够忍受。就算当你历经千辛万苦程序跑完了,你会发现不太容易验证运行结果的正确性,你不知道改了某个参数值到底是起作用了,还是没起作用。
看了网上一堆AI开发的文章,得出两个字总结:写的都是垃圾!对,都是
在学的过程中,我就想着。等我做出个东西。我一定要把这些个牛鬼蛇神给掰扯清楚。废话不多说,故事就从hello world说起。
工具准备
- MiniConda 首先装这个,这个玩意有点像docker,可以隔离多个项目的python环境,并且默认带有vc++等库。为什么我把它放第一。作为程序员的洁癖,开始的时候我非常不想装这玩意的,直接装个python 3.12,手动pip install霹雳巴拉下各种包多潇洒,直到运行一个最简单的代码时缺各种依赖环境,不但缺python的包,竟然还缺各种dll,还缺vc++运行时,当时心里各种NMBD....然后老老实实把它装上了,一切都顺了。安装时默认会集成python。我装的版本:MiniConda3 py312_24.7.1
- PyCharm 开发python的第一选择。开始我用的vs code,调试运行各种手动命令敲烦了,还是pycharm按钮好使。
就先装这俩吧。
环境准备
电脑cmd命令提示符。设置清华的镜像,用于后面下载各种python的包。默认国外的镜像和.net nuget包、java maven库及前端npm包一个尿性卡的要死,只能用国内的。
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple新建项目
直接pycharm新建一个项目,名字随便起。毕竟我们是整大模型的,不是学python入门的。叫llmTest吧!如图1:

(图1)
这里注意:
- interpreter type:就是运行环境,选custom environment。基于conda新建的环境名(想象成docker的一个实例,这个环境只对我们这个项目有效)。界面上提供了project venv,这种方式也可以控制项目的运行环境,想了解地自行搜索,新手不能太多选择,我就喜欢用顺手的,哈哈哈!!
- path to conda:就是工具准备里面miniconda3的安装路径。
模型下载
目前国内外的通用大模型可以用密密麻麻来形容,gitee上面已经收录了1万多个了:https://ai.gitee.com/models 。模型下载方式很多,有直接用git lfs下载的、有直接下文件的,还有不直接下载运行时才加载的写代码方式。关键是这种方案还挺好使。本着新手不能太多选择,直接推最顺手的原则。我用的阿里魔塔modelscope(注意它不是模型,不是!它只是个下载工具 )。直接在pycharm命令终端里面执行pip install modelscope,如图2:

(图2)
注意图上红框的部分。这里没有用windows的命令终端执行,就是保证一直用的是我们刚刚创建的conda环境llmTest。防止安装包的时候,装到其他找不到的位置了。也可以看出下载的源用的是我们刚刚设置的清华镜像。
新建一个app.py。编写下载代码:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='D:\Transformers')这里我以清华智谱ChatGLM3 模型为例,下载到D:\Transformers。如果人品不是太差的话,运行效果如下:

(图3)
总共有15个G左右,需要等一段时间。至此一个大模型顺利下载完毕,它的结构如下图所示,别问我里面是啥,我也看不懂:

(图4)
模型使用
以上算是完成了全部的准备工作,作为一个有效率的打工人,马上迫不及待地想看效果了。立马码字:
from modelscope import AutoTokenizer, AutoModel, snapshot_download
model_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='D:\Transformers')
# model_dir ='D:\Transformers\ZhipuAI\chatglm3-6b';
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cpu() # 权重和计算从 32 位浮点数转换为16位
model = model.eval()
response, history = model.chat(tokenizer, '你好', history=[])
print(response)这段代码意图无比清晰,启动刚刚下载的chatglm3-6b模型,和它打个招呼,羞涩地问下:"你好"。先别急着运行,因为你运行肯定会报错(多么痛地领悟,该踩的坑我都踩完了😂)。先参考图2,在pycharm命令终端依次执行以下安装命令,保证安装模型运行所需要的包:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
pip install transformers==4.40.0
pip install sentencepiece全部安装完毕后,点击Debug尝试运行:

(图5)
ChatGLM会输出类似"你好!我是人工智能助手ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。"这样的回答。当然,就像文章开始说的结果不确定,你的结果和上面不一定相同。
视频我剪辑过,在我的电脑上,实际运行时间5分钟左右😂。至此最简单的模型应用开发完毕。
提供API支持
上面最简单的Hello world写完了,接下来就要为各种客户端提供接口服务了。.Net有WebAPI + IIS,java有spring boot+tomcat,大模型有FastAPI+Uvicorn:FastAPI用于构建应用的业务逻辑,Uvicorn是运行这些应用的服务器。参考图2,在pycharm命令终端依次执行以下安装命令:
pip install uvicorn
pip install fastapi把上面的代码微调一下:
import uvicorn
from fastapi import FastAPI,Body
from fastapi.responses import JSONResponse
from typing import Dict
app = FastAPI()
from modelscope import AutoTokenizer, AutoModel, snapshot_download
model_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='D:\Transformers')
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cpu() # 权重和计算从 32 位浮点数转换为16位
@app.post("/chat")
def chat(data: Dict):
query = data['query']
history = data['history']
if history== "":
history = []
response, history = model.chat(tokenizer, query, history=history, top_p=0.95, temperature=0.95)
response = {'response':response,'history':history}
return JSONResponse(content=response)
if __name__ == '__main__':
uvicorn.run(app, host="127.0.0.1", port=7866)点击Debug尝试运行,即可启动一个7866端口的API服务。

(图5)
我们用postman等客户端工具测试一下:

(图6)
编写客户端
服务端有了,当然要做个漂亮的客户端,总不能一直用postman。不得不吐槽下,大模型也搞前后端分离这套🤮!.net java 有httprequest,js有jquery、axios,大模型也有个出名的库langchain,官方的解释它提供了"链"的概念,允许开发者将多个语言模型调用、API请求、数据处理等操作链接起来,以创建更复杂的应用流程。这里你就当它是个用来封装http请求的客户端吧!还是按图2的方式先安装:
pip install langchain
pip install langchain-community在工程里面新建一个文件client.py。编写客户端代码:
import requests
import logging
from typing import Optional, List, Dict, Mapping, Any
import langchain
from langchain.llms.base import LLM
from langchain.cache import InMemoryCache
logging.basicConfig(level=logging.INFO)
langchain.llm_cache = InMemoryCache()
class ChatLLM(LLM):
url = "http://127.0.0.1:7866/chat"
history = [];
@property
def _llm_type(self) -> str:
return "chatglm"
def _construct_query(self, prompt: str) -> Dict:
query = {
"history": self.history,
"query": prompt
}
import json
query = json.dumps(query)
return query
@classmethod
def _post(self, url: str, query: Dict) -> Any:
response = requests.post(url, data=query).json()
return response
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
query = self._construct_query(prompt=prompt)
response = self._post(url=self.url, query=query)
response_chat = response['response']
self.history = response['history']
return response_chat
@property
def _identifying_params(self) -> Mapping[str, Any]:
_param_dict = {
"url": self.url
}
return _param_dict
if __name__ == "__main__":
llm = ChatLLM()
while True:
user_input = input("我: ")
response = llm(user_input)
print(f"ChatGLM: {response}")执行一下,和它说个'你好',再问下它是谁,效果如下(再次友情提示:视频剪辑过,肯定没有这么快😀!!!):

(图7)
等等,这好像还是算不上客户端!怎么着也得个应用程序APP之类,再不济也得有个Web吧!好吧,安排!为了搞大模型的人能安心研究模型,不用花精力在界面上。市场上就出现了2个常用的大模型web界面框架Gradio 和Streamlit,不用去研究哪个更好,顺手就行!类似ElementUI、AntDesign没必要非争个你死我活的!我这里以Gradio为例,先安装:
pip install gradio
#如果安装gradio后ImportError: DLL load failed while importing _multiarray_umath: 找不到指定的模块。执行下面:
pip install numpy==1.25.2在工程里面新建一个文件webclient.py。编写网页代码:
import gradio as gr
from client import ChatLLM #引用client.py里面我们定义的ChatLLM
llm = ChatLLM()
# 流式处理
def stream_translate(text):
response = llm(text)
for chunk in response.split():
yield chunk + " "
demo = gr.Interface(fn=stream_translate, inputs="text", outputs="text", title="ChatGLM",
description="A chatbot powered by ChatGLM.")
demo.launch()执行一下:

(图8)
在浏览器里面打开:http://127.0.0.1:7860就可以看到我们的客户端。这时随便问大模型几个问题吧(再次友情提示:视频剪辑过,后面那个问题1500多秒!):

(图9)
到这里,入门流程介绍完毕。看的人多的话,我会继续介绍模型微调和训练,希望大家喜欢!
最后
经过无数的蹂躏,我开发了个小应用【i歌词】,无任何条件免费提供全部源码。它基于chatglm4-9b大模型,从部署到训练,通用对话功能,核心根据歌名查歌词并创作歌词!用它来参加gitee AI创新应用大赛,可以在线体验,方便的话投个小票: https://ai.gitee.com/events/iluvatar-ai-app-contest/detail?app=36
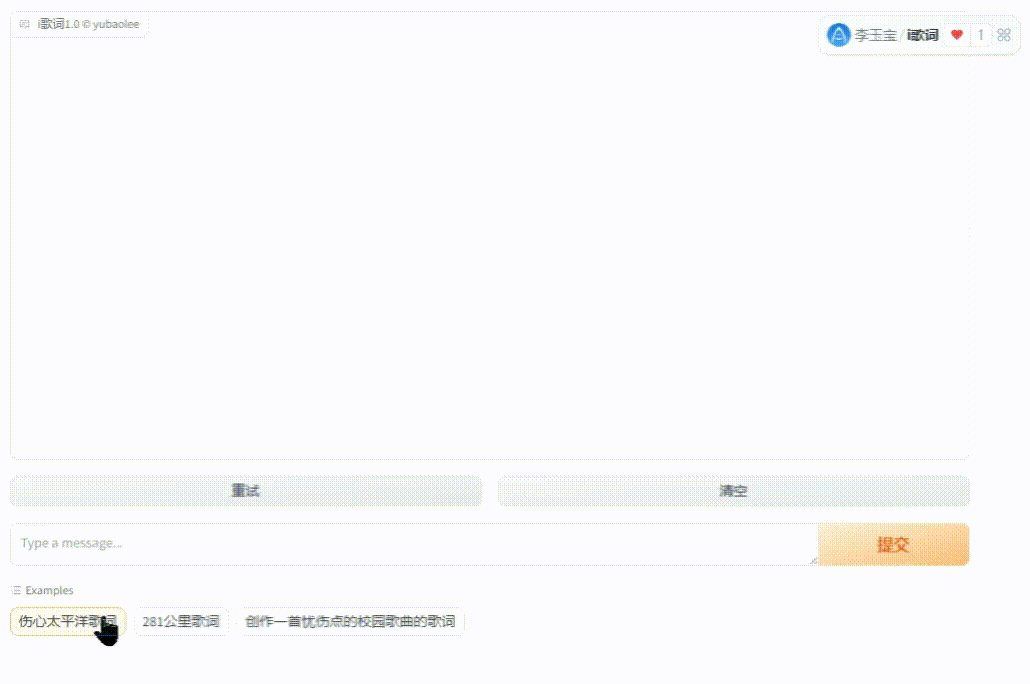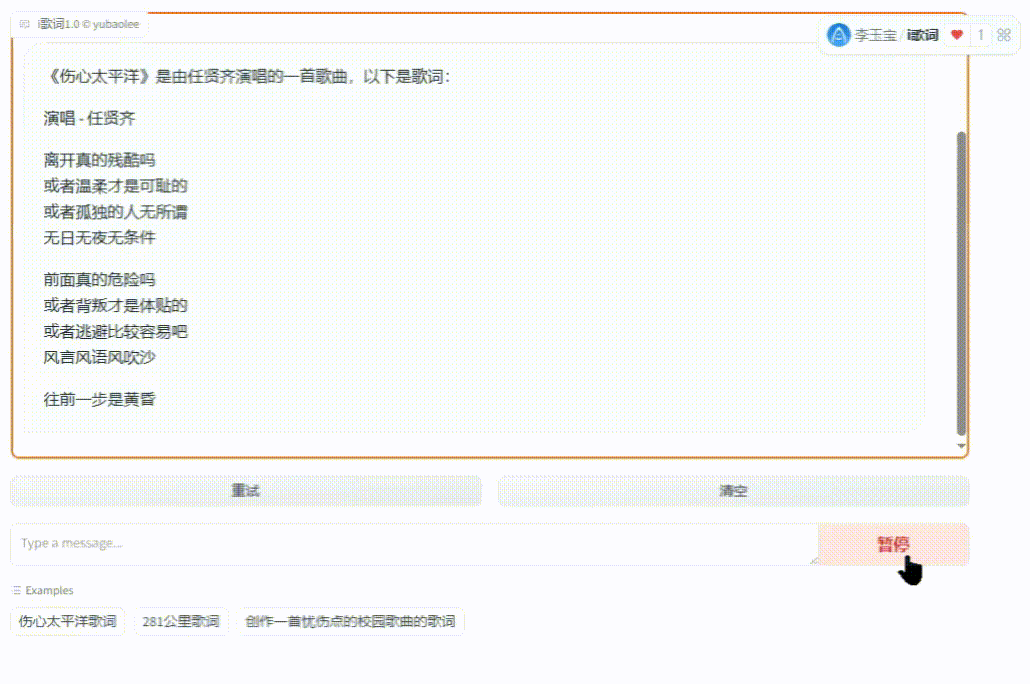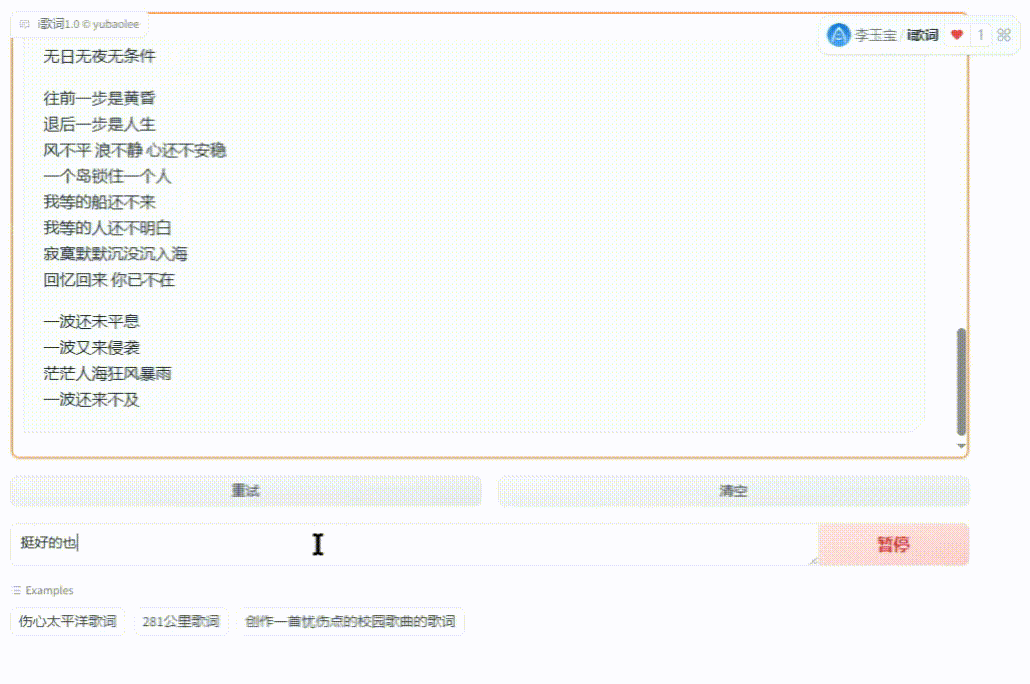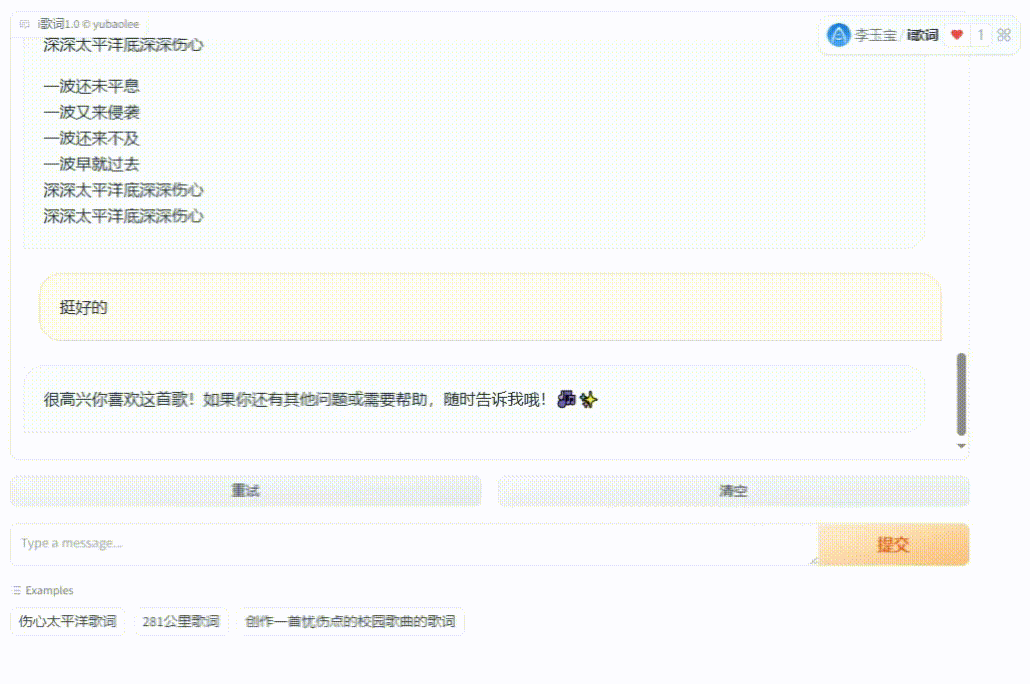
(图10)