环境变量和进程地址空间
- [1. 环境变量](#1. 环境变量)
-
- [1.1. 概念](#1.1. 概念)
- [1.2. 常见环境变量](#1.2. 常见环境变量)
- [1.3. 和环境变量相关的命令](#1.3. 和环境变量相关的命令)
- [2. 命令行参数](#2. 命令行参数)
-
- [2.1. int argc、char* argv\[\]](#2.1. int argc、char* argv[])
- [2.2. char* env\[\]](#2.2. char* env[])
- [3. 环境变量的特性](#3. 环境变量的特性)
- [4. 环境变量的获取](#4. 环境变量的获取)
-
- [4.1. 代码方式](#4.1. 代码方式)
- [4.2. 系统调用方式](#4.2. 系统调用方式)
- [5. 环境变量的配置文件](#5. 环境变量的配置文件)
- [6. 程序地址空间](#6. 程序地址空间)
- [7. 进程地址空间](#7. 进程地址空间)
-
- [7.1. 概念](#7.1. 概念)
- [7.2. 区域划分](#7.2. 区域划分)
- [8. 页表](#8. 页表)
-
- [8.1. 概念](#8.1. 概念)
- [8.2. new、malloc原理](#8.2. new、malloc原理)
- [8.3. 写时拷贝原理](#8.3. 写时拷贝原理)
- [9. 地址空间、页表存在的原因](#9. 地址空间、页表存在的原因)
1. 环境变量
1.1. 概念
环境变量:是由操作系统提供的一组全局变量,每个环境变量都有它特定的用途,它们对于多个程序都是可见,并且可在程序之间共享。
-
定义变量的本质是开辟内存空间,并通过变量名来标识这块空间,以便程序能够读取或修改其中的数据。
-
操作系统或者bash都是程序,程序在运行期间可以通过malloc、new等函数来动态开辟内存空间。
-
系统或者用户级别的环境变量,本质是在操作系统或者bash运行期间开辟内存空间,并给这块空间赋予了名称和内容。
-
环境变量不是一个单一的变量,而是由多个变量组成的集合,每个变量都有特定的名称和内容,彼此之间互不影响。
1.2. 常见环境变量
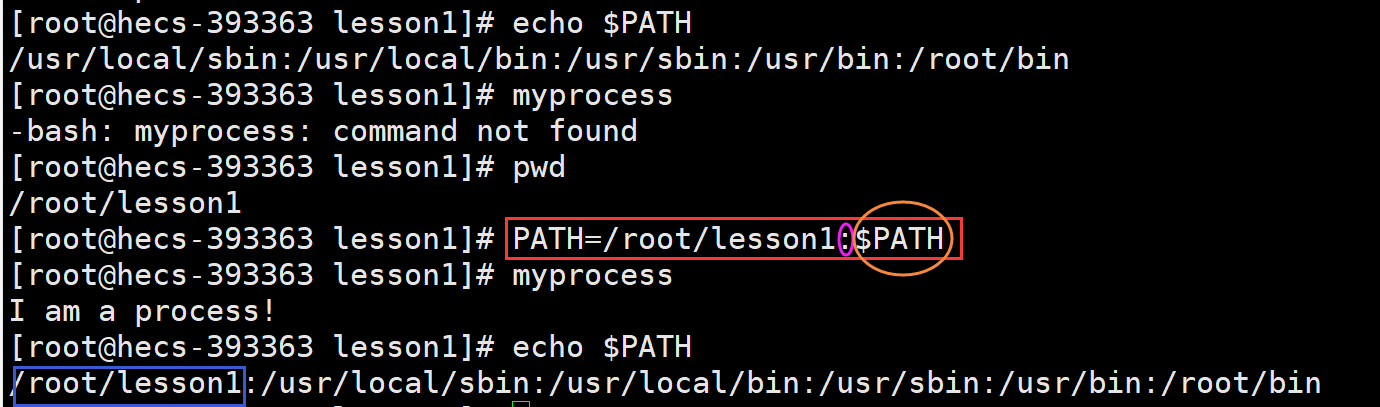
一、PATH
PATH:指定命令的搜索路径。
-
PATH用于指定一系列目录,其中的可执行文件可在命令行中直接运行,无需指定完整路径。
-
PATH结构:其内容是一个字符串,这个字符串是由多个路径组成,路径之间以冒号作为分隔符,其中每个路径都是系统默认的搜索路径。

- 因为执行一个程序的前提是找到它,所以在命令行中直接输入一个命令时,OS会按照以下步骤来查找该命令对应的可执行文件:检查命令是否为Shell的内部命令(cd、alias等),如果是,直接执行 ---> 检查PATH变量,根据PATH变量中指定的路径顺序逐个查找 ---> 如果找到,就立即执行;如果没找到,就会报错 (commad not found)。

PATH=路径:$PATH
- 功能:将新的路径添加到PATH中,同时保留原有的路径不被覆盖($PATH功能)。
 二、USER
二、USER
USER:表示当前登陆的用户名。

- whoami:显示当前登陆的用户名;一种实现方式是直接读取USER环境变量的内容来确定当前用户名。
三、PWD
PWD:表示当前工作目录的路径。

四、HOME
HOME:表示当前用户的主目录路径。即:用户登陆Linux系统中,默认所处的路径(家目录)。

1.3. 和环境变量相关的命令
echo $本地/环境变量
- 功能:显示某个本地/环境变量的内容。
export 环境变量名=内容。
- 功能:设置一个新的环境变量。
env
- 功能:显示所有的环境变量。
unset 本地/环境变量
- 功能:清楚某个本地/环境变量。
set
- 功能:显示本地变量和环境变量。
2. 命令行参数
-
命令行参数:在执行命令或者程序时,传递给它们的额外信息。这些参数可以用来控制程序的行为、指定输入文件、配置选项。
-
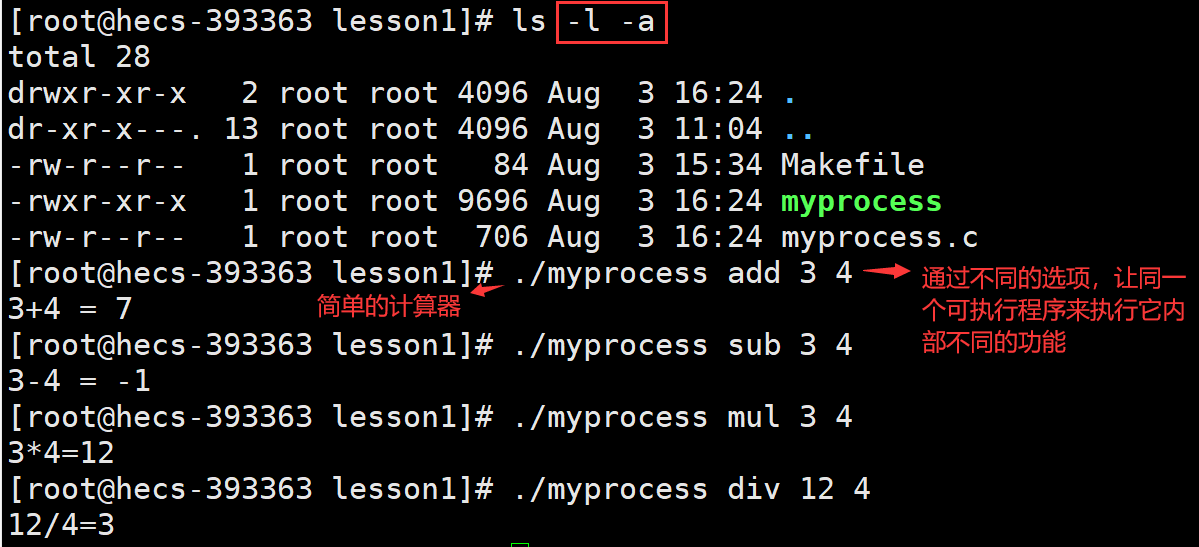
命令参数通常分为两种类型:一种为位置参数,它是按顺序传递给程序的参数,如:cat file1 file2,file1、file2为位置参数;另一种为选项参数,它用于控制程序的行为,如:ls -l -a,-l、-a为选项参数。
2.1. int argc、char* argv\[\]
int main(int argc,char* argv\[\])
-
int argc:整数类型的参数,表示命令行参数的数量(包括程序名本身)。
-
char* argv:字符指针数组,用于存储命令行参数。argv0是程序的名称。
-
通过命令行启动一个程序时,程序的本身名称被视为第一个命令行参数(argv0),是命令行参数的一部分;程序的选项和位置参数也是命令行参数的一部分(argv1. . .)。
问:为什么指令可以根据不同的选项执行不同的功能?
答:选项作为命令行参数传递给指令(程序)的main函数中的argc、argv参数,来完成让同一个指令根据不同的选项执行不同的功能。即:通过不同的选项,让同一个可执行程序来执行它内部不同的功能。
 💡Tips:命令行参数,是Linux指令选项的基础。
💡Tips:命令行参数,是Linux指令选项的基础。
2.2. char* env\[\]
-
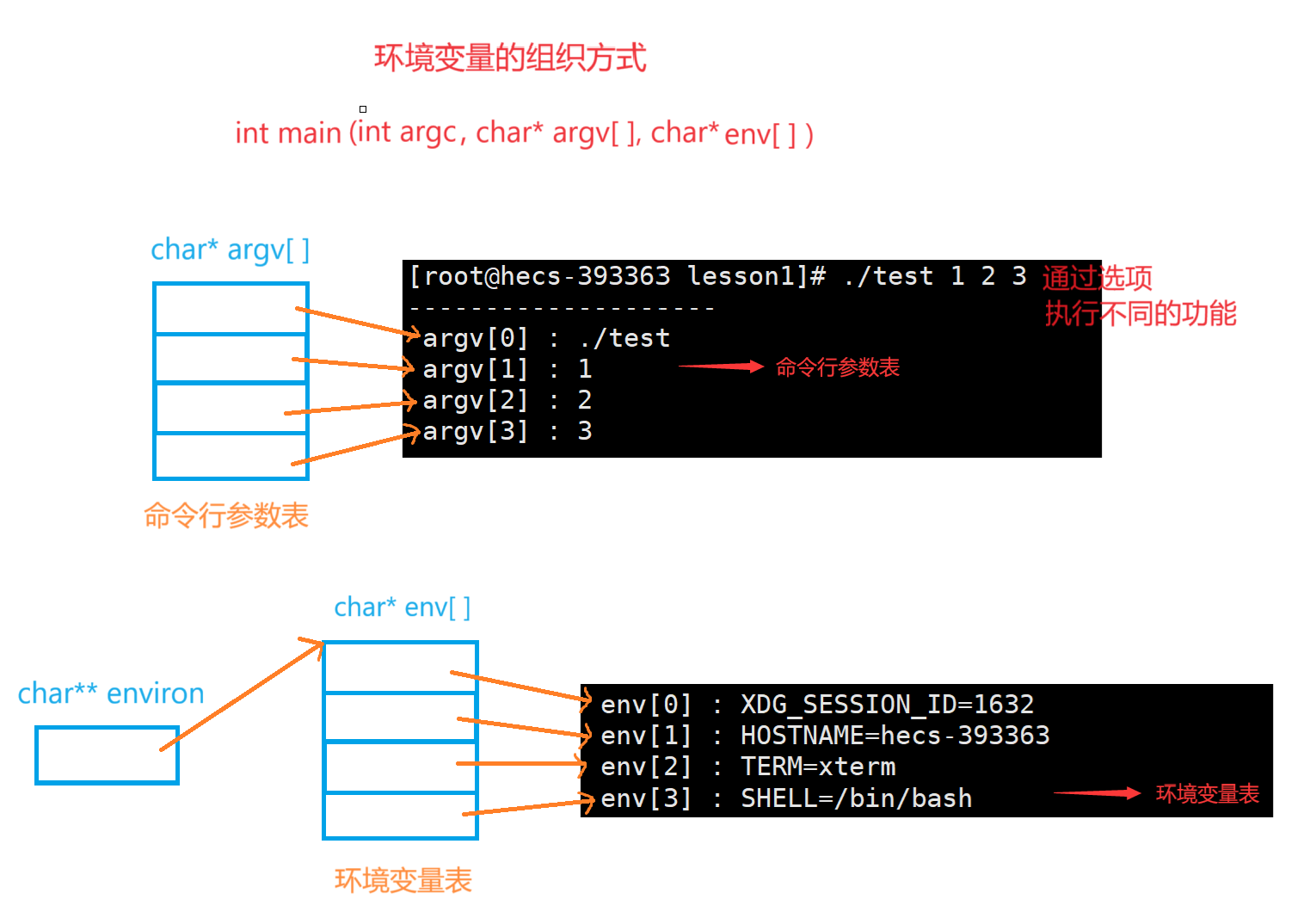
bash创建子进程时,会维护两张表,分别为命令行参数表和环境变量表,并将它们通过参数传递给子进程的main函数,以便子进程能够访问这些参数和环境变量。
-
命令行参数通过argc、argv传递给main函数,根据选项执行不同的功能; 环境变量通过environ指针数组传递给main函数,根据环境变量获取环境变量的属性,供我们后序操作。
c
#include<stdio.h>
int main(int argc, char* argv[], char* env[])
{
printf("--------------------\n");
for(int i = 0; argv[i]; i++)
printf(" argv[%d] : %s\n",i, argv[i]);
printf("--------------------\n");
printf("-------------------\n");
for(int i = 0; env[i]; i++)
printf(" env[%d] : %s\n",i, env[i]);
printf("-------------------\n");
return 0;
}
3. 环境变量的特性
-
环境变量会被所有子进程继承,即:环境变量具有全局属性。
-
子进程获取父进程环境变量的主要方式:进程地址空间的继承和参数传递。
进程地址空间的继承:当一个进程通过fork()创建子进程,因为子进程是以父进程作为模板,所以子进程会继承父进程的地址空间(包括了环境变量),意味着子进程的内存布局与父进程的内存布局相同。
参数传递:在创建子进程后,当当子进程通过exec*( )系列函数执行新的程序时,新程序的main函数会接受两个参数argv、env,argv是指向父进程中命令行参数的指针数组、envs是指向父进程中环境变量的指针数组。
- 本地变量不是环境变量,不能被子进程继承,只在定义它们的上下文中有效(即: 只在bash内部有效)。

env不能显示本地变量的内容,只能通过set、echo才能查看本地变量的内容。
为什么要有环境变量?
答:在不同的场景下执行某些任务和工作时,需要知道更多的其他属性的。在系统启动时,需要提前知道用户的相关信息,需要提前帮我们预制好这些信息,方便我们随时使用。
4. 环境变量的获取
4.1. 代码方式
一、通过命令行第三个参数(env)获取 --- 不常用
c
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{
int i = 0;
for(; env[i]; i++){
printf("%s\n", env[i]);
return 0;
}二、通过第三方变量environ获取 --- 不常用
- libc中的定义的变量char** environ,指向环境变量表,而environ变量没有被包含在任何头文件中,所以在使用时,要用extern进行外部声明(手动声明它为外部变量)。
c
#include<stdio.h>
int main()
{
extern char** environ;
for(int i = 0; environ[i]; i++)
printf("%s\n", environ[i]);
return 0;
}4.2. 系统调用方式
一、getenv --- 常用
char* getenv(const char* name) ;
- 功能:获取环境变量的内容。

c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main()
{
char* username = getenv("USER"); //getenv可以用作于用户身份认证
if(strcmp(username, "zzx") == 0 || strcmp(username, "love") == 0)
printf("This is my core function\n");
else
printf("你没有权限\n");
return 0;
}5. 环境变量的配置文件
环境变量的配置文件:.bash_profile。
-
环境变量通常在进程的上下文中存储的,它们存在于内存中,即:每个进程都有自己的环境变量集合。
-
环境变量是内存级别的数据、它们的生命周期与创建它们的进程(bash)生命周期相同、它们不会自动保存到磁盘中,仅存在于内存中,需要通过某些机制将它们写入磁盘文件中。
当在bash中对环境变量做修改,下次再重新登陆时,环境变量会被重新初始化,这是因为登入XShell会读取并执行.bash_profile文件中的命令,来设置环境变量。
问:为什么用户在登录时,默认所处的路径就是你自己的家目录?
因为登陆XShell在启动时,先需要读取环境变量的配置文件来设置环境变量。
每个用户在登陆时都有自己的一套环境变量,因为每个用户都有自己的环境变量的配置文件.bash_profile。

6. 程序地址空间
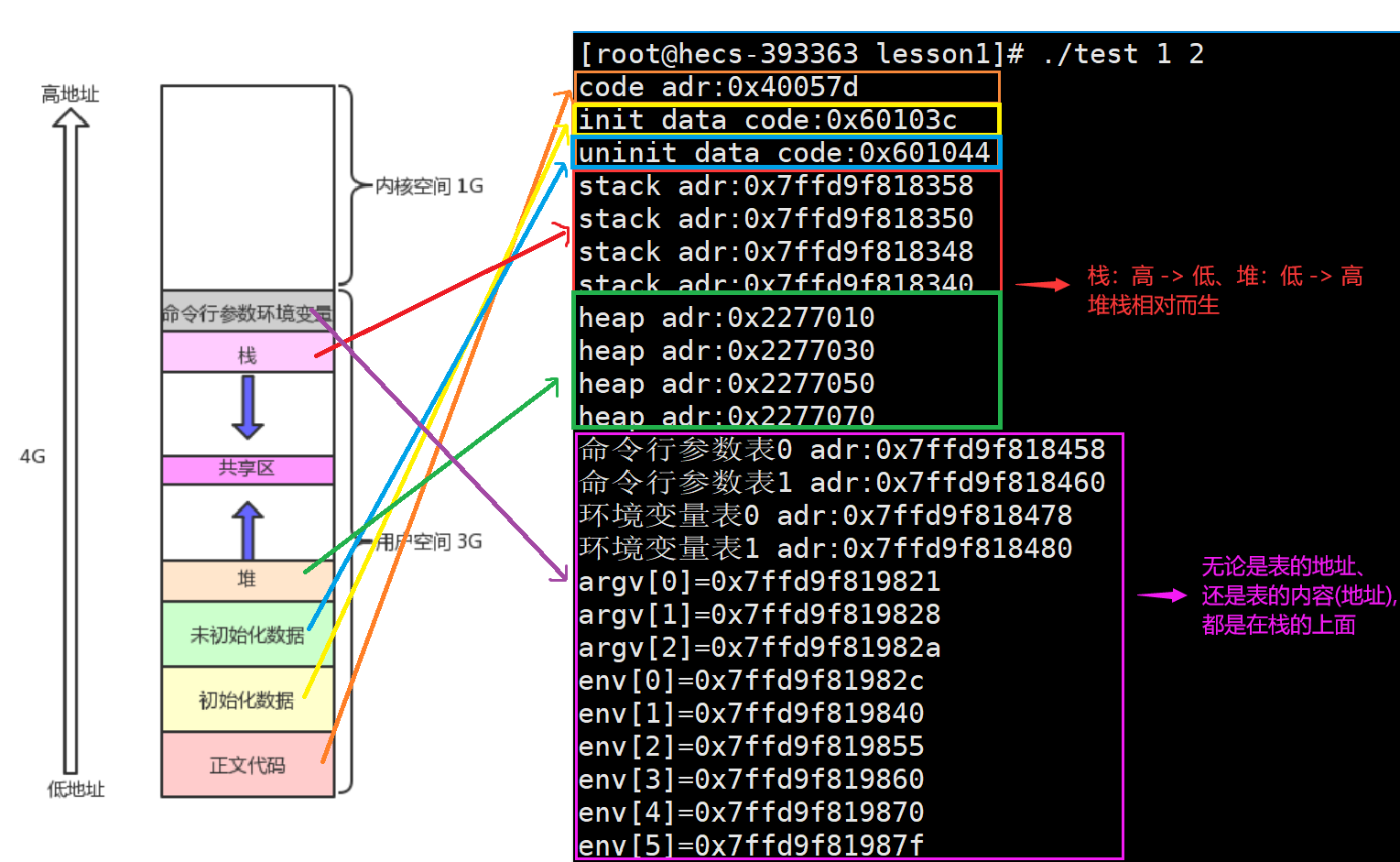
一、验证地址空间的内部布局
-
static关键字用于定义静态变量,只在声明它的源文件内部可见。它只会被初始化一次,如果未显示初始化,默认初始化为0,存储在静态存储区,在程序地址空间中属于初始化数据。
-
地址空间中的初始化、未初始化数据,以及静态变量具有全局属性,在程序的运行期间一直存在。
c
#include<stdio.h>
#include<stdlib.h>
int g_val1 = 100;
int g_val2;
int main(int argc, char* argv[], char* env[])
{
printf("code adr:%p\n", main); //正文代码
printf("init data code:%p\n", &g_val1); //初始化全局变量
printf("uninit data code:%p\n", &g_val2); //未初始化全局变量
char* heap1 = (char*)malloc(10);
char* heap2 = (char*)malloc(10);
char* heap3 = (char*)malloc(10);
char* heap4 = (char*)malloc(10);
printf("stack adr:%p\n", &heap1); //栈
printf("stack adr:%p\n", &heap2);
printf("stack adr:%p\n", &heap3);
printf("stack adr:%p\n", &heap4);
printf("heap adr:%p\n", heap1); //堆
printf("heap adr:%p\n", heap2);
printf("heap adr:%p\n", heap3);
printf("heap adr:%p\n", heap4);
for(int i = 0; i < 2; i++) //命令行参数表
printf("命令行参数表%d adr:%p\n", i, argv + i);
for(int i = 0; i < 2; i++) //环境变量表
printf("环境变量表%d adr:%p\n", i, env + i);
for(int i = 0; argv[i]; i++) //命令行参数
printf("argv[%d]=%p\n", i, argv[i]);
for(int i = 0; env[i]; i++) //环境变量
printf("env[%d]=%p\n", i, env[i]);
return 0;
}
二、利用fork函数观察子进程对某个共享数据修改时父子进程读取到的值和地址
- 我们用语言(c/c++等)所看的地址,全部都是虚拟地址/线性地址,不是物理地址(用户不可见) !
虚拟地址/线性地址:程序所看的地址,用于访问内存中的数据;由编译器和链接器为程序分配的地址;由程序直接使用,但不直接对应物理内存中的具体位置。
物理地址:是实际内存的地址,直接对应于内存中的物理位置,具有唯一性;对于程序通常是不可见的;由操作系统和MMU统一管理。
- 此图不是物理内存的分布图,而是进程地址地址空间的分布图。
内存分布图:涵盖了整个系统的内存使用情况,包括OS和其他进程。
进程地址空间图:侧重于单个程序的内存布局。
c
#include<stdio.h>
#include<unistd.h>
int g_val = 10
int main()
{
pid_t id = fork();
if(id == 0) //子进程
{
int cnt = 6;
while(cnt--)
{
printf("I am a child process! g_val = %d, &g_val = %p\n", g_val, &g_val);
sleep(1);
if(cnt == 3) //子进程修改共享数据
{
g_val = 200;
printf("child modify g_val: 100->200\n");
}
}
}
else //父进程
{
int cnt = 6;
while(cnt--)
{
printf("I am a father process! g_val = %d, &g_val = %p\n", g_val, &g_val);
sleep(1);
}
}
return 0;
}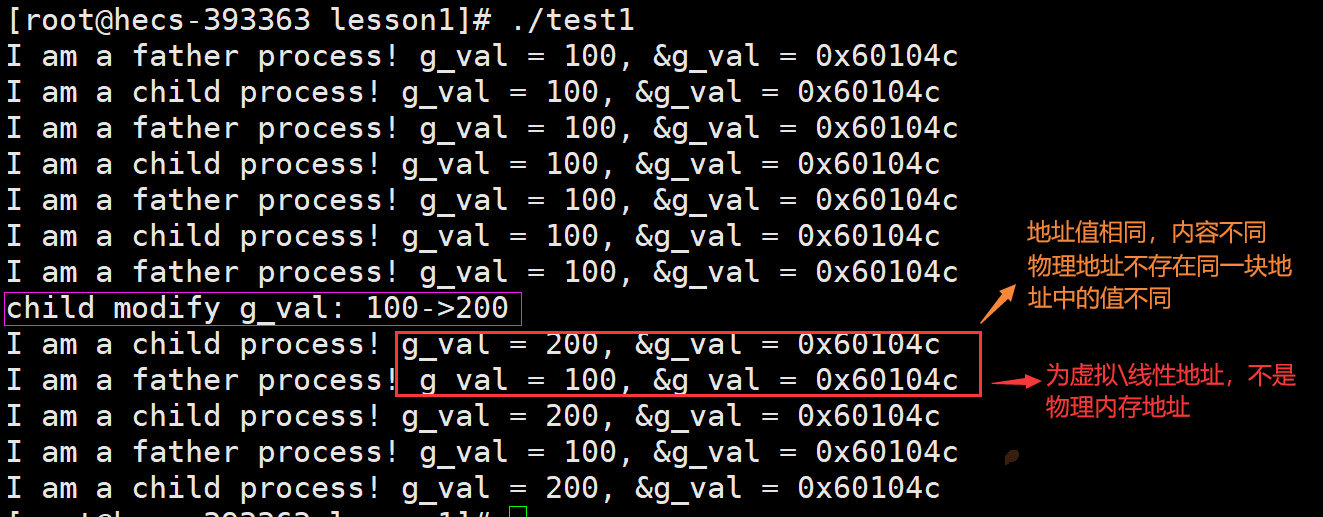 现象:子进程修改共享数据后,变量的内容不同,说明不是同一个变量,但地址值相同,说明不是位于同一物理地址上,因为物理地址是唯一的,每个物理地址对应内存中的一个特定位置。
现象:子进程修改共享数据后,变量的内容不同,说明不是同一个变量,但地址值相同,说明不是位于同一物理地址上,因为物理地址是唯一的,每个物理地址对应内存中的一个特定位置。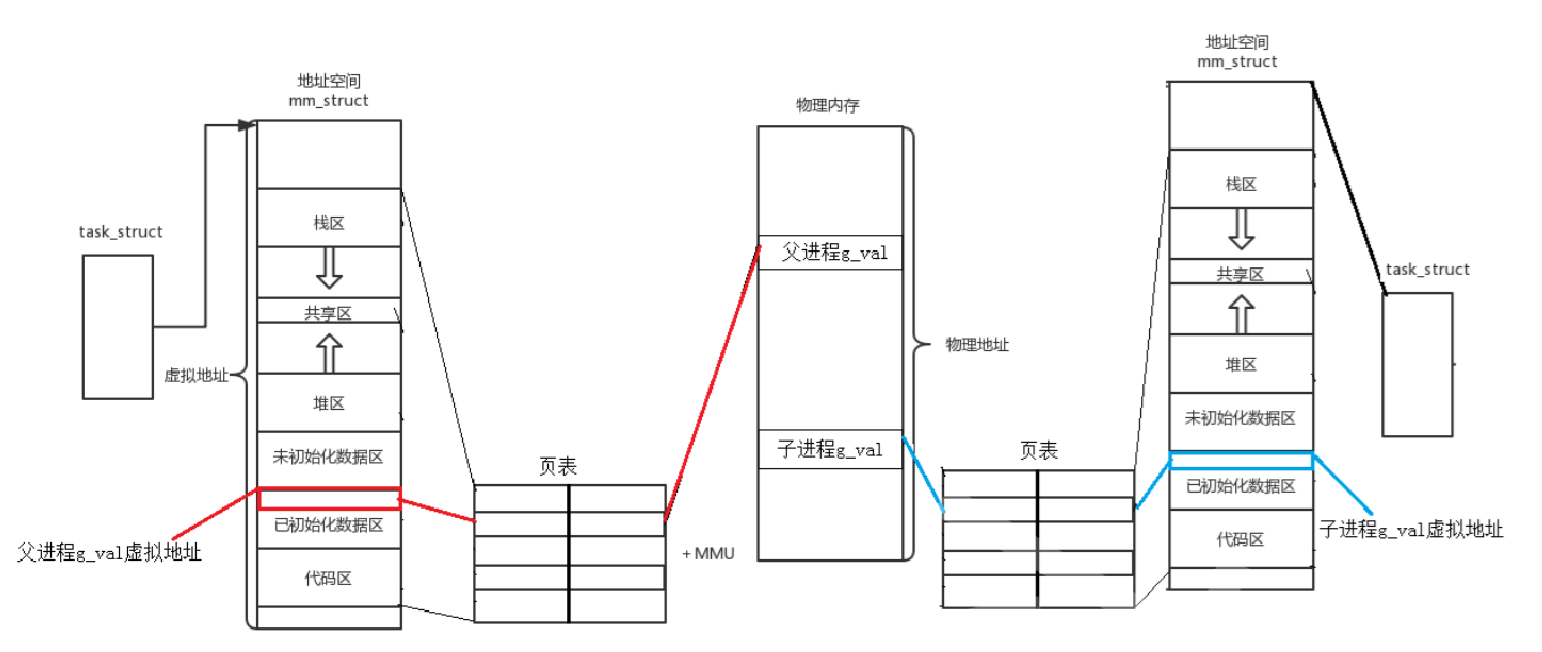 fork函数创建子进程,是以父进程为模板,子进程会继承父进程大部分数据结构(task_struct、进程地址空间、页表),所以父子进程代码和数据共享。当父子进程任意一方对共享数据进行写入,触发缺页中断,进行写时拷贝。
fork函数创建子进程,是以父进程为模板,子进程会继承父进程大部分数据结构(task_struct、进程地址空间、页表),所以父子进程代码和数据共享。当父子进程任意一方对共享数据进行写入,触发缺页中断,进行写时拷贝。
g_val地址值相同,内容不同,因为父子进程的虚拟地址相同,但在页表中虚拟地址到物理地址的映射关系不同,指向不同的物理内存。
7. 进程地址空间
7.1. 概念
-
进程地址空间:是指进程在运行过程中所使用的虚拟地址空间;每个进程都有独立的地址空间,它由操作系统分配;在32位平台下,地址空间大小为0, 4GB;
-
进程地址空间其实就是数据结构,具体到进程中,就是特定的数据结构对象。
eg:有一个大富翁,有10亿资产,两个孩纸,分别为小A、小B,两人都不知对方的存在。有一天大富翁对两孩分别画饼,对小A说 :"儿子,你好好经营你的公司,等我走后,我的10亿资产全部是你的",对小B说 :"闺女,你好好读书,等我走后,我的10亿资产全部都是你的",小A/B都认为将来自己有10亿 --- 大富翁是OS、10亿资产为物理内存、小A/B为独立的进程、饼为每个进程的进程地址空间。
- 操作系统如何管理每个进程的进程地址空间?先描述、再组织,对进程地址空间的管理,就转化为了对特定数据结构的增删查改。
💡Tips:每个进程都有自己的PCB、进程地址空间以及页表,都是在操作系统内部。
7.2. 区域划分
-
地址空间划分的概念:进程地址空间是特定的数据结构,主要包含的字段是对地址空间进行区域划分,在特定位数的计算机中它能寻址的地址范围中划分为若干个区域,方便了操作系统的寻址操作。
-
区域划分的目的:判断是否越界、扩大或缩小范围、内存保护、支持动态内存管理等。
判断是否越界:通过各个区域的边界,OS可以检测并阻止进程尝试访问超出分配区域之外的内存。
扩大或缩小范围:根据需求,动态调整各个区域的大小,如:堆空间动态申请和释放。
内存保护:通过页表和其他内存管理机制来控制对进程的访问权限(r、w、x) , 防止进程未经授权访问内存区域,增加了系统的安全性和稳定性。
支持动态内存管理:通过划分堆、栈等区域,支持程序在运行时动态申请和释放内存资源。
- 区域划分的本质:区域内的所有地址,都可以被使用(访问权限例外)。
c
struct task_struct {
/*
offsets of these are hardcoded elsewhere - touch with care
*/
volatile long state; /* -1 unrunnable, e runnable, >0 stopped */
unsigned long flags; /* per process flags, defined below */
int sigpending;
mm_segment_t addr_limit; /* thread address space:
O-OxBFFFFFFF for user-thead
O-OxFFFFFFFF for kernel-thread
*/
struct exec_domain *exec_domain;
volatile long need_resched;
unsigned long ptrace;
int lock_depth; /* Lock depth */
/* offset 32 begins here on 32-bit platforms. We keep
* all fields in a single cacheline that are needed for
* the goodness() loop in schedule().
*/
long counter;
long nice;
unsianed long nolicv;
struct mm_struct *mm; //mm指针指向的是进程地址空间
int processor;
...
}
c
struct mm_struct
{
struct vm_area_struct* mmap;
struct rb_root mm_rb;
struct vm_area_struct* mmap_cache;
//....
unsingned long start_code, end_code, start_data, end_data;
//代码段的范围[start_code, end_code],数据段的范围[start_data, end_data];
unsigned long start_brk, brk, start_stack;
//start_brk表示堆的最低地址边界,brk表示堆的最高地址边界; 堆:低->高
//start_stack表示栈底的地址,即:栈的最高地址边界; 栈:高->低
unsigned long arg_start, arg_end, env_start, env_end;
//命令行参数的范围[arg_start, arg_end],环境变量的范围[env_start, env_end];
}8. 页表
8.1. 概念
-
页表:是用于支持虚拟内存管理的数据结构;主要用于存储虚拟地址到物理地址的映射关系;使得程序能够透明地使用虚拟地址空间,而无需管理物理内存(不必关心物理内存的具体布局)。
-
页表将虚拟地址转化为物理地址的过程,是由CPU内部的一个硬件组件MMU(内存管理单元)来完成的。MMU能够自动完成页表的映射、查找等工作,从而实现虚拟地址到物理地址的转化,进而找到数据并将其加载到CPU中进行处理。
CR3寄存器中保存了指向当前活动页表的物理地址,当MMU需要进行地址转化时,它会使用CR3中的值来定位正确的页表结构。
- 进程地址空间不具备对代码和数据的保存能力,而是通过页表机制和MMU的支持,将虚拟地址空间映射到物理内存,从而实现了代码和数据的保存和访问。
8.2. new、malloc原理
问:new、malloc申请内存,会立即使用吗?本质是在哪里申请?这样做有什么好处吗?
-
当new、malloc申请内存时,不会立即使用此块内存,因为操作系统一定要对效率、资源使用率负责,所以OS不会直接分配实际的物理内存,而是在进程地址空间中申请,页表中未建立对应的映射关系。
-
这样做的好处:a. 充分保证了内存的使用率,不会空转;b. 提升了new、malloc的速度。
充分保证了内存的使用率:进程实际使用的内存数量往往少于分配的数量,通过延迟分配的策略,OS可以避免分配未使用的物理内存,显著减少了物理内存的浪费。
提升了new、malloc的速度:由于OS不需要立即查找和分配内存,new、malloc的调用可以更快完成。
- 用户尝试对new、malloc申请的内存进行写入,OS会经历以下步骤:虚拟内存分配 -> 尝试写入 -> 物理内存的分配 -> 页表映射 -> 写入操作。
当用户尝试向虚拟地址进行写入,OS就会发现当前是往合理的空间内进行写入,且页表中当前并未建立虚拟地址到物理地址的映射关系,就会触发 "缺页中断",将写入操作暂停,开辟物理内存,再建立对应的映射关系,一旦页表映射建立完成,用户就可以进行写入操作。eg:支票。
8.3. 写时拷贝原理
- 写实拷贝工作过程:初始状态 -> 写入尝试 -> 缺页中断 -> 内存分配和映射更新 -> 权限更新。
初始状态:父子进程共享同一段内存空间的数据,这些共享数据页在页表中权限位最初被标记为可读(r,只读),以确保数据的一致性。
写入尝试:当父子进程任意一方尝试修改这些共享数据时,它会执行写操作。处理器会检查页表中的权限位,发现该页面是只读的。
缺页中断:操作系统检测写操作,并尝试修改只读页面时,会触发一个缺页中断。
内存分配与映射更新包括以下内容:
- 内存分配:操作系统为请求写入的进程分配新的物理内存。
- 内容复制:操作系统将原始共享页面的内容拷贝到新分配的物理内存中。
- 映射更新:操作系统更新请求写入的进程的页表的映射关系,使其指向新的物理内存。
权限更新包括以下内容:
- 原页面权限:可读,保持不变。这确保了其他进程不能通过这条路径改变数据,从而维护了数据的一致性。
- 新页面限:标记为可读写(rw),供请求写入的进程自由使用。
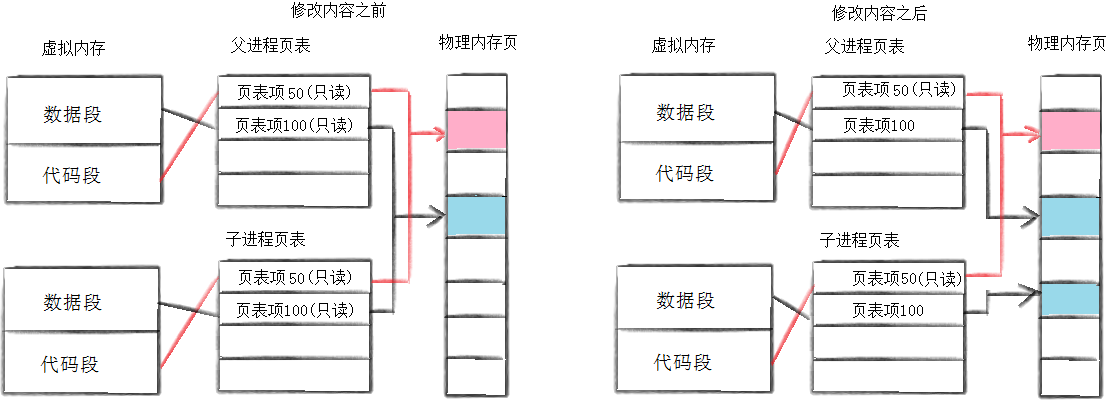
页面在页表中的权限位最初被标记为可读,也就是只读的,当其中一个进程试图写入该页面时,操作系统才会触发缺页中断,然后为写入的进程创建一个页面副本,并将新的页面权限设置为可读写。
- 按需拷贝:只有在实际写入时才会进行拷贝,而不是一开始就开辟空间,复制所有的数据,从而节省内存资源。
一、为什么字面值常量具有常属性,其值不能被修改?
答:str中保存的是字符串常量的起始地址,该地址为虚拟地址,尝试对虚拟地址进行写入(赋值)时,需要进行虚拟地址到物理地址的转化,而字面值常量存放在常量区,此区域的条目权限位为只读位。
即:根本原因在与操作系统的内存保护机制,它通过页表中的权限位来控制对内存的访问,阻止了对只读区域的写入操作。
-
内存保护机制:操作系统使用内存保护机制来限制对内存区域的访问,这些机制通常通过页表中的权限位来实施的。
-
页表权限位:页表中每一条目都会有一个或者多个权限位,用来指示此条目的内容是否可读(r位)、可写(w位)、可执行(x位)。常量区的页表条目通常只设置为只读,不允许写入。
-
写保护:尝试修改一个只读的内存区域时,操作系统会检测到这种尝试,并阻止它。这通常会导致一个保护故障,如:段错误(segmentation fault)。
-
虚拟地址到物理地址的转化:当进程尝试访问虚拟地址时,处理器会查询页表来查询对应的物理地址,如果页表中的权限位禁止写入,则处理器不会允许对该地址进行写操作。
c
#include<stdio.h>
int main()
{
char* str = "hello world!"; //编译通过,运行时报错
*str = 'H';
return 0;
}
二、为什么最好加上const关键字来修饰字面值常量?
-
提前暴露错误:将运行时才会发生的错误,提前到编译阶段暴露出来,有助于提高程序的质量和稳定性。
-
提高代码质量:通过使用const关键字,明确表明了该变量不能被修改,提高了代码的可读性和可维护性,是一种良好的编程习惯。
-
防御性编程的范畴:这是一种防御性编程的做法,有助于减少错误和异常的发生。
- 防御性编程:旨在通过预防性措施来减少错误和异常的发生。通过在编译时捕获错误,而不是等待在运行时出现问题,可以有效提高程序的健壮性和可靠性。
c
#include<stdio.h>
int main()
{
const char* str = "hello world!"; //编译不通过
*str = 'H';
return 0;
}
9. 地址空间、页表存在的原因
- 将物理内存从无序变为有序,让进程以统一的视角,看待内存。
统一的视角:每个进程都有进程地址空间,这个空间是个连续的线性地址空间。意味着每个进程看到的内存布局时一样的,无论内存是如何分布,进程统一认为自己拥有一个完整的、连续的线性地址空间。
无序变为有序:通过进程地址空间和页表机制,即使物理内存是分散的,可以通过页表将它们映射成连续的虚拟地址空间。
- 将进程管理和内存管理进行解耦合。
解耦合:页表的存在使得操作系统将进程管理和内存管理进行分离。进程管理模块主要负责创建、调度和终止进程,内存管理模块主要负责物理内存的申请和释放。通过页表,进程可以被加载到磁盘的任意位置,而不需要关心具体的内存布局。
- 进程管理包含进程的task_struct、地址空间、页表;内存管理包含物理内存。
- 是保护内存安全的重要手段。
内存保护:页表提供了内存保护机制,可以设置权限来控制不同内存区域的访问权限,如:有些区域只能特定的进程访问、有些区域只能读不能写等。
保护内存安全,对异常地址的访问时,它们就会拦住非法的请求操作。eg:访问野指针,程序崩溃,但并不影响OS正常的运行,也不影响其他进程正常运行,因为拦住你的是你自己的地址空间和页表,只会影响你自己。