摘要:
1,LFU的介绍
2,LFU元素的添加
3,LFU元素的读取
4,LFU完整代码实现
1,LFU的介绍
LFU(Least Frequently Used)最不经常使用算法,它和我们前面讲的《LRU缓存》类似,也是一种缓存淘汰策略。
在讲LRU缓存的时候,当缓存满了需要删除的时候,根据元素使用的时间来删除,越久没有被使用越容易被删除。
但这样会存在一个问题,比如一个元素使用的频率非常高,由于最近一段时间一直没有被使用,所以它很容易被删除,这个时候我们就可以考虑根据元素的使用频率来删除。当缓存满的时候,使用频率越低的越容易被删除,这个就是今天要讲的LFU缓存。
这里我们还是使用双向链表来实现LFU缓存,越靠近链表头部,元素使用的频率越低,越靠近链表尾部,元素使用的频率越高,也就是说链表从头到尾,元素的使用频率是递增的。当缓存满了,需要删除的时候,优先删除靠近头部的节点。
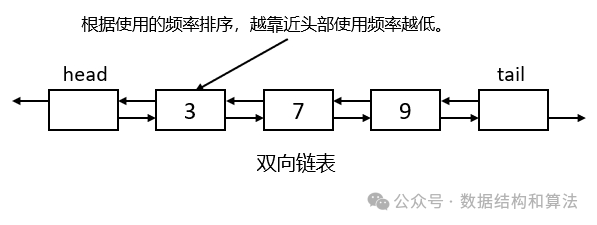
先来看下链表的节点类,在学习LFU缓存之前最好先看下之前讲的《双向链表》和《LRU缓存 》。
Java 代码:
go
// 双向链表的节点
class LinkedNode {
int key, val;// 节点的key和val值
int freq = 1;// 当前节点的操作的频率
LinkedNode pre;// 指向前一个节点的指针
LinkedNode next;// 指向后一个节点的指针
}C++ 代码:
go
// 双向链表的节点类
struct LinkedNode {
int key{}, val{};// 节点的key和val值
int freq = 1;// 当前节点的操作的频率
LinkedNode *pre = nullptr;// 指向前一个节点的指针
LinkedNode *next = nullptr;// 指向后一个节点的指针
};2,LFU元素的添加
LFU中的元素是根据键值对存储在map中的,在添加新元素的时候,会按照它的频率插入到链表中。
如果有相同频率的元素存在,要按照使用时间顺序插入,具体插入方式就是使用时间越久的越靠头部,使用时间越近的越靠尾部。这样就能保证在删除具有相同频率的元素的时候,优先删除越久没被使用的。
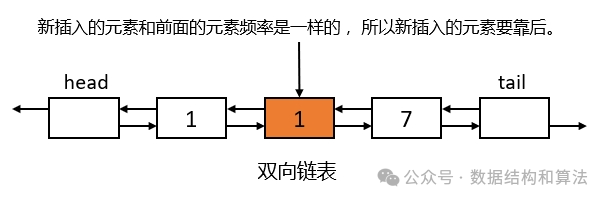
因为插入的时候可能会涉及到元素数量的增加,所以如果在缓存满的时候还需要删除。
LFU元素添加的具体步骤如下:
1,如果key值存在,直接把value值替换掉,频率增加 1 ,然后根据它的频率重新插入到新的位置。