最近多模态生成领域也在"神仙打架",比如Meta的全新训练方法Transfusion,用单个模型就能同时生成文本和图像!
还有之前华为、清华提出的个性化多模态内容生成技术PMG,生成的内容可"量身定制",更能满足偏好。
这些效果炸裂的新成果证明了多模态生成一直是研究热门,更实际点的证明还有:
-
从学术角度来看,今年CVPR等顶会的收录论文中,多模态生成是最热门的研究主题之一。
-
从就业角度来看,多模态生成的人才需求也比较大,很多公司都有相应的岗位,比较好拿offer。
因此多模态生成依旧是我们非常好的选择,想抓紧投中顶会给自己加码的同学可以考虑。这里为了帮助各位快速了解这个方向目前的最新动态,我整理好了10篇多模态生成今年最新的论文给各位作参考,代码基本都有。
论文原文+开源代码需要的同学看文末
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
**方法:**论文一个多模态模型训练的配方Transfusion,可以处理离散数据(如文本或代码)和连续数据(例如图像、音频和视频数据)。Transfusion结合了语言建模损失函数(下一个词预测)和扩散模型,通过单一的transformer来训练混合模态序列,使其能够无缝地生成离散和连续的模态,例如同时生成文本和图像。
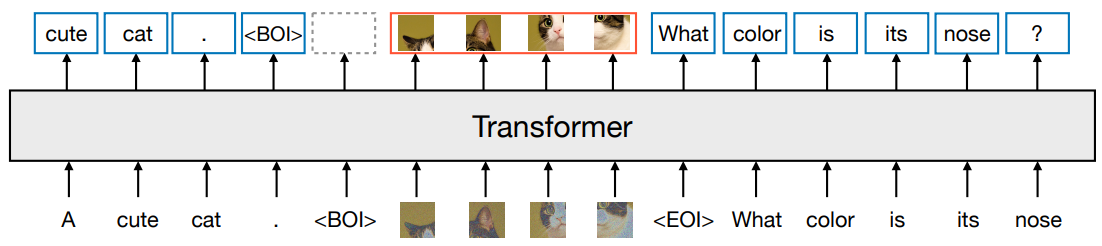
创新点:
-
Transfusion是一个统一的多模态模型,可以同时生成文本和图像,不需要信息的丢失。
-
在文本到图像生成和图像到文本生成任务中,Transfusion模型在FID和CLIP得分方面表现优于Chameleon模型,且在相同的计算复杂度下,Transfusion模型的FID得分约为Chameleon模型的一半。
-
Transfusion模型在学习文本到文本预测任务上的效率也更高,达到了Chameleon模型计算复杂度的50%到60%的困惑度。
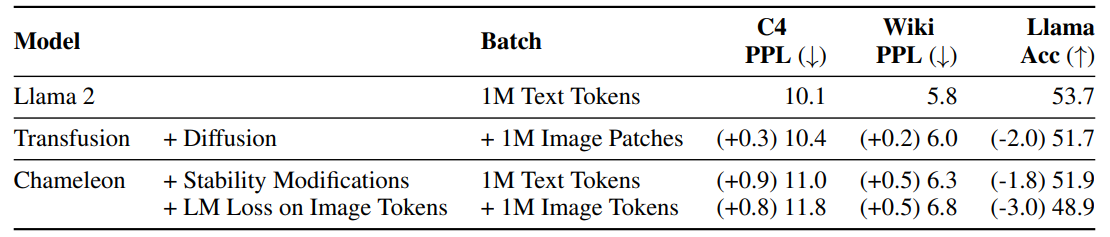
PMG: Personalized Multimodal Generation with Large Language Models
**方法:**论文提出了一种基于大语言模型(LLMs)的个性化多模态生成方法(PMG),首先将用户行为转化为自然语言,以便LLM能够理解并提取用户的偏好。然后,将用户偏好输入生成器(如多模态LLM或扩散模型)以生成个性化内容。
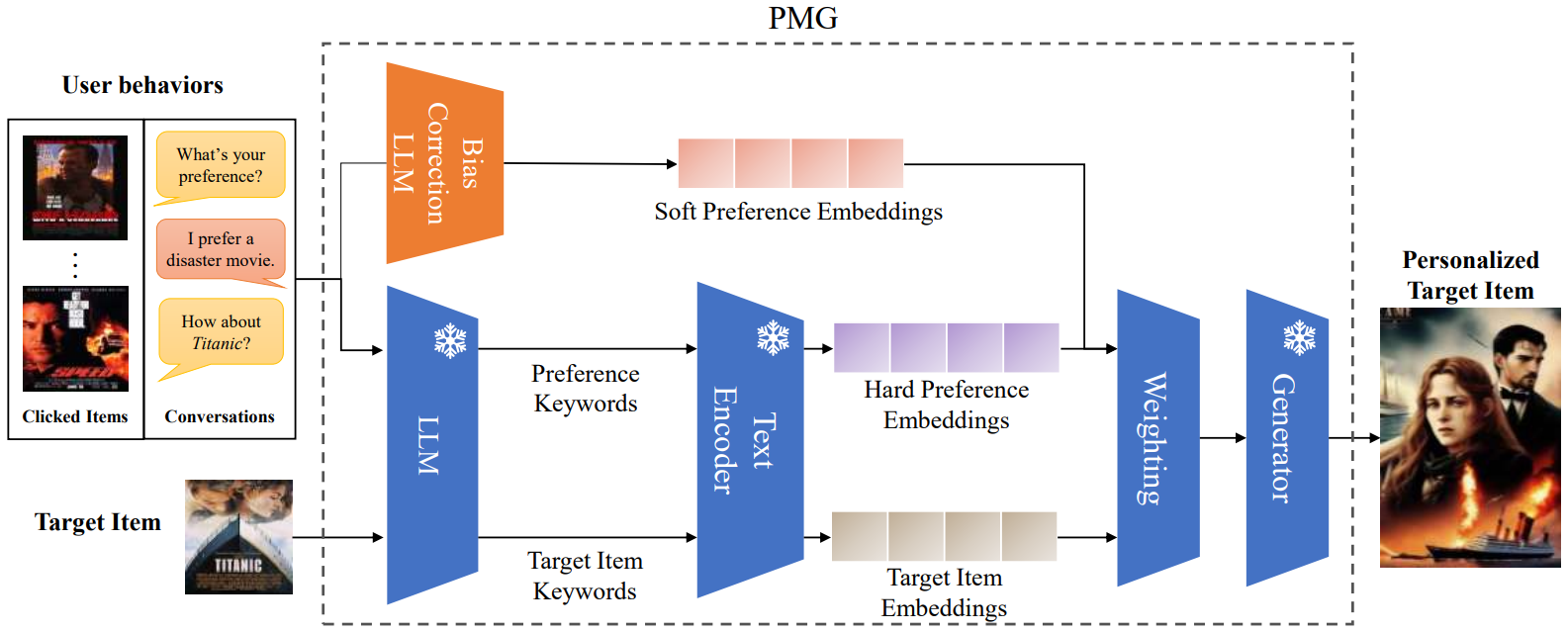
创新点:
-
提出了一种个性化多模态生成方法(PMG),首次将LLMs应用于个性化多模态生成任务,实现了一系列应用场景的个性化生成。
-
引入了基于用户行为的用户偏好表示方法,结合显式关键词和隐式嵌入,有效地捕捉用户的偏好信息,用于生成过程的条件。
-
使用加权求和的方式平衡准确性得分和个性化得分,实现了生成内容在准确性和个性化之间的良好平衡。
ANOLE: An Open, Autoregressive, Native Large Multimodal Models for Interleaved Image-Text Generation
**方法:**ANOLE是一个开源的多模态模型,专注于交错图像-文本生成。它基于Meta AI的Chameleon模型,通过高效微调少量参数来增强图像和多模态生成能力,而无需依赖扩散模型。
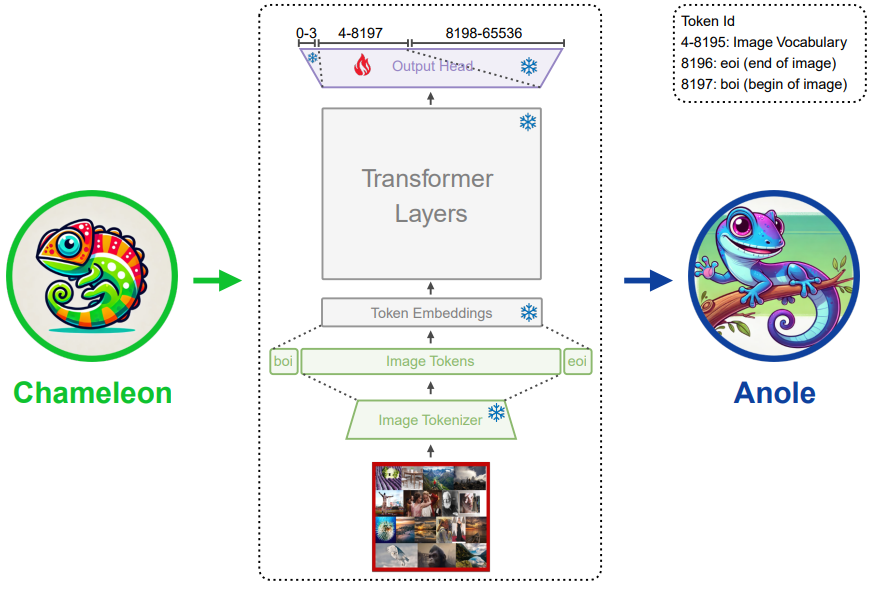
创新点:
-
ANOLE采用自回归方法进行图像和文本的生成,这使得它能够产生连贯且高质量的交错图像-文本序列。
-
ANOLE通过微调不到40M的参数,使用大约6000个样本,有效地实现了视觉和多模态生成能力,体现了它在大型多模态模型中引入复杂功能时的高数据和参数效率。
-
提供了一个用于自回归多模态模型的训练和推理的统一框架,降低了开发和实验的门槛。

Generative Multimodal Models are In-Context Learners
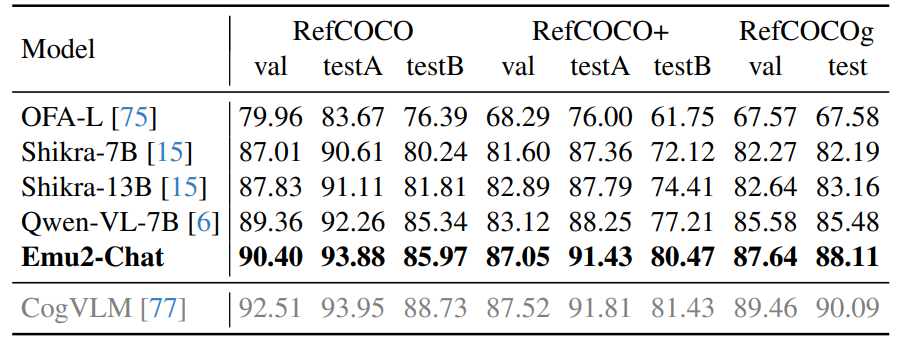
**方法:**论文介绍了一个名为 Emu2 的大型多模态生成模型,它通过大规模多模态序列的训练,具备了强大的多模态上下文学习能力。Emu2 能够处理包括文本、图像-文本对和交错的图像-文本-视频等在内的多种数据类型,并且在少量样本或简单指令的情况下解决多模态任务。

创新点:
-
Emu2通过大规模多模态序列的统一自回归目标进行预训练,能够预测下一个多模态元素(无论是视觉嵌入还是文本标记)。
-
在少量样本或简单指令的情况下,Emu2展现出解决多模态任务的能力,包括需要即时推理的视觉提示和基于对象的生成任务。
-
通过对Emu2进行指令微调,模型能够在遵循特定指令的情况下,在大型多模态模型的问答基准测试和开放式主题驱动生成等具有挑战性的任务上实现新的最佳状态。
关注下方《学姐带你玩AI》🚀🚀🚀
回复"多模态生成"获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏