引言
今天带来一篇结合RAG和微调的论文:RAFT: Adapting Language Model to Domain Specific RAG。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
本文介绍了检索增强微调(Retrieval Augmented Fine Tuning , RAFT)训练方法,可以提高模型在"开卷"领域内问答的能力。在训练RAFT时,给定一个问题和一组检索到的文档,我们训练模型忽略那些在回答问题时无用的文档,即干扰文档。RAFT通过逐字引用相关文档中的正确序列来帮助回答问题,同时结合RAFT的思维链式响应,帮助提高模型的推理能力。
1. 总体介绍
LLM越来越多地被用于专业领域,在这些场景中,通用知识推理的作用较小,主要目标是基于给定的文档集最大化准确性。本文研究了以下问题:如何将预训练的LLMs适应于专业领域中的检索增强生成?
在将LLMs适应于专业领域时,我们考虑了以下两个方案:通过检索增强生成进行的上下文学习和监督微调。基于RAG的方法允许LLM在回答问题时引用文档。然而,基于RAG的上下文学习方法未能利用固定领域设置。另一种选择是监督微调,这提供了学习文档中更一般模式的机会,并更好地与最终任务和用户偏好对齐。然而,现有的基于微调的方法要么未能在测试时利用文档(没有融入RAG),要么未能在训练过程中考虑检索过程中的不完美之处。

图1: 如何最好地准备考试?(a)基于微调的方法通过直接记忆输入文档或回答练习问答而不引用文档来实现"学习"。(b)另一方面,上下文检索方法未能利用固定领域所提供的学习机会,相当于在没有学习的情况下参加开卷考试。相比之下,RAFT通过在模拟的不完美检索环境中参考文档,并结合问题-答案对进行微调------从而有效地为开卷考试做好准备。
可以类比于开卷考试。现有的上下文检索方法就像是在没有学习的情况下参加开卷考试。另一方面,现有的基于微调的方法通过直接"记住"输入文档或回答练习问题来实现"学习",但不引用文档。虽然这些方法利用了领域内的学习,但未能为开卷考试的特性做好准备。
本文研究了如何将指令微调(IFT)与检索增强生成(RAG)相结合。提出了一种新颖的适应策略------检索增强微调(RAFT)。RAFT专门解决了将LLMs微调以融入领域知识的挑战,同时提高领域内RAG的表现。RAFT不仅使模型能够通过微调学习领域特定的知识,还确保对干扰性检索信息的鲁棒性。实现这一目标的方法是训练模型理解问题(prompt)、检索到的领域特定文档和正确答案之间的动态关系。回到开卷考试的类比,我们的方法类似于通过识别相关和无关的检索文档来准备开卷考试。
在RAFT中,我们训练模型在存在干扰文档( D k D_k Dk)的情况下从文档( D ∗ D^* D∗)中回答问题( Q Q Q),生成答案( A ∗ A^* A∗),其中 A ∗ A^* A∗包括思维链推理。
代码发布在 https://github.com/ShishirPatil/gorilla 。
2. LLM用于开卷考试
这里用开卷和闭卷考试来进行类比。
闭卷考试 通常指的是LLMs在考试期间无法访问任何额外文档或参考资料来回答问题的情况。例如,在这个场景中,LLM作为聊天机器人使用,从预训练和监督微调中获得的知识来回应用户的提示。
开卷考试 相对而言,我们将开卷考试的设置比作LLM可以参考外部信息源(例如网站或书籍章节)的场景。在这种情况下,LLM通常与检索器配对,检索器获取k份文档(或文档的特定部分),并将其附加到用户的提示中。LLM通过这些检索到的文档获得领域特定信息。因此,在这些设置中,LLM作为通用LLM的表现在很大程度上依赖于检索器的质量以及检索器准确识别最相关信息的能力。
领域特定开卷考试 在本文中,我们关注比一般开卷考试更狭窄但日益流行的领域,即我们称之为领域特定开卷考试。在这种情况下,我们事先知道LLM将被测试的领域。LLM可以使用在该特定领域上进行微调的任何信息来回应用户的提示。领域特定的例子包括企业文档、组织的代码库等。在所有这些场景中,LLM将用于回答可以在文档集合中找到答案的问题。检索技术本身对机制的影响很小。本文研究了领域特定开卷考试的设置以及如何将预训练的LLM适应于该特定领域,包括如何使其对不同数量的检索文档和干扰项更加鲁棒。
3. RAFT
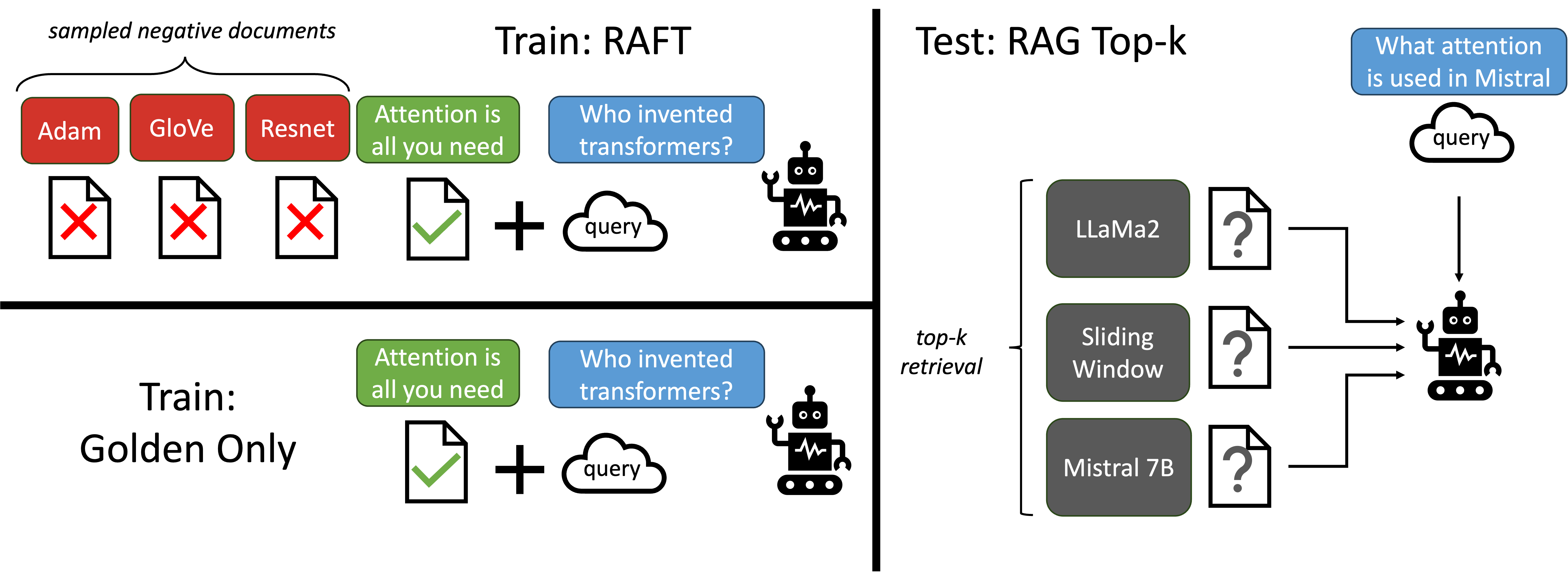
图2: RAFT方法的概述。左上图展示了将LLMs适应于从一组正面和干扰文档中提取答案的方法,与标准RAG设置相比,后者基于检索器的输出进行训练,这是一种记忆与阅读的混合方式。在测试时,所有方法都遵循标准RAG设置,提供了上下文中的前k个检索文档。
监督微调
考虑一个用于问答数据集的监督微调(SFT设置。该设置包括从数据集( D D D)中提取或已有的一组问题( Q Q Q)及其对应的答案( Q Q Q)对。在经典的SFT设置中,模型被训练以提高其基于知识回答问题的能力。经过这样的训练,模型也可以在测试时与检索增强生成RAG设置一起使用,在此情况下,额外的文档可以被引入提示中,以帮助模型回答问题。可以表示如下:
{ 训练: Q → A } , { 0 − s h o t 推理: Q → A } , { R A G 推理: Q + D → A } \{训练:Q → A\},\{0-shot推理:Q → A\},\{RAG推理:Q + D → A\} {训练:Q→A},{0−shot推理:Q→A},{RAG推理:Q+D→A}
RAFT: 检索增强微调(RAFT) 提供了一种新颖的方法来准备微调数据,以使模型适应领域特定的开卷考试设置,相当于领域内RAG。在RAFT中,我们准备训练数据,使每个数据点包含一个问题( Q Q Q)、一组文档( D k D_k Dk)以及从其中一个文档( D ∗ D^* D∗)生成的思维链风格答案( A ∗ A^* A∗)。我们区分两类文档:golden文档( D ∗ D* D∗),即可以从中推导出问题答案的文档,以及干扰文档( D i D_i Di),即不包含答案信息的文档。作为实现细节,golden文档不必是单一文档,而可以是多个文档。对于数据集中P比例的问题( q i q_i qi),保留黄金文档( d i ∗ d_i^* di∗和干扰文档( d k − 1 d_{k-1} dk−1)。对于(1-P)比例的问题( q i ) q_i) qi),不包括黄金文档,只包括干扰文档( d k d_k dk)。然后,我们使用标准的监督训练(SFT)技术对语言模型进行微调,训练模型从提供的文档和问题中生成答案。图2展示了RAFT的高级设计原则。
RAG方法使模型在其训练的文档集上表现更好,即在领域内。通过在某些情况下移除黄金文档,促使模型记忆答案而不是从上下文中推导答案。RAFT的训练数据如下,示例训练数据见图3。
P % of data : Q + D ∗ + D 1 + D 2 + . . . + D k → A ∗ (1 − P) % of data : Q + D 1 + D 2 + . . . + D k → A ∗ \text{P \% of data}: Q + D^∗ + D_1 + D_2 + . . . + D_k → A∗ \\ \text{(1 − P) \% of data}: Q + D_1 + D_2 + . . . + D_k → A∗ P % of data:Q+D∗+D1+D2+...+Dk→A∗(1 − P) % of data:Q+D1+D2+...+Dk→A∗

随后,在测试场景中,模型会接收到问题 Q Q Q以及RAG流水线检索到的前k个文档。注意RAFT与所使用的检索器无关。
提高训练质量的一个关键因素是生成推理过程,例如思维链,以解释提供的答案。RAFT方法类似:创建完整的推理链,并明确引用来源,可以提高模型在回答问题时的准确性。在图3中,以这种方式生成训练数据涉及向模型提供问题、上下文和经过验证的答案,然后要求模型形成一个适当引用原始上下文的推理链。
在实验中,对于所有数据集,使用上述技术生成答案。Gorilla APIBench数据集已经包含了答案中的推理过程。我们在图3中提供了生成步骤的示例,详细的推理答案包括来自原始上下文的引用,位于##begin_quote##和##end_quote##之间,以及如何基于这些引用得出结论的详细解释。添加详细的推理段落可以帮助提升模型在实验中的表现。
4. 评估
我们设计实验以研究RAFT与各种基线方法的表现。我们发现,RAFT-7B模型(LlaMA-2的微调版本)在从领域特定文档中读取和提取信息的能力上优于领域特定微调模型和带有RAG的通用模型。作为消融实验,我们还展示了模型学习思维链响应的重要性。
数据集
使用以下数据集来评估我们的模型和所有基线。
- Natural Questions(NQ)
- Trivia QA
- HotpotQA
- HuggingFace
- Torch Hub
- TensorFlow Hub
- PubMed QA
NQ、Trivia QA和HotpotQA是相对通用领域的数据集,而其他则是领域特定文档的数据集。
基线
在实验中考虑了以下基线方法:
- LlaMA2-7B-chat模型,0-shot提示:这是常用的用于问答任务的指令微调模型,我们提供清晰的书面指令,但没有参考文档。
- LlaMA2-7B-chat模型与RAG(Llama2 + RAG):与之前的设置类似,不同的是这里包括了参考文档。这是在处理领域特定问答任务时的一个流行技术。
- 领域特定微调与0-shot提示(DSF):标准监督微调,没有上下文中的文档。我们发现它主要用于调整模型的回答风格以及熟悉领域背景。
- 领域特定微调与RAG(DSF + RAG):使用RAG为领域特定微调的模型提供外部知识。因此,对于模型不知道的知识,它仍然可以参考上下文。
4.1 结果
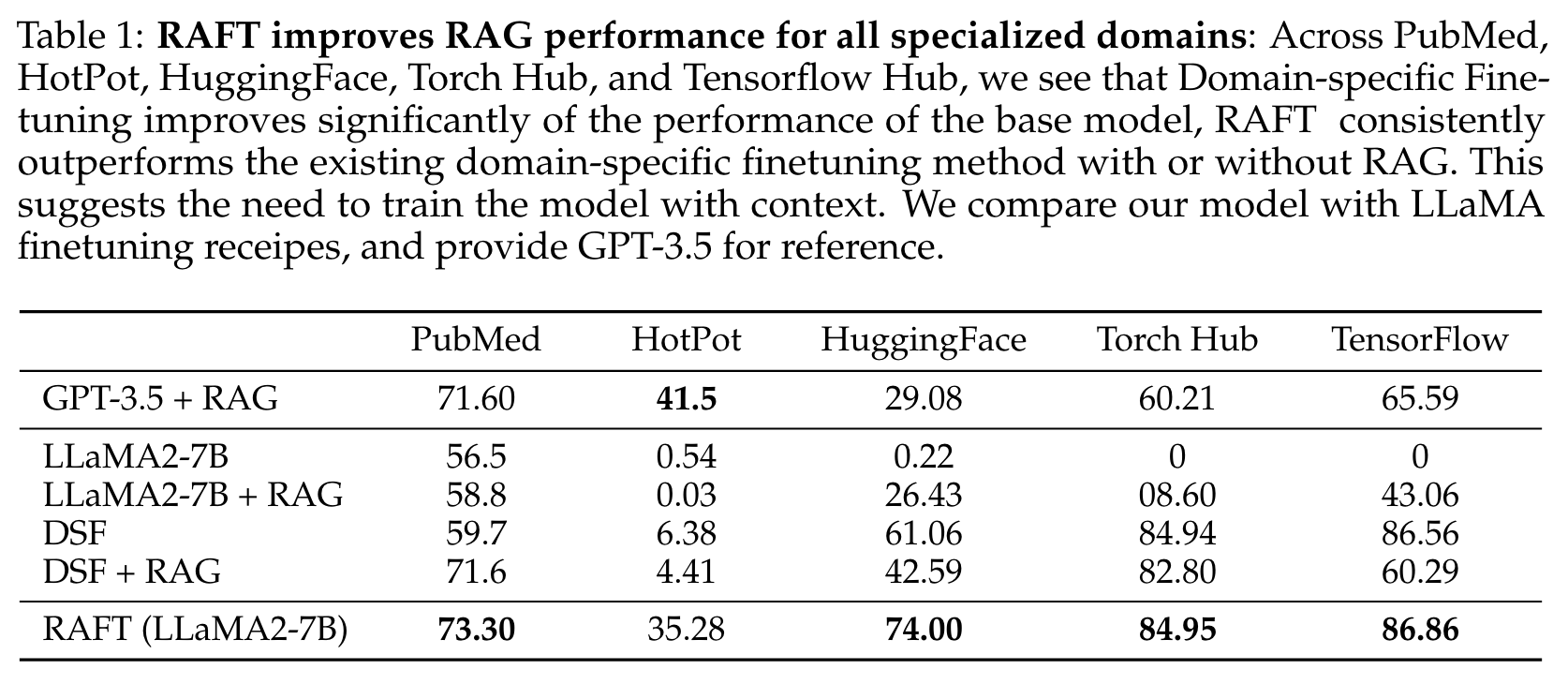
使用上述数据集和基线,评估了RAFT模型,并在表1中展示了RAFT的有效性。我们发现RAFT在提取信息和对抗干扰项方面始终显著优于基线。与基础Llama-2指令微调模型相比,带有RAG的RAFT在信息提取和对干扰项的鲁棒性方面表现更好。
与特定数据集上的DSF相比,我们的模型在依赖提供的上下文解决问题方面表现更佳。
总体而言,LLaMA-7B模型,无论是否使用RAG,其表现都较差,因为其回答风格与实际情况不符。通过应用领域特定微调,我们显著提升了其性能。这一过程使模型能够学习和采用适当的回答风格。然而,将RAG引入领域特定微调(DSF)模型并不总是能带来更好的结果。这可能表明模型在上下文处理和信息提取方面的训练不足。通过采用我们的RAFT方法,我们不仅使模型的回答风格匹配要求,还改善了其文档处理能力。因此,我们的方法优于所有其他方法。
4.2 CoT的效果

还评估了思维链方法在提升模型性能方面的有效性。如表2所示,仅仅提供答案可能并不总是足够的。这种方法可能导致损失快速下降,从而使模型开始过拟合。引入一个推理链,不仅引导模型得到答案,还能丰富模型的理解,可以提高整体准确性并防止过拟合简短答案。在我们的实验中,整合思维链显著提高了训练的鲁棒性。我们使用GPT-4-1106生成思维链提示,并在图3中包括了我们使用的提示示例。
4.3 质量分析

为了说明RAFT相对于领域特定微调(DSF)方法的潜在优势,我们在图4中展示了一个对比示例。这个示例定性地展示了一个场景,其中DSF模型在回答一个要求识别编剧身份的问题时变得困惑。它错误地引用了编剧写的电影之一,而没有提供正确的名字。相比之下,RAFT模型准确回答了问题。这一差异表明,仅用问答对训练模型可能会削弱其从提供的文档中提取相关上下文的能力。这个对比突显了在训练数据集中整合标准的指令微调和上下文理解的重要性,以保持和提升模型处理文本的能力。
4.4 是否应该始终使用Golden上下文来训练LLM以进行RAG?
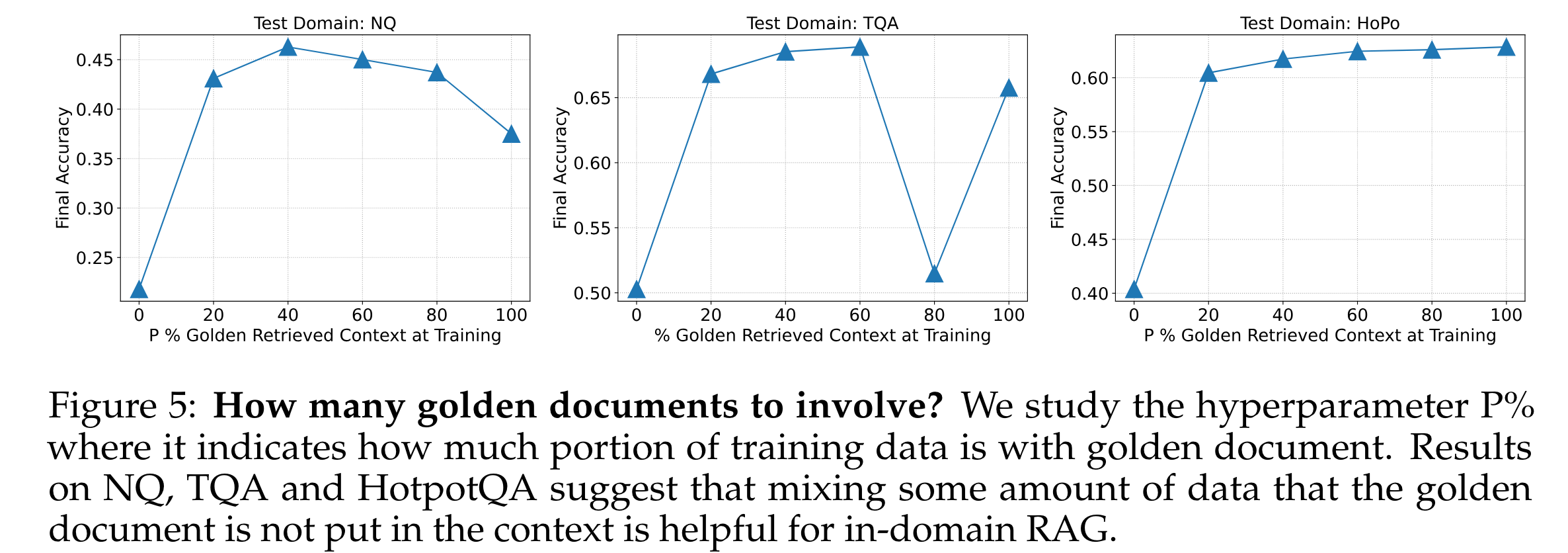
在我们探索大型语言模型是否应该始终使用Golden上下文进行检索增强生成时,我们提出了一个关键问题:训练数据中应该包含多少比例( p % p\% p%)的黄金文档?直观上,可能会假设,为了有效地训练阅读和从上下文中提取信息,Golden文档应在训练过程中始终包含( P = 100 % P = 100\% P=100%)。然而,我们的发现挑战了这一假设:在上下文中包含部分没有黄金文档的训练数据( P = 80 % P = 80\% P=80%)似乎能够提升模型在RAG任务上的表现。
图5展示了我们对超参数 P % P\% P%的调查, P % P\% P%表示应包含黄金文档的训练实例的百分比。我们发现,最佳比例因数据集而异, P % P\% P%范围从40%、60%到100%不等。这表明,在训练LLM时,有时不包含正确的上下文可能对下游任务(如回答与文档相关的问题)有益。在我们的训练设置中,我们在Golden文档旁边包含了四个干扰文档,并且在测试时,我们保持这种格式,提供了黄金文档和四个干扰文档。我们的发现表明,对于领域特定的RAG任务,将一定比例的训练数据中不包含Golden文档的上下文被证明是有利的。
5. RAFT 在 Top-K RAG 上的泛化能力
在使用 Top-K RAG 结果进行评估时,RAFT 中干扰文档的数量如何影响模型的性能?之前的研究已经突出了 LLM 对无关文本的脆弱性。这个问题对于 LLMs + RAG 特别重要,因为在测试时经常使用 Top-K RAG 以确保高召回率。这种情况下,模型需要具备辨别和忽略无关内容的能力,专注于相关信息。
5.1 提高模型对 Top-K RAG 的鲁棒性
为了解决提升 LLM 在检索管道中筛选无关文本的能力的挑战,我们的分析显示,单独使用Golden(高度相关)文档进行训练可能会不自觉地削弱模型辨别和忽略无关信息的能力。为此,我们的算法 RAFT 采用了一种将Golden文档与一部分无关文档混合的策略。这种方法促使我们研究在整个训练过程中应纳入多少干扰(无关)文档,以及这种训练方法如何适应测试阶段 RAG 遇到的不同文档量。我们的目标是优化相关和无关信息之间的平衡,以增强模型识别和利用相关内容的效率。
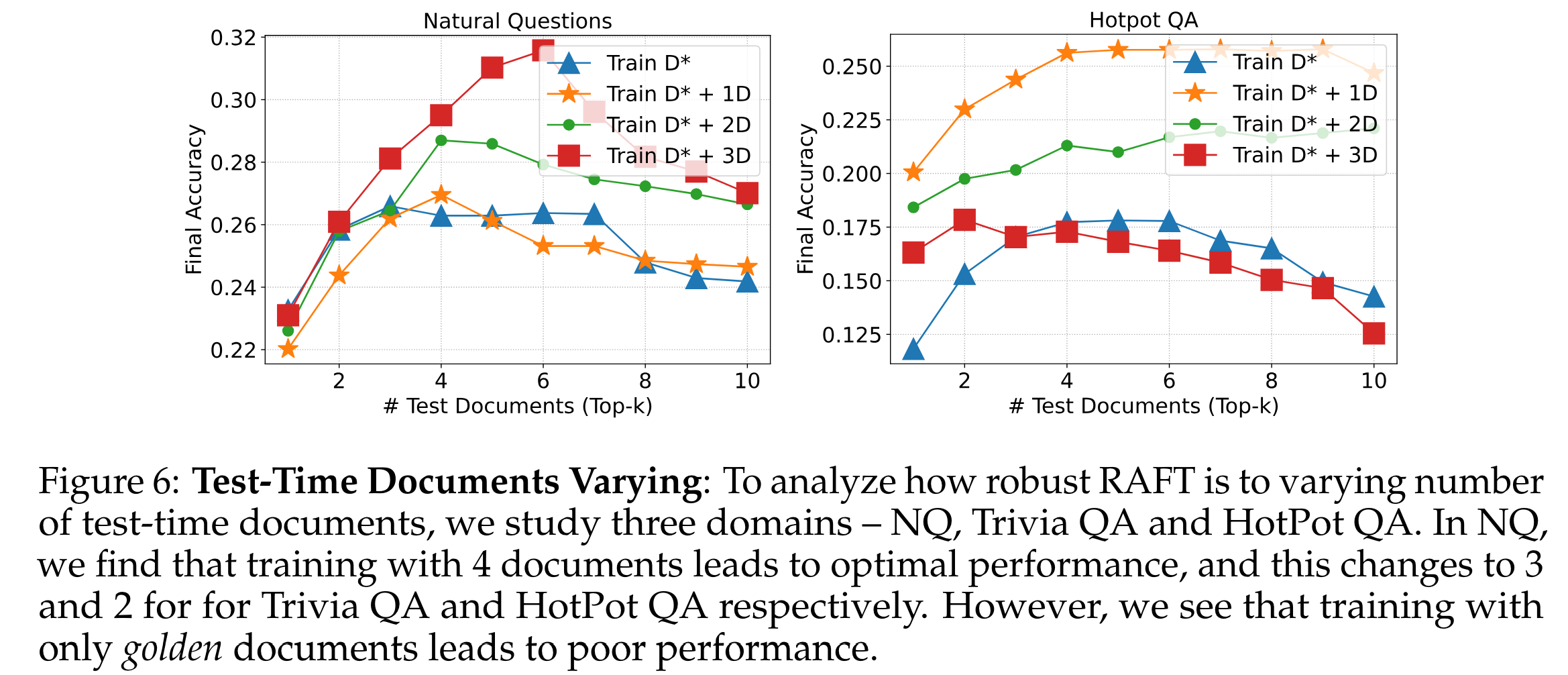
使用干扰文档进行训练
为了提高 LLM 对检索文档中无关文本的鲁棒性,我们采用了一种包含黄金(Golden,高度相关)文档和干扰(无关)文档的微调方法。模型在包含不同数量的干扰文档的情况下进行训练,但始终使用从检索器获得的 Top-3 文档进行评估------这与 p 不同。我们的发现(如图6所示)表明,仅使用黄金文档的微调方法通常会导致性能低于包含更多干扰文档的配置。图中显示,自然问题(Natural Questions)使用 D ∗ + 3 D D^∗ + 3D D∗+3D 的训练效果较好,而 Hotpot QA 使用 D ∗ + 1 D D^∗ + 1D D∗+1D 的文档效果更佳。在实验中,始终采用一份黄金文档和四份干扰文档的训练设置。
对测试时不同文档数量的泛化
考察了不同数量的测试文档对模型性能的影响。具体来说,我们的实验关注于评估模型在训练时使用不同数量的干扰文档如何响应测试时文档数量的变化。结果(如图6所示)确认,训练过程中包含干扰文档确实使模型对测试时文档数量波动更具弹性。这种在测试时文档数量变化下维持一致性能的能力进一步验证了我们方法 RAFT 的鲁棒性。这一发现强调了一个良好校准的训练环境对于准备模型应对现实世界中可能遇到的各种场景的重要性。
6. 相关工作
检索增强语言模型 检索增强语言模型(RALMs) 通过集成检索模块,从外部知识库中提取相关信息,从而显著提升了各种自然语言处理任务的性能,包括语言建模和开放域问答。
记忆 关于大型神经语言模型的一个关键问题是它们是否真正"理解"文本,还是仅仅依赖于表面模式的记忆。Feldman,Carlini开发了量化神经模型记忆化程度的方法。Brown,Power,Liu进一步探讨了记忆如何影响模型的泛化能力。
针对 RAG 的微调 最近,几篇论文探讨了将预训练的 LLM 微调以更好地处理 RAG 任务的想法(Lin; Wang; Xu;liu)。这些工作关注于构建 RAG 微调数据集,并训练模型在这些任务上表现良好。特别是,在他们的设置中,测试时的领域或文档可能与训练时不同;而我们论文则研究了一个略微相反的情境,即只关心在相同文档集上测试 LLM。
7. 结论
RAFT 是一种旨在提升模型在特定领域的开卷环境中回答问题性能的训练策略。我们强调了几个关键设计决策,比如在训练中加入干扰文档、组织数据集以使一部分数据没有黄金文档的背景,并以思维链的方式生成答案,直接引用相关文本。
总结
⭐ 本篇工作提出了一种检索增强微调方法RAFT,可以提高模型在开卷领域内问答的能力。在训练RAFT时,给定一个问题和一组检索到的文档,训练模型忽略那些在回答问题时无用的干扰文档。RAFT通过逐字引用相关文档中的正确序列来帮助回答问题,同时结合RAFT的思维链式响应,帮助提高模型的推理能力。