一、前言
最近在最新的数据库受欢迎程度排行榜中,排在第一位的竟然不是我们熟悉的MYSQL数据库而是PostgreSQL,并且MySQL数据库的受欢迎程度比PostgreSQL竟然落后了15个百分点。
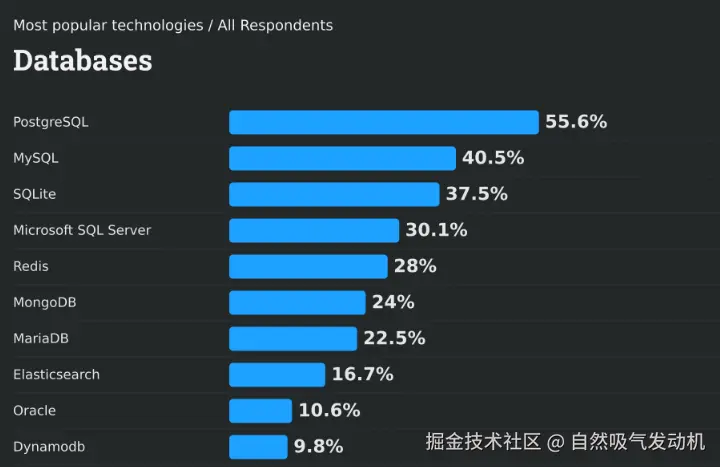 为何pg数据库这几年突飞猛进,为何mysql数据库逐渐落寞?本文旨在总结和挖掘Pg数据库的几个亮点功能,分析为何pg数据库能成为当下最受欢迎的数据库
为何pg数据库这几年突飞猛进,为何mysql数据库逐渐落寞?本文旨在总结和挖掘Pg数据库的几个亮点功能,分析为何pg数据库能成为当下最受欢迎的数据库
二、安装
这里简要说明下安装过程,笔者是使用docker安装的pg数据库 过程中使用到的几个关键命令如下:
shell
docker run --name postgres-db -e POSTGRES_PASSWORD=initialpass -p 5432:5432 -d postgres:latest
docker exec -it postgres-db psql -U postgres
-- 创建用户root并设置密码
CREATE USER root WITH SUPERUSER PASSWORD 'root';
-- 授予所有权限
GRANT ALL PRIVILEGES ON DATABASE postgres TO root;
-- 使用root用户登录 postgres 数据库
psql -U root -d postgres三、Pg数据库功能亮点
3.1 强大的面向对象的支持能力
Pg数据库是关系型数据库但是也是面向对象的数据库,这就使得这个数据库更符合服务端面向对象编程的思维模式。
先定义一个雇员类型:
sql
create TYPE employee AS (
name VARCHAR,
age INT,
skill TEXT[]
);上面的代码中 我们创建了一个自定义类型 employee包含三个字段:
- name:字符串类型(员工姓名)
- age:整数类型(员工年龄)
- skill:文本数组(员工技能列表)
然后我们创建一个数据表
sql
CREATE TABLE "tb_employees" (
id SERIAL PRIMARY KEY,
"employee_info" "employee",
"department_id" varchar(20)",
"created_at" timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP,
"updated_at" timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT "tb_employees_pkey" PRIMARY KEY ("id")
)
;
INSERT INTO "tb_employees" (employee_info) VALUES (ROW('张三', 30, ARRAY['Java', 'Python'])::employee);
-- 注意 employee 类型中的每个字段值都必须写上,缺少任何一个字段都会报错
INSERT INTO "tb_employees" (employee_info, department_id) VALUES (ROW('Maria', 20, ARRAY[]::TEXT[])::employee, 'Guard');表和表之间还能够继承,我们创建了一个子公司员工表 tb_sub_employees ,它继承了 tb_employees 数据表,同时我们还定义了一个额外字段 sub_company_name
sql
create table tb_sub_employees(
sub_company_name VARCHAR(64)
) INHERITS (tb_employees)
INSERT INTO tb_sub_employees (
employee_info,
sub_company_name,
department_id
) VALUES
(
ROW('王一', 30, ARRAY['java']::TEXT[])::employee, -- employee 类型完整字段(name, age, skill)
'北京分公司',
'技术部'
),
(
ROW('王二', 35, ARRAY['项目管理']::TEXT[])::employee,
'广州分公司',
'行政部'
);然后我们打开这个表看下结构 发现这个表继承了父表的所有字段

表的继承还有下面两个重要规律
- 父表后续新增 / 删除字段时,子表不会自动同步(需手动调整子表结构);但父表修改字段类型(如 VARCHAR(32) 改 VARCHAR(64)),子表会自动同步。
- 不会自动继承父表的触发器、索引、主键约束、外键约束等 "对象级配置",仅继承字段结构
此外当我们执行SELECT * from tb_employees,会同时查找出来子表和父表的内容.
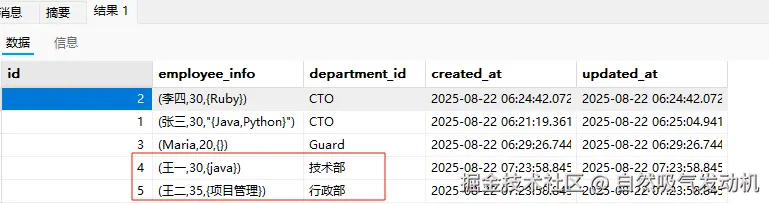
如果只需要查找出子表的内容需要将查询修改为下面这样,添加一个ONLY 关键字
sql
SELECT * from ONLY tb_employees利用这个机制其实还可以做数据隔离,比如我们现在的 tb_employees 有一个状态字段 status,标识员工是否在职,然后我们创建一个 tb_employees_his 表记录已经离职的人员,然后给tb_employees 绑定一个触发器在status变为离职状态的时候,往tb_employees_his插入一条数据,然后删除掉tb_employees 中的数据,这样上层应用就查不到这个员工了,但是如果去掉ONLY关键字就还能查到。
3.2 丰富的内置字段类型
Pg数据库比Mysql数据库支持更多的字段类型,除了上一节说过的自定义字段类型之后还有下面几种内置字段类型值得关注:
(1)CIDR类型
sql
CREATE TABLE "net_segments" (
-- serial 是一种特殊的自动增长整数类型,用于简化自增主键(ID 字段)的创建。它本质上是一个语法糖,底层通过结合 integer 类型、序列(sequence)和默认值实现自动增长功能
"id" SERIAL PRIMARY KEY,
"segment" cidr NOT NULL,
"segment_remark" varchar(255)
)
;
COMMENT ON COLUMN "net_segments"."id" IS 'id';
COMMENT ON COLUMN "net_segments"."segment" IS '网段';
COMMENT ON COLUMN "net_segments"."segment_remark" IS '网段说明';
INSERT INTO "net_segments" ("id", "segment", "segment_remark") VALUES (1, '192.168.1.0/24', '机房1');
-- >> 运算符:这是 PostgreSQL 中专门用于网络地址类型的包含运算符,表示 "左侧网络包含右侧网络"
select * from net_segments where segment >> '192.168.1.128/28'::CIDR(2)几何学类型
sql
-- 创建包含 circle 类型的表
CREATE TABLE circles (
id SERIAL PRIMARY KEY,
area circle
);
-- 插入圆形数据
INSERT INTO circles (area) VALUES
('((0,0), 10)'), -- 圆心(0,0),半径10
('((5,5), 3)'); -- 圆心(5,5),半径3
-- 查询:判断点 (3,3) 是否在圆内
SELECT id, area
FROM circles
WHERE area @> point '(3,3)'; -- @> 是包含运算符,判断圆是否包含点3.3 强大的JSON字段类型支持
在mysql 8.0 版本之后,数据库的字段类型也支持了json,但是mysql对json的支持还是比较简单,接下来我们看看 postgreSQL在JSON字段类型上的强大支持能力
sql
CREATE TABLE tb_request_log (
id SERIAL PRIMARY KEY,
url VARCHAR(1024) NOT NULL,
response JSONB,
request_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
-- 说明:这里为什么不给字段直接添加注释呢?是因为部分版本的pg不支持直接在建表语句里面写注释,可以通过COMMENT ON COLUMN 这个语法在创建完数据表之后再添加注释随后向这个表里面添加几条数据:

那么请你思考下如果我们要在mysql数据库中选出code是200的记录,是不是还挺麻烦的,但是在pg这边这些问题就可以轻松解决,首先为了支持JSON数据的检索,pg定义了很多新的操作符:
- ->:返回 JSON 对象(带引号,如 "success")
- ->>:返回文本值(不带引号,如 success)
- @>:判断 JSON 是否包含指定对象(如数组包含某元素)
- ||:合并两个 JSON 对象(用于更新)
- -:删除 JSON 中的指定键
例如下面给出来的一些查询实例,这些查询在MySQL中每个查询实现起来都比较麻烦,但是在Pg中就比较好实现。
sql
-- 查询code==200 的访问log
SELECT *
FROM tb_request_log
WHERE response ->> 'code' = '200';
-- 查询 response 中包含顶级 data 字段的记录
SELECT *
FROM tb_request_log
WHERE response ? 'data';
-- 查询 response 字段中的requestType 数组中包含 "API" 的记录
SELECT *
FROM tb_request_log
WHERE response -> 'requestType' @> '["API"]'::JSONB;
-- 查询 tb_request_log 表中,response(JSONB 类型)字段包含 {"code":200} 这个 JSON 对象的所有记录
select * from tb_request_log where response @> '{"code":200}' 上面的sql虽然可以查询到结果,但是如果数据表的记录数比较多,查询效率就比较一般了,但是不要慌,pg还支持给需要经常用来作为检索条件的json字段加索引。
sql
-- 对response中的"code"字段创建索引
CREATE INDEX idx_tb_request_log_response_status ON tb_request_log USING GIN ((response -> 'code'));那么如果在mysql中如果要修改一个json字段的内容,比如添加一个key或者移除一个key,那么基本上就是要覆盖重写,但是在pg中就比较简单了。
sql
-- 更新JSON字段中的值(如修改某条记录的message)
UPDATE tb_request_log
SET response = response || '{"message": "登录成功(已更新)"}'::JSONB -- 使用||合并更新
WHERE id = 1;
-- 删除JSON字段中的某个键(如删除details字段)
UPDATE tb_request_log
SET response = response - 'details' -- 使用-删除键
WHERE id = 2;3.4 丰富的数据库插件生态
pg数据库拥有强大的插件生态,这就让pg的拓展功能非常强大,这其中有5个插件功能读者可以重点了解一下:
全文检索功能(安装中文分词器插件 ,让pg实现类似 ElasticSearch的全文检索功能,默认情况下 PostgreSQL支持英文分词检索,且不需要安装任何插件)
快速数据读取(安装 redis_fdw,让pg充当redis类似的角色。备注:PostgreSQL可以使用CREATE UNLOGGED TABLE 命令创建临时表(数据库重启之后数据全部丢失)这种临时表也可以支持快速查询和快速写入,也可以可以间接的当缓存使用而不用安装任何插件)
地理位置支持(安装 postgis ,让pg支持地理位置,例如经纬度范围查询)
向量数据库(安装 pgvector ,让pg支持向量检索 ,用于AI-Agent的 RAG 功能实现)
定时任务(安装 pg_cron 让pg支持定时任务)
由于篇幅所限不能将所有插件以及特色功能全部介绍一遍,下面以pg_cron和pg_vector为例子介绍下具体的插件安装和基础使用
3.4.1 pg_cron 定时任务插件
安装插件之前需要先获取下当前pg数据库的版本,比如我这个docker安装的postgreSQL的版本就是 17.6 版本,插件的安装需要考虑和当前pgSQL 的版本匹配

安装插件也非常简单,这里以 pg_cron 插件为例子说明下安装命令
shell
# 更新包索引(容器内操作)
apt-get update
# 安装 pg_cron(版本号与 PostgreSQL 17 匹配)
apt-get install -y postgresql-17-cron随后打开pgSQL docker 容器的的配置文件
shell
vim /var/lib/postgresql/data/postgresql.conf在这个配置文件做下述修改
shell
# 原配置可能为空或包含其他插件
shared_preload_libraries = 'pg_cron' # 例如:已有 postgis 则改为 'pg_cron,postgis'注意pg_cron 插件默认只能且只能在 postgres 数据库(默认系统数据库)创建和管理定时任务,如果你自己定义了一个数据库,需要在这个数据库中使用插件,你需要修改配置文件,添加下面的选项:
shell
# 在文件末尾添加(替换为你的数据库名,如 test)
cron.database_name = 'test'创建一个定时任务也非常简单:
sql
# 在 postgres 数据库中创建插件和任务(此时不会报错)
CREATE EXTENSION pg_cron;
# 创建定时任务 每天凌晨 2 点自动删除 tb_request_log 表中 30 天前的记录
SELECT cron.schedule(
'clean-test-logs',
'0 2 * * *',
$$DELETE FROM tb_request_log WHERE request_time < NOW() - INTERVAL '30 days'$$
);
# 查看当前有哪些定时任务
SELECT * FROM cron.job;
# 关闭任务 删除名为 test-cron-job 的定时任务。
SELECT cron.unschedule('test-cron-job')启用定时任务拓展之后就会在当前数据库下开启一个新的数据表 cron.job 结构如下:

3.4.2 pgvector 向量数据库插件
本文使用一个真实案例来介绍 使用pg数据库来实现RAG功能
RAG功能用咱的大白话来说就是用私域的知识来和用户的提问一起交给大模型,这样大模型就知道一些问题的背景了,因为有时候用户的问题涉及到的相关知识大模型是没有训练过的。那么私域的知识可能有很多,不可能每次用户提问都把所有的知识库都带上,带上哪些相关材料就是RAG要解决的问题。 那么为什么需要向量数据库呢,这是因为我们的知识库如果要想实现上面的这套流程,必须先转为向量存储之后才行。在用户在提问的时候,会检索向量数据库里面的相似内容,放在提示词里面一起送给大模型。
我们先按照类似的流程安装 pgvector 插件 (postgresql-17-pgvector),但是安装pgvector由于不涉及后台数据库调度所以不用改数据库配置文件也不用重启容器,具体命令也就下面这一行即可
shell
apt-get install -y postgresql-17-pgvector随后我们登录数据库笔者这里是使用navicat 直接执行一下下面的命令,当前数据库也就开启了vector的拓展
sql
CREATE EXTENSION vector在RAG中 把 "外部知识" 变成 "可检索的格式",具体分为四步:
步骤 1:数据加载(Load)
步骤 2:数据拆分(Split):大模型处理文本有 "长度限制"(如 GPT-4 上下文窗口是 128k tokens,约 10 万字),因此需要将长文档拆成 "短片段"(如每段 200-500 字),确保后续检索和生成时能完整覆盖关键信息。
步骤 3:文本向量化(Embed):用嵌入模型(Embedding Model) 将每个文本片段转换成 "向量"(一串数字,如 768 维 / 1536 维数组)。
向量的核心作用是 "用数字表示语义":语义越相似的文本,向量在 "向量空间" 中的距离越近
步骤 4:向量存储(Store)
首先我们先用langchain的相关API构建下述智能体代码,对langchain 或者 langgraph 不熟悉的同学可以简单看下我之前写的相关博客,或者直接去官网了解最新的内容。
python
import asyncio
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_postgres import PGEngine, PGVectorStore
# Set embeddings
embd = DashScopeEmbeddings(
dashscope_api_key="xxxxxxxxxxxxxx",
model="text-embedding-v3"
)
# Docs to index
urls = [
"https://java2ai.com/docs/1.0.0-M6.1/tutorials/vectorstore/?spm=4347728f.4dbc009c.0.0.179c6e97dDjP50",
]
# Load
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
print(docs_list)
# Split
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
async def get_store(embedding: OpenAIEmbeddings):
CONNECTION_STRING = "postgresql://root:root@localhost:5432/test?sslmode=disable"
pg_engine = PGEngine.from_connection_string(url=CONNECTION_STRING)
# 创建向量存储表,指定表名和向量维度
await pg_engine.ainit_vectorstore_table(
table_name="vectorstore",
vector_size=768,
)
store = await PGVectorStore.create(
engine=pg_engine,
table_name="vectorstore",
embedding_service=embedding,
)
return store
store = asyncio.run(get_store(embd))
store.aadd_documents(doc_splits)
retriever = store.as_retriever()
user_query="什么是向量存储"
# 基于向量相似度检索相关文档。
docs = retriever.invoke(user_query)
print(docs)上面的代码会创建一个支持向量存储和相似度搜索的专用表 vectorstore,表中包含文本内容、对应的768维向量以及可选的元数据字段,数据表中记录这文本片段和向量化之后的信息。
在Langgraph中也支持使用pg数据库来做长期记忆,避免使用内存记忆无法进行持久化的问题。在AI-Agent开发过程中使用Pg数据库做向量存储也是一个非常好的选择
四、为何MYSQL数据库逐渐黯淡
笔者依然记得在大学时期学习数据库理论的时候使用的数据库是一款叫做SQL-Server的数据库,当时在学习的时候了解到了 触发器、存储过程、视图 这样的数据库概念,但是后来毕业后参加工作后这些特性竟然很少用到,这些功能更多的还是利用自己编写代码去实现而不是利用数据库自带的功能。
笔者分析看来pg数据库能够越来越受欢迎的原因有下面几个
(1)强大的插件生态
(2)丰富的内置功能
(3)更符合标准SQL数据库规范
也许在未来做数据库技术选型的时候Pg数据库更值得考虑,尤其是在一些低预算小项目中,pg的丰富功能可以让我们去替代一部分的中间件例如es、mongo、定时任务调度中心等。
如果读者对Pg数据库感兴趣 后期笔者还会出一期 关于MybatisPlus 和Pg数据库的结合使用的注意事项。