一、mysql介绍
1、InnoDB引擎
mysql5.5.8版本开始后。InnoDB引擎就是默认存储引擎,本文介绍知识点也都是围绕该引擎展开。
知 识 点 1 聚集存 储
InnoDB引擎采用聚集存储,即每张表的存储都是主键的顺序进行存放,也就是每行存****储 的物理 顺 序和主 键顺 序相同 ,如果未指定主键,引擎会为每张表生成一个6字节的rowid作为主键。相对于非聚集存储,聚集存储会同****时 存 储 索引和 数据 。
知 识 点 2 B+ 树索引
InnoDB引擎采用B+树索引,同样也是磁盘和存储工具设计的一种数据结构,它是一种平衡查找树,它在查找,插入、修改方面的时间复杂度都稳定为 O(logn)。相对于平衡二叉树,节点可以存 储 多个元素 ,因此整体可以存储较多的数据,并且树的高度也会矮,可以减少磁盘IO,提高检索效率。
注: 树结构,既有数****组结 构 检索的速度,又有链 表 结 构 增删改的速度
1.1、索引数据结构
按聚集存储方式的B+树索引数据结构如下
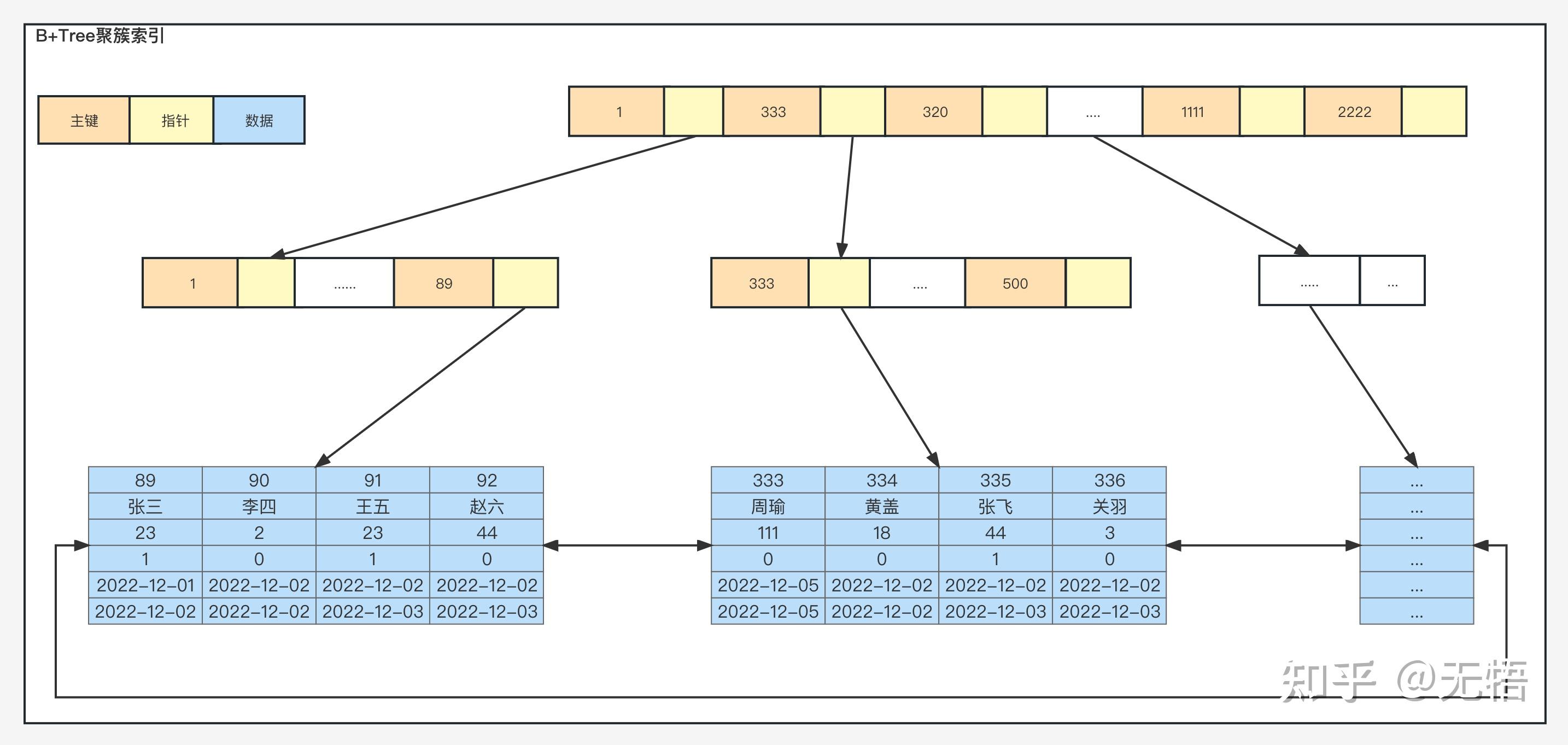
|----------------------------------------------------------------------------------------------|
| a、非叶子节点不存储data,只存储索引,且可以存储多个索引字段 b、叶子节点既存储data,也存储索引即主键,此时叶子结点覆盖所有数据 c、叶子节点用双向指针连接,提高区间访问的性能 |
总得来说,这个数据结构带来了空间和时间上成本,空间上每建立一个索引都要为它建立一棵 B+ 树,时间上每次对表中的数据进行增、删、改操作时,都需要去修改各个 B+ 树索引。
注: 非聚集存储方式相对于聚集存储方式的最大区别,这里叶子节点存储的data变更为数据地址
1.2、索引适用条件
从1.1原理,可知一个索引一个B+树,那么索引天然是排序的、分组的。若非叶子存储多个索引字段,需遵循最左匹配原则。那么索引适用条件如下:
假设t_student表,主键为id,联合索引为idx_name_age
|-------|-----------------------------|----------------------------------------------------------------------------------------------------------------------------------------------|
| 适用条件 | 参考原理 | 示例 |
| 全值匹配 | 索引检索 | select * from t_student where name = 'zhangsan' |
| 最左匹配 | 多个索引时,字段按顺序匹配 | 错误示例 select * from t_student where age > 18 and age< 30 |
| 范围值匹配 | 索引排序 | select * from t_student where name > 'zhangsan' and name < 'lisi' |
| 列前缀匹配 | 索引排序,例如字符串已经按字母排序好,此时只能匹配前缀 | select * from t_student where name list 'zhang%' |
| 排序匹配 | 索引排序 | select * from t_student order by age |
| 分组配置 | 索引分组 | select * from t_student order by name |
| 混合匹配 | 索引检索、索引排序 | select * from t_student where name = 'zhangsan' and age > 18 and age < 30 注: 任意条件仅限一个字段,即不能新增nick_name 精确匹配或birthday 范围匹配 |
1.3、索引失效场景
结合1.1和1.2,以及日常使用场景,总结索引失效场景如下:
假设t_student表,主键为id,联合索引为idx_name_age
|-----------|------------------|----------------------------------------------------------------------|
| 失效场景 | 参考原理 | 示例 |
| 字段类型不匹配 | 索引检索 | select * from t_student where age = 'zhangsan' |
| 索引字段条件不匹配 | 索引检索(即or出现未索引字段) | select * from t_student where name = 'zhangsan' or nick_name = 'zs' |
| 通配符不匹配 | 索引排序 | 同1.2 |
| 联合索引不匹配 | 多个索引时,字段按顺序匹配 | 同1.2 |
| 运算符不匹配 | 索引排序,仅支持大于、小于、等于 | != 、< >、not in、+、-、*、/、is null、is not null、字段比较 |
| 排序不匹配 | 索引排序 | 禁止使用asc、desc |
通过explain语句判断索引是否生效
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| EXPLAIN SELECT * FROM table_name WHERE column_name = 'value'; 示例1and条件---索引命中,即如图key为命中索引  示例2 or条件---索引未命中,即如图key为空 |
示例2 or条件---索引未命中,即如图key为空 |

2、锁
2.1、定义
锁是数据库系统区别于文件系统的一个关键特性。锁机制用于管理对共享资源的并发访问。
注:
这里的共享资源,不仅仅是行记录,还可以是表数据、操作缓冲池数据。
这里我们关注的锁是lock。lock的对象是事务,用来锁定的是数据库中的对象,如表、页、行。并且一般lock的对象仅事务commit或rollback后进行释放。
2.2、锁类型
共享锁(S Lock): 允许事务读一行数据
排他锁(X Lock): 允许事务删除或更新一行数据
意向共享锁(IS Lock): 事务想要获得一张表中某几行的共享锁
意向排他锁(IX Lock): 事务想要获得一张表中某几行的排他锁
注:
为了支撑在不同粒度(表、页)上加锁,并减少锁开销,引入意向锁,意向锁锁对某种资源的意向,可通过意向锁提前判断是否有冲突,减少遍历所有行锁的开销。
页是mysql的数据存储单位,SHOW VARIABLES LIKE 'innodb_page_size'可查看页大小
实践分享
|-------------------------------------------------------------------------------------------------------------------------------|
| 考虑到select 默认不加锁,而delete/update/insert 默认加排他锁,可以通过lock in share mode 主动加上S Lock ,for update 主动加上X Lock |
监控可能存在的锁问题
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| select * from information_schema.INNODB_TRX;  select * from information_schema.INNODB_LOCKS;
select * from information_schema.INNODB_LOCKS;  select * from information_schema.INNODB_LOCKS_WAITS;
select * from information_schema.INNODB_LOCKS_WAITS;  |
|
2.3、锁算法
Record Lock: 单个行记录上的锁
适用场景:sql语句查询条件字段仅主键索引
Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
适用场景:sql语句查询条件字段仅普通索引
注:插入意向锁( Insert Intention Locks**),** 提高并发插入的性能,允许多事务在同一间隙内插入数据而不会相互阻塞
Next key Lock:锁定一个范围,但包含记录本身,默认算法
适用场景:sql语句查询条件字段既有主键索引又有普通索引
2.4、死锁定义
死锁上指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象。死锁概率与事务数量、每个事务的操作数量、每个事务操作的数据量息息相关,所以需要在业务上减少事务数量、每个事务的操作数量,扩大每个事务操作的数据量范围。
3、事务
3.1、定义
事务同样是数据库区别于文件系统的重要特性,来保障事务里面所有操作ACID特性,即原子性、一致性、隔离性、持久性。
3.2、类型
默认事务类型READ REPEATABLE
4、设计规范
4.1、设计原则
a.基本原则
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1、第一范式 即每个列遵循原子性 举例:人的多个属性不能都放在一列 2、第二范式 即每个表遵循模块化 举例:订单模块和产品模块分开,即同一张表只能依赖一个主键(或负荷主键) 3、第三范式 即每个列遵循冗余性 举例:单价和总价不应该同时出现,班级和老师不应该同时出现 总结:需求>性能>范式,为了性能/需求,该冗余还是得冗余;为了成本,至少遵循第三范式 |
b.进阶原则(单表数据量过大怎么解决)

4.2、阿里建表规范
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1.【强制】表达是与否概念的字段,必须使用is_xxx的方式命名,数据类型是unsigned tinyint(1表示是,0表示否),此规则同样适用于odps建表。 说明:任何字段如果为非负数,必须是unsigned。 2.【强制】表名、字段名必须使用小写字母或数字;禁止出现数字开头,禁止两个下划线中间只 出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。 正例:getter_admin,task_config,level3_name 反例:GetterAdmin,taskConfig,level_3_name 3.【强制】表名不使用复数名词。 说明:表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于DO类名也是单数形式,符合表达习惯。 4.【强制】禁用保留字,如desc、range、match、delayed等,参考官方保留字。 5.【强制】唯一索引名为uk_字段名;普通索引名则为idx_字段名。 说明:uk_即unique key;idx_即index的简称。 6.【强制】小数类型为decimal,禁止使用float和double。 说明:float和double在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不正确的结果。如果存储的数据范围超过decimal的范围,建议将数据拆成整数和小数分开存储。 7.【强制】如果存储的字符串长度几乎相等,使用CHAR定长字符串类型。 8.【强制】varchar是可变长字符串,不预先分配存储空间,长度不要超过5000,如果存储长度大于此值,定义字段类型为TEXT,独立出来一张表,用主键来对应,避免影响其它字段索引效率。 9.【强制】表必备三字段:id, gmt_create, gmt_modified。 说明:其中id必为主键,类型为unsigned bigint、单表时自增、步长为1;gmt_create, gmt_modified的类型均为date_time类型。 10.【推荐】表的命名最好是加上"业务名称_表的作用"。 正例:tiger_task / tiger_reader / mpp_config 11.【推荐】库名与应用名称尽量一致。 12.【推荐】如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。 13.【推荐】字段允许适当冗余,以提高性能,但是必须考虑数据同步的情况。冗余字段应遵循: 1)不是频繁修改的字段。 2)不是varchar超长字段,更不能是text字段。 正例:各业务线经常冗余存储商品名称,避免查询时需要调用IC服务获取。 14.【推荐】单表行数超过500万行或者单表容量超过2GB,才推荐进行分库分表。 说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。 15.【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度。 正例:人的年龄用unsigned tinyint(表示范围0-255,人的寿命不会超过255岁);海龟就必须是smallint,但如果是太阳的年龄,就必须是int;如果是所有恒星的年龄都加起来,那么就必须使用bigint |
5、案例分享
5.1、慢查询
开启慢查询日志
|--------------------------------------------------------------------------------------------------------|
| mysqld slow_query_log = 1 slow_query_log_file = /path/to/mysql-slow.log #单位秒 long_query_time = 0.1 |
模拟慢查询
|---------------------------------------------|
| 第一步 批量插入100万条数据 第二步 以未加索引字段nick_name为条件进行查询 |
慢查询日志示例
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Time Id Command Argument # Time: 2024-08-20T04:43:20.250382Z # User@Host: rootroot @ localhost ::1 Id: 2 # Query_time: 0.537167 Lock_time: 0.017117 Rows_sent: 0 Rows_examined: 1000000 use food_db; SET timestamp=1724129000; SELECT * FROM t_student where nick_name = 'aaa' LIMIT 0, 10; |
5.2、死锁
模拟死锁
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 会话1 begin; //排它锁 select * from t_student where id=4 for update; //产生死锁 insert into t_student values(3,'test',18) 会话2 begin; //共享锁 select * from t_student where id<=4 lock in share mode; --等待 提示:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction |
查询死锁情况
select * from information_schema.INNODB_LOCKS;

lock_data是主键记录,lock_page是页序号,lock_rec是记录序号
注: mysql8.0版本后,可使用select * from performance_schema.data_locks
6、参考书籍
《MySQL技术内幕 InnoDB存储引擎 第2版》