前言
首先我们得知道我们为什么要学ShardingSphere-JDBC?
最初(2016年)该项目名为 Sharding-JDBC ,2018 年,项目团队将 Sharding-JDBC 纳入 Apache ShardingSphere (顶级 Apache 项目)生态,成为其核心模块之一。为了统一品牌和架构层次,Sharding-JDBC 更名为 ShardingSphere-JDBC ,同时新增了其他模块(如 ShardingSphere-Proxy、ShardingSphere-Sidecar)。而我们则更喜欢叫他Sharding-JDBC
阿里巴巴Java开发手册:
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,
请不要在创建表时就分库分表。
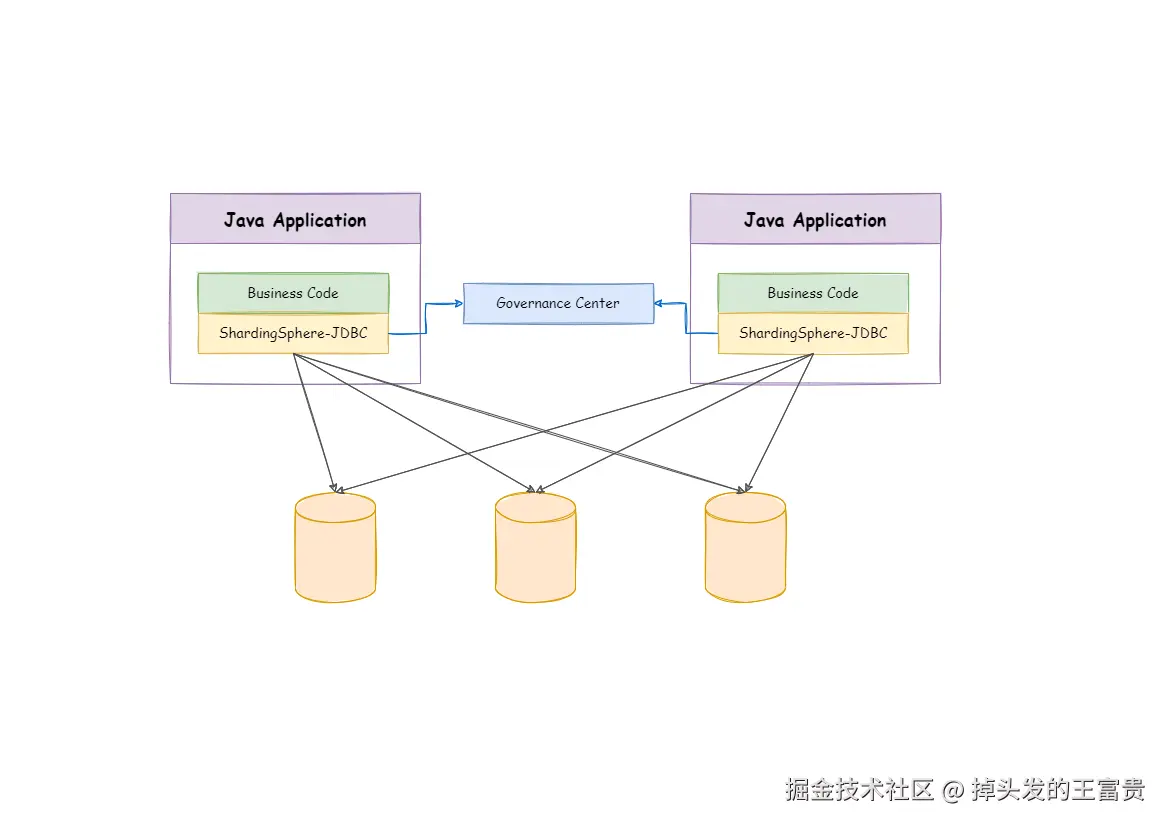
当我们的数据量太大的时候,我们的数据库就要进行分库分表,读写分离等一系列为了给数据库减负的操作,其中我们的市面上大致有两种解决方案: Apache ShardingSphere(程序级别和中间件级别)MyCat(数据库中间件) 。而ShardingSphere-JDBC就是作为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。也就是说我们可以使用Sharding-JDBC作为我们的Java框架来实现分库分表,读写分离这一系列的操作。
而什么是分库分表,读写分离我们就不在这篇文章做解释了,大家可以自行查找资料去了解一下,这篇文章主要是用来介绍和使用Sharding-JDBC这一个应用框架。首先你需要准备这样的一个多数据库环境:
读写分离
如果你环境搭建好了说明就有一个一主二从的mysql服务器集群了,我们现在可以直接来编写springboot程序
第一步,搭建springboot程序
我们的pom文件如下:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.7.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.masiyi</groupId>
<artifactId>ShardingSphere</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ShardingSphere</name>
<description>ShardingSphere</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>第二步,编写实体类
在此之前我们需要准备一张表以及表数据在主库中去执行
sql
CREATE TABLE `t_user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`uname` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC;
INSERT INTO `test-slave`.`t_user` (`id`, `uname`) VALUES (1, 'zhang3');
INSERT INTO `test-slave`.`t_user` (`id`, `uname`) VALUES (2, 'ec49d2f312fb');
INSERT INTO `test-slave`.`t_user` (`id`, `uname`) VALUES (3, '王富贵');根据对应的表结构编写对应的实体类:
java
package com.masiyi.shardingsphere.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@TableName("t_user")
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String uname;
}第三步,编写mapper接口
java
package com.masiyi.shardingsphere.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.masiyi.shardingsphere.entity.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserMapper extends BaseMapper<User> {
}第四步,编写controller类测试
java
package com.masiyi.shardingsphere;
import com.masiyi.shardingsphere.entity.User;
import com.masiyi.shardingsphere.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("selectAll")
public List<User> selectAll() {
List<User> users = userMapper.selectList(null);
return users;
}
}第五步,编写配置文件
编写application.properties文件,这是我们的重头戏了,我们可以看到前面的四步我们都可以看得懂,都很熟悉,和我们平时写web程序加mybatisplus没什么区别,但是我们这个配置类就和平时有些不一样了,而Sharding-JDBC最核心的配置都是在这里面实现的。
模式配置
shardingsphere.apache.org/document/5....
这里一共提供了三个模式配置:
yaml
mode (?): # 不配置则默认内存模式
type: # 运行模式类型。可选配置:Memory、Standalone、Cluster
repository (?): # 久化仓库配置。Memory 类型无需持久化
overwrite: # 是否使用本地配置覆盖持久化配置内存模式,就是存在内存里面的,数据不会持久化,我们学习这个框架用,直接把数据写死在yaml文件中,所以我们只要用这个模式就行了。
单机模式:这个的意思就是我们可以选择单机模式启动,里面的具体源数据我们可以存在本地文件(元数据存储路径 .shardingsphere为后缀的文件),适合我们开发调试的时候用
集群模式:这个就很好理解了,这个需要连接想zookeeper那种注册中心使用。官方也说了,如果我们上生产,必须使用这个模式,那么我们只是学习这个框架,我们只使用内存模式就可以了。
properties
# 内存模式
spring.shardingsphere.mode.type=Memory数据源配置
properties
# 配置真实数据源
spring.shardingsphere.datasource.names=master,slave1,slave2
# 配置第 1 个数据源
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://127.0.0.1:13306/test-slave
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://127.0.0.1:13307/test-slave
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://127.0.0.1:13308/test-slave
spring.shardingsphere.datasource.slave2.username=root
spring.shardingsphere.datasource.slave2.password=123456properties的配置就是这样的,可能看起来很奇怪,甚至有点懵,但是如果把他换成yaml格式的他就是这样的:
yaml
spring:
shardingsphere:
datasource:
master:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:13306/test-slave
username: root
password: 123456
slave1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:13307/test-slave
username: root
password: 123456
slave2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:13308/test-slave
username: root
password: 123456你看这样是不是清楚很多了?所以yaml牛逼!!!
这里我们一共配置了三个数据源,即我们前面配置的一主二从服务器,想我们上面的 master,slave1,slave2叫什么都无所谓,关键是换算成yaml要对的上格式就行,但是如果是properties文件,则需要名字和配置一一对上
那么里面具体的意思引用官方的文档大概就是这样的:
yaml
dataSources: # 数据源配置,可配置多个 <data-source-name>
<data-source-name>: # 数据源名称
dataSourceClassName: # 数据源完整类名
driverClassName: # 数据库驱动类名,以数据库连接池自身配置为准
jdbcUrl: # 数据库 URL 连接,以数据库连接池自身配置为准
username: # 数据库用户名,以数据库连接池自身配置为准
password: # 数据库密码,以数据库连接池自身配置为准
# ... 数据库连接池的其它属性上面就是我们的基础属性了,下面我们开始介绍读写分离专有的配置
读写分离类型
properties
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static分为静态和动态。如 Static、Dynamic
Static:适合固定主从架构,手动指定主库和从库。Dynamic:适合动态主从架构(如服务发现场景)。
读写分离配置
如果上面我们配置了静态,例如就像我们上面搭建教程中的,主从节点的ip和端口都是固定好的,我们则需要这样写:
properties
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=master
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,slave2这里面我们取名的 myds也是可以自己自定义名称。但是如果我们上面写的是Dynamic动态,我们则需要这样写:
properties
type: Dynamic # 动态模式
props:
auto-aware-data-source-name: readwrite_ds_group # 动态数据源组名(需提前注册)ShardingSphere的Dynamic动态读写分离模式通过注册中心(如Nacos/ZooKeeper)管理主从库,也就是说我们不需要把谁是主库,谁是从库这样的配置写死在硬编码上面。允许我们通过 注册中心(如 ZooKeeper、Nacos) 动态管理主从库的节点变化(如从库扩容或主库切换),而无需修改应用配置。auto-aware-data-source-name 指向的是一个 逻辑数据源组,该组的主从信息由注册中心维护。那么具体的里面的内容估计博主还能出一篇文章出来,这里我们知道他大概就是这样概念,有意识就好了。
负载均衡算法
ShardingSphere-JDBC提供了以下几种算法用来控制**读数据库(从库)**的访问机制
轮询算法ROUND_ROBIN:这个很好理解,例如一共两台从库,那么它ShardingSphere-JDBC就会依次每个都访问一次,第一次访问slave1,第二次访问slave2,第三次再访问slave1。。。以此类推。 随机访问算法RANDOM:这个随机二字更好理解了,随机选择从库。 权重访问算法WEIGHT:按权重分配(如 slave2 的权重是 slave1 的 2 倍,承载更多读请求)。
我们可以使用这样的properties写法来定义和选择最终的算法:
properties
# 负载均衡算法名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=wfg_round
# 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_round.type=ROUND_ROBIN
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_random.type=RANDOM
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_weight.type=WEIGHT
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_weight.props.slave1=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_weight.props.slave2=2属性配置
更多的属性配置可以参考这里:官方文档-属性配置
例如我们要打印sql,则可以写成这样:
properties
# 打印SQl
spring.shardingsphere.props.sql-show=true完整示例
那么上面我们基础的配置讲完了之后,我们可以看一下最终的properties文件是这样的:
properties
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=master,slave1,slave2
# 配置第 1 个数据源
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://127.0.0.1:13306/test-slave
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://127.0.0.1:13307/test-slave
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://127.0.0.1:13308/test-slave
spring.shardingsphere.datasource.slave2.username=root
spring.shardingsphere.datasource.slave2.password=123456
# 读写分离类型,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=master
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,slave2
# 负载均衡算法名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=wfg_round
# 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_round.type=ROUND_ROBIN
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_random.type=RANDOM
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_weight.type=WEIGHT
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_weight.props.slave1=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.wfg_weight.props.slave2=2
# 打印SQl
spring.shardingsphere.props.sql-show=true第六步,测试效果
我们启动项目调用controller接口测试一下效果,现在我们的从数据库(slave1)里面是一个这样的数据:
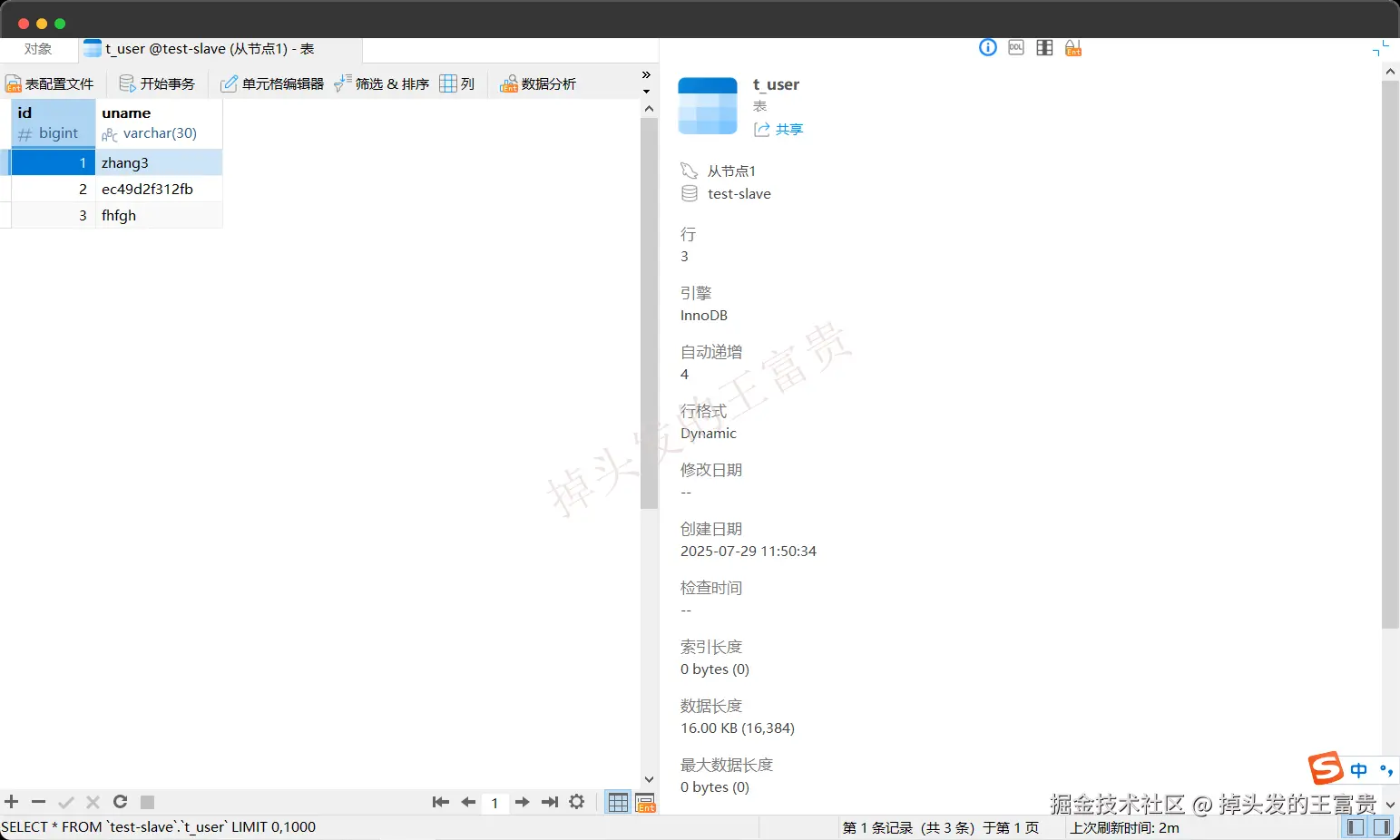
我们的配置文件里面的内容就是上面完整示例中的配置,现在我们调用接口看一下效果:
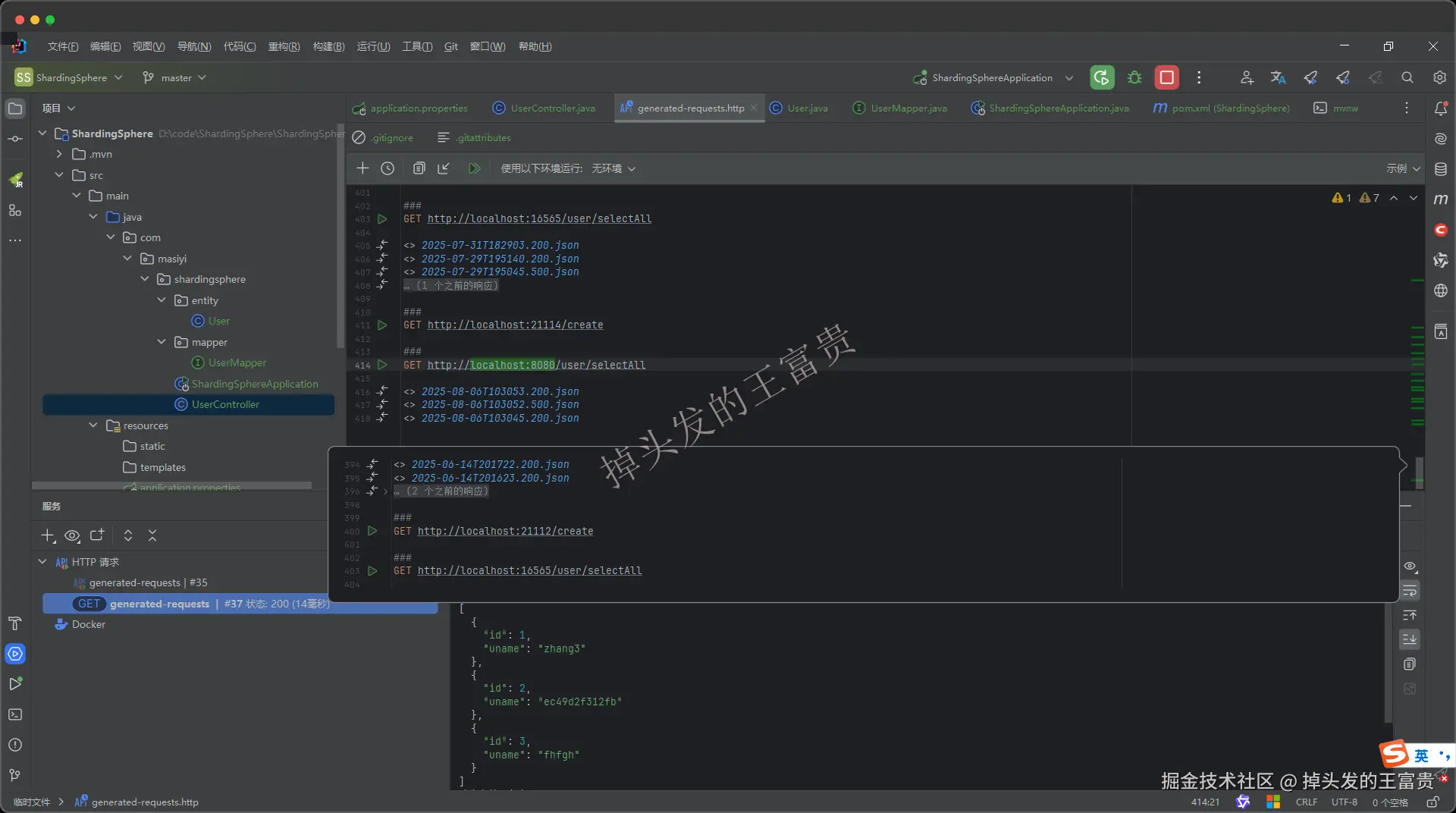
可以看到,完美显示从库的数据,那么我们再写一个插入接口写一个数据来看看:
java
@GetMapping("insert")
public void insert() {
User entity = new User();
entity.setUname("masiyi");
userMapper.insert(entity);
}调用之后可以看到我们的主节点是有把 masiyi这条数据写进去的:
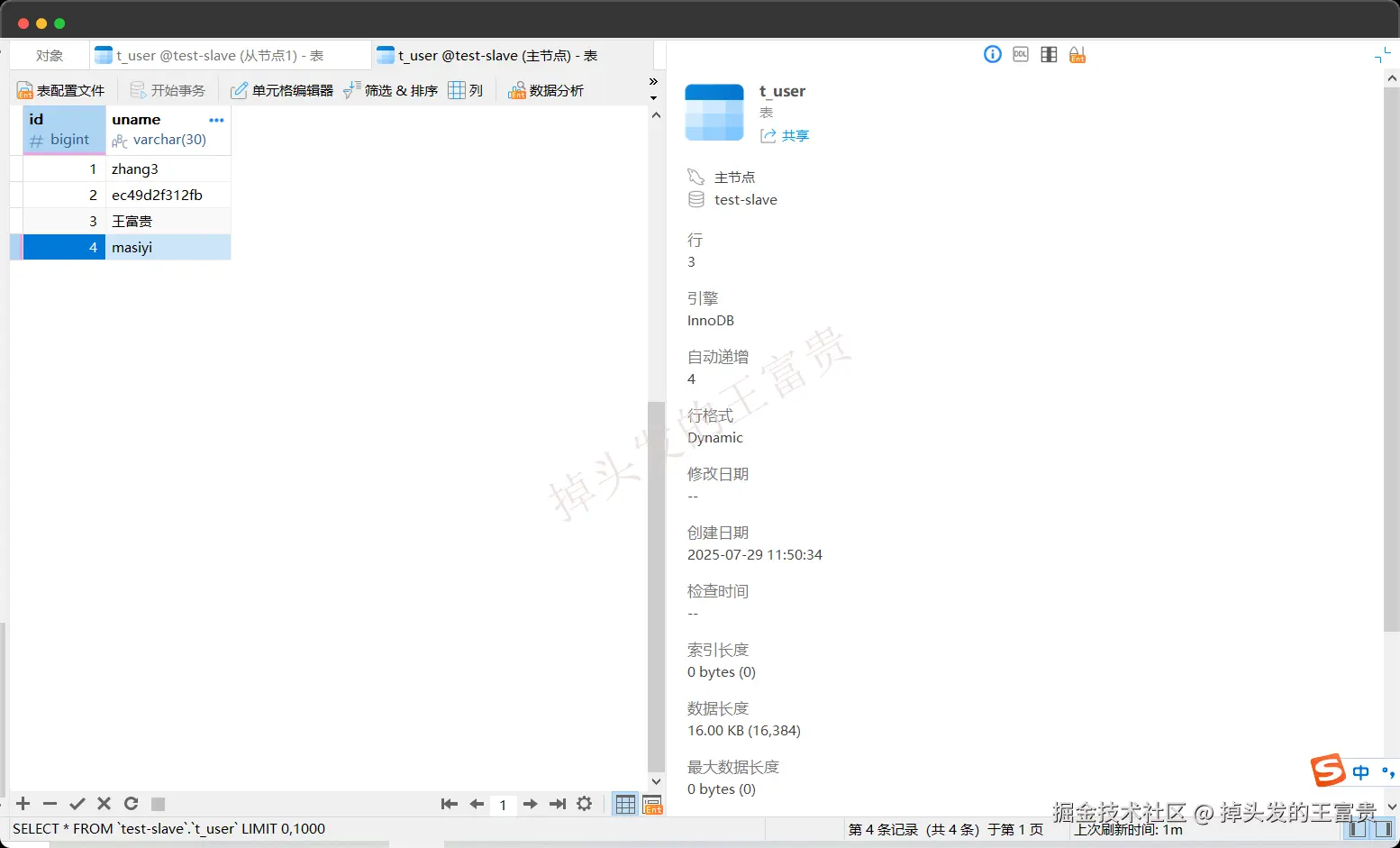
至此我们的通过ShardingSphere-JDBC实现数据库的读写分离入门就做完了。
垂直分片
我们这里简单讲一下垂直分片,它主要分为垂直分库 和垂直分表,例如我们有一个查询,这个原来我们是这样设计数据库的:把用户和订单全部存在一张表里面(虽然现在不会这样设计),我们原来是这样查询的:

而垂直分表是将用户和订单的表分离出来

而垂直分库则是把用户表存在用户库中,订单表存在订单库中

而咱们目前就将弄一个垂直分表加垂直分库的案例来实践
第一步,搭建数据库环境
这里我们使用docker来快速搭建,如果你不会用docker搭建,可以直接弄两个不同的数据库也是可以的,不管是数据库存在一个ip和两个不同的ip里面各有一个数据库都是可以的。
创建user容器
javascript
docker run -d -p 13306:3306 -v C:\docker\mysql\user\conf:/etc/mysql/conf.d -v C:\docker\mysql\user\data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 --name user mysql:8.0.29
bash
#进入容器:
docker exec -it user env LANG=C.UTF-8 /bin/bash
#进入容器内的mysql命令行
mysql -uroot -p123456
#修改默认密码插件
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';创建order容器
javascript
docker run -d -p 13307:3306 -v C:\docker\mysql\order\conf:/etc/mysql/conf.d -v C:\docker\mysql\order\data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 --name order mysql:8.0.29
bash
#进入容器:
docker exec -it order env LANG=C.UTF-8 /bin/bash
#进入容器内的mysql命令行
mysql -uroot -p123456
#修改默认密码插件
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';第二步,创建数据库
user库user表
sql
CREATE DATABASE d_user;
USE d_user;
CREATE TABLE `t_user` (
`f_id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`f_uname` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '名字',
PRIMARY KEY (`f_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;order库order表
sql
CREATE DATABASE d_order;
USE d_order;
CREATE TABLE `t_order` (
`f_id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`f_order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '订单号',
`f_user_id` bigint DEFAULT NULL COMMENT '用户id',
`f_amount` decimal(10,2) DEFAULT NULL COMMENT '数量',
PRIMARY KEY (`f_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;第三步,编写实体类
java
package com.masiyi.shardingsphere.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.math.BigDecimal;
/**
*
* @TableName t_order
*/
@TableName(value ="t_order")
@Data
public class Order {
/**
* 主键
*/
@TableId(value = "f_id", type = IdType.AUTO)
private Long id;
/**
* 订单号
*/
@TableField(value = "f_order_no")
private String orderNo;
/**
* 用户id
*/
@TableField(value = "f_user_id")
private Long userId;
/**
* 数量
*/
@TableField(value = "f_amount")
private BigDecimal amount;
}
java
package com.masiyi.shardingsphere.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
*
* @TableName t_user
*/
@TableName(value ="t_user")
@Data
public class User {
/**
* 主键
*/
@TableId(value = "f_id", type = IdType.AUTO)
private Long id;
/**
* 名字
*/
@TableField(value = "f_uname")
private String uname;
}对应数据库里面的表,这个就不用我多说了吧,其他的东西都是和上面读写分离里面是一样的,无非我们多加几个接口测试。
第四步,编写接口
java
package com.masiyi.shardingsphere;
import com.masiyi.shardingsphere.entity.Order;
import com.masiyi.shardingsphere.entity.User;
import com.masiyi.shardingsphere.mapper.OrderMapper;
import com.masiyi.shardingsphere.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.math.BigDecimal;
import java.util.List;
@RestController
@RequestMapping
public class UserController {
@Autowired
private UserMapper userMapper;
@Autowired
private OrderMapper orderMapper;
@PostMapping("insert")
public void testInsertOrderAndUser(){
User user = new User();
user.setUname("掉头发的王富贵");
userMapper.insert(user);
Order order = new Order();
order.setOrderNo("20260953123454");
order.setUserId(user.getId());
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
@GetMapping("selectAll")
public void selectAll() {
User user = userMapper.selectById(1L);
System.out.println("==================user===============");
System.out.println(user);
Order order = orderMapper.selectById(1L);
System.out.println("==================order===============");
System.out.println(order);
}
}这里我们先插入了一条数据,再查询。
第五步,编写配置文件
数据源配置
和上面的编写配置文件一样,这一步垂直分片主要是在配置文件控制的,我们先来看看和我们上面一样的配置数据源步骤:
properties
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order
# 配置第 1 个数据源
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://localhost:13306/d_user
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.order.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order.jdbc-url=jdbc:mysql://localhost:13307/d_order
spring.shardingsphere.datasource.order.username=root
spring.shardingsphere.datasource.order.password=123456分片表配置
接下来告诉 Sharding-JDBC哪个表对应的是哪个库里面的那个表,这里面写得很详细了,例如告诉它如果对t_user表操作则去user数据库里面去找一个名叫t_user的表,另一个亦然。
properties
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order.t_order属性配置
更多的属性配置可以参考这里
完整示例
properties
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order
# 配置第 1 个数据源
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://localhost:13306/d_user
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.order.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order.jdbc-url=jdbc:mysql://localhost:13307/d_order
spring.shardingsphere.datasource.order.username=root
spring.shardingsphere.datasource.order.password=123456
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order.t_order
# 打印SQL
spring.shardingsphere.props.sql-show=true第六步,测试效果
我们启动项目调用controller接口测试一下效果
当我们执行 insert接口之后,我们可以看到我们的user和order数据库都有数据插入了:

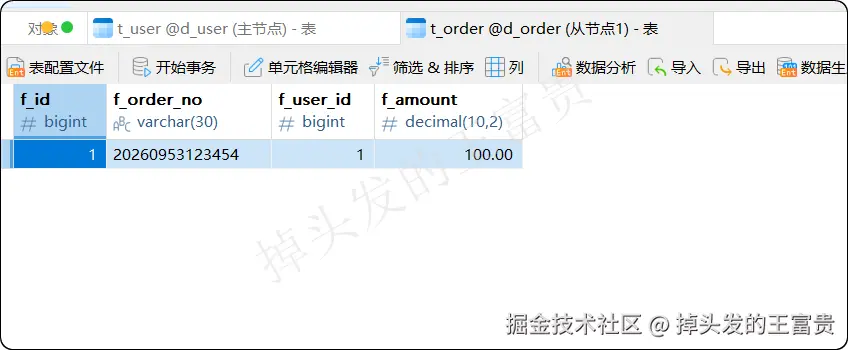
调用 selectAll接口也会发现,成功从数据库中查出数据:
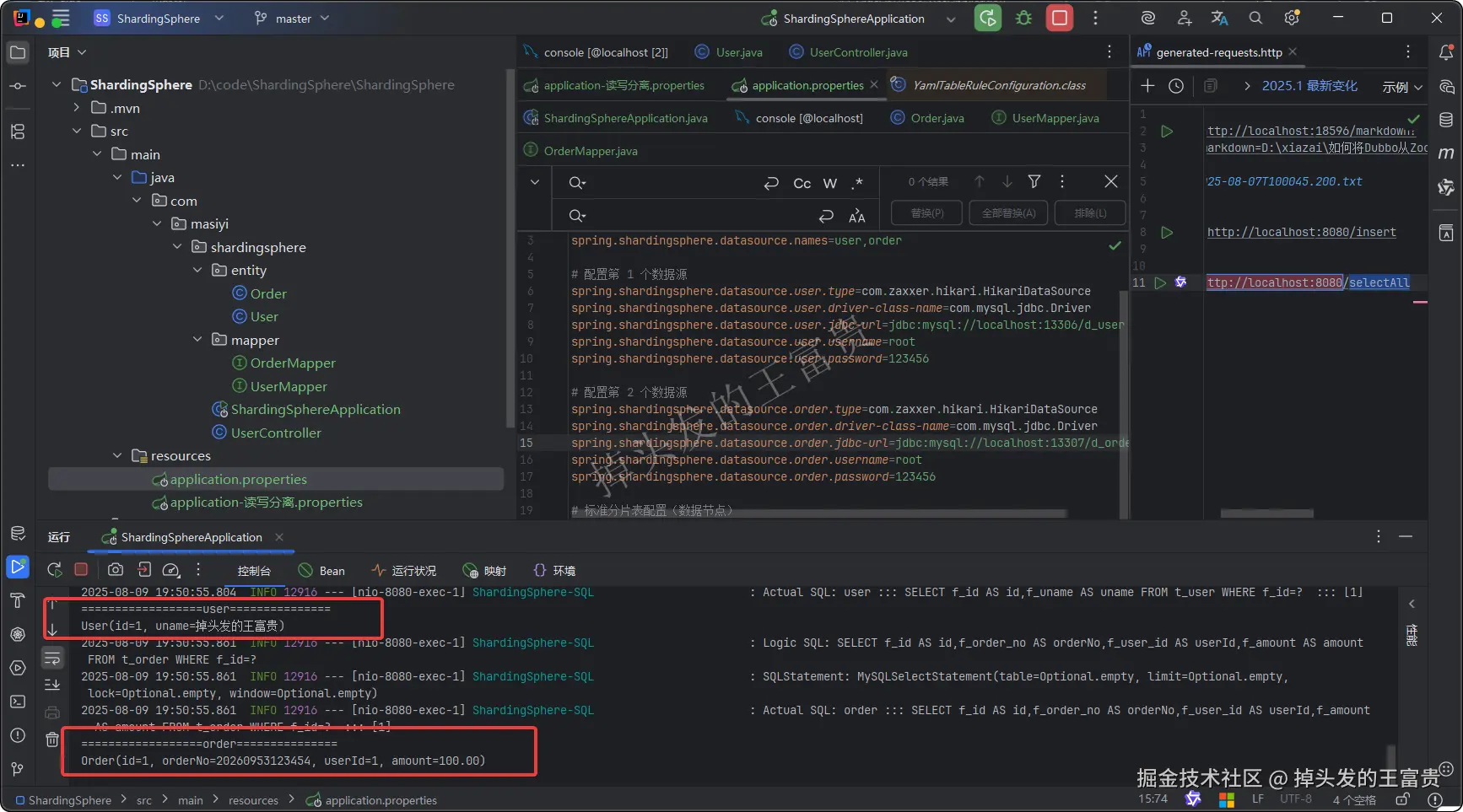
至此我们的通过ShardingSphere-JDBC实现数据库的垂直分片入门就做完了。
由于篇幅原因,这里ShardingSphere-JDBC这篇我们入门就暂时入门到这,这是上一期文章,还会有下一期文章,我们会来讲一下如何使用这个框架来配置水平分片,表关联查询以及其他特性的入门。感谢大家观看到这里!!
