RestoreFormer++: Towards Real-World Blind Face Restoration from Undegraded Key-Value Pairs(IEEE,2023,8)
动机:认为之前的模型都只关注了图像的纹理信息,而忽视了人脸的细节信息,本文采用多尺度、交叉注意力的方式引入模型的语义信息.
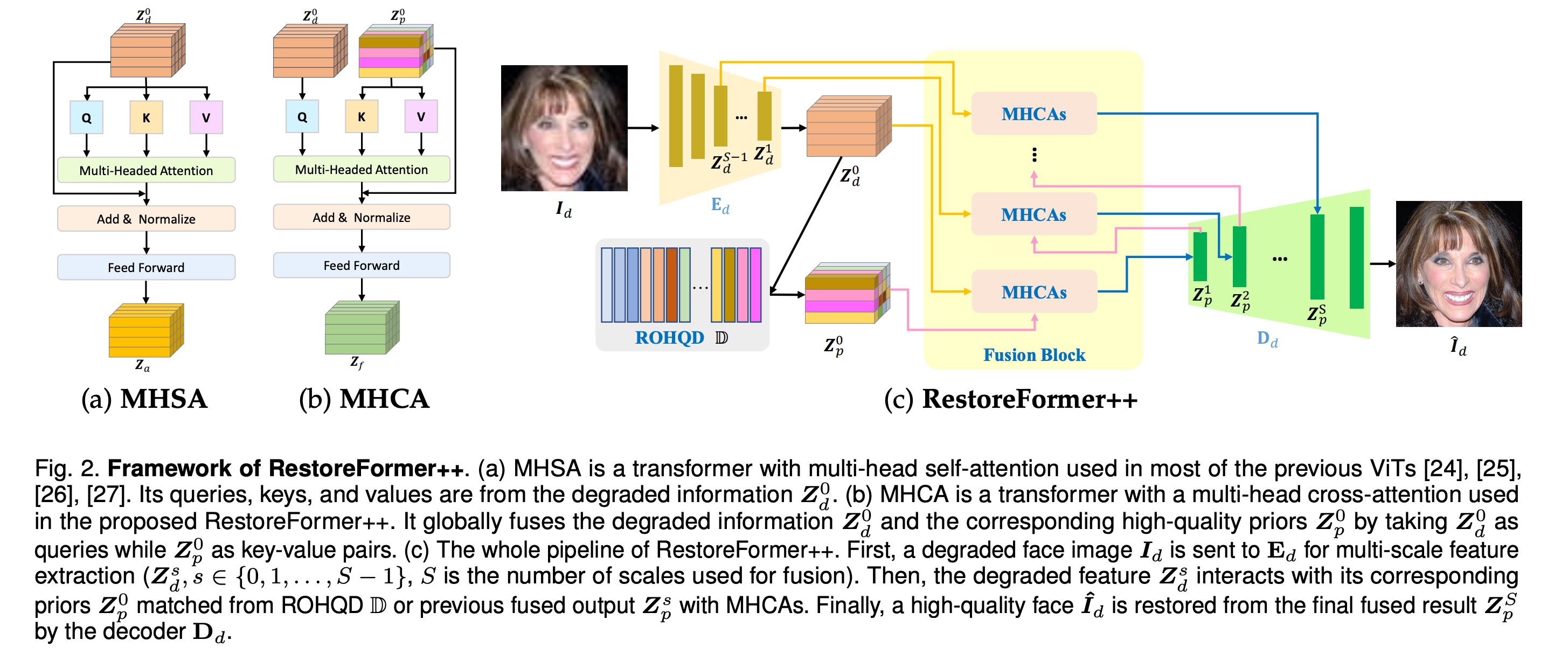
总体可以分为两大部分:
- Encoder和Decoder部分,Encoder和Decoder部分整体类似于transformer,只不过QKV并不是采用的Linear,而是Conv2D来进行映射的
-
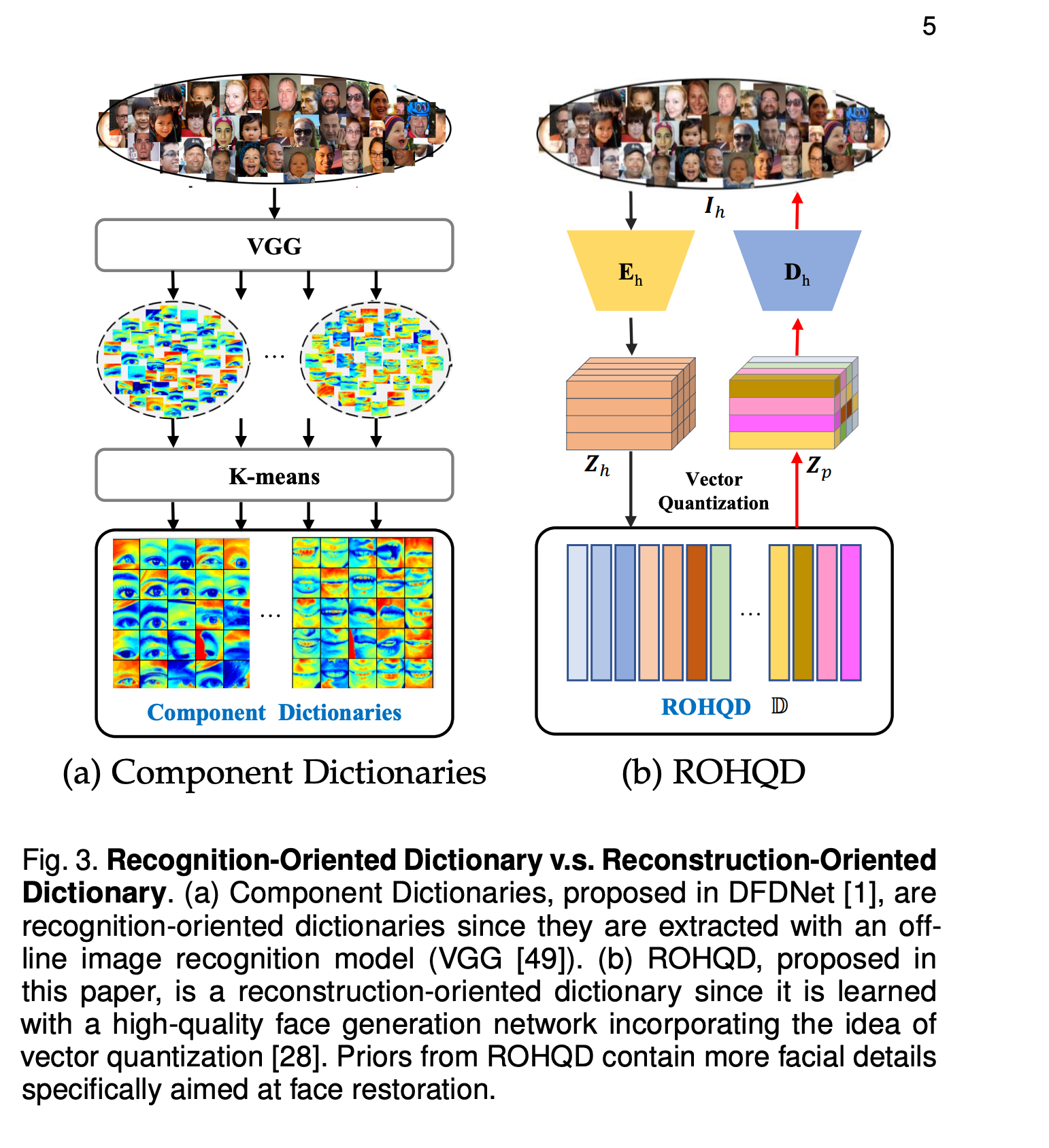
VQVAE部分.VQVAE在Encoder和Decoder中间的潜空间进行的,并且VQVAE的输出作为Decoder的Q来进行Cross Attention,作者认为之间构建的Facial Component Dictionary并没有包含足够的语义信息,通过VQVAE进行编码的ROHQD能够包含更多的细节信息.
-
EDM,Extending Degraded Model,为了构建和真实世界类似的模糊的数据集,必须要使用一个模型模拟真实世界图像的退化过程.本文这个EDM缝合和高斯噪声、雾化等过程.
另吐槽:本文用了大量的辅助loss函数,似乎为了增强指标,具体有perceptual loss、discriminator loss、identity loss,并且判别损失不仅用在图像,也用在了对人脸关键部位的判别上.
TODO:之后在做超分的任务时可以关注一下这个EDM构造数据集的做法.