不靠囤算力,拿下数家大模型明星公司订单。
93 年创始人掌舵的清华系计算创业公司,有点出其不意。
2023 上半年,百模大战开启,模型预训练需求空前爆发,在算力焦虑下,囤积算力成为一种趋同性动作,更充裕的算力几乎就等于金额更高的订单。
10 亿、甚至 50 亿,诱惑非常大。
站在暴风眼最核心,创始人闫博文没有这么做。从技术角度出发,他知道未来算力一定会有闲置,疯狂囤算力对于一家技术公司而言似乎也不够 make sense。
而且从结果看,这也不影响他拿大单。百度、Kimi 以及视频生成赛道顶尖玩家生数科技等,都选择与他们合作。
So,why?
3 次获得戈登 · 贝尔奖
是石科技创立于 2021 年,团队从国家超级计算无锡中心孵化而来,是国内最早将超算智算并行优化的技术进行产业化的团队之一。
创始人兼董事长闫博文,出生于 1993 年,毕业于清华大学,是清华计算机系博士后。主要研究方向包括计算机应用技术、高性能计算、并行优化等。
博士期间,闫博文参与了国家超级计算无锡中心项目,主要实现将 CFD 整体算法移植到国产超算 "神威 · 太湖之光" 上。
"神威 · 太湖之光",在超算领域这个名字绝不陌生,它是世界上首台峰值运算性能超过每秒 10 亿亿次浮点运算能力的超级计算机,在 2016 年 - 2017 年连续两年位居全球 TOP500 超算榜首。

△ 国家超级计算无锡中心盐城分中心
它最大的特点是完全使用国产芯片(申威 26010)构建,高度异构、并行度极高(>10,000,000 核心线程)。由于不同于 x86、ARM、CUDA 等国际主流计算生态,意味着多数软件算法都要重写或者重构。
闫博文主要参与的项目,就是广泛应用于工业仿真、航空航天、气候气象领域的计算流体力学(CFD)算法移植到 "神威 · 太湖之光" 上,需要对算法的底层数据结构、并行任务调度、线程级任务划分、内存访问策略全部做重新设计。

**△**国家超级计算无锡中心
这项工作涉及国产芯片、国产算法、国产应用的全流程打通,验证了国产超算不仅 "快",而且 "好用"。
也是这次经历,让闫博文看到了国产算力软硬件适配的需求强烈,产业界对高性能计算、国产可替代的呼声越来越高,由此成立是石科技。
团队的核心成员大多来自国家超算无锡中心并行优化团队,拥有深厚的高性能计算和并行优化背景,曾 3 次获得全球高性能计算领域最高奖项------"戈登 · 贝尔奖",是国内首个拿下该奖项、也是唯一一个 3 次获得该奖项的团队。
戈登 · 贝尔奖(Gordon Bell Prize)是高性能计算(HPC)领域的国际最高奖项,被誉为高性能计算应用领域的 "诺贝尔奖",由全球最大的计算机学术组织 ACM(国际计算机协会)颁发。
此外,团队也多次获得由中国计算机学会(CCF)颁发的 "中国版戈登 · 贝尔奖"------CCF 年度最佳应用奖。
如此技术积累下,是石科技在 2021 年正式成立。
这时,距离 ChatGPT 诞生不到 2 年。从时间维度看,是石科技似乎是提前抢占风口,在 AI 计算需求爆发前完成了底层计算能力构建。
但在当时,业内对于大模型是否应该继续卷参数规模都还有诸多争议,没什么人能预料到后来 ChatGPT 引爆的趋势,更别提背后的 AI 大规模计算需求,热度远不及当下。
说是石预判了 AI 趋势,确实不合理...... 但如果不是对趋势有预估,为何它能稳稳承接突然爆发的 AI 计算需求,并不断拿大单?
创始人闫博文似乎并不觉得这应该是个问题,因为:
无论大模型爆不爆发,我们都一定会长期从事高性能计算这一行。
不是什么火就做什么,始终从计算维度做判断
如此判断,有来自实际需求、国家战略的影响,当然也有源自技术公司长期主义的思考。
时间回到 2021 年,高性能计算产业本身的风口更早浮现。
国家战略方面,2020 年 "新基建" 被首次写入政府工作报告,算力与 AI 被明确列为重点方向。2021 年《"十四五" 数字经济发展规划》中,算力建设作为数字经济发展的核心基础设施,被明确纳入国家战略。中国高端算力也被列入 "战略资源"。
这个时间节点很像互联网爆发前期。2000 年左右,宽带、服务器、CDN 的基础设施铺好后,才有了新浪、百度、阿里、腾讯的起飞。2021 年的高性能计算,正处于同样的拐点。
更何况产业侧本身的需求也很明显。闫博文提到,当时已经在科研、工业等领域看到了对大规模数值模拟的强烈需求。同时也观察到国内在算力平台建设方面还处于早期,企业缺乏算力供应,也缺乏专业团队维护------供需不平衡的问题亟需解决,需要有专业团队来调节这一问题。
由此,是石科技成立。要做的事就两件:
-
提高计算效率
-
降低计算成本
核心业务是 IaaS 和模型专家模型服务。
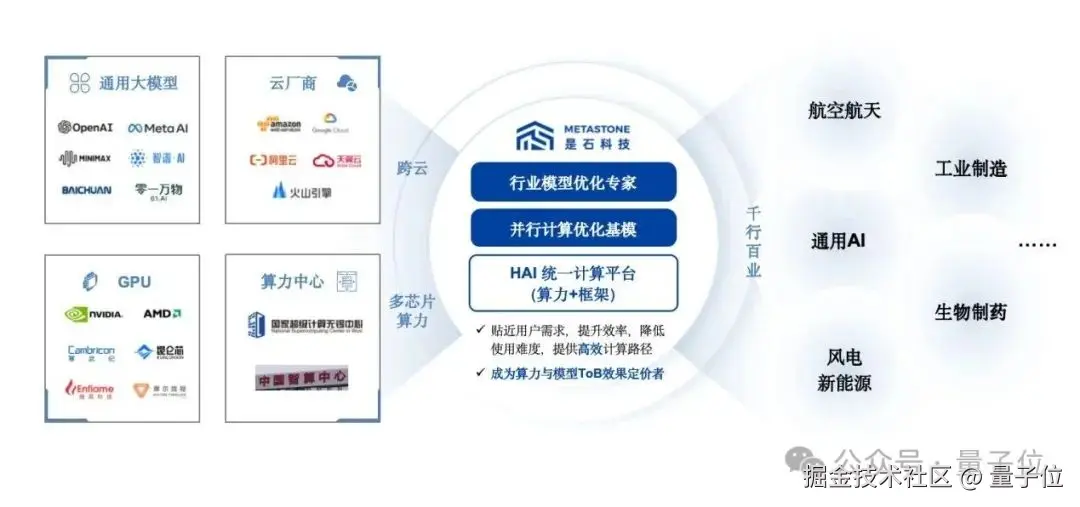
**△**是石科技核心业务
核心技术是并行计算,这其中包括对计算系统中计算、存储、网络等方面的一系列优化,CPU、GPU 异构计算的调配;本质上是通过软硬结合让用户的算法以最适配的方式规模化部署在硬件上。
在创立早期,是石就构建了包括超算和智算在内的底层算力,并向上搭建算力调度平台、Infra 优化框架以及应用服务在内的全栈能力。目前已构建起 HAI 统一计算平台。
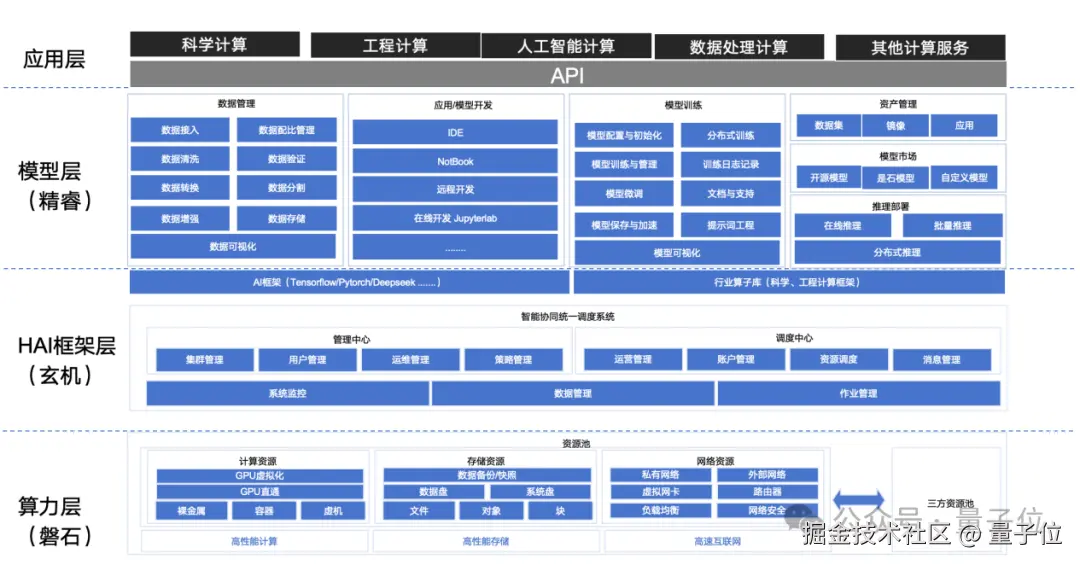
△ 是石科技 HAI 统一计算平台
-
算力层:管理约 10 余个智算中心 和 2 个国家级超算中心 / 训练场 ,总算力规模超过 10000PFlops。其中:盐城超级计算中心获批 "国家新一代人工智能公共算力创新平台";是石科技总部落户浙江平湖市,并建成超智融合计算平台;北京经开区模数世界成立是石科技模型调优工厂。
-
HAI 框架层:提供支持多种型号 CPU 和 GPU 的算力调度、纳管,训练 + 推理的一体化平台,以及 AI 算子库和行业算子库的深度优化库环境。服务超过 20 余个应用领域,200 多项应用课题,200 万个作业任务,HAI 框架经多场景落地验证的部署、调度与优化能力得到众多用户认可。
-
模型层:提供基础模型优化和行业专家模型优化训练推理服务,专家模型覆盖高端制造、生物医药、医疗健康等领域。
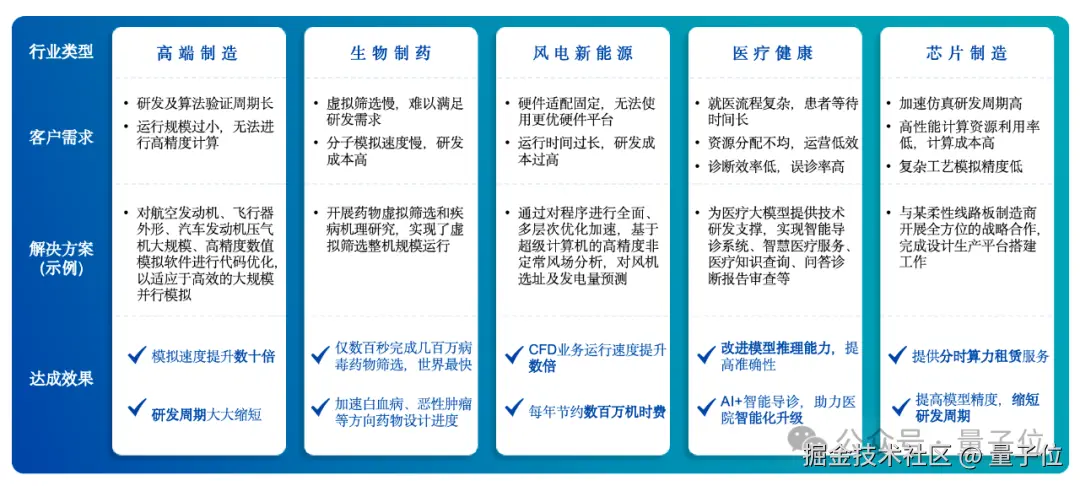
**△**是石科技行业专家模型服务
在此技术栈基础上,大模型趋势爆发,把是石更进一步推向台前。
从 2023 年到现在,AI 计算需求大、而且变化快。无论是基础模型厂商,还是有 AI 模型训推的企业,都需要有更专业的团队为其优化算法与算力配置。
在这之中,是石科技为月之暗面、生数科技、瑞莱智慧、爱诗科技、云道智造等头部企业,以及清华大学、北京大学、香港科技大学等头部高校,均提供了算力及优化服务,且不同领域客户面对的挑战不尽相同。

△是石科技 HAI 平台运行结果
比如视频生成方面,文生视频、图生视频... 不同任务的计算需求不同,在底层算力上也要做好划分,这就更考验对计算本身的理解,使用 CPU、GPU 还是异构计算?不同类型计算配比如何?怎样能尽可能降低通道拥堵?越是细节的问题,就越考验运维团队的功力。
以及视频任务本身就更 "烧卡",对成本考验更大。如何为客户优化算力构成,让同一任务以相同的完成度跑在更低配置的卡上,也是对团队优化能力的考验。
据闫博文透露,是石科技在过去 2 年陪伴多家基础模型公司走完模型训练、推理等阶段,推动其基础模型快速上线、以及对外提供稳定优质服务。
另外在大模型垂直领域研发上,是石科技也为高校科研团队、企业提供底层计算优化服务。是石科技携手深圳大学大数据国家工程实验室、南方科技大学风险分析预测与管控研究院、深圳市渊维科技有限公司发布财务风险预警推理一体机,基于推理大模型与财务专家经验,为投资机构与个人客户提供高效的风险预警解决方案。
目前,是石科技的业务占比中,AI 计算带来的营收占比超过 50%,特点是大单多 。与之对应,科学计算领域的订单则呈现出 "客户多" 的特点,当下也依旧是是石科技业务的主要构成部分。
在闫博文看来,虽然科学计算不是新风口,但是它的算力需求更刚性 、更结构化,比如工业模拟仿真、气象预测等领域。
有时候一个仿真系统的物理时间要求是几秒钟,它背后的模型计算量是数十倍于普通 AI 推理的。
如今随着 AI 大火,科学计算也与 AI 进一步融合。比如在航空航天领域,既需要上千核并行的仿真程序,也需要跑神经网络的 AI 模型。
总之,作为计算优化领域的资深玩家,是石判断做什么、不做什么,更多是从计算本身的需要出发,而不是简单跟随趋势。
但这其实要求自身对行业有深刻理解,要知道这两年算力行业的变化瞬息万变,趋势预估变得更加困难,甚至充满诱惑。
比如开头提到的,闫博文从算力供需平衡的角度出发,认为公司已经没必要囤算力,后续可以依靠调度闲置算力服务客户。但这就意味着,他们不仅要顶住巨大算力焦虑,也要顶住数十家算力中心的前置签约诱惑。
从一个创业公司角度,摆过来一个 10 亿、甚至 50 亿的订单,诱惑力非常大,但它也可能是个糖衣炮弹。
那么闫博文的判断逻辑是什么?
2023 年国家新一代人工智能公共算力平台建成、上千家算力中心或建成或在规划中,这意味着算力紧张只是暂时的,未来一定存在大量闲置算力。如果参与了这场 "囤积算力" 的豪赌,一旦没有把握时机,很可能在供需快速变化中面临亏本。
因为算力的折旧是非常快的,一旦事先囤积、发生空置,就有成本损耗,而且是白白浪费。如果一年之中空置了一个月,相当于这一年都白干了。
如今在 2025 年回看,这种判断正确且理性。虽然摩尔定律开始失效,但是 "老黄定律" 出现,底层芯片的供应并没有预料中如此严峻。同时国产算力再进一步跟上,为市场提供更丰富选择。
当然,这种判断也一定不只依赖于技术认知,还有个人风格影响。
毕竟大模型趋势如火如荼,不是谁都能克制且不焦虑的。
93 年创始人带队,松弛感十足
由 93 年创始人掌舵的是石,整体团队都相当年轻,团队成员中 60% 的 90 后,20% 的 00 后。
年轻的好处,就是不容易内耗! 上亿的订单做不做,一天内即可决策出来。
这种不内耗,在闫博文身上更明显。
技术趋势演进如此快,独角兽林立、入场玩家越来越多,大家都担心自己掉队或者没能乘上时代的东风。
我们问,介意行业出现更多竞争玩家吗?
闫博文:不介意,玩家越多市场越大。
也不焦虑?
闫博文:不焦虑。我们目前就是在有限范围内扩张和投入,不寄希望于投入 10 个亿下去,做个标准化产品出来,然后大家就都用起来了。这事和我们预判到的技术路线相违背。
那是石科技看到的技术趋势是什么?
越优化的东西,通用性越差。
看似悖论,实则道出计算领域长期存在的一个结构性张力:性能 vs 通用性。
比如针对某个任务 / 芯片 / 模型深度定制,如 CUDA kernel 手写、硬件深度绑定、数据布局精调,性能爆炸性提升,但很难迁移到其他任务或平台;如果是 PyTorch 这类通用接口,适配范围广,开发效率高,但牺牲性能、调度、资源利用率。
对于正在爆发的算力领域,也将遵循这一规律,逐渐从通用计算走向场景计算。
闫博文认为,未来的计算中心将不再以地区作为划分依据,而更应该是某个计算中心集中处理某一类计算任务,类似于专攻某一场景。这样能集中做优化,也能进一步提高算力资源利用率。
这种思想在是石的产品中亦有体现,在模型服务划分上,团队也遵循以场景作为分类标准。
而对于行业来说,真正的挑战是:如何在通用与优化之间找到 "高效、可复制、快速定制" 的平衡点。行业距离抵达这样的终点,还有很长的路要走。
换言之,在算力领域,贪图一时的快速扩张可能会违背行业发展规律。选择以慢打快,焦虑自然也不存在。
长远来看,是石科技则希望未来作为用算力赋能各行各业的代表,也能打出类似 "Made in China" 的影响力------Powered by METASTONE 是石,这是对未来愿景的终极畅想。
回归当下,是石科技要做的就是为客户提供好算力与模型优化服务,进一步提高效率优化成本。
今年,一直沉于水面之下的是石科技开始更多对外亮相。在刚刚落幕的 WAIC 2025 大会上,是石科技团队也做了进一步分享;同时,新的标准化产品即将发布、新一轮融资也正在筹备中,可以说是技术储备的一次大释放。
所以,在 AI 爆发的趋势里,哪有什么 "小荷才露尖尖角",更多都是 "早有蜻蜓立上头"。
你觉得呢?
One More Thing
最后,如果一定要问,当 boss 有什么焦虑点。
闫博文也相当坦诚:
焦虑客户满不满意、担心成员吵不吵架、钱够不够用...
嗯,果然是 90、00 后为主的团队,就是有啥都不掖着!
欢迎在评论区留下你的想法!
--- 完 ---