目录
[Dev Tools操作](#Dev Tools操作)
[使用Kibana Dev Tools测试](#使用Kibana Dev Tools测试)
概述
本文主要介绍如何在Windows10单机节点下安装如下ELK软件、工具及插件:
- elasticsearch-8.15.0
- elasticsearch-head-5.0.0
- kibana-8.15.0
- logstash-8.15.0
- elasticsearch-analysis-ik-8.15.0
ELK简介
ELK 是三个开源软件的缩写,分别是 Elasticsearch、Logstash 和 Kibana。它提供了一个强大的工具集,帮助用户收集、存储、分析和可视化大量的数据。
Elasticsearch
Elasticsearch(简称es) 是一个基于 Lucene 的搜索服务器。它提供了一个分布式、多租户的全文搜索引擎,具有高可扩展性和高可用性。
-
强大的搜索功能:可以快速地对大量数据进行全文搜索,支持复杂的查询语法和过滤器。
-
分布式架构:能够轻松地处理大规模数据,通过将数据分布在多个节点上,实现水平扩展。
-
实时性:可以实时索引和搜索数据,确保数据的及时性。
Logstash
Logstash 是一个数据收集引擎。它可以从各种数据源收集数据,对数据进行过滤和转换,然后将数据发送到目标存储或分析系统。
-
丰富的输入插件:支持从文件、网络协议、数据库等多种数据源收集数据。
-
强大的过滤功能:可以使用各种过滤器对数据进行清洗和转换,例如 grok 过滤器可以解析非结构化数据。
-
灵活的输出插件:可以将处理后的数据发送到 Elasticsearch、文件、数据库等多种目标。
Kibana
Kibana 是一个数据分析和可视化平台。它与 Elasticsearch 集成,提供了丰富的可视化工具和仪表盘,帮助用户分析和理解数据。
-
可视化工具:支持创建各种图表、地图和表格,直观地展示数据。
-
仪表盘:可以将多个可视化组件组合在一起,形成一个仪表盘,方便用户进行综合分析。
-
探索性分析:用户可以通过 Kibana 进行探索性分析,快速发现数据中的趋势和模式。
安装elasticsearch
下载elasticsearch

下载文件:elasticsearch-8.15.0-windows-x86_64.zip
解压
将elasticsearch解压到合适的目录
配置不用登录及关闭SSL
为了方便学习测试,配置连接不用登录及关闭SSL
修改elasticsearch config目录下的elasticsearch.yml
1.将xpack.security.enabled设置为false。
xpack.security.enabled: false2.将ssl的enabled改为false。
xpack.security.http.ssl:
enabled: false启动elasticsearch
进入elasticsearch安装目录,在bin目录下,双击elasticsearch.bat
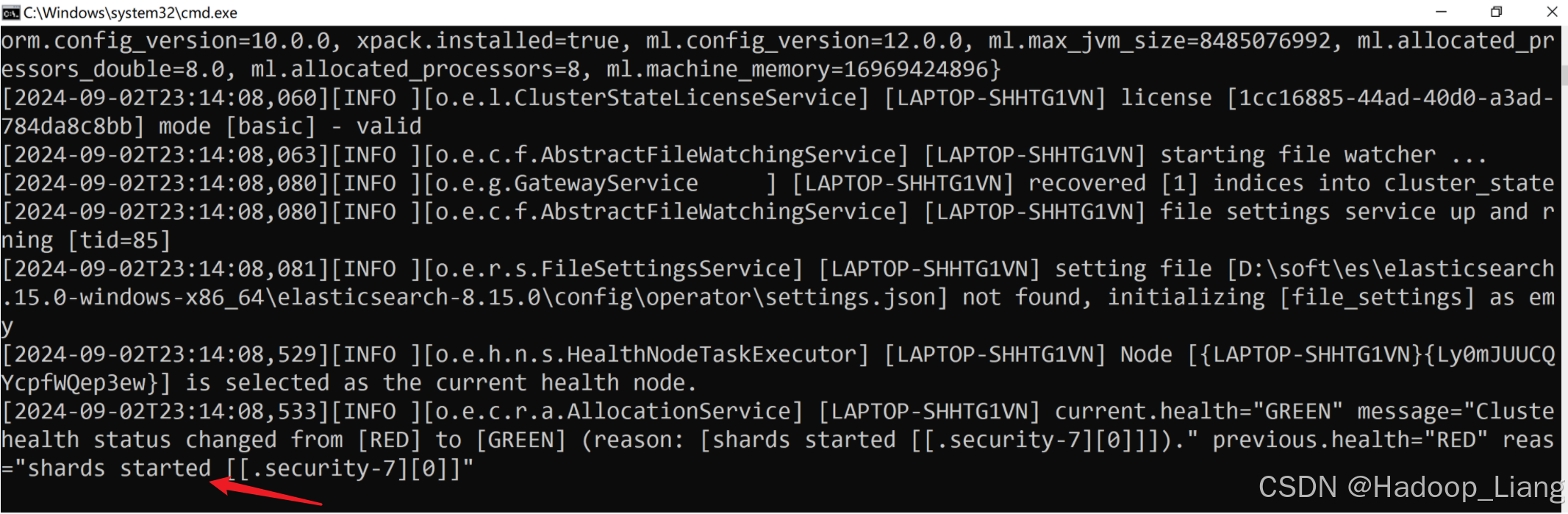
看到日志最后输出shards started,说明启动成功。
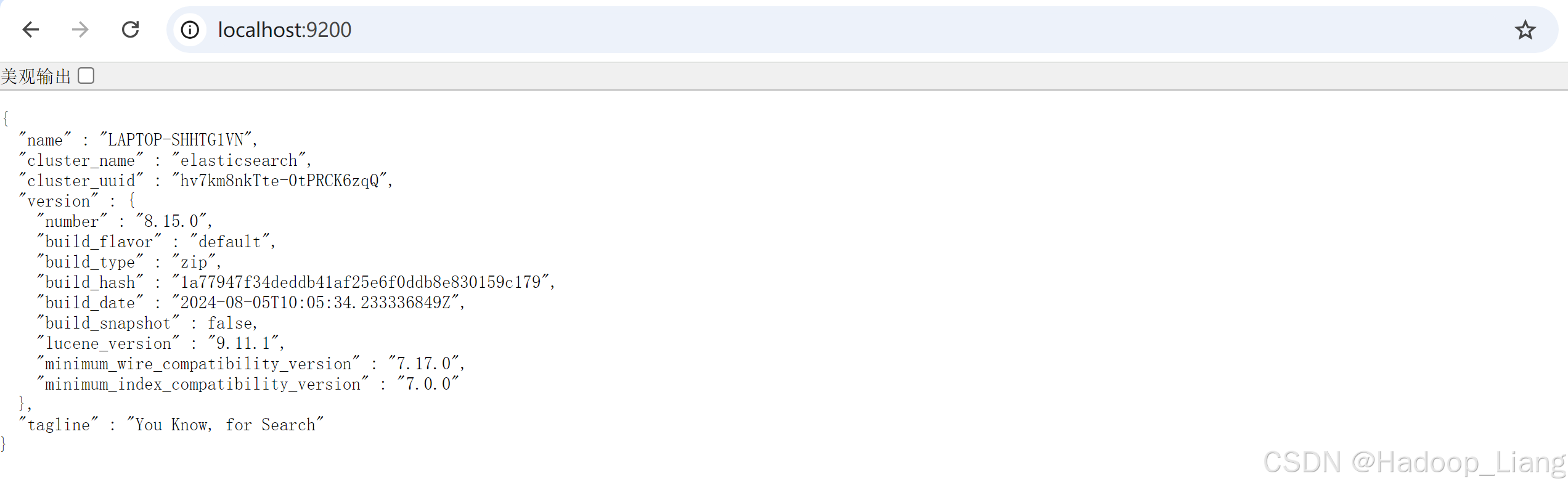
访问elasticsearch
浏览器访问localhost:9200或127.0.0.1:9200,输出界面如下
安装elasticsearch-head
提前准备node.js
安装elasticsearch可视化工具head,需要node.js环境(如果没有,自行安装node.js),cmd执行如下命令验证node.js环境
C:\Users\Administrator>node -v
v14.20.1下载elasticsearch-head
下载文件:elasticsearch-head-5.0.0.zip
解压
解压elasticsearch-head zip包到合适目录
浏览器打开index.html
访问index.html
用浏览器打开解压目录里面的index.html,点击连接,右键-->检查-->切换到Console,看到如下跨域的错误
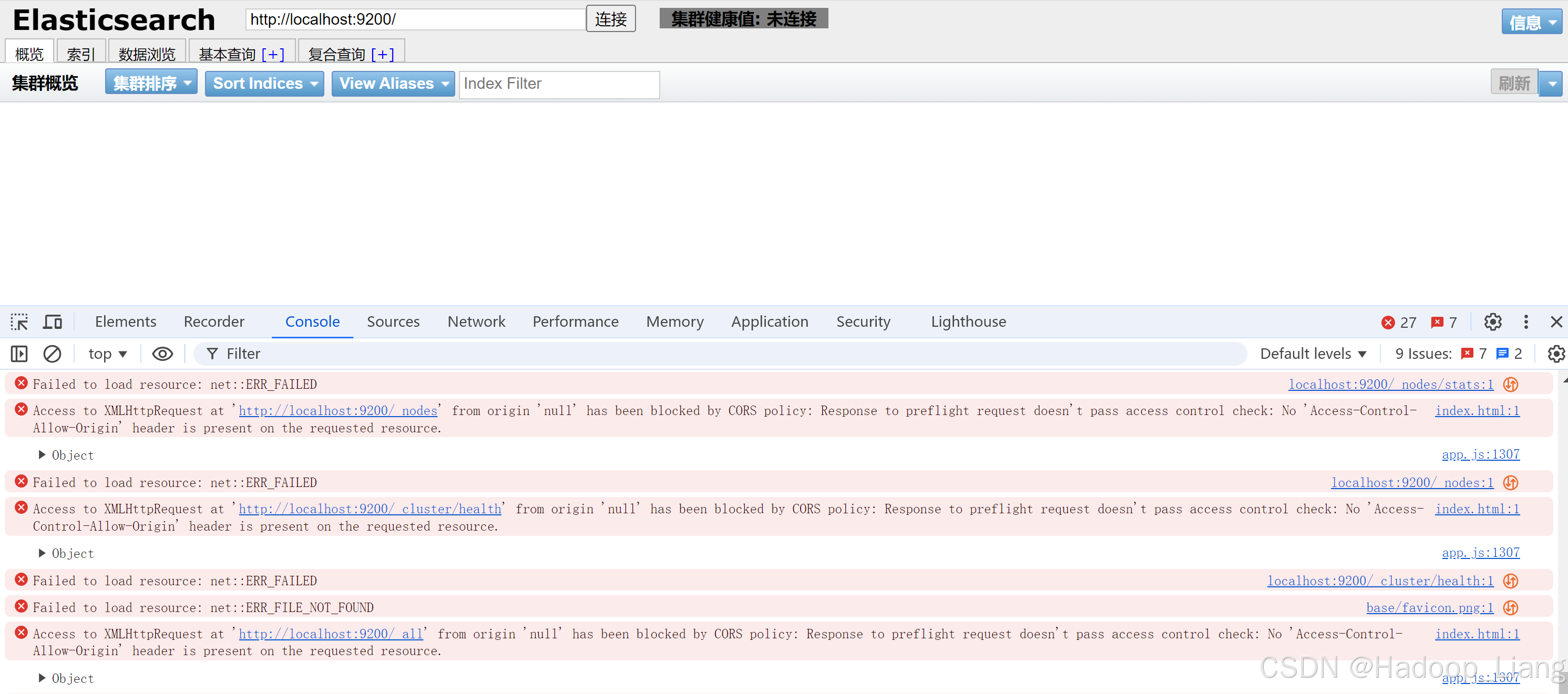
解决跨域问题
解决跨域,修改elasticsearch config目录下的elasticsearch.yml文件,在末尾添加如下配置
http.cors.enabled: true
http.cors.allow-origin: "*"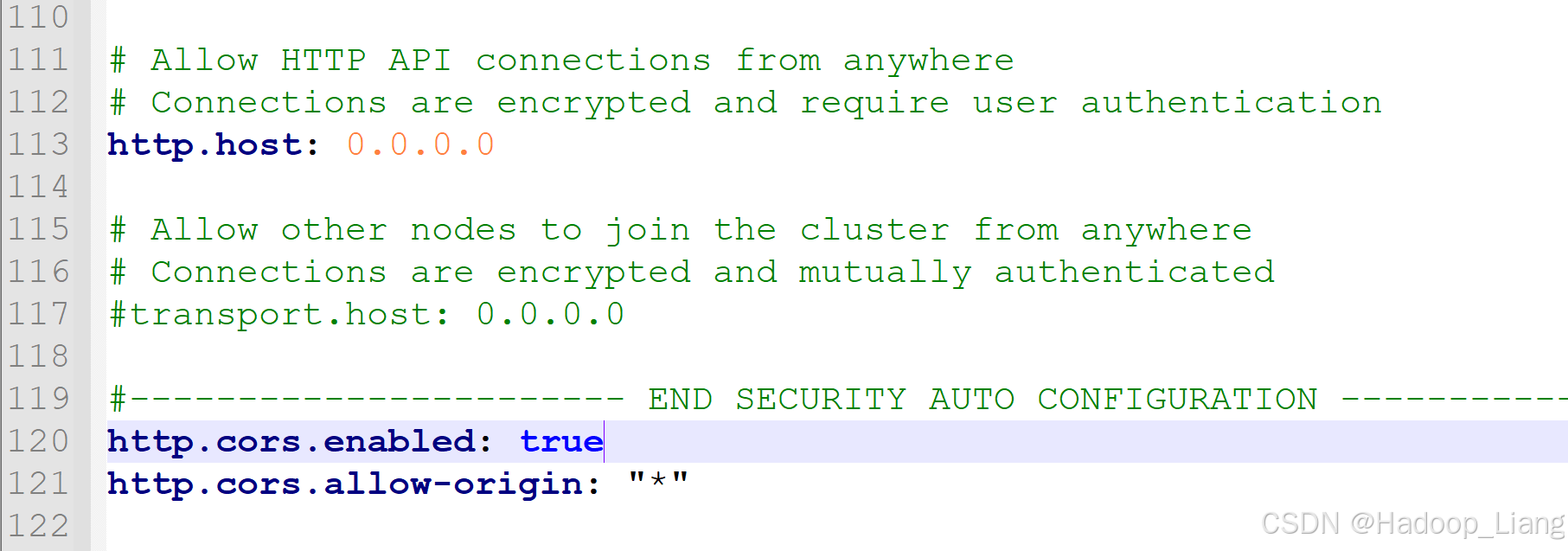
重启es生效
返回es cmd控制台,按Ctrl+c结束es进程,然后重新执行elasticsearch.bat
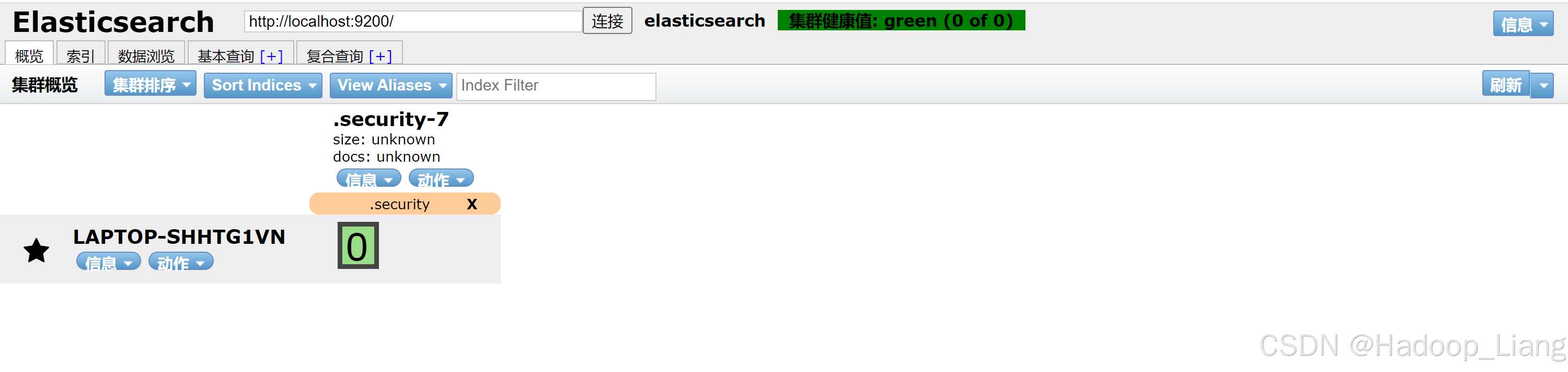
重新访问elasticsearch-head的index.html
刷新elasticsearch-head 的index.html,点击连接,连接成功后看到集群健康值为green,表示已正常连接
安装kibana
下载kibana
下载文件:kibana-8.15.0-windows-x86_64.zip
注意:kibana版本号要与es版本号一致。
解压
解压kibana到合适目录
运行kibana
先启动es,然后进入kibana bin目录,双击运行kibana.bat启动kibana。启动过程较慢需要一定的时间(约几分钟,电脑配置不同等待时间也会有差异)。
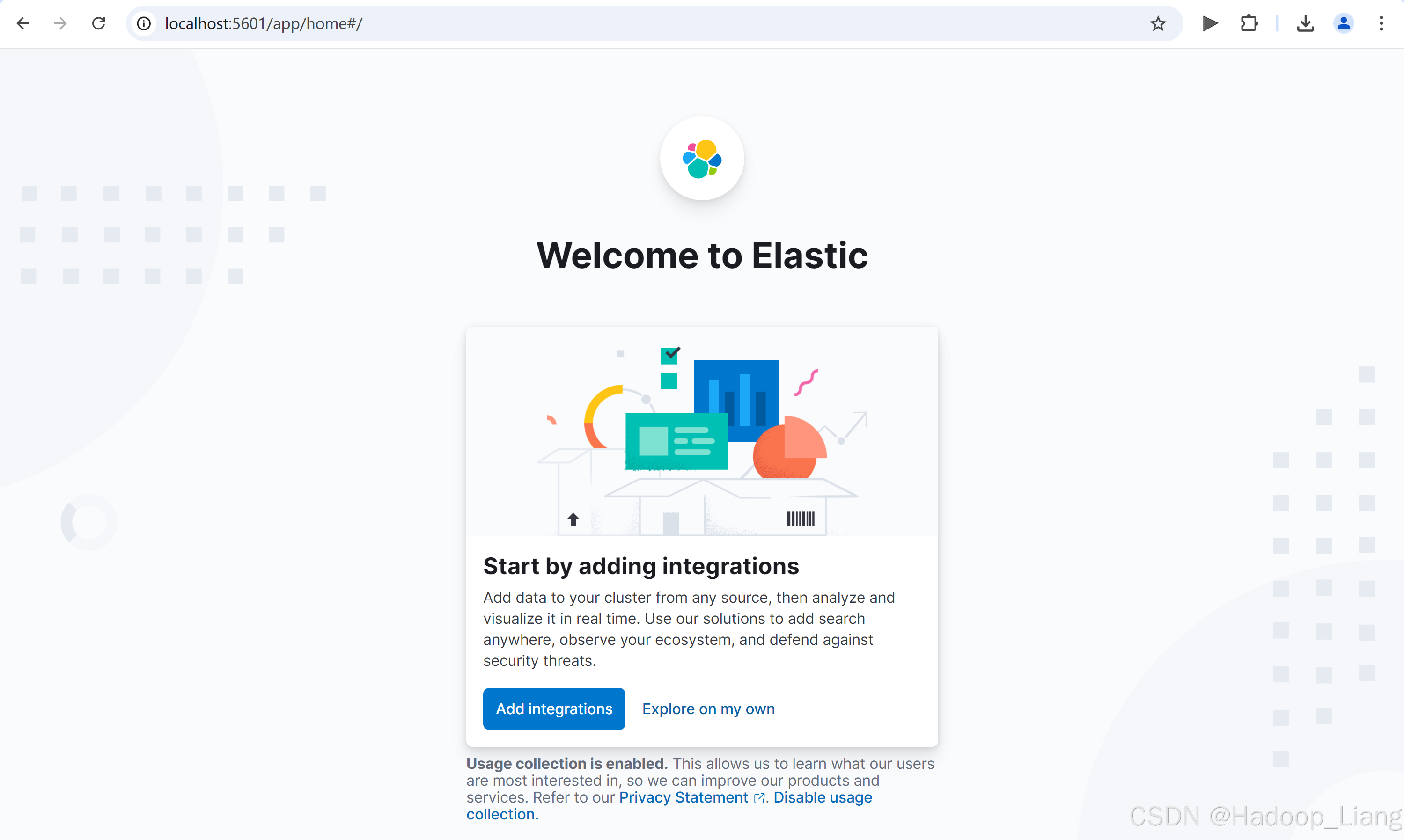
浏览器访问
localhost:5601看到如下界面,点击Add integrations
Dev Tools操作
点击箭头指向的图标
向下滚动左侧导航栏的滚动条,找到Management下的Dev Tools
点击Dev Tools,进入如下界面,点击左边API命令语句的执行按钮,右边显示执行结果。
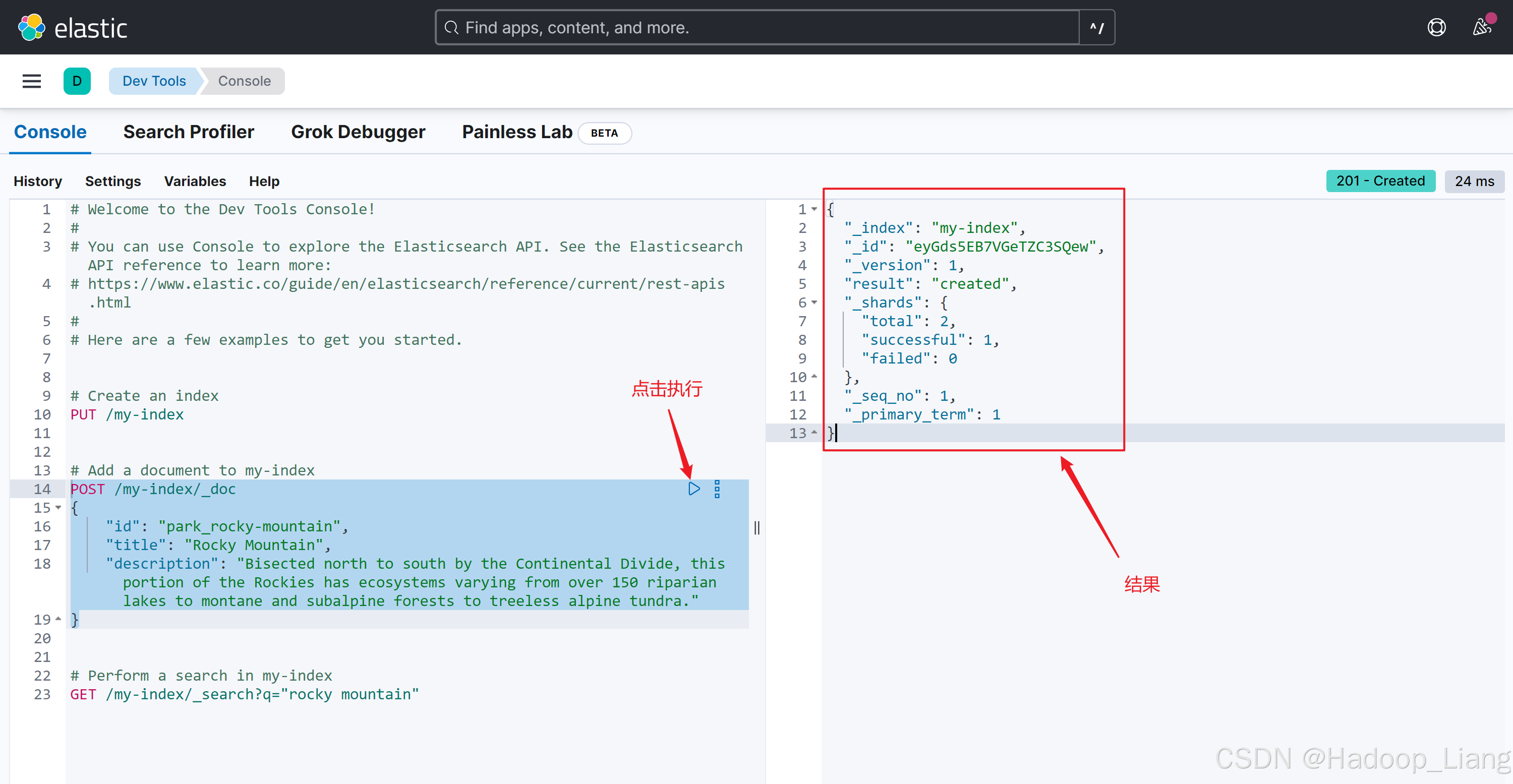
这里演示了通过kibana 发送API命令来操作es。
安装logstash
下载logstash
下载文件:logstash-8.15.0-windows-x86_64.zip
注意:logstash版本号要和es版本号一致
解压
解压logstash到合适目录
编写配置文件
简单测试logstash
在某个目录下编写配置文件,配置文件名例如:test1.conf,配置输入为标准输入,数据进入logstash后可以做相关过滤操作,这里先不做过滤,输出到标准输出。
test1.conf内容如下:
input {
stdin { }
}
output {
stdout { }
}运行logstash
语法
logstash -f path\to\logstash.confcmd进入logstash 安装目录,执行如下命令
D:\soft\es\logstash-8.15.0-windows-x86_64\logstash-8.15.0>bin\logstash -f ..\..\mytest\testconf\test1.conf注意:test1.conf的路径根据实际情况修改。
末尾输出日志如下
...
[2024-09-03T23:00:00,892][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :
non_running_pipelines=>[]}
{
"event" => {
"original" => "\r"
},
"@version" => "1",
"message" => "\r",
"@timestamp" => 2024-09-03T15:00:00.896209500Z,
"host" => {
"hostname" => "LAPTOP-SHHTG1VN"
}
}
{
"event" => {
"original" => "\r"
},
"@version" => "1",
"message" => "\r",
"@timestamp" => 2024-09-03T15:00:00.893219400Z,
"host" => {
"hostname" => "LAPTOP-SHHTG1VN"
}
}控制台输入
hello控制台输出
{
"event" => {
"original" => "hello\r"
},
"@version" => "1",
"message" => "hello\r",
"@timestamp" => 2024-09-03T15:00:23.452791Z,
"host" => {
"hostname" => "LAPTOP-SHHTG1VN"
}
}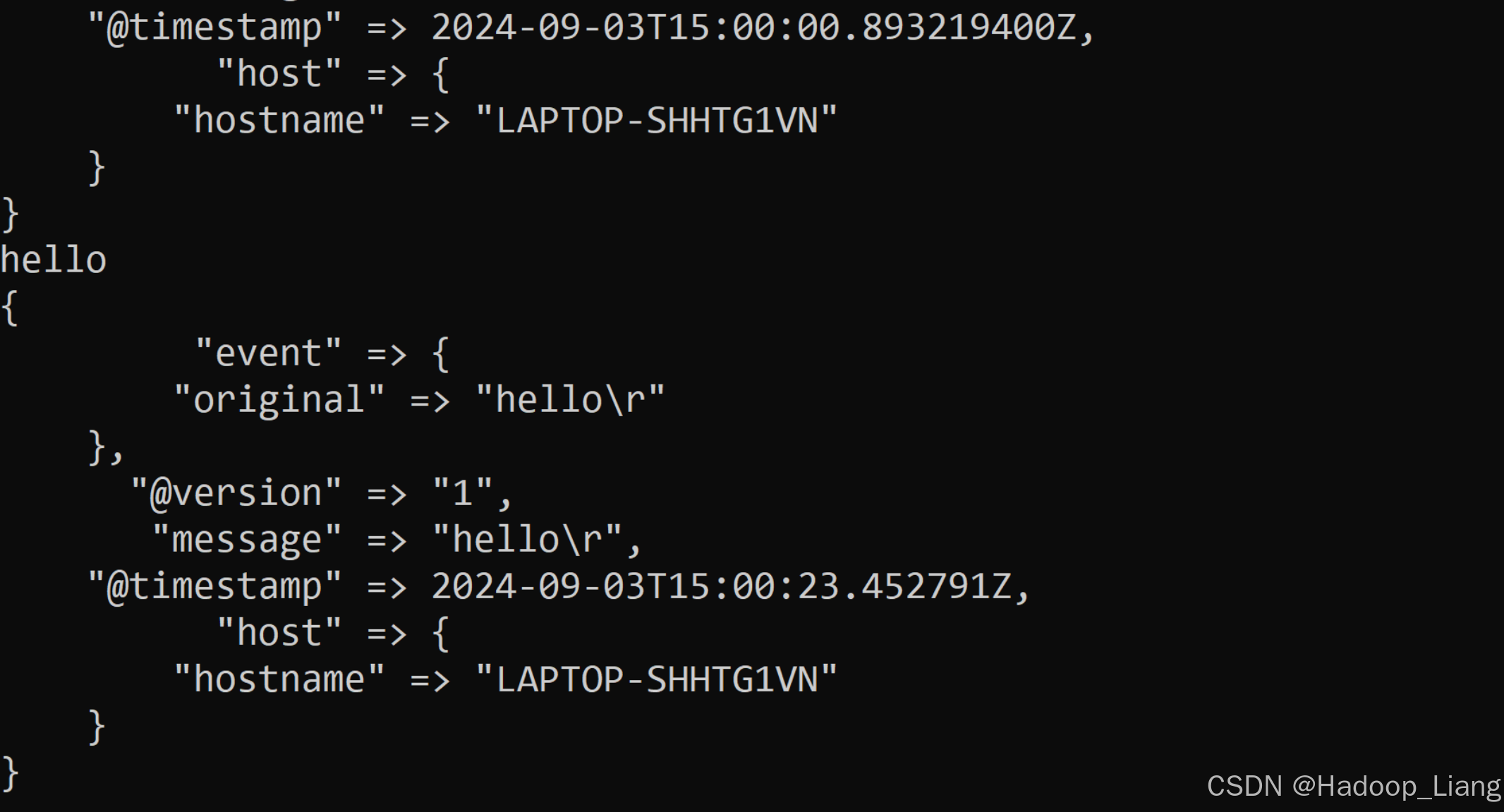
可以自行继续输入测试数据,看看输出情况。
关闭logstash
按ctrl + c退出logstash进程,根据提示输入y确认退出。
安装ik分词器插件
elasticsearch-analysis-ik(简称ik)为中文的分词器
下载elasticsearch-analysis-ik
下载文件:elasticsearch-analysis-ik-8.15.0.zip
注意:ik版本号要和es版本号一致
安装elasticsearch-analysis-ik插件
将下载的elasticsearch-analysis-ik-8.15.0.zip解压到目录复制到es的plugins目录下即完成ik插件的安装

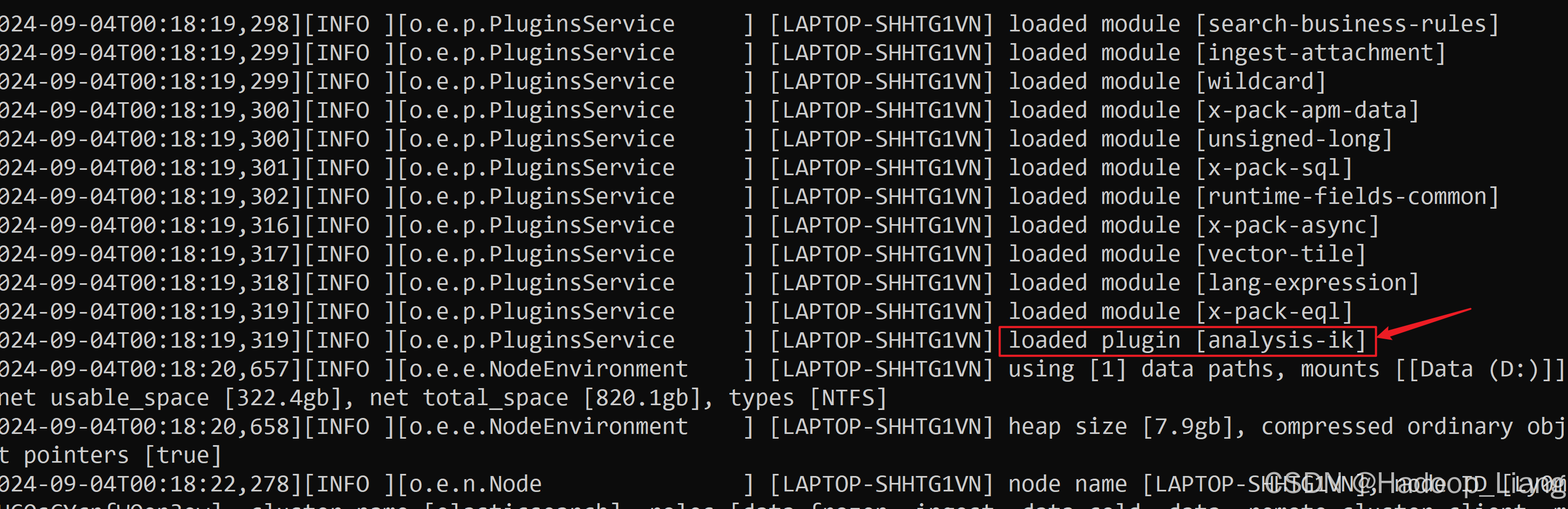
重启es生效
启动日志看到loaded plugin analysis-ik,说明加载了ik分词器
使用Kibana Dev Tools测试
重新启动kibana
浏览器访问
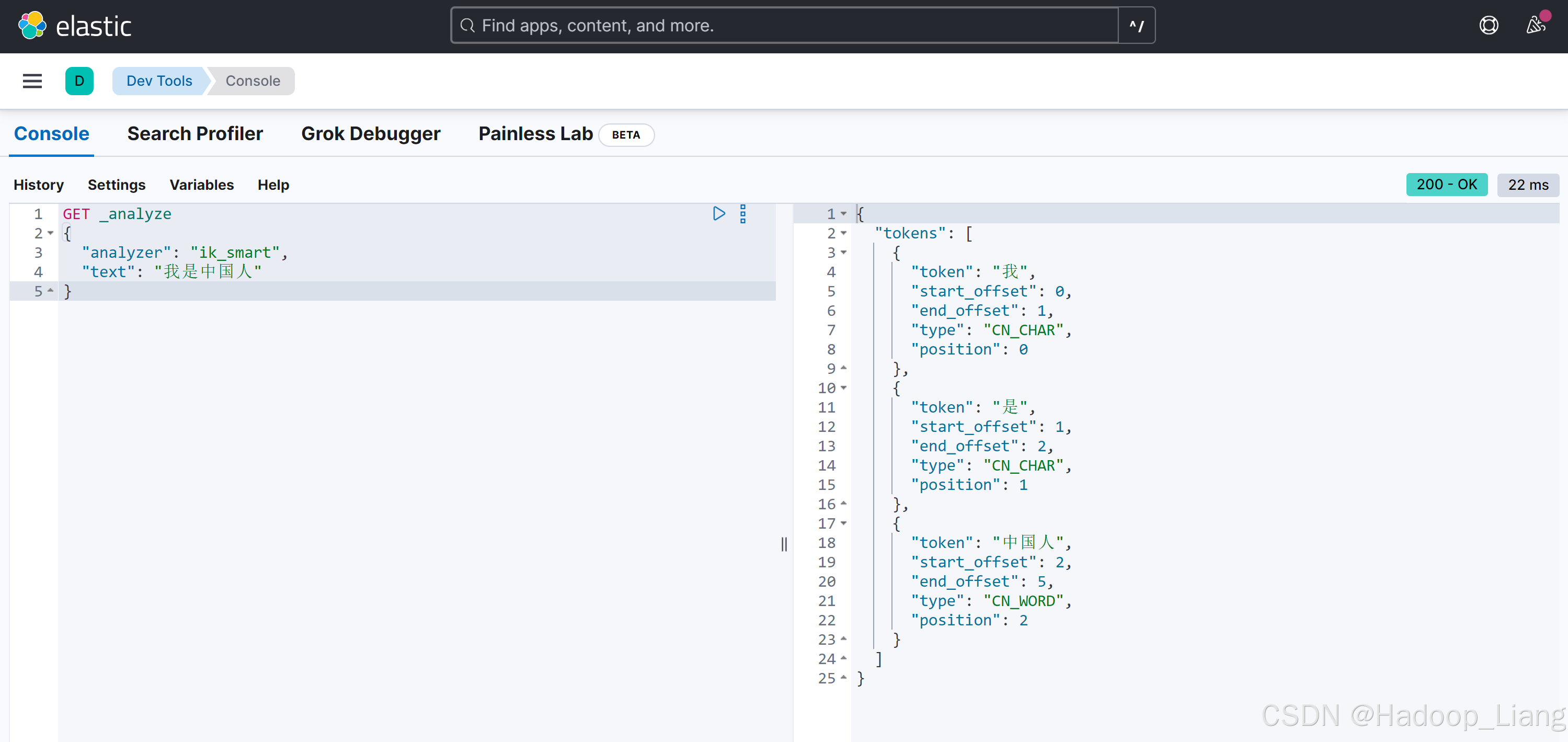
localhost:5601进入Dev Tools界面,删除原有内容,添加并执行如下语句
GET _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}说明:
ik_smart:最少分词
ik_max_word:最多分词
执行结果
执行如下语句
GET _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}执行结果
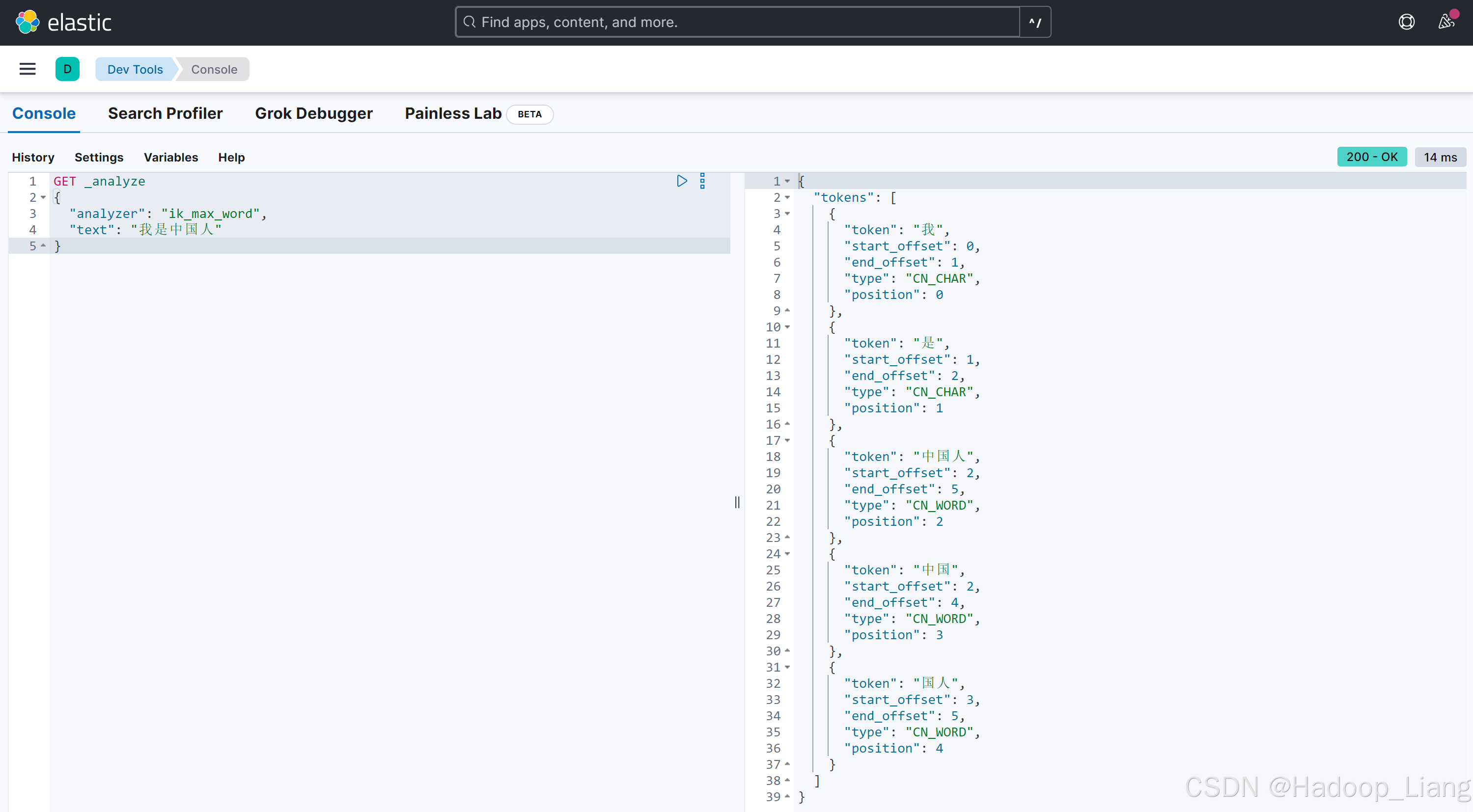
通过对比结果,看到 ik_smart分词少,cik_max_word分词多。
自定义关键字
执行如下语句
GET _analyze
{
"analyzer": "ik_smart",
"text": "吉普森吉他"
}结果如下
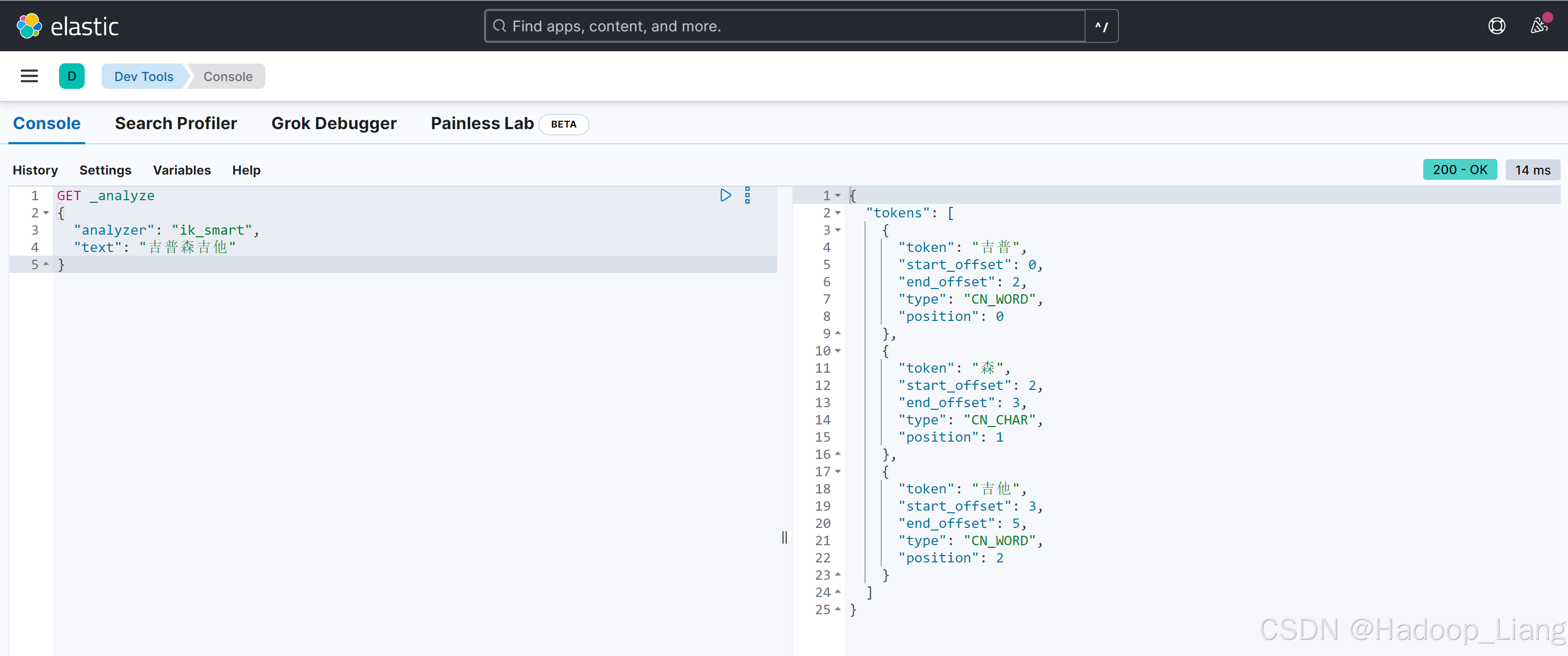
看到吉普森被分词为"吉普"和"森"了,如果吉普森是一个完整的词,不希望被拆分,就需要自定义关键字。
自定义关键字的需要自定义一个字典文件,然后在IKAnalyzer.cfg.xml中引用自定义的字典文件。
ik的config目录下新建自定义的字典文件,文件名例如:my.dic,内容为需要自定义的词如下:
吉普森如果需要定义多个完整的词,则每个词单独放一行。
修改IKAnalyzer.cfg.xml,配置使用自定义的字典文件:
<entry key="ext_dict">my.dic</entry>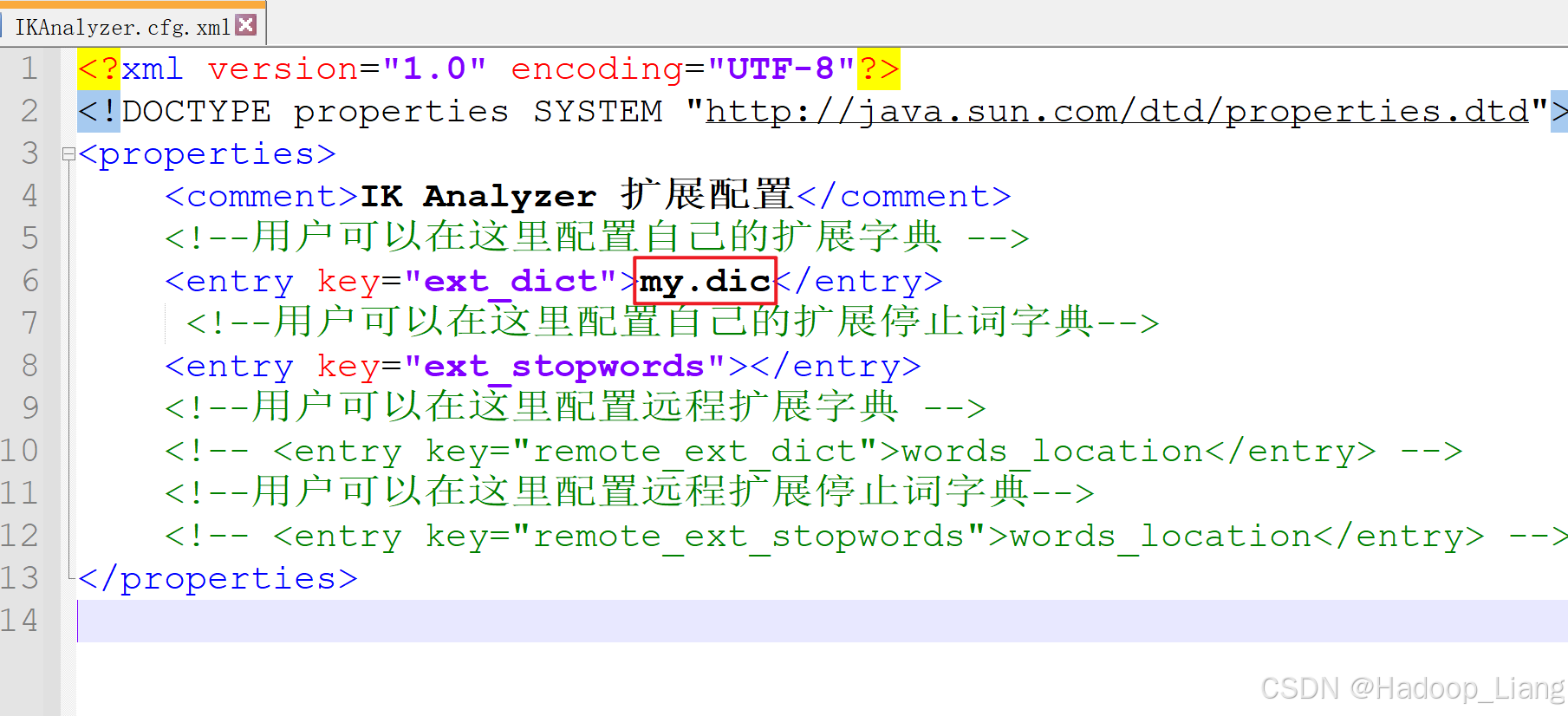
重启es,输出日志查看到加载了自定义的my.dic,如下
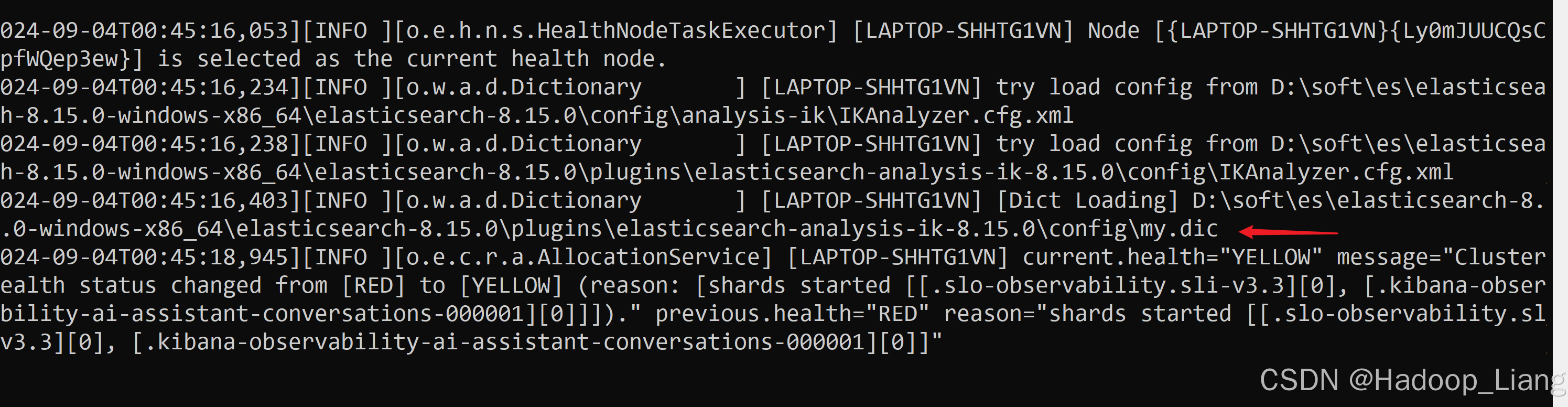
Dev Tools再次测试
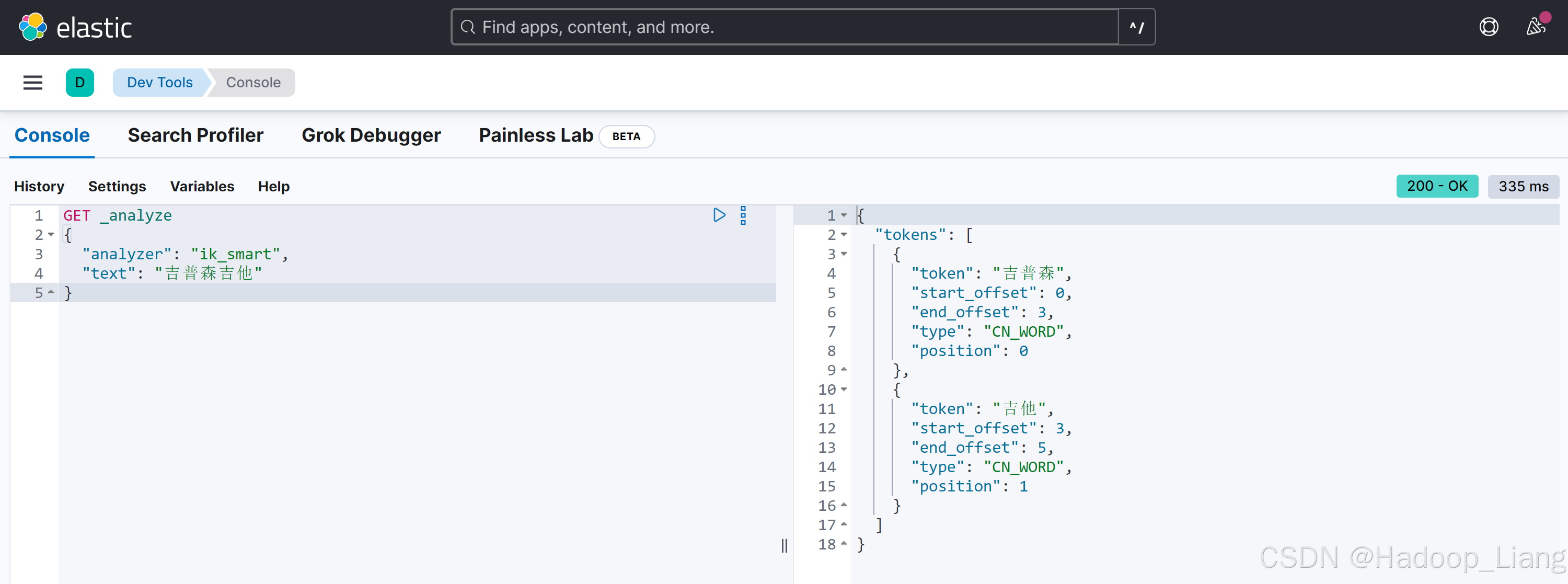
发现自定义的吉普森没有被拆分了。
完成!enjoy it!