引言
我叫李庆旺,是Cisco Webex的一名软件工程师,同时也是Apache DolphinScheduler(以下简称DS)的Committer。

在过去的两年里,公司基于Apache DolphinScheduler进行了多项持续改进和创新,以更好地适应我们的业务需求。本文将介绍这些改进的具体内容,以及我们对社区的贡献。
主要包括以下五个部分:
- 我们的系统架构
- 在业务上遇到的挑战以及解决方案
- 探讨在安全性方面所做的优化和关键指标
- 我们对社区的贡献
- 遇到的有趣技术问题。
公司及项目背景
首先,跟大家简要介绍一下我们公司。Cisco Webex是一家专注于开发和销售在线会议产品的软件公司,这些产品包括Meeting、Calling、ContactCenter等。

我们团队设计并搭建了一个大数据平台,为上述产品的数据接入和处理提供支持。以Webex Meeting产品为例,Webex会议会生成各种指标。当会议进行时,客户端和服务器会向我们的Kafka集群发送指标和日志。
外部和内部客户依赖这些指标来优化会议体验或生成相关报告。
我们的愿景是打造一个能够服务于内部和外部客户的大数据平台,通过消除数据孤岛,实现所有基础设施的整合,并且该平台需要能够适应公共云和现有私有数据中心的架构。
由于思科网讯是一家全球协作服务提供商,我们的客户跨越多个时区和大洲,因此我们在全球拥有许多数据中心。这些数据中心包括本地自我管理的数据中心 Webex DC,同时最近两年,我们也支持了亚马逊云管理的集群。
调度选型
三年前,我们选择了Apache DolphinScheduler作为我们的工作流数据处理引擎,原因是它的功能强大、设计优雅且易于扩展。我们最初使用的版本是2.0.3,之后升级到了3.1.1。
感兴趣的朋友可以参考公众号的文章
- 使用 Apache DolphinScheduler 构建和部署大数据平台,将任务提交至 AWS 的实践经验:https://mp.weixin.qq.com/s/Md5C84kZLA_H4pdfzLmxbw
- 杭州思科对 Apache DolphinScheduler Alert 模块的改造:https://mp.weixin.qq.com/s/cyGs1MHnlxhLBl0mumJBdg
- Apache DolphinScheduler2.0升级3.0版本方案:https://mp.weixin.qq.com/s/tZMEatdnQibX7ifxp67DTQ
技术架构
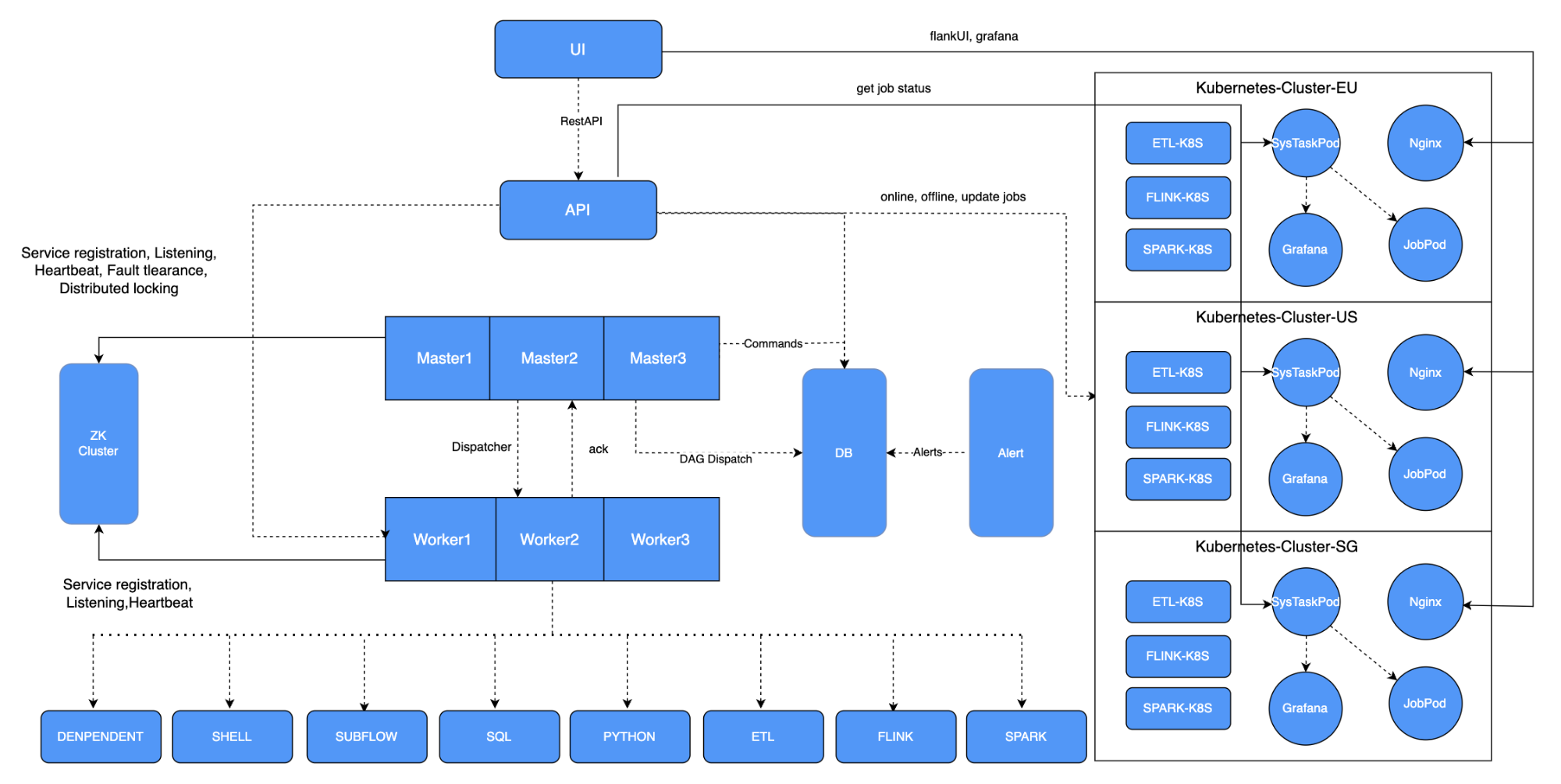
以上是两年前的架构图,基于社区版本,我们做了一些适应性的改动。
由于平台部署在Kubernetes(K8s)上,我们开发了Flink on K8s,支持将Spark调度到K8s上,同时开发了一套通过拖拽形式生成ETL作业的ETL模块。
我们在每个K8s集群中配置了Grafana,每个集群有一个系统任务Pod,用于获取集群中Pod的状态。此外,我们在系统中增加了集群和Namespace的管理功能。
业务挑战与解决方案
在过去的两年中,我们在业务上面临了诸多挑战,并为此提出了相应的解决方案。
多集群支持
首先是多集群支持。目前,我们已经支持了多个Webex DC数据中心,但由于业务需求,我们需要支持亚马逊AWS下的EKS集群、公司基于EKS二次封装的Kubed集群,以及支持美国政府业务的高安全性集群。
AWS EKS集群的支持
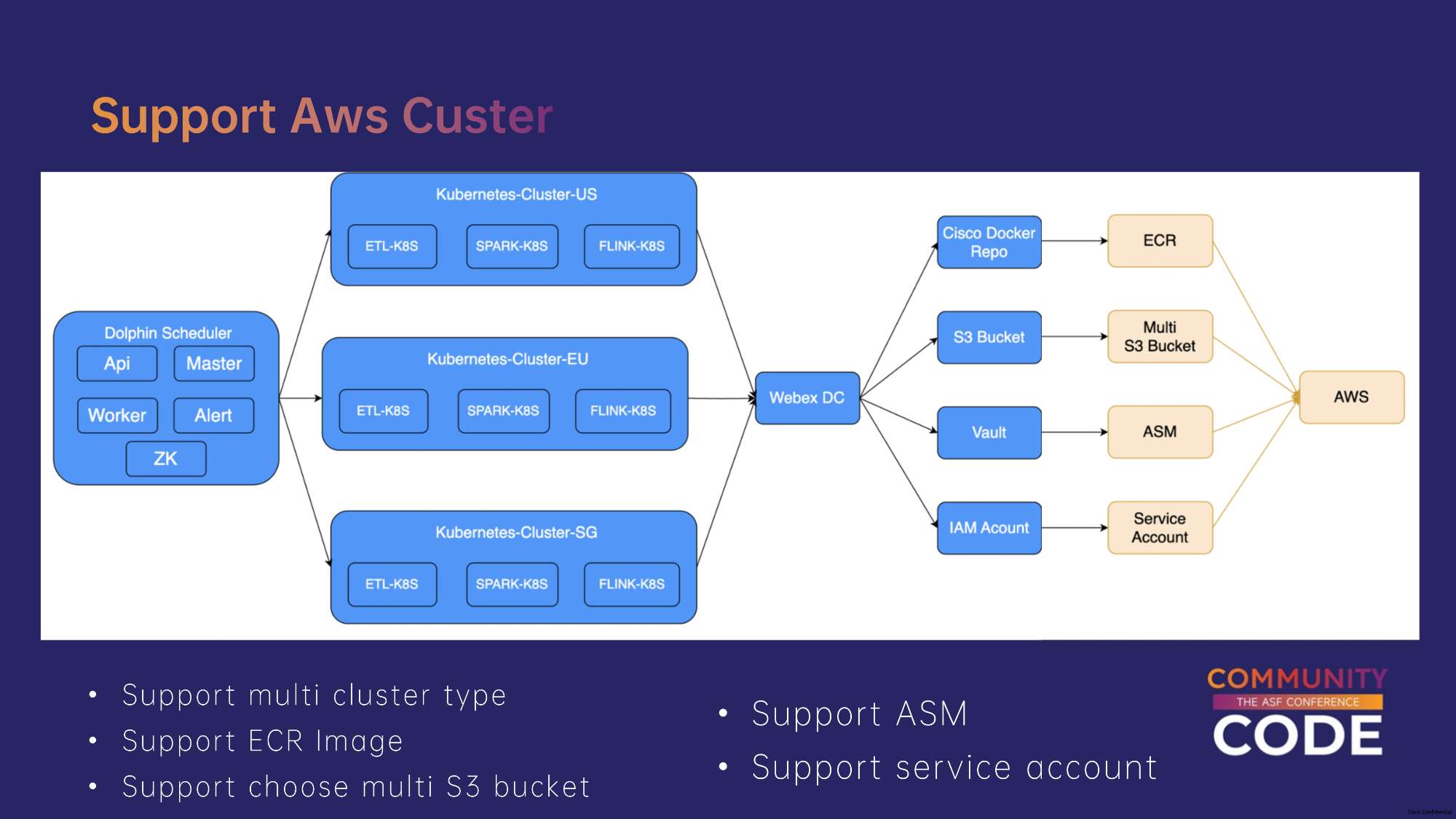
如何支持AWS EKS 集群?
我们使用单个DolphinScheduler服务来控制多个集群,当前支持多个Webex DC。为了支持任务在K8s集群上运行,我们依赖多个组件,包括Docker镜像、JAR包和配置文件,这些资源都存储在AWS S3存储桶中,集群在运行任务时从这个S3存储桶拉取资源。
对于涉及到数据库密码、Kafka topic等需要加密的信息,我们将其存储在Cisco内部的Vault服务中,任务实际运行时将相关密码映射到任务内部。
权限控制
我们还开发了一个权限管理系统,将IAM Account存到K8s Secert里,内容是AWS Key id和Access key。
如果想要支持AWS EKS,我们需要做一些改动。
AWS里面提供了Docker Repo相关的服务,名字叫ECR,我们会将Docker images存入了ECR中。而支持多地的EKS集群,每个集群都有对应的S3 Bucket,需要支持资源读写入多个S3 kubet。
密钥管理
对于密钥管理,AWS也提供了对应的服务,叫ASM。我们将需要加密的信息存到了ASM里面。
对于IAM Account,K8s的Secert里面存的AWS Key ID和Access Key,会存在过期,需要重新Refresh,这里面存在着不够安全的问题。
于是我们切换到了Service Account,Service Account里面保存的是AWS Role,会更加安全,同时也不存在过期的问题。
同时我们对于Clusterr管理也做了修改,支持了多重集群类型。
我们还开发了Auth系统,在上面保存了AWS的组件,比如不同的S3 bucket,ECR等,用户如果想要申请权限需要在auth上走申请流程。
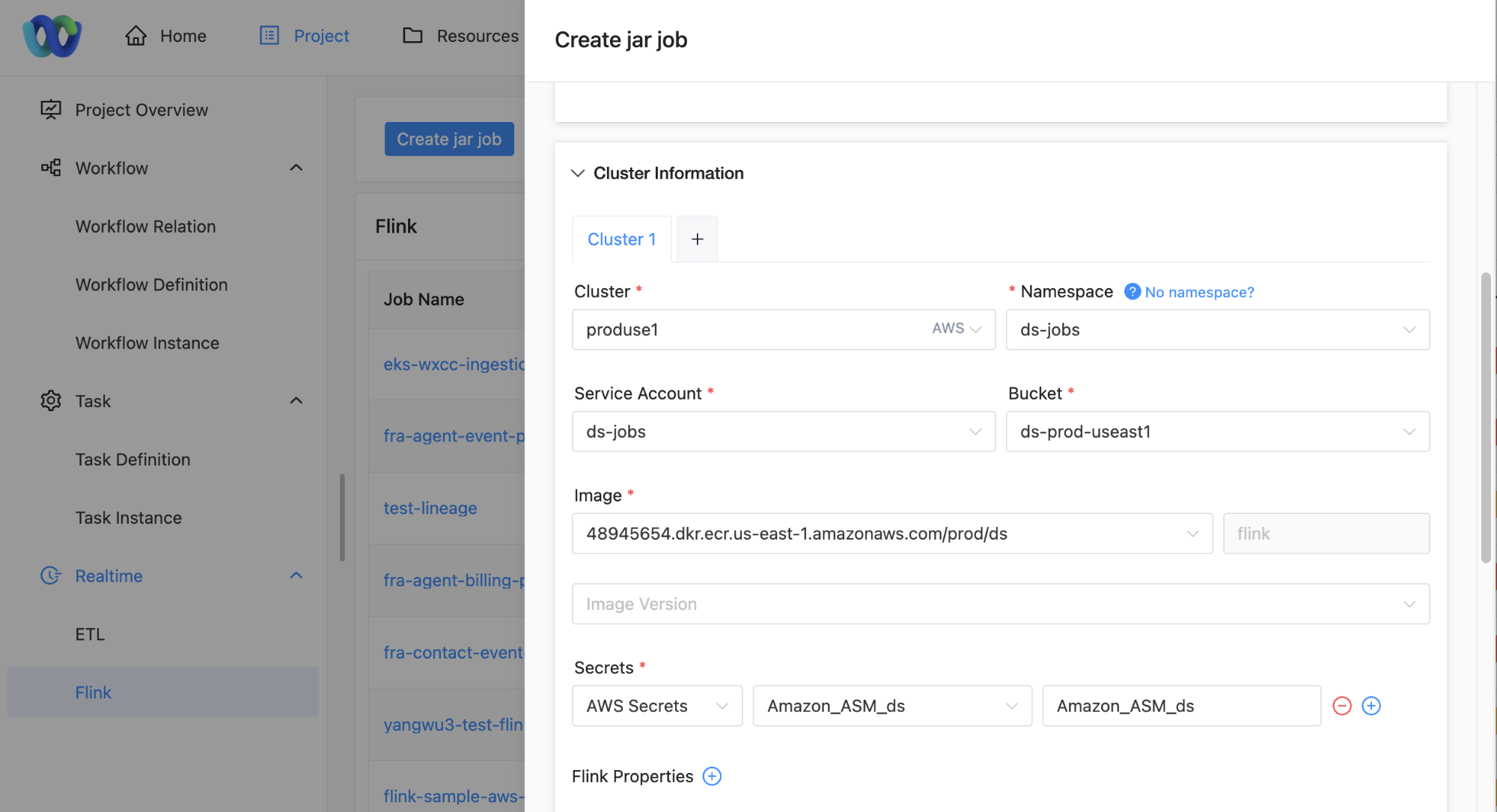
说了这么多,其实对于用户来说操作很简单,在定义任务的时候选取想要运行的集群、Namespace,就会根据当前的Project、Cluster、Namespace,和用户ID展示出来用户拥有权限的Service account。
当用户选取了Service account,就会列出这service account下面绑定的AWS组件,比如ECR Bucket、AWS等。
然后在任务运行时,会把用户选取的资源下载或者映射到Pod里面。
安全性优化
在安全性方面,我们对社区版的审计日志功能进行了优化。在实际场景中,许多用户需要查看任务的修改记录,尤其是那些具有较高安全要求的客户(如美国政府)。
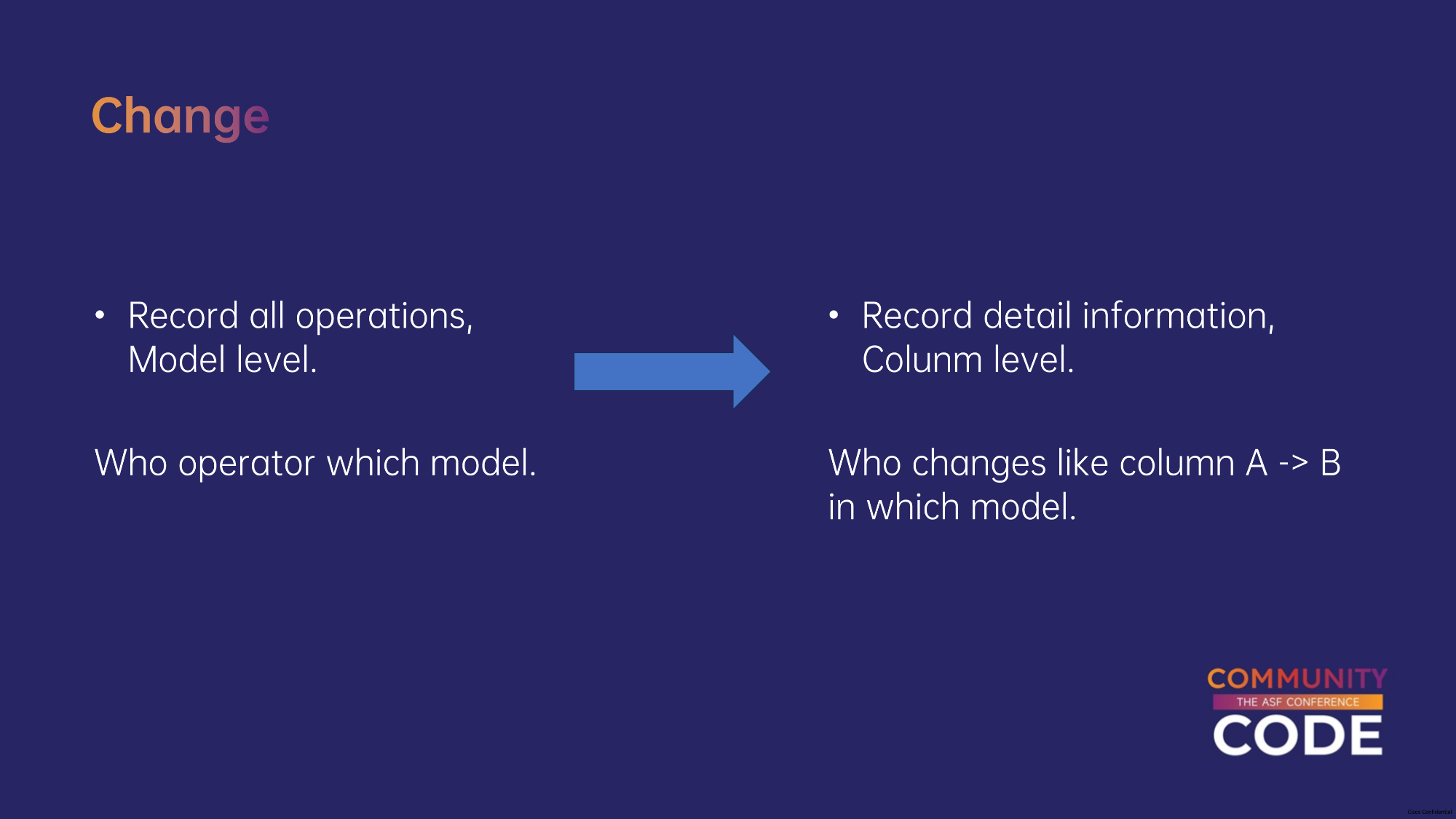
我们将审计日志的开发分为两部分:
社区在3.x版本已经有了审计日志的框架。但是只有一个框架,对于实际的用户操作并没有做记录。并且之前社区版的设计采用的发布订阅模式,对于代码的侵入性非常大。
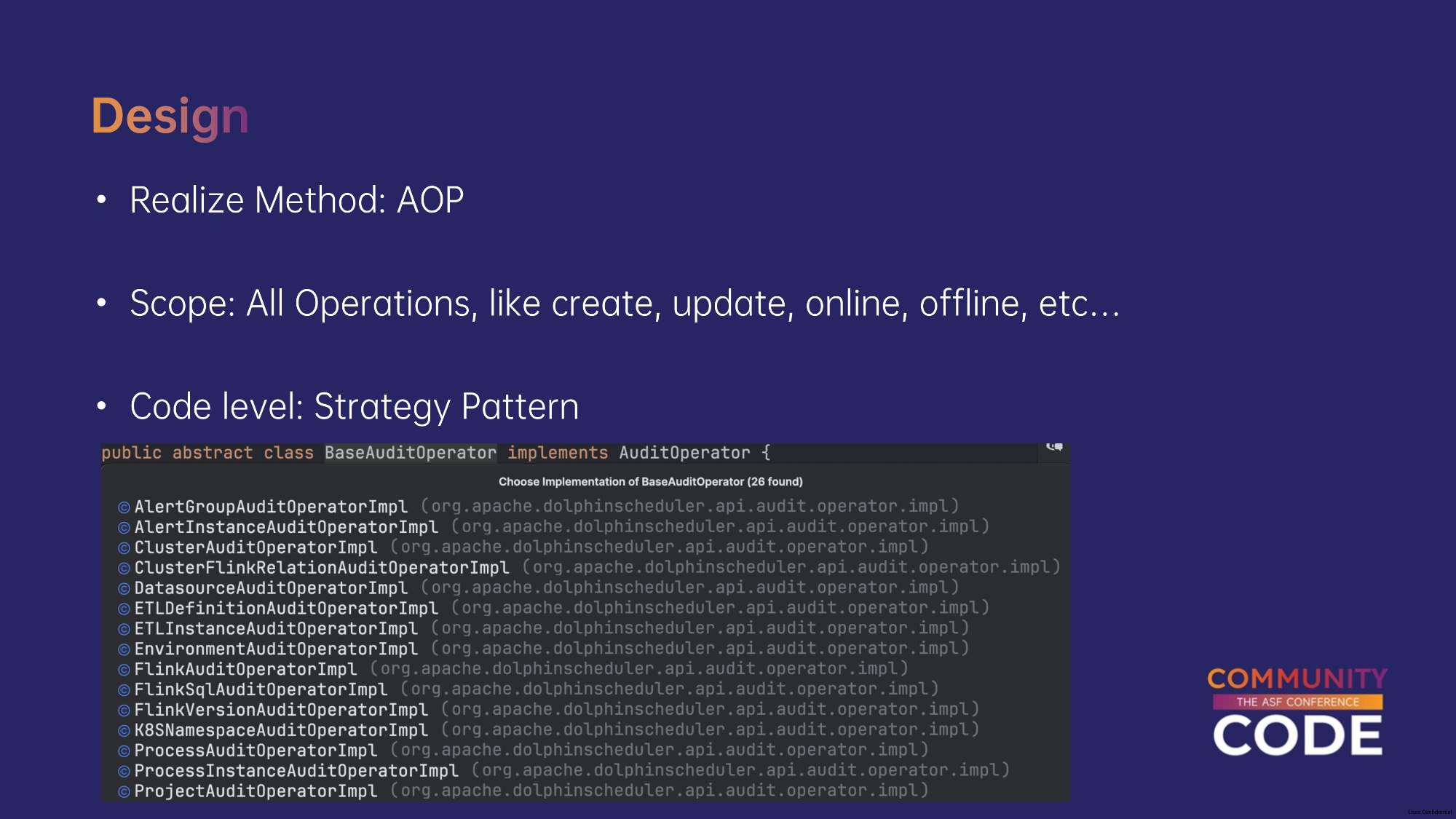
我们进行了重构,采取了AOP方法实现审计日志,这样只需要在需要记录审计日志的接口上添加注解,代码侵入性很低。支持了Model层面的日志,记录谁做了改动。二期我们会记录改动的详细内容。
采用了策略模式的设计模式,这样非常易于扩展,如果有新的模块需要支持审计日志,只需要新建一个实现类,里面定义这个模块特定的审计逻辑即可。
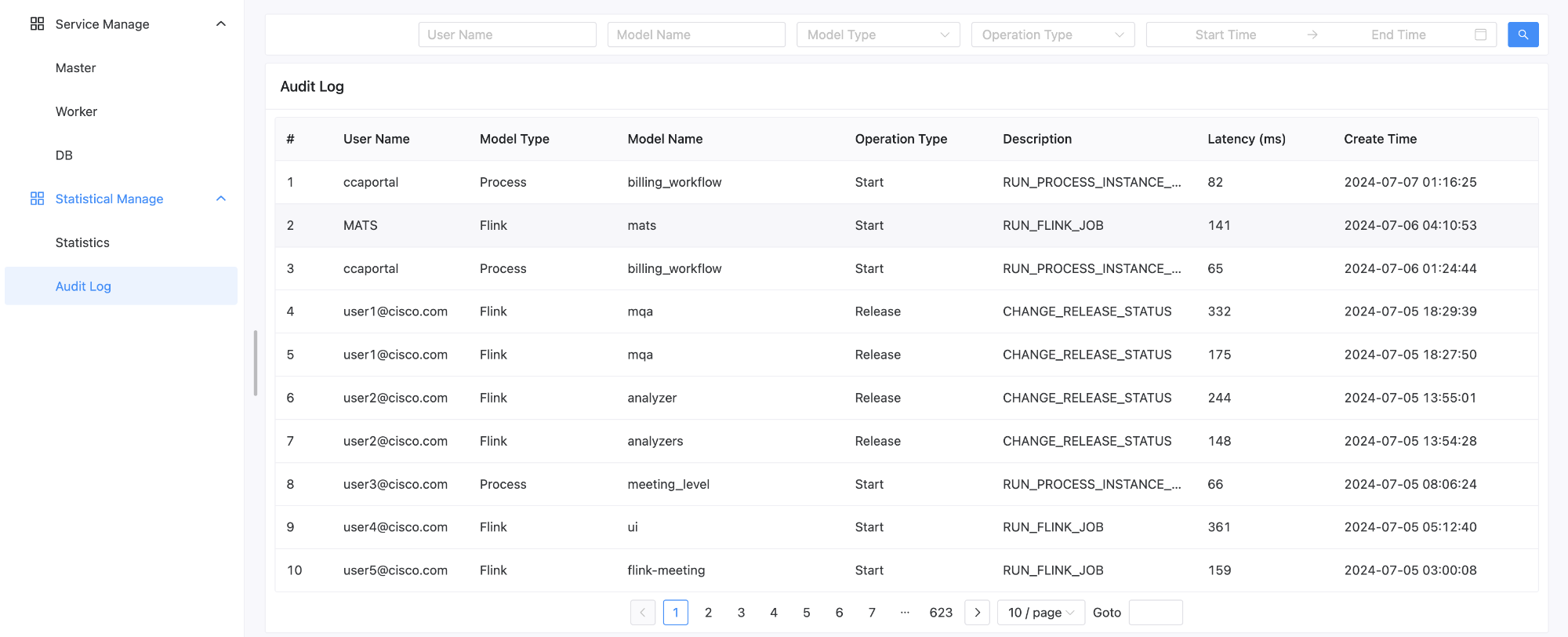
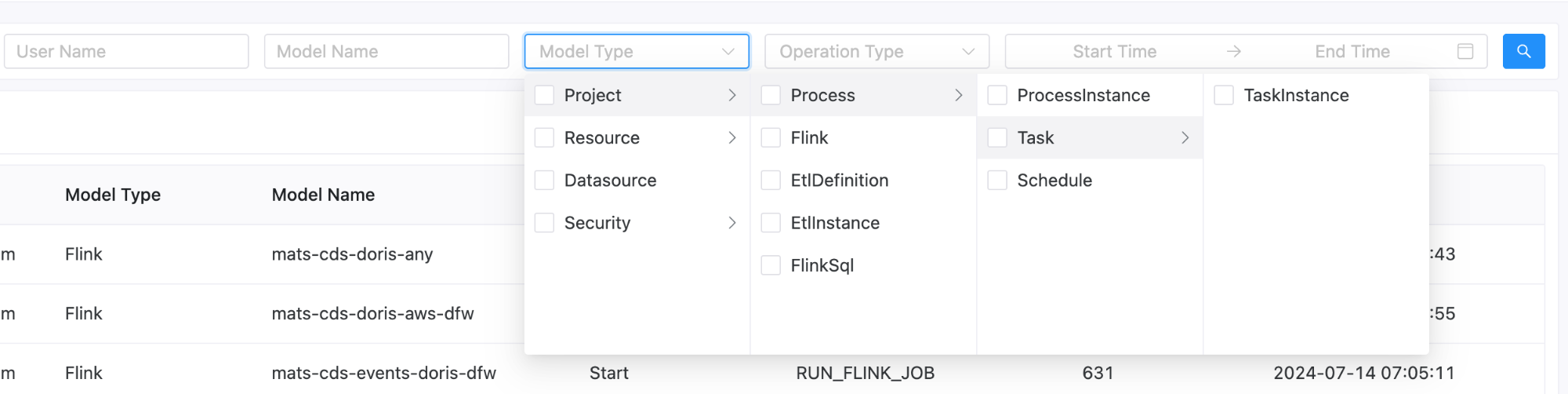
如图就是审计日志的页面,用户也可以按照模块纬度去搜索日志。比如用户想看所有针对于Project的操作等。
数据质量模块的开发
在没有数据质量模块之前,用户在任务执行结束后需要人工去检测生成的数据的质量,比如手动去执行一些检测SQL来判断数据质量。
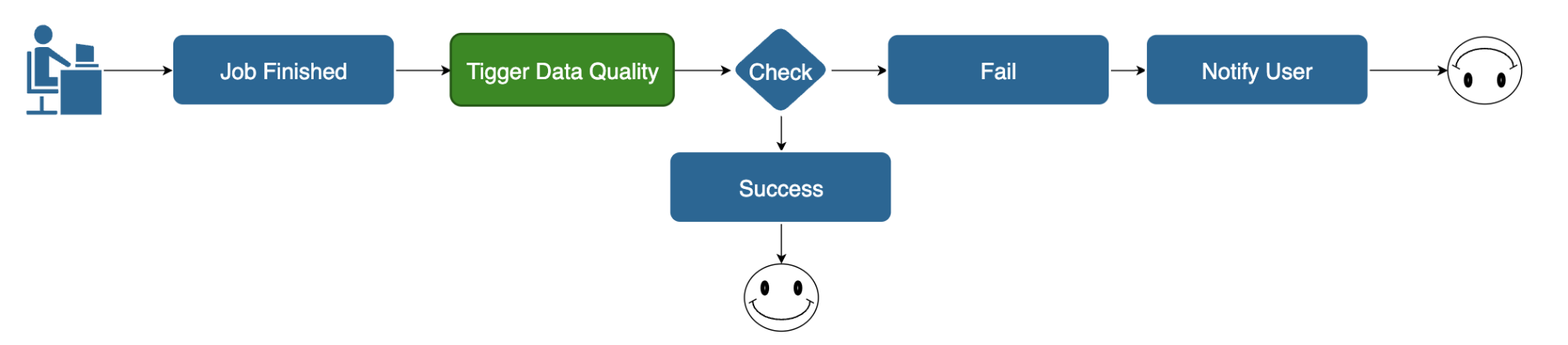
引入数据质量模块后,用户只需配置一个数据质量任务,批处理任务结束后会自动调用该任务。

如果检测失败,会及时通知用户进行干预。该模块支持一些常见的规则配置,如查询数据表的总行数、检查是否存在重复键值等,从而降低了使用成本并提高了易用性。
我们还在数据质量模块中增加了对不同数据源(如Iceberg和Pinot)的支持。
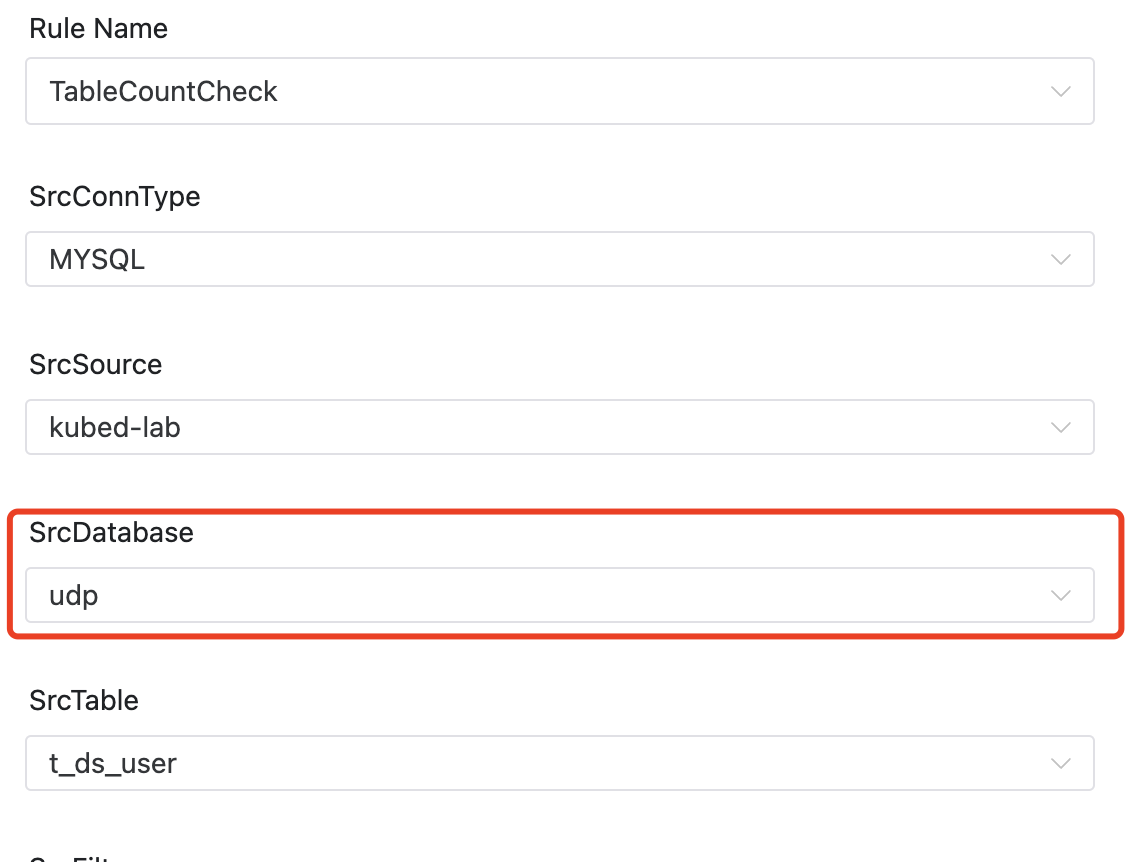
同时在生产环境中,由于一些数据迁移等需要,用户偶尔需要比对两个数据库同一个数据表,按照Day或者Org的维度聚合,总数应该是接近的,不一定完全一致但是总数误差在5%之内,我们也需要支持这种规则。
我们的DolphinScheduler是all on k8s的,后续也会支持数据质量任务跑在k8s上面。
端到端测试(E2E)的改进
我们先来看一下社区的流程。当贡献者代码写完以后,会往社区提交一个PR,会触发CI/CD流程,首先会基于贡献者提交的代码打最新Docker镜像,然后在镜像上面会运行写好的Case,来保证贡献者写的代码不会影响到现有功能。
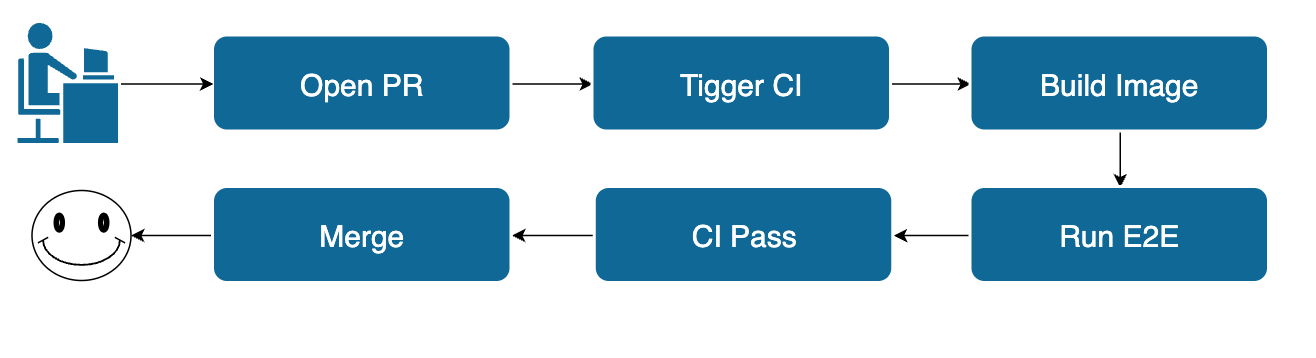
只有所有的Case通过后,经过Committer或者PMC Approve PR后,代码才可以合进仓库。这个流程是没什么问题的。同时社区也很多基础功能的Case。
但是对于我们的实际生产环境有些不够用。
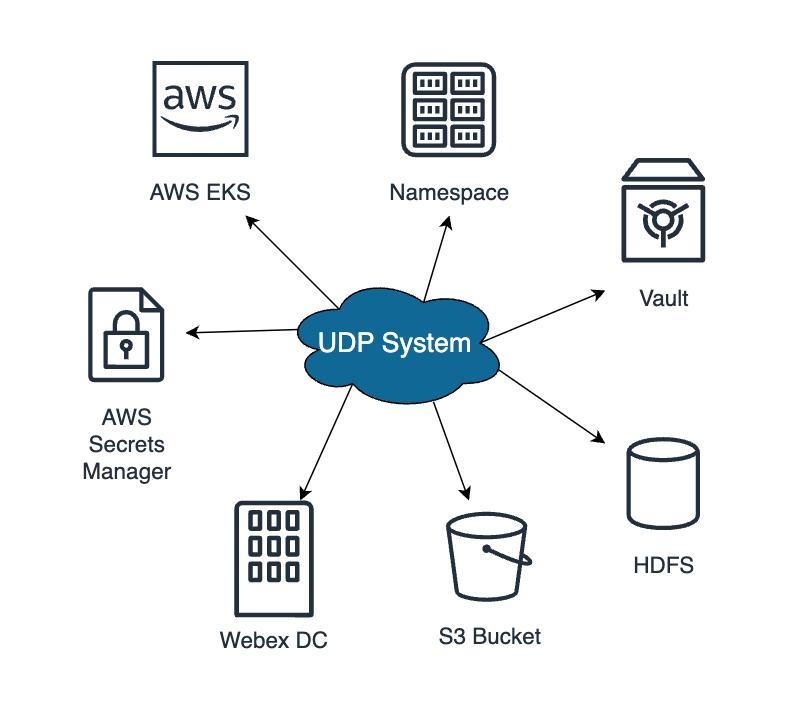
刚才介绍过,我们的服务on k8s,支持多k8s集群,包括Webex DC和AWS EKS集群,同时还支持多Bucket,不光多个S3 Bucket,同时针对于美国政府业务,我们还在Webex搭建了HDFS作为相关的存储中心。
这些服务往往是需要一些特定的配置文件,而这些配置文件或者配置信息是无法在代码中写死的,甚至也不是完全存在数据库中,比如AWS秘钥的Service Account是存在K8s集群中。
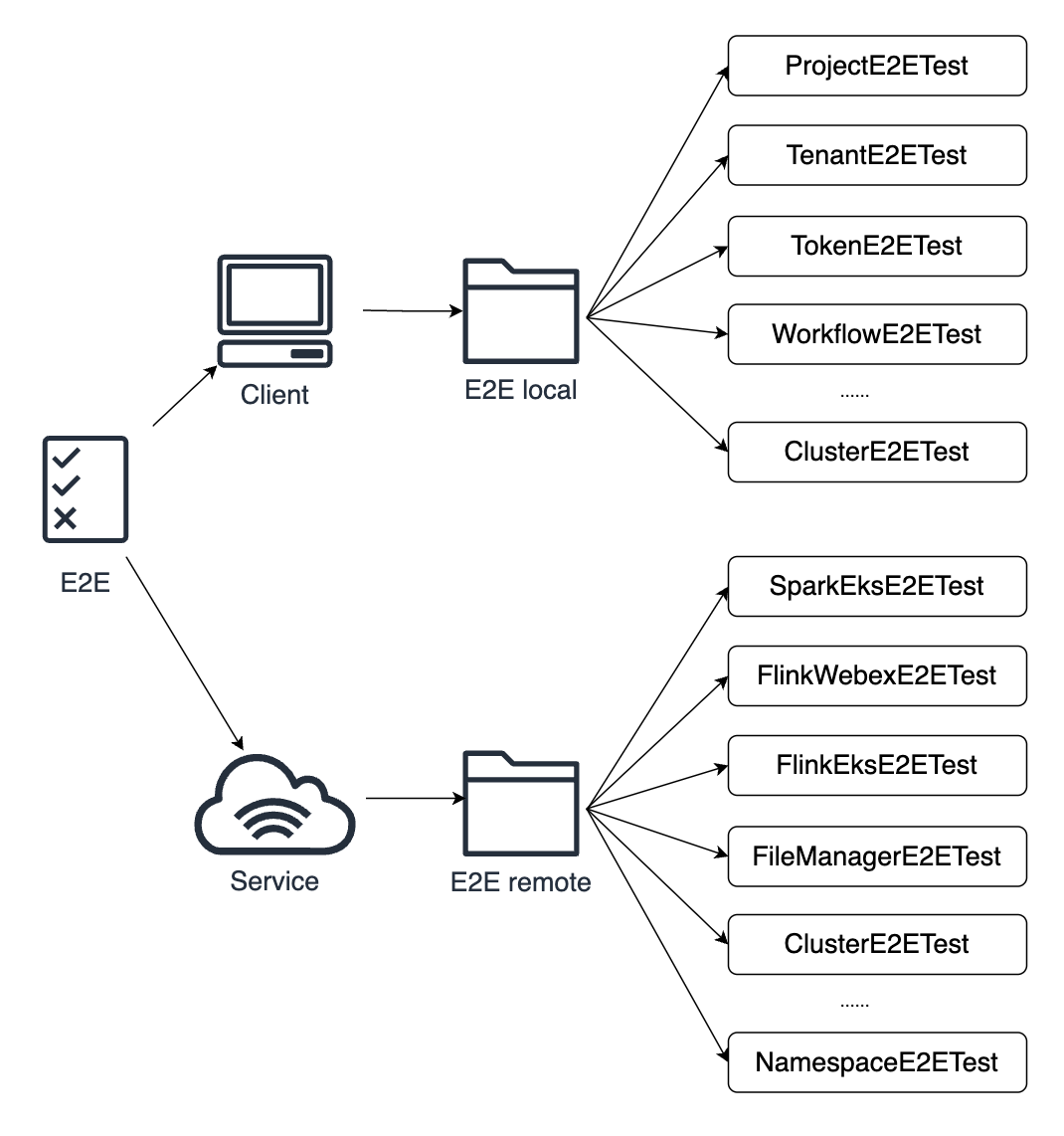
社区的E2E流程较为基础,无法覆盖我们实际生产环境中的所有测试场景。
为此,我们将E2E拆分为两部分:一部分使用社区的E2E测试增删改查基础功能,另一部分需要依赖一些配置信息的我们重新编写了一些测试远端服务的case。
可以看到E2E local就是社区相关的基础的Case。
E2E Remote我简单列出来了一些,比如我们Spark Flink ETL 任务需要支持不同的集群运行。
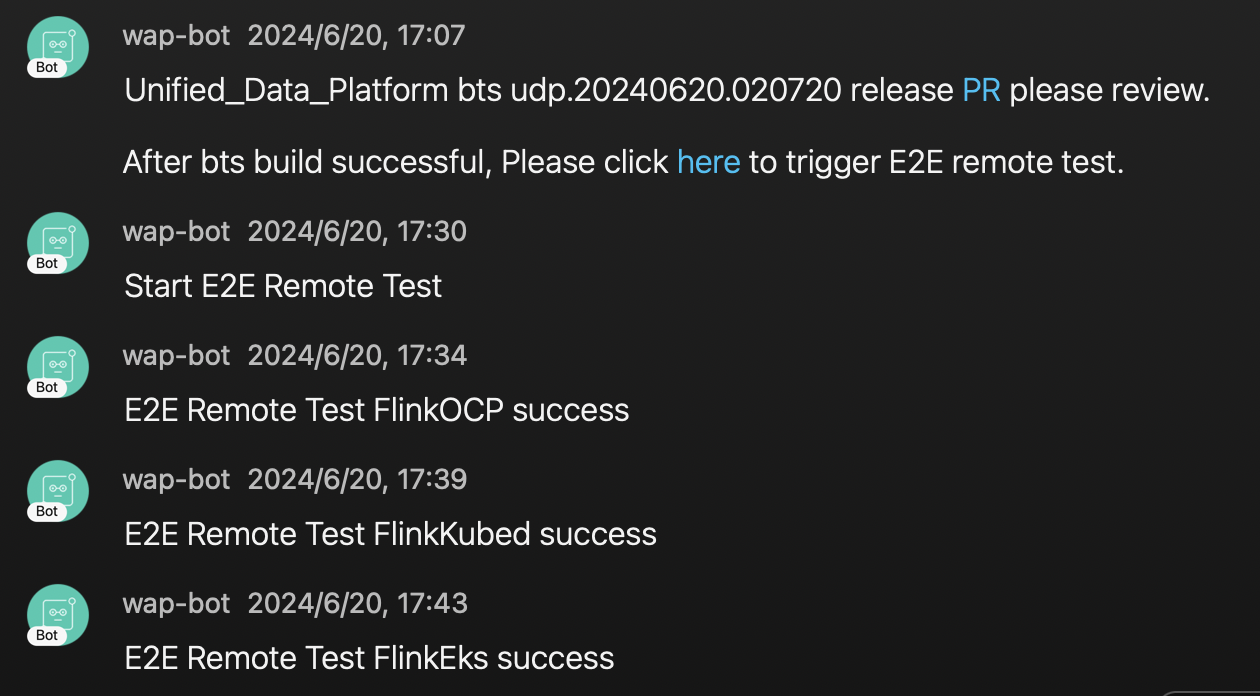
我们就编写了相关的E2E Case来判断是否可以实际运行到不同类型的集群,一些Spark Flink UI是否能打开等等。
像资源中心,也会测试往多个S3 Bucket和HDFS实际上传下载删除文件来测试系统的功能。这些测试用例覆盖了多个K8s集群的实际运行、资源中心的文件操作等场景。
CI/CD经过改动后,开发人员想要提交代码到Github仓库,会首先经过E2E Local的监测,通过基础功能的检测后才能合并进仓库,同时在发版的时候,会将发版的分支部署到预发环境,进行E2E Remote test,通过所有Case后才会正常的走发布流程,同时发布完成后会再次运行E2E Remote test再次确保线上功能符合预期。
新架构及其他优化
以下是我们添加了上述功能后的新架构图。
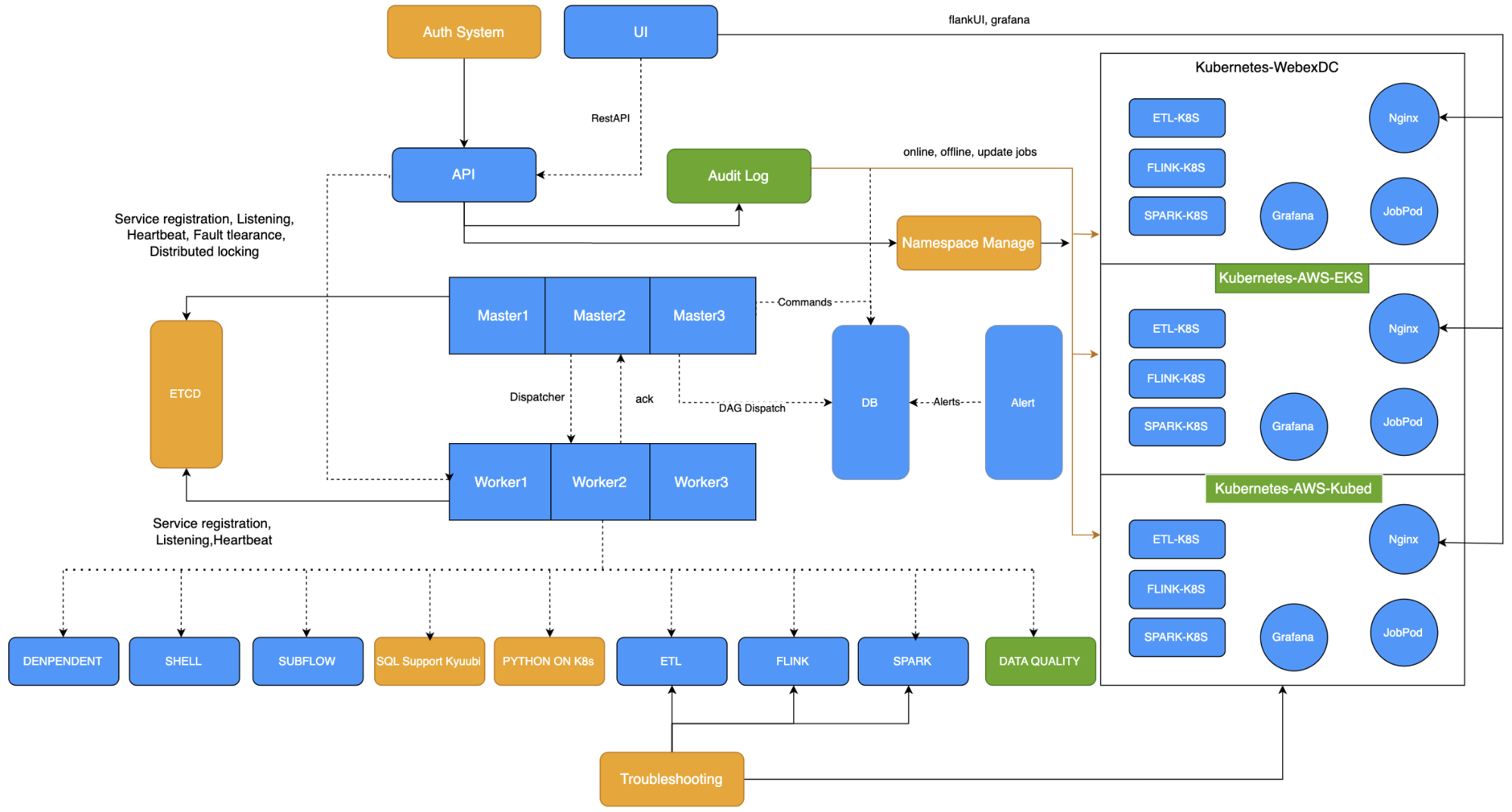
在过去两年,我们团队还做了其他一些优化。
例如,我们使用ETCD替代了Zookeeper作为注册中心,开发了权限系统,简化了集群申请和命名空间授权流程。
还扩展了K8s集群上支持的任务类型,如SQL任务、Python任务,并优化了监控系统。
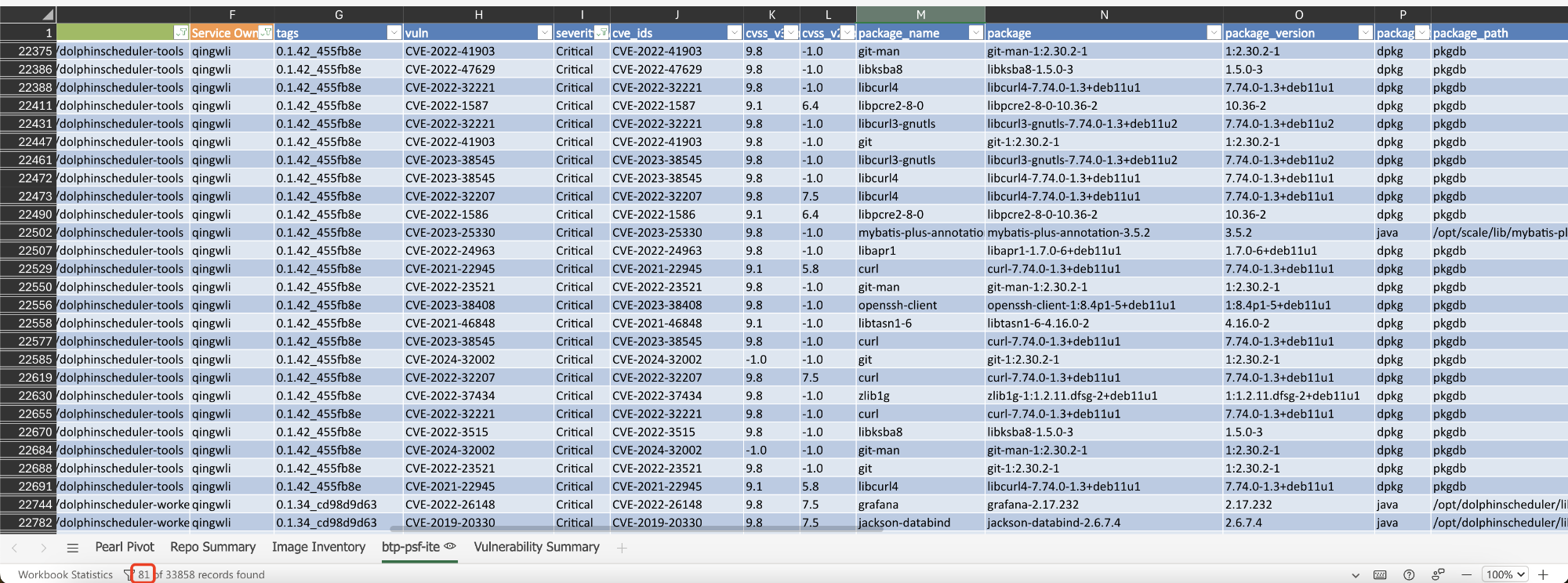
此外,为了支持美国政府的高安全性业务需求,修复了相关的代码漏洞,并将漏洞数量从81个减少到1个。

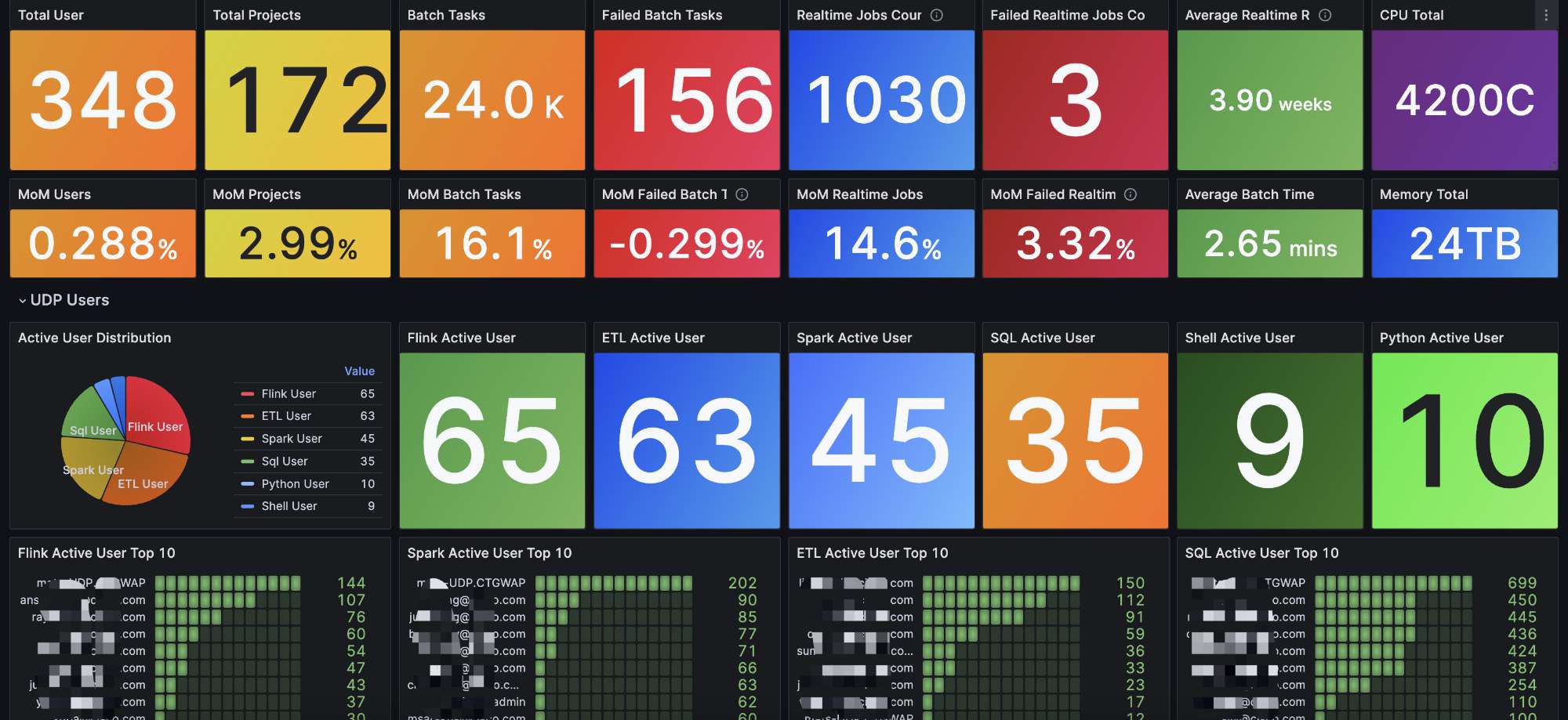
我们还绘制了平台相关的Metrics,显示有多少用户,多少任务。可以看到比较活跃的Flink Spark等用户。
同时还添加一些告警,比如某个Spark Job的运行时间过长,会及时通知运维人员及时介入处理。
对社区的贡献
在对社区的贡献方面,我们将绝大多数功能都回馈给了社区。例如,审计日志、数据质量模块、一系列告警优化、K8s部署相关的Bug修复、以及对LDAP和etcd SSL连接的支持等功能。

后续开发的新功能我们也会持续贡献给社区。
技术问题分享
最后,我想与大家分享一个有趣的技术问题。我们之前的监控检测到同一任务在同一时间被执行了两次,可以看到这两个任务实例的调度时间是相同的,并且ID相差1。

具体的排查过程也不是非常顺利,先说结论,DS底层使用的调度框架时Quartz,Quartz使用了数据库的锁来控制并发。
我们使用的是TiDB数据库。TiDB数据库和Mysql数据库,在默认的RR,可重复读的隔离级别下。创建事务时,创建Read-view 读试图的时机不一定,导致了TiDB数据库会出现重复调度的问题。
可以参考这篇文章:【故障排查】10 分钟解决 Quartz 重复调度的疑难杂症
Mysql是在事务执行第一个快照读时创建read-view。而TiDB官方没有找到相应的文档说明,但是经过测试,应该在事务开始的时候就创建了Read-view。
解决方案是将TIDB的隔离级别切换为读已提交(RC)。
结语
以上就是我今天的全部分享内容。在过去的两年里,我们在基于DolphinScheduler的系统中遇到了许多挑战,并通过一系列的改进和创新,成功应对了这些挑战。
未来,我们将继续致力于优化和扩展Apache DolphinScheduler,并将新功能持续回馈给社区。
本文由 白鲸开源科技 提供发布支持!