课程源码+资料
我用夸克网盘分享了「网页自动化1」
链接:https://pan.quark.cn/s/b64120f46e44
准备工作
为什么要模拟浏览器?
对爬虫是稍微有了解的同学可能会有疑问,明明可以使用 requests 库直接获取到网页源代码了,为什么还是要模拟浏览器进行网页自动化操作呢?获取源码的方式虽然简单又直接,但大家别忘了你有爬虫,别人有反爬虫。
另外网页里一些关键数据的解析和提交,往往可能通过脚本(JavaScript)来进行解析和加密,我们要理解这些混淆后的 JavaScript 代码是很费劲的,就不能很快地进行数据的抓取或提交。而且很多网站往往是有验证码的,现在验证方式五花八门,要想模拟过验证那确实是有难度的。所以用浏览器的打开网页,真实地模拟人类操作,才能克服读取网页内容的障碍。
Selenium介绍
Selenium可以说是网络爬虫中的王者了,它可以控制浏览器,当使用 Selenium 当爬虫工具时,网络服务器会认为来读取数据的是正常的浏览器,所以不会有阻挡无法读取网页 HTML 原始文件的问题。
当然,Selenium作为爬虫王者,不仅是可以打开网页,读取信息,还可以用它点击链接,填写登录信息,甚至可以做自动上下架商品、抢票抢茅台系统。
安装工作
要在 Windows 中使用 Selenium 来控制浏览器完成自动操作,必须要先安装好下面的软件:
-
Selenium库 本教程以 Pycharm 开发环境作为示例。
-
浏览器 本教程以Win10系统下使用 Chrome 浏览器作为示例。
-
驱动程序 这里指的是浏览器对应的驱动程序,要使用配合 Chrome 的 chromedriver 。
1. 安装Selenium
这个比较简单,在 Pycharm 底部的功能菜单中选择 终端(Terminal),然后在控制台中输入
pip install selenium
按回车后等下载安装完成,可以使用以下的方式导入对应模块
from selenium import webdriver
2.安装浏览器
本教程使用 Chrome 作为示例,直接点击这个链接去官方下载: https://www.google.cn/chrom
e/ (经测试这个网址国内是可以打开的),下载完成后安装好,就是最新版的。(旧版本我也进行了整理并已经发布http://t.csdnimg.cn/hx8DK)
3. 安装驱动程序
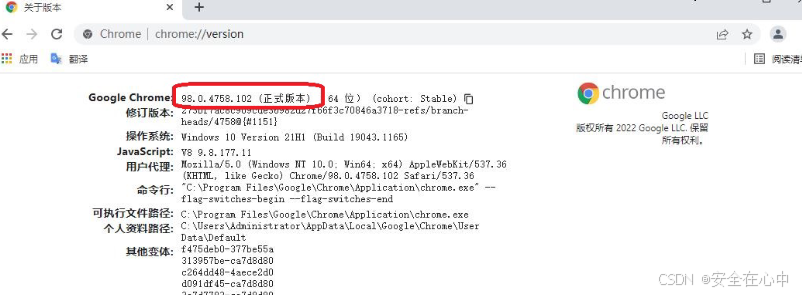
这一步就比较关键了,首先打开 Chrome 浏览器,在地址栏里输入 chrome://version/ ,看看浏览器的版本号是多少,比如我的版本号是 "98.0.4758.102 (正式版本) (64 位) (cohort: Stable)"
,记住这串数字,等下要去下载对应版本的驱动程序。在浏览器里再打开这个网址 从
找到刚才对应的版本号:
from seleni
在浏览器里再打开这个网址 从http://chromedriver.storage.googleapis.com/index.html ,找
到刚才对应的版本号:
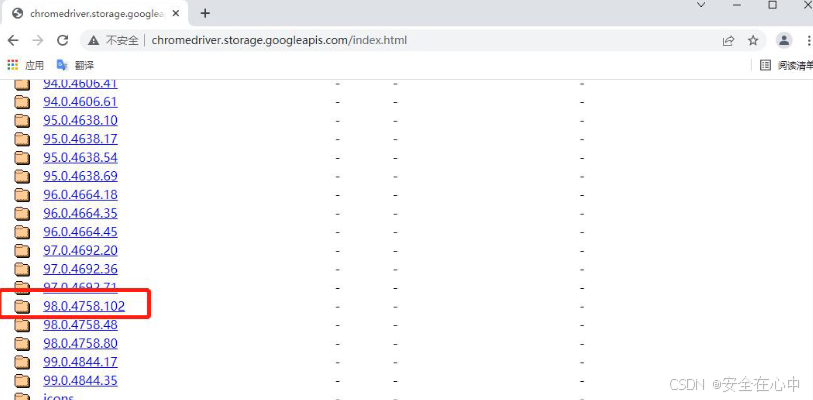
点击进去选择 windows 版本的驱动下载:
 基本用法
基本用法
这节我们就从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面和前进后退、定位元素输入或点击等基础操作开始学习。
初始化浏览器对象
准备工作都已就绪,接下来我们尝试打开第一个网站,看看效果是什么样的。
新建一个 Python 代码文件,在文件中输入以下代码:
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'C:\Users\77653\AppData\Local\Microsoft\WindowsApps\chromedriver.exe')#这里的chromedriver.exe我将其放在python文件环境位置并调用
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
time.sleep(2)
# 关闭浏览器
browser.close()可以看到以上是有界面的浏览器,我们还可以初始化浏览器为无界面的浏览器
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'C:\Users\77653\AppData\Local\Microsoft\WindowsApps\chromedriver.exe')
option = webdriver.ChromeOptions()
option.add_argument("headless")
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s, options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
time.sleep(2)
# 关闭浏览器
browser.close()运行后,打开工程下的 截图.png 图片可以看到:
完成浏览器对象的初始化后并将其赋值给了browser 对象,接下来我们就可以调用browser来执行各种方法模拟浏览器的操作了。
访问页面
进行页面访问使用的是 get 方法,传入参数为待访问页面的 URL 地址即可。
#URL 地址(Uniform Resource Locator)是用来定位互联网资源的标准化字符串。它包含了访问资源所需的所有信息,包括协议(如 `http` 或 `https`)、主机名(如 `www.example.com`)、路径(如 `/index.html`)、查询参数(如 `?id=123`)等。举个例子,`https://www.example.com/index.html?search=chatgpt\` 是一个 URL 地址,其中 `https` 是协议,`www.example.com` 是主机名,`/index.html` 是路径,`search=chatgpt` 是查询参数。
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'C:\Users\77653\AppData\Local\Microsoft\WindowsApps\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
# 关闭浏览器
browser.close()设置浏览器大小
set_window_size() 方法可以用来设置浏览器大小(就是分辨率),而 maximize_window 则是设置浏览器为全屏
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'C:\Users\77653\AppData\Local\Microsoft\WindowsApps\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()刷新页面
刷新页面是我们在浏览器操作时很常用的操作,这里 refresh() 方法可以用来进行浏览器页面刷新。
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'C:\Users\77653\AppData\Local\Microsoft\WindowsApps\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
time.sleep(2)
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()大家也是自行演示看效果哈,作用同 F5 快捷键一样。
前进后退
前进后退也是我们在使用浏览器时非常常见的操作,这里 forward() 方法可以用来实现前进,
back() 可以用来实现后退。
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'C:\Users\77653\AppData\Local\Microsoft\WindowsApps\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()获取页面基础属性
当我们用 selenium 打开某个页面,有一些基础属性如网页标题、网址、浏览器名称、页面源码等信息。
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'C:\Users\77653\AppData\Local\Microsoft\WindowsApps\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
# 关闭浏览器
browser.close()如果有需要,这里的页面源码我们就可以用 正则表达式、 Bs4、xpath 以及 pyquery等工具进行解析提取想要的信息了。
1.BeautifulSoup4
是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。它通过提供简单的 API 来解析和遍历文档。BS4 支持多种解析器,包括内置的 HTML 解析器和 lxml、html5lib 等第三方解析器。它的特点是处理复杂的 HTML 文档非常方便,并且能够轻松应对不完美或破损的标记。
主要功能:
- 解析 HTML 和 XML 文档
- 提供多种解析器选项
- 提供简洁的 API 来搜索和导航文档
- 支持 CSS 选择器和属性访问
示例:
python
from bs4 import BeautifulSoup
html_doc = "<html><head><title>Test</title></head><body><p class='title'>This is a title</p></body></html>"
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.title.string) # 输出: Test2. XPath
XPath 是一种用于在 XML 文档中进行导航和数据选择的语言。XPath 可以用于提取 XML 数据中的特定节点、值和结构。它是许多 XML 解析器和处理工具的基础,支持对 XML 文档进行复杂的查询和操作。
主要功能:
- 定位 XML 文档中的节点
- 支持绝对路径和相对路径
- 支持各种操作符,如逻辑运算、节点测试等
- 可用于与 XSLT 等技术配合使用
3. PyQuery
PyQuery 是一个类似于 jQuery 的 Python 库,它用于处理和解析 HTML 文档。PyQuery 提供了 jQuery 风格的选择器,方便开发者使用类似 jQuery 的语法来操作 DOM 元素。它使用 lxml 作为底层解析器,因此速度较快,并且支持 CSS 选择器。
主要功能:
- 支持 jQuery 风格的选择器
- 提供类似 jQuery 的操作方法
- 支持链式操作
- 支持 DOM 操作和数据提取
获取页面基础属性
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'C:\Users\77653\AppData\Local\Microsoft\WindowsApps\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
# 关闭浏览器
browser.close()定位元素
我们在实际使用浏览器的时候,很重要的操作有输入文本、点击确定等等。对此, Selenium 提供了一系列的方法来方便我们实现以上操作。常说的 8种 定位页面元素的操作方式,我们一一演示一下!
我们以百度首页的搜索框节点为例,搜索:python

搜索框的 html 结构:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
Selenium 还提供了一个通用的方法 find_element() ,这个方法有两个参数:定位方式和定位值。
使用前先导入By类
from selenium.webdriver.common.by import By
1、id定位
browser.find_element(By.ID, 'kw') 根据 id 属性获取,这里 id 属性是 kw
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service(r'D:\driver\chromedriver.exe')
初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
browser.find_element(By.ID, 'kw').send_keys('python')
time.sleep(2)
关闭浏览器
browser.close()
运行后,可以看到浏览器输入了搜索的关键词:python
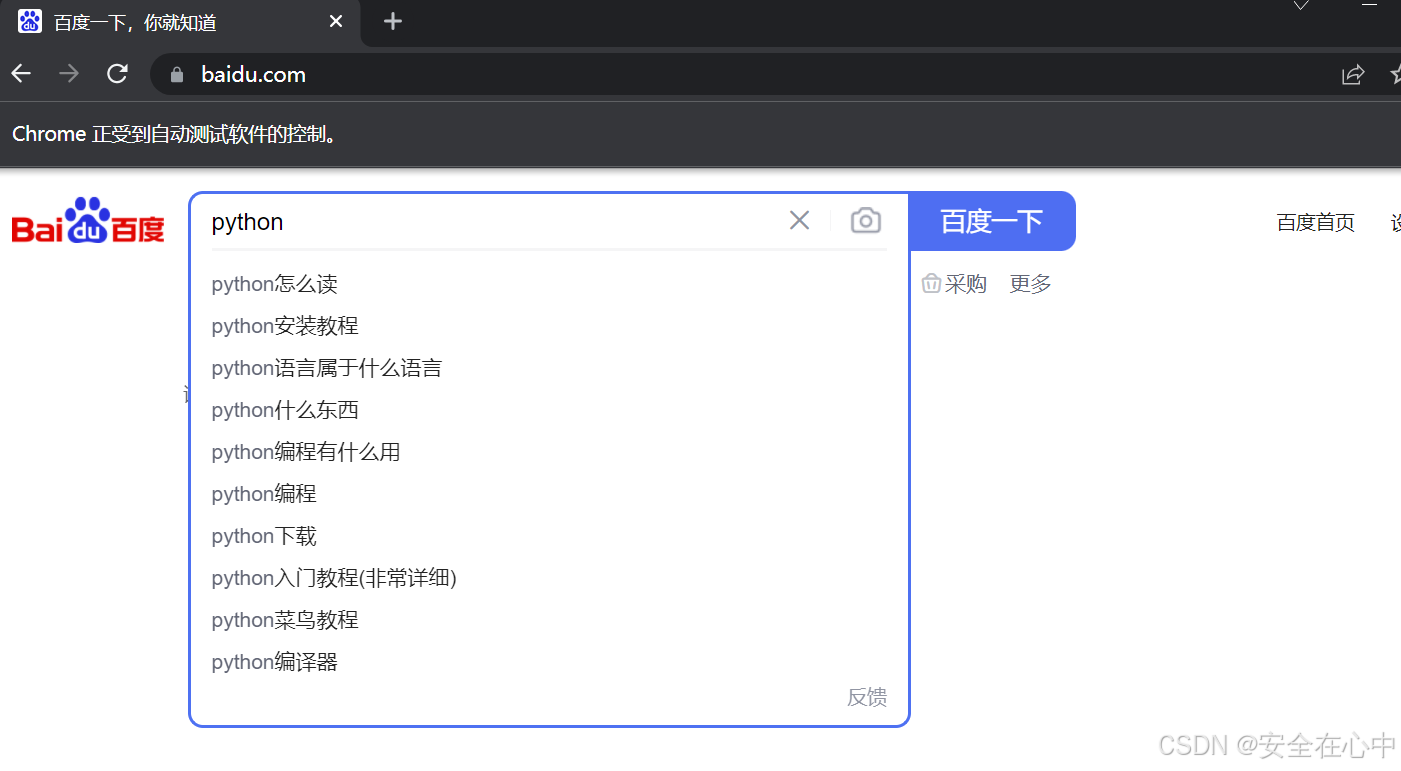
2、name定位
browser.find_element(By.NAME, 'wd') 根据 name 属性获取,这里 name 属性是 wd
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service(r'D:\driver\chromedriver.exe')
初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
browser.find_element(By.NAME, 'wd').send_keys('python')
time.sleep(2)
关闭浏览器
browser.close()
3、class定位
browser.find_element(By.CLASS_NAME, 's_ipt') 根据 class 属性获取,这里 class 属性是 s_ipt
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service(r'D:\driver\chromedriver.exe')
初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
browser.find_element(By.CLASS_NAME, 's_ipt').send_keys('python')
time.sleep(2)
关闭浏览器
browser.close()
4、tag定位
我们知道 HTML 是通过 tag 来定义功能的,比如 input 是输入, table 是表格等等。每个元素其实就是一个 tag ,一个 tag 往往用来定义一类功能,我们查看百度首页的 html 代码,可以看到有很多同类tag ,所以其实很难通过 tag 去区分不同的元素。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service(r'D:\driver\chromedriver.exe')
初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
browser.find_element(By.TAG_NAME, 'input').send_keys('python')
time.sleep(2)
关闭浏览器
browser.close()
注意: 由于存在多个 input ,以上代码会报错。
5、link定位
这种方法顾名思义就是用来定位文本链接的,比如百度首页上方的分类模块链接
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service(r'D:\driver\chromedriver.exe')
初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
browser.find_element(By.LINK_TEXT, '新闻').click()
time.sleep(2)
关闭浏览器全部页面
browser.quit()
6、partial定位
有时候一个超链接的文本很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,用这种方法模糊匹配了。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service(r'D:\driver\chromedriver.exe')
初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
browser.find_element(By.PARTIAL_LINK_TEXT, '闻').click()
time.sleep(2)
关闭浏览器
browser.quit()
7、xpath定位
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的 id 或 name 或 class 或 超链接文本 的属性,那么我们就可以通过这个唯一的属性值来定位他们。
但是在实际工作中并非有这么美好,那么这个时候我们就只能通过 xpath 或者 css 来定位了。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service(r'D:\driver\chromedriver.exe')
初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
browser.find_element(By.XPATH, '//*@id="kw"').send_keys('python')
time.sleep(2)
关闭浏览器
browser.quit()
8、css定位
这种方法相对 xpath 要简洁些,定位速度也要快些。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
s = Service(r'D:\driver\chromedriver.exe')
初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(2)
browser.find_element(By.CSS_SELECTOR, '#kw').send_keys('python')
time.sleep(2)
关闭浏览器
browser.quit()
9、多个元素
如果定位的目标元素在网页中不止一个,那么则需要用到 find_elements ,得到的结果会是列表形
式。简单来说,就是 element 后面多了复数标识 s ,其他操作一致。
课程总结
本节我们学习了网页自动化控制的工具 Selenium 的安装和基本使用方法和元素定位的实现,这些基础知识是后面实现复杂功能的基石,同学们值得花时间去多看看,动手写写,加深印象和理解。