全文链接:https://tecdat.cn/?p=37604
分析师:Yuanchun Niu
在人工智能的诸多领域中,分类技术扮演着核心角色,其应用广泛而深远。无论是在金融风险评估、医疗诊断、安全监控还是日常的交互式服务中,有效的分类算法都是实现智能决策的关键**(** 点击文末"阅读原文"获取完整代码数据******** )。
相关视频
随着大数据时代的到来,分类算法面临着前所未有的挑战和机遇。一方面,海量的数据为算法提供了丰富的学习材料;另一方面,如何从这些数据中提取有价值的信息,构建准确、可靠的分类模型,成为了研究的热点。
本文旨在探讨分类技术在不同领域的应用,并深入分析其理论基础与实现方法。我们首先概述了分类问题的基本框架,包括常见的输入输出特性。随后,通过具体的应用实例的代码数据,展示了分类技术在手写字符识别数据等领域的实际应用。进一步地,本文详细讨论了分类方法的演进,从基于回归的简单分类到基于概率模型的复杂分类策略,再到现代的贝叶斯方法,揭示了分类技术的发展脉络。
特别地,本文重点研究了贝叶斯卷积神经网络(Bayesian CNN)在处理数据不确定性方面的优势。通过引入KL散度作为正则化项,贝叶斯CNN能够在模型训练过程中自然地考虑参数的不确定性,从而在面对数据的噪声和变化时,提供更加鲁棒的预测。本文通过在玩具数据集和真实世界的胸部X光图像数据集上的实验,验证了贝叶斯CNN的有效性,并探讨了其在实际应用中的潜力。
一、引言
在人工智能领域,分类是一项至关重要的任务,它在众多实际应用中发挥着关键作用。从金融领域的信用评分到医疗诊断,从手写字符识别到人脸识别,分类问题无处不在。本文将对不同领域的分类问题进行探讨,分析其输入输出特点,并深入研究分类的实现方法。
二、分类应用实例
-
信用评分
-
输入:收入、储蓄、职业、年龄、过往财务历史等信息。
-
输出:接受或拒绝。
-
医疗诊断
-
输入:当前症状、年龄、性别、过往医疗历史等。
-
输出:可能的疾病种类。
-
手写字符识别
-
输入:手写字符 "金"。
-
输出:识别结果。
-
人脸识别
-
输入:面部图像。
-
输出:对应的人物。
三、分类方法
-
基于回归的分类
-
以二分类为例,训练时将类别 1 表示为目标为 1,类别 2 表示为目标为 -1。测试时,接近 1 的归为类别 1,接近 -1 的归为类别 2。
-
多分类问题
-
以类别 1 目标为 1、类别 2 目标为 2、类别 3 目标为 3 等为例,说明多分类问题的复杂性。
-
理想的分类替代方案
-
函数(模型):若函数 g (x)>0,输出为类别 1;否则输出为类别 2。
-
损失函数:L (f) 为训练数据中函数结果错误的次数。
-
寻找最佳函数:例如感知机、支持向量机等。
四、从类别中获取概率
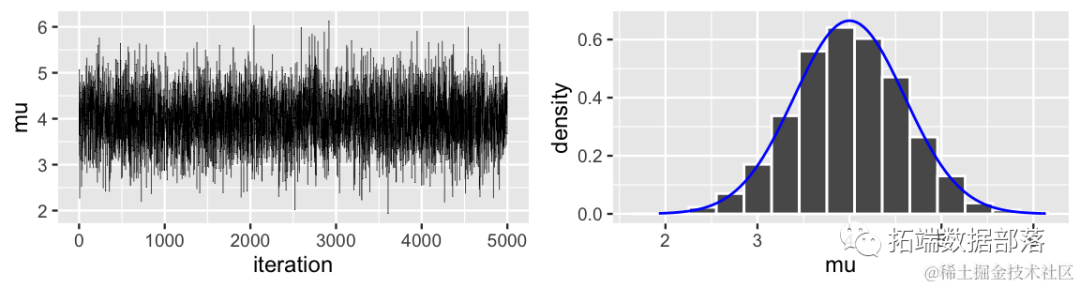
假设数据点是从高斯分布中采样得到,寻找背后的高斯分布以确定新数据点的概率。
五、最大似然估计
对于给定的 "水" 类型数据点 x1,x2,x3,...,x79,假设它们来自具有最大似然的高斯分布 (μ*,Σ*)。
-
高斯分布的概率密度函数用特定形式表示。
-
似然函数 L (μ,Σ) 为多个概率密度函数的乘积形式。
-
通过最大似然估计确定参数 μ*,Σ*=argmax (μ,Σ) L (μ,Σ),其中 μ* 有特定表达式。
六、分类应用
现在可以进行分类,例如对于 "水" 类型分类问题,有 f (μ1,Σ1)(x) 的表达式,其中 P (c1) 有特定值。类似地,对于另一类别有 f (μ2,Σ2)(x) 的表达式,其中 P (c2) 有特定值。如果 P (c1|x)>0.5,则 x 属于类别 1(水)。
贝叶斯卷积神经网络对数据的影响|附代码数据
在本研究中,我们探讨了KL权重在贝叶斯卷积神经网络(CNN)中对数据的影响。首先,我们使用标准化方法对数据进行预处理,以确保模型训练的有效性。
x = \text{Scaler}().\text{fit_transform}(x)
为了监控模型在每个训练周期后参数的不确定性,我们设计了一个回调函数PosteriorRecorder,用于记录后验标准差。
go
``````
class PosteriorRecorder(tf.keras.callbacks.Callback):def \_\_init\_\_(self, \*\*kwargs):super(PosteriorRecorder, self).\_\_init\_\_(\*\*kwargs)随后,我们对不同的KL权重进行了模型训练,并对结果进行了记录和分析。
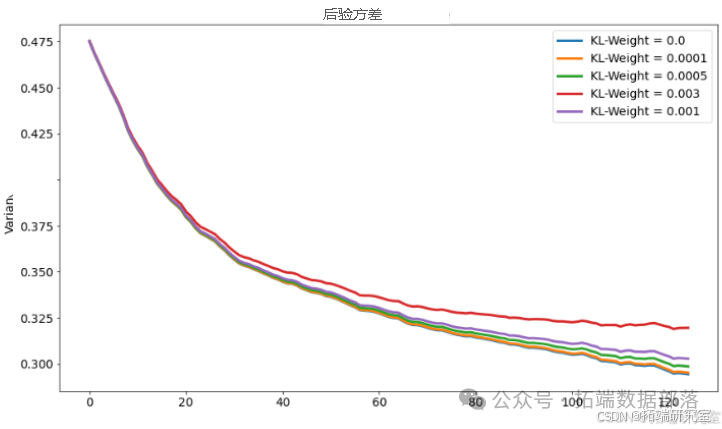
最后,我们绘制了不同KL权重下后验标准差的图表,以直观展示其对模型性能的影响。
go
scaler = Scaler()x = scaler.fit_transform(x)
点击标题查阅往期内容

R语言贝叶斯Metropolis-Hastings采样 MCMC算法理解和应用可视化案例

左右滑动查看更多
01
02
03
04
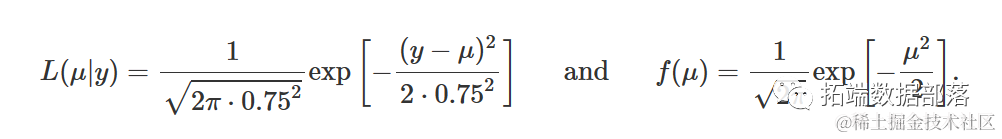
贝叶斯卷积神经网络在胸部X光图像数据集上的应用|附代码数据
在研究的第二部分,我们将贝叶斯CNN应用于真实数据集,以验证其在实际问题中的有效性。
go
``````
import warningswarnings.filterwarnings('ignore')import tensorflow as tf # 2.8.0import tensorflow_probability as tfp # 0.16接着,我们加载并预处理了胸部X光图像数据集,为模型训练做好准备。
go
``````
data\_path = 'data/chest\_xray/'train\_ds = tf.keras.utils.image\_dataset\_from\_directory(data_path)为了更好地理解数据集,我们探索了数据集中的图像和标签,并检查了类别分布。

我们定义了一个函数get_classes来统计数据集中各类别的数量,并通过可视化手段展示了类别分布。
go
def get\_classes(dataset: tf.data.Dataset) -> np.ndarray:counts = \[\]for image, label in dataset:counts.append(np.argmax(label, axis=-1))# 使用Seaborn库绘制类别分布图sns.countplot(class\_names\_test, ax=ax\[1\])ax\[1\].set\_title('Test set')fig.suptitle('Class distribution')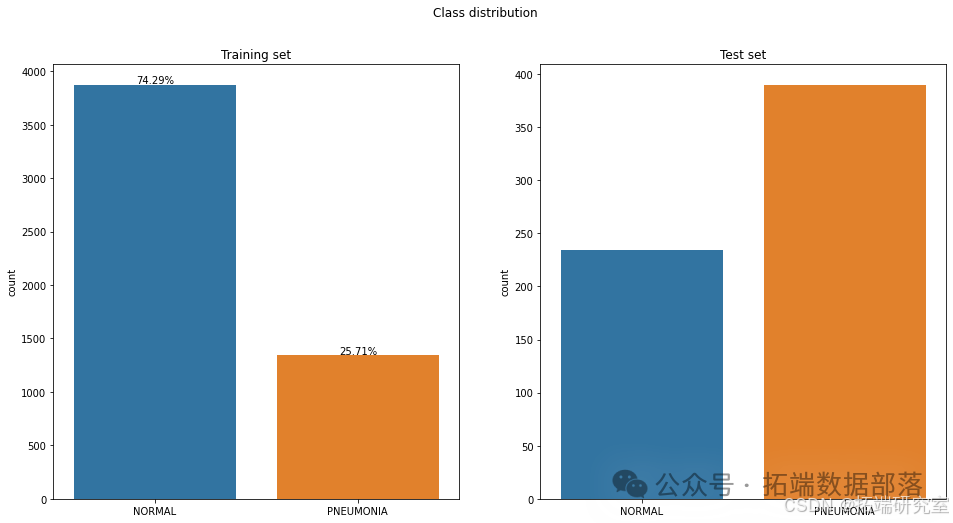
为了近似计算KL散度,我们定义了kl_approx函数,并将其应用于模型训练过程中。
go
``````
def kl\_approx(q, p, q\_tensor):return tf.reduce\_mean(q.log\_prob(q\_tensor) - p.log\_prob(q\_tensor))divergence\_fn = lambda q, p, q\_tensor: kl\_approx(q, p, q\_tensor) / (len(train\_classes))我们封装了重参数化层的创建过程,以简化模型构建的复杂性。
go
``````
def get\_convolution\_reparameterization(filters, kernel\_size, activation, strides=1, padding='SAME', prior=prior, divergence\_fn=divergence\_fn, name=None) -> tfpl.Convolution2DReparameterization:"""返回一个Convolution2DReparameterization层。"""return tfpl.Convolution2DReparameterization(filters=filters,kernel\_size=kernel\_size,activation=activation,strides=strides,padding=padding,kernel\_posterior\_fn=tfpl.default\_mean\_field\_normal\_fn(is\_singular=False),kernel\_prior\_fn=prior,kernel\_divergence\_fn=divergence\_fn,bias\_posterior\_fn=tfpl.default\_mean\_field\_normal\_fn(is\_singular=False),bias\_prior\_fn=prior,bias\_divergence\_fn=divergence_fn,name=name)通过构建残差块和特征提取器,我们构建了一个基于DenseNet121的贝叶斯ResNet模型,并对其进行了训练和评估。
go
``````
feature\_extractor = tf.keras.applications.DenseNet121(include\_top=False, input\_shape=(224, 224, 3), weights='imagenet')feature\_extractor.summary()# 构建贝叶斯ResNet模型# ...在模型训练过程中,我们使用了自定义的损失函数和评估指标,并应用了早停和学习率衰减等策略来优化训练效果。
go
``````
model.compile(optimizer=tf.keras.optimizers.Adam(learning\_rate=0.001), loss=nll, metrics=\[tf.keras.metrics.CategoricalAccuracy()\])callbacks = \[tf.keras.callbacks.EarlyStopping(monitor='val\_categorical\_accuracy', patience=7, restore\_best\_weights=True, verbose=1),tf.keras.callbacks.ReduceLROnPlateau(monitor='val\_categorical\_accuracy', min\_lr=1e-9, factor=0.1, patience=3, verbose=1)\]model.fit(train\_ds, epochs=64, validation\_data=test_ds, callbacks=callbacks)最后,我们对模型的预测结果进行了分析,以评估模型在真实数据上的性能。
go
def analyse\_model\_prediction(image, label=None, forward_passes=10):# ...# 分析模型预测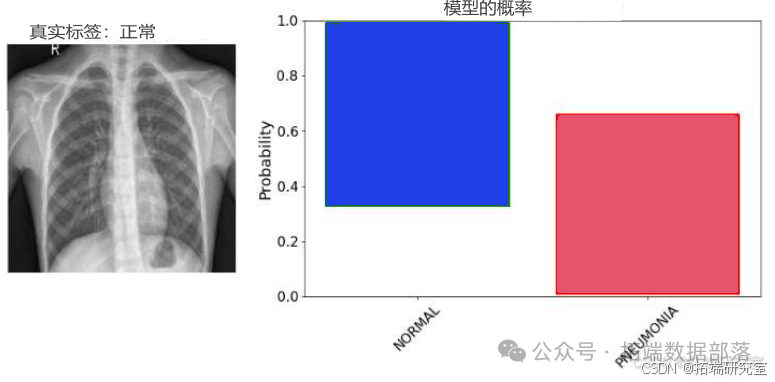
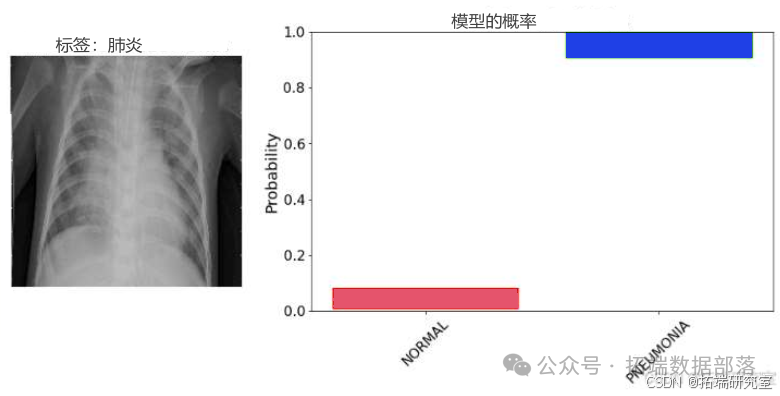
通过上述研究,我们展示了贝叶斯CNN在处理数据和真实数据时的有效性和灵活性。我们的研究为未来在更复杂的数据集上应用贝叶斯深度学习模型提供了有价值的参考。
关于分析师

在此对 Yuanchun Niu 对本文所作的贡献表示诚挚感谢,他完成了控制科学与工程专业的硕士研究生学位,专注深度学习、机器学习领域。擅长汇编语言、Python。

本文中分析的数据、代码**** 分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取全文完整代码数据资料。
本文选自《Python贝叶斯卷积神经网络分类胸部X光图像数据集实例》。
点击标题查阅往期内容
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
PYTHON银行机器学习:回归、随机森林、KNN近邻、决策树、高斯朴素贝叶斯、支持向量机SVM分析营销活动数据|数据分享
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
R语言中贝叶斯网络(BN)、动态贝叶斯网络、线性模型分析错颌畸形数据
python贝叶斯随机过程:马尔可夫链Markov-Chain,MC和Metropolis-Hastings,MH采样算法可视化
Python贝叶斯推断Metropolis-Hastings(M-H)MCMC采样算法的实现
Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言RSTAN MCMC:NUTS采样算法用LASSO 构建贝叶斯线性回归模型分析职业声望数据
R语言STAN贝叶斯线性回归模型分析气候变化影响北半球海冰范围和可视化检查模型收敛性
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户
R语言贝叶斯MCMC:用rstan建立线性回归模型分析汽车数据和可视化诊断
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
R语言贝叶斯Poisson泊松-正态分布模型分析职业足球比赛进球数
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
R语言实现MCMC中的Metropolis--Hastings算法与吉布斯采样
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计




