感知机
、
感知机
- 感知机是根据输入实例的特征向量 x x x 对其进行二㺯分尖的线性分光模型:
f ( x ) = sign ( w ⋅ x + b ) f(x)=\operatorname{sign}(w \cdot x+b) f(x)=sign(w⋅x+b)
感知机模型对应于输入空间 (特征空间) 中的分离超平面 w ⋅ x + b = 0 w \cdot x+b=0 w⋅x+b=0 。 - 感知机学习的策略是极小化损失函数:
min w , b L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) \min {w, b} L(w, b)=-\sum{x_{i} \in M} y_{i}\left(w \cdot x_{i}+b\right) w,bminL(w,b)=−xi∈M∑yi(w⋅xi+b)
损失函数对应于误分类点到分离超平面的总距离。 - 感知机学习算法是基于随机梯度下降法的对损失函数的最优化算法,有原始形式和对偶形式。算法简单且易于实现。原始形式中,首先任意选取一个超平面, 然后用梯度下降法不断极小化目标函数。在这个过程中一次随机选取一个误分类点使其梯度下降。
k ⩽ ( R γ ) 2 k \leqslant\left(\frac{R}{\gamma}\right)^{2} k⩽(γR)2
当训练数据集线性可分时,感知机学习算法存在无穷多个解,其解由于不同的初值或不同的迭代顺序而可能有所不同。
一分类模菖
f ( x ) = sign ( w ⋅ x + b ) sign ( x ) = { + 1 , x ⩾ 0 − 1 , x < 0 \begin{aligned} &f(x)=\operatorname{sign}(w \cdot x+b) \\ &\operatorname{sign}(x)= \begin{cases}+1, & x \geqslant 0 \\ -1, & x<0\end{cases} \end{aligned} f(x)=sign(w⋅x+b)sign(x)={+1,−1,x⩾0x<0
给定训练集:
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\} T={(x1,y1),(x2,y2),⋯,(xN,yN)}
定义感知机的损失函数
L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w, b)=-\sum_{x_{i} \in M} y_{i}\left(w \cdot x_{i}+b\right) L(w,b)=−xi∈M∑yi(w⋅xi+b)
算法
随机梯度下降法 Stochastic Gradient Descent
随机抽取一个点使其梯度下降。
w = w + η y i x i b = b + η y i \begin{aligned} &w=w+\eta y_{i} x_{i} \\ &b=b+\eta y_{i} \end{aligned} w=w+ηyixib=b+ηyi
当实例点被误分类,即位于分离超平面的错误侧,则调整 w , b w, b w,b 的值,使分离超平面向该无分类点的一侧移动,直至误分类点被正确分类
三要素分析
模型
输入空间: X ⊆ R n \mathcal X\sube \bf R^n X⊆Rn
输出空间: Y = + 1 , − 1 \mathcal Y={+1,-1} Y=+1,−1
决策函数: f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign (w\cdot x+b) f(x)=sign(w⋅x+b)
策略
确定学习策略就是定义**(经验)**损失函数并将损失函数最小化。
注意这里提到了经验 ,所以学习是base在训练数据集上的操作
损失函数选择
损失函数的一个自然选择是误分类点的总数,但是,这样的损失函数不是参数 w , b w,b w,b的连续可导函数,不易优化
损失函数的另一个选择是误分类点到超平面 S S S的总距离,这是感知机所采用的
感知机学习的经验风险函数(损失函数)
L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w,b)=-\sum_{x_i\in M}y_i(w\cdot x_i+b) L(w,b)=−xi∈M∑yi(w⋅xi+b)
其中 M M M是误分类点的集合
给定训练数据集 T T T,损失函数 L ( w , b ) L(w,b) L(w,b)是 w w w和 b b b的连续可导函数
算法
原始形式
输入: T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ... , ( x N , y N ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \ldots,\left(x_{N}, y_{N}\right)\right\} T={(x1,y1),(x2,y2),...,(xN,yN)}
x i ∈ X = R n , y i ∈ Y = { − 1 , + 1 } , i = 1 , 2 , ... , N ; 0 < η ⩽ 1 x_{i} \in \mathcal{X}=\mathbf{R}^{\mathbf{n}}, \mathbf{y}_{\mathbf{i}} \in \mathcal{Y}=\{-1,+1\}, i=1,2, \ldots, \mathcal{N} ; 0<\eta \leqslant 1 xi∈X=Rn,yi∈Y={−1,+1},i=1,2,...,N;0<η⩽1输出: w , b ; f ( x ) = s i g n ( w ⋅ x + b ) w,b;f(x)=sign(w\cdot x+b) w,b;f(x)=sign(w⋅x+b)
选取初值 w 0 , b 0 w_0,b_0 w0,b0
训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
如果 y i ( w ⋅ x i + b ) ⩽ 0 y_i(w\cdot x_i+b)\leqslant 0 yi(w⋅xi+b)⩽0
w ← w + η y i x i w \leftarrow w+\eta y_{i} x_{i} w←w+ηyixi
b ← b + η y i b \leftarrow b+\eta y_{i} b←b+ηyi转至(2),直至训练集中没有误分类点
注意这个原始形式中的迭代公式,可以对 x x x补1,将 w w w和 b b b合并在一起,合在一起的这个叫做扩充权重向量,书上有提到。
对偶形式
对偶形式的基本思想是将 w w w和 b b b表示为实例 x i x_i xi和标记 y i y_i yi的线性组合的形式,通过求解其系数而求得 w w w和 b b b。
算法流程:
输入: T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ... , ( x N , y N ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \ldots,\left(x_{N}, y_{N}\right)\right\} T={(x1,y1),(x2,y2),...,(xN,yN)}
x i ∈ X = R n , y i ∈ Y = { − 1 , + 1 } , i = 1 , 2 , ... , N ; 0 < η ⩽ 1 x_{i} \in \mathcal{X}=\mathbf{R}^{\mathbf{n}}, \mathbf{y}_{\mathbf{i}} \in \mathcal{Y}=\{-1,+1\}, i=1,2, \ldots, \mathcal{N} ; 0<\eta \leqslant 1 xi∈X=Rn,yi∈Y={−1,+1},i=1,2,...,N;0<η⩽1输出:
α , b ; f ( x ) = sign ( ∑ j = 1 N α j y j x j ⋅ x + b ) α > = ( α 1 , α 2 , ⋯ , α N ) T \begin{aligned} \alpha, b ; f(x) &=\operatorname{sign}\left(\sum_{j=1}^{N} \alpha_{j} y_{j} x_{j} \cdot x+b\right) \\ \alpha >&=\left(\alpha_{1}, \alpha_{2}, \cdots, \alpha_{N}\right)^{T} \end{aligned} α,b;f(x)α>=sign(j=1∑Nαjyjxj⋅x+b)=(α1,α2,⋯,αN)T
α ← 0 , b ← 0 \alpha \leftarrow 0,b\leftarrow 0 α←0,b←0
训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
如果 y i ( ∑ j = 1 N α j y j x j ⋅ x + b ) ⩽ 0 y_i\left(\sum_{j=1}^N\alpha_jy_jx_j\cdot x+b\right) \leqslant 0 yi(∑j=1Nαjyjxj⋅x+b)⩽0
α i ← α i + η b ← b + η y i \alpha_i\leftarrow \alpha_i+\eta \nonumber\\ b\leftarrow b+\eta y_i αi←αi+ηb←b+ηyi
- 转至(2),直至训练集中没有误分类点
Gram matrix
对偶形式中,训练实例仅以内积的形式出现。
为了方便可预先将训练集中的实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是所谓的Gram矩阵
G = x i ⋅ x j N × N G=\leftx_{i} \\cdot x_{j}\\right_{N \times N} G=xi⋅xjN×N
相关问题
题中问考虑损失函数最值的时候,不会有影响么?
-
感知机处理线性可分数据集,二分类, Y = { + 1 , − 1 } \mathcal{Y}=\{+1,-1\} Y={+1,−1},所以涉及到的乘以 y i y_{i} yi 的操作实际贡献的是符号;
-
损失函数 L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w,b)=-\sum_{x_i\in M}y_i(w\cdot x_i+b) L(w,b)=−∑xi∈Myi(w⋅xi+b),其中 M M M 是错分的点集合,线性可分的数据集肯定能找到超平面 S S S, 所以这个损失函数最值是0。
-
如果正确分类, y i ( w ⋅ x i + b ) = ∣ w ⋅ x i + b ∣ y_i(w\cdot x_i+b)=|w\cdot x_i+b| yi(w⋅xi+b)=∣w⋅xi+b∣ ,错误分类的话,为了保证正数就加个负号,这就是损失函数里面那个负号,这个就是函数间隔;
-
1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1 用来归一化超平面法向量,得到几何间隔,也就是点到超平面的距离, 函数间隔和几何间隔的差异在于同一个超平面 ( w , b ) (w,b) (w,b) 参数等比例放大成 ( k w , k b ) (kw,kb) (kw,kb) 之后,虽然表示的同一个超平面,但是点到超平面的函数间隔也放大了,但是几何间隔是不变的;
-
具体算法实现的时候, w w w要初始化,然后每次迭代针对错分点进行调整,既然要初始化,那如果初始化个 ∣ ∣ w ∣ ∣ = 1 ||w||=1 ∣∣w∣∣=1 的情况也就不用纠结了,和不考虑 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1 是一样的了;
-
针对错分点是这么调整的
w ← w + η y i x i b ← b + η y i \begin{aligned} w&\leftarrow w+\eta y_ix_i\\ b&\leftarrow b+\eta y_i \end{aligned} wb←w+ηyixi←b+ηyi
前面说了 y i y_i yi 就是个符号,那么感知机就可以解释为针对误分类点,通过调整 w , b w,b w,b 使得超平面向该误分类点一侧移动,迭代这个过程最后全分类正确;
-
感知机的解不唯一,和初值有关系,和误分类点调整顺序也有关系;
-
这么调整就能找到感知机的解?能,Novikoff还证明了,通过有限次搜索能找到将训练数据完全正确分开的分离超平面。
例子
iris数据集分类实战
数据集查看
python
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# load data
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = [
'sepal length', 'sepal width', 'petal length', 'petal width', 'label'
]
df.label.value_counts()
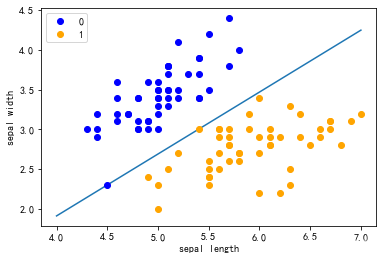
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()- 数据集显示

python
data = np.array(df.iloc[:100, [0, 1, -1]])
X, y = data[:,:-1], data[:,-1]
y = np.array([1 if i == 1 else -1 for i in y])
# 数据线性可分,二分类数据
# 此处为一元一次线性方程
class Model:
def __init__(self):
self.w = np.ones(len(data[0]) - 1, dtype=np.float32)
self.b = 0
self.l_rate = 0.1
# self.data = data
def sign(self, x, w, b):
y = np.dot(x, w) + b
return y
# 随机梯度下降法
def fit(self, X_train, y_train):
is_wrong = False
while not is_wrong:
wrong_count = 0
for d in range(len(X_train)):
X = X_train[d]
y = y_train[d]
if y * self.sign(X, self.w, self.b) <= 0:
self.w = self.w + self.l_rate * np.dot(y, X)
self.b = self.b + self.l_rate * y
wrong_count += 1
if wrong_count == 0:
is_wrong = True
return 'Perceptron Model!'
perceptron = Model()
perceptron.fit(X, y)
x_points = np.linspace(4, 7, 10)
y_ = -(perceptron.w[0] * x_points + perceptron.b) / perceptron.w[1]
plt.plot(x_points, y_)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()显示结果
sklearn 实战感知机
python
import sklearn
from sklearn.linear_model import Perceptron
clf = Perceptron(fit_intercept=True,
max_iter=1000,
shuffle=True)
clf.fit(X, y)
print(clf.coef_)
# 截距 Constants in decision function.
print(clf.intercept_)
# 画布大小
plt.figure(figsize=(10,10))
# 中文标题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('鸢尾花线性数据示例')
plt.scatter(data[:50, 0], data[:50, 1], c='b', label='Iris-setosa',)
plt.scatter(data[50:100, 0], data[50:100, 1], c='orange', label='Iris-versicolor')
# 画感知机的线
x_ponits = np.arange(4, 8)
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)
# 其他部分
plt.legend() # 显示图例
plt.grid(False) # 不显示网格
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()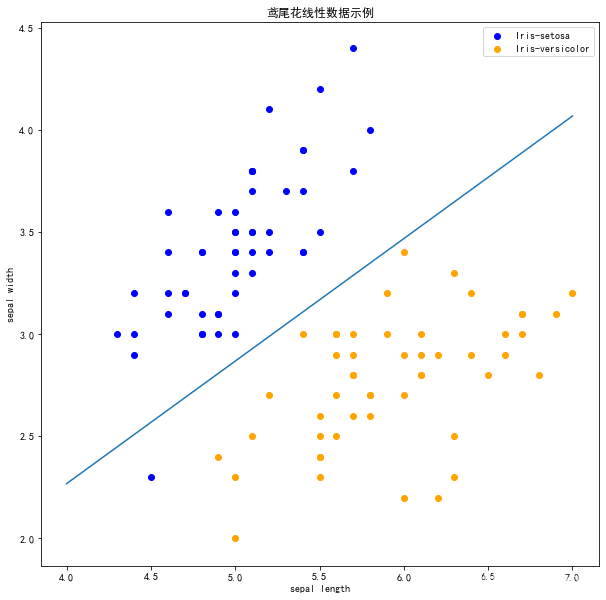
在上图中,有一个位于左下角的蓝点没有被正确分类,这是因为 SKlearn 的 Perceptron 实例中有一个tol参数。
tol 参数规定了如果本次迭代的损失和上次迭代的损失之差小于一个特定值时,停止迭代。所以我们需要设置 tol=None 使之可以继续迭代:
python
clf = Perceptron(fit_intercept=True,
max_iter=1000,
tol=None,
shuffle=True)
clf.fit(X, y)
# 画布大小
plt.figure(figsize=(10,10))
# 中文标题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('鸢尾花线性数据示例')
plt.scatter(data[:50, 0], data[:50, 1], c='b', label='Iris-setosa',)
plt.scatter(data[50:100, 0], data[50:100, 1], c='orange', label='Iris-versicolor')
# 画感知机的线
x_ponits = np.arange(4, 8)
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)
# 其他部分
plt.legend() # 显示图例
plt.grid(False) # 不显示网格
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()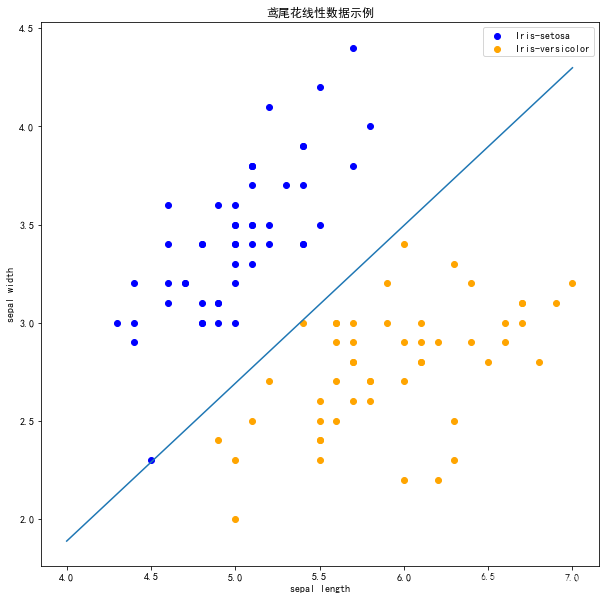
习题解答
习题2.1
Minsky 与 Papert 指出:感知机因为是线性模型,所以不能表示复杂的函数,如异或 (XOR)。验证感知机为什么不能表示异或。
- 列出异或函数(XOR)的输入和输出;
- 使用图例法证明异或问题是线性不可分的;
- 使用反证法证明感知机无法表示异或。
解题步骤
异或函数(XOR)的输入和输出
对于异或函数(XOR),全部的输入与对应的输出如下:
x 1 x 2 y = x 1 ⊕ x 2 0 0 − 1 0 1 1 1 0 1 1 1 − 1 \begin{array}{|c|c|c|} \hline x_{1} & x_{2} & y=x_{1} \oplus x_{2} \\ \hline 0 & 0 & -1 \\ \hline 0 & 1 & 1 \\ \hline 1 & 0 & 1 \\ \hline 1 & 1 & -1 \\ \hline \end{array} x10011x20101y=x1⊕x2−111−1
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 使用Dataframe表示异或的输入与输出数据
x1 = [0, 0, 1, 1]
x2 = [0, 1, 0, 1]
y = [-1, 1, 1, -1]
x1 = np.array(x1)
x2 = np.array(x2)
y = np.array(y)
data = np.c_[x1, x2, y]
data = pd.DataFrame(data, index=None, columns=['x1', 'x2', 'y'])
data.head()
# 获取正类别(y=1)的数据
positive = data.loc[data['y'] == 1]
# 获取负类别(y=-1)的数据
negative = data.loc[data['y'] == -1]
# 绘制数据图
# 绘制坐标轴
plt.xlim(-0.5, 1.5)
plt.ylim(-0.5, 1.5)
plt.xticks([-0.5, 0, 1, 1.5])
plt.yticks([-0.5, 0, 1, 1.5])
# 添加坐标轴文字
plt.xlabel("x1")
plt.ylabel("x2")
# 绘制正、负样本点
plt.plot(positive['x1'], positive['x2'], "ro")
plt.plot(negative['x1'], negative['x2'], "bx")
# 添加图示
plt.legend(['Positive', 'Negative'])
plt.show()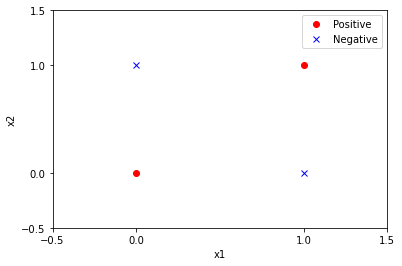
从上图可以看出,无法使用一条直线将两类样本分开,所以异或问题是线性不可分的
下一步,使用感知机模型进行测试w,b
python
from sklearn.linear_model import Perceptron
import numpy as np
# 构造异或问题的训练数据集
X_train = np.array([[1, 1], [1, 0], [0, 1], [0, 0]])
y = np.array([-1, 1, 1, -1])
# 使用sklearn的Perceptron类构建感知机模型
perceptron_model = Perceptron()
# 进行模型训练
perceptron_model.fit(X_train, y)
# 打印模型参数
print("感知机模型的参数:w=", perceptron_model.coef_[
0], "b=", perceptron_model.intercept_[0])
python
感知机模型的参数:w= [0. 0.] b= 0.0反证法
f ( x ) = sign ( w ⋅ x + b ) f(x)=\operatorname{sign}(w \cdot x+b) f(x)=sign(w⋅x+b)
sign ( x ) = { + 1 , x ⩾ 0 − 1 , x < 0 \operatorname{sign}(x)= \begin{cases}+1, & x \geqslant 0 \\ -1, & x<0\end{cases} sign(x)={+1,−1,x⩾0x<0
假设咸知机模型可以表示异或问题,即满足异或函数(XOR)输入与输出的情况(见第 1 步 1 步 1步 )。假设 x x x 向量只有两个维度 x 1 , x 2 x_{1}, x_{2} x1,x2 :
- 根据 x 1 = 0 , x 2 = 0 , f ( x ) = − 1 x_{1}=0, x_{2}=0, f(x)=-1 x1=0,x2=0,f(x)=−1 ,则 w ⋅ x + b < 0 w \cdot x+b<0 w⋅x+b<0 ,可得 b < 0 b<0 b<0 ;
- 根据 x 1 = 0 , x 2 = 1 , f ( x ) = 1 x_{1}=0, x_{2}=1, f(x)=1 x1=0,x2=1,f(x)=1 ,则 w 2 + b > 0 w_{2}+b>0 w2+b>0 ,结合 b < 0 b<0 b<0 ,可得 w 2 > − b > 0 w_{2}>-b>0 w2>−b>0;
- 根据 x 1 = 1 , x 2 = 0 , f ( x ) = 1 x_{1}=1, x_{2}=0, f(x)=1 x1=1,x2=0,f(x)=1, 则 w 1 + b > 0 w_{1}+b>0 w1+b>0 ,结合 b < 0 b<0 b<0 ,可得 w 1 > − b > 0 w_{1}>-b>0 w1>−b>0;
- 根据 x 1 = 1 , x 2 = 1 x_{1}=1, x_{2}=1 x1=1,x2=1 ,并结合 w 1 + b > 0 、 w 2 > 0 w_{1}+b>0 、 w_{2}>0 w1+b>0、w2>0 ,则 w 1 + w 2 + b > 0 w_{1}+w_{2}+b>0 w1+w2+b>0 ,可得 f ( x ) = 1 f(x)=1 f(x)=1 ,与异或条件中的 f ( x ) = − 1 f(x)=-1 f(x)=−1 矛盾。
- 所以假设不成立,原命题成立,即感知机模型不能表示异或。
习题2.2
解题步骤在上面的iris数据中已经体现。
python
import numpy as np
from matplotlib import pyplot as plt
%matplotlib tk
class Perceptron:
def __init__(self, X, Y, lr=0.001, plot=True):
"""
初始化感知机
:param X: 特征向量
:param Y: 类别
:param lr: 学习率
:param plot: 是否绘制图形
"""
self.X = X
self.Y = Y
self.lr = lr
self.plot = plot
if plot:
self.__model_plot = self._ModelPlot(self.X, self.Y)
self.__model_plot.open_in()
def fit(self):
# (1)初始化weight, b
weight = np.zeros(self.X.shape[1])
b = 0
# 训练次数
train_counts = 0
# 分类错误标识
mistake_flag = True
while mistake_flag:
# 开始前,将mistake_flag设置为False,用于判断本次循环是否有分类错误
mistake_flag = False
# (2)从训练集中选取x,y
for index in range(self.X.shape[0]):
if self.plot:
self.__model_plot.plot(weight, b, train_counts)
# 损失函数
loss = self.Y[index] * (weight @ self.X[index] + b)
# (3)如果损失函数小于0,则该点是误分类点
if loss <= 0:
# 更新weight, b
weight += self.lr * self.Y[index] * self.X[index]
b += self.lr * self.Y[index]
# 训练次数加1
train_counts += 1
print("Epoch {}, weight = {}, b = {}, formula: {}".format(
train_counts, weight, b, self.__model_plot.formula(weight, b)))
# 本次循环有误分类点(即分类错误),置为True
mistake_flag = True
break
if self.plot:
self.__model_plot.close()
# (4)直至训练集中没有误分类点
return weight, b
class _ModelPlot:
def __init__(self, X, Y):
self.X = X
self.Y = Y
@staticmethod
def open_in():
# 打开交互模式,用于展示动态交互图
plt.ion()
@staticmethod
def close():
# 关闭交互模式,并显示最终的图形
plt.ioff()
plt.show()
def plot(self, weight, b, epoch):
plt.cla()
# x轴表示x1
plt.xlim(0, np.max(self.X.T[0]) + 1)
# y轴表示x2
plt.ylim(0, np.max(self.X.T[1]) + 1)
# 画出散点图,并添加图示
scatter = plt.scatter(self.X.T[0], self.X.T[1], c=self.Y)
plt.legend(*scatter.legend_elements())
if True in list(weight == 0):
plt.plot(0, 0)
else:
x1 = -b / weight[0]
x2 = -b / weight[1]
# 画出分离超平面
plt.plot([x1, 0], [0, x2])
# 绘制公式
text = self.formula(weight, b)
plt.text(0.3, x2 - 0.1, text)
plt.title('Epoch %d' % epoch)
plt.pause(0.01)
@staticmethod
def formula(weight, b):
text = 'x1 ' if weight[0] == 1 else '%d*x1 ' % weight[0]
text += '+ x2 ' if weight[1] == 1 else (
'+ %d*x2 ' % weight[1] if weight[1] > 0 else '- %d*x2 ' % -weight[1])
text += '= 0' if b == 0 else ('+ %d = 0' %
b if b > 0 else '- %d = 0' % -b)
return text
python
X = np.array([[3, 3], [4, 3], [1, 1]])
Y = np.array([1, 1, -1])
model = Perceptron(X, Y, lr=1)
weight, b = model.fit()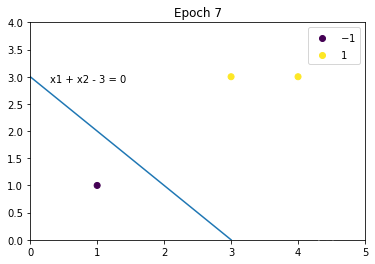
习题2.3
证明以下定理:样本集线性可分的充分必要条件是正实例点所构成的凸壳与负实例点所构成的凸壳互不相交。
- 写出凸壳和线性可分的定义
- 证明必要性:线性可分\Rightarrow⇒凸壳不相交
- 证明充分性:凸壳不相交\Rightarrow⇒线性可分
凸壳
设集合 S ⊂ R n S \subset R^{n} S⊂Rn ,是由 R n R^{n} Rn 中的 k k k 个点所组成的集合,即 S = { x 1 , x 2 , ⋯ , x k } S=\left\{x_{1}, x_{2}, \cdots, x_{k}\right\} S={x1,x2,⋯,xk} 。定义 S S S 的凸壳 conv ( S ) \operatorname{conv}(S) conv(S) 为:
conv ( S ) = { x = ∑ i = 1 k λ i x i ∣ ∑ i = 1 k λ i = 1 , λ i ⩾ 0 , i = 1 , 2 , ⋯ , k } \operatorname{conv}(S)=\left\{x=\sum_{i=1}^{k} \lambda_{i} x_{i} \mid \sum_{i=1}^{k} \lambda_{i}=1, \lambda_{i} \geqslant 0, i=1,2, \cdots, k\right\} conv(S)={x=i=1∑kλixi∣i=1∑kλi=1,λi⩾0,i=1,2,⋯,k}
线性可分
给定一个数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{n}, y_{n}\right)\right\} T={(x1,y1),(x2,y2),⋯,(xn,yn)}
其中 x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , n x_{i} \in \mathcal{X}=R_{n}, y_{i} \in \mathcal{Y}=\{+1,-1\}, i=1,2, \cdots, n xi∈X=Rn,yi∈Y={+1,−1},i=1,2,⋯,n ,如果存在某个超平面 S S S
w ⋅ x + b = 0 w \cdot x+b=0 w⋅x+b=0
能够将数据集的正实例点和负实例点完全正确划分到超平面的两侧,即对所有 y i = + 1 y_{i}=+1 yi=+1 的实例 i i i ,有 w ⋅ x i + b > 0 w \cdot x_{i}+b>0 w⋅xi+b>0 ,对 y i = − 1 y_{i}=-1 yi=−1 的实例 i i i ,有 w ⋅ x i + b < 0 w \cdot x_{i}+b<0 w⋅xi+b<0 ,则称数据集 T T T 为线性可分 数据集,否则称数据集 T T T 线性不可分。
线性可分证明凸壳不相交
证明思路(反证法):
假设原命题不成立:样本集线性可分,正实例点所构成的凸壳与负实例点所构成的凸壳相交
条件推理
发现矛盾,得出原命题成立
- 假设原命题不成立:
设数据集 T T T 中的正例点集为 S + , S + S_{+} , S_{+} S+,S+的凸壳为 conv ( S + ) \operatorname{conv}\left(S_{+}\right) conv(S+),负实例点集为 S − , S − S_{-} , S_{-} S−,S−的凸壳为 conv ( S − ) \operatorname{conv}\left(S_{-}\right) conv(S−)。
假设样本集线性可分,正实例点所构成的凸壳与负实例点所构成的凸壳相交,即存在某个元素 s s s ,同时满足 s ∈ conv ( S + ) s \in \operatorname{conv}\left(S_{+}\right) s∈conv(S+)和 s ∈ conv ( S − ) s \in \operatorname{conv}\left(S_{-}\right) s∈conv(S−)。 - 条件推理:
若数据集 T T T 是线性可分的,根据线性可分的定义,则存在一个超平面能够将 S + S_{+} S+和 S − S_{-} S−完全分离:
w ⋅ x + b = 0 w \cdot x+b=0 w⋅x+b=0
对于所有的正例点 x i x_{i} xi ,有
w ⋅ x i + b = ε i > 0 , i = 1 , 2 , ⋯ , ∣ S + ∣ w \cdot x_{i}+b=\varepsilon_{i}>0, \quad i=1,2, \cdots,\left|S_{+}\right| w⋅xi+b=εi>0,i=1,2,⋯,∣S+∣
根据凸壳的定义,对于 conv ( S + ) \operatorname{conv}\left(S_{+}\right) conv(S+)中的元素 s + s_{+} s+,有
w ⋅ s + + b = w ⋅ ( ∑ i = 1 ∣ S + ∣ λ i x i ) + b = ( ∑ i = 1 ∣ S + ∣ λ i ( ε i − b ) ) + b = ∑ i = 1 ∣ S + ∣ λ i ε i − ( b ∑ i = 1 ∣ S + ∣ λ i ) + b ( ∵ ∑ i = 1 ∣ S + ∣ λ i = 1 ) = ∑ i = 1 ∣ S + ∣ λ i ε i \begin{aligned} w \cdot s_{+}+b &=w \cdot\left(\sum_{i=1}^{\left|S_{+}\right|} \lambda_{i} x_{i}\right)+b \\ &=\left(\sum_{i=1}^{\left|S_{+}\right|} \lambda_{i}\left(\varepsilon_{i}-b\right)\right)+b \\ &=\sum_{i=1}^{\left|S_{+}\right|} \lambda_{i} \varepsilon_{i}-\left(b \sum_{i=1}^{\left|S_{+}\right|} \lambda_{i}\right)+b \quad\left(\because \sum_{i=1}^{\left|S_{+}\right|} \lambda_{i}=1\right) \\ &=\sum_{i=1}^{\left|S_{+}\right|} \lambda_{i} \varepsilon_{i} \end{aligned} w⋅s++b=w⋅ i=1∑∣S+∣λixi +b= i=1∑∣S+∣λi(εi−b) +b=i=1∑∣S+∣λiεi− bi=1∑∣S+∣λi +b ∵i=1∑∣S+∣λi=1 =i=1∑∣S+∣λiεi
因此 w ⋅ s + + b = ∑ i = 1 ∣ S + ∣ λ i ε i > 0 w \cdot s_{+}+b=\sum_{i=1}^{\left|S_{+}\right|} \lambda_{i} \varepsilon_{i}>0 w⋅s++b=∑i=1∣S+∣λiεi>0 。
同理对于 S − S_{-} S−中的元素 s − s_{-} s−,有 w ⋅ s − + b = ∑ i = 1 ∣ S − ∣ λ i ε i < 0 w \cdot s_{-}+b=\sum_{i=1}^{\left|S_{-}\right|} \lambda_{i} \varepsilon_{i}<0 w⋅s−+b=∑i=1∣S−∣λiεi<0 - 找出矛盾,得出原命题成立:
根据条件推理,当 s ∈ conv ( S + ) s \in \operatorname{conv}\left(S_{+}\right) s∈conv(S+)有 w ⋅ s + b = ∑ i = 1 ∣ S + ∣ λ i ε i > 0 w \cdot s+b=\sum_{i=1}^{\left|S_{+}\right|} \lambda_{i} \varepsilon_{i}>0 w⋅s+b=∑i=1∣S+∣λiεi>0 ,当 s ∈ conv ( S − ) s \in \operatorname{conv}\left(S_{-}\right) s∈conv(S−)有 w ⋅ s + b = ∑ i = 1 ∣ S − ∣ λ i ε i < 0 w \cdot s+b=\sum_{i=1}^{\left|S_{-}\right|} \lambda_{i} \varepsilon_{i}<0 w⋅s+b=∑i=1∣S−∣λiεi<0 ,既 s s s 不可能同时满足若 s ∈ conv ( S + ) s \in \operatorname{conv}\left(S_{+}\right) s∈conv(S+)和 s ∈ conv ( S − ) s \in \operatorname{conv}\left(S_{-}\right) s∈conv(S−),这与假设命题 矛盾。
因此,原命题成立,当样本线性可分时, conv ( S + ) \operatorname{conv}\left(S_{+}\right) conv(S+)和 conv ( S − ) \operatorname{conv}\left(S_{-}\right) conv(S−)必不相交。必要性得证。
证明充分性:凸壳不相交\Rightarrow⇒线性可分
证明思路:
根据凸壳不相交,找到一个超平面
证明这个超平面可将两个互不相交的凸壳分隔开(反证法)
上述超平面可以将凸壳分隔开,则样本集满足线性可分
证明步骤
- 根据凸壳不相交,找到一个超平面:
设数据集 T T T 中的正例点集为 S + , S + S_{+} , S_{+} S+,S+的凸壳为 conv ( S + ) \operatorname{conv}\left(S_{+}\right) conv(S+),负实例点集为 S − , S − S_{-} , S_{-} S−,S−的凸壳为 conv ( S − ) \operatorname{conv}\left(S_{-}\right) conv(S−),且conv ( S + ) \left(S_{+}\right) (S+)与 conv ( S − ) \operatorname{conv}\left(S_{-}\right) conv(S−)不相交。
定义两个点 x 1 , x 2 x_{1}, x_{2} x1,x2 的距离为
dist ( x 1 , x 2 ) = ∥ x 1 − x 2 ∥ 2 \operatorname{dist}\left(x_{1}, x_{2}\right)=\left\|x_{1}-x_{2}\right\|{2} dist(x1,x2)=∥x1−x2∥2
定义 conv ( S + ) 、 conv ( S − ) \operatorname{conv}\left(S{+}\right) 、 \operatorname{conv}\left(S_{-}\right) conv(S+)、conv(S−)的距离是,分别处于两个凸壳集合中的点的距离最小值:
dist ( conv ( S + ) , conv ( S − ) ) = min ∥ s + − s − ∥ 2 s + ∈ conv ( S + ) , s − ∈ conv ( S − ) \operatorname{dist}\left(\operatorname{conv}\left(S_{+}\right), \operatorname{conv}\left(S_{-}\right)\right)=\min \left\|s_{+}-s_{-}\right\|{2} \quad s{+} \in \operatorname{conv}\left(S_{+}\right), s_{-} \in \operatorname{conv}\left(S_{-}\right) dist(conv(S+),conv(S−))=min∥s+−s−∥2s+∈conv(S+),s−∈conv(S−)
记最小值点分别为 x + , x − x_{+}, x_{-} x+,x−, 即:
dist ( conv ( S + ) , conv ( S − ) ) = dist ( x + , x − ) x + ∈ conv ( S + ) , x − ∈ conv ( S − ) \operatorname{dist}\left(\operatorname{conv}\left(S_{+}\right), \operatorname{conv}\left(S_{-}\right)\right)=\operatorname{dist}\left(x_{+}, x_{-}\right) \quad x_{+} \in \operatorname{conv}\left(S_{+}\right), x_{-} \in \operatorname{conv}\left(S_{-}\right) dist(conv(S+),conv(S−))=dist(x+,x−)x+∈conv(S+),x−∈conv(S−)
定义以 ( x + , x − ) \left(x_{+}, x_{-}\right) (x+,x−)为法线,且过两点中点的超平面为 f ( x ∣ w , b ) = 0 f(x \mid w, b)=0 f(x∣w,b)=0, 则参数为:
f ( x ∣ w , b ) = ( x + − x − ) T ( x − x + + x − 2 ) { w = ( x + − x − ) T b = − 1 2 ( ∥ x + ∥ 2 2 − ∥ x − ∥ 2 2 ) \begin{aligned} f(x \mid w, b) &=\left(x_{+}-x_{-}\right)^{T}\left(x-\frac{x_{+}+x_{-}}{2}\right) \\ \left\{\begin{aligned} w &=\left(x_{+}-x_{-}\right)^{T} \\ b &=-\frac{1}{2}\left(\left\|x_{+}\right\|{2}^{2}-\left\|x{-}\right\|_{2}^{2}\right) \end{aligned}\right. \end{aligned} f(x∣w,b)⎩ ⎨ ⎧wb=(x+−x−)T=−21(∥x+∥22−∥x−∥22)=(x+−x−)T(x−2x++x−) - 证明这个超平面可将两个互不相交的凸壳分隔开 (反证法)
若某个超平面可将两个互不相交的凸壳分隔开,则 f ( x ) ≥ 0 , x ∈ conv ( S + ) f(x) \geq 0, x \in \operatorname{conv}\left(S_{+}\right) f(x)≥0,x∈conv(S+)且 f ( x ) ≤ 0 , x ∈ conv ( S − ) f(x) \leq 0, x \in \operatorname{conv}\left(S_{-}\right) f(x)≤0,x∈conv(S−)。
f ( x ) = ( x + − x − ) T ( x − x + + x − 2 ) = ( x + − x − ) T ( x + x + − x + − x + + x − 2 ) = ( x + − x − ) T ( x − x + + x + − x − 2 ) = ( x + − x − ) T ( x − x + ) + ∥ x + − x − ∥ 2 2 2 \begin{aligned} f(x) &=\left(x_{+}-x_{-}\right)^{T}\left(x-\frac{x_{+}+x_{-}}{2}\right) \\ &=\left(x_{+}-x_{-}\right)^{T}\left(x+x_{+}-x_{+}-\frac{x_{+}+x_{-}}{2}\right) \\ &=\left(x_{+}-x_{-}\right)^{T}\left(x-x_{+}+\frac{x_{+}-x_{-}}{2}\right) \\ &=\left(x_{+}-x_{-}\right)^{T}\left(x-x_{+}\right)+\frac{\left\|x_{+}-x_{-}\right\|{2}^{2}}{2} \end{aligned} f(x)=(x+−x−)T(x−2x++x−)=(x+−x−)T(x+x+−x+−2x++x−)=(x+−x−)T(x−x++2x+−x−)=(x+−x−)T(x−x+)+2∥x+−x−∥22
假设原命题不成立:当 x ∈ conv ( S + ) x \in \operatorname{conv}\left(S{+}\right) x∈conv(S+)时,假设 f ( x ) < 0 f(x)<0 f(x)<0 ,则有:
( x + − x − ) T ( x − x + ) < 0 \left(x_{+}-x_{-}\right)^{T}\left(x-x_{+}\right)<0 (x+−x−)T(x−x+)<0
设点 u = x + + t ( x − x + ) , t ∈ 0 , 1 u=x_{+}+t\left(x-x_{+}\right), t \in0,1 u=x++t(x−x+),t∈0,1 ,即 u u u 在 x + x_{+} x+和 x x x 的线段上。根据凸壳定义, u ∈ conv ( S + ) u \in \operatorname{conv}\left(S_{+}\right) u∈conv(S+)。则 u u u 和 x − x_{-} x−距离的平方为:
g ( t ) = ∥ u − x − ∥ 2 2 = ∥ x + + t ( x − x + ) − x − ∥ 2 2 \begin{aligned} g(t) &=\left\|u-x_{-}\right\|{2}{ }^{2} \\ &=\left\|x{+}+t\left(x-x_{+}\right)-x_{-}\right\|_{2}{ }^{2} \end{aligned} g(t)=∥u−x−∥22=∥x++t(x−x+)−x−∥22
求解 u u u 和 x − x_{-} x−距离的最小值, 对上式求导:
g ′ ( t ) = 2 ( x + + t ( x − x + ) − x − ) ( x − x + ) = 2 ( x + − x − ) T ( x − x + ) + t ∥ x − x + ∥ 2 2 \begin{aligned} g^{\prime}(t) &=2\left(x_{+}+t\left(x-x_{+}\right)-x_{-}\right)\left(x-x_{+}\right) \\ &=2\left(x_{+}-x_{-}\right)^{T}\left(x-x_{+}\right)+t\left\|x-x_{+}\right\|_{2}{ }^{2} \end{aligned} g′(t)=2(x++t(x−x+)−x−)(x−x+)=2(x+−x−)T(x−x+)+t∥x−x+∥22
根据假设,在 t = 0 t=0 t=0 时,得 g ′ ( t ) < 0 g^{\prime}(t)<0 g′(t)<0 。在当 t t t 足够接近于 0 时 (导函数在 0 处的极限值为负,则存在邻域函数递减),即 g ( t ) < g ( 0 ) g(t)<g(0) g(t)<g(0) 。
∴ \therefore ∴ 存在一点 u u u ,使得它到 x − x_{-} x−的距离,比定义的凸壳距离 dist ( x + , x − ) \operatorname{dist}\left(x_{+}, x_{-}\right) dist(x+,x−)还小。产生矛盾。
故原命题成立,即 f ( x ) ≥ 0 , x ∈ conv ( S + ) f(x) \geq 0, x \in \operatorname{conv}\left(S_{+}\right) f(x)≥0,x∈conv(S+)。同理,可证 f ( x ) ≤ 0 , x ∈ conv ( S − ) f(x) \leq 0, x \in \operatorname{conv}\left(S_{-}\right) f(x)≤0,x∈conv(S−)。则可以找到一个超平面将两个互不相交的凸壳分隔开。
- 上述超平面可以将凸壳分隔开,则样本集满足线性可分
根据凸壳定义,数据集 T T T 中正例点 s + ∈ conv ( S + ) , s_{+} \in \operatorname{conv}\left(S_{+}\right) , s+∈conv(S+), 负例点 s − ∈ conv ( S − ) s_{-} \in \operatorname{conv}\left(S_{-}\right) s−∈conv(S−)。上述超平面可以将正例点集 S + S_{+} S+和负例点集 S − S_{-} S−两个凸壳分隔开,则可以使样本集线性可分。充分性得证。
链接: DataWhale.