引言
今天带来北京智源研究院(BAAI)团队带来的一篇关于如何微调LLM变成密集检索器的论文笔记------Making Large Language Models A Better Foundation For Dense Retrieval。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
密集检索需要学习具有区分性的文本嵌入,以表示查询和文档之间的语义关系。考虑到大语言模型(LLM)在语义理解方面的强大能力,它们可能会对密集检索有所裨益。然而,LLM 是通过文本生成任务进行预训练的,其工作方式与将文本表示为嵌入的方式完全不同。因此,研究如何适当地调整 LLM,以使其能够有效地初始化为密集检索的主干编码器,是至关重要的。
在本文中,我们提出了一种新方法,称为 LLaRA(LLM Adapted for dense Retrieval),该方法作为对 LLM 进行后处理适应以用于密集检索应用。LLaRA 包含两个前置任务:EBAE(Embedding-Based Auto-Encoding)和 EBAR(Embedding-Based Auto-Regression),其中 LLM 的文本嵌入分别用于重构输入句子的词元和预测下一个句子的词元。
模型在仓库: https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker 中进行公开。
1. 总体介绍
密集检索是深度神经网络带来的信息检索(IR)新范式。与传统的 IR 方法不同,密集检索学习将查询和文档表示为同一潜在空间中的嵌入,其中查询和文档之间的语义关系可以通过嵌入相似性反映出来。
密集检索的质量受到其主干编码器能力的严重影响。在过去几年中,预训练语言模型被广泛应用于查询和文档的表示。实证研究发现,模型规模和训练规模的扩大可以显著提高密集检索的准确性和泛化能力。
最近,大语言模型(LLMs)已被微调作为许多经典 NLP 任务的通用解决方案。考虑到 LLM 在语义理解方面的优越能力,利用这些强大的模型进行密集检索也具有很大潜力。事实上,已有一些开创性的努力在这一方向上进行,其中 LLM 被提示或微调以生成具有区分性的嵌入,从而促进密集检索(Muennighoff;Neelakantan;Ma;Zhang)。
尽管已有初步进展,但要充分发挥大语言模型在密集检索中的潜力仍然面临挑战。特别是,LLMs 是通过文本生成任务进行预训练的,其嵌入的学习目标是为了预测下一个词元。因此,LLMs 的输出嵌入主要集中于捕捉上下文的局部和近期语义。然而,密集检索需要的嵌入应该能表示整个上下文的全局语义。这种大的差异将严重限制 LLMs 在密集检索中的直接应用。
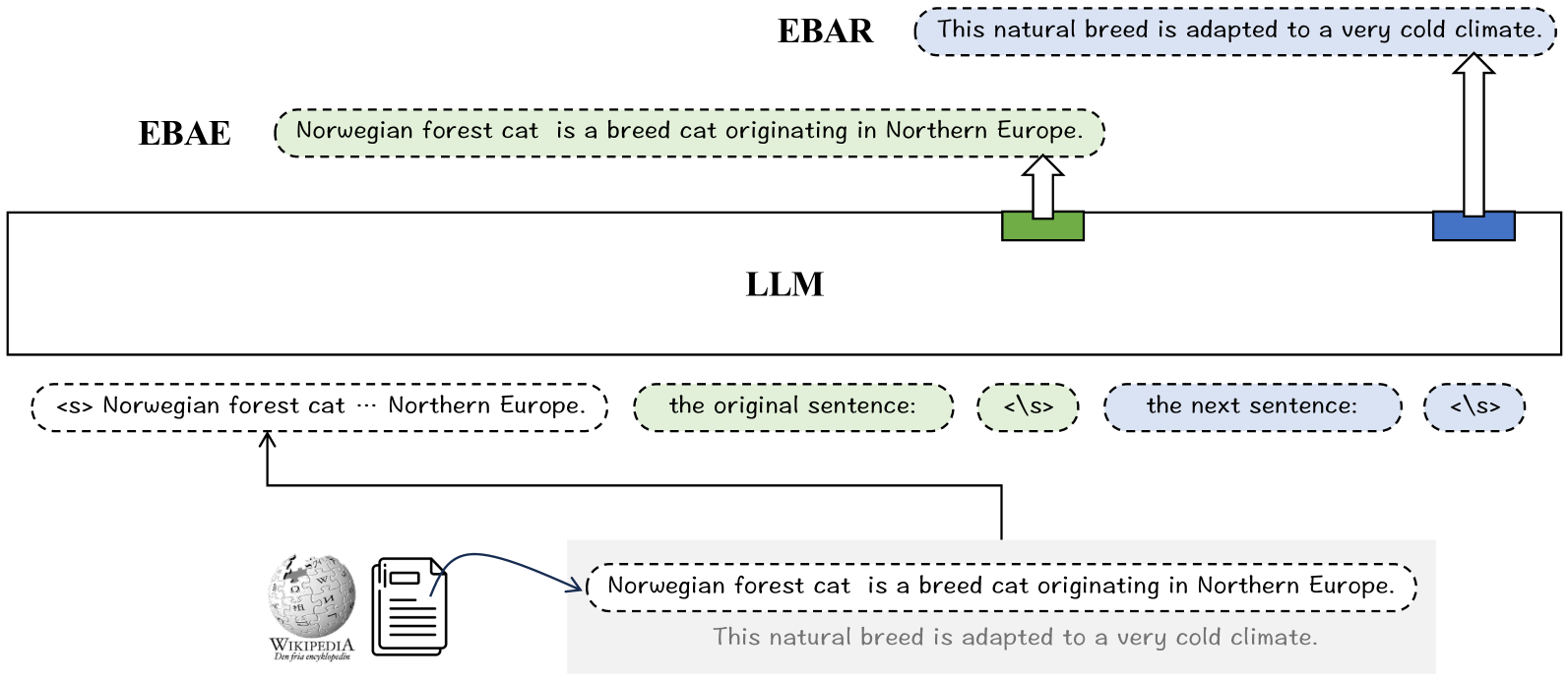
图 1:LLaRA 框架。LLM 被提示生成两个文本嵌入。一个用于 EBAE(绿色),其任务是预测原始句子。另一个用于 EBAR(蓝色),其任务是预测下一个句子。
为了解决这个问题,我们提出了一种新方法 LLaRA(见图 1),它作为 LLMs 的后处理适应,旨在提高其在密集检索中的可用性。LLaRA 可以被视为无监督生成预训练的扩展训练阶段。通过精心设计的前置任务,LLaRA 旨在增强 LLMs 生成文本嵌入的能力,以便更好地表示全局上下文的语义。
具体来说,LLaRA 引入了两个前置训练任务:EBAE(Embedding-Based Auto-Encoding)和 EBAR(Embedding-Based Auto-Regression)。在 EBAE 中,LLM 被提示生成可以用来预测输入句子自身词元 的文本嵌入。而在 EBAR 中,LLM 被提示生成可以用来预测下一个句子词元的文本嵌入。通过学习这些前置任务,LLM 的文本嵌入可以从局部语义表示(即预测下一个词元)调整为全局语义表示(即预测句子级特征)。借助这两种不同的提示模板,LLM 的嵌入能力可以被区分,以处理各种语义匹配场景,例如相似性搜索(使用 EBAE 的提示)和问答(使用 EBAR 的提示)。
在 LLaRA 中,句子级特征的预测是通过对 LLM 输出嵌入进行线性投影完成的,不需要额外的解码组件。因此,LLaRA 可以直接在现有的生成预训练流程上实现,具有极高的训练效率。此外,因为 LLaRA 完全基于原始语料库进行操作,所以不需要收集任何标注数据。
总结来说,我们在本工作中做出了以下技术贡献:
- 我们提出了 LLaRA,这是首个将 LLM 适应于密集检索应用的研究工作。
- LLaRA 设计简单但有效,通过对未标注数据执行两个前置任务,显著提升了 LLM 的检索能力。
- 预训练和微调 LLM 需要巨大的成本。为了促进该领域未来的研究,公开发布模型和源代码。
2. 相关工作
密集检索是将查询和文档表示为同一潜在空间中的嵌入,在此空间中,可以基于嵌入的相似性检索相关文档。密集检索的准确性由嵌入的质量决定,其中主干编码器是学习区分性嵌入的决定性因素。在过去几年中,预训练语言模型被广泛用于查询和文档的编码。得益于大规模预训练和基于变换器的架构,PLMs 能够为输入文本生成细粒度的语义表示。
沿着相同的思路,利用 LLMs 进行主干编码器的持续扩展是自然的选择。LLMs 在许多方面具有前景,尤其是其强大的语义理解能力可以显著改善复杂查询和文档的建模。此外,考虑到 LLMs 显著扩展的上下文长度,它为构建文档级检索器 提供了直接基础。由于 LLMs 的前所未有的普适性和指令跟随能力,它们也有助于多任务嵌入模型的学习。最近,有几项工作对将 LLMs 作为密集检索的主干编码器进行了初步尝试(Muennighoff;Neelakantan;Ma;Zhang)。然而,现有方法仅仅是直接使用 LLMs,由于文本生成任务和文本嵌入任务之间的巨大差异,LLMs 的潜力可能没有得到充分发挥。实际上,如何将 LLM 适应为密集检索应用的更好基础模型仍需进一步研究。
3. 方法
3.1 前置知识
密集检索利用文本嵌入模型生成查询和文档的嵌入: e q e_{q} eq 和 e d e_{d} ed。查询和文档的相关性通过它们的嵌入相似性来反映: ⟨ e q , e d ⟩ \langle e_{q}, e_{d} \rangle ⟨eq,ed⟩。因此,可以通过在嵌入空间内进行近似最近邻(ANN)搜索来检索与查询相关的文档 D q D_{q} Dq: D q ← Top-- k ( { d : ⟨ e q , e d ⟩ ∣ D } ) D_{q} \gets \text{Top}--k(\{d : \langle e_{q}, e_{d} \rangle | D\}) Dq←Top--k({d:⟨eq,ed⟩∣D})。
预训练语言模型曾被用作嵌入模型的主干编码器。以 BERT 为例,输入文本被标记化为序列 T : C L S , t 1 , . . . , t N , E O S T: CLS, t1, ..., tN, EOS T:CLS,t1,...,tN,EOS。然后,标记化的序列由 BERT 编码,输出的嵌入被整合为文本嵌入。执行整合的两种常见选项是:CLS 或均值池化:
e t ← BERT ( T ) CLS (1) e_{t} \leftarrow \text{BERT}(T)\\text{CLS} \tag 1 et←BERT(T)CLS(1)
e t ← AVG ( BERT ( T ) ) (2) e_{t} \leftarrow \text{AVG}(\text{BERT}(T)) \tag 2 et←AVG(BERT(T))(2)
当使用大语言模型(LLMs)作为主干编码器时,文本嵌入需要以不同的方式生成。鉴于现有的 LLMs 主要采用仅解码器架构,全局上下文只能通过输入序列末尾的词元来获取。因此,关于特殊词元 ⟨ \ s ⟩ \langle \backslash \text{s} \rangle ⟨\s⟩ 或 E O S EOS EOS 的输出嵌入被用作文本嵌入。以 LLaMA 为例,我们有以下更新后的文本嵌入形式:
e t ← LLaMA ( T ) ⟨ \\ s ⟩ . (3) e_{t} \gets \text{LLaMA}(T)\\langle \\backslash \\text{s} \\rangle. \tag 3 et←LLaMA(T)⟨\\s⟩.(3)
3.2 LLaRA
尽管在 LLM 中最后一个词元可以关注整个上下文,但其输出嵌入并不是输入文本的最佳表示。这是因为 LLM 是通过文本生成任务进行预训练的,其中每个词元的嵌入用于预测下一个词元。换句话说,LLM 的输出嵌入主要关注捕捉局部和未来的语义,而不是全局上下文的语义。
目标:为了解决上述问题,我们提出了 LLaRA,用于检索导向的 LLMs 适应。通过适应过程,LLM 的文本嵌入预计实现两个属性:
- 文本嵌入需要表示全局上下文的语义。
- 全局上下文表示应促进查询和文档之间的关联。
前置任务 :为实现上述两个目标,我们引入了两个前置(pretext)任务。第一个是 EBAE,在这个任务中,文本嵌入 e t e_{t} et 被用于预测输入文本本身。具体来说,如果 e t e_{t} et 能预测原始输入文本,那么 e t e_{t} et 必须完全编码输入文本的全局语义。第二个任务是 EBAR,在这个任务中,文本嵌入 e t e_{t} et 被用于预测输入文本的下一句。知道相关文档是查询的可能下一句(例如,问题的答案或对话上下文的回应),可以通过为这种语义建立表示来建立查询和文档之间的关联。
文本嵌入 :LLM 使用两个不同的模板生成 EBAE 和 EBAR 的文本嵌入(图 1)。对于 EBAE,LLM 由模板提示:[Placeholder for input]<space>The original sentence:<space><\s> (<space>表示一个空白符),文本嵌入生成如下:
e t α ← LLaMA ( T , SELF, ⟨ \ s ⟩ ) − 1 . (4) e_{t}^{\alpha} \gets \text{LLaMA}(T, \text{SELF,}\langle\backslash\text{s}\rangle)-1. \tag 4 etα←LLaMA(T,SELF,⟨\s⟩)−1.(4)
这里,SELF代表 EBAE 的提示:The original sentence:。
对于 EBAR,LLM 由模板提示:[Placeholder for input]<space>The next sentence:<space><\s> ,文本嵌入生成如下:
e t β ← LLaMA ( T , NEXT , ⟨ \ s ⟩ ) − 1 . (5) e_{t}^{\beta} \gets \text{LLaMA}(T, \text{NEXT}, \langle\backslash\text{s}\rangle)-1. \tag 5 etβ←LLaMA(T,NEXT,⟨\s⟩)−1.(5)
这里,NEXT 代表 EBAR 的提示:The next sentence:。
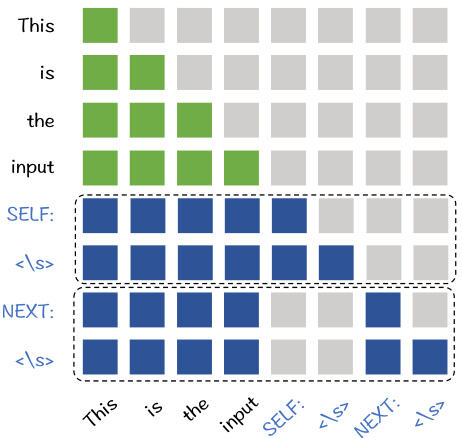
图2: LLaRA的注意力掩码
直接计算 e t α e_{t}^{\alpha} etα 和 e t β e_{t}^{\beta} etβ 会导致大量成本浪费,因为输入文本 T T T 被处理了两次。为了解决这个问题,我们提出在一次处理过程中计算 e t α e_{t}^{\alpha} etα 和 e t β e_{t}^{\beta} etβ。具体来说,将 EBAE 和 EBAR 的提示合并为一个联合提示:[Placeholder for input]<space>SELF<space><\s><space>NEXT<space><\s>。由于两个文本嵌入需要独立计算,我们修改了传统的因果语言建模的注意力掩码,其中SELF<space><\s> 和NEXT<space><\s> 是相互不可见的(图 2)。现在,第一和第二个 ⟨ \ s ⟩ \langle\backslash\mathbf{s}\rangle ⟨\s⟩ 词元的输出嵌入分别用于 e t α e_{t}^{\alpha} etα 和 e t β e_{t}^{\beta} etβ。由于输入文本 T T T 将占用联合提示的大部分长度,这种处理方式比直接计算节省了大约 50% 的成本。
训练目标:如前所述,LLaRA 的文本嵌入旨在捕捉输入文本本身和下一句的全局语义。在此基础上,我们提出了一个简单但有效的训练目标,将文本嵌入转化为全局语义表示者。从理论上讲,我们认为,如果一个嵌入能够准确预测特定上下文的所有词元,则该嵌入必须是对应上下文全局语义的强表示者。
基于这一基本原则,文本嵌入的训练被表述为多类别分类问题,其中文本嵌入经过线性投影用于预测目标上下文中的词元。上述问题的目标函数如下:
min ∑ t ∈ T exp ( e T W t ) ∑ v ∈ V exp ( e T W v ) . (6) \operatorname*{min} \sum_{t \in \mathcal{T}} \frac{\exp{\left(e^{T} \pmb{W}{t}\right)}}{\sum{v \in V} \exp{\left(e^{T} \pmb{W}_{v}\right)}}. \tag 6 mint∈T∑∑v∈Vexp(eTWv)exp(eTWt).(6)
其中 W ∈ R ∣ V ∣ × d W \in \mathbb{R}^{|V| \times d} W∈R∣V∣×d 是线性投影矩阵, V V V 是词汇空间。 T \mathcal{T} T 代表输入文本本身或下一句的词元集合,具体取决于 e t α e_{t}^{\alpha} etα 和 e t β e_{t}^{\beta} etβ 的处理。这一训练目标简单但有效,可以轻松实现于现有的语言建模训练流程之上。
4. 实验
4.1 设定
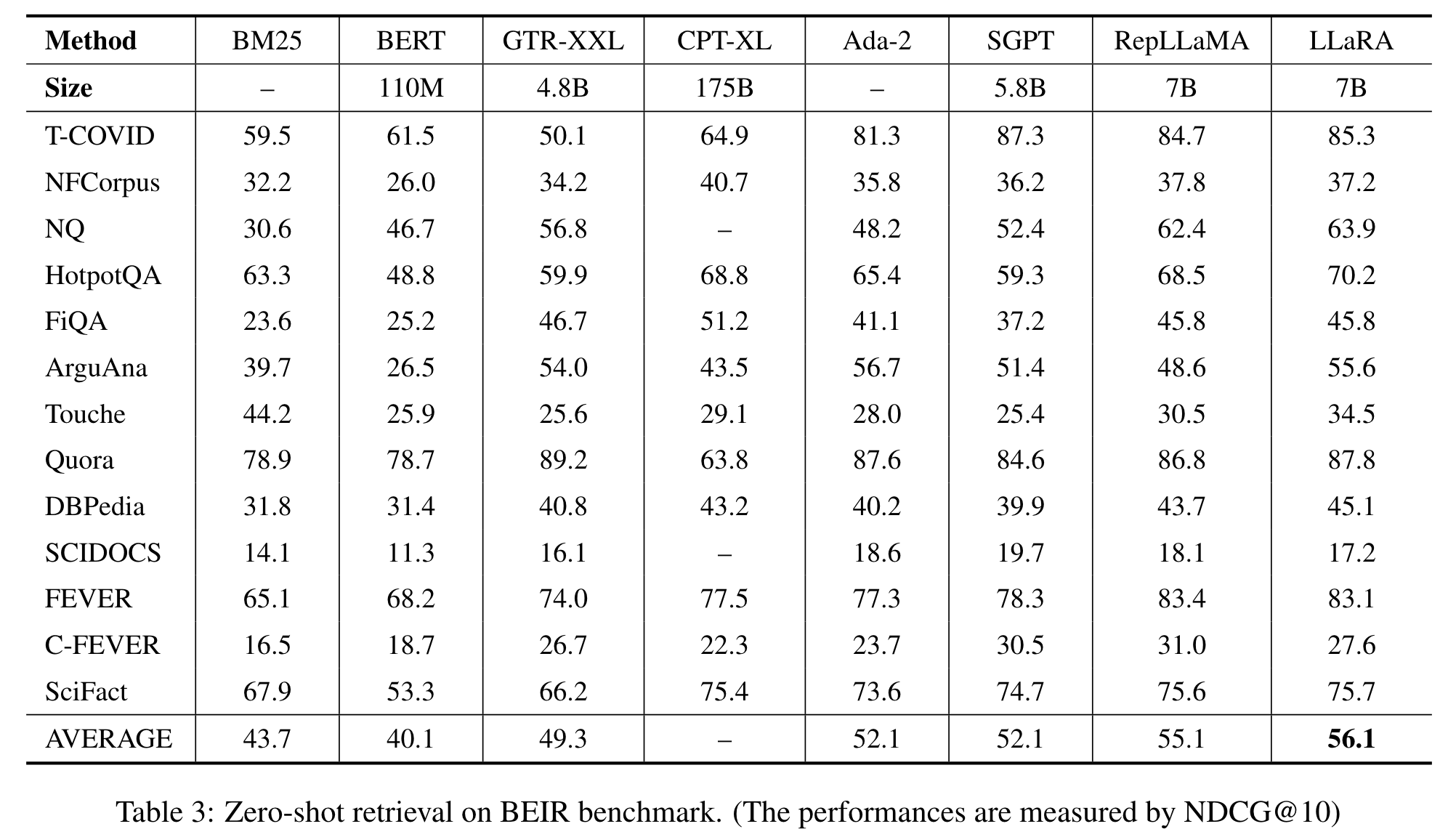
实验研究旨在验证 LLaRA 的有效性,特别是其在微调后的检索准确性和在不同场景中的泛化能力。为此,我们使用 MS MARCO作为微调数据集,对段落检索和文档检索任务进行评估。为了评估模型的泛化能力,我们还利用了 BEIR 基准,该基准涵盖了各种检索场景,如问答、事实验证、实体检索、重复检测等。来自 MS MARCO 的微调模型直接用于 BEIR 的0-shot 评估。
训练:LLaRA 应用于 LLaMA-2-7B(base)模型。训练基于由 DPR整理的未标注的维基百科语料库。我们总共进行 10000 步的 LLaRA 适应,批量大小为 256,序列长度为 1024,学习率为 1e-5。LLaRA 的微调遵循 RepLLaMA提出的程序:利用 LoRA进行高效的 LLM 参数训练,并使用 ANN 硬负样本进行嵌入模型的对比学习。
4.2 分析
关于 MS MARCO 的段落和文档检索,以及 BEIR 基准上的0-shot 检索的评估结果分别展示在表 1、表 2 和表 3 中。我们与多种基准方法进行了比较,包括基于预训练语言模型的代表性密集检索器,如 ANCE、RocketQA、GTR、RetroMAE、SimLM以及传统的基于 BM25 的稀疏检索器。我们还引入了最新的利用 LLM 作为骨干编码器的方法,包括 CPT、SGPT、RepLLaMA。
主要观察结果如下。首先,LLaRA 在每个评估场景中都取得了最好的检索性能。
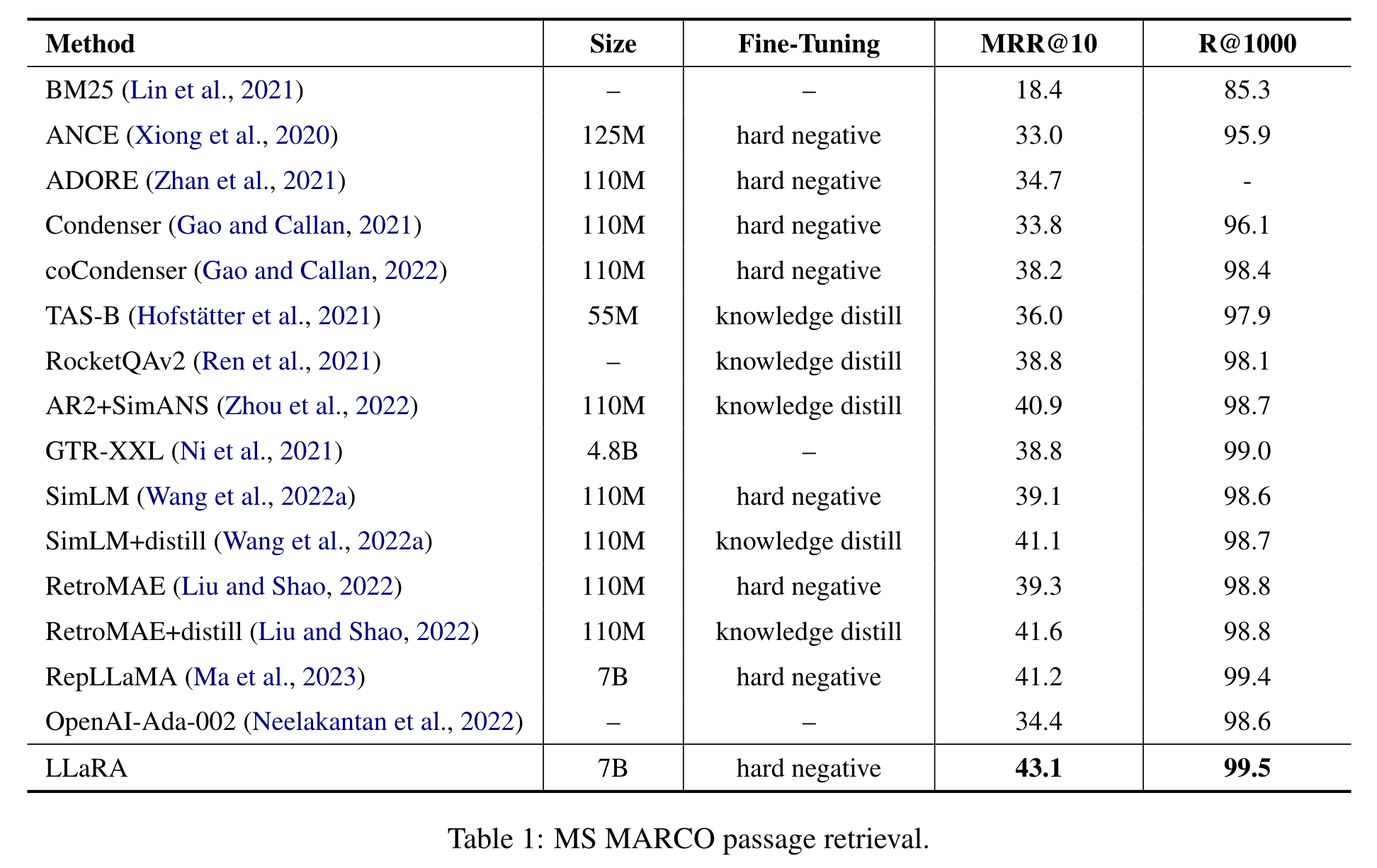
对每个具体场景的观察结果如下。首先,MS MARCO 段落检索(表 1)曾是信息检索领域最广泛引用的基准之一。值得注意的是,LLaRA 仅通过硬负样本进行微调。如果未来可以利用更先进的微调方法,报告的性能可能会进一步提高。与基于 BERT 的替代方法(如 RetroMAE 和 SimLM)相比,切换骨干编码器带来了近 + 4 % +4\% +4% 的 MRR @10 增益。这一显著提升表明了应用 LLM 进行密集检索的巨大潜力。
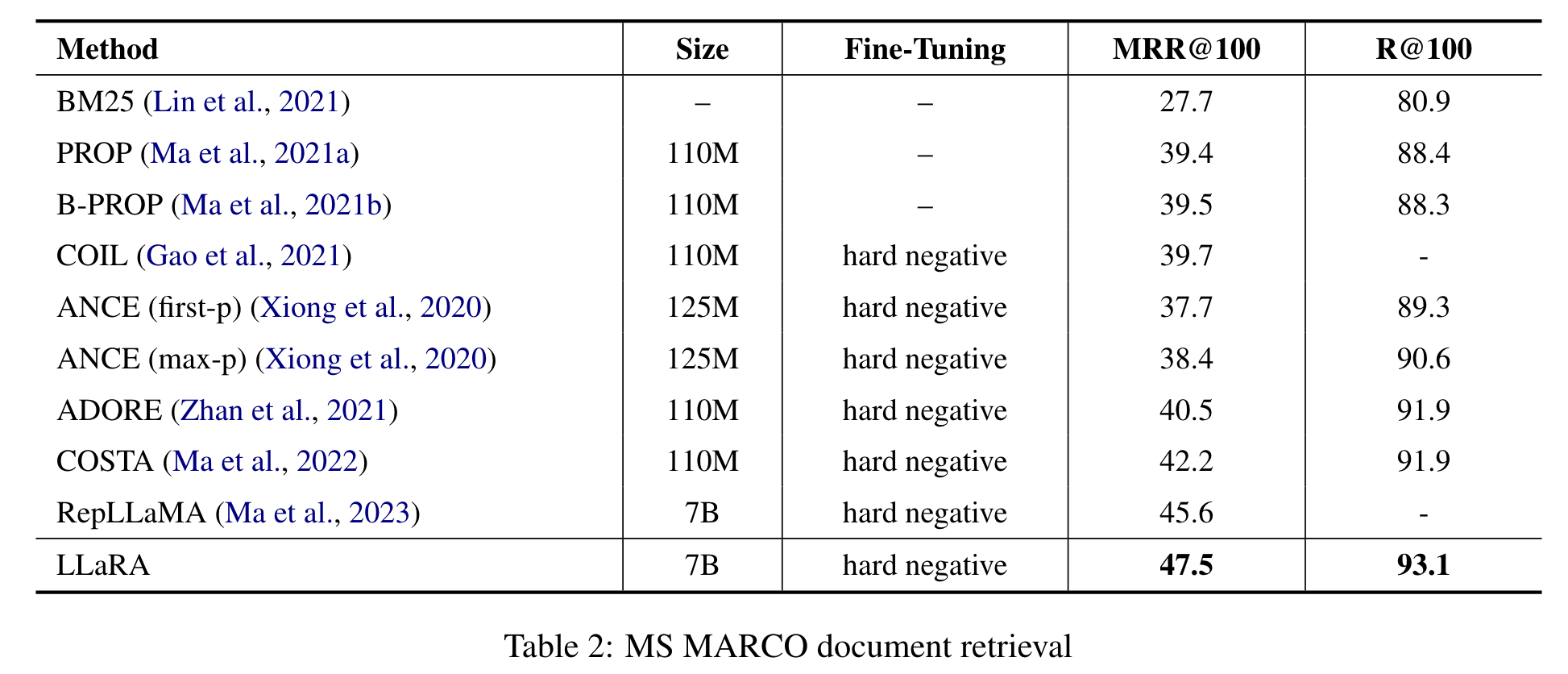
在 MS MARCO 的文档检索任务中(表2),相同的观察结果也得到了验证。基于 LLM 的检索器带来了优越的经验性能。实际上,文档检索直接受益于使用 LLM 作为骨干编码器,鉴于 LLM 显著扩展的上下文长度,例如 LLaMA-2 的 4K 长度。
根据 BEIR 基准上的0-shot 评估结果,检索器的泛化能力是使用 LLM 作为骨干编码器的另一个明显优势。在 BEIR 基准的许多评估任务中,基于 BERT 的方法甚至比简单的 BM25 基于稀疏检索器表现更差。然而,通过切换到基于 LLM 的骨干编码器,密集检索器的0-shot 性能可以显著提升。值得注意的是,随着模型规模的大幅扩展,所有大型基准能够在大多数情况下超越 BM25。此外,与 BERT 基准相比,LLaRA 在每个单独任务中的表现都要好得多,这最终带来了在平均性能上 + 16 % +16\% +16% 的 NDCG@10 显著提升。
5. 结论
在本文中,我们提出了 LLaRA,这是一种新颖的方法,旨在通过提高文本嵌入能力,使 LLM成为更好的密集检索基础。LLaRA 由两个前置任务 EBAE 和 EBAR 组成。这两个任务协作将 LLM 的文本嵌入转化为全局上下文的表示者,从而促进查询与相关目标之间的语义匹配。
总结
⭐ 本工作提出了LLaRA,该方法作为对 LLM 进行后处理适应以用于密集检索应用。LLaRA 包含两个前置任务: LLM 的文本嵌入分别用于重构输入句子的词元和预测下一个句子的词元。通过这种方式旨在捕捉输入文本本身和下一句的全局语义,从而使LLM变成一个有效的密集检索器。