本站以分享各种运维经验和运维所需要的技能为主
《python零基础入门》:python零基础入门学习
《python运维脚本》: python运维脚本实践
《shell》:shell学习
《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战
《k8》从问题中去学习k8s
《docker学习》暂未更新
《ceph学习》ceph日常问题解决分享
《日志收集》ELK+各种中间件
《运维日常》运维日常
《linux》运维面试100问
一、mysql主从
1.主库操作
1.主库配置server_id
2.主库开启binlog
3.主库授权从库连接的用户
4.查看binlog信息
5.导出所有数据2.从库操作
1.从库配置server_id(跟主库不一致)
2.确认主库授权的用户可以连接主库
3.同步主库数据
4.配置主库信息(change master to)
5.开启slave3.主从复制原理
1)图解
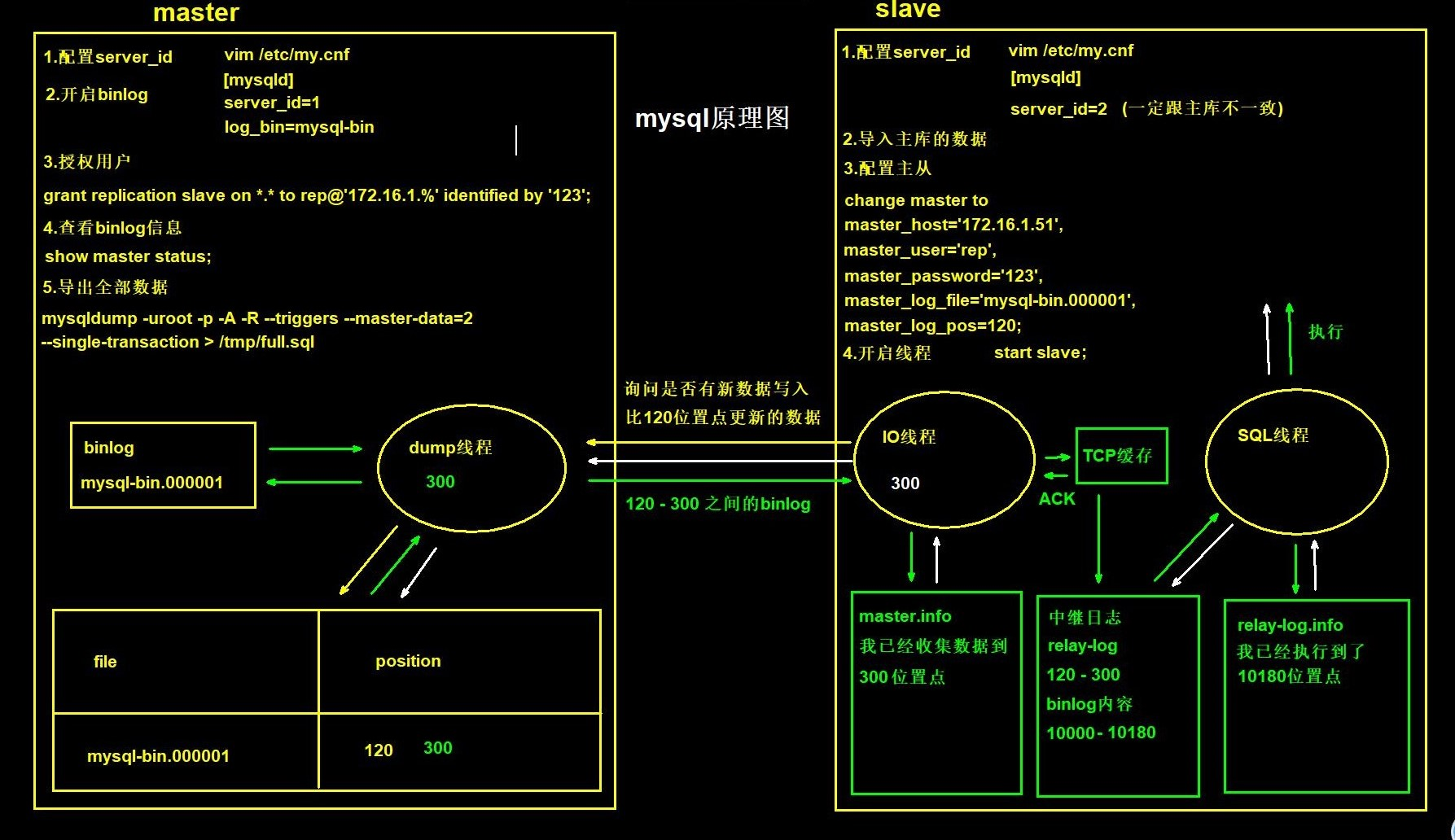
2)文字描述
(1)从库执行change master to语句,然后立即将主库的信息(ip、端口等)记录到master.info中,这个文件就在从库的数据目录下。
(2)从库执行start slave语句的瞬间,会立即生成IO_Thread和SQL_Thread。
(3)IO_Thread读取master.info文件,获取主库的相关信息(IP、端口号等)。
(4)IO_Thread连接主库,连接层开始验证用户名、密码、端口号、IP等是否合法。
一旦合法,主库会立即分配一个dump_thread线程,来与IO_Thread进行交互。
(5)IO_Thread根据master.info中的二进制日志信息,向主库的DUMP_Thread线程请求最新的二进制日志。
(6)DUMP_Thread经过show master status查询,如果发现有新的二进制日志,就截取新的日志并返回给从库的IO_Thread。
(7)从库IO_Thread收到主库发来的binlog,存储在到TCP_IP缓存中,在网络底层返回ACK给主库。
(8)从库IO_Thread会将二进制日志信息写入到relay-log中。
(9)从库IO_Thread更新master.info信息,重置二进制日志位置点信息。
(10)从库SQL_Thread读取relay-log.info文件,获取上次执行过的relay-log.info位置点。
(11)根据获取到的位置点,SQL_Thread按照位置点往下执行relaylog日志。
(12)SQL_Thread执行完后,更新relay-log.info文件。
(13)pwrge线程(非主从线程)把应用过的relay_log定期自动清理4.主从中涉及到的文件或者线程
1)主库
1.binlog:主库执行的sql语句
2.dump线程:对比binlog是否更新,获取新的binlog2)从库
1.IO线程:连接主库,询问新数据,获取新数据
2.SQL线程:执行从主库哪来的sql语句
3.relay-log:中继日志,记录从主库拿过来的binlog
4.master.info:记录主库binlog信息,会随着同步进行更新
5.relay-log.info:记录sql线程执行到了那里,下次从哪里开始执行三、主从复制的搭建
1.主库操作
1)配置
[root@db03 ~]# vim /etc/my.cnf
[mysqld]
server_id=1
log_bin=/service/mysql/data/mysql-bin
[root@db03 ~]# /etc/init.d/mysqld start2)授权一个用户
mysql> grant replication slave on *.* to rep@'172.16.1.%' identified by '123';
Query OK, 0 rows affected (0.03 sec)3)查看binlog信息
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000003 | 326 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)4)导出所有数据
[root@db03 data]# mysqldump -uroot -p -A --master-data=2 --single-transaction > /tmp/full.sql
[root@db03 data]# scp /tmp/full.sql 172.16.1.52:/tmp/2.从库操作
1)配置
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
[root@db02 ~]# /etc/init.d/mysqld start2)验证主库用户
[root@db02 ~]# mysql -urep -p -h172.16.1.533)同步数据
[root@db02 ~]# mysql -uroot -p123 < /tmp/full.sql4)配置主从
change master to
master_host='172.16.1.51',
master_user='rep',
master_password='123',
master_log_file='mysql-bin.000001',
master_log_pos=787368;
Query OK, 0 rows affected, 2 warnings (0.02 sec)5)开启线程
mysql> start slave;
Query OK, 0 rows affected (0.04 sec)6)查看主从
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes3.主从数据库出错
1)IO线程出错
mysql> show slave status\G
Slave_IO_Running: No
Slave_SQL_Running: Yes
mysql> show slave status\G
Slave_IO_Running: Connecting
Slave_SQL_Running: Yes
#排查思路
1.网络
[root@db02 ~]# ping 172.16.1.53
2.端口
[root@db02 ~]# telnet 172.16.1.53 3306
3.防火墙
4.主从授权的用户错误
5.反向解析
skip-name-resolve
6.UUID或server_id相同2)SQL线程出错
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: No
#原因:
1.主库有的数据,从库没有
2.从库有的数据,主库没有
#处理方式一:自欺欺人
1.临时停止同步
mysql> stop slave;
2.将同步指针向下移动一个(可重复操作)
mysql> set global sql_slave_skip_counter=1;
3.开启同步
mysql> start slave;
#处理方式二:掩耳盗铃
1.编辑配置文件
[root@db01 ~]# vim /etc/my.cnf
#在[mysqld]标签下添加以下参数
slave-skip-errors=1032,1062,1007
#处理方式三:正解
重新同步数据,重新做主从