简介
近几年热门的RISC-V架构发展迅猛,尽管因为生问题,RISC-V应用方向主要是单片机级的,高端应用方向发展发展速度缓慢,依然有不少公司推出了基于RISC-V指令集的高端应用场景的处理器。
本文汇总具有代表性的RISC-V公司推出的先进CPU微架构,其主要市场目标为服务器和PC端等高端应用方向。有分析表示,目前RISC-V阵营CPU微架构设计能力和ARM相比差距小于2年。
SIFIVE P870
P870是当前SiFive公司推出的最先进的RV处理器,遵循RVA23 profile。6 decode乱序处理器,具有128b向量长度,Hypervisor 拓展,Vector Crypto,IOMMU/AIA等特性。微架构核心参数对标ARM公司的N2处理器(服务器端)。 相比较于ARM,SIFIVE的CPU流水线做的相对较深,这对预测器考验比较大,目前业内最先进的预测器提升比较缓慢了,更深的流水线对预测错误更加敏感,这几年ARM有些系列的流水线深度基本维持在较低的状态(ARM N2流水线从N1的11降到10,频率依然保持较高的水准),从预测器相对瓶颈角度考虑,降低流水线深度是不错的提升方式,这对各模块的并行设计以及解耦设计要求比较高。对于RISC而言,亦安个人觉得合理的微架构设计将流水线维持在较低水平是不错的微架构方案。并且要在较低流水线下保持时序上的高水平。

整体的微架构参数,常规参数基本和arm的N2/V2系列对标:

IFU
32 entry itlb,64kb icache,64 entry的RAS,16K的TAGE预测器,2.5K的间接预测器。和ARM N2比较主要是单周期处理的分支数,N2是2个,P870目前没有看到相关的描述,应该只能预测一个。N2还具有MOp Cache。
Decode
P870使用6 decode宽度和ARM的V2保持一致,但高于N2的5 decode宽度。支持32bit指令和压缩指令,228 integer,240 FP浮点,128 Vector,Dispatch也是6宽度。这里的参数和ARM的N2/V2系列没有太大的差距。
Execute
96 integer issue 队列,4 ALU,1 分支执行单元,这里也能看出P870大概率不是单周期2分支。
LSU
64KB DeCache,2 LS pipes,Load/Store buffer均是48 entries,DTLB是64entris。
总结
目前觉得P870和ARM的参数差距主要还是IFU侧的一些能力吧,比如单周期的处理的分支数量,细节化的一些性能不好评价,网上没有见到太多关于P870更详细的参数。不过按照N2的流水线深度为10考虑,说明微架构的解耦性和并行性,ARM还是领先。尽管参数上对标了ARM的前一代旗舰,考虑到各种因素,设计差距在2年左右还是比较合理的。
Veyron V1
简介
这个处理器主要目标是面向服务器,汽车等高端方向,RISCV应该有的高端特性,例如IOMMU/AIA,Hypervisor拓展,支持48VA-52PA,V1都是有的。流水线也比较深,这个芯片的设计比较有特色,我对其不分模块描述。
微架构
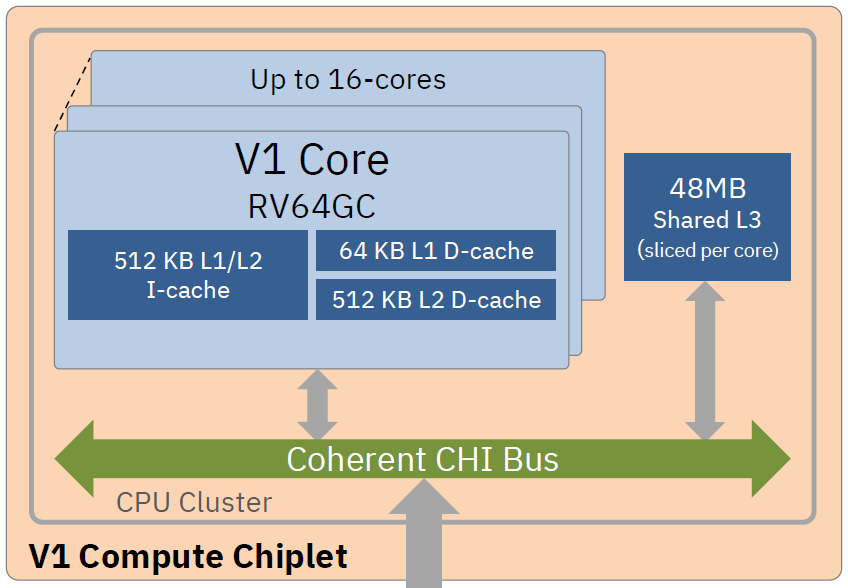
汇总一下比较特色的微架构设计,64KB的Dcache为VIPT结构。512KB的L1/L2的指令Cache,这里从官方描述来看,不是L1+L2 ICache有512KB,而是就一块超大的ICache。512 KB Instruction L2 with power-efficient L0 cache/loop buffer,官方PPT又说有个L0的Cache,这里应该就是个buffer。至少2个cycle 的Icache和ITLB的访问延迟,在overlap的情况下。也有个单独的512KB的Dcache,这里在L2区分指令和数据还是比较有意思的,并且大小设置的还一致。官方还表示这种设计有利于优化延迟和功耗。
L2 TLB也是区分了指令和数据TLB,大小在3K的样子,比P870大了不止一点点,单级ITLB。
每个cycle可以取64B指令,预测器和取指也是高性能CPU常规的解耦设计,decode的宽度是8。
总结
突出一个指令和数据分开,微架构和ARM的区别还是比较大的,因为巨大的指令Cache,延迟也是很大,从而负面的影响是流水线深度需要加深,其它一些"特色"的设计没有更多的细节来解释可能产生的负面影响。