本节可以解决的问题
知道MySQL集群吗?为什么要使用集群架构?
介绍一下MySQL主从复制的原理?
如何配置MySQL主从复制?
MySQL主从复制中常用的SQL指令?
MySQL主从复制模式中从机的IO线程与SQL线程的作用是什么?
二进制日志与中继日志的作用是什么?
MySQL集群中server_id的作用是什么?
了解读写分离吗?读写分离的应用场景是什么?
什么是数据分片?数据分片的方式都有哪些?
介绍一下垂直分片与水平分片,以及应用场景?
配置过读写分离和数据分片吗?
介绍一下你使用过的高性能架构中间件?
介绍一下数据分片的策略,为什么要使用这样的策略?
在MySQL集群环境中如何解决各数据节点的主键问题?
在MySQL高性能架构中,如何处理高并发的读写请求?
在MySQL集群架构中,如何保证数据的一致性?
在MySQL集群架构下,有哪些性能优化的方法?
MySQL集群
集群: 由多台数据库服务器组成的,统一对外提供服务
**1.性能提升:**通过将负载分散到多个服务器,显著提升数据库的读写性能
**2. 高可用性:**MySQL集群通过数据冗余和故障转移机制确保高可用性,即使某个节点发生故障,其他节点仍可继续提供服务
**3. 扩展性:**集群可以通过添加更多节点,来水平扩展系统的容量和处理能力
**4. 数据一致性:**通过复制和同步技术,集群模式可以确保数据在多个节点间的一致性
**5. 读写分离:**通过主从复制,可以将写操作集中在主库,读操作分散到多个从库,进一步提升数据库的读写性能
**6. 分库分表:**为了解决单一数据库性能瓶颈,提高数据库扩展性,可以采用分库分表的集群模式
**7. 负载均衡:**在集群中,可以通过负载均衡技术,将请求合理分配到不同的节点上,防止单个节点过载
MySQL集群的使用是为了应对大数据量和高并发访问的需求,通过提升性能、保证高可用性、实现数据的一致性和扩展性,以及通过读写分离和分库分表等技术手段,来满足互联网业务的高速发展
单机模式
使用非常少量的服务器来部署应用程序和数据库,这种场景数据库服务器可以只有一台,多个应用程序服务器都访问同一台数据库服务器。当应用程序的访问量越来越多,数据量越来越大,单台数据库服务器已无法支持业务系统,为解决这个问题可以把数据库部署成集群
集群模式
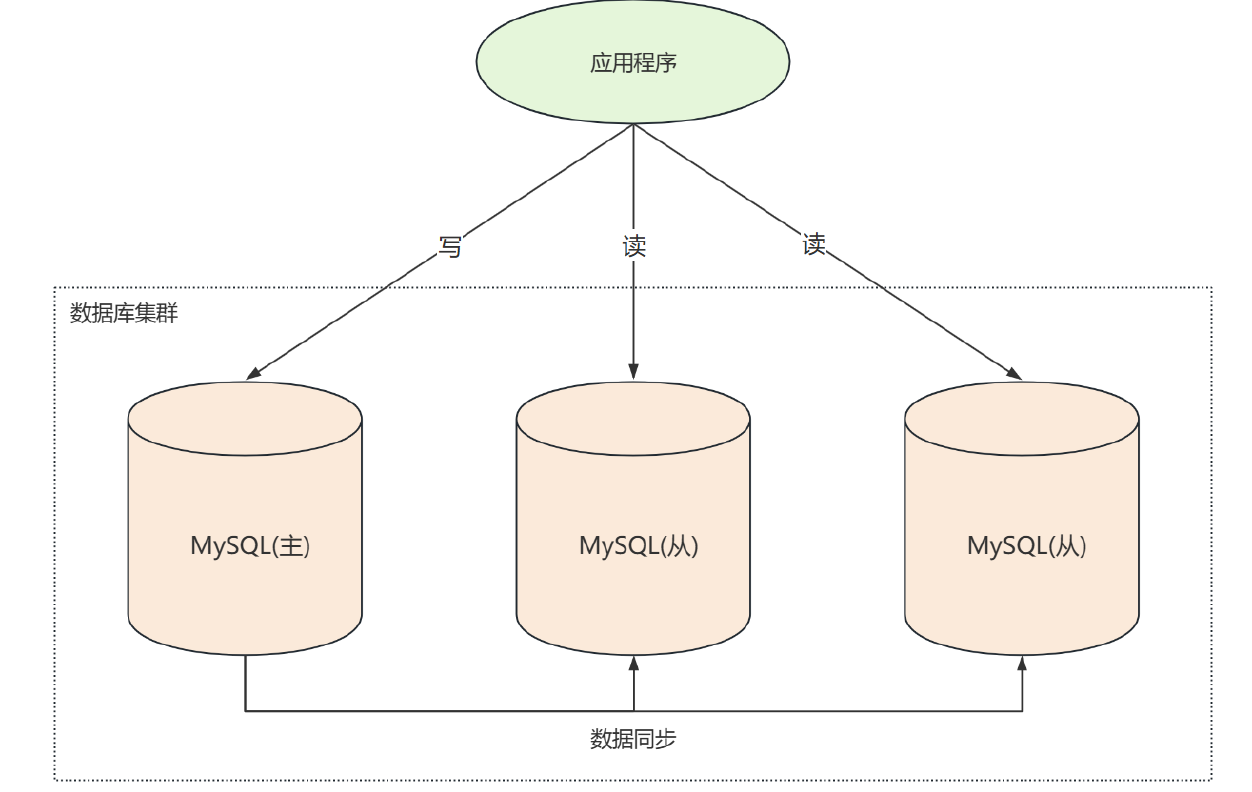
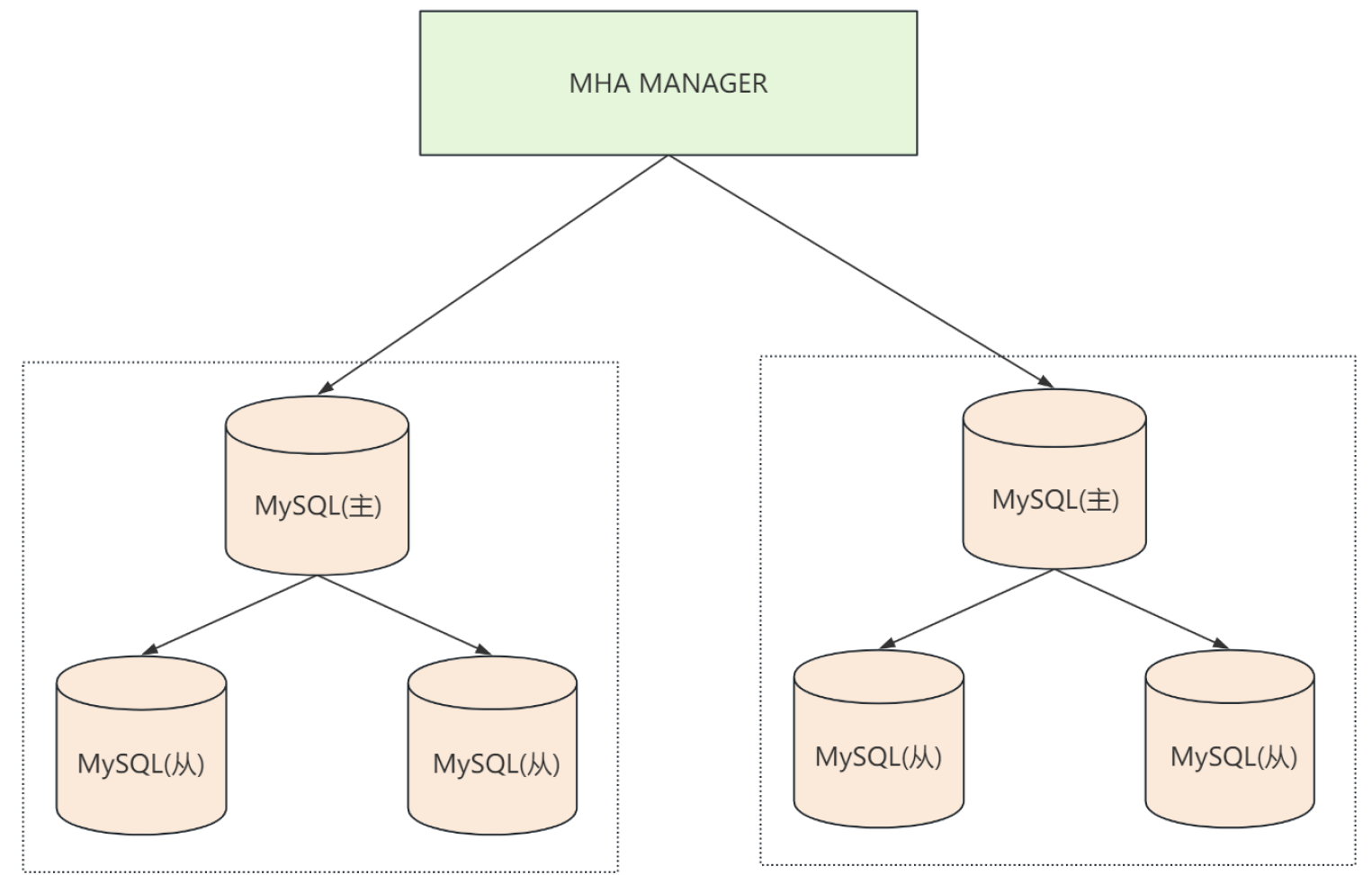
多台数据库服务器共同完成整个系统的数据读写负载,下图是一主二从的部署:
从图中可以看出,写入数据时只往主服务器中写 ,从服务器通过读取主服务器的二进制日志 ,然后在从服务器上回放数据修改操作。所有的查询操作都访问从服务器。由此一来,将读和写操作分散到了不同的服务器,从而有效降低了单台服务器的压力,提升整个业务系统的性能
集群部署可以是一主一从,一主多从,多主多从等等
高性能架构
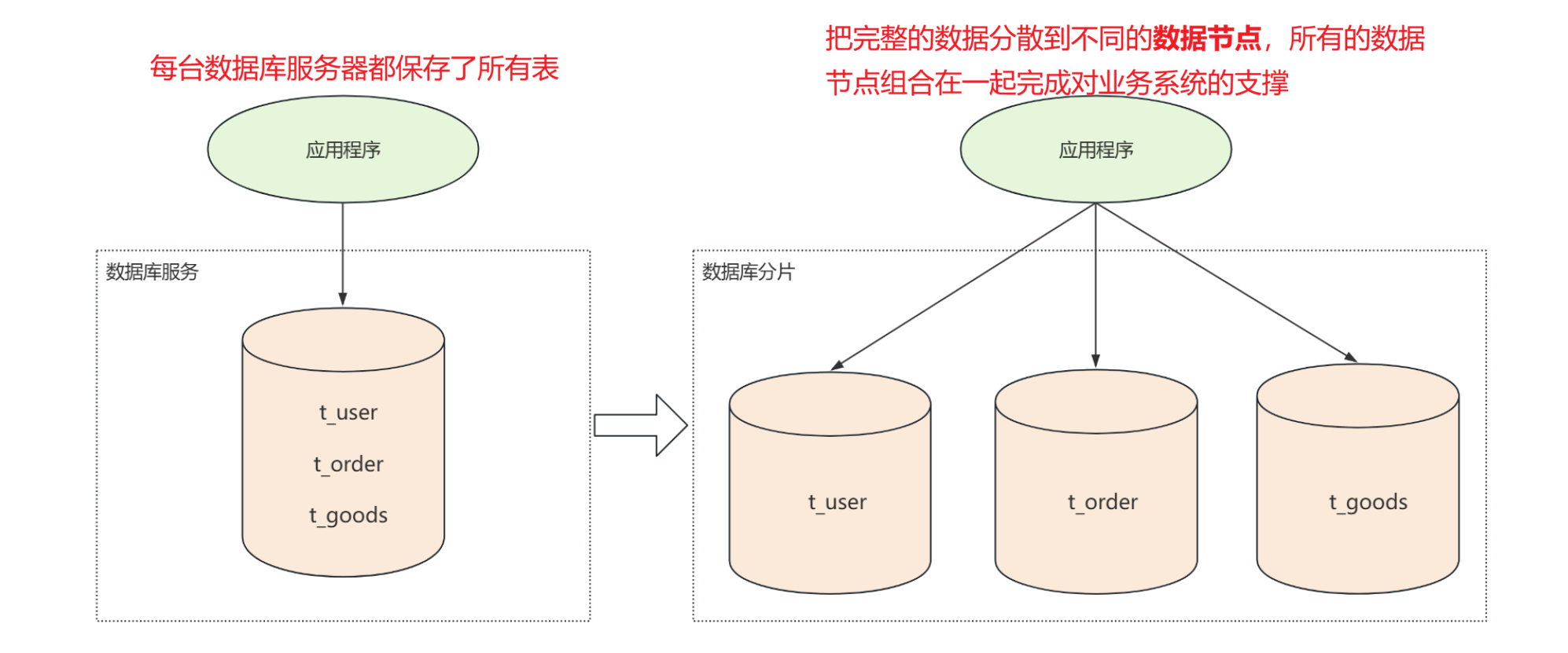
MySQL高性能架构主要分为读写分离与数据库分片
读写分离: 写操作和读操作发生在不同的服务器上。写操作分发到主服务器 ,读操作分发到从服务器 ,从服务器的数据通过数据同步的方式从主服务器中获取
数据库分片: 由原来每个数据库服务中保存完整的数据,拆分为每个数据库服务保存一部分数据,多个数据库服务共同组成完整的数据
主从架构
主服务器(Master): 主要负责写操作和简单查询操作
从服务器(Slave): 主要负责复杂查询和备份
主从复制原理
主服务器将DML和DDL操作记录到binlog ,从服务器通过复制主服务器的binlog,并且把binlog中记录的操作转换为SQL,在从服务器上进行回放。
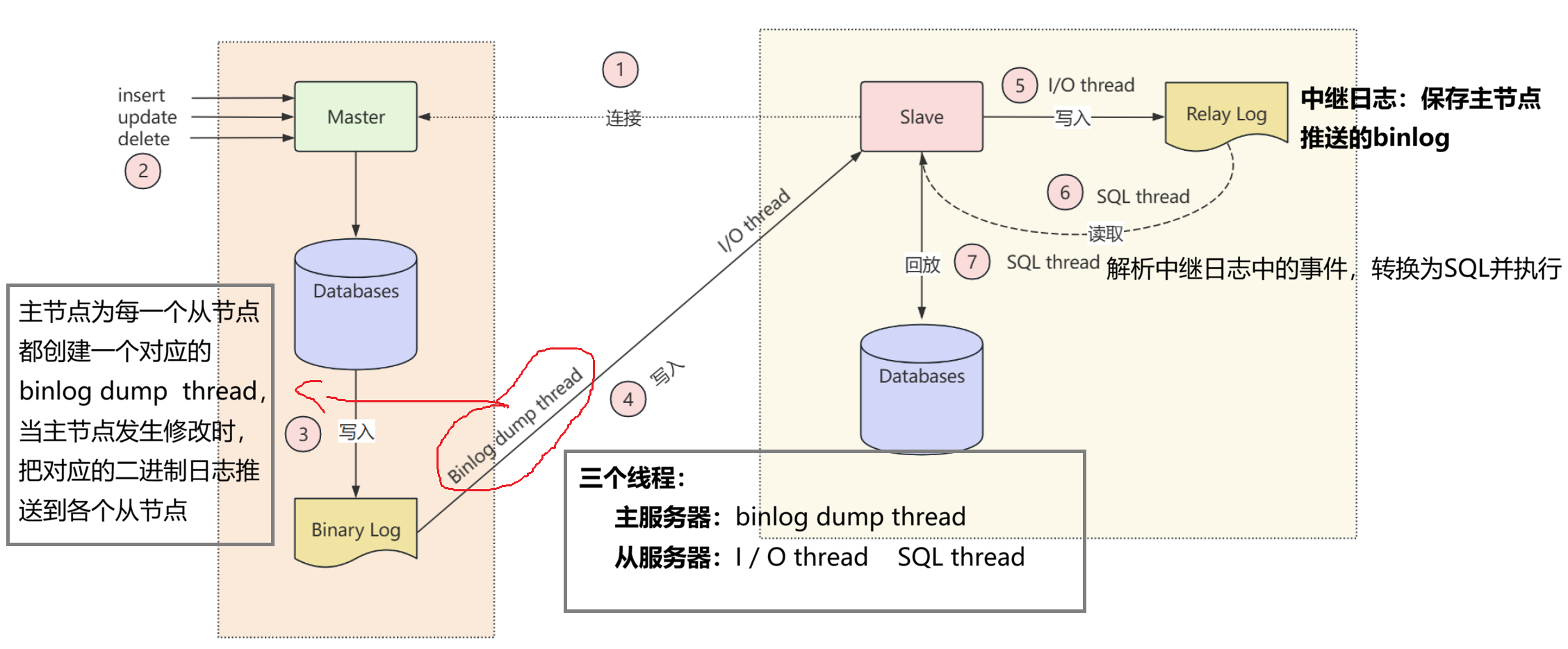
**1.**从服务器连接主服务器,读取主服务器的版本和时钟信息,并在主库注册自己
2. 主服务器为每个 从服务器创建对应的binlog dump线程
3. 主节点在进行DML 、DDL操作时,把相应的操作按执行顺序 写入binlog
4. 当主节点的binlog发生变化时,binlog dump线程把binlog的增量内容以event事件 的方式推送给从节点的I/O线程
5. 从节点的I/O线程 把接收的内容写入Relay Log
6. 从节点的SQL线程 读取Relay Log的内容
7. 从节点的SQL线程解析日志并转为SQL 并进行回放,把数据写入从库
主从复制
数据备份和恢复: 通过主从复制,可以实现实时数据备份 ,确保数据安全。当主服务器出现问题时,从服务器可以随时接管服务,保证数据的一致性和业务的连续性
**读写分离:**减轻主服务器压力,提高系统并发处理能力。主从复制支持大规模高并发读写,同时有效地保护了物理服务器宕机场景的数据备份
**负载均衡:**由于主从数据节点都有完整的数据,可以通过一定的策略或者规则,将负载分摊到多个不同的数据节点,提高系统的负载均衡能力
主从复制模式
**一主一从:**一台主服务器主要负责读写操作,一台从服务器主要负责读操作或备份
**一主多从:**一台主服务器负责写操作,多台从服务器负责读操作和备份。
主节点只需给一个从节点 同步数据,其他的从节点从从节点同步数据,不从主节点同步数据,以此来减轻主节点的压力
多主多从: 以上的主从配置在实际中部署多套 ,避免单台故障
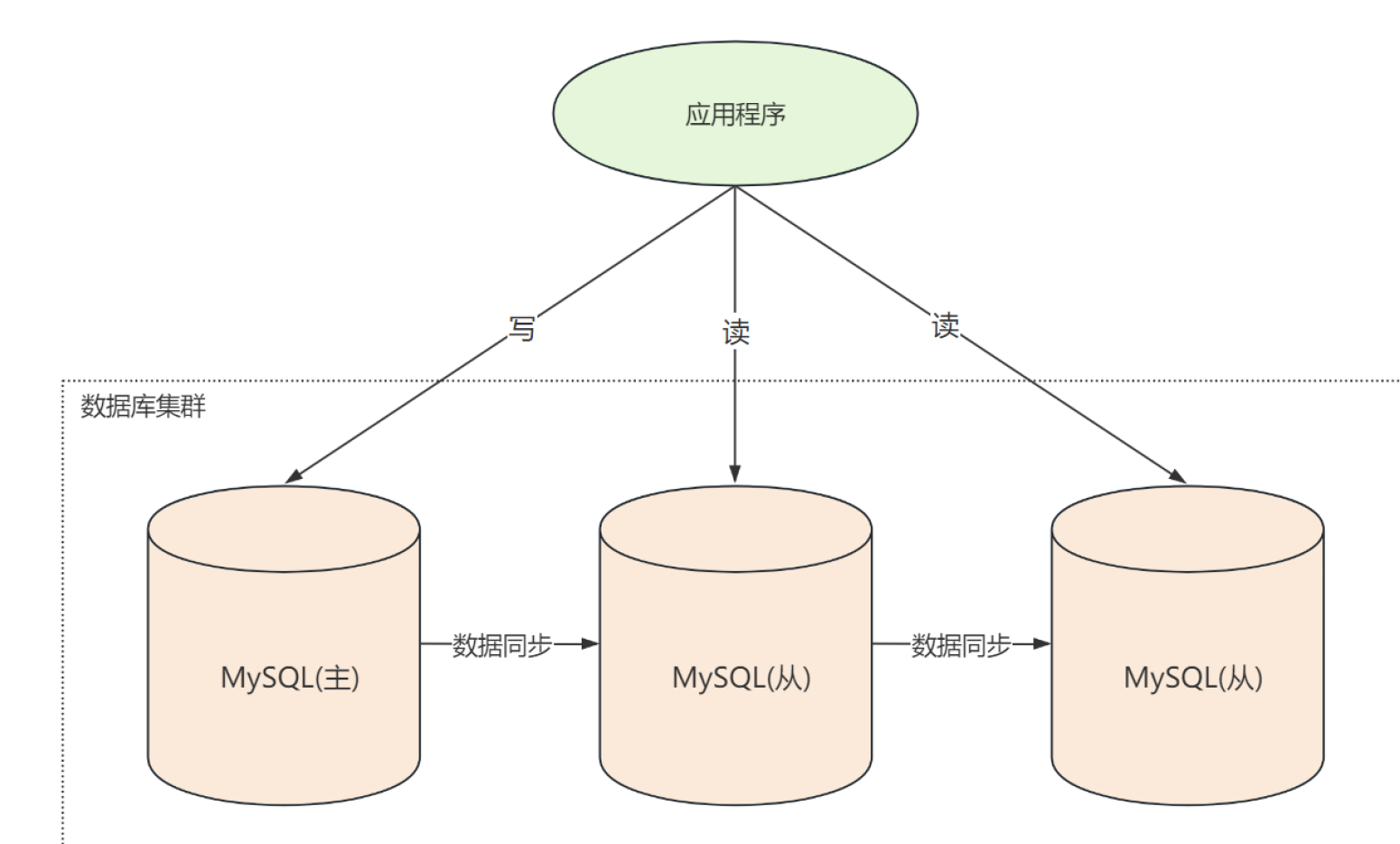
主从复制实践
以下示例使用一主两从架构,当往主服务器写入数据时,从服务器可以实现自动同步,查询时可以在任意节点获取数据。示例中使用Docker来模拟多个服务器的情况
服务器规划
在单台服务器上使用Docker模拟多台服务器的场景,主从服务器Ip一致 ,端口号不同
**主服务器:**容器名:study-mysql-master 端口号 53306
**从服务器1:**容器名:study-mysql-slave1 端口号 53307
**从服务器2:**容器名:study-mysql-slave2 端口号 53308
主库配置
创建MySQL主服务器
sql
docker run -d \
-p 53306:3306 \
-v /bit/mysql/master/conf:/etc/mysql/conf.d \
-v /bit/mysql/master/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=密码 \
--name 容器名 \
mysql:8.0.381. 通过端口映射 ,将容器的3306端口 与主机的53306端口进行绑定,实现从外部访问Docker中的MySQL
2. 将配置目录 映射到主机,修改主机目录 的配置文件会直接同步到容器内,无需进入容器
创建配置文件
在宿主机的主服务器配置映射目录中创建并修改配置文件 my.cnf,设置完成后重启服务器
sql
# MySQL服务器节点
[mysqld]
# 服务器唯一id, IP后三位+端口号
server-id=13803306
# 二进制日志基本名, Linux下默认为binlog, window下默认为"机器名-bin"
# 生产环境推荐自定义日志路径
log-bin=binlog
# 二进制日志的格式,默认为ROW,生产环境也推荐用ROW
binlog_format=ROW
# 二进制日志过期时间,指定10天,默认30天
binlog_expire_logs_seconds=864000
# 在事务提交之前把二进制日志写入磁盘
sync-binlog=1配置主服务器
为从服务器创建访问账户,用于从服务器登录主服务器,设置完成后刷新权限
javascript
create user '用户名'@'IP' identified with mysql_native_password by '密码';
grant REPLICATION SLAVE on *.* to '用户名'@'IP'; -- 远程复制权限查看主服务器状态
sql
show master status;记录File和Position 的值,表示从哪个日志文件 中的哪个位置开始同步数据,在整个主从配置完成之前不要再操作主服务器,防止主服务器发生变化
从库配置
创建MySQL从服务器
sql
docker run -d \
-p 53307:3306 \
-v /study/mysql/slave1/conf:/etc/mysql/conf.d \
-v /study/mysql/slave1/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=密码 \
--name 容器名 \
mysql:8.0.38创建配置文件
文件内容:
sql
# MySQL服务器节点
[mysqld]
# 服务器唯一id, 默认值为1
server-id=13803307
# 二进制日志基本名, Linux下默认为binlog, window下默认为"机器名-bin"
# 生产环境推荐自定义日志路径
log-bin=binlog
# 二进制日志的格式,默认为ROW,生产环境也推荐用ROW
binlog_format=ROW
# 二进制日志过期时间,指定10天,默认30天
binlog_expire_logs_seconds=864000
# 在事务提交之前把二进制日志写入磁盘
sync-binlog=1
# 从服务器:
# 中继日志基本名,默认为"机器名-relay-bin",也可以指定自定义路径
relay-log=relay-bin
# 服务器启动时不启动复制,稍后手动启动使用start REPLICA语句(SQL指令)
# MySQL8.0.26之前用skip-slave-start=ON,稍后手动启动使用start SLAVE语句。
skip-replica-start=ON
# SQL线程执行的更新写入副本自己的二进制日志,MySQL8.0.26之前用log_slave_updates=ON
# 如果要实现 "A服务器 <-- B服务器 <-- C服务器" 这种链式日志同步,则B服务器即是主又是从,需要开启该选项
# log-replica-updates=ON重启MySQL服务器:
sql
docker restart 服务器名设置主从关系
sql
CHANGE MASTER TO
MASTER_HOST = '主机地址',
MASTER_PORT = 主机端口,
MASTER_USER = '从机登录的用户名',
MASTER_PASSWORD = '密码',
MASTER_LOG_FILE = '日志文件',
MASTER_LOG_POS = 位点;重复以上步骤创建第二台从服务器
启动主从复制
sql
START REPLICA;查看从服务器状态:
sqlSHOW REPLICA STATUS;参考信息:https://dev.mysql.com/doc/refman/8.0/en/show-replica-status.html
查看主服务器进程列表
sqlshow processlist;查看并行复制的线程数
sqlshow variables like '%replica_parallel_workers%'
高性能架构模式
主从复制配置完成之后,只是保证了各个数据节点的一致性 ,但没有进行高性能的策略配置
读写分离
高性能数据库集群其中的一种实现方式是数据库读写分离 ,读写分离是一种提高数据库性能和可扩展性的常用策略,他将数据库的操作分为读(查询) 和写(更新、插入、删除) 两部分,使主数据库处理事务性操作(增删改) ,而从服务器处理查询操作。
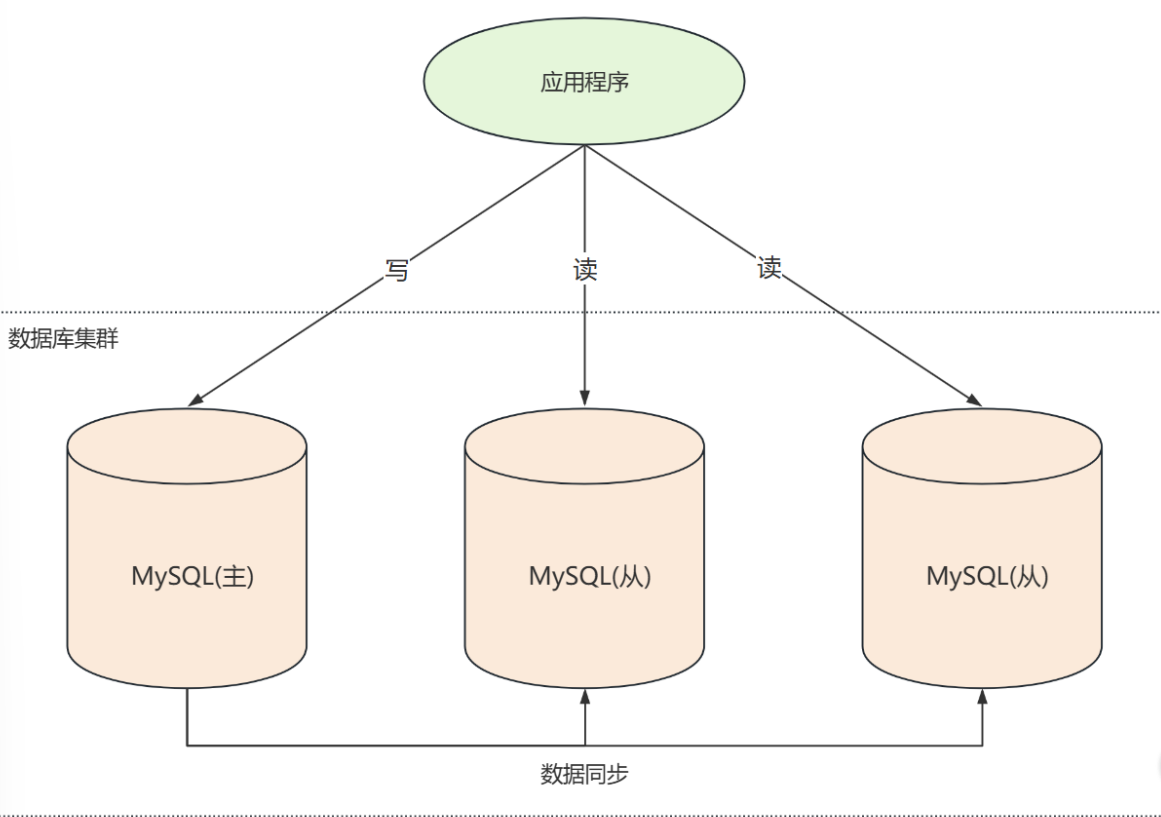
特点
**1. 主从复制:**主库负责处理所有写操作,以及部分读操作。从库负责处理读操作,通常有多个从库来分担负载
2. 负载均衡: 通过负载均衡器 ,将读请求分发到不同的从库,以实现负载均衡
3. 数据同步:主库和从库 之间的数据需要保持同步,这通常通过数据库自带的复制机制实现
4. 故障转移: 当主库发生故障时,将主库 的职责转移到从库上
**5. 数据延迟:**由于数据需要从主库复制到从库,可能会存在一定的延迟,根据业务评估是否可以接受
6. 读写分离策略:
**静态分离:**根据业务逻辑直接将读和写操作分配到不同数据库
动态分离: 通过中间件或应用逻辑动态决定将请求发送到哪个数据库
数据分片
读写分离架构,分散了数据库的读写操作压力,但无论是主库还是从库,都管理着一个完整的数据库 。随着系统的运行,单个表的数据会不断增加,从而导致索引深度 的增加,使得磁盘访问IO次数增加,导致查询性能下降。
数据分片指按照某个维度 将存放在单一数据库中的数据分散地 存放至多个数据库或表 中以达到提升性能瓶颈以及可用性的效果。数据分片的有效手段是对关系型数据库 进行分库分表 。数据拆分方式又分为垂直分片和水平分片
垂直分片
按照业务拆分 的方式称为垂直分片 ,又称纵向拆分 ,它的核心理念是专库专用 。拆分之前,一个数据库由多个数据表 构成,每个表对应不同的业务。拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散到不同数据库
垂直分库: 垂直分库后还可为每个分库部署主从复制和读写分离
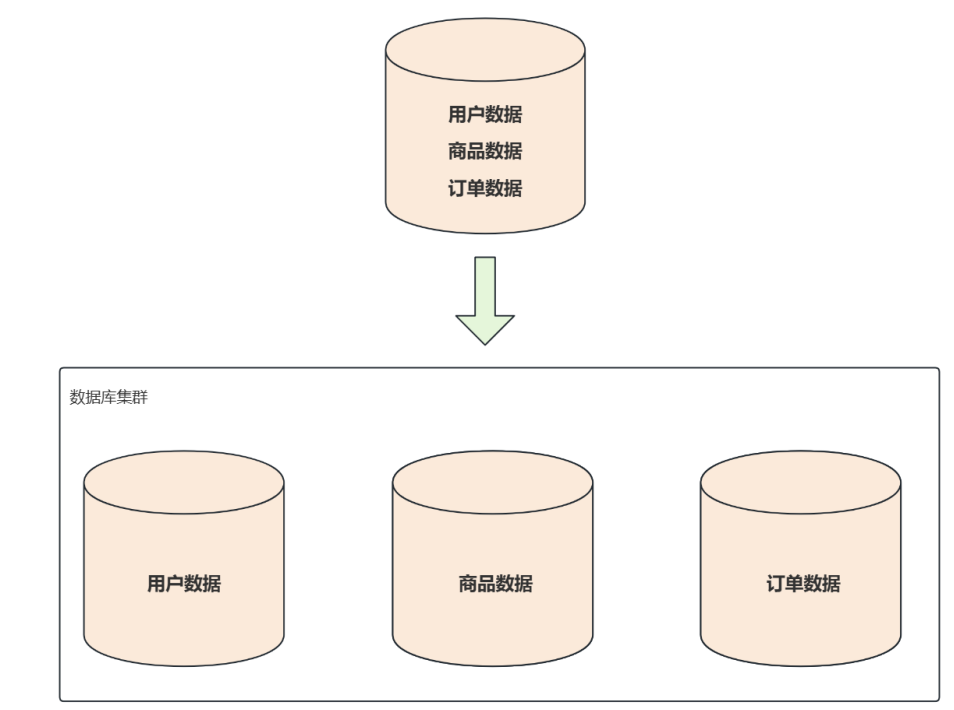
问题: 分库之后有可能核心业务对应的单表数据过大,依然对系统造成性能影响。
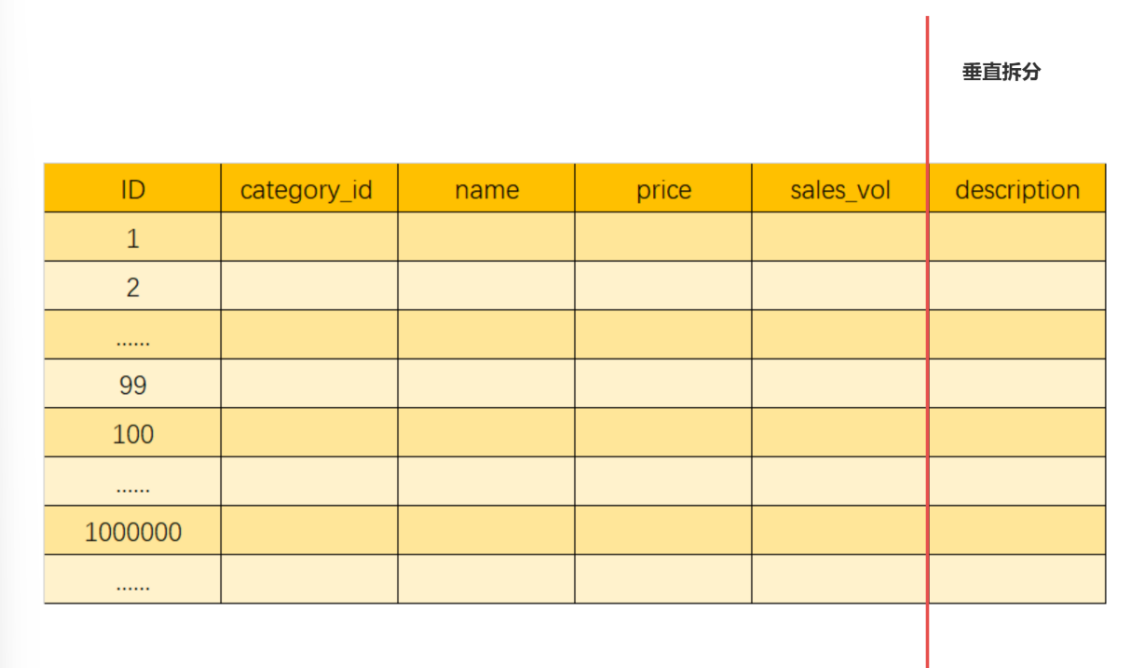
垂直分表: 将表中某些不常用的列 或者占大量存储空间 的列拆分成一个单独的表,一个大表拆成多个小表
假设以下是一张商品信息表,用户在筛选信息时主要查询商品id,名称和价格字段,description字段主要用于展示商品详情,在查询商品列表时用不到。由于description字段 内容比较长,占用磁盘空间也比较大,所以可以把这个字段独立到另一张表中,以提升商品查询时的性能
垂直分表后两张表是一对一关系 ,使用相同的主键 进行关联。垂直分表引入的复杂性主要体现在增加了表操作的数量(更新时同时更新两张表,查询时要连表查询)
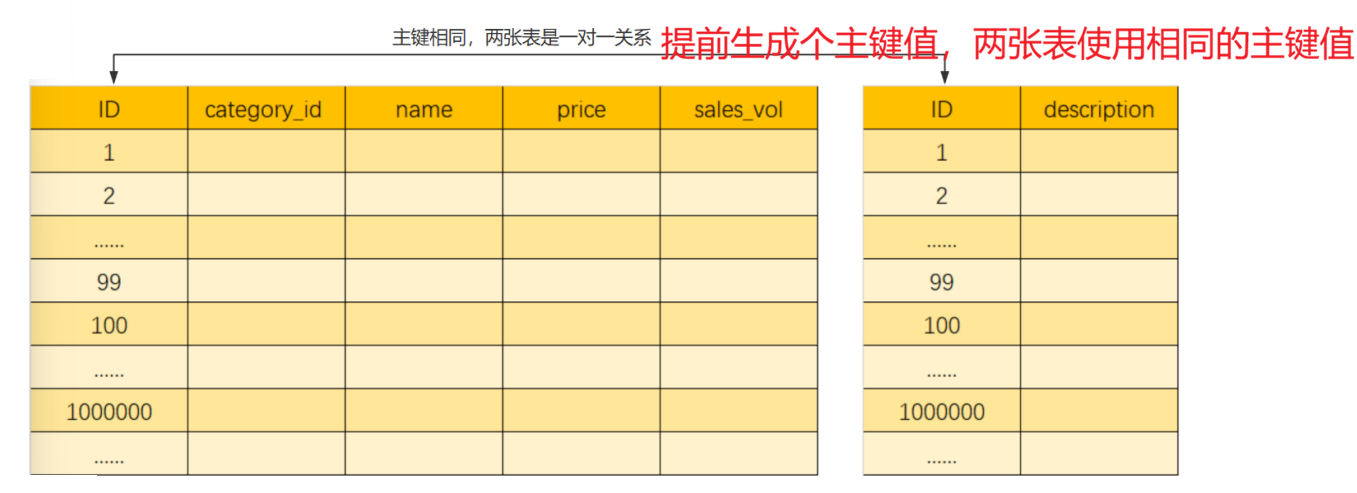
垂直拆分可以缓解数据量和访问量 带来的问题,但无法根治。如果垂直拆分后,表中的数据量依然超过单节点所能承载的阈值,则需水平分片来进一步处理
水平分片
水平分片又称横向分片 ,相对于垂直分片,它不再将数据业务根据业务逻辑分类,而是通过某个字段(或几个字段),根据某种规则将数据分散到多个库或表中 ,每个分片仅包含数据的一部分,从而减轻单库或单表的访问压力。
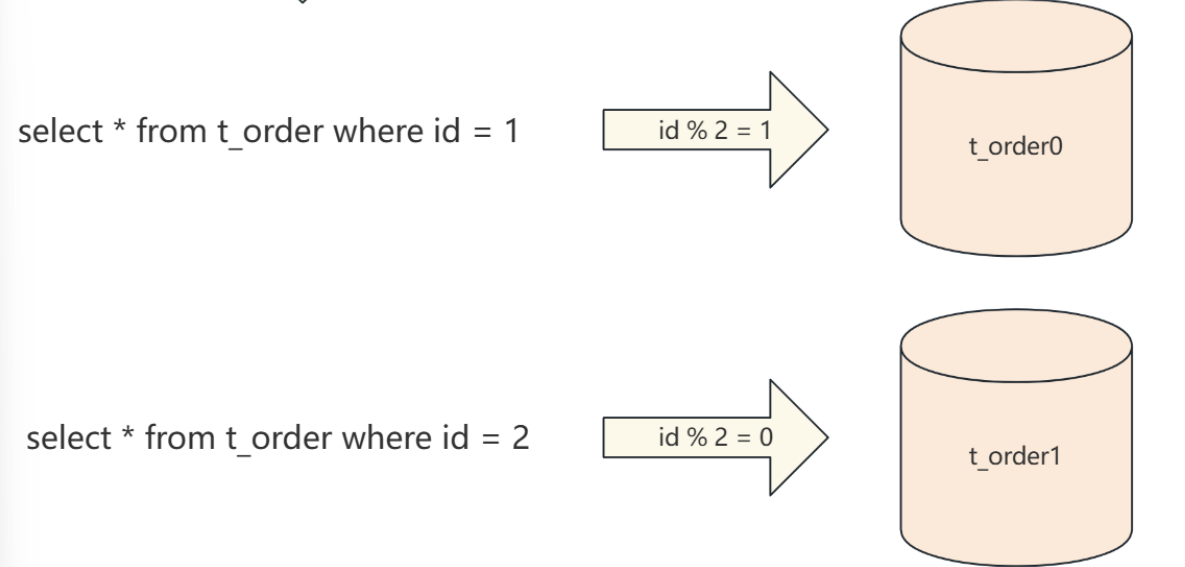
水平分表:
把原来在一张表中保存的数据,按某种规则分散到多个表中,以 ID%2为例
拆分出来的多个表,表结构是相同的 ,多个表组合成完整的数据。这样单个表的数据量有效的降低了,从而降低了B+树的树高,减少了IO的次数
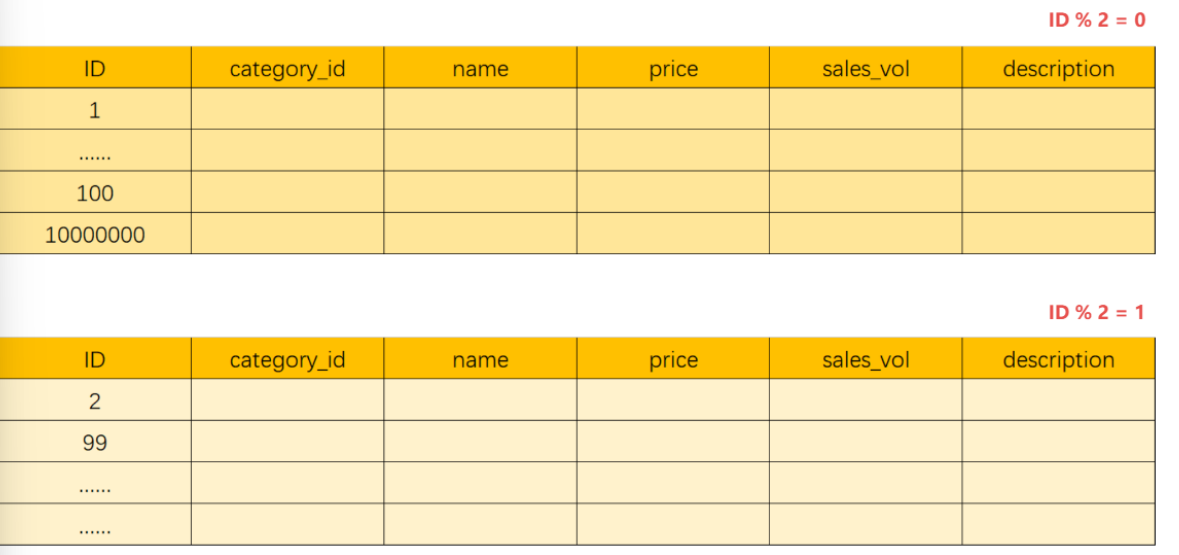
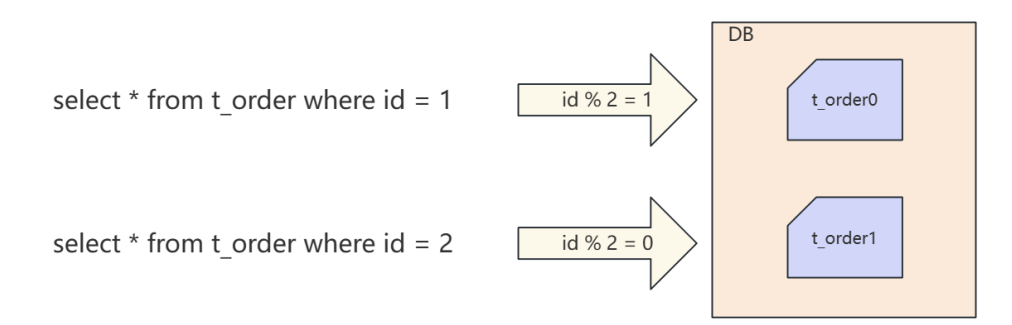
单表拆分为多表后,会对性能带来很可观的提升。如果数据库性能可以满足业务需求,不建议 把多个表分散到不同的服务器。因为当两个表在同一个数据库中,可以避免跨库事务。
水平分库: 如果单表切分后,单台服务器依然无法满足数据库性能要求,那么就需要将多个表分散在不同的数据库服务器上
数据分片之后每个分片分散在多台服务器还是单台服务器:
1. 数据分片的目的是为了提升数据库的性能 ,分片又分为分库和分表
2. 通常在进行分表之后,如果单台服务器可以满足性能要求,建议不同的分片部署在当前数据库中,这样可以避免跨库事务,单台服务器性能不能满足性能需求是再进行分库操作,同时可以配置主从复制
- 分库之后,即使不同分片在当前服务器 上也无法避免跨库事务,同时单台服务器 的负载并没有降低,所以建议此时把不同的分片部署在不同服务器上
水平分库之后可能会引入更多的复杂性,比如表连接查询,分布式事务等等
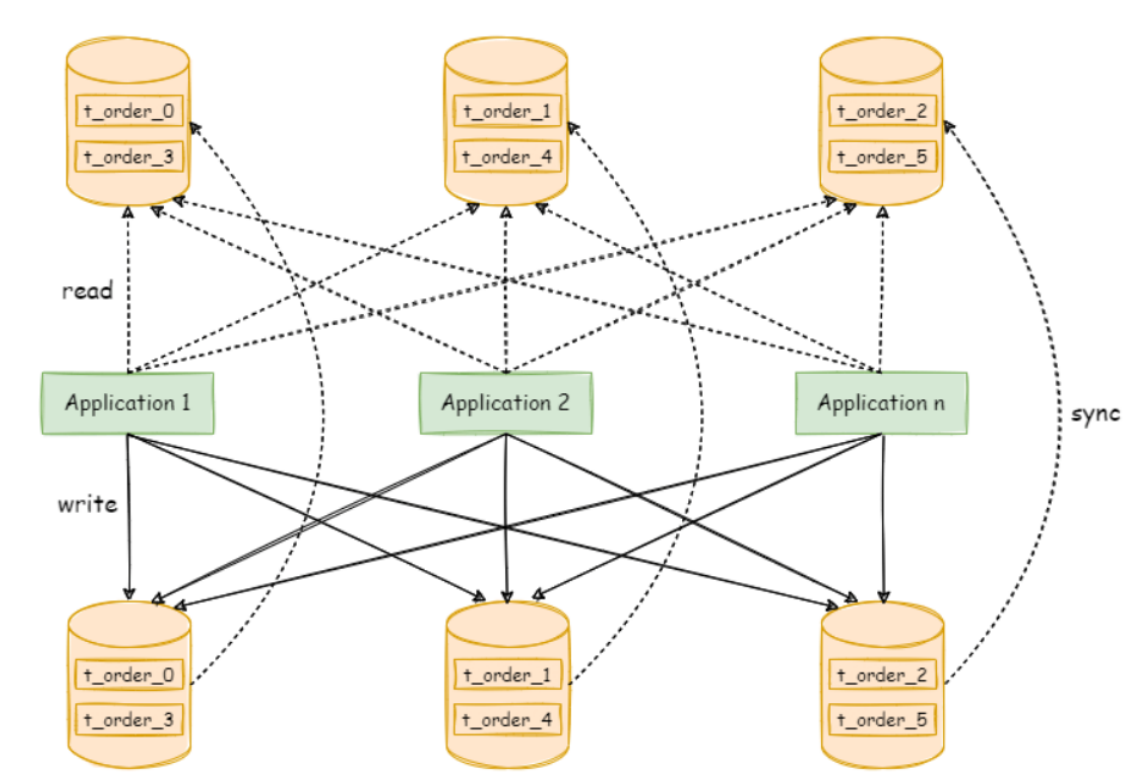
读写分离和数据分片架构
下图表示数据分片和读写分离一同使用时,应用程序与数据库集群之间的拓扑关系
高性能架构实现方式
读写分离和数据分片的实现方式一般有两种:程序代码封装和中间件封装
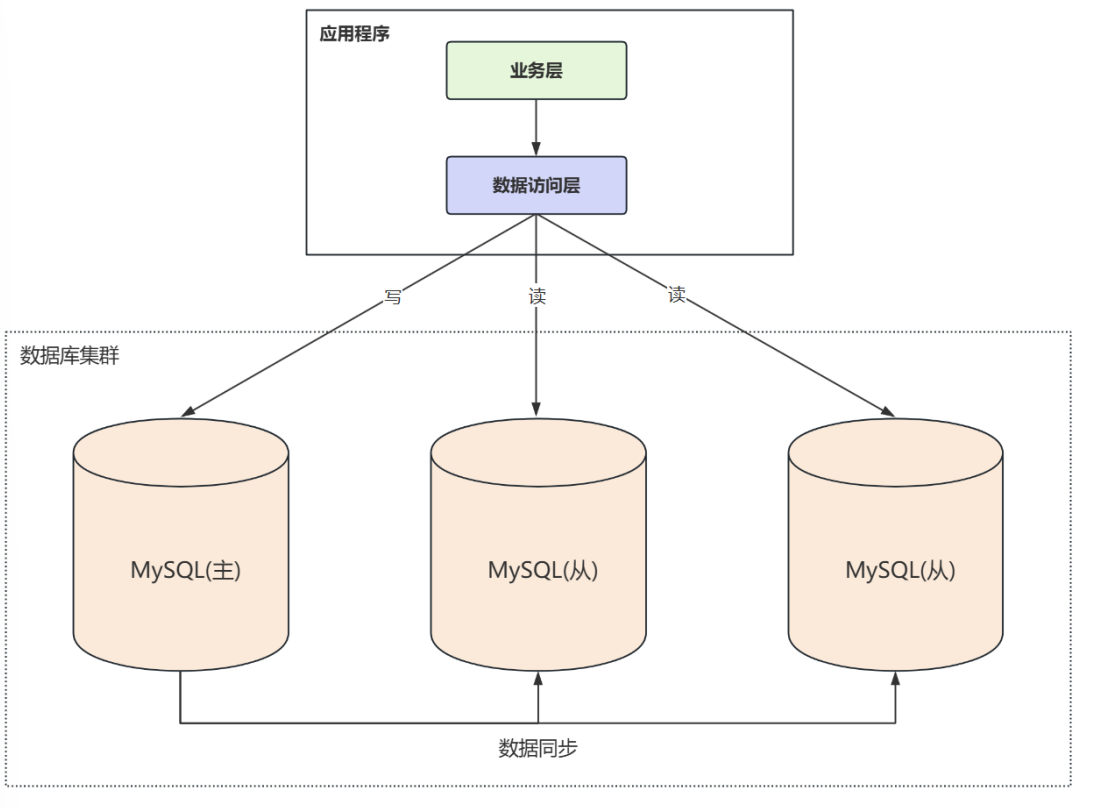
程序代码封装
在应用程序中抽象出一个数据访问层,根据读操作与写操作,来控制访问哪个数据库。数据库访问的代码与业务代码耦合在一起了,侵入性比较强,维护时就不太方便
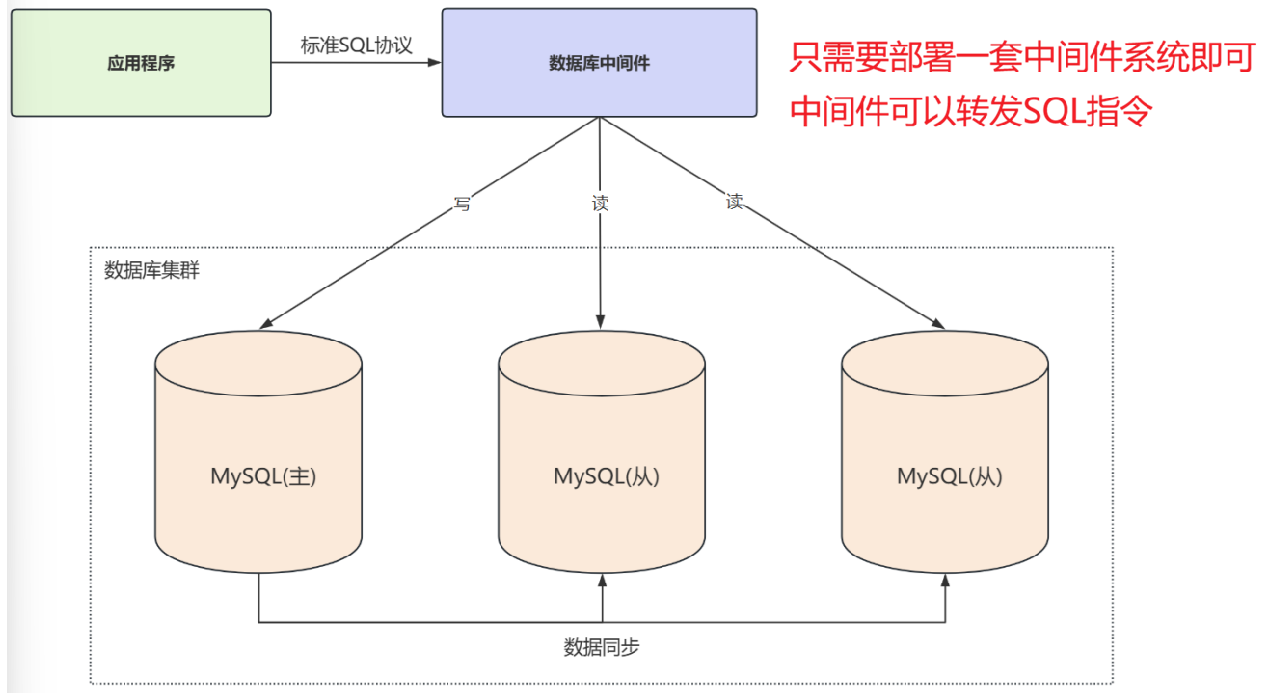
中间件封装
中间件指用来解决某些特定的问题,可以独立运行的一套系统。使用中间件封装实现读写分离和数据分片,对于应用程序来说,访问中间件和访问数据库没有区别,中间件可以看作一个数据库服务器。
ShardingSphere
一款分布式的数据库原生系统,可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强
ShardingSphere-JDBC: 轻量级Java框架,在Java的JDBC层提供额外服务
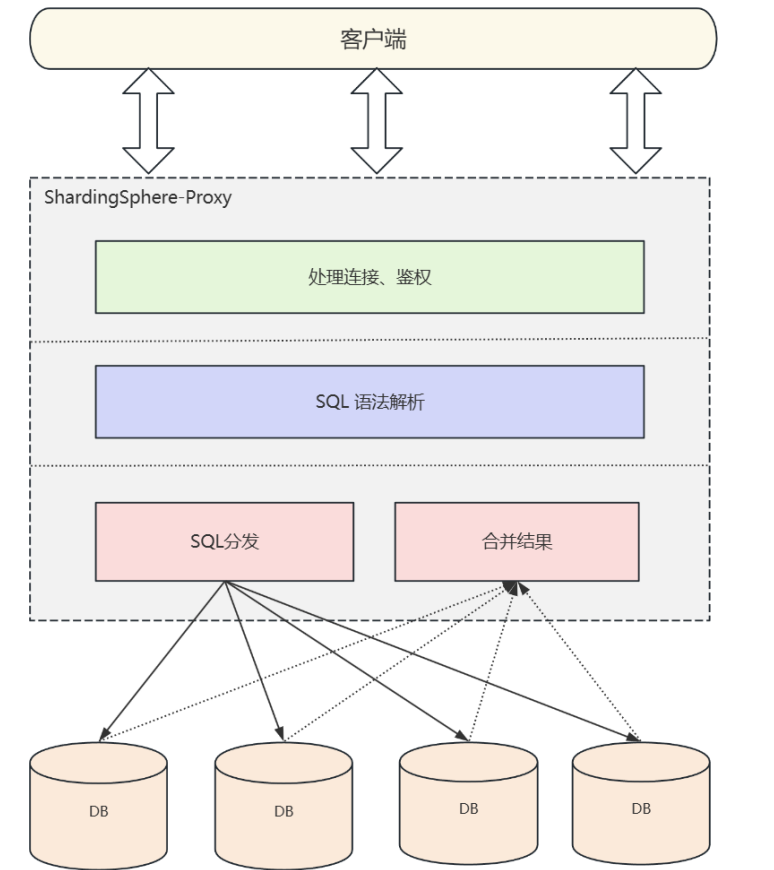
ShardingSphere-Proxy: 定位为透明化的数据库代理端 ,通过实现数据库二进制协议,对异构语言提供支持。客户端可以像使用MySQL一样使用ShardingSphere-Proxy,包括命令行操纵和程序访问
ShardingSphere-Proxy工作原理
1. 客户端发送SQL语句到ShardingSphere-proxy
2. ShardingSphere-proxy接收SQL语句并解析操作类型,如SELECT、INSERT等等
3. ShardingSphere-proxy根据操作类型和分片规则 将SQL转发到底层真实的数据库节点(可能是多个)
4. 底层真实数据库节点执行SQL语句 ,并将结果返回给ShardingSphere-proxy
5. ShardingSphere-proxy合并不同数据节点返回的数据,并将最终结果返回给客户端
也就是说我们连接的是shardingsphere-proxy ,shardingsphere-proxy连接的MySQL
安装
这里以5.3.2为例
sql# 解压 tar -zxvf apache-shardingsphere-5.3.2-shardingsphere-proxy-bin.tar.gz # 重命名目录 mv apache-shardingsphere-5.3.2-shardingsphere-proxy-bin shardingsphere-proxy # 安装JAVA运行时环境,JRE apt-get update apt install openjdk-17-jre-headless # 在解压目录(shardingsphere-proxy)中创建ext-lib目录,用于存放MYSQL驱动
配置文件介绍
配置文件 在安装目录中的conf文件夹
bin目录下存放的是linux和win环境下的启动脚本
修改配置文件
这些在配置文件中以及存在,只需要取消注释后稍加修改即可,具体配置见操作手册
sql
authority: # 授权
users: # 用户配置
- user: root@% # 配置一个用户,用户名为root@%
password: 123456 # 为用户指定密码
privilege: # 权限
type: ALL_PERMITTED # 授予用户所有权限
props: # 属性配置
sql-show: true # 显示执行的SQL语句读写分离实践
如果使用了事务,那么读和写都会被路由到写节点!!!!!!
**1. 读多写少场景:**很多应用程序都是读多写少的场景,读写分离可以将读请求分散到多个从服务器上,从而减轻主服务器的负担,显著提高读操作性能
2. 水平扩展: 通过增加从服务器 数量,可以进一步扩展数据库的读能力
**3. 故障转移:**在主服务器发生故障时,可以快速将读和写操作切换到从服务器,保证服务的可用性
4. 实时备份:从服务器 也可以作为主服务器的实时备份节点,当主服务器发生故障的时,可以快速恢复数据
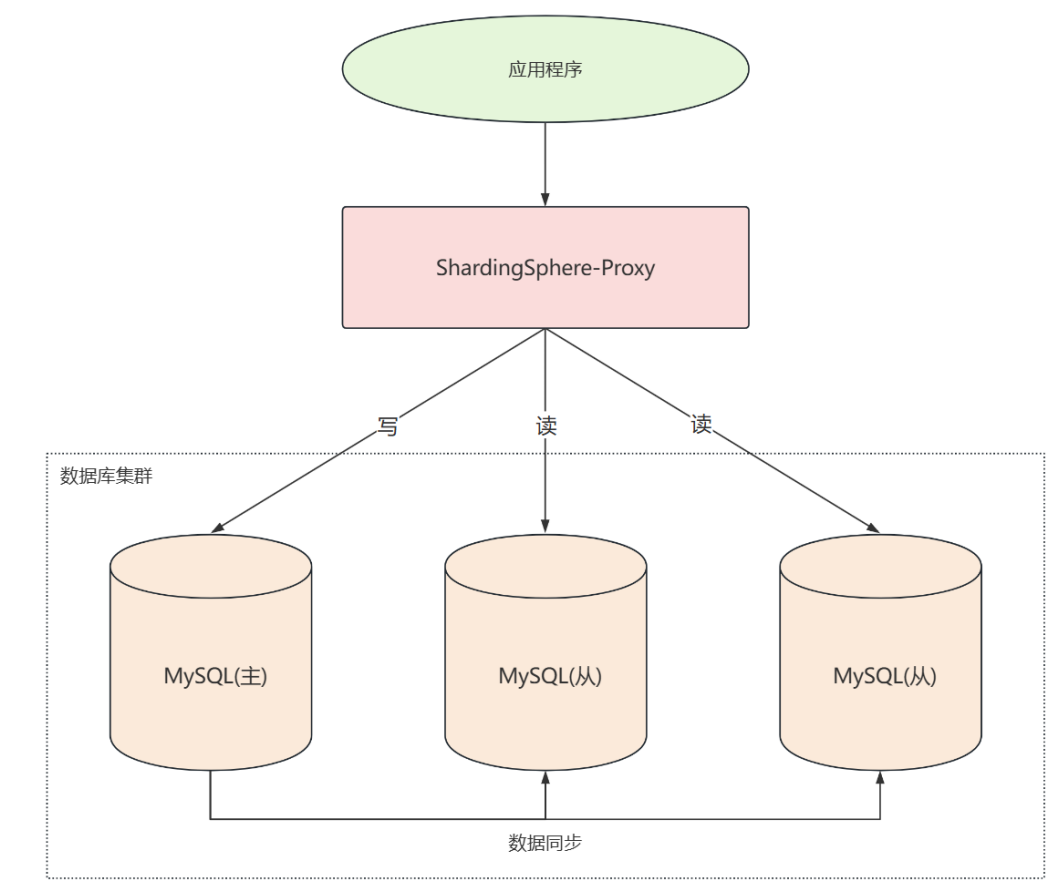
在单台服务器上使用Docker模拟多台服务器的场景,主从IP一致,端口号不同
配置读写分离
修改database-readwrite-splitting.yaml文件,从下图的位置开始为mysql的配置

javascript
databaseName: shardingsphere的逻辑库名
dataSources:
写数据源名:
url: jdbc:mysql://IP:端口号/bit_db?characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useSSL=false
username: 用户名
password: 密码
connectionTimeoutMilliseconds: 连接超时时间毫秒
idleTimeoutMilliseconds: 连接池中空间连接超时时间
maxLifetimeMilliseconds: 连接池中连接关闭后的最长生命周期
maxPoolSize: 连接池最大连接数
minPoolSize: 连接池最小连接数
读数据源名:
url: jdbc:mysql://IP:端口号/bit_db?characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useSSL=false
username: 用户名
password: 密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
读数据源名:
url: jdbc:mysql://IP:端口号/bit_db?characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useSSL=false
username: 用户名
password: 密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !READWRITE_SPLITTING
dataSources:
逻辑组名(唯一):
staticStrategy:
writeDataSourceName: 写节点数据源名
readDataSourceNames:
- 读节点数据源名
- 读节点数据源名
loadBalancerName: 自定义负载均衡器名字
loadBalancers:
自定义负载均衡器名字:
type: 负载均衡器算法RANDOM-随机、ROUND_ROBIN-轮询、WEIGHT-权重新建logback.xml日志文件
javascript
<?xml version="1.0"?>
<configuration>
<!-- 日志输入到文件 -->
<appender name="SHARDING_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 日志路径 -->
<file>./logs/shardingsphere.log</file>
<encoder>
<!-- 日志输入的样式 -->
<pattern>[%-5level] %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>shardingsphere.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
</appender>
<root level="INFO">
<appender-ref ref="SHARDING_FILE" />
</root>
</configuration>配置完成后重启ShardingSphere的Docker容器
日志查询
通过tail实时查询日志更新
javascript
tail -f shardingsphere.log

可以发现,读和写被分配到了不同的服务器。
负载均衡
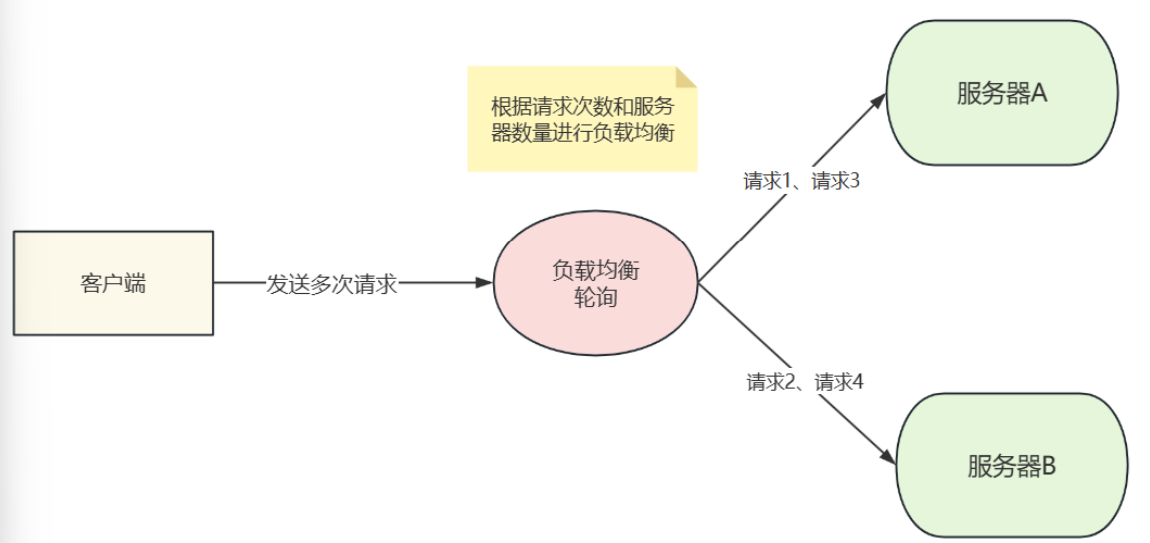
轮询算法:
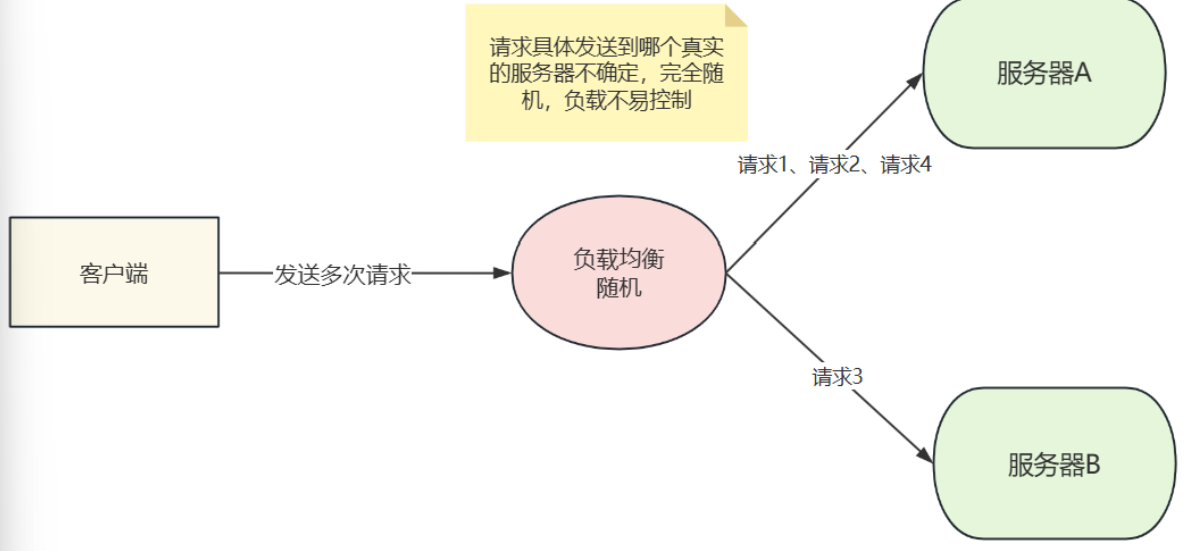
随机访问算法:
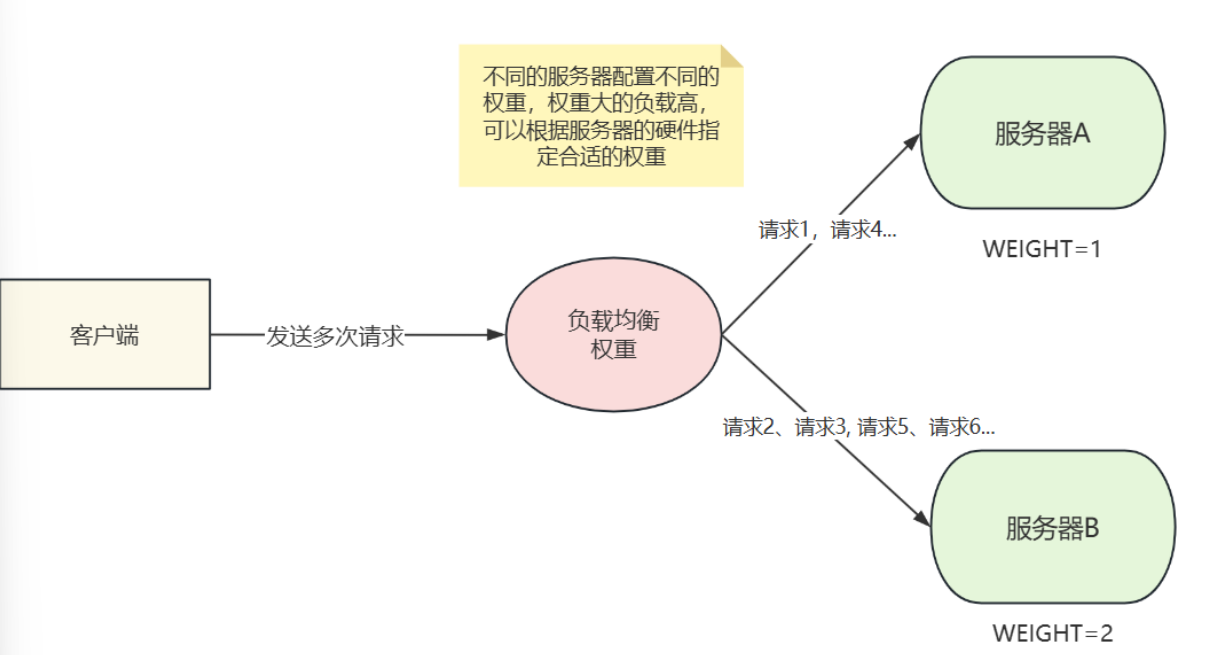
权重访问算法:
要为服务器设置权重,权重值为double类型
props: # 为不同的读节点配置权重,与type同级 数据库名: 值 数据库名: 值
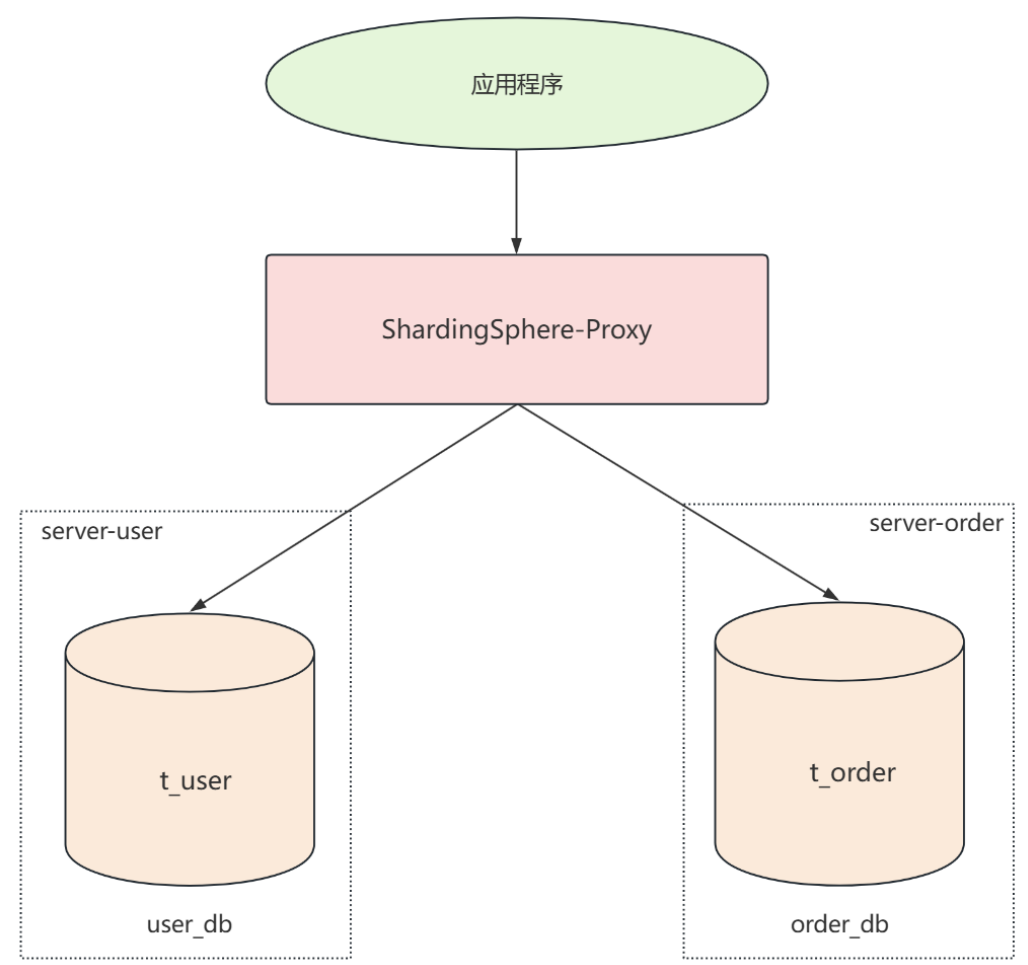
垂直分片
主要介绍垂直分库 ,通过ShardingSphere将对不同表 的操作,路由到指定的服务器
创建Docker容器并修改配置文件
创建server-user和server-order两个docker容器,并为其映射不同的端口号以及文件目录。创建完成后,再分别创建用户表和订单表。创建容器的操作与配置主从复制时相同
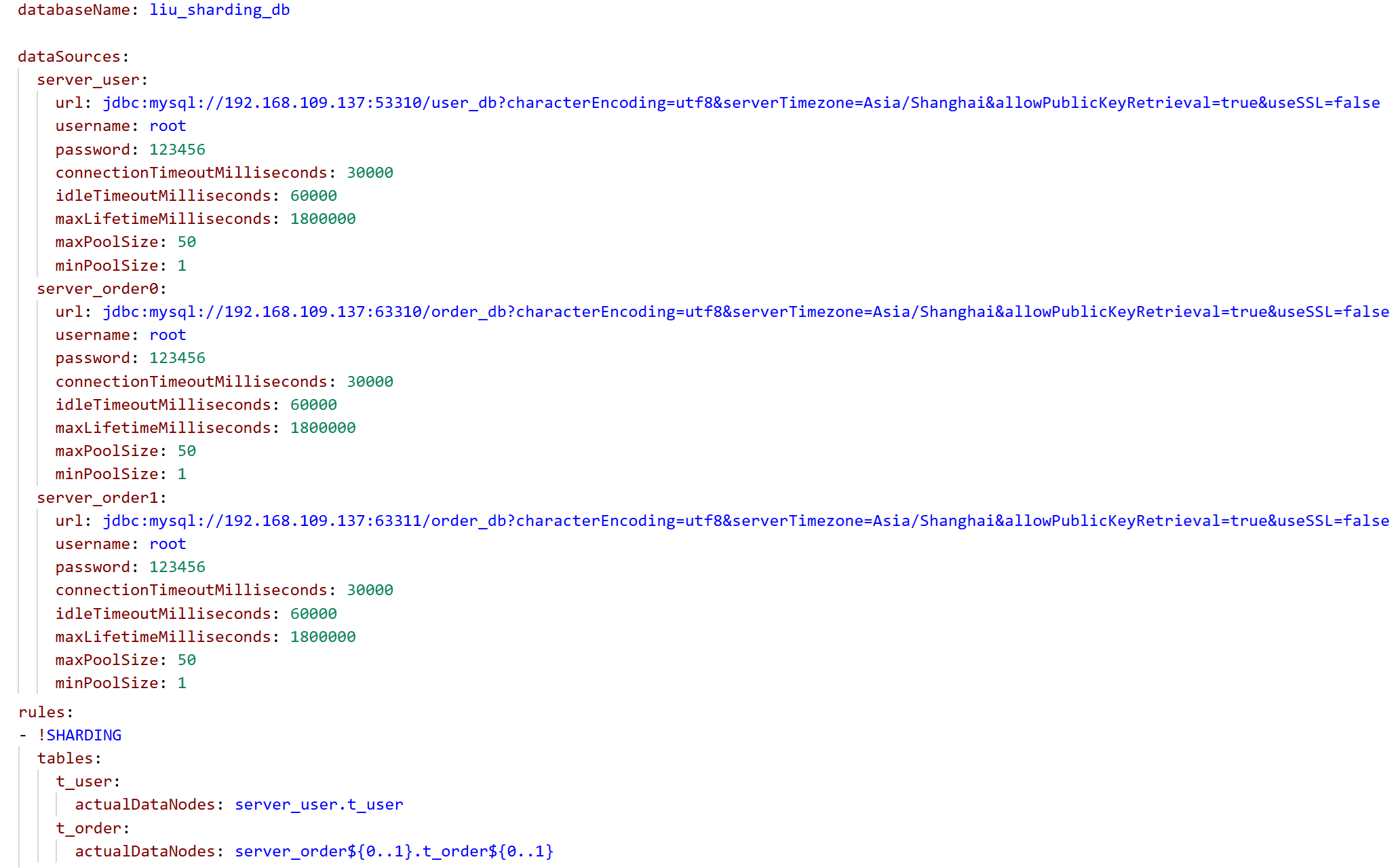
编辑config-sharding.yaml文件
databaseName: 逻辑库名,对应用程序暴露的库名
dataSources:
数据源名:
url: jdbc:mysql://IP:端口号/数据库名?
characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=tr
ue&useSSL=false
username: 用户名
password: 密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
数据源名:
url: jdbc:mysql://IP:端口号/数据库名?
characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=tr
ue&useSSL=false
username: 用户名
password: 密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
逻辑表名(代码中直接操作的表名,映射到真实的表(数据节点)):
actualDataNodes: 数据源名.真实表名 真实数据节点
因为垂直分库将不同的表分散在了不同的数据器上,所以要指定具体的数据节点
逻辑表名:
actualDataNodes: 数据源名.真实表名日志查询
可以发现SharadingSphere将不同的表路由到了与之对应的节点

水平分片
下图同时进行了水平分片和水平分库 ,用不同的数据库来部署不同的数据分片,去进一步提升系统的性能,在前面垂直分库的基础上,对t_order 进行横向拆分。
水平分库:server-order0 和server-order1
水平分表: 每个数据库中的t_order0 和t_order1
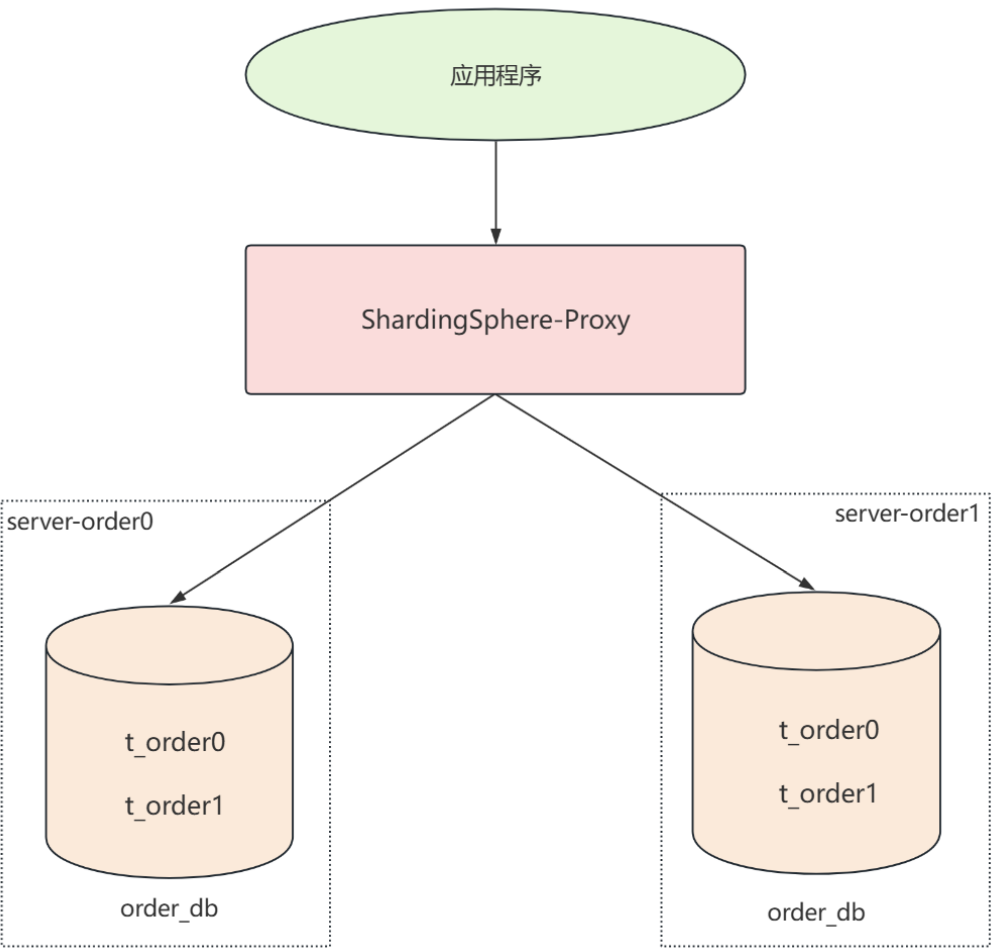
创建docker容器并修改配置文件
创建server-order0和server-order1两个docker容器,并为其映射不同端口号以及文件目录。并登录两个服务器的MySQL并创建数据库。水平分片后由于数据分布在不同数据节点,所以主键值不能依赖自增值,生成策略由业务层实现,插入记录时指定一个主键值。
修改配置文件:
数据分片策略:
需要配置的文件是config-sharding.yaml ,配置server_user、server_order0、server_order1三个数据源,配置方法与垂直分片一样。
分库策略:
根据订单表中的user_id 来确定数据写入哪个数据节点(数据库),从而避免跨库事务和跨库查询
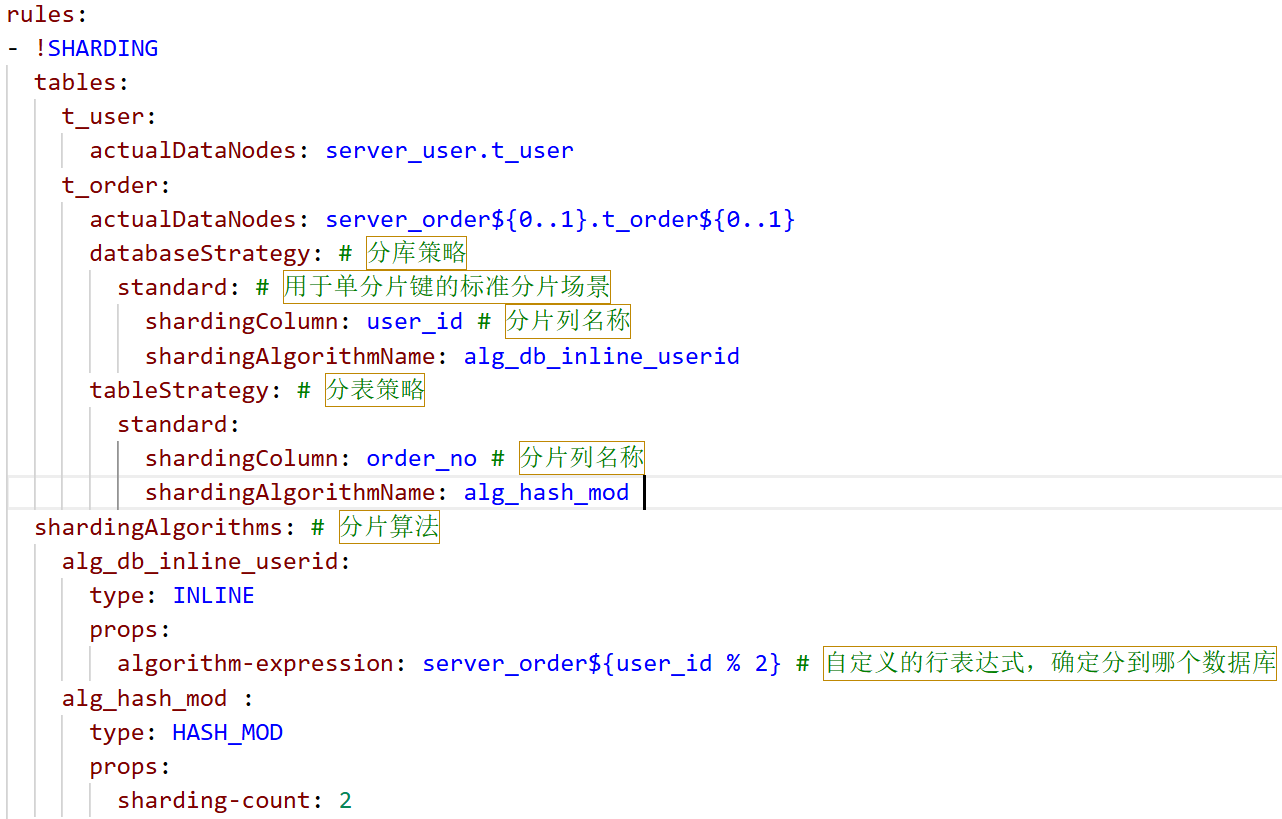
rules: - !SHARDING tables: t_user: actualDataNodes: server_user.t_user t_order: actualDataNodes: server_order${0..1}.t_order${0..1} databaseStrategy: # 分库策略,以下分库策略选其一 standard: # 用于单分片键的标准分片场景 shardingColumn: user_id # 分片列名称 shardingAlgorithmName: # 分片算法名称(自定义) complex: # 用于多分片键的复合分片场景 shardingColumns: 分片列名称,多个列以逗号分隔 shardingAlgorithmName: # 分片算法名称(自定义) hint: # 分片策略 shardingAlgorithmName: # 分片算法名称(自定义) none: # 不分片 分片算法名称: # 分片算法配置 alg_db_inline_userid: type: INLINE # 分片算法类型 props: algorithm-expression: server_order${user_id % 2} # 自定义的行表达式 确定分到哪个数据库我们也可以使用取模分片算法:
算法名: type: MOD # 分片算法类型,用于数值类型 props: sharding-count: 分片数量,表示根据分片列对2取模 算法名: type: HASH_MOD # 分片算法类型,用于字符串类型 props: sharding-count: 分片数量,表示根据分片列对2取模分表策略:
根据订单记录中的order_no 来确定数据写入哪个数据节点(表) ,策略种类与分库策略相同,使用哈希取模算法。
至此,所有配置文件配置成功
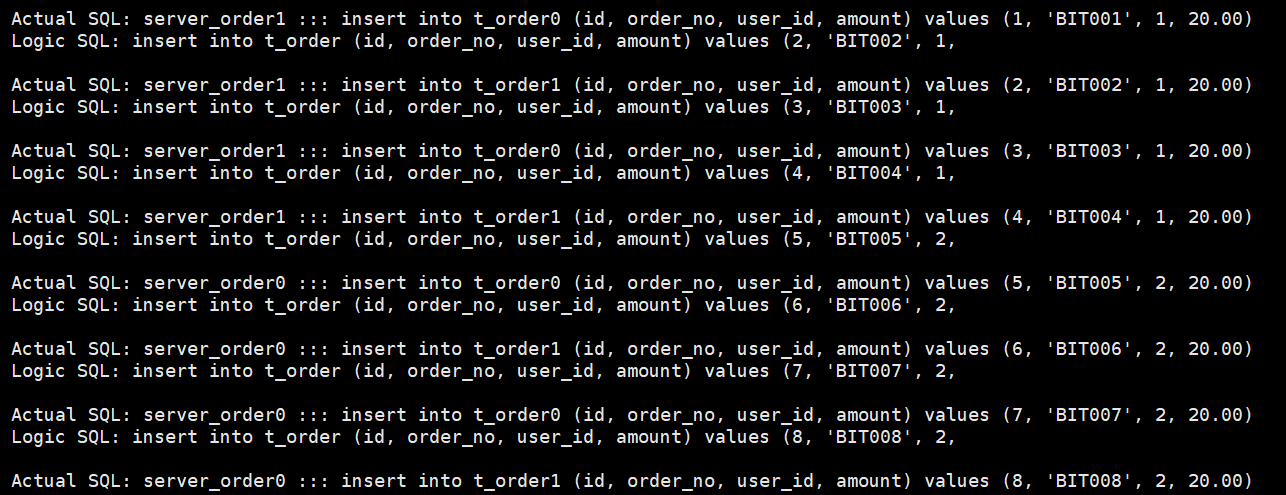
日志查询
插入测试:
查询测试:
ShardingSphere在所有的节点查询记录,并把各个节点的记录组装好 ,统一返回客户端

分布式序列算法
单表 中使用自增主键 就可以满足表中主键的唯一性,但在数据分片 的环境里,如果只依赖于单个分片的自增特性,那么这些分片表之间无法相互感知,就可能出现主键重复的现象。在ShardingSphere中间件这一层实现了分布式序列算法 ,在写入数据前,先生成 全局唯一的主键值,把这个值插入到主键值 再进行数据插入,以保证全局主键不冲突
UUID
可以生成时间、空间上都独一无二的值,但是由于UUID是无序的,不太适合作为数据库的主键
雪花算法
ShardingSphere在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法 生成有序的64bit的长整型数据
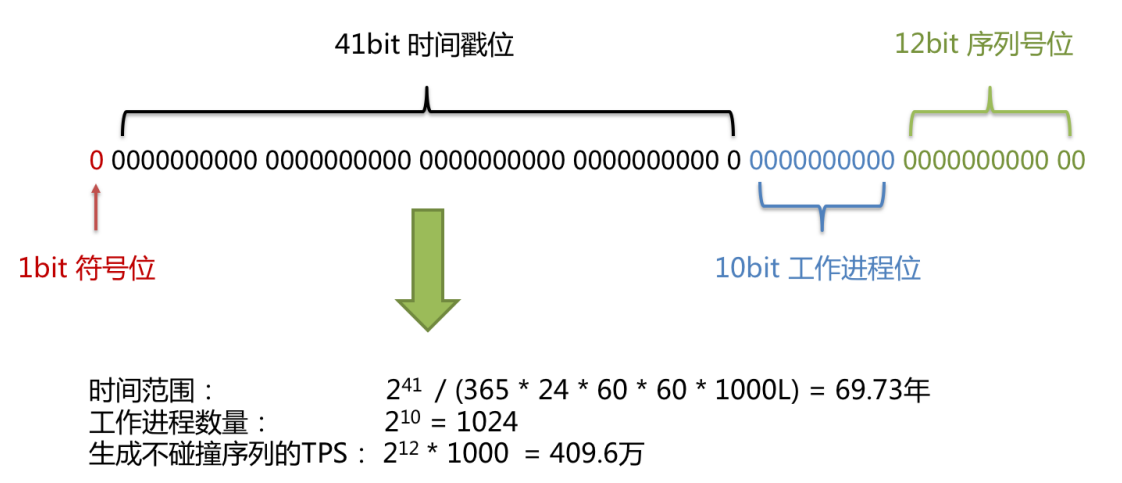
使用雪花算法生成的主键,二进制表示形式包含四个部分,从高位到低位 分别为:符号位,时间戳位,工作进程位,序列号位
符号位:
预留的符号位,恒为零
时间戳位:
41位的时间戳可以容纳的毫秒数是2^41 ,根据计算,41位时间戳可以保存约69.73年的时间范围。ShaedingSphere的雪花算法从2016年11月1日零点开始,可以使用到2086年
工作进程位:
该标志在Java进程内是唯一的 ,如果是分布式应用部署,应保证每个工作进程的Id是不同的,该值默认是0,最多可表示1024台机械
序列号位:
用来对同一机器 在同一个毫秒内 生成不同的ID ,如果在这个毫秒内生成的数量 超过4096个,那么会等到下一毫秒生成
时钟回拨
服务器时钟回拨 会导致产生重复序列 ,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数 。如果时钟回拨的时间超过了最大容忍的毫秒数阈值,则程序报错。如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间 后继续工作。最大容忍的时钟回拨毫秒数默认是0
分布式序列配置
修改config-sharding.yaml文件
keyGenerateStrategy: # 分布式序列策略
column: id # 列名
keyGeneratorName: alg_snowflake # 分布式序列算法名
keyGenerators:
alg_snowflake: # 分布式序列算法名
type: SNOWFLAKE # 算法类型配置完成后,插入数据可不自行插入主键
多表关联查询
在实际业务中,订单表 通常与订单详情表 关联,订单详情记录用户购买商品的单价以及个数,订单与订单详情是一对多 关系。为了避免跨库关联,把同一个用户 产生的订单数据 以及订单详情数据 存在同一数据库中,因此两张表可以采用相同的分片策略。
绑定表
配置config-sharding.yaml文件
bindingTables:
- t_order,t_order_item # 设置需要根据分片规则绑定的表,绑定的表
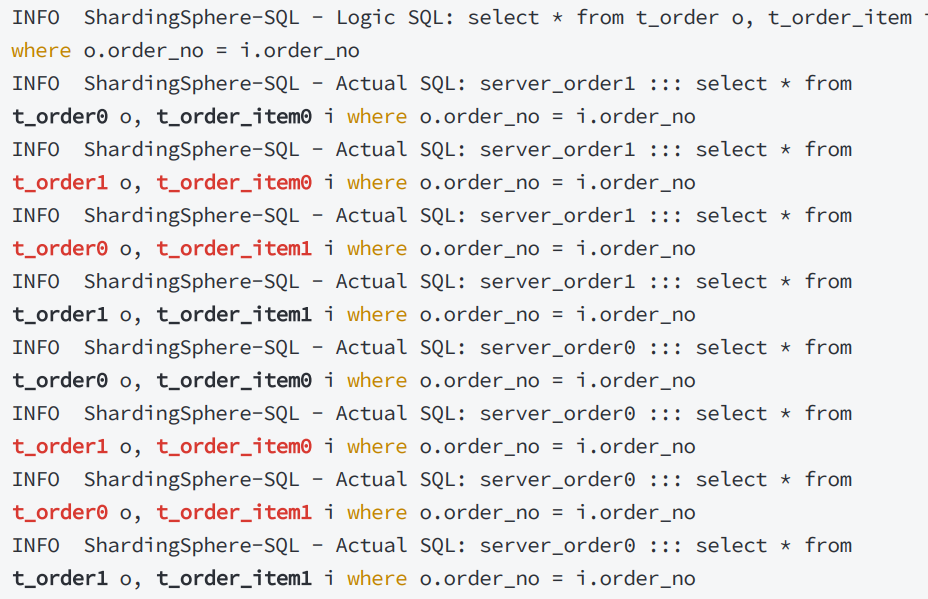
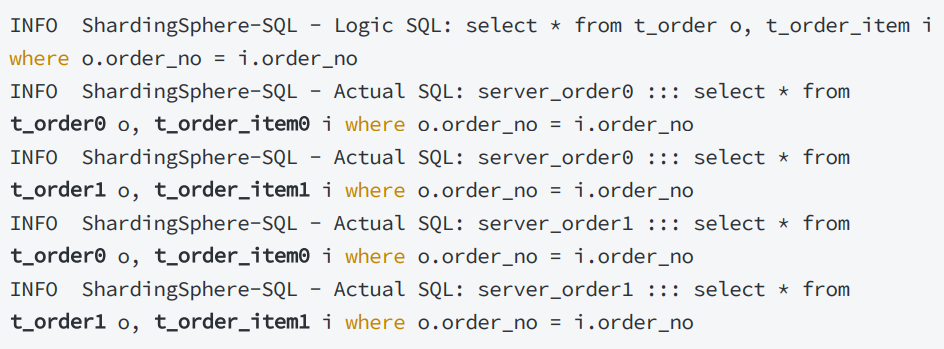
应使用相同的分片规则设置完绑定表之后,再通过分片键 进行联合查询,可避免无效关联,以下是对比
不设置绑定表:
设置绑定表:
广播表
分布式数据库的所有分片数据源 都存在的表 ,其表结构及其数据 在每个数据库节点中保持完全一致 。设置广播表的目的主要是通过数据冗余 ,将原本需要跨库的分布关联 转化为本地关联,提升查询效率
1. 插入更新操作会通过分布式中间件实时在所有数据节点上执行,以保证数据的一致性
2. 执行查询时,系统仅从随机一个数据节点获取数据
3. 广播表可以与任何分片表在本地进行join操作,不受分片键的限制
配置
修改config-sharding.yaml文件
broadcastTables:
- 表名CAP理论
CAP理论 又称布鲁尔定理,用来描述分布式系统再设计时必须做出的三个关键需求之间的权衡。
分布式系统: 指多台真实的服务器共同组合在一起对外提供完整的服务
一致性( Consistency ): 在分布式系统中,多个数据节点之间能否保持同步 ,在一致性要求下,任何写操作完成后,所有后续的读操作都应该返回最新的值
可用性( Availability ): 可用性指系统在任何时候 都能够响应用户的请求(在合理的时间返回合理的值)。即使某些节点发生故障,系统仍可对外继续提供服务
分区容错性( Partition tolerance ): 分区容错性指系统在遇到节点之间的通信失败 的情况下,仍然能够继续运行。这是分布式系统中的一个基本要求,因为网络问题在分布式系统中是不可避免的
核心观点
一个分布式系统不可能 同时满足一致性、可用性和分区容错性这三个需求,只能满足其中两个,另外一个必须牺牲。在分布式系统中,系统间的网络不能100%保证健康,一定会有故障的时候,而系统必须对外保证服务。因此分区容错性必须得到保证
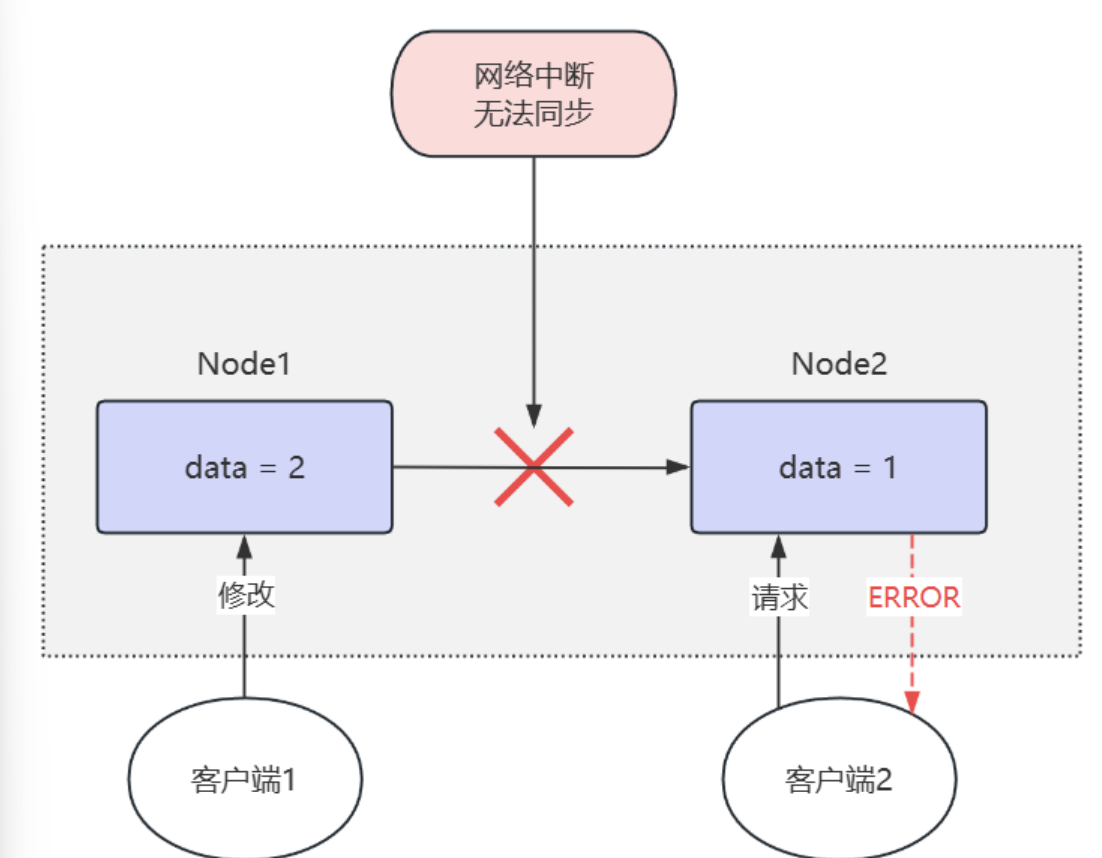
CP系统
在网络故障发生时,系统选择牺牲可用性 ,从而保证一致性。例如拒绝服务直到网络修复数据同步完成再恢复服务,此时系统可用性受到影响
AP系统
如果系统保证分区容错性和高可用性 ,那么必须牺牲一致性 ,返回给客户端一个合理的值 。这种系统可能会允许数据在不同节点间暂时出现不一致,但最终会通过一些机制(如异步复制)来达到最终一致性
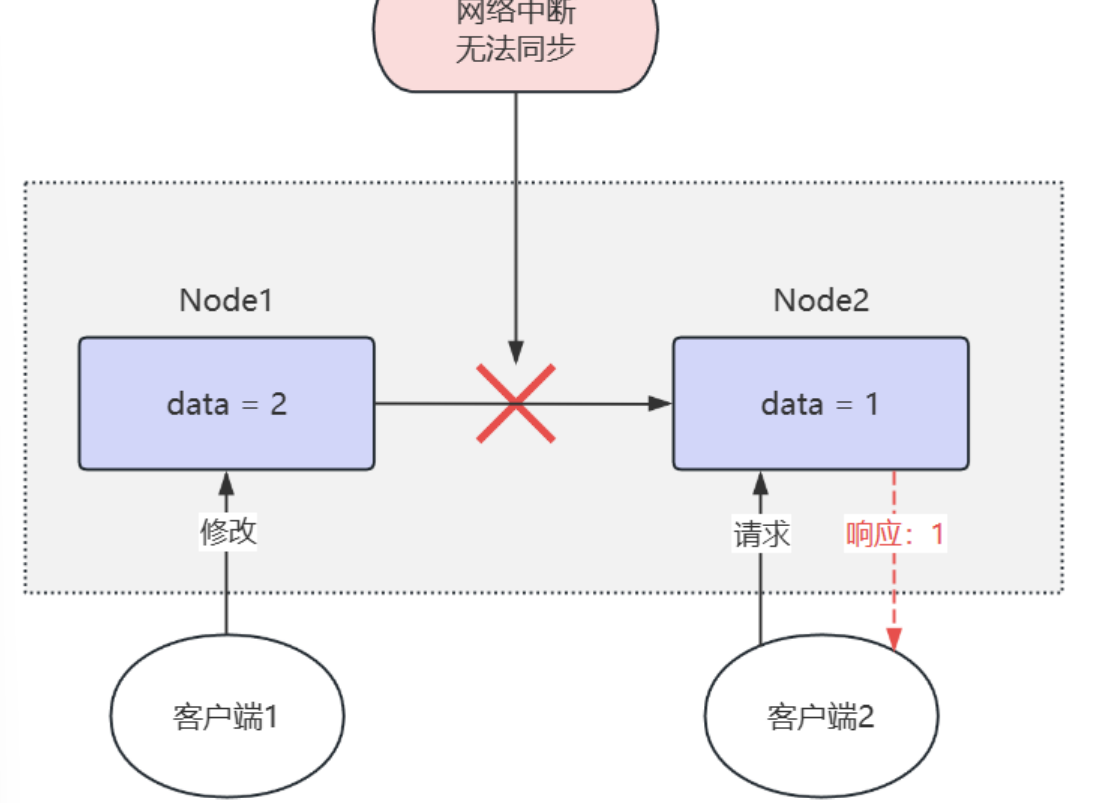
在这个场景中,返回的虽然不是一个正确的结果,但是是一个合理的结果,因为1只是旧数据 ,不是一个错误的值
BASE理论
在分布式系统中,由于网络分区和其他因素,强一致性可能难以实现,因此系统设计可以允许数据在一段时间内不一致,但最终达到一致状态
基本可用: 分布式系统在出现故障时,尽管可能无法提供完整的服务,但仍然能够提供核心功能,从而保证系统的基本运行。
软状态: 系统中的数据可以存在中间状态 ,这种状态不会影响系统的整体可用性。比如分布式系统中不同节点的数据可能会暂时不一致 ,这种不一致状态被接受为软状态
最终一致性: 最终一致性强调的是,经过一段时间后,系统中所有数据最终会达到一致状态