
欢迎来到雲闪世界。到目前为止,本系列已经介绍了线性规划的基础知识。在本文中,我们将从基本概念转向底层细节!本文将介绍单纯形法,这是通常用于解决线性规划问题的算法。虽然我们将使用单纯形法手动解决一个简单的线性规划示例,但我们的重点是算法的直觉,而不是记住算法步骤(我们有计算机来做这种事情!)。
以下是我们将要介绍的内容:
-
为什么需要单纯形法
-
从图形解决方案转向代数解决方案
-
用一个简单的例子来演示单纯形法的工作原理
为什么需要单纯形法 在本系列的第一篇文章中,我们讨论了线性规划的属性如何使其仅将约束的角点视为潜在的最优解。这是一个非常强大的功能,可将无限的解空间缩小到有限的解空间。在我们回顾的例子中,我们只有几个约束和几个变量------我们甚至手动解决了其中一些!看了一些简单的例子后,人们可能会认为,采用穷举、蛮力(查看每个角点)的方法来寻找最优解就足够了。 虽然对于较小的 LP 问题,蛮力法是可行的,但随着问题变得越来越复杂,角点的数量可能会激增。角点总数(包括可行和不可行)取决于 (1) 问题中的变量数量和 (2) 约束数量。
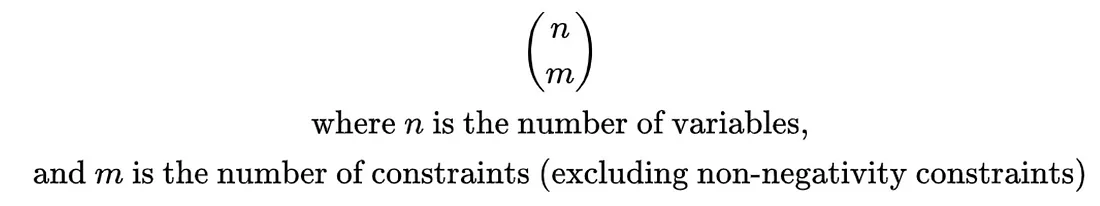
角总数的公式
下面是多个变量和约束组合的角点数量增长的一些例子:
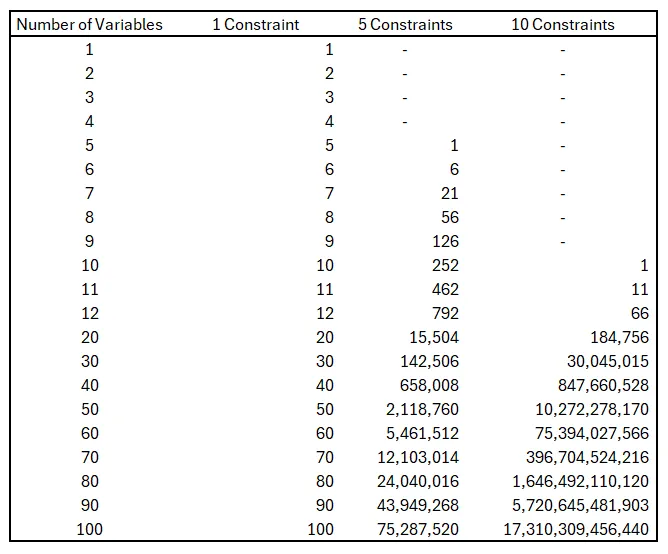
角点数量的快速增长
角点的快速增长需要一种更聪明的方式来寻找最优解------进入单纯形法!单纯形法是一种聪明的方法,它只考虑所有可能解决方案的一小部分,同时仍能保证全局最优结果------我们将在下文中详细介绍。 从图形解决方案转向代数解决方案 在学习线性规划的基础知识时,查看具有两个决策变量的优化问题的图形表示确实很有用。我们在第 1 部分中介绍了这一点。虽然这对于加深对基础知识的理解非常有效,但它不能很好地推断出更复杂的问题。它的用处基本上仅限于教学目的。 为了进一步加深对 LP 的理解,并准备开始讨论单纯形法的细节,我们需要了解如何将 LP 问题转换成代数格式。 建立代数系统的主要组成部分之一是将约束不等式转换为等式。在 LP 上下文之外,没有很好的数学方法可以做到这一点。但请记住,对于 LP,我们实际上只对角点感兴趣?并且所有角点都在线上?由于我们实际上只关心解空间的边界,因此我们基本上忽略了不等式!同样,这是因为我们无论如何都不会担心不在空间边界线上的区域。 很好,让我们把所有不等号都换成等号,这样就可以了,对吧?别那么急!当我们考虑角点时,我们通常不会同时在所有线上。因此,我们需要添加一种方法来"跳"上和跳下特定的约束线。这有点难以用语言解释------讽刺的是,我将用图形来解释这个概念......
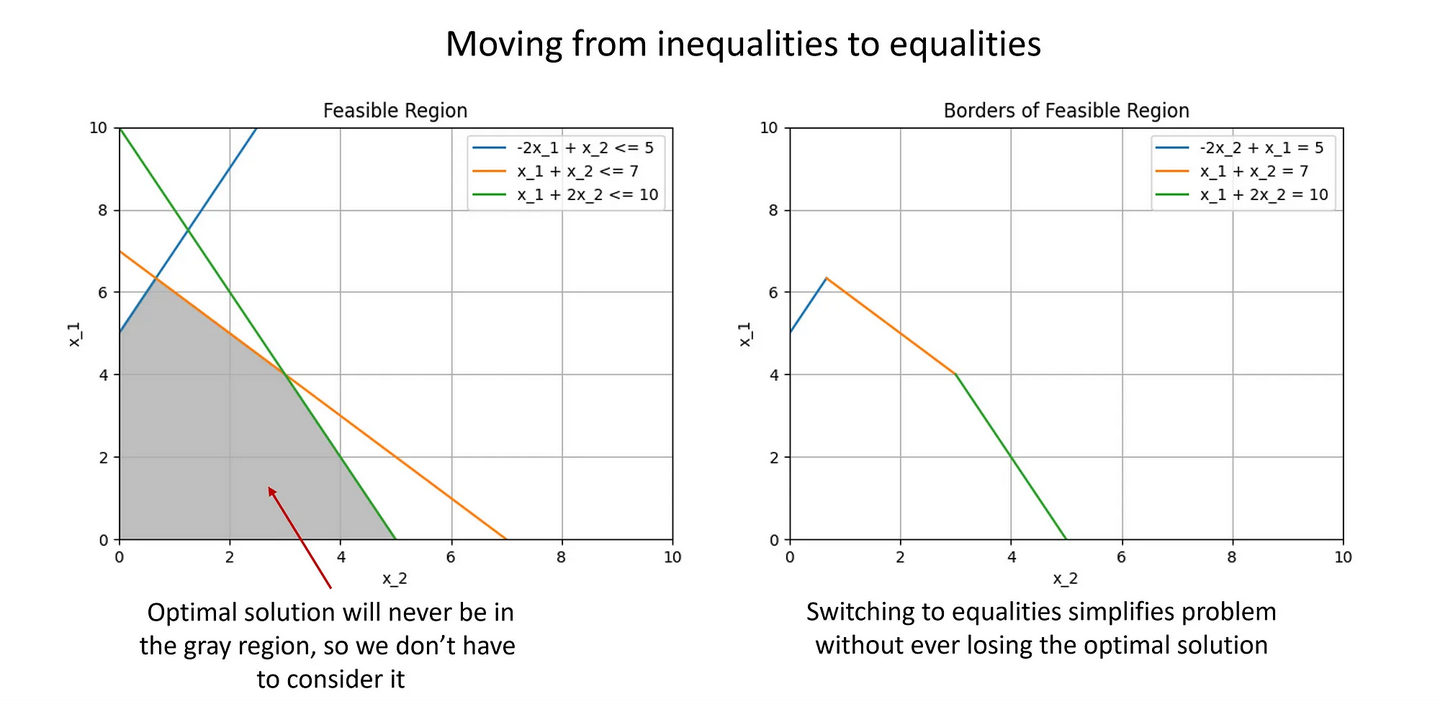
从不平等转向平等
好的,现在看看为什么我们可以消除不平等而获得平等------但我们有一个大问题。让我们通过研究特定角点的数学来探讨这个问题:
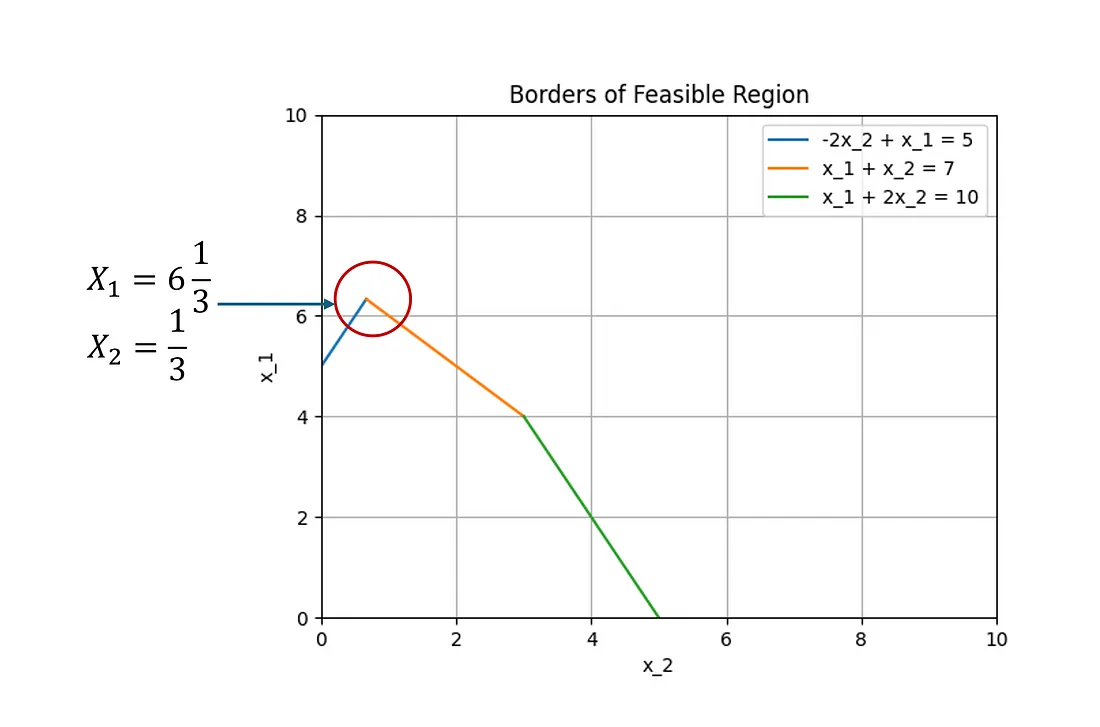
添加图片注释,不超过 140 字(可选)
让我们将这些 X₁ 和 X₂ 值代入所有线性约束中:

添加图片注释,不超过 140 字(可选)
我们在这里看到,更严格的等式导致 X₁ 和 X₂ 的值对于第三个约束来说不是可行的选择。我们需要一种方法,让我们能够处于拐角处,同时让变量值在所有约束公式中起作用。 上述问题的解决方法是创建松弛变量。松弛变量被添加到每个等式中,使我们能够灵活地一次只考虑一个角所涉及的约束。 我们可以通过将涉及的约束的松弛变量设置为 0 来"跳"到角点。对于不涉及的其他约束,我们可以将松弛变量设置为方程式的决策变量侧和方程式的常数侧之间的差值(或松弛值)。

添加松弛变量使我们能够灵活地"跳"到角点
如果松弛变量设置为 0,则该约束是我们正在考虑的角点中的约束之一。如果它不为零,则我们知道特定约束不涉及所考虑的角点。 好的,将不等式设置为等式并创建松弛变量后,我们就可以代数地解决线性规划问题了。现在让我们详细了解单纯形法如何使用此设置进行有效优化! 注意:当我们在上一节讨论可能的角点数量时,n包括松弛变量,而不仅仅是原始决策变量。 用一个简单的例子来演示单纯形法的工作原理 首先,单纯形法是一种有效地从一个角点移动到另一个角点的算法,计算角点的目标值,直到找到全局最优解。单纯形法是一种贪婪算法,它移动到使目标函数增加(最大化)或减少(最小化)最多的角点。贪婪算法通常因寻找次优解而臭名昭著------但由于线性规划的特点,单纯形法保证找到最优解。 我想花点时间直观地了解一下为什么贪婪算法(如单纯形法)能够找到线性规划的全局最优解。贪婪算法的定义属性是它仅根据即时信息做出最佳
决策。通常,一系列局部最优决策不会导致全局最优解------但正如我所提到的,线性规划并非如此。它成立的原因是因为约束的线性要求。让我们看一个使用线性函数做出最佳决策的例子。 想象一下,我们处于两个函数的交点------我们想要选择能够为下一个 x 值提供最高 y 值的函数。
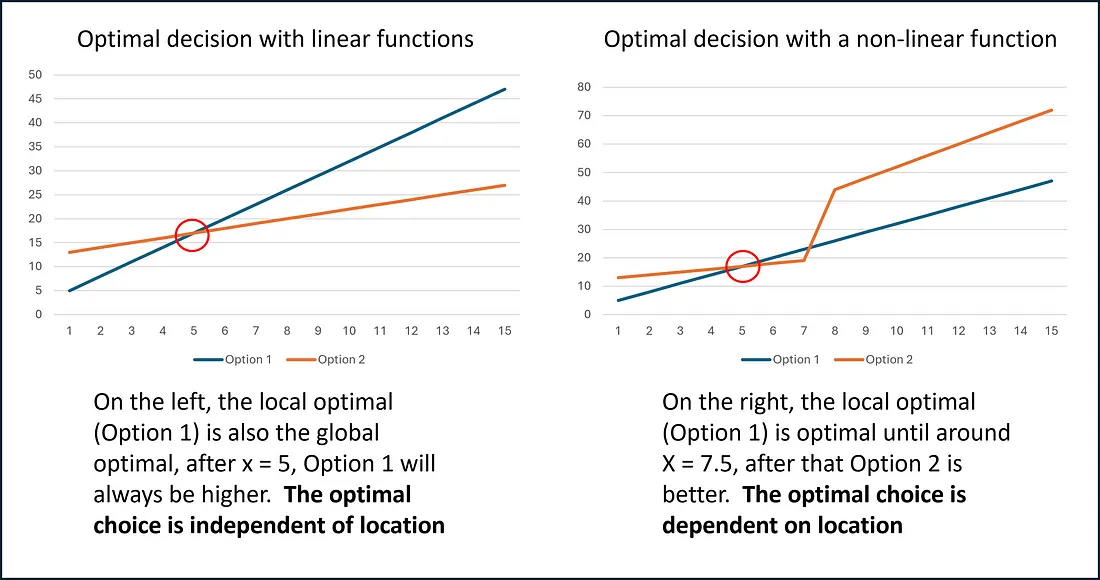
证明对于线性函数,局部最优决策也是全局的
单纯形法使用非常类似的方法以贪婪的方式移动到不同的角点。单纯形法的关键之一是,当找不到更好的相邻角点时,它会终止。由于解空间的凸性,这个角点既是局部最优解,也是全局最优解。 直观示例 在对单纯形法的设置和它的作用有基本了解(贪婪地迭代角点以找到全局最优解)之后,我想我们已经准备好开始通过一个例子来研究了。 到目前为止,我们已经讨论了三个约束,但尚未建立目标函数。为此,我们将得出一些系数来给出 X₁ 和 X₂,并将添加所有系数为 0 的松弛变量(这使优化表完整)。 以下是我们要解决的问题:
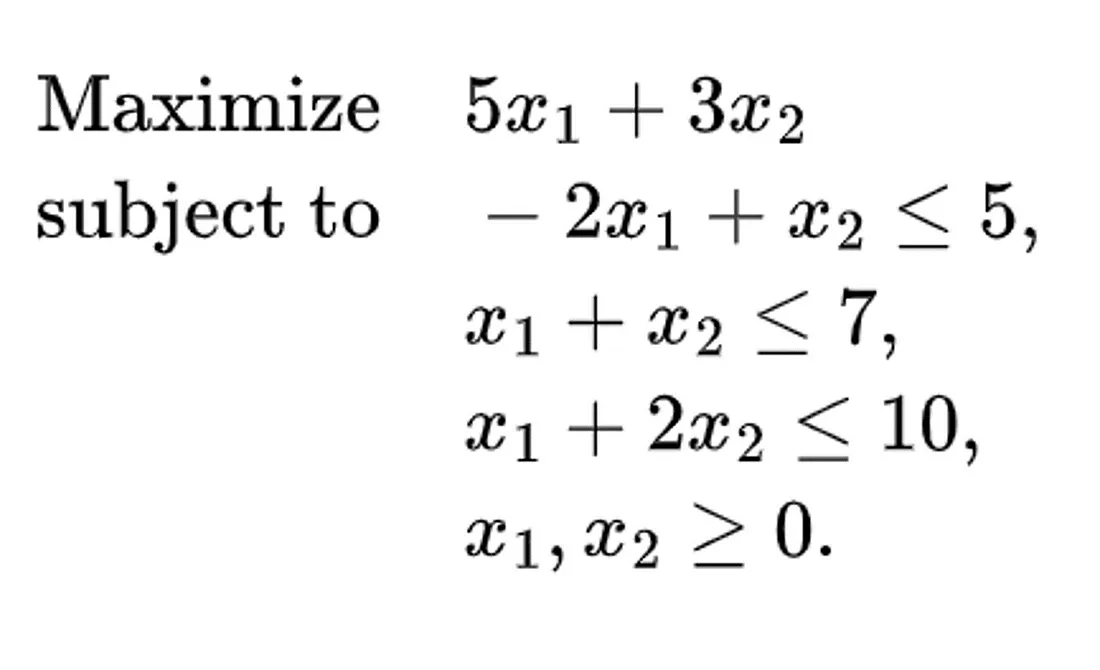
添加图片注释,不超过 140 字(可选)
让我们将这组线性方程式准备好。我们将从上面已经讨论过的约束开始。它们看起来是这样的:
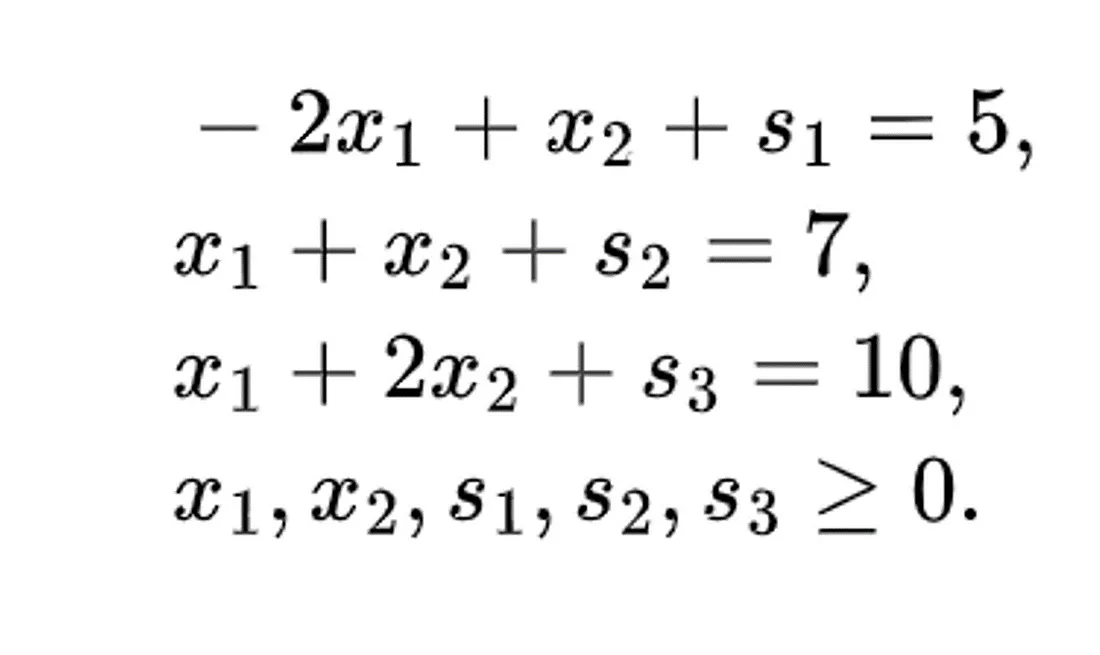
添加图片注释,不超过 140 字(可选)
我们还没有讨论如何修改目标函数以适应单纯形法。这很简单,我们将目标值设置为Z,然后将函数代数变换为右侧为 0 的位置。如下所示:
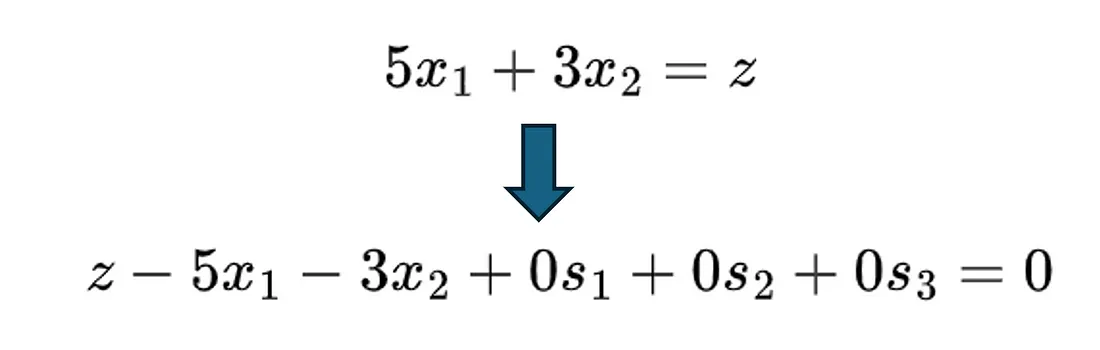
添加图片注释,不超过 140 字(可选)
请注意,我们为松弛变量添加了 0,它们对目标没有任何价值,但当我们开始构建单纯形表时,这种公式设置将会很有帮助。 单纯形表是单纯形法中用来遍历角点并计算其目标函数值的数据表。它还具有在找到最优值后停止探索的功能。 该表有一行用于目标函数,每行用于每个约束。在算法执行的任何时刻,都有基本变量和非基本变量。随着算法的进展,变量在这些类别之间切换。基本变量是未设置为 0 的变量,您可以将它们视为活动的变量。非基本变量是值为 0 的变量,您可以将这些变量视为已停用。单纯形法总是从原点开始。在原点,所有决策变量都设置为 0,这意味着只有松弛变量是基本的,即非零或"活动的"。起始表将在开始时将松弛变量显示为非基本变量。 下面是我们示例的起始画面:

添加图片注释,不超过 140 字(可选)
好的,现在我们已经完成了初始设置,可以开始单纯形法的第一次迭代了。我们需要开始远离原点 --- 方法是将其中一个松弛变量移到非基本变量中,并将其中一个决策变量拉入基本解决方案集。但是我们要取出哪个松弛变量,又要引入哪个X ? 首先,我们来弄清楚要使哪个变量成为基本变量。还记得我们说过单纯形算法是贪婪的吗?这就是它发挥作用的地方!我们查看 z 行的系数并选择具有最大负系数的变量。这是一个最大化问题,但请记住,我们交换了系数的符号以在右侧获得 0,因此负数 = 好,正数 = 坏。最大负系数与现在将最大增加目标函数的变量相关。我们的选项是 X₁ 为 -5,X₂ 为 -3,因此我们选择 X₁。这被称为进入变量------幸运的是,这是一个非常直观的名称!

添加图片注释,不超过 140 字(可选)
现在,让我们讨论如何找到松弛变量,使其变为非基本变量或停用/移除。在单纯形术语中,被移除的变量(也直观地)称为离开变量。我们想要找到可以设置的进入变量的最大值,而不会违反任何约束。这意味着我们需要找到与 X₁ 上最严格/最严格的约束相关的松弛变量。我们可以通过取"解决方案"列与约束的 X₁ 系数的比率来实现这一点。X₁ 的约束系数为 -2、1 和 1 --- 相应的"解决方案"列值为 5、7 和 10。
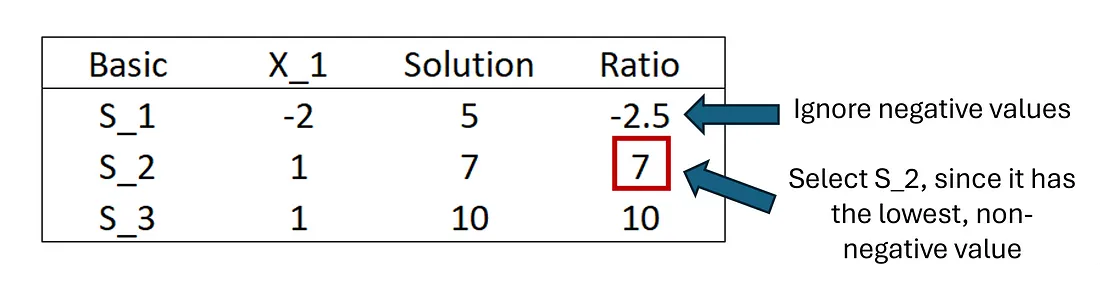
S_2 具有最低的非负比率,因此它将被选为离开变量。
这是此选择背后的直觉。我们试图找到 X₁ 可以取的最大值,同时与它所属的线性方程组保持一致。对于第一个约束,实际上任何事情都可以发生,因为 X₁ 系数为负 - 其他变量可以在任何级别进行补偿,以使整体方程等于 5。显然,"任何事情都可以"并不是一个非常严格的约束😄!
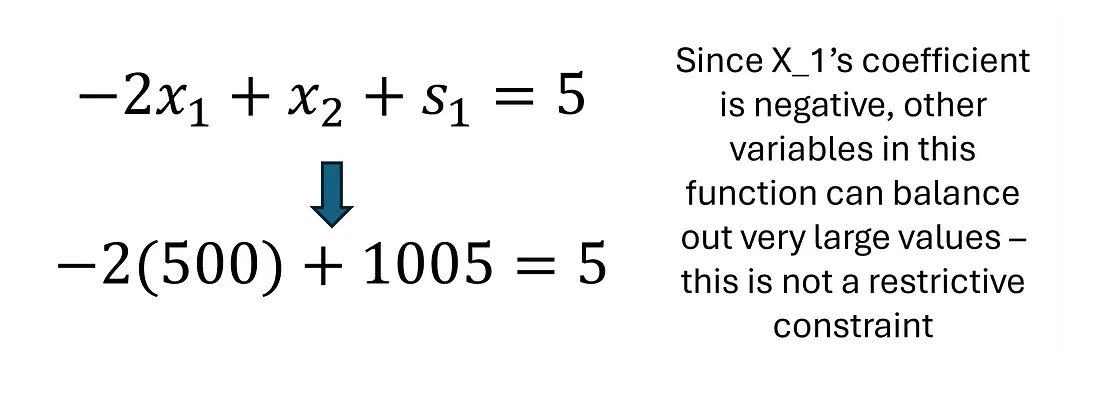
添加图片注释,不超过 140 字(可选)
对于第二个约束,当 S₁ 和 X₂ 设置为 0 时,X₁ 的最大值将实现,这个最大值是 7。我们看到还有其他变量的值可以使线性方程组起作用。
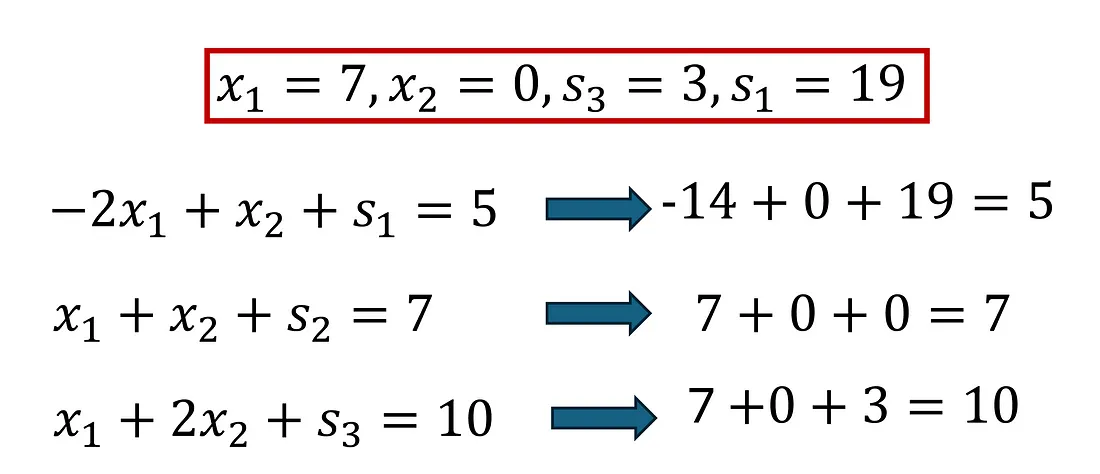
值的存在使得线性方程组不会失效
现在让我们看看最后一个选项,即将 X₁ 设置为 10。这会导致大问题;请记住,所有变量都必须≥0。如下所示,如果 X₁ 的值为 10,则无法使第二个约束起作用。因此,在不违反线性方程组中的函数的情况下,我们可以将 X₁ 设置为的最高值为 7。
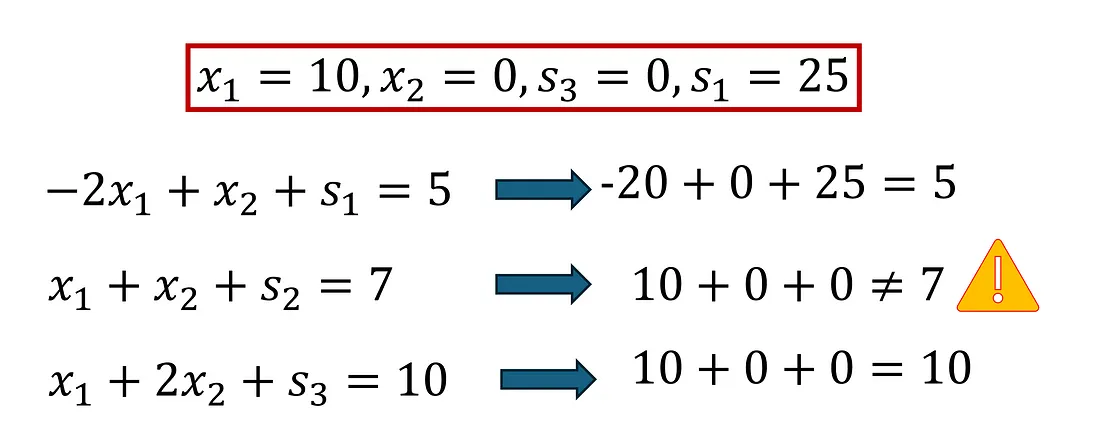
没有办法让系统在 x1 = 10 时正常工作
哇,我觉得我们已经做了很多工作!我们已经确定了要引入哪些变量以及哪些变量将离开单纯形表。现在我们必须更新表以反映这些变化。 在我们深入了解更新进入和离开变量的表的细节之前,让我们快速了解一些关键术语。属于离开变量的行称为枢轴行。属于进入变量的列称为枢轴列。枢轴行和枢轴列的交点称为枢轴元素。
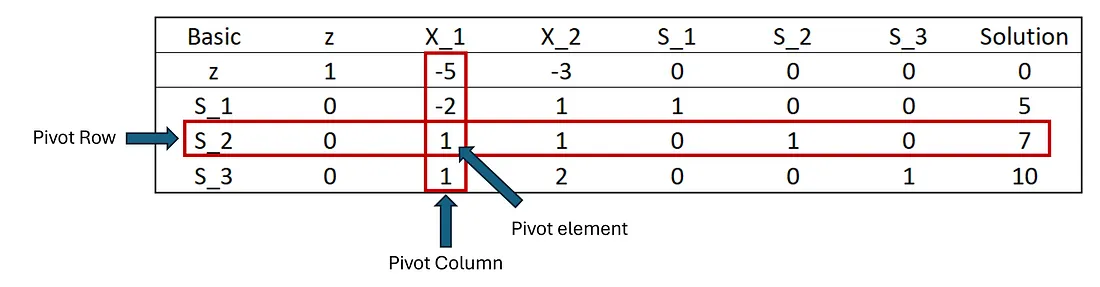
单纯形进入/离开变量项
好的,让我们更新此表以进行我们需要进行的更改!第一步是更新 S₂ 的行(它得到特殊处理,因为它是我们要用 X₁ 交换的行),然后我们需要更新所有其他行。 我们通过将整行除以枢轴元素来更新枢轴行。这将设置行,以便"解决方案"列的值等于 X₁ 值。不幸的是,对于这个例子,由于枢轴元素是 1,所以看起来什么都没有改变(我想我应该选一个更好的例子......)。但我们将更新"基本"列以显示 X₁ 现在在基本解决方案中,而 S₂ 不在。
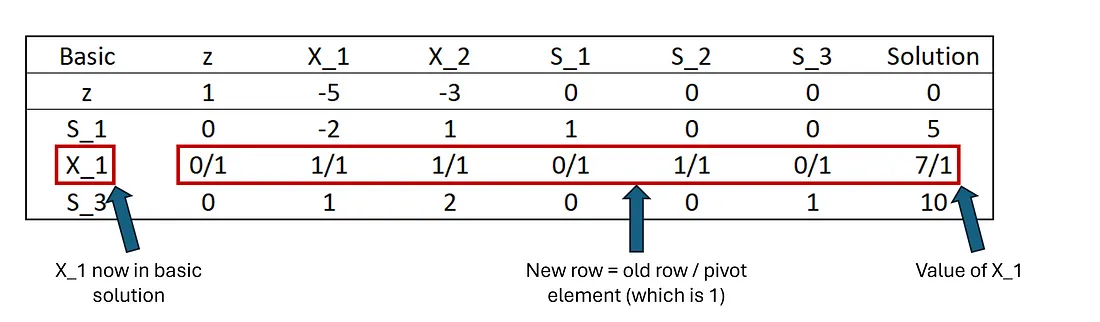
添加图片注释,不超过 140 字(可选)
所有其他行都通过此功能进行修改:
新行 = (当前行)---(其枢轴列系数)X(新枢轴列)
此函数更新解决方案列,以便基本变量的值构成一组连贯的线性方程。现在让我们来看一下。我们将从松弛变量 S₁ 的行开始。
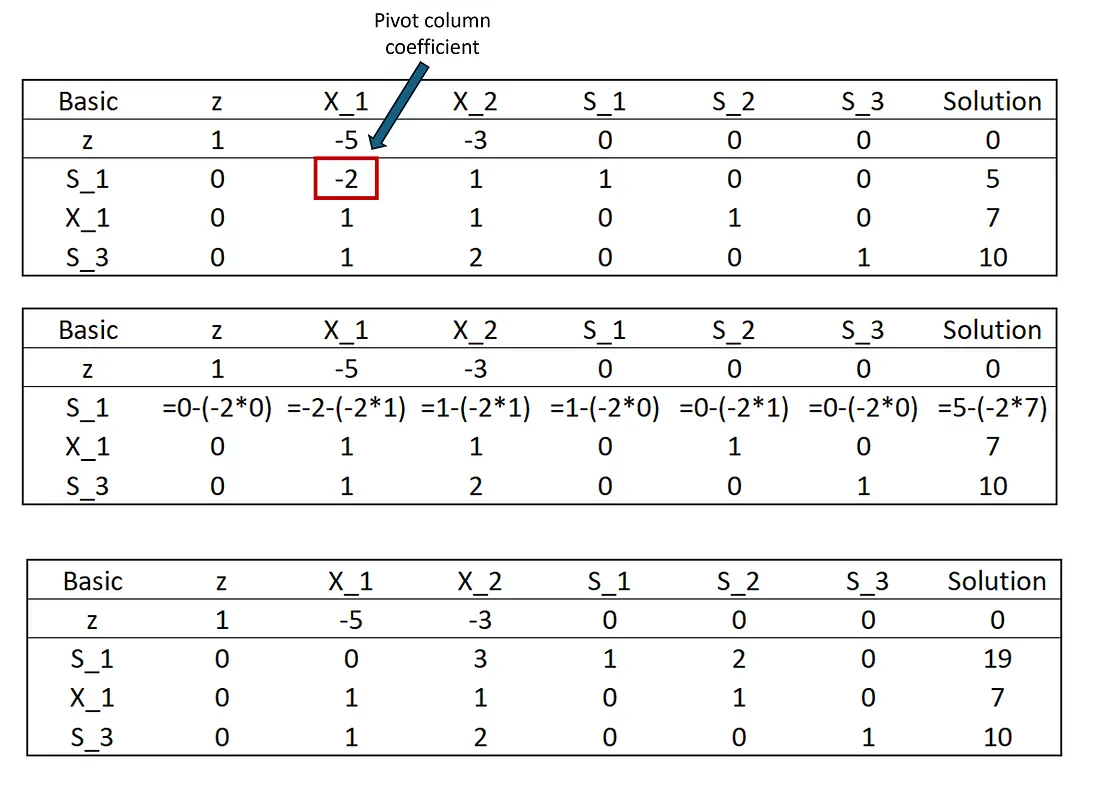
修改 S1,因为 X1 被引入到基本解决方案中
S₁ 行的数学运算现在"加起来了"。请记住,X₁ 现在等于 7。对应于第一行的约束是 -2X₁ + X₂ + S₁ = 5。经过第一步后,这等于 -14 + 0 + S₁ = 5。根据这个公式,S₁ 必须等于 19,这就是我们现在得到的"解决方案"列。我们将对其他两行执行相同的步骤。生成的表格是单纯形算法第一次迭代的输出。

第一次迭代后更新的单纯形图
现在我们已经完成了第一次迭代,我们开始新的迭代并遵循与第一次迭代完全相同的步骤。请记住,第一步是找到 z 行上的最小负数。有趣的是......所有数字都是正数。当 z 行中的所有数字均为 0 或正数时,您当前处于最优点 - 这是单纯形法的停止标准。对于此示例,我们的最优解是 X₁ = 7 和 X₂ = 0,目标函数值为 35。松弛变量仅用于代数目的,在找到最优解后将被丢弃。 为了便于说明,我们假设 z 行中有一个负值。如下所示:
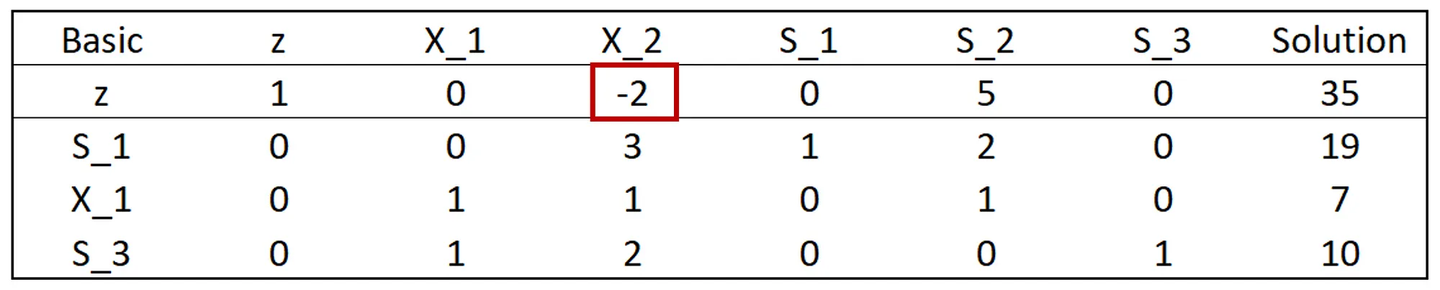
假设 z 行出现负值
如果是这种情况,我们将选择 X₂ 作为进入变量,然后继续 (1) 选择离开变量,(2) 重新计算离开变量的行并将其替换为 X₂,(3) 重新计算所有其他行,(4) 最后在 z 行中查找负值以查看我们是否找到了最优解,或者我们是否需要进入下一次迭代。 结论 我们在本文中深入探讨了单纯形法的细节。我认为了解细节很重要,但不要只见树木不见森林也很重要。特别是因为在实践中你永远不需要手动解决线性规划问题。 以下是本文的一些关键要点:
-
单纯形法是一种使用代数解决线性规划问题的算法
-
在使用单纯形法之前,需要将目标和约束公式重写为具有松弛变量的等式
-
单纯形法通过贪婪搜索来优化对目标函数贡献最大的变量,然后将该变量设置为尽可能高
-
单纯形法在无法找到任何可以改善目标函数的变量后就会停止------这使得单纯形法可以提前退出问题并获得最优解------而不必探索所有的角点
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)