文章目录
redis 的特性
redis 的一些特性(优点)成就了它
在内存中存储数据
In-memory data structures
MySQL 主要是通过"表"的方式来存储组织数据的"关系型数据 "
Redis 主要是通过"键值对"的方式来存储数据的"非关系型数据库"
key都是Stringvalue则可以是这些数据结构(string、hashes、lists、sets、sorted sets、streams,and more)
可编程的
Programmability
针对Redis的操作,可以直接通过简单的交互式命令进行操作,也可以通过一些脚本的方式,批量执行一些操作(可以带有一些逻辑)- 主要是使用
Lua语言
扩展能力
Extensibility
可以在Redis原有的功能基础上,再进行扩展。Redis提供了一组API,可以通过C、C++、Rust这几个语言编写Redis扩展(本质上就是第一个动态链接库)Windows上的.dll(动态链接库),里面包含很多的函数和代码,去给exe调用LInux上的动态库是.so,虽然和dll格式不同,但本质是一样的
这个特性可以让我们自己去扩展 Redis 的功能。比如,Redis 自身已经提供了很多的数据结构和命名,通过扩展,让 Redis 支持更多的数据结构以及支持更多的命令
持久化
Persistence
Redis是把数据存储在内存上的,为了能更快速地访问。但内存上的数据是"易失的"(当进程退出/系统重启,数据就会丢失)
Redis 会把数据存储在硬盘上,内存为主,硬盘为辅(硬盘相当于对内存的数据备份了一下)。如果 Redis 重启了,就会在重启的时候加载硬盘中的备份数据,使 Redis 的内存回复到启动前的状态
集群
Clustering
Redis作为一个分布式系统的中间件,能够支持集群是很关键的
一个 Redis 能存储的数据是有限的(内存空间有限)。如果要存储更多的数据,就可以引入多个主机,部署多个 Redis 节点,每个 Redis 存储数据的一部分
高可用
High availability
核心就是"冗余/备份 "
Redis 自身也使支持"主从"结构,从节点就相当于主节点的备份,当主节点挂了,从节点就能顶上去,代替主节点。这样就能保证系统可用性是很高的。当主节点挂了用户也感知不到,因为在这挂的一瞬间,从节点就顶上去了
快
天下武功,唯快不破!但为什么 Redis 快?
-
Redis数据在内存中,就比访问硬盘的数据库速度要快很多 -
Redis核心功能都是比较简单的逻辑,功能都是比较简单的操作内存的数据结构 -
从网络角度上,
Redis使用了 IO多路复用 的方式(epoll)
IO多路复用 就是使用一个线程,管理多个Socket。这样就可以在系统资源开销比较小的情况下,可以比较高效的处理比较高的并发量 -
Redis使用的是单线程模型(虽然更高版本的Redis引入了多线程)这样的单线程模型,减少了不必要的线程之间的竞争开销
多线程提高效率的前提是:这是一个
CPU密集型的任务,使用多个线程可以充分的利用多核资源。但是对于 Redis 来说,它的主要核心任务主要就是操作内存的数据结构,不会吃很多 CPU
redis 的应用场景
实时数据存储
Real-time data store
把Redis当做了数据库,按照键值对存储数据。(低延迟、高吞吐情况)存的是全量数据,这里的数据不能随便丢
大多数情况下,考虑到数据存储,优先考虑的是"大 ",但是仍然有一些场景,考虑的是"快"
缓存
Caching
使用MySQL来存储数据,大、慢。使用二八原则,把热点数据拎出来,存储在redis中,把其他数据还是放在MySQL中
redis里面存的是部分数据,全量数据都是以MySQL为主的,哪怕redis里面的数据没有了,还可以从MySQL中再加载回来
session storage
cookie实现用户身份信息的保存,需要session配合session在服务器这里真正的存储了用户数据cookie只是在浏览器里存储了一个用户的身份标识(sessionId)
之前session是存储在应用服务器上的,但现在变成了分布式系统,引入了负载均衡
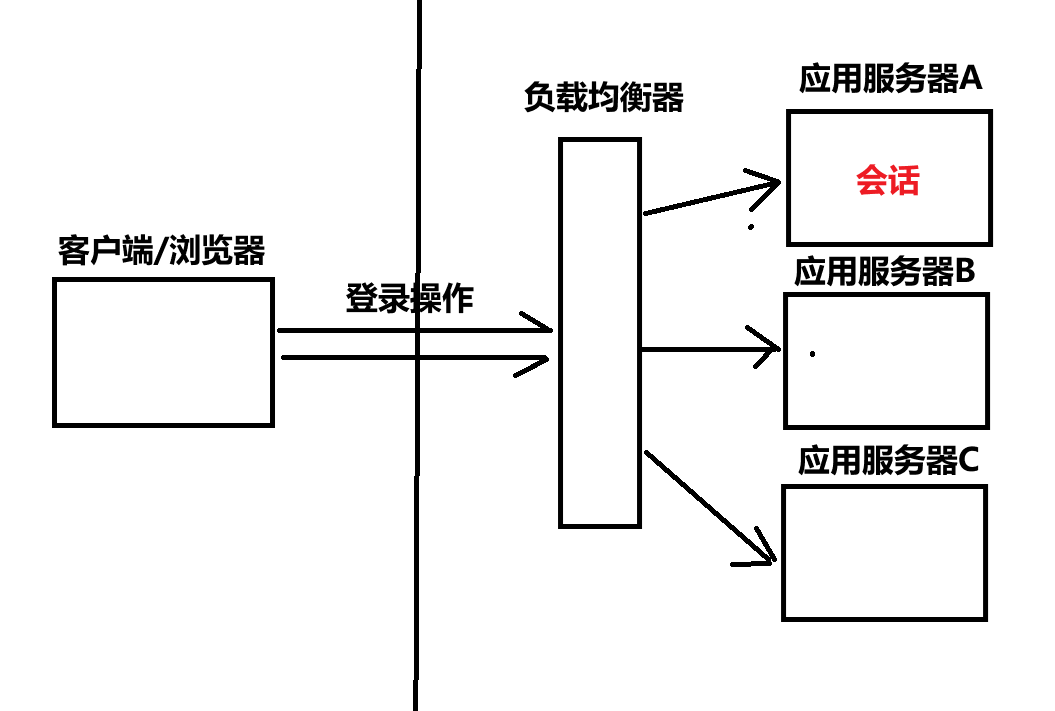
第一次客户端发出请求,负载均衡器将请求传到应用服务器 A,进行登录操作。登录成功之后,应用服务器就会生成当前用户的会话
但下次这个用户再次访问的时候,负载均衡器就可能将请求传到应用服务器 B,而这个应用服务器又没有这个用户上次进行访问产生的相关会话,难倒要再登录一次吗?
如何解决上述问题?
-
想办法让负载均衡器,把同一个用户的请求始终打到同一个机器上(不能轮询了,要通过 userId 之类的方式来分配机器)
-
把会话数据单独拎出来,放到一组独立的机器上存储
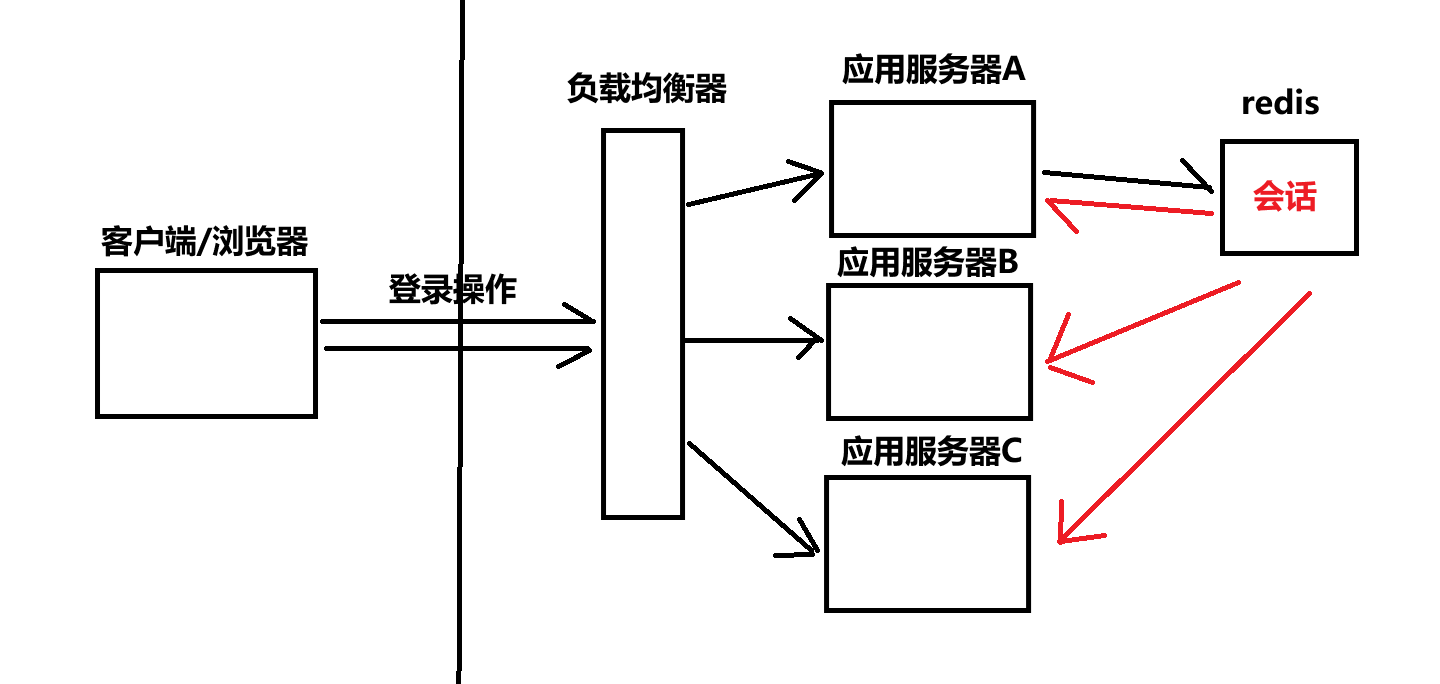
- 可以让应用服务器存到
redis中,之后每一个应用服务器在读取会话或者写入会话的时候,都去访问这个redis - 之后不管用户的请求打到那个应用服务器上,始终我们都是从
redis中拿到会话,这样就能保证无论访问到哪台应用服务器上,会话数据都能被完整的拿到。 - 万一应用程序重启了,会话也不会丢失
消息队列
Streaming & messaging
此处说到的消息队列,是一个消息队列服务器 。它是一个单独的服务器,起到消息队列的功能。基于这个服务器,我们就能实现一个网络版本 的"生产者-消费者模型 "
对分布式系统来说,服务器和服务器之间,有时候也需要使用到生产者消费者模型,因为有优势:
- 解耦合
- 削峰填谷
业界也有很多知名的消息队列,RabbitMQ、Kafka、RocketMQ... redis 也是提供了消息队列的功能的,但一般不怎么使用。如果当前场景中,对于消息队列的功能依赖的不是很多,并且又不想引入额外的依赖,redis 可以作为一个选择