文章目录
- [1. 引言:为什么选择 Druid 作为数据库连接池?](#1. 引言:为什么选择 Druid 作为数据库连接池?)
- [2. Spring Boot 中集成 Druid 的基本步骤](#2. Spring Boot 中集成 Druid 的基本步骤)
-
-
- [2.1 方式一:使用官方 Starter(推荐)](#2.1 方式一:使用官方 Starter(推荐))
- [2.2 方式二:自定义配置类(传统方式)](#2.2 方式二:自定义配置类(传统方式))
-
- [3. 连接池核心参数解析:从初始化到销毁](#3. 连接池核心参数解析:从初始化到销毁)
-
- [3.1 连接池大小配置](#3.1 连接池大小配置)
-
- [initial-size: 5](#initial-size: 5)
- [min-idle: 5](#min-idle: 5)
- [maxActive: 50](#maxActive: 50)
- [maxWait: 60000](#maxWait: 60000)
- [3.2 连接有效性检测](#3.2 连接有效性检测)
-
- [timeBetweenEvictionRunsMillis: 60000](#timeBetweenEvictionRunsMillis: 60000)
- [minEvictableIdleTimeMillis: 300000](#minEvictableIdleTimeMillis: 300000)
- [validationQuery: SELECT 1](#validationQuery: SELECT 1)
- [validationQueryTimeout: 5](#validationQueryTimeout: 5)
- [3.3 检测策略配置](#3.3 检测策略配置)
-
- [testWhileIdle: true](#testWhileIdle: true)
- [testOnBorrow: false](#testOnBorrow: false)
- [testOnReturn: false](#testOnReturn: false)
- [3.4 连接池参数配置建议](#3.4 连接池参数配置建议)
- [4. 监控配置揭秘:StatViewServlet 与 WebStatFilter](#4. 监控配置揭秘:StatViewServlet 与 WebStatFilter)
- [5. 过滤器链:stat、wall、slf4j 的作用与原理](#5. 过滤器链:stat、wall、slf4j 的作用与原理)
-
- [5.1 StatFilter:性能监控的基石](#5.1 StatFilter:性能监控的基石)
- [5.2 WallFilter:SQL 防火墙](#5.2 WallFilter:SQL 防火墙)
- [5.3 Slf4jLogFilter:可定制的日志输出](#5.3 Slf4jLogFilter:可定制的日志输出)
- [5.4 过滤器链的工作流程与扩展](#5.4 过滤器链的工作流程与扩展)
- [6. 高级特性:PSCache 与连接属性配置](#6. 高级特性:PSCache 与连接属性配置)
-
- [6.1 PSCache:预编译语句缓存](#6.1 PSCache:预编译语句缓存)
- [7. 实战中的性能调优与常见陷阱](#7. 实战中的性能调优与常见陷阱)
1. 引言:为什么选择 Druid 作为数据库连接池?
Druid 作为阿里巴巴开源的数据库连接池,在现代应用开发中备受青睐,尤其在大规模生产环境中展现出显著优势。它不仅提供了高效的数据库连接管理,还内置了强大的监控和统计功能,能够帮助开发者深入理解数据库访问性能。
下面这个表格清晰地展示了 Druid 与其它常见数据库连接池的核心特性对比,您能直观地看到其优势所在:
| 特性 | Druid | HikariCP | DBCP | C3P0 |
|---|---|---|---|---|
| 性能 | 高 | 非常高 | 中等 | 低 |
| 监控功能 | 极其强大 | 基础 | 较弱 | 弱 |
| 可扩展性 | Filter-Chain模式,易于扩展 | 较弱 | 中等 | 中等 |
| SQL防注入 | 内置WallFilter支持 | 不支持 | 不支持 | 不支持 |
| 生产环境验证 | 阿里巴巴大规模应用 | 广泛使用 | 广泛使用 | 广泛使用 |
核心优势解读
Druid 的优势体现在多个方面,使其在众多连接池中脱颖而出:
-
全面的监控能力 :Druid 号称"为监控而生"。它的监控功能远超其他连接池,能够提供详尽的统计信息,例如 SQL执行的耗时区间分布 (帮助你清晰了解慢SQL的分布情况)、连接池的详细状态 (如活跃连接数、等待线程数等)以及 PSCache命中率 等关键指标。这为性能调优和故障排查提供了坚实的数据基础。
-
卓越的性能与可扩展性 :Druid 在性能上表现优异,同时采用了 Filter-Chain 模式的插件体系 ,允许你像添加过滤器一样自定义功能,轻松实现性能监控、SQL审计、加密等需求。其内置的 ExceptionSorter 机制能快速识别并移除不可用的数据库连接,提升了系统的稳定性。
-
企业级安全特性 :Druid 内置了 SQL防火墙(WallFilter),能够有效防御 SQL 注入攻击,这是很多其他连接池所不具备的重要安全特性。同时,它还支持对配置文件中的数据库密码进行加密,进一步增强了安全性。
-
历经考验的稳定性:Druid 在阿里巴巴内部经历了大规模苛刻生产环境的长期考验,其稳定性和可靠性得到了充分验证。
2. Spring Boot 中集成 Druid 的基本步骤
在 Spring Boot 项目中集成 Druid 连接池,主要有两种主流方式:一种是使用官方提供的 druid-spring-boot-starter,这是目前最推荐、最便捷的方式;另一种是通过自定义配置类的方式,这种方式更传统,提供了更细粒度的控制。下面的表格清晰地展示了这两种方式的核心步骤和主要区别。
| 特性 | 使用官方 Starter (推荐) | 自定义配置类 |
|---|---|---|
| 易用性 | 高,开箱即用 | 中,需要手动编写配置类 |
| 依赖管理 | 自动管理依赖和版本 | 需手动排除默认数据源(如 HikariCP) |
| 配置方式 | 主要在 application.yml 中完成 |
需结合 application.yml 和 Java 配置类 |
| 灵活性 | 满足大部分场景 | 高,可进行高度定制 |
| 监控集成 | 通过配置属性轻松开启 | 需在配置类中手动注册 Servlet 和 Filter |
2.1 方式一:使用官方 Starter(推荐)
这是当前最简单、最流行的集成方式,绝大多数项目都采用此法。
第1步:添加 Maven 依赖
在项目的 pom.xml 文件中添加 druid-spring-boot-starter 依赖。请注意,如果您的项目已经引入了 mybatis-spring-boot-starter 等包含默认数据源(HikariCP)的依赖,通常无需手动排除,因为 Druid Starter 的配置优先级更高。
xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.20</version> <!-- 请使用最新稳定版本 -->
</dependency>第2步:配置 application.yml
这是核心步骤。您的配置示例正是采用了这种方式,关键在于 spring.datasource.druid 这个配置前缀。
第3步:验证集成
创建一个简单的测试类,检查数据源是否已成功切换为 Druid。
java
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import javax.sql.DataSource;
@SpringBootTest
class ApplicationTests {
@Autowired
DataSource dataSource;
@Test
void contextLoads() {
System.out.println("当前数据源:" + dataSource.getClass().getName());
// 输出应类似于:com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceWrapper
}
}完成以上步骤后,启动应用并访问 http://你的服务器地址/druid,即可看到Druid强大的监控后台。
2.2 方式二:自定义配置类(传统方式)
这种方式在早期Spring Boot版本中较常见,现在多用于需要深度定制的情况。
第1步:添加基本依赖
xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId> <!-- 注意,这里不是starter -->
<version>1.2.20</version>
</dependency>第2步:创建Druid配置类
通过 @Configuration 注解的配置类,手动将Druid数据源及其监控组件注册为Spring容器的Bean。
java
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
// 将 application.yml 中 spring.datasource 前缀的配置绑定到DruidDataSource
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druidDataSource() {
return new DruidDataSource();
}
// 配置监控后台的Servlet
@Bean
public ServletRegistrationBean<StatViewServlet> statViewServlet() {
ServletRegistrationBean<StatViewServlet> bean =
new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
Map<String, String> initParams = new HashMap<>();
initParams.put("loginUsername", "admin"); // 后台管理用户名
initParams.put("loginPassword", "123456"); // 后台管理密码
initParams.put("allow", ""); // 允许所有访问(IP白名单)
// initParams.put("deny", "192.168.1.100"); // IP黑名单 (拒绝访问)
bean.setInitParameters(initParams);
return bean;
}
// 配置Web监控的Filter
@Bean
public FilterRegistrationBean<WebStatFilter> webStatFilter() {
FilterRegistrationBean<WebStatFilter> bean = new FilterRegistrationBean<>();
bean.setFilter(new WebStatFilter());
Map<String, String> initParams = new HashMap<>();
// 忽略静态资源和监控页面本身的请求
initParams.put("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*")); // 拦截所有请求
return bean;
}
}3. 连接池核心参数解析:从初始化到销毁
Druid 连接池的核心参数配置直接决定了数据库连接的性能、稳定性和资源利用率。
3.1 连接池大小配置
initial-size: 5
初始连接数,表示连接池启动时立即创建的连接数量。这就像停车点刚建成时,先投放5辆单车,确保有用户来时能立即使用,避免"冷启动"等待。
min-idle: 5
最小空闲连接数,连接池中始终保持的最小空闲连接数量。即使没有用户借车,停车点也要保留至少5辆单车,这样新用户来了就能直接骑走,无需等待调度。
maxActive: 50
最大活跃连接数,连接池能同时支持的最大连接数量。停车点最多只能容纳50辆单车,如果超过这个数量,新用户就需要排队等待。
maxWait: 60000
获取连接的最大等待时间(单位:毫秒)。当所有单车都被借走时,用户最多等待60秒,如果超时还没等到,就放弃借车(抛出异常)。
3.2 连接有效性检测
timeBetweenEvictionRunsMillis: 60000
检测间隔时间,每隔60秒检查一次连接池中的空闲连接。就像停车点管理员每隔1小时巡视一次,检查哪些单车长时间没人用,可能需要维修或回收。
minEvictableIdleTimeMillis: 300000
连接最小生存时间,空闲连接超过5分钟(300秒)后,如果连接池中的连接数超过min-idle,这些"超时"连接会被回收。这相当于停车点规定:如果某辆单车连续5分钟没人使用,且停车点单车总数超过5辆,就把它运回仓库。
validationQuery: SELECT 1
连接有效性检测SQL,用于检查连接是否可用。就像管理员每次借车前,会检查单车刹车是否正常(执行SELECT 1),确保安全。
validationQueryTimeout: 5
检测超时时间,执行validationQuery最多等待5秒,超时则认为连接不可用。
3.3 检测策略配置
testWhileIdle: true
空闲时检测,建议开启。当连接空闲时间超过timeBetweenEvictionRunsMillis时,自动执行validationQuery检测。这就像管理员在巡视时,会检查长时间没人用的单车是否还能正常使用。
最佳实践建议:将testWhileIdle设置为true,testOnBorrow和testOnReturn设置为false,可以在不影响性能的前提下保证连接有效性。
testWhileIdle 只是 Druid 的"空闲时检测"开关,把它从 false 改成 true 后,连接池会周期性地把当前池里空闲 的连接拿出来执行一条探活 SQL(默认 SELECT 1)。如果探活失败就会把这条连接丢弃并新建,从而保证:
- 连接在真正被业务线程借出去之前,大概率已经被验证过,不会拿到"僵尸连接";
- 对 MySQL 来说,这条探活 SQL 也算一次通讯,会把
wait_timeout的空闲计时器清零,避免服务端把连接杀掉。
testOnBorrow: false
借出时检测,默认关闭。每次借出连接时都检测,会降低性能。就像每次借车前都要检查刹车,虽然安全但效率低。
testOnReturn: false
归还时检测,默认关闭。每次归还连接时检测,同样影响性能。就像每次还车都要检查单车是否损坏,没必要。
3.4 连接池参数配置建议
| 参数 | 推荐值 | 说明 |
|---|---|---|
| initial-size | 5-10 | 根据应用启动时的并发量调整 |
| min-idle | 5-10 | 保持一定数量的"热连接" |
| maxActive | 20-100 | 根据数据库性能和业务并发量调整 |
| maxWait | 30000-60000 | 避免长时间等待导致请求超时 |
| timeBetweenEvictionRunsMillis | 60000 | 每分钟检测一次 |
| minEvictableIdleTimeMillis | 300000 | 5分钟空闲后回收 |
4. 监控配置揭秘:StatViewServlet 与 WebStatFilter
Druid 最强大的特性之一就是其内置的监控功能,它通过两个核心组件实现:StatViewServlet 和 WebStatFilter。这两个组件就像连接池的"眼睛"和"耳朵",分别负责展示监控数据和收集统计信息。
4.1 StatViewServlet:监控页面的"展示窗口"
StatViewServlet 是 Druid 提供的监控后台,通过 Web 页面展示连接池的详细状态信息。它就像连接池的"仪表盘",让你可以实时查看各项指标。
核心配置参数
yaml
spring:
datasource:
druid:
stat-view-servlet:
enabled: true # 启用监控页面
url-pattern: /druid/* # 访问路径
login-username: admin # 登录用户名
login-password: 123456 # 登录密码
allow: # IP白名单,空表示允许所有
reset-enable: false # 是否允许重置统计数据监控页面功能详解
启动应用后,访问 http://localhost:8080/druid(根据实际端口调整),输入配置的用户名和密码,即可看到以下核心功能:
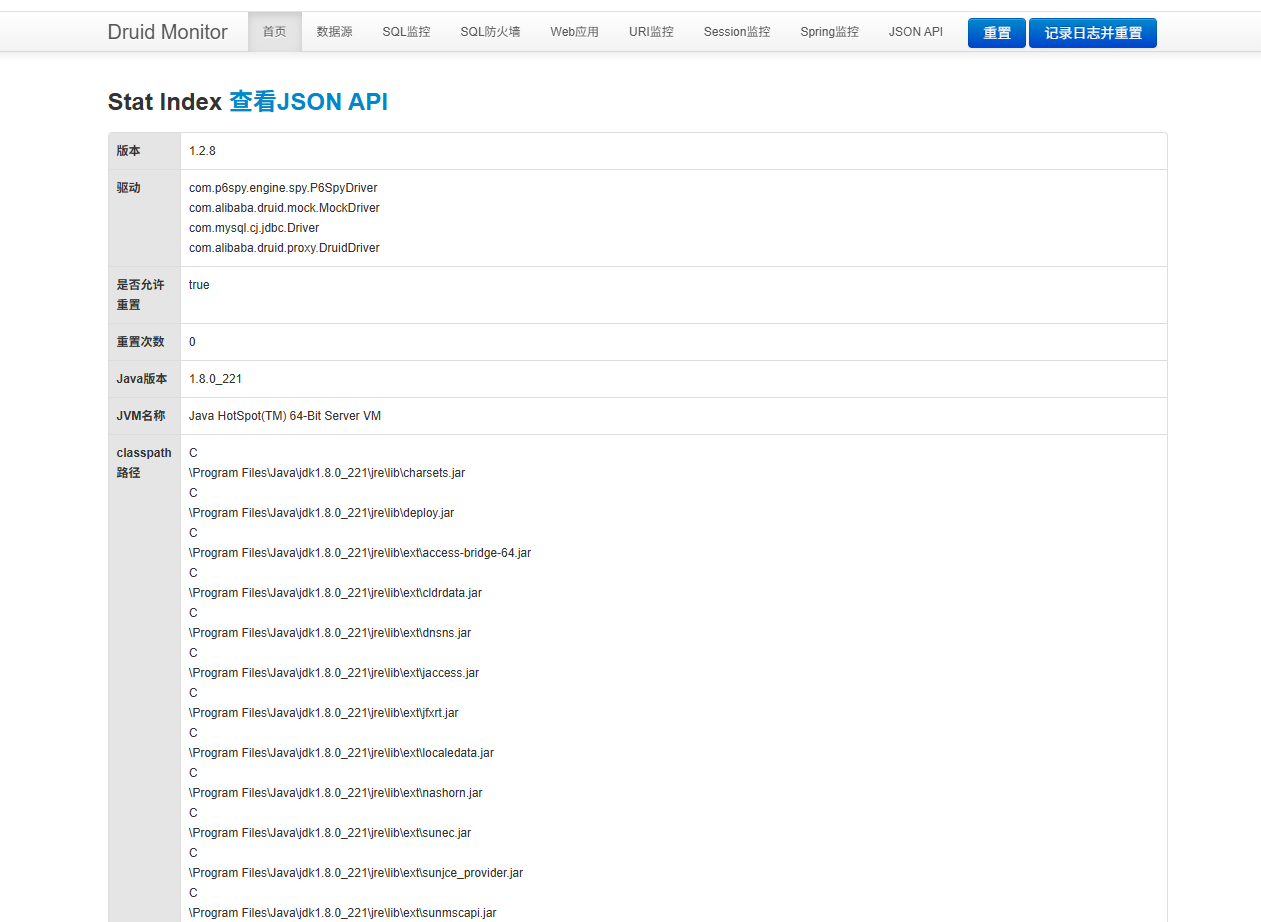
1. 数据源页面
- 活跃连接数:当前正在使用的连接数量
- 池中连接数:连接池中总连接数
- 等待线程数:正在等待获取连接的线程数
- 最大活跃连接数 :历史最大活跃连接数
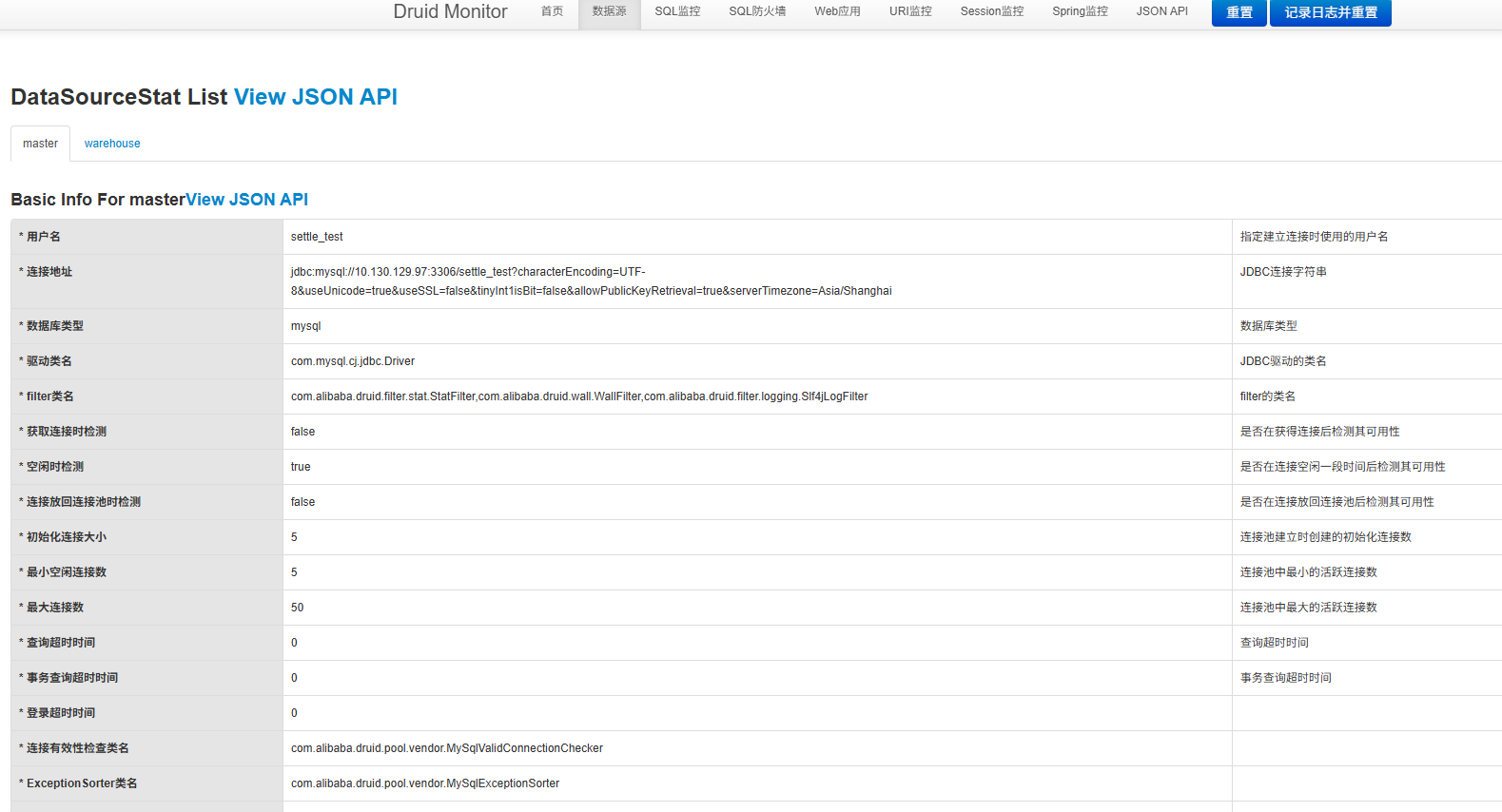
2. SQL监控页面
- 执行次数:每条SQL的执行次数
- 执行时间:总执行时间、最大执行时间、平均执行时间
- 慢SQL统计:执行时间超过阈值的SQL(默认5000ms)
- 执行时间分布:0-1ms、1-10ms、10-100ms、100-1000ms、1-10s、10s+ 的分布情况
3. Web应用页面
- URI访问统计:每个URI的访问次数、执行时间
- Session监控:活跃Session数量、创建时间
- JVM监控 :堆内存、非堆内存、GC次数
4.2 WebStatFilter:统计数据的"收集器"
WebStatFilter 负责收集 Web 应用的访问统计信息,包括 URI 访问次数、执行时间、Session 信息等。它就像连接池的"耳朵",监听所有 Web 请求。
核心配置参数
yaml
spring:
datasource:
druid:
web-stat-filter:
enabled: true
url-pattern: "/*" # 拦截所有请求
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" # 排除静态资源
session-stat-enable: true # 启用Session统计
session-stat-max-count: 1000 # 最大Session统计数量配置参数详解
exclusions:需要排除统计的请求,通常包括:
- 静态资源:
*.js,*.gif,*.jpg,*.png,*.css,*.ico - 监控页面本身:
/druid/* - 健康检查接口:
/actuator/health
session-stat-enable:是否启用 Session 统计,建议开启以监控用户会话状态。
session-stat-max-count:最大 Session 统计数量,避免内存溢出。
4.5 监控页面访问
启动应用后,访问 http://localhost:8080/druid(根据实际端口调整),输入配置的用户名和密码,即可看到完整的监控界面。
关键建议:
- 生产环境必须配置安全措施:设置强密码、限制IP访问、禁止重置数据
- 定期查看监控数据:重点关注慢SQL、连接池状态、内存使用情况
- 根据监控数据调优 :如果发现连接池频繁达到最大连接数,需要调整
max-active参数;如果发现大量慢SQL,需要优化SQL语句或添加索引
Druid 过滤器链是其架构设计的精髓所在,它通过责任链模式为数据库操作提供了强大的可扩展性。您配置中的 filters: stat,wall,slf4j 正是启用了三个核心过滤器,它们各自扮演着独特的角色。下面这个表格清晰地展示了这三者的分工。
| 过滤器 | 核心职责 | 好比... |
|---|---|---|
| StatFilter | 性能监控官:统计 SQL 执行次数、耗时、连接池状态等指标。 | 高速公路的测速摄像头和车流量统计系统,记录每辆车的速度、车型和通行时间。 |
| WallFilter | 安全守卫:基于 SQL 语义分析防御 SQL 注入攻击,强制执行安全策略。 | 高速公路的安检站和交通法规,检查车辆是否携带违禁品,是否遵守通行规则(如禁止货车通行)。 |
| Slf4jLogFilter | 审计记录员:将 SQL 执行相关的日志输出到 SLF4J 接口,便于集成日志框架。 | 收费站的通行记录仪,详细记录每一笔交易(SQL执行)的细节,用于对账和复查。 |
5. 过滤器链:stat、wall、slf4j 的作用与原理
5.1 StatFilter:性能监控的基石
StatFilter 是 Druid 监控功能的数据来源,它负责收集所有关键的性能指标。
工作原理
StatFilter 通过代理(Proxy)机制,在 JDBC 驱动的 Connection, Statement, ResultSet 等对象的关键方法(如 execute, close)执行前后插入拦截点。在这些拦截点中,它会记录方法调用的开始时间和结束时间,从而计算出执行耗时,并累加执行次数。
核心配置(通常在 application.yml 中)
您配置中的 connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 就与 StatFilter 密切相关。
yaml
spring:
datasource:
druid:
filter:
stat:
enabled: true # 启用StatFilter
log-slow-sql: true # 开启慢SQL记录
slow-sql-millis: 5000 # 定义慢SQL阈值,单位毫秒
merge-sql: true # 合并相似SQL(如SELECT * FROM user WHERE id = ?),便于统计这些统计数据最终会在 Druid 的监控页面(如 SQL监控 、数据源页面)上直观地展示出来。
5.2 WallFilter:SQL 防火墙
WallFilter 是 Druid 提供的企业级安全特性,它通过内置的 SQL 语法解析器对执行的 SQL 进行实时分析,而非简单的字符串匹配,从而有效防御 SQL 注入攻击。
防御策略
WallFilter 维护了一套详尽的安全策略(WallConfig),主要包括:
- 语法检查 :检测是否使用了永真条件(如
1=1)、注释等可疑语法。 - 对象检查 :是否引用了禁止访问的表(
tableCheck)或模式(schemaCheck)。 - 行为控制 :是否可以执行
DELETE、UPDATE不带WHERE子句等危险操作。您甚至可以配置一个只读数据源,禁止任何数据修改语句。
配置示例
yaml
spring:
datasource:
druid:
filter:
wall:
enabled: true
config:
delete-allow: false # 是否允许删除语句
drop-table-allow: false # 是否允许删表操作,生产环境应严格关闭
# 更多精细策略,如指定只读表
read-only-tables: config_table, audit_log当检测到违规 SQL 时,WallFilter 默认会抛出 SQLException 中止执行,从而保护数据库。你可以在监控页面的 SQL防火墙 标签页查看拦截信息。
5.3 Slf4jLogFilter:可定制的日志输出
Slf4jLogFilter 充当了数据库操作与应用程序日志系统(如 Logback、Log4j2)之间的桥梁。它将 SQL 执行信息输出到日志文件,方便开发调试和问题追踪。
高度可配置的日志内容
与 StatFilter 聚焦于聚合统计不同,Slf4jLogFilter 更关注单次执行的详细信息,并且可以按需开启或关闭特定日志。
yaml
spring:
datasource:
druid:
filter:
slf4j:
enabled: true
statement-executable-sql-log-enable: true # 关键配置:在日志中打印出可执行的(带参数的)完整SQL
# 以下选项提供了更细粒度的控制
statement-create-after-log-enabled: false # 记录Statement创建日志(通常不需要)
statement-close-after-log-enabled: false # 记录Statement关闭日志
result-set-open-after-log-enabled: false # 记录ResultSet打开日志启用 statement-executable-sql-log-enable 后,在你的应用日志中可能会看到这样的输出,这对于调试非常有帮助:
[Druid-ConnectionPool-Log-Thread] INFO c.a.d.filter.logging.Slf4jLogFilter -
Executable SQL: SELECT * FROM user WHERE name = '张三' AND age > 185.4 过滤器链的工作流程与扩展
链式调用
当应用程序通过 Druid 执行一条 SQL 时,请求会依次经过配置的过滤器链。例如,一条 SELECT 语句会先经过 WallFilter 的安全检查 ,然后由 StatFilter 记录耗时和次数 ,最后通过 Slf4jLogFilter 打印详细日志。这种设计使得每个过滤器职责单一,且易于扩展。
自定义过滤器
Druid 的过滤器链是开放的。你可以通过实现 com.alibaba.druid.filter.Filter 接口或继承 FilterAdapter 类,并重写相关方法(如 statementExecuteBefore, statementExecuteAfter)来创建自定义过滤器,实现诸如分库分表路由、数据加解密等高级功能。
6. 高级特性:PSCache 与连接属性配置
Druid 除了基础的连接池功能外,还提供了一些高级特性,这些特性能够显著提升数据库访问性能并提供更细致的监控能力。您配置中的 poolPreparedStatements 和 connectionProperties 正是这些高级特性的体现。
6.1 PSCache:预编译语句缓存
PSCache(PreparedStatement Cache)是 Druid 中的一个重要性能优化特性,它通过缓存预编译的 SQL 语句来提升数据库访问效率。
什么是 PreparedStatement?
在了解 PSCache 之前,先简单了解 PreparedStatement:
java
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
// 不使用 PreparedStatement
String sql1 = "SELECT * FROM users WHERE id = " + userId; // 有SQL注入风险
// 使用 PreparedStatement
String sql2 = "SELECT * FROM users WHERE id = ?";
PreparedStatement pstmt = connection.prepareStatement(sql2);
pstmt.setInt(1, userId);
ResultSet rs = pstmt.executeQuery();PSCache 的工作原理
没有 PSCache 的情况:
- 每次执行 SQL 时,都需要创建新的 PreparedStatement 对象
- 数据库每次都需要重新解析和编译 SQL
- 创建和销毁 PreparedStatement 对象带来额外开销
启用 PSCache 的情况:
- PreparedStatement 对象被缓存起来
- 下次执行相同 SQL 时,直接使用缓存的 PreparedStatement
- 只需设置参数即可执行,无需重新编译
核心配置参数
yaml
spring:
datasource:
druid:
# 启用PSCache
poolPreparedStatements: true
# 每个连接上PSCache的大小
maxPoolPreparedStatementPerConnectionSize: 100参数详解
poolPreparedStatements: true
启用 PSCache 功能。当设置为 true 时,Druid 会缓存每个连接上的 PreparedStatement 对象。
maxPoolPreparedStatementPerConnectionSize: 100
每个数据库连接最多缓存的 PreparedStatement 数量。这个值不宜设置过大,通常 20-100 是比较合理的范围。
PSCache 的优缺点
优点:
- 性能提升:避免重复编译 SQL,提高执行效率
- 资源复用:复用 PreparedStatement 对象,减少内存分配
- 减少数据库负载:数据库无需重复解析相同 SQL
缺点:
- 内存占用:每个缓存的 PreparedStatement 都会占用内存
- 连接隔离:缓存是连接级别的,不同连接之间不共享
- SQL 差异:只有完全相同的 SQL 才会被缓存
7. 实战中的性能调优与常见陷阱
在掌握了 Druid 的各项配置后,如何将这些知识应用到实际项目中,避免常见的性能问题和配置陷阱,是每个开发者都需要面对的挑战。本章将结合实战经验,为您提供一套完整的性能调优方案和常见问题的解决方案。
连接池大小的配置直接影响系统性能,过大或过小都会带来问题。黄金法则:连接池大小 = (核心数 * 2) + 有效磁盘数。
调优步骤:
-
初始配置:基于业务场景设置初始值
yamlinitial-size: 10 min-idle: 10 max-active: 50 -
监控观察:通过 Druid 监控页面观察以下指标:
- 活跃连接数是否经常达到 max-active
- 等待线程数是否频繁出现
- 连接获取时间是否过长
-
动态调整:
- 如果活跃连接数经常达到 max-active,且等待线程数较多,适当增大 max-active
- 如果活跃连接数远小于 max-active,且 min-idle 连接长时间空闲,适当减小配置
生产环境建议:
- 对于 OLTP 系统:max-active 建议 20-100
- 对于 OLAP 系统:max-active 建议 50-200
- 对于批处理任务:根据并发度调整
完整示例
yml
datasource:
druid:
stat-view-servlet:
enabled: true
loginUsername: admin
loginPassword: admin
url-pattern: /druid/*
allow:
web-stat-filter:
enabled: true
dynamic:
druid: # 全局druid参数,绝大部分值和默认保持一致。(现已支持的参数如下,不清楚含义不要乱设置)
# 连接池的配置信息
# 初始化大小,最小,最大
initial-size: 5
min-idle: 5
maxActive: 50
# #获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
# 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用
validationQuery: SELECT 1
validationQueryTimeout: 5
#建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效
testWhileIdle: true
#申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnBorrow: false
#归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
#要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100
maxPoolPreparedStatementPerConnectionSize: 100
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,slf4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000
datasource:
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/database?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: admin
password: admin