摘 要 **:**本文整理自饿了么大数据架构师、Apache Flink Contributor 王沛斌老师在8月3日 Streaming Lakehouse Meetup Online(Paimon x StarRocks,共话实时湖仓架构)上的分享。主要分为以下三个内容:
-
饿了么实时数仓演进之路
-
实时湖仓方案选型与探
-
实时湖仓规划及展望
Tips:点击「阅读原文」跳转阿里云实时计算 Flink~
01
饿了么实时数仓演进之路
1.1 饿了么典型实时应用场景
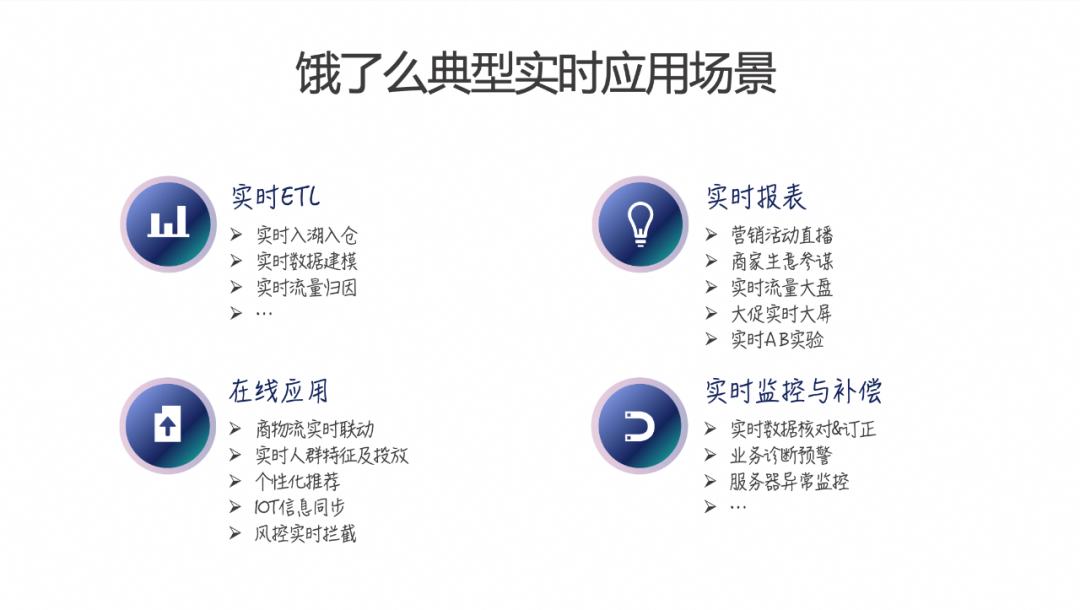
以上是饿了么在实时应用中的一些典型场景,和许多公司有相似之处。具体分为以下几个部分:
(1)实时 ETL:包括实时数据入湖入仓、实时数据建模、实时流量归因等。
(2)实时报表应用:包括营销活动直播、商家生意参谋、实时流量大盘、大促实时大屏、实时AB实验等。
(3)实时与在线应用的联动:包括商物流实时联动、实时人群特征及投放、个性化推荐、IOT信息同步、风控实时拦截等。
(4)实时监控与补偿:包括实时数据核对与订正、业务诊断预警、服务器异常监控等。
1.2 饿了么数据结构大图
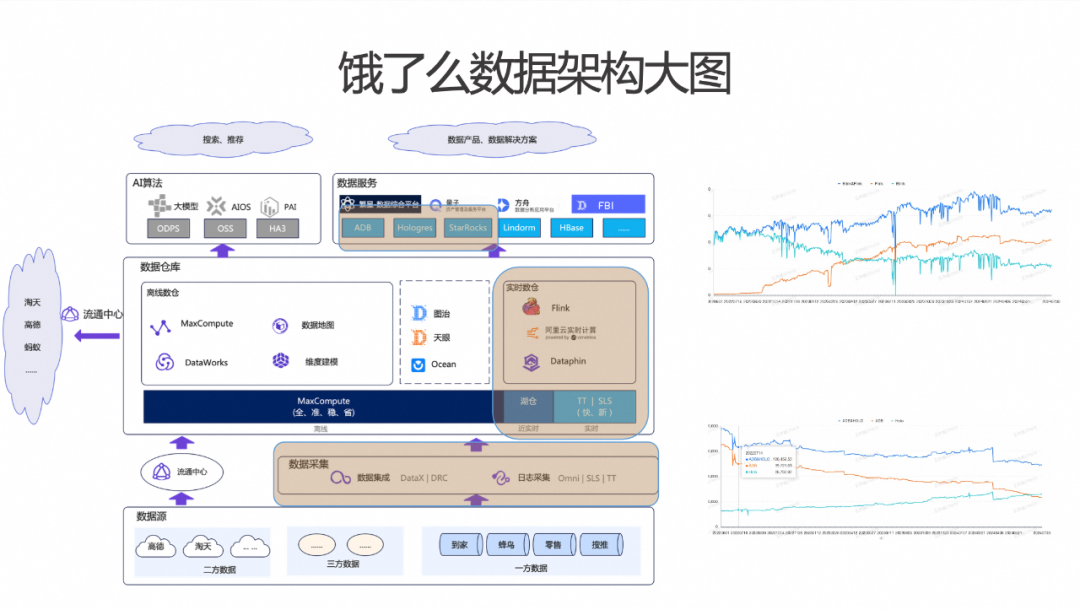
饿了么整体数据架构大图主要由三个层面组成,分别为数据采集层,数据加工层,数据服务层。相关的数据组件依托阿里云组件。整体数据采集使用 DataX 和 DRC 链路来进行数据库 Binlog 的采集。日志采集主要使用内部的Omni 平台来收集用户行为数据,而应用层的日志通过SLS和TT来进行相应的日志接入。
数据仓库这一层是一个重点。一个是存储方面可以分为两块:一块是近实时的湖仓,采用 Paimon On OSS方案来进行存储;而对于实时性要求更高的数据,使用的是 TT 和 SLS。在数仓计算层,使用的是 Dataphin、VVP 和Flink 三件套。在数据服务层,主要的数据存储使用 ADB 和 Hologres,最近引入了 StarRocks 来结合湖仓进行落地。在这个存储基础上,通过内部的数据服务应用(包括繁星、方舟、FBI、量子等组件)来提供相应的数据服务。通过以上数据服务,构建了整体的数据产品和数据解决方案。
最核心的两个点是计算和存储。上图右边展示了整体计算变化的情况。右边第一张图显示了我们内部Blink和Flink的用量曲线。可以观察到,早期更多使用的是 Blink,随着 Flink 的进一步拓展,到 2023 年左右,开始大规模切换到 Flink。计划在今年将所有 Blink下线,全部统一切换到 Flink。第二张图显示的是存储层的情况。存储层早期更多使用的是 ADB,现阶段更多使用 Hologres 来支持。未来 Hologres 的用量也会逐步扩大,并引入类似StarRocks这样的 OLAP 引擎,以提升团队整体研发效率。
1.3 实时数仓1.0
基于上述的两个背景,接下来介绍一下我们内部当前实时数仓建设的情况。
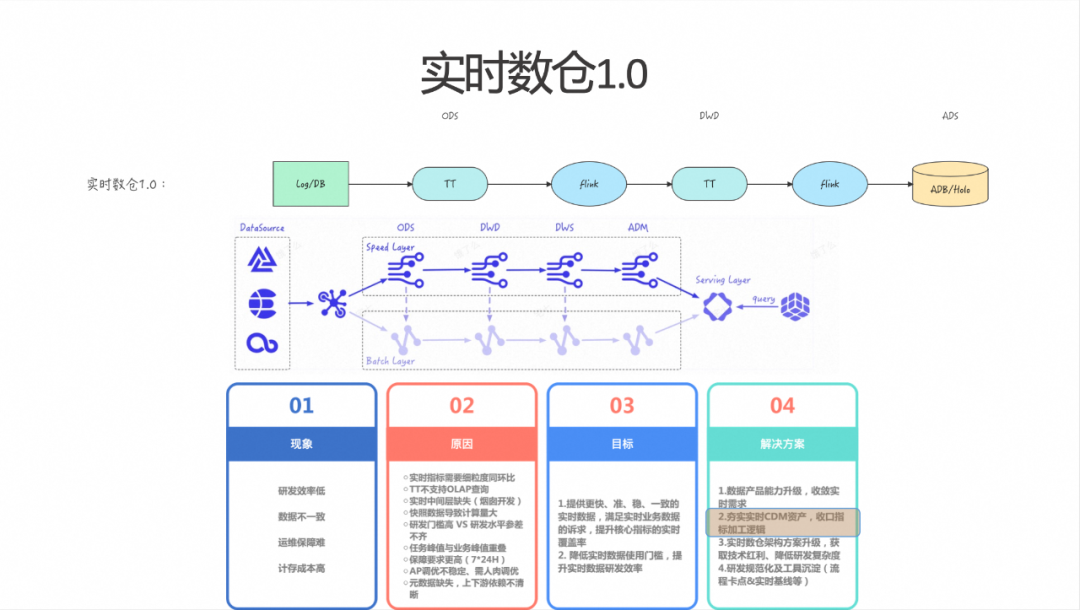
实时数仓的 1.0 版本中,这是大多数公司早期版本的典型样子。我们通过日志和数据库的 Binlog 进行数据采集,这些数据最终进入 ODS 层。在 1.0 版本的早期阶段,我们投入了大量工作来建设 DWD 层。在 DWD 层,我们对一些共性的维度和逻辑进行了扩展,并屏蔽了多余的场景,建设了完善的 DWD 层群以供下游消费使用。
对于不同的应用场景,我们开发了相对独立的 ADS 层,这一层并未进行公共层的建设。而对于核心业务场景,我们采用了 Lambda 架构将历史数据通过 T+1 的方式导入到 OLAP 引擎中,以保证数据的稳定性。在此过程中会出现几个问题:首先是研发效率较低的问题,会产生较多的重复开发工作。其次,随着业务的变化,这些逻辑往往无法及时同步更新,导致数据一致性缺乏保障。这不仅增加了整体的运维成本,也增加了计存成本。
基于上述情况,我们期望达成以下两个目标:首先是确保数据能够更快、更准、更稳、更一致;其次是提升整体的开发效率和运维效率。具体的解决方案总结为四个要点:
(1)数据产品能力升级,收敛实时需求。
(2)夯实实时的 CDM 资产,收口指标加工逻辑。
(3)实时数仓架构方案升级,获取技术红利,降低研发复杂度。
(4)研发规范化及工具沉淀(流程卡点&实时基线等)。
1.4 实时数仓2.0
上述第二点对应的是实时数仓 2.0 的具体方案。具体方案是建设核心的 CDM 层,将常见的共性维度和指标加工成 DWS 资产。这个方案是在去年年初提出的,整体方式是借助 Dataphin 来构建一个流批一体化的系统。
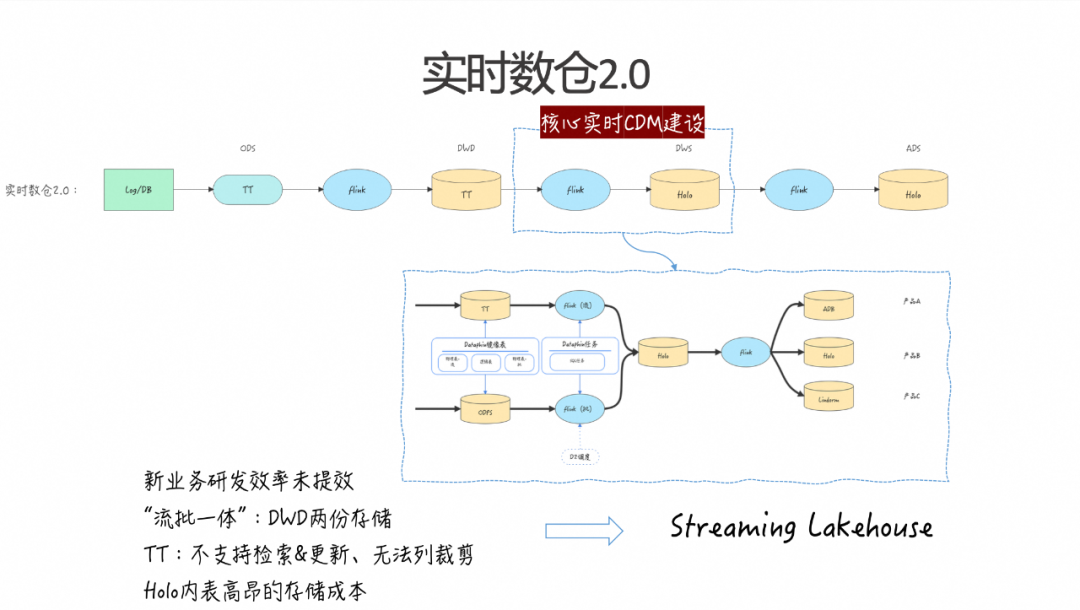
实时的 DWD 和离线的 DWD 通过 Dataphin 的逻辑表进行映射,在 Dataphin 上开发具体的 SQL 任务后, Dataphin 会将其翻译成 Flink 的流任务和批任务。在此基础上,结合 D2 的 Dataworks,根据每一个调度将每天的 T+1 任务触发,最终将数据回写到 Hologres 中。通过 Hologres 的 Binlog,驱动下游的具体消费。这样,下游的 ADS 层只需进行现有指标的简单行业转化或格式转化,将数据写入各自的存储,以满足不同查询场景的使用和需求。
完成这条链路后,整体的核心资产消费链路和研发效率得到了提升,数据一致性也得到了保障。然而,仍然存在一些问题。例如,对于一些新兴业务,这条链路并不适用,它主要支持存量的重要业务。另外,虽然这条链路旨在实现流批一体化,但实际上并未完全实现这一目标。因为在 DWD 层,数据实际上有两份存储,一份在 TT,一份在 ODPS。
此外,实时中间层更多使用的是 TT,但 TT 不支持检索和更新。在研发或数据订正的过程中,这会带来较高的成本。同时,TT 也不支持列裁剪。以流量中间层为例,每次消费都会产生单列巨额的费用。再者,Hologres 的存储成本非常高。因此,无论是从降低成本还是提升效率的角度来看,我们都希望引入更好的数据架构。因此,我们找到了当前比较热门的解决方案------Streaming Lakehouse。
02
实时湖仓方案选型与探索
那么我们想引入 Streaming Lakehouse 要如何实施呢?首先要做的就是具体的选型和探索落地的实践。
2.1 造型与测评方案
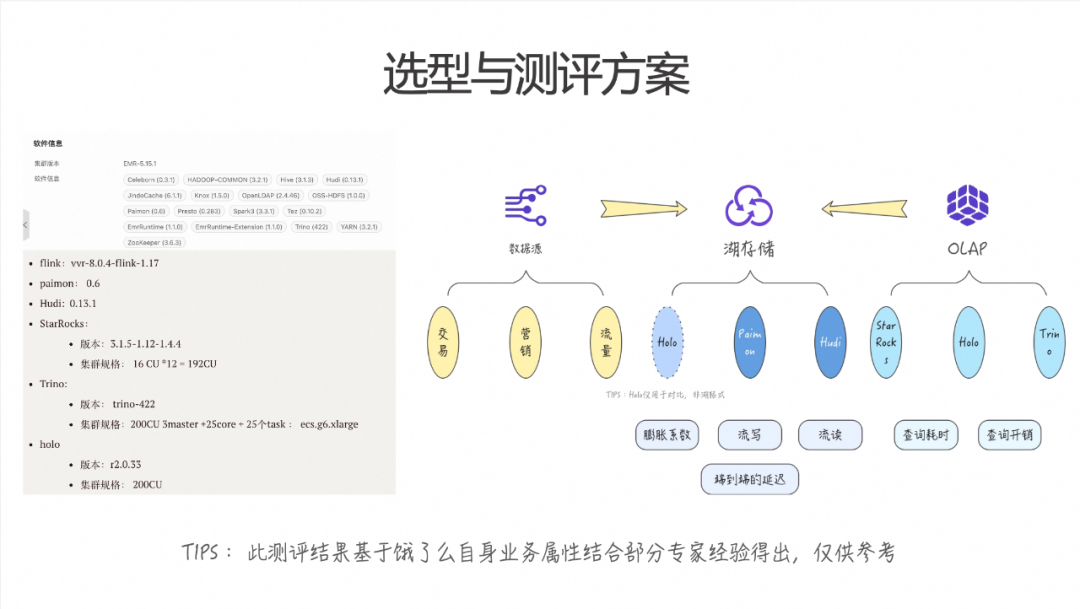
在整个选型过程中,使用了饿了么最核心的交易、营销和流量三个域的明细数据作为测试数据,并将数据写入对应的湖存储格式中。我们当时评测选择了 Paimon + Hudi 这两种湖格式。为了方便整体验证,还将 Hologres 的内表拿过来进行对比。
在 OLAP 引擎方面,主要引入了 StarRocks、Hologres 和 Trino 这三个引擎进行对比。在存储层,我们主要关注数据写入后的膨胀系数、流读和流写的性能,以及端到端的写入延迟。在 OLAP 部分,我们重点关注查询的耗时和单次查询的开销。
上图左边展示了我们在整个评测中所使用的版本。整体使用的集群规模大约为 200CU。由于规格的原因,StarRocks 的集群总共是 16CU 乘以 12 的配置。在这些配置中,大家比较关注的 StarRocks 和 Trino 我们是直接采用了阿里云的 EMR 5.15.1 版本进行部署的。
2.2 Paimon VS Hudi
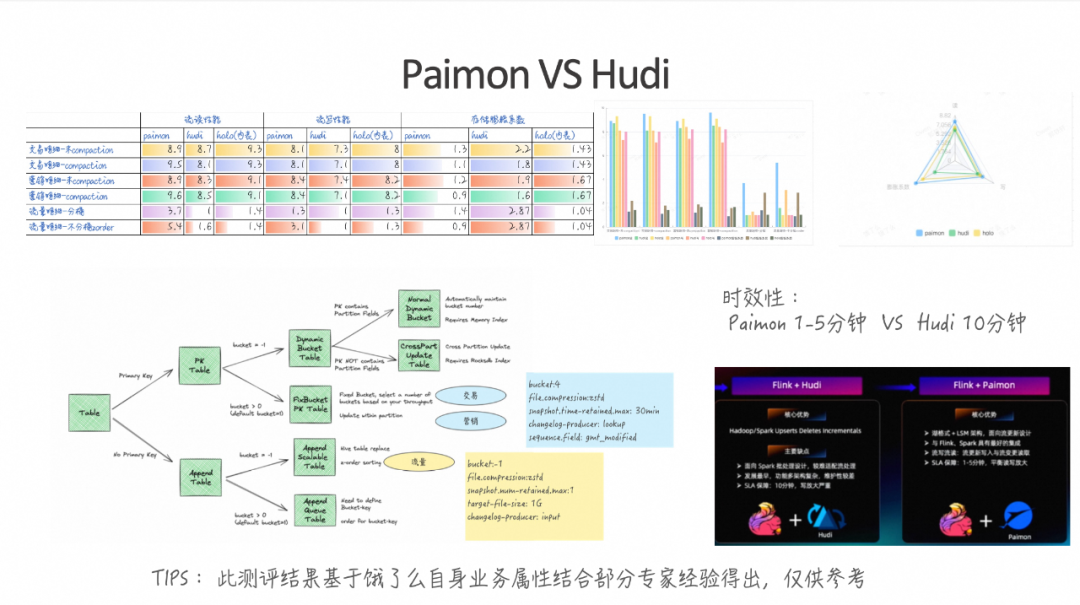
Paimon 和 Hudi 哪个更优呢?
图中左上角展示了经过多轮测试后得出的结果,整体排名基本上都是 Paimon 优于 Hudi。同时,Paimon 的性能也接近 Hologres 内表的流读流写性能。但是在端到端的时效性方面,Hologres 内表仍然最快,可以达到秒级别。Paimon 的时效性测试结果大约在1到5分钟,平均约为3分钟。Hudi 在这一块的延迟一般在10分钟左右。
基于上述测评结果,选择 Paimon 作为后续的湖存储格式。结合前面提到的三个月具体场景,上图可以看到对应的 Paimon 表的创建方式。对于交易和营销数据,由于需要实时更新,因此我们使用了一个PK表,指定了Bucket并同时开启了ZSTD压缩。在这个过程中,还需要通过 Sequence Field 进行版本控制。流量表则是一个 Append Only 表,基本上设置为 Bucket=-1,以支持自动化扩展。同时为了保障读写的性能平衡,所以每一个文件大概需要控制在一个 GB 范围内。
2.3 StarRocks VS Holo VS Trino

在对比 StarRocks、Hologres 和 Trino 的性能时,StarRocks 在各个方面都表现出色,并且优势明显。是什么原因使得 StarRocks 的性能如此出色呢?首先,StarRocks 的 JNI Connector 对 Paimon 进行了良好的适配。其次,StarRocks 支持过滤下推。上图右下展示了饿了么基于 StarRocks 的一个 profile 截图,可以看到 "city_id" 和 "is_valid_order" 这两个字段实现了有效的下推。此外,StarRocks 还具备高效的向量化执行引擎,并且可支持对 Paimon 的 RO 表进行查询。最后,虽然我们目前还没有正式使用物化视图 +SQL 透明改写和 Data Cache 这两个功能,但可以预见一旦投入使用性能将会进一步提升。在这样的背景下,饿了么最终选择使用 StarRocks 和Paimon 作为湖仓解决方案。
2.4 实时湖仓落地探索
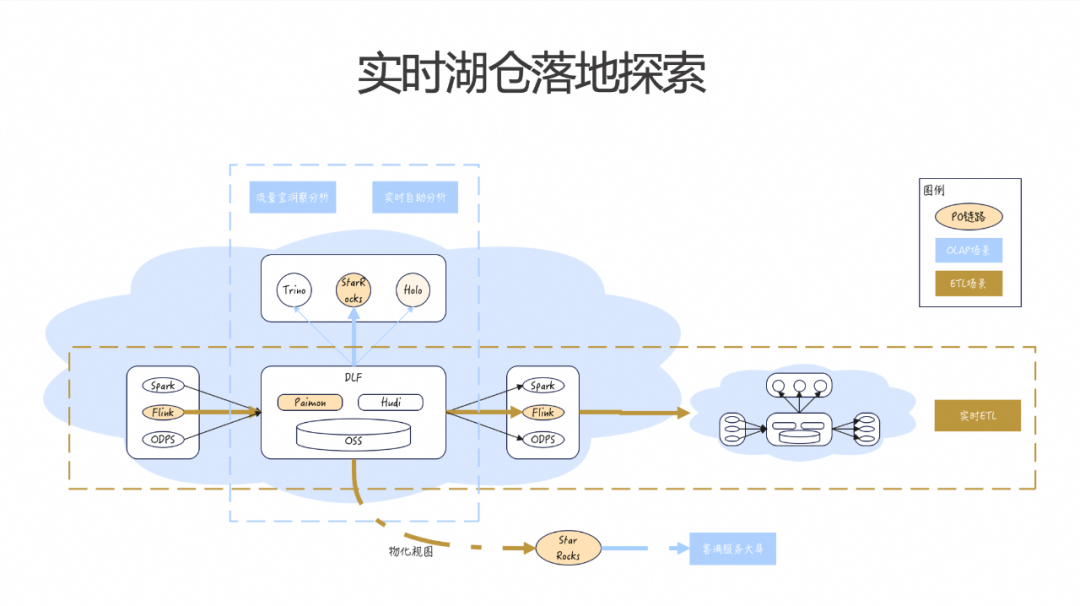
经过多次探索,我们确定了如上图所示的湖仓建设架构。主要的数据处理链路使用 Flink 进行 Paimon 的流读流写,Paimon 的数据存储在内部 OSS 集群上,并通过 DLF(Data Lake Formation)进行元数据管理。通过 Paimon 的流读流写功能,支持实时数仓的分层建模。在特定场景下,利用 StarRocks 的物化视图进行应用层或汇总层的计算。同时,对于一些明细数据,通过 StarRocks 和 Hologres 支持自助分析和洞察分析的需求。具体应用场景包括:内部的流量宝洞察分析、实时交易补贴自助分析以及客满的服务大屏等。
2.5 落地探索-DWD自助分析
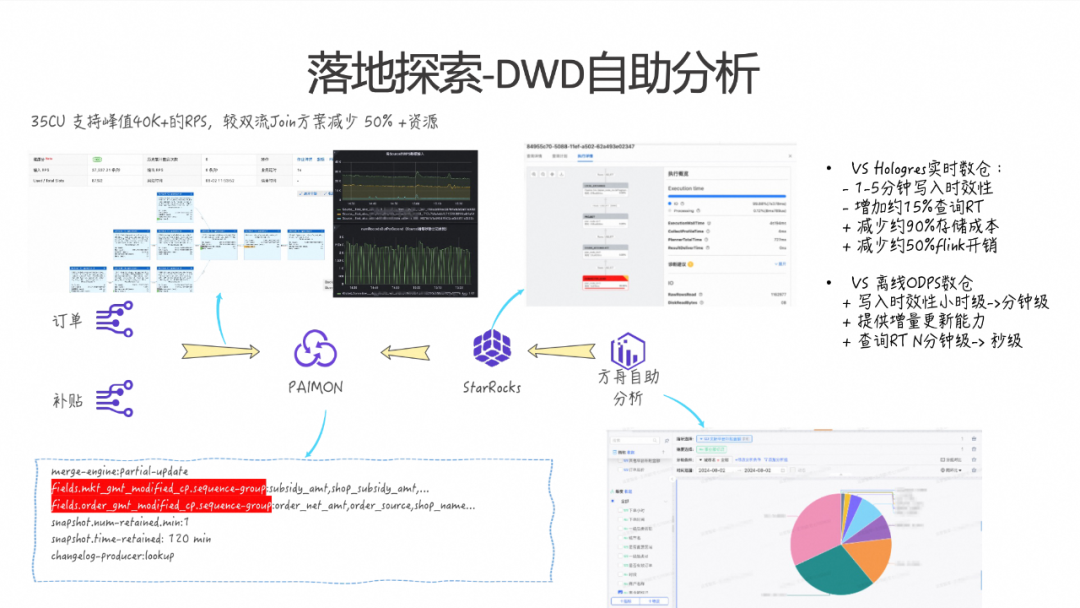
接下来主要介绍基于交易和补贴的自助分析场景。首先,数据源提供订单流和补贴流两个实时流。在传统方案中,这两个流在 Flink 任务中进行双流 Join 处理后写入 Hologres,再基于 Hologres 提供具体的自助分析服务。引入 Paimon 之后,这个流程得以简化。通过使用 Paimon 的 Partial-update 表格式,指定不同流中的 Sequence Group 和对应字段,通过这两条流直接写 Paimon 的方式做一些具体的 Merge。在这种情场景下,整体 Flink 的资源开销相比原来的双流 Join 方案减少了大约 50%,同时系统的整体稳定性也显著提升。
然后在 StarRocks 这一层,通过是 StarRocks 来读 Paimon 外表这块来支持的。上图右上角是整体的 Profile 的结果,可以看到大部分的瓶颈其实还是在IO这一层的。所以后续如果又要做数据湖的加速分析的话,IO这一层还是整体的瓶颈和优化点。
上图右下角展示了整个自助分析的结果示意图。与之前基于 Hologres 的实时数仓方案相比,这个方案在写入时效性上牺牲了1到5分钟,同时单次查询的耗时增加了约5%。然而,整体存储成本较 Hologres 内表减少了约90%,Flink 任务的资源开销也减少了大约50%。
03
实时湖仓规划及展望
3.1 实时数仓3.0展望
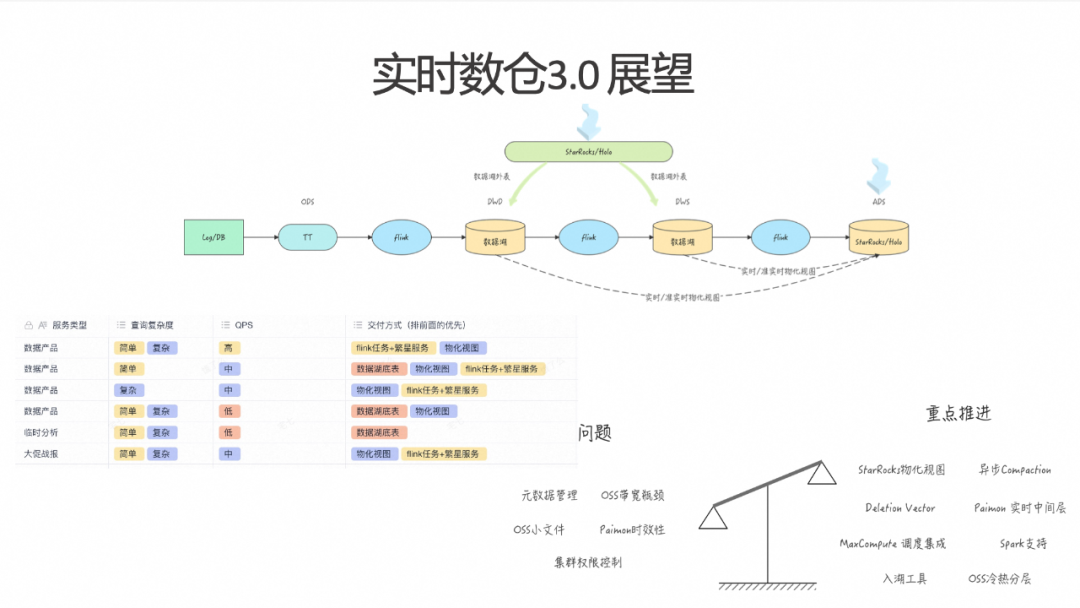
如果建设了实时湖仓,后续的加工链路可以进一步丰富,从而构建不同场景下的数据解决方案。相比之前的实时数仓2.0版本,DWD 层和TT层将逐步替换为数据湖。使用数据湖后,可以针对低频场景构建准实时或实时的物化视图,通过物化视图进行分层建模。同时,还可以利用 Flink 的流读流写能力进行分层建模。在数据服务层,可以根据业务需求,查询对应的 DWD、DWS 或 ADS 层,从而构建多元化的交付方案。
具体的交付方案如上图左下角所示,不同场景可以选择不同的交付方案,利用现有的实时数据资产,提升研发效率,不需要为每个需求从头开发具体的 Flink 任务。然而仍会遇到一些问题:OSS 带宽瓶颈在压测过程中已经显现出来需要解决,同时 OSS 上的小文件问题也是需要解决的。Paimon 的时效性目前为1到5分钟,这限制了实时数仓的分层,无法实现多层依赖,尽管也不推荐过多层数。虽然 Paimon 和 StarRocks 现有的元数据可以通过DLF管理,但与内部原有的元数据管理缺乏打通,需要进一步拓展。此外,目前集群的权限控制相对较弱的,需要进行强化。
右边展示了后续希望重点推进的几个方面。首先是 StarRocks 物化视图,之前进行了轻度测试,因遇到一些问题,暂时未能显著提升研发效率,未来希望重点完善这一方案。此外,在 Flink 写入 Paimon 时,常因 Compaction 问题导致显著抖动,计划采用异步 Compaction 机制,以保障整个实施链路的稳定性。此外,诸如期望引入 Deletion Vector,显著提升查询效率。
目前,Paimon 实时中间层已应用于一些核心链路,未来希望将其推广到更多数据场景。还计划与 DataWorks 和 MaxCompute 进行集成,这属于生态系统建设的一部分。在 OSS 方面,我们希望通过冷热分层能力进一步降低成本。之前尝试结合 Paimon 的 Tag 机制来实现这一目标,但暂时还未找到理想的解决方案。
3.2 回顾
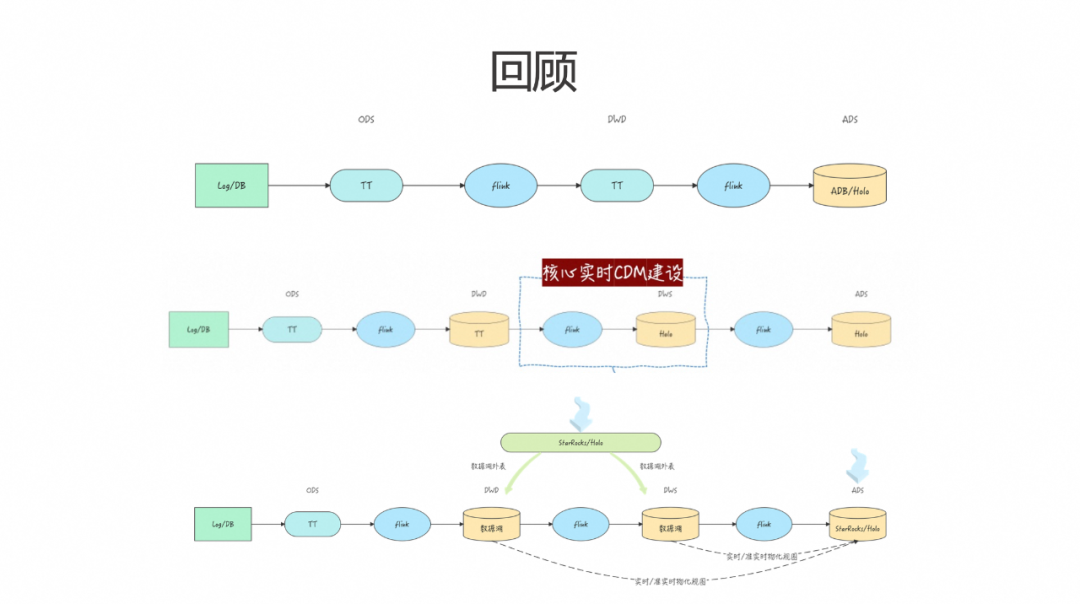
最后回顾一下饿了么整体实时数仓的建设历程,大致可以分为几个阶段。首先是相对原始的开发阶段,这一阶段主要建设实时的 DWD 层,各个应用层通过 Flink 任务各自生成自己的 ADS 数据。在这一过程中,ADS 层出现了大量数据一致性问题和重复开发的问题。为了解决这些问题,我们构建了实时的 CDM 层,从而解决了共性问题。然而,对于新增业务和场景的支持仍显不足。因此,我们引入了实时湖仓方案。虽然该方案目前仍在探索阶段,但已经在一些具体场景中实现了落地。未来,我们希望在 Paimon 和 StarRocks 上进行更多的探索和应用。

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
新用户复制下方链接或者扫描二维码即可0元免费试用 Flink + Paimon
了解活动详情:https://free.aliyun.com/?pipCode=sc

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅 读原文 」跳转阿里云实时计算 Flink ~
点击「阅 读原文 」跳转阿里云实时计算 Flink ~