一、背景描述
现状概述
当前生产环境的 Elasticsearch 集群采用了混合模式部署,所有节点均为主节点、数据节点的组合,没有专门配置独立的主节点、数据节点和协调节点。由于业务需求的不断增长,ES 集群中的索引数量和规模逐渐增加,其中很多索引的单个大小超过 200GB。这种情况导致了在查询压力大或出现异常时,经常发生节点宕机。此外,节点间恢复数据平衡所需的时间较长,影响业务数据的写入,导致索引数据挤压,影响系统的正常运行。
现有的 elasticsearch.yml 配置如下:
yaml复制代码node.attr.rack: r1
node.attr.type: hot
node.master: true
node.data: true
node.ingest: false
node.ml: false
cluster.remote.connect: false解决方案规划
为解决上述问题,计划对 Elasticsearch 集群的节点角色进行拆分,增加独立的主节点和协调节点,以提高集群的稳定性和性能。具体思路如下:
- 将部分服务器配置为专门的主节点,负责管理集群的元数据和协调节点间的通信;
- 增加协调节点,专门处理查询请求,减少数据节点的负载;
- 数据节点仅用于存储和处理索引的数据,以提高写入和查询的性能。
3. 测试环境配置
为了验证上述方案,在测试环境中进行了如下部署:
- 测试环境共有 4 台服务器,每台服务器部署 2 个节点;
- 为方便测试,在其中 3 台服务器上分别增加了一个节点,作为专门的主节点;
- 在另外 2 台服务器上增加了 2 个协调节点,专门处理查询请求。
实施过程
1)修改配置文件
针对新增的主节点和协调节点,分别修改了 elasticsearch.yml 配置文件,确保主节点和协调节点的角色正确设置:
-
主节点的配置:
yaml复制代码node.master: true node.data: false node.ingest: false node.ml: false -
协调节点的配置:
yaml复制代码node.master: false node.data: false node.ingest: true node.ml: false
2) 逐步重启和启动节点
修改完配置后,按顺序重启了相应的 Elasticsearch 节点进程,确保集群能够逐步恢复。
出现的问题
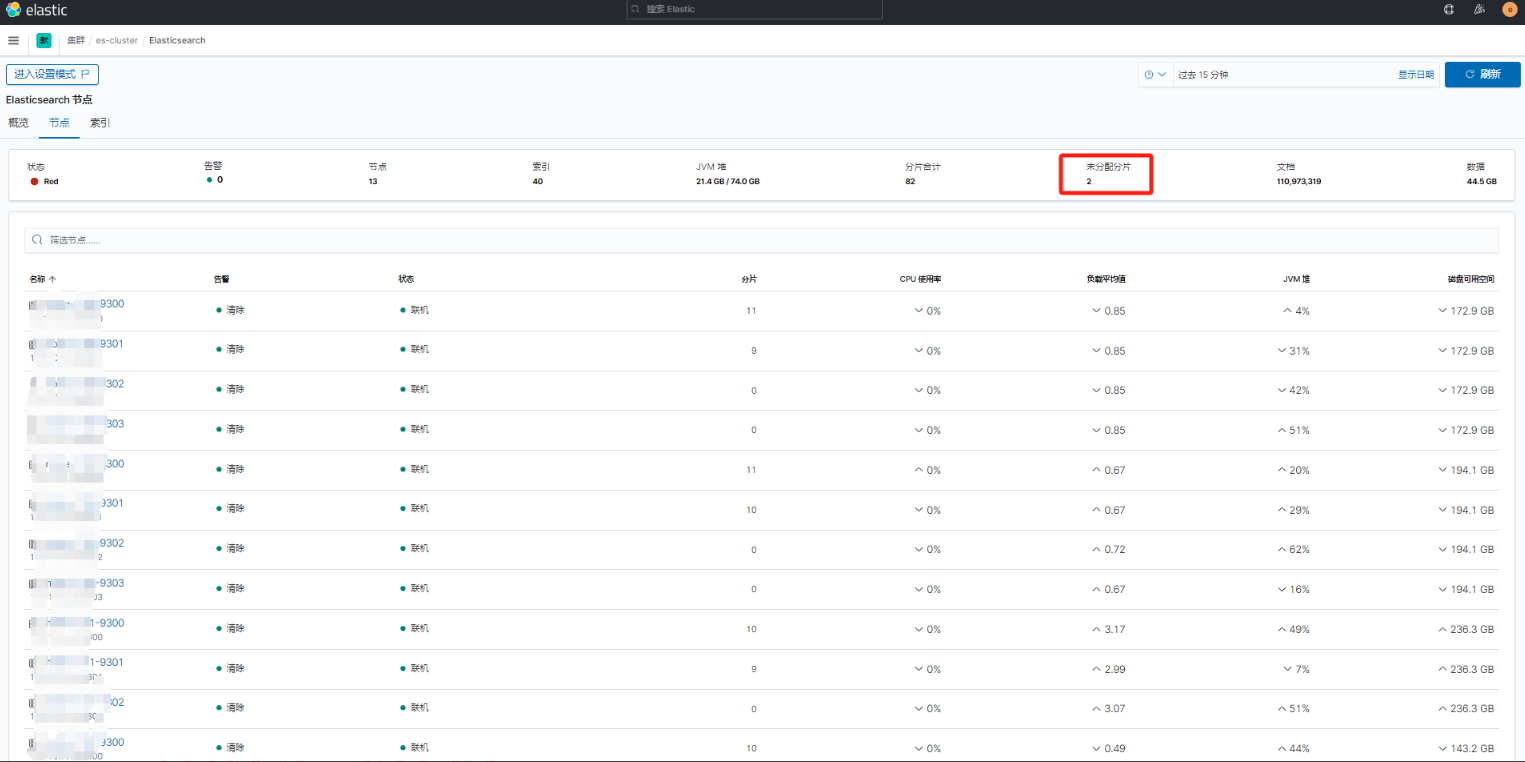
集群重新启动后,发现状态显示有两个未分配分片,如下图所示。原因可能与新增节点的角色配置不当或数据节点的分片分配逻辑不匹配有关。需要进一步排查未分配分片的问题,检查分片的分配策略和副本设置。
二、处理过程
1)查询未分配分片
# 首先查询 Elasticsearch 中未分配的分片有哪些,可登录kibana,在开发工具里去执行如下命令
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
# 此命令将列出集群中的所有分片,并且会显示未分配的分片以及未分配的原因。输出中的 unassigned.reason 列将显示未分配分片的原因
通过上述截图,可以看到 .kibana_task_manager_7.12.1_001 索引的分片状态为 UNASSIGNED,并且有两个分片的未分配原因分别为 ALLOCATION_FAILED 和 CLUSTER_RECOVERED。
ALLOCATION_FAILED:表示分片尝试分配失败,通常是由于资源不足、节点故障或某些限制性设置阻止了分片的分配。
CLUSTER_RECOVERED:表示集群恢复后,该分片尚未分配,这种情况通常与集群状态恢复有关。2)查看分片分配失败的详细信息
# 通过如下命令可查看未分配分片失败的详细信息:
GET /_cluster/allocation/explain
---得到的信息如下
{
"index" : ".kibana_task_manager_7.12.1_001",
"shard" : 0,
"primary" : true,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "ALLOCATION_FAILED",
"at" : "2024-09-11T08:33:07.434Z",
"failed_allocation_attempts" : 5,
"details" : "failed shard on node [-Xn5XL_rS6CCoMEkpfk0Tw]: failed to create shard, failure IOException[failed to obtain in-memory shard lock]; nested: ShardLockObtainFailedException[[.kibana_task_manager_7.12.1_001][0]: obtaining shard lock for [starting shard] timed out after [5000ms], lock already held for [closing shard] with age [50940ms]]; ",
"last_allocation_status" : "no"
},
"can_allocate" : "yes",
"allocate_explanation" : "can allocate the shard",
"target_node" : {
"id" : "-Xn5XL_rS6CCoMEkpfk0Tw",
"name" : "node-xxx.xxx-9301",
"transport_address" : "xxx.xxx.xxx.xxx:9301",
"attributes" : {
"rack" : "r1",
"xpack.installed" : "true",
"type" : "hot",
"transform.node" : "true"
}
},
.......
# 从提供的截图信息来看,.kibana_task_manager_7.12.1_001 索引的分片分配失败,具体的失败原因是由于分片锁定超时,具体错误信息为: failed to obtain in-memory shard lock
这个错误通常是由于分片在执行某些操作时(如关闭或迁移)被锁定,无法释放锁定,导致其他操作(如重新分配)无法继续。可能的原因有:
节点宕机或重启:节点可能在处理分片时出现问题,导致分片没有正常关闭,从而导致锁未被释放。
系统资源紧张:内存或磁盘等资源不足,导致锁定操作无法正常完成。
长时间锁定分片:截图中显示,锁定分片已经超过 509040ms(约8.5分钟),可能是由于某些长时间的操作导致。3)查看磁盘空间和资源
# 分片分配失败可能是由于磁盘空间不足,或者某些节点没有足够的资源。可使用以下命令检查集群节点的磁盘空间使用情况
GET _cat/allocation?v 
查看到磁盘和内存都是正常。
4)手动释放分片锁定
此时可手动触发重新分配未分配的分片手动清除锁定:
# 执行如下命令 POST /_cluster/reroute?retry_failed # 该命令会强制重新尝试分配未能成功分配的分片。
5)查看分片信息
# 可执行如下命令查看分片信息
GET /_cluster/allocation/explain
# 执行结果如下
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "unable to find any unassigned shards to explain [ClusterAllocationExplainRequest[useAnyUnassignedShard=true,includeYesDecisions?=false]"
}
],
"type" : "illegal_argument_exception",
"reason" : "unable to find any unassigned shards to explain [ClusterAllocationExplainRequest[useAnyUnassignedShard=true,includeYesDecisions?=false]"
},
"status" : 400
}
# 执行的命令和返回的错误信息来看,GET /_cluster/allocation/explain 返回了一个 400 Bad Request 错误,并提示无法找到任何未分配的分片,表明分片都已正常分配
查看 ES 集群,此时未再显示有未分配的分片。