
在当今数字影像时代,后期处理技术已成为将原始图像转化为视觉上令人惊叹艺术作品的点睛之笔。随着人工智能技术的飞速发展,尤其是Stable Diffusion技术在图像处理领域的应用,图片后期处理已达到前所未有的高度,为摄影师、设计师及视觉艺术爱好者提供了一键修复的神器。这项技术通过智能色彩校正、光影重塑、细节优化和噪点去除,不仅保留了图像的原始信息,避免了失真,还实现了高效且易用的专业级别修复体验,极大地提升了图像处理的效率和品质,降低了技术门槛。
如下图:

好易智算
首先,我们可以通过好易智算平台迅速启动。在好易智算的平台上,它整合了多个AI应用程序------应用即达,AI轻启。这样的便捷性使得访问和使用这些先进技术变得前所未有地简单快捷。
我们这里选择Stable Diffusion
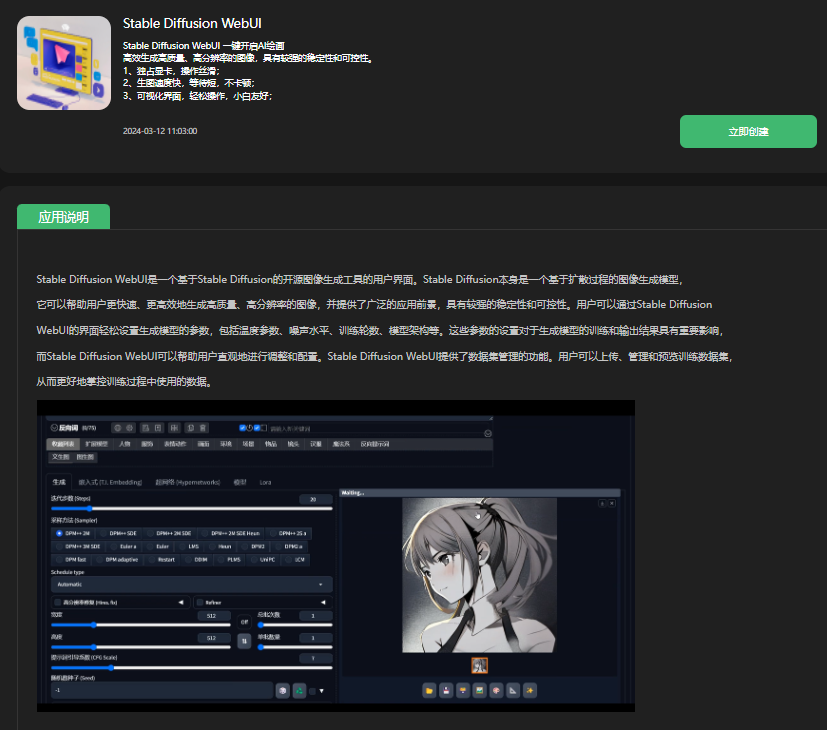
我们开启之后,找到后期处理

我们可以看到很多种算法:
GFPGAN
GFPGAN(生成式面部先验生成对抗网络)是一种先进的人工智能模型,专注于面部图像的修复和优化。它主要利用预训练的人脸GAN(生成对抗网络)中的丰富多样先验来进行真实世界的盲脸修复。GFPGAN的设计使其能够实现真实性和保真度之间的良好平衡,特别是在处理低质量输入图像时

①将人脸图像恢复任务与GAN这种具有丰富先验的盲脸生成模型相结合;
②提出了一种网络结构,和CS-SFT层以及新的损失函数,可以很好地兼顾真实性和保真度。

该模型的整体架构精巧而高效,主要由两个核心部分构成。首先,是一个专门设计的退化消除网络,其基于U-net结构,专司去模糊功能,类似于一个高效的去噪过滤器。紧接着,是一个预训练的styleGAN2风格的脸部生成网络,它负责注入丰富的面部细节。这两部分通过网络中的CS-SFT层巧妙地衔接在一起。
在退化消除网络中,U-net结构分为三个主要部分:下采样层(编码器)、中间层以及上采样层(解码器)。输入的模糊图像首先通过编码器进行下采样,提取出图像的高级抽象特征。在中间层,我们得到图像的潜在特征,记作F_latent。这个潜在特征F_latent随后通过一个多层感知器(MLP)转换成潜在编码W,这一编码直接作为StyleGAN2的输入,进而生成包含丰富脸部细节的卷积特征F_GAN。
在U-net的上采样解码器阶段,我们处理的是经过去模糊处理的不同尺度(分辨率)的图像,记作F_spatial。这些图像与F_GAN结合,共同作为CS-SFT层的输入,进行空间调制,从而实现从模糊到清晰、从抽象到具体的图像转换。
在webUI中的体现在于插件配置中,可以调节GFPGAN的能见度,来调节图像的清晰度

CodeFormer
人脸复原模型,由南洋理工大学与商汤科技联合研究中心S-Lab在NeurIPS 2022大会上隆重推出。该模型融合了VQGAN与Transformer技术,开创了一种新颖的人脸复原方法。基于预训练的VQGAN离散码本空间,CodeFormer颠覆了传统的人脸复原任务范式,将其转化为Code序列的预测问题,极大地减少了复原过程中的不确定性。此外,VQGAN的码本先验为复原任务注入了丰富的面部细节。得益于Transformer的全局建模能力,CodeFormer在应对严重图像退化问题上展现出卓越的鲁棒性,使得复原出的人脸图像更加逼真、自然。

CodeFormer的工作原理主要包括以下三个步骤:
- 自动编码器:CodeFormer利用自动编码器的结构,这是一种深度学习模型,专门设计用于高效地编码和解码数据。在这个阶段,自动编码器扮演着至关重要的角色,它通过学习人脸图像的低维表示,实现了对人脸的精细变换。这个过程不仅包括了对图像的色彩化处理,使得黑白或色彩失真的图像恢复生机,还包括了清晰化处理,通过增强图像的细节和对比度,使得模糊的图像变得更加锐利。此外,自动编码器还能有效地进行去马赛克修复,将图像中的马赛克区域还原成自然的纹理和颜色,从而为人脸图像的高质量修复和增强奠定了坚实的基础。
- VQGAN离散码本空间:在自动编码器的基础上,进一步采用了预训练的VQGAN(向量量化生成对抗网络)离散码本空间。这种方法的核心在于将连续的人脸图像数据转换为一系列离散的Code序列,这些序列对应于VQGAN学习到的面部特征码本。通过这种方式,CodeFormer极大地降低了人脸复原任务中的不确定性,因为离散的Code序列更容易预测和控制。同时,VQGAN的码本先验知识为复原任务提供了丰富的人脸细节信息,这些细节信息包括皮肤纹理、毛发、眼睛等特征,使得复原出的人脸不仅在视觉上更加真实,而且在特征上也更加细腻和准确。
- Transformer全局建模:最后一环是利用Transformer进行全局建模。Transformer模型以其强大的全局上下文捕捉能力而著称,它能够处理序列数据中的长距离依赖关系。在CodeFormer中,Transformer的作用是进一步加强对人脸图像全局结构的理解,从而提升模型对严重退化图像的鲁棒性。这意味着即使在面对严重损坏、模糊不清或者有大量噪声的图像时,CodeFormer依然能够通过Transformer的全局建模能力,有效地进行图像修复和增强。这种全局性的处理使得复原的人脸不仅在局部细节上表现出色,而且在整体结构和和谐度上也达到了高度一致,从而实现了更加自然和逼真的修复效果。
在webUI中的体现在于插件配置中,可以调节CodeFormer的能见度以及模型权重,来调节图像的清晰度

Caption
BLIP
BLIP(Bootstrapping Language-Image Pre-training)算法是一种用于图像和文本理解的多模态预训练模型,它在Stable Diffusion模型中扮演着重要的角色,尤其是在理解和生成图像的上下文中。BLIP算法由Salesforce研究院开发,旨在通过结合图像识别和自然语言处理技术来提高模型对图像内容的理解能力。
以下是BLIP算法的主要组成部分和特点:
- 多模态预训练 :
- BLIP算法通过在大量图像和文本对上进行预训练来学习图像和文本之间的关联。这种预训练使模型能够理解和生成与图像内容相关的文本描述。
- 双流架构 :
- BLIP采用了双流架构,包括一个图像流和一个文本流。图像流负责从图像中提取视觉特征,而文本流则处理文本信息。这两个流在模型的不同层次上进行交互,以共同学习图像和文本的表示。
- 自监督任务 :
- 在预训练过程中,BLIP执行自监督任务,如图像文本匹配(判断给定的图像和文本是否匹配)和图像文本检索(给定图像或文本,找到与之匹配的文本或图像)。这些任务帮助模型学习如何将图像内容与文本描述相对应。
- 多任务学习 :
- BLIP算法在预训练期间还采用了多任务学习策略,包括图像分类、图像文本匹配和文本生成等任务。这种多任务学习使模型能够在不同的任务上获得更全面的理解能力。
- 文本生成 :
- BLIP的一个重要特性是其能够根据图像内容生成描述性文本。这一能力在Stable Diffusion模型中非常有用,因为它可以帮助模型更好地理解用户提供的文本提示,从而生成更符合用户意图的图像。
在Stable Diffusion模型中,BLIP算法的作用通常包括以下几个方面:
- BLIP的一个重要特性是其能够根据图像内容生成描述性文本。这一能力在Stable Diffusion模型中非常有用,因为它可以帮助模型更好地理解用户提供的文本提示,从而生成更符合用户意图的图像。
- 理解文本提示:BLIP可以帮助Stable Diffusion模型理解用户输入的文本提示,将其转化为图像生成过程中可用的视觉概念。
- 生成图像描述:BLIP可以生成图像的文本描述,这对于评估生成图像的质量和是否符合用户意图非常有用。
- 图像编辑 :在图像编辑任务中,BLIP可以帮助模型理解需要对图像进行哪些修改,以符合用户的编辑指令。
总之,BLIP算法通过其多模态理解和生成能力,极大地增强了Stable Diffusion模型在处理图像和文本关联任务时的效能。
DEEPBOORU
在Stable Diffusion中,DEEPBOORU算法主要用于图像和文本的生成。它通过深度学习模型来识别和生成Booru风格的图像标签,从而帮助模型更好地理解和生成图像内容。DEEPBOORU的核心功能包括图像识别、标签生成、预训练模型、自定义训练、开源性质等。它使用深度学习模型,尤其是卷积神经网络(CNN),来分析和识别图像中的视觉内容,并能够自动生成描述性的标签。此外,DEEPBOORU还提供了预训练的模型,这些模型可以直接用于图像标签的生成,并且可以通过收集特定类型的图像数据集进行进一步训练。由于其开源性质,DeepBooru在图像识别和标签生成领域成为一个有价值的工具,其应用场景广泛,包括图像管理、内容审核、艺术创作等。

Stable Diffusion允许用户以一张图片为基准,生成另外一张图片。这个过程包括对原始图片进行反向推理、涂鸦、重绘、蒙版等操作。例如,用户可以使用DeepBooru反推提示词功能,通过一张图片来生成相关的文本描述。这个过程可以更准确地传达用户想要的画面内容,提高图像生成的准确性。DEEPBOORU算法在这个过程中的作用是通过分析图片内容,生成相关的标签和描述,帮助模型更好地理解用户的输入,从而生成更符合用户意图的图像。
除此之外,我们还可以依据后期处理,进行分辨率的修复,翻转,换脸等操作
例如:
pro
正向提示词:
<lora:twdtx:1>twdtx,1girl, full body, ((white theme:1.75)),((best quality)), ((masterpiece)), ((ultra-detailed)), (illustration), (detailed light), (an extremely delicate and beautiful),incredibly_absurdres,(glowing),(1girl:1.7),solo,a beautiful girl,(((upper body))),standding,((beautiful Dress+stocking):1.25),((Belts)),(leg loops),((flower headdress:1.45)),((white hair)),(((beautiful blue eyes))),(+++(english text:1.5)),(flower:1.65),(rose),(garden),(petal),(magic_circle:1.2), (Saturn ring:1.1),(((border:1.5)))
负向提示词:
(worst quality:2),(low quality:2),(normal quality:2),lowres,watermark,badhandv4,ng_deepnegative_v1_75t,
勾选反转之后



进行换脸:

只需要在这里进行简单配置

这里选择的是reactor模型,这在之前的文章已经进行详细使用的介绍,就不多介绍了
https://blog.csdn.net/Why_does_it_work/article/details/141337314
结语

在数字影像领域的后期处理技术方面,人工智能技术,特别是Stable Diffusion技术的应用,已经取得了显著的进步。这项技术通过智能色彩校正、光影重塑、细节优化和噪点去除等功能,不仅保留了图像的原始信息,避免了失真,还实现了高效且易用的专业级别修复体验。这极大地提升了图像处理的效率和品质,降低了技术门槛,使得更多的人能够轻松享受到高质量图像处理带来的便利。通过好易智算平台,我们可以迅速启动Stable Diffusion模型,整合多个AI应用程序,使得访问和使用这些先进技术变得简单快捷。此外,GFPGAN和CodeFormer等算法在图像修复和优化方面发挥着重要作用,提高了图像处理的效率和品质,为摄影师、设计师及视觉艺术爱好者提供了更多的创作可能性。
