TechDay
本文由阿里云技术专家魏子珺在【AI搜索TechDay】上的分享【阿里云Elasticsearch AI搜索实践】整理而成。
【AI搜索TechDay】是Elastic和阿里云联合主办的AI技术Meetup系列,聚焦企业级AI搜索应用和开发者动手实践,旨在帮助开发者在大模型浪潮下升级AI搜索,助力业务增长。
阿里云Elasticsearch的AI搜索实践与探索
近年来,Elasticsearch(简称ES)在AI领域的发展非常快。作为一名深耕ES领域近十年的研究者,我见证了ES的飞速发展,但像现在AI相关特性上如此快速的迭代,还是非常惊讶的,并意识到持续跟进AI技术的重要性,特别是在阿里云ES上,我们要去做些什么,能够让ES的用户能够更好的去使用上这些AI功能。
本次分享聚焦于阿里云ES平台上的AI搜索实践与探索。经过团队研究,我们已在多个方向取得实质性进展。我先简要概述ES在AI领域的核心特性,提供一个概览性的理解。
ES在AI场景核心技术之一是引入了先进的语义理解能力,特别是通过embedding向量技术革新搜索引擎。具体而言,我们将文本转换为高维向量,这超越了传统分词和同义词匹配的局限,实现了对词语语境和含义的深度捕捉。例如,对于"狗"这个词,不仅能识别出直接相关的查询,还能延伸至"哈士奇"、"泰迪"等具体品种,极大地丰富了搜索的相关性和精准度。
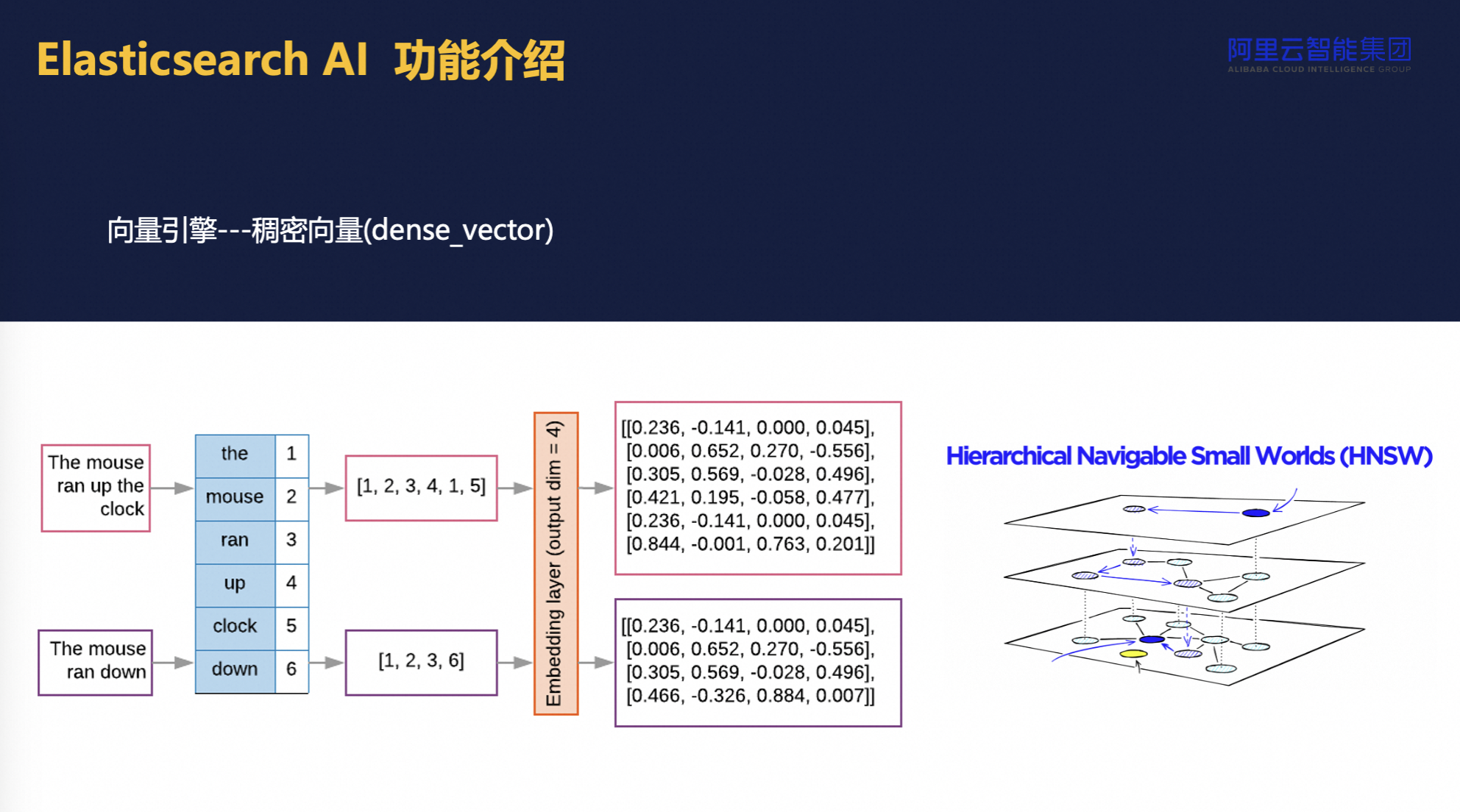
实现这一突破的关键在于采用了HNSW算法进行近似最近邻搜索。该算法采用分层结构进行高效检索,通过逐步细化搜索空间来逼近最相似结果,有效减少了全量数据扫描的需求,提升了查询效率。然而,HNSW要求较高的内存资源以支持其全内存操作,这对系统资源管理提出了挑战,同时也强调了参数调优的重要性,以在保证效率的同时最大化搜索的准确性和召回率。
Elasticsearch向量引擎的性能提升与迭代更新
聚焦于Elasticsearch向量引擎的持续优化进程,特别是针对性能与成本的改进,显得尤为关键。初期,由于普遍存在的认知偏差------认为ES向量引擎虽功能强大但在性能上可能存在短板,尤其是对于Java生态系统中的应用------这一观点正逐渐被其技术演进所颠覆。实际上,自8.0初始版本至当前已经迈入的8.15版本的历程中,ES不断迭代,特别是在性能优化方面取得了显著进展,其中包括但不限于对硬件加速技术的有效整合。
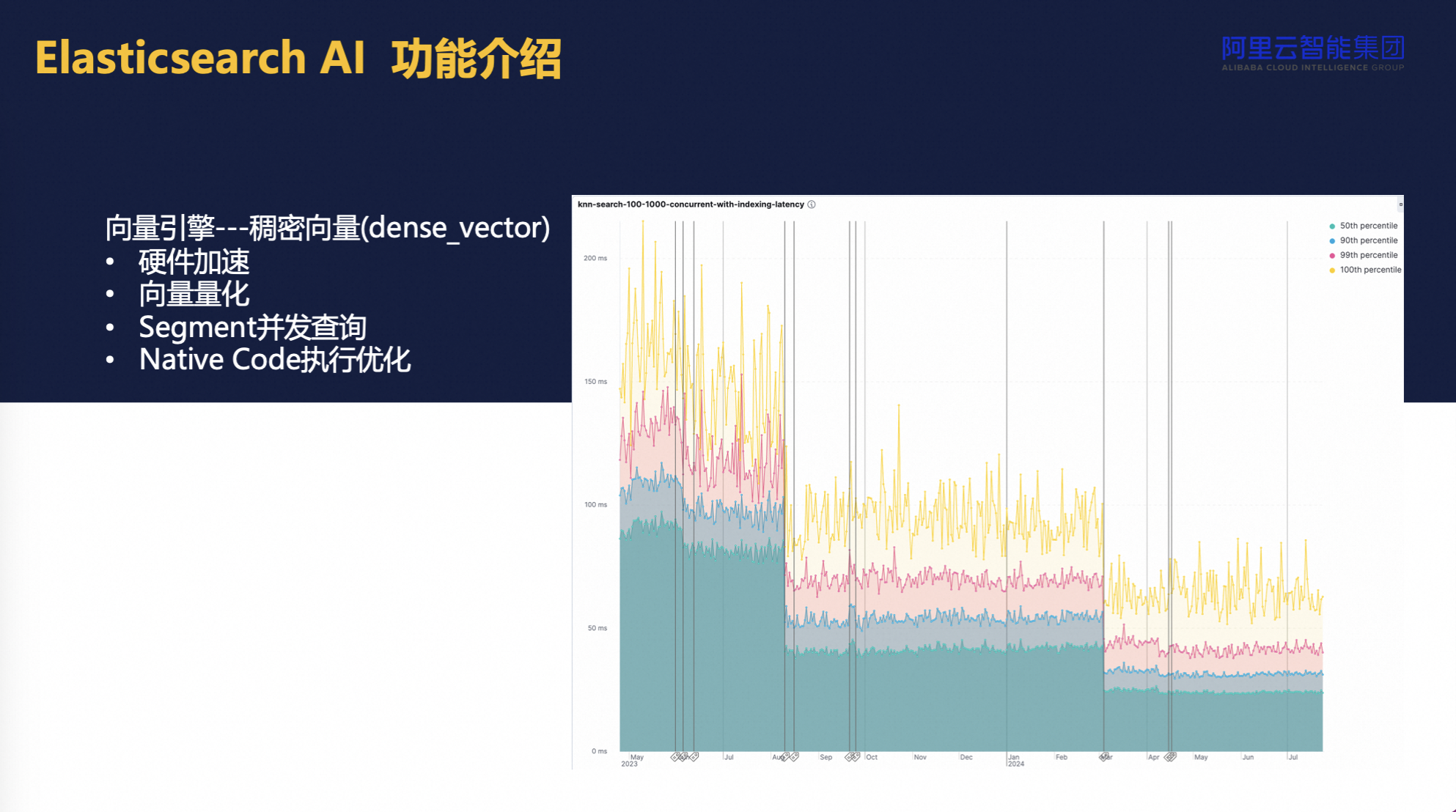
特别地,ES利用硬件加速技术在向量检索领域,尤其是处理复杂相似度计算任务时,实现了显著的性能飞跃。这种技术创新不仅限于理论层面,实践证明,通过硬件加速器的深度融合,部分计算密集型操作的效率提升了数倍乃至更多。例如,从2022年9月至今的基准测试数据可直观看出,查询响应时间从最初100ms大幅缩减至现在20ms左右,彰显了ES向量检索迭代升级带来的巨大性能提升。
此外,ES在内存优化同样值得关注,通过向量量化技术,所需内存仅为原先需求的四分之一,极大提升了资源利用率。同时,针对高并发查询场景进行的优化,确保了在处理大规模客户信息查询等任务时,系统的稳定性和响应速度得以保持,进一步验证了ES在向量处理应用中的高性能。
提升Elasticsearch性能与功能:稀疏向量与模型应用
在探讨 Elasticsearch 的应用时,特别是关注其在处理文本数据、性能优化及混合搜索策略方面的高级功能,核心要点可精炼如下:
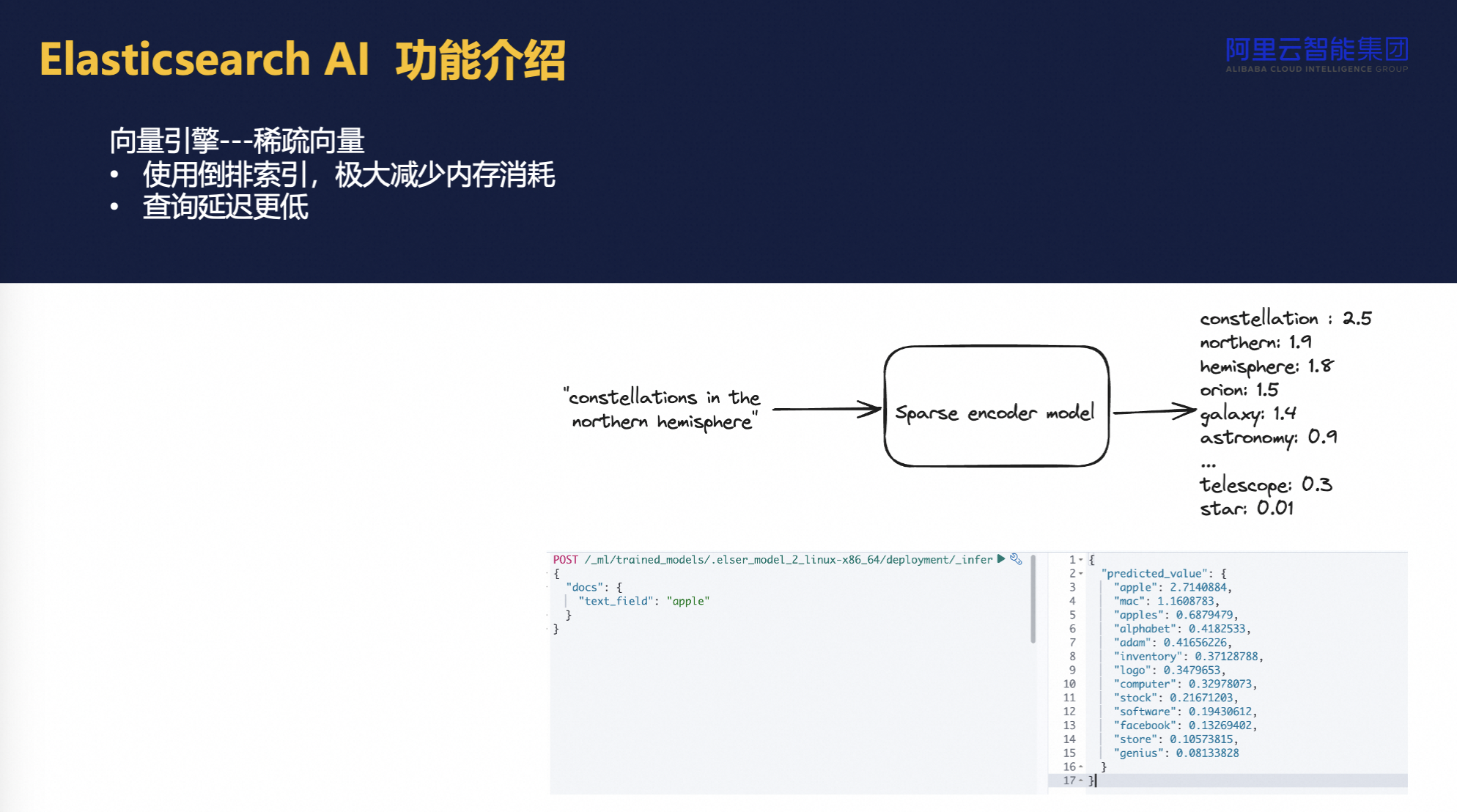
- 语义扩展与稀疏向量表示:Elasticsearch利用诸如稀疏编码技术,不仅能够基于原始词汇建立索引,还能有效扩展至与其相关的概念或词汇,每项扩展均附有模型计算出的权重,增强了语义理解的深度和广度。这得益于稀疏向量技术,它以较低内存占用高效存储信息,对比稠密向量需全内存索引,显著提升了资源效率。
- 查询效率与资源优化:查询过程受益于倒排索引结构,避免了向量相似度匹配的开销,加速了检索速度。此外,Elasticsearch的稀疏向量减少了内存需求,进一步优化了资源利用。
- 混合搜索策略:现代搜索需求促使Elasticsearch支持多模态查询,结合文本、向量检索以及rrf混合排序方法,以增强结果的相关性和覆盖范围。这种混合搜索策略能够召回更多样化的数据,提升用户体验。
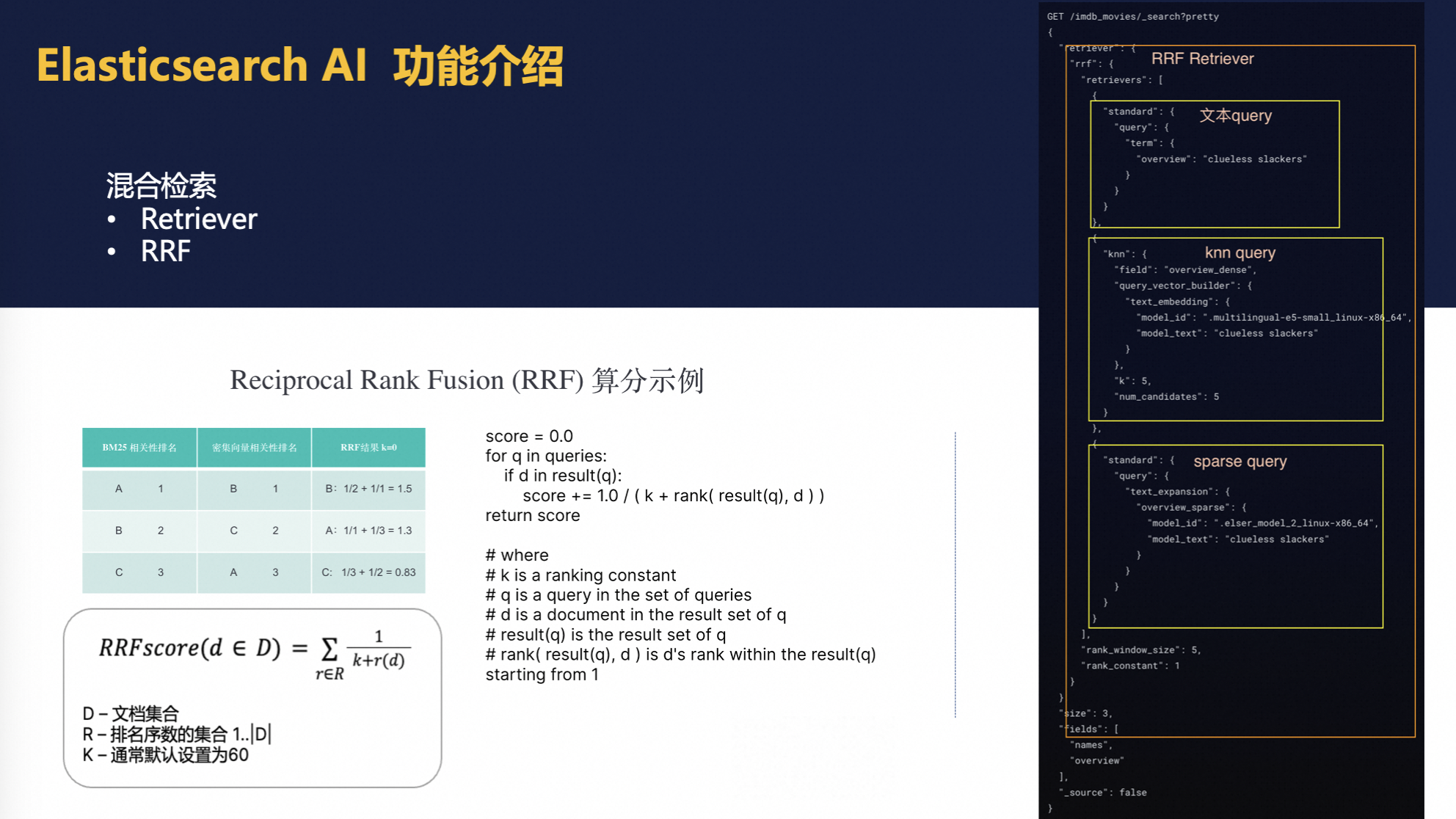
- 排名与相关性调整:为了从召回的大量数据中精确选出最相关的结果,ES采用如BM25等排序机制,考虑文档频率和位置等因素初步确定权重。随后,通过集成学习或更精细的模型(如rerank阶段)对初步筛选出的文档进行二次排序,确保顶部结果高度相关。
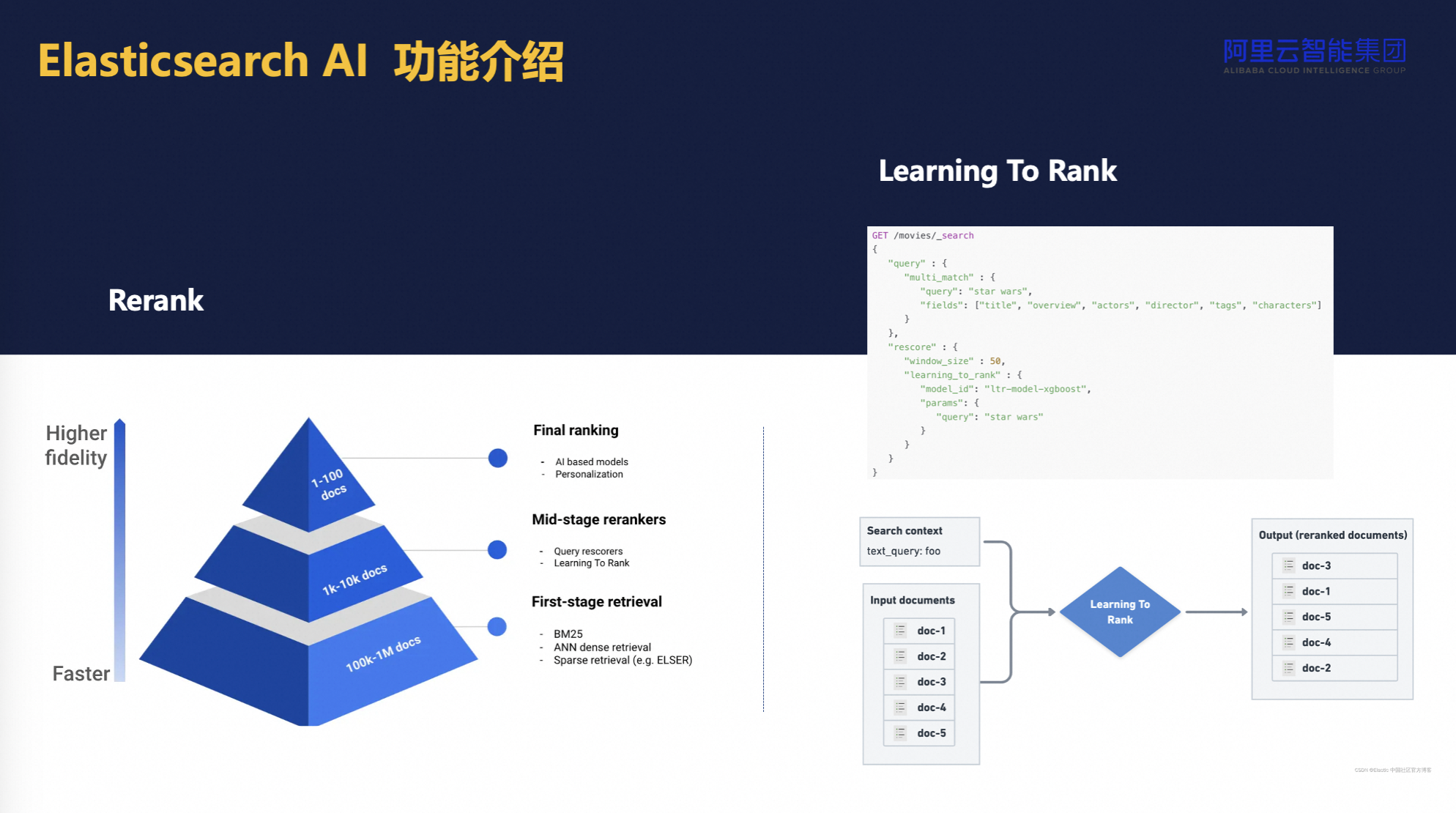
- 模型集成与原生支持:Elasticsearch展现了强大的模型集成能力,允许用户直接将自定义模型加载至集群中运行,实现从输入到输出(如词嵌入生成)的端到端处理,无需外部预处理步骤。这不仅简化了工作流程,还促进了机器学习模型与搜索引擎的无缝融合,强化了系统的智能化水平和适应性。
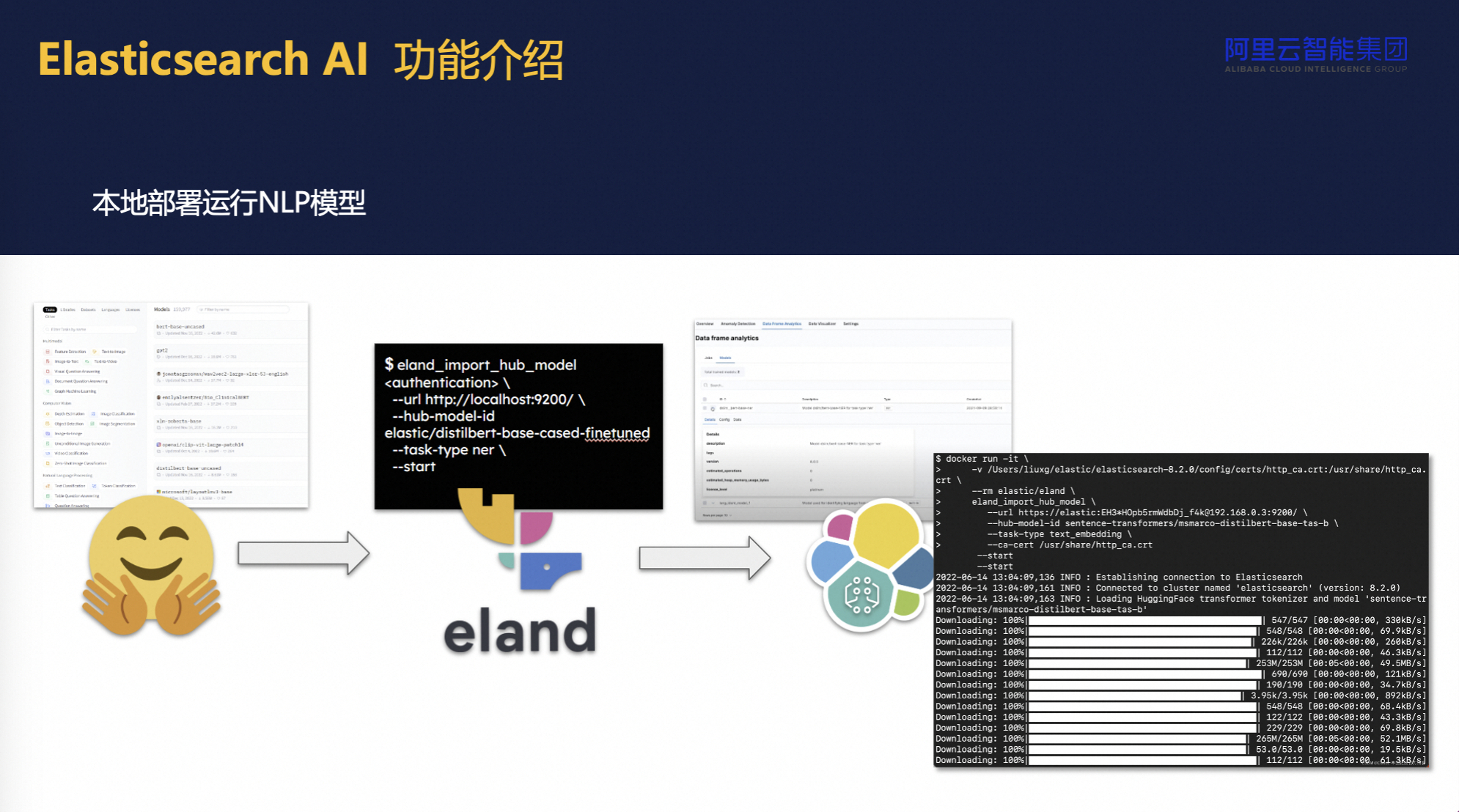
用云服务提升模型的使用效率和灵活性
Elasticsearch中的Inference API及其在阿里云环境下的应用,这是一个相对较新的功能,自8.11版本引入,旨在简化和优化机器学习模型在ES上的部署与使用流程。该API的核心价值在于,它允许用户无需经历繁琐的模型下载、安装及资源调配等步骤,即可直接在ES中利用预训练模型进行高级查询和数据分析,特别是针对诸如文本向量化这样的任务。

具体而言,Inference API通过整合第三方模型服务,如来自OpenAI、Hugging Face等知名平台的模型,以及阿里云自家的AI搜索模型,为用户提供了一个统一且便捷的接口。这意味着,用户仅需通过简单的API调用,就能在ES环境中启用这些模型,无论模型是本地部署还是远程托管,极大地降低了技术门槛和运维成本。用户在操作时,体验几乎无差异,无论是创建、查询还是执行嵌入操作,所有过程均围绕模型ID进行,ES内部会自动处理文本到向量的转换及后续的查询优化工作。
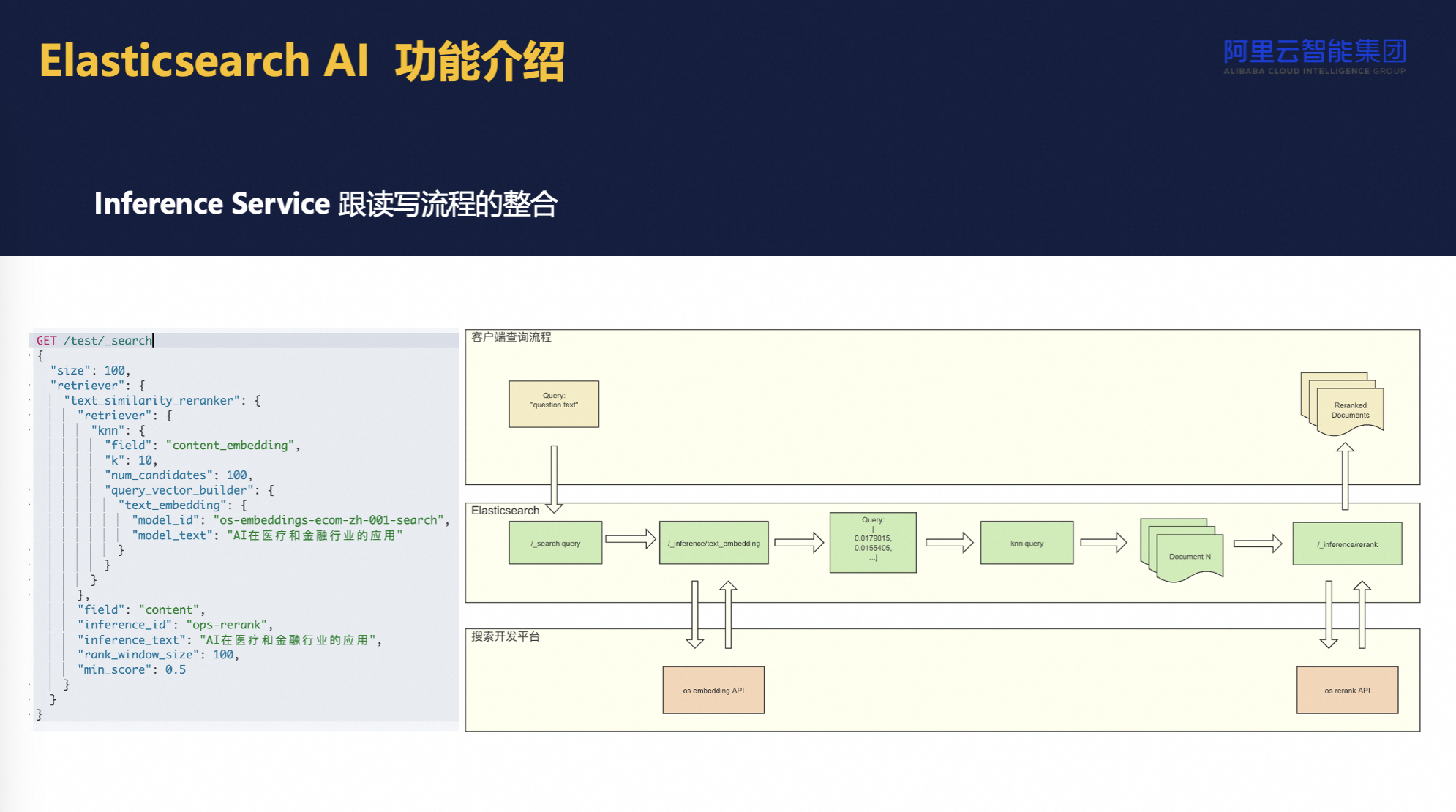
这一创新对于ES用户,尤其是那些涉及语义搜索或复杂文本分析场景的用户来说,意义重大。它不仅简化了模型集成的流程,还内置了文本预处理、特征提取等功能,用户仅需关注业务逻辑,通过提供的模型ID,即可实现从原始文本查询到模型预测结果的无缝对接,进而进行高效的向量搜索或其他相关检索操作。最终,这促进了ES作为数据存储与分析平台的功能延展,使之更加适应现代AI驱动的应用需求,提升了用户体验和系统整体效能。
基于阿里云AI的Elasticsearch引擎扩展与服务

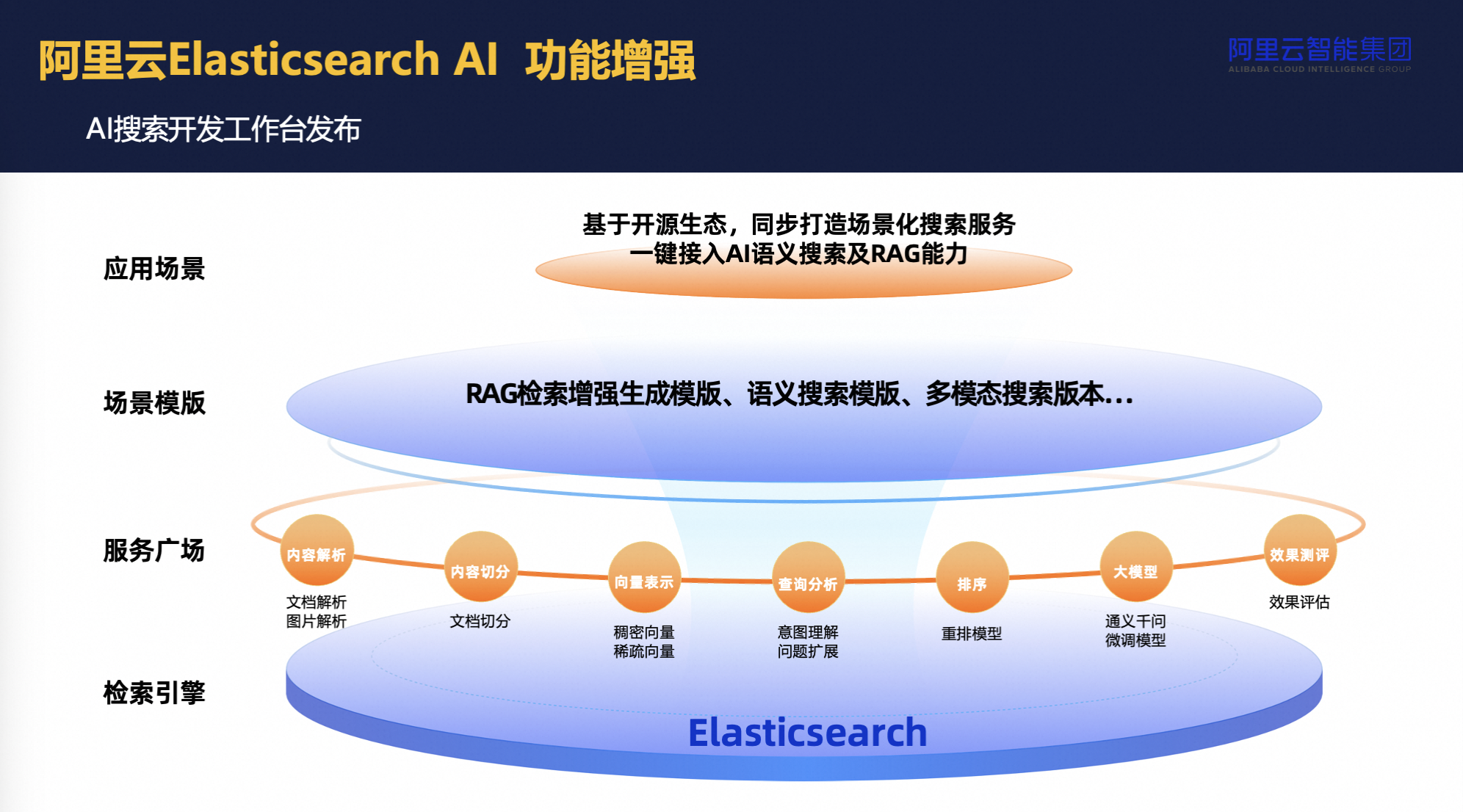
阿里云Elasticsearch AI搜索方案集成了人工智能模型的搜索引擎架构,旨在优化用户的查询体验与内容处理能力,核心在于将复杂的模型服务与 Elasticsearch 引擎紧密结合,简化了从数据摄入到信息检索的全过程,具体如下:
-
用户查询接口:用户通过提交查询query启动流程,这可能是自然语言文本或其他形式的输入。
-
AI搜索开发工作台:提供一个集成环境,允许用户不仅提交查询,还能利用预设的场景模板进行高级搜索配置,如增强的语义搜索等,提升了易用性和灵活性。
-
模型服务集成:创新之处在于将多种模型服务直接嵌入ES内部,用户无需在本地部署模型。这些模型涵盖了内容解析、文档处理等多种功能,简化了从前端到后端的模型应用流程。
-
数据处理自动化:用户上传文档时,系统自动解析(如PDF、HTML等格式),并运用预训练的文本理解模型进行内容分析,实现结构化信息提取及文本向量化,这一过程无缝集成于ES的索引流程中。
-
查询处理与混合检索:查询接收后,通过自然语言处理技术理解用户意图,即使面对模糊或上下文不全的查询也能有效识别。检索过程中,结合传统的关键词匹配与基于向量的相似性检索,实现了混合检索策略,提高了查询结果的相关性。
-
结果展示与交互:检索完毕,数据经由Elasticsearch处理后,可直接用于前端展示或进一步的业务逻辑处理。
阿里云Elasticsearch在RAG场景的应用

RAG核心要求包括:高度精确的产出、即时答案生成、控制高昂的训练推理成本,并解决数据安全问题。尽管网页应用在流程上相对直观,但仅将引擎作为召回工具可能无法满足性能预期。因此,深入内容理解、精细排序机制、高效的文档解析及切片技术,都是提升RAG整体效果的关键环节。
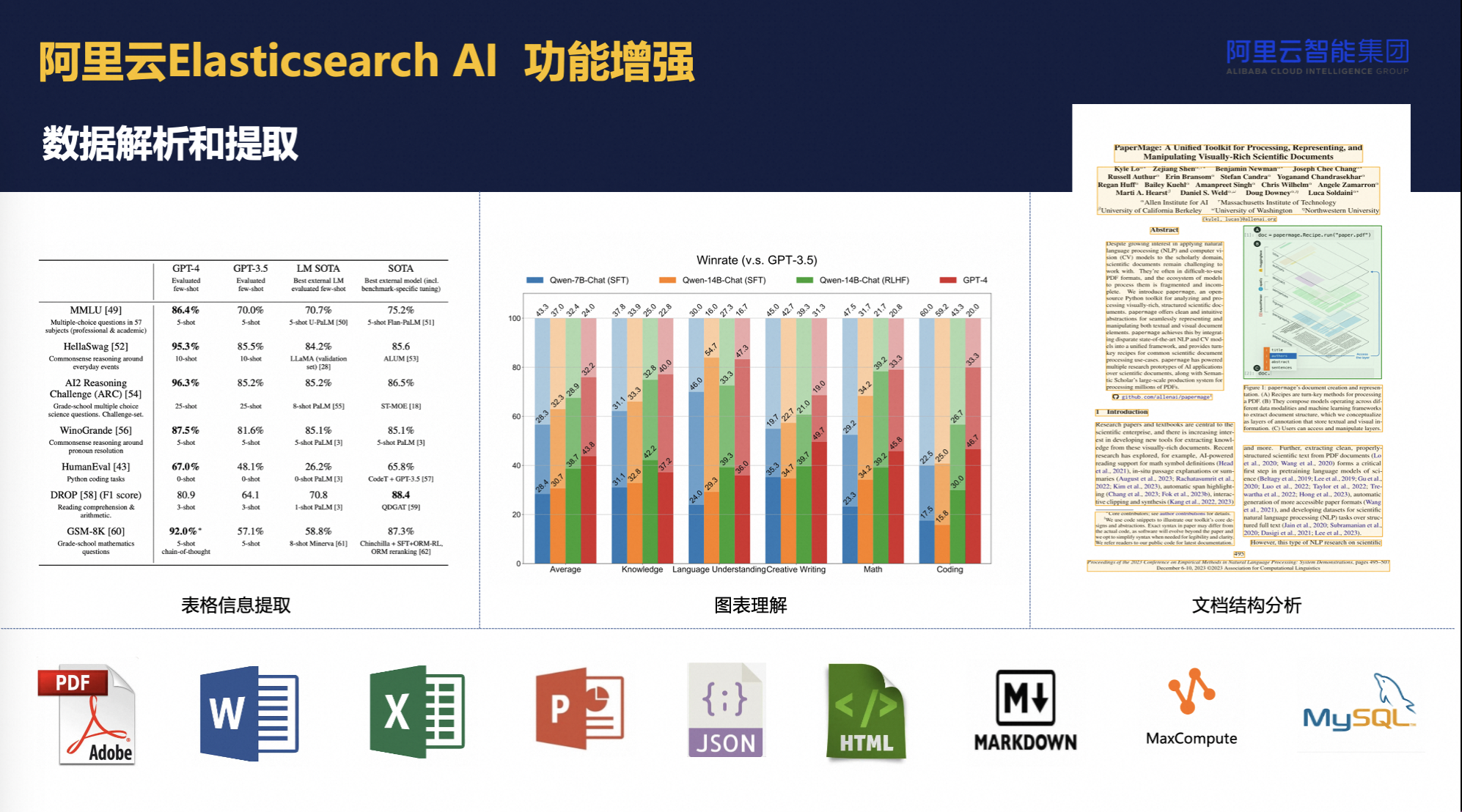
我们已开发出一款数据解析与提取模型,能灵活应对PDF等多种文档格式,大幅减轻用户处理复杂文件结构(如图文混排PDF)的负担。此模型可智能化地分割文档并优化入库数据质量。
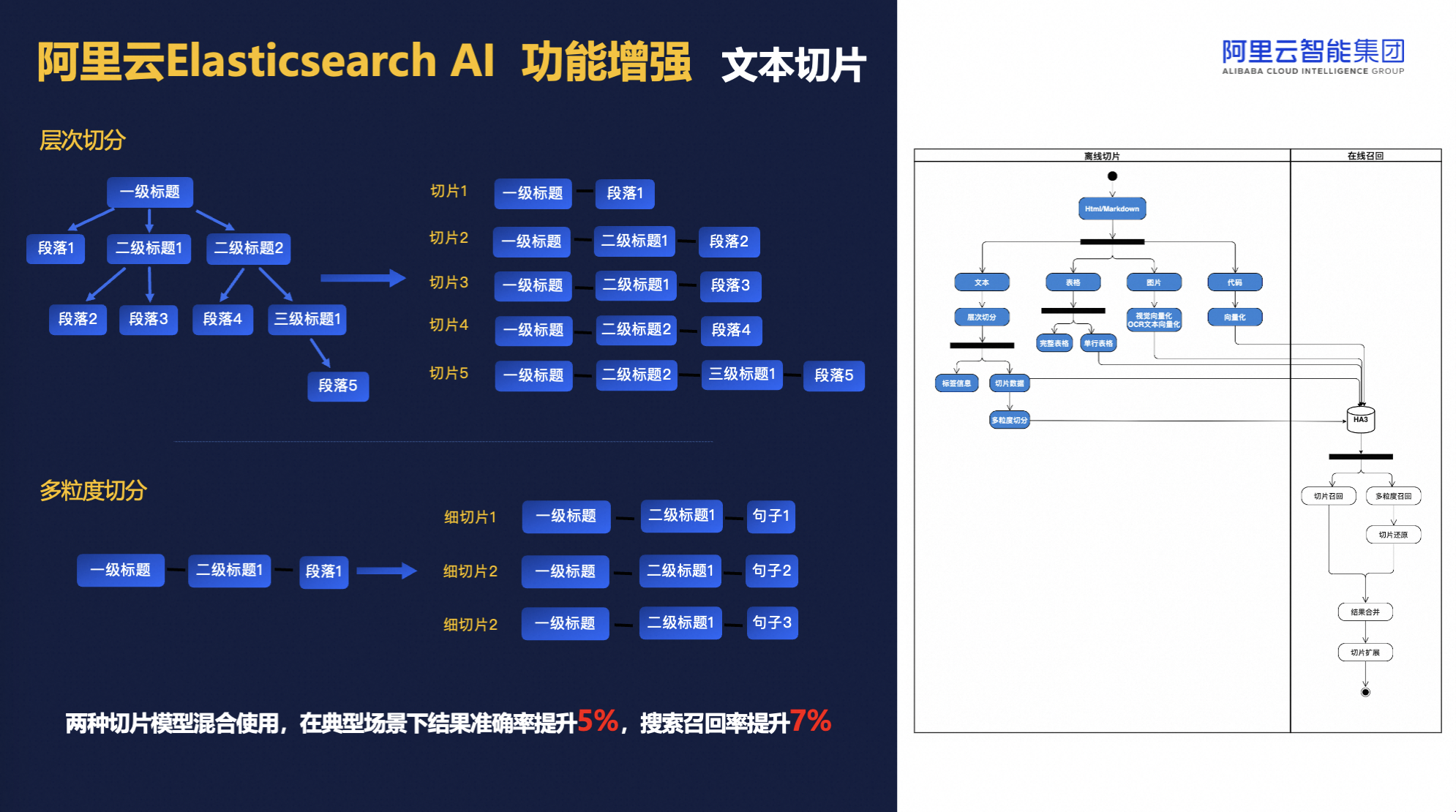
此外,我们还设计了文本切片模型,确保在处理长文本时保持语义完整性,避免信息割裂,通过合理切分提高处理效率。
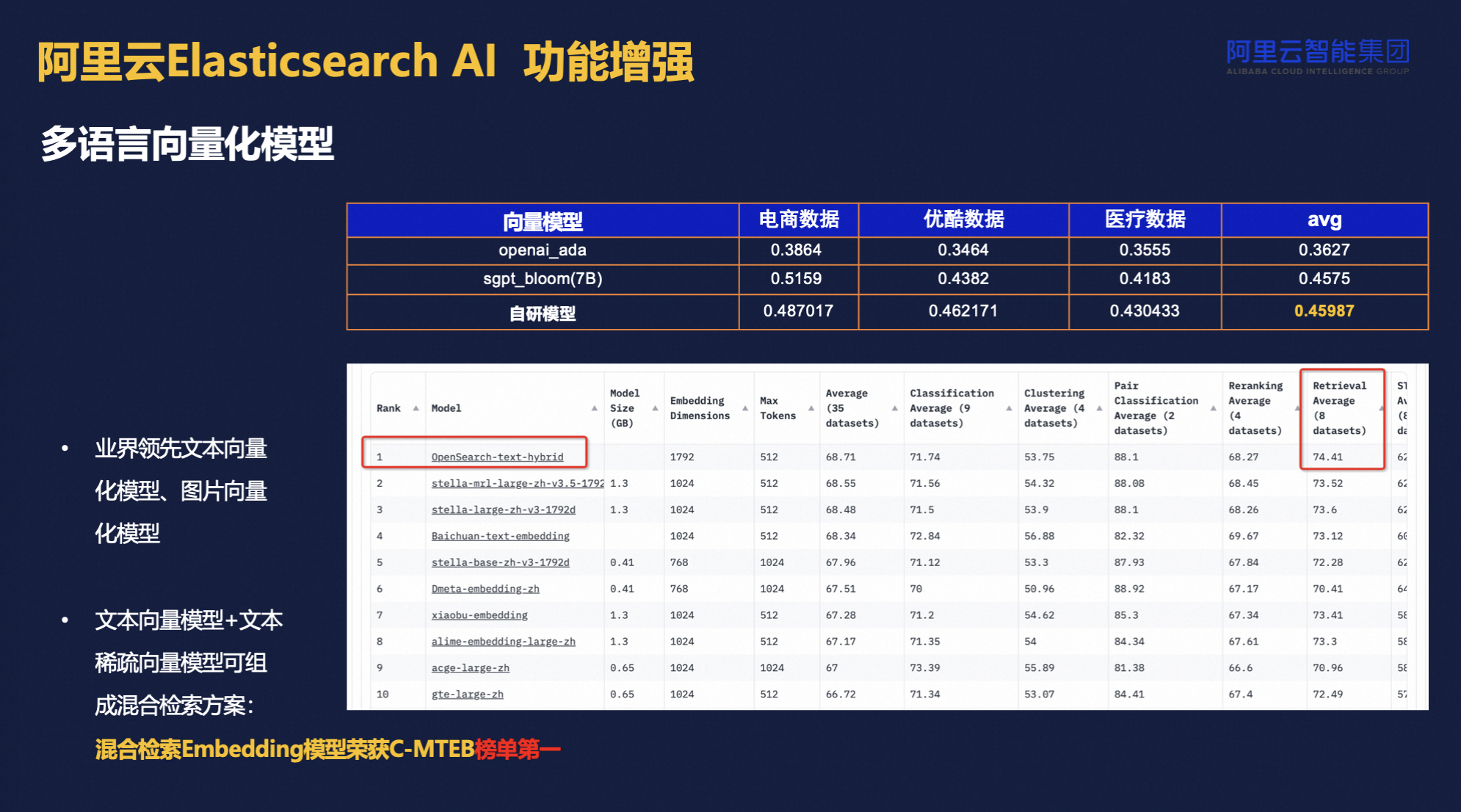
而向量化模型经过我们团队的持续调优,在相关评测中表现出色,用户可通过API直接调用,简化文本预处理流程。
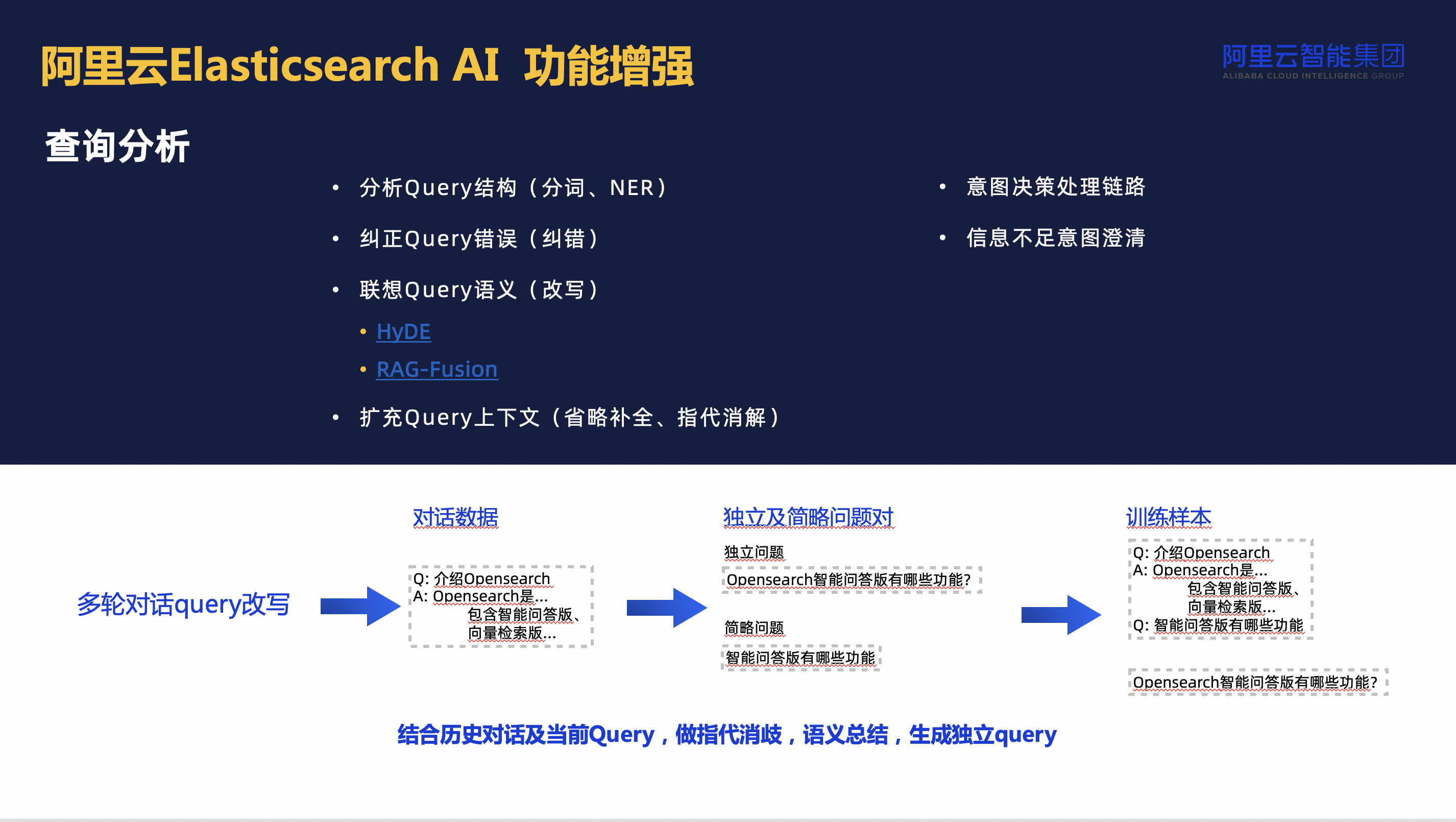
查询分析模块则增强了对用户查询意图的理解,优化查询指令后,能更精准地在引擎中检索相关信息。
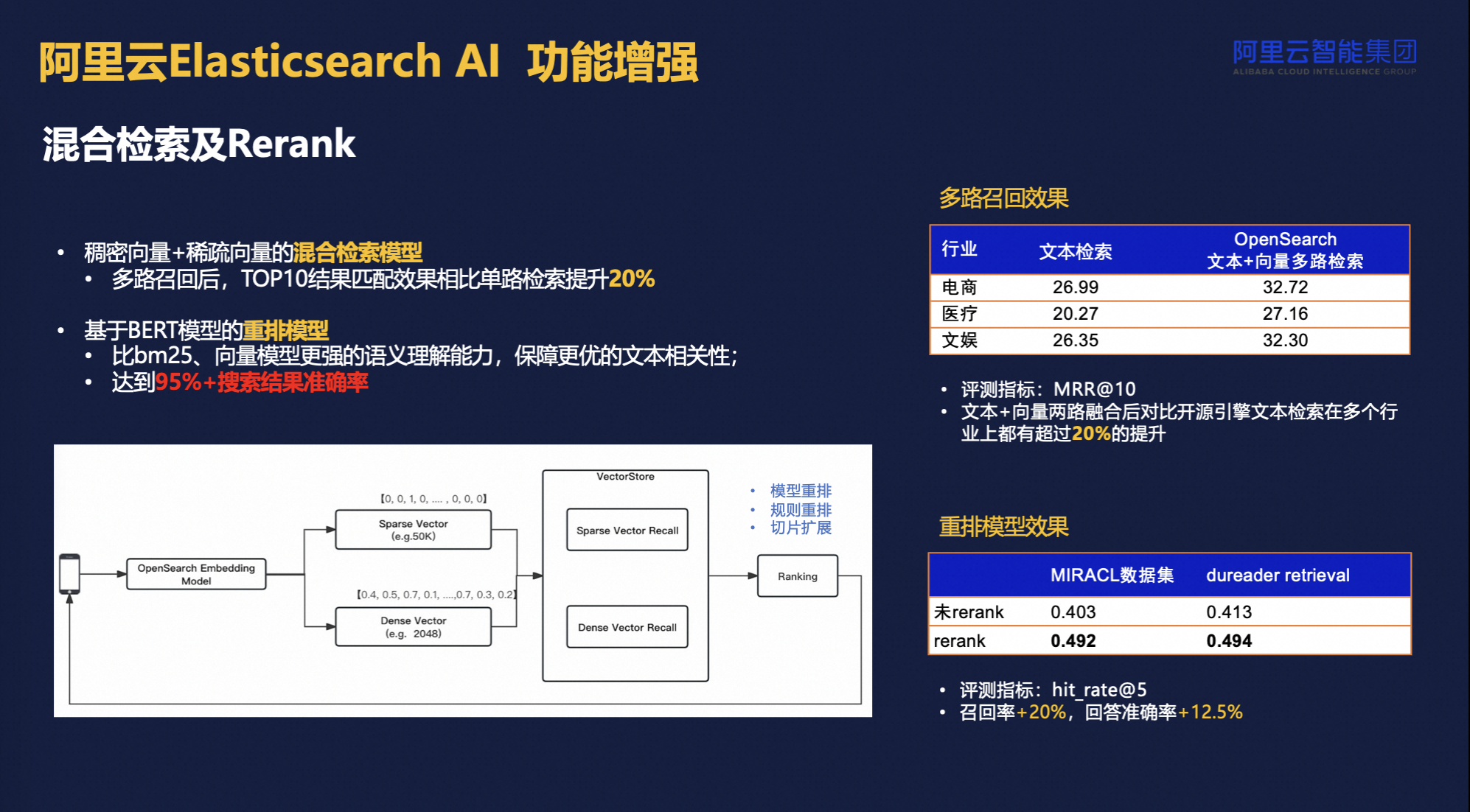
然后这是一个rerank的模型,经过混合检索之后,可以再去调用rerank模型,可以让数据的排序的效果更好。可以看到经过rerank模型的重排后,回答准确率可以提高12.5%。
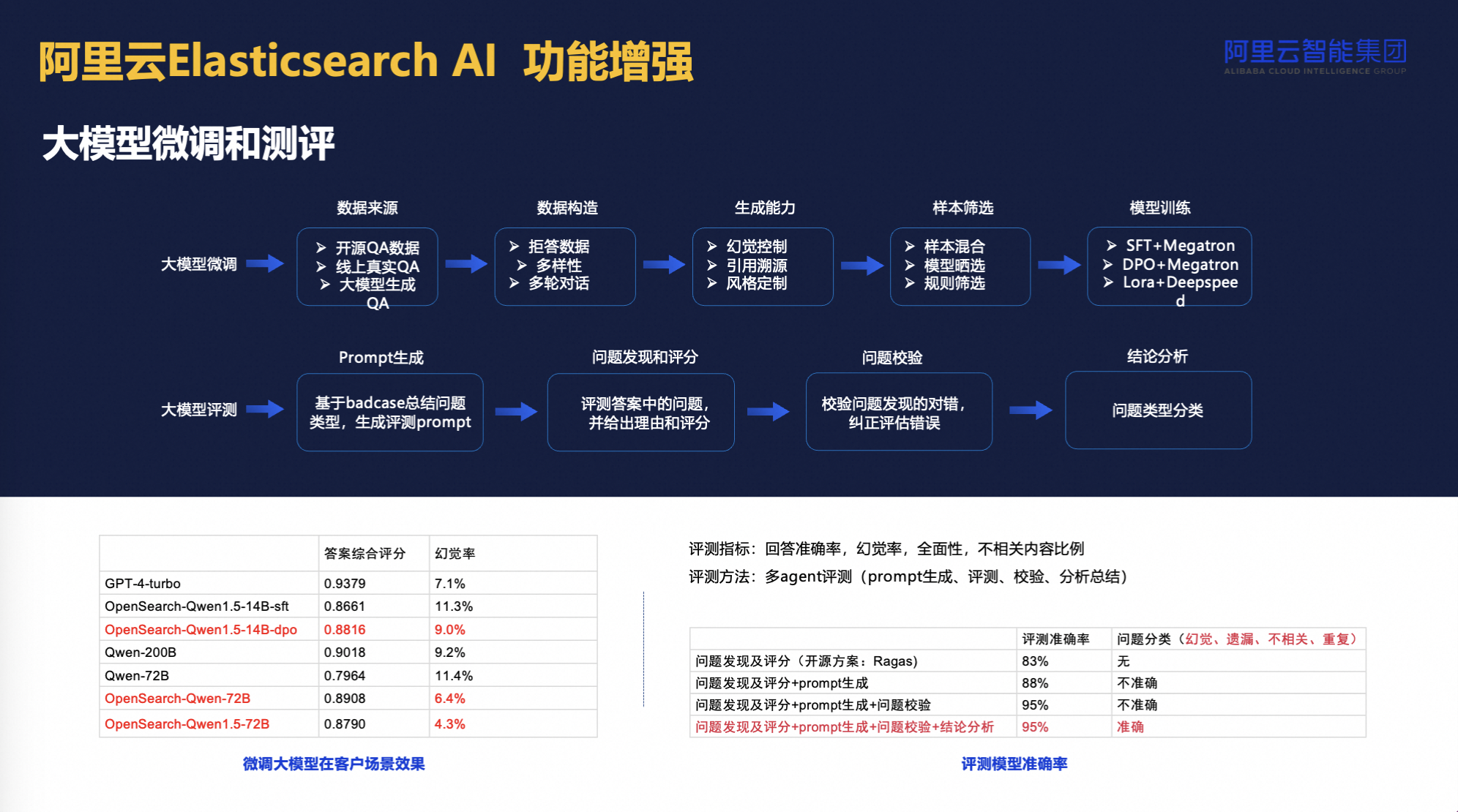
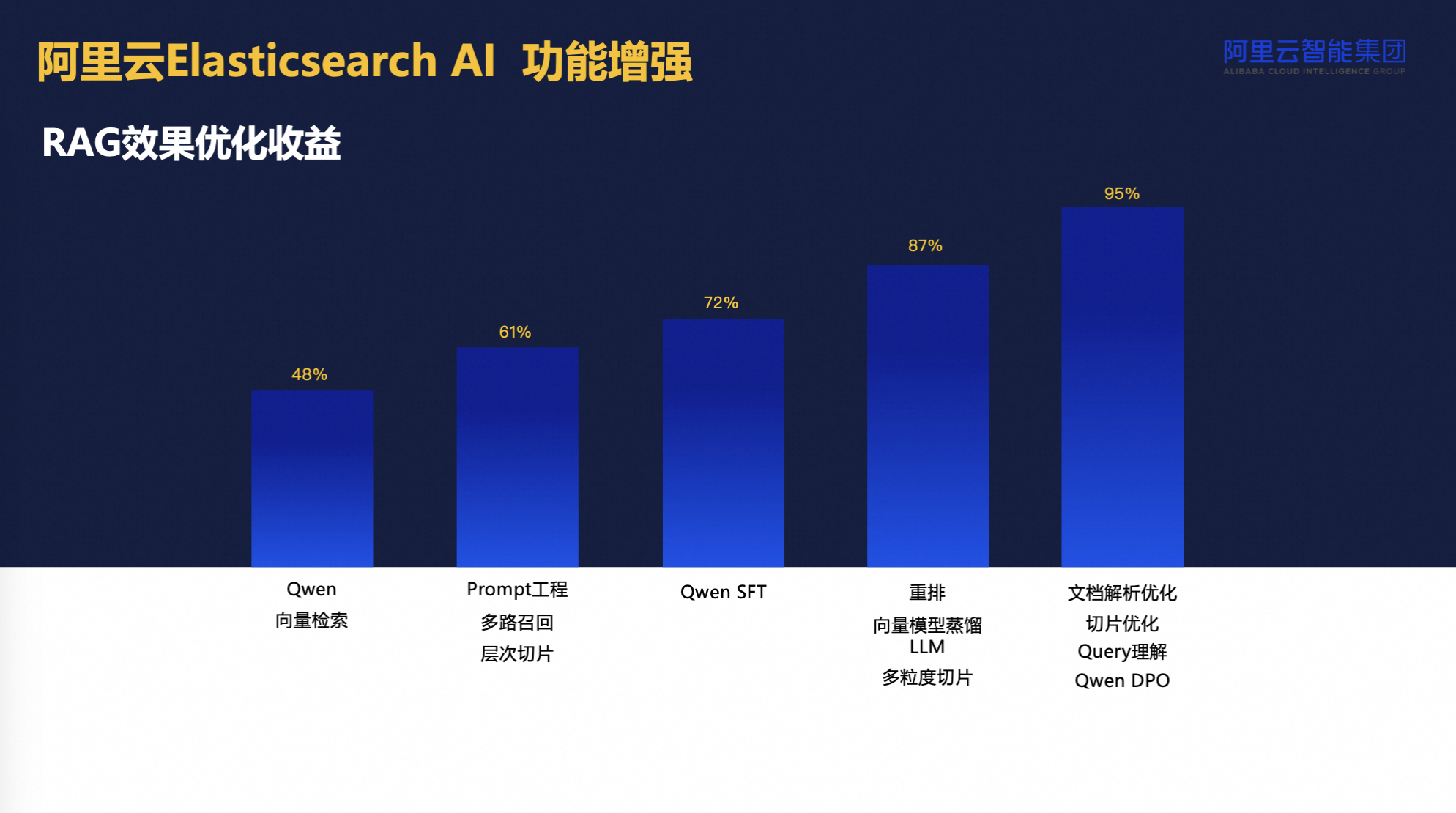
在AI搜索平台上,我们不仅提供了测评与模型微调工具,还集成了经微调的大模型,其在问题理解、生成内容的准确性上达到了95%的高水准。这一整套RAG体系,结合ES的原生功能,旨在为各类产品提供强大的搜索与分析能力,最终实现高达95%的效果提升,显著增强了用户的搜索体验与成果质量。
阿里云搜索开发工作台面向企业及开发者提供先进的AI搜索开发平台,内置实践打磨的多模态数据解析、文档切分、文本向量、查询分析、大模型文本生成、效果测评等丰富的组件化服务以及开发模版,同时,可选多种引擎能力,用户可灵活调用,实现智能搜索、检索增强生成(RAG)、多模态搜索等搜索相关场景的搭建。