1.为了调用写在其他包里面的类的方法 但是不使用new来实现调用这个类里面的方法,这个时候我们就需要将这个类注入到ioc容器里面,通过ioc容器来实现自动生成一个对象。
对ioc容器的理解:自动将一个对象实现new.

考察了and 和 or组合使用,需要注意的是or的运算符等级比and的等级低。
答案为:
sql
select device_id,gender,age,university,gpa from user_profile
where (gpa > 3.5 and university = "山东大学")
or (gpa > 3.8 and university = "复旦大学")
主要考察了 like的使用方法:我犯错的地方就是使用like之后应该在需要进行查找的时候加上%
sql
select device_id, age, university from user_profile
where university like "%北京%"
主要考察了where语句和"order"和"limit"的用法。
where的使用用法常常在限定数据的大小和等于什么,这种往往需要加在where的后面,然后像order和limit这种不需要加在where后面,应该放在最后表示查询的额外条件 ,而且order需要放在limit的后面
sql
select gpa from user_profile
where university = "复旦大学"
order by gpa desc
limit 1
主要考察了:avg的使用方法,和count的使用方法。
不能使用 count(gender) as male_num的方法,因为这个不可以进行计算,而是where来限制搜索的范围是在male来确定搜索的是男性,然后通过avg(gpa) as avg_male来算出得到的平均gpa。
sql
select count(*) as male_num ,avg(gpa) as avg_gpa from user_profile
where gender = "male"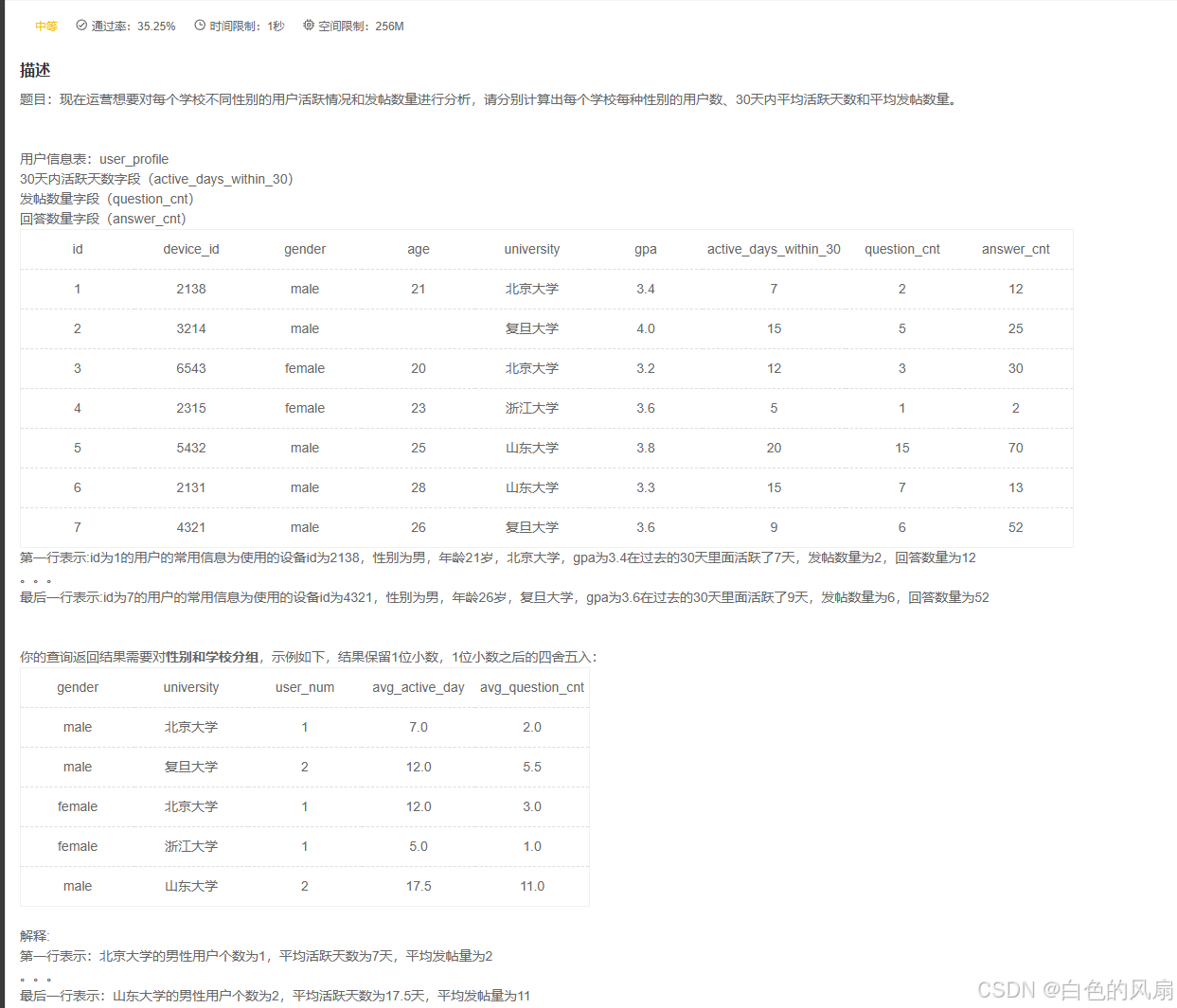
开始上强度了,这一题主要考察了,分组查询。
当使用group by关键字来进行查询的时候 后面进行分组的字段必须需要出现在select后面或者在聚合函数中。
何为聚合函数 就是count函数,avg函数等这种。
另外需要注意的是 编写代码时候的分段 需要保证格式是对的
sql
select
gender, university,
count(gender) as user_num,
avg(active_days_within_30) as avg_active_day,
avg(question_cnt) as avg_question_cnt
from user_profile
group by gender ,university描述
题目:现在运营想查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校进行重点运营,请取出平均发贴数低于5的学校或平均回帖数小于20的学校。
示例:user_profile
|----|-----------|--------|-----|------------|-----|-----------------------|--------------|------------|
| id | device_id | gender | age | university | gpa | active_days_within_30 | question_cnt | answer_cnt |
| 1 | 2138 | male | 21 | 北京大学 | 3.4 | 7 | 2 | 12 |
| 2 | 3214 | male | | 复旦大学 | 4.0 | 15 | 5 | 25 |
| 3 | 6543 | female | 20 | 北京大学 | 3.2 | 12 | 3 | 30 |
| 4 | 2315 | female | 23 | 浙江大学 | 3.6 | 5 | 1 | 2 |
| 5 | 5432 | male | 25 | 山东大学 | 3.8 | 20 | 15 | 70 |
| 6 | 2131 | male | 28 | 山东大学 | 3.3 | 15 | 7 | 13 |
| 7 | 4321 | female | 26 | 复旦大学 | 3.6 | 9 | 6 | 52 |
第一行表示:id为1的用户的常用信息为使用的设备id为2138,性别为男,年龄21岁,北京大学,gpa为3.4在过去的30天里面活跃了7天,发帖数量为2,回答数量为12
。。。
最后一行表示:id为7的用户的常用信息为使用的设备id为4321,性别为男,年龄26岁,复旦大学,gpa为3.6在过去的30天里面活跃了9天,发帖数量为6,回答数量为52
根据示例,你的查询应返回以下结果,请你保留3位小数(系统后台也会自动校正),3位之后四舍五入:
|------------|------------------|----------------|
| university | avg_question_cnt | avg_answer_cnt |
| 北京大学 | 2.5000 | 21.000 |
| 浙江大学 | 1.000 | 2.000 |
解释: 平均发贴数低于5的学校或平均回帖数小于20的学校有2个
属于北京大学的用户的平均发帖量为2.500,平均回答数量为21.000
属于浙江大学的用户的平均发帖量为1.000,平均回答数量为2.000
思路:对于聚合函数 ,它的限制条件不是 where 而是 having 。之前创建过的变量 可以在这里使用。
sql
select
university,
avg(question_cnt) as avg_question_cnt,
avg(answer_cnt) as avg_answer_cnt
from
user_profile
group by
university
having
avg_question_cnt < 5 or avg_answer_cnt <20描述
题目:现在运营想要查看不同大学的用户平均发帖情况,并期望结果按照平均发帖情况进行升序排列,请你取出相应数据。
示例:user_profile
|----|-----------|--------|-----|------------|-----|-----------------------|--------------|------------|
| id | device_id | gender | age | university | gpa | active_days_within_30 | question_cnt | answer_cnt |
| 1 | 2138 | male | 21 | 北京大学 | 3.4 | 7 | 2 | 12 |
| 2 | 3214 | male | | 复旦大学 | 4.0 | 15 | 5 | 25 |
| 3 | 6543 | female | 20 | 北京大学 | 3.2 | 12 | 3 | 30 |
| 4 | 2315 | female | 23 | 浙江大学 | 3.6 | 5 | 1 | 2 |
| 5 | 5432 | male | 25 | 山东大学 | 3.8 | 20 | 15 | 70 |
| 6 | 2131 | male | 28 | 山东大学 | 3.3 | 15 | 7 | 13 |
| 7 | 4321 | female | 26 | 复旦大学 | 3.6 | 9 | 6 | 52 |
第一行表示:id为1的用户的常用信息为使用的设备id为2138,性别为男,年龄21岁,北京大学,gpa为3.4在过去的30天里面活跃了7天,发帖数量为2,回答数量为12
。。。
最后一行表示:id为7的用户的常用信息为使用的设备id为4321,性别为男,年龄26岁,复旦大学,gpa为3.6在过去的30天里面活跃了9天,发帖数量为6,回答数量为52
根据示例,你的查询应返回以下结果:
|------------|------------------|
| university | avg_question_cnt |
| 浙江大学 | 1.0000 |
| 北京大学 | 2.5000 |
| 复旦大学 | 5.5000 |
| 山东大学 | 11.0000 |
order by 这个关键字和 having并不属于属从关系,所以可以单独使用order by。
另外需要注意的是 group by 这个关键字要写在order by前面