关于波克城市和作者
波克城市,一家专注于研发精品休闲游戏的全球化公司,连续七年入选中国互联网综合实力百强,2023 年位列 17 位。波克城市旗下拥有《捕鱼达人》《猫咪公寓2》等精品休闲游戏,全球注册用户超 5 亿,月活 6000 万,其中 70% 来源于海外,产品发行范围覆盖全球 200 多个国家和地区。
作者潘长江,波克大数据团队成员,自 2022 年起专注于图数据分析,其在风控和数据血缘管理等关键业务场景的应用实践,有效推动了业务的显著增长和效率提升。

一、业务背景
随着公司的持续发展和扩张,所涉及的项目日益增多,相应的数据积累也在持续上升。在这一过程中,数据表及其需要计算的数据指标数量也在急剧增加,数据结构变得愈加复杂和杂乱。
为了应对这一挑战,建立一个有效的数据血缘系统显得尤为必要。数据血缘系统能够追踪数据的来源、流向以及其间的变化过程,这对于维护数据质量、确保数据的可追溯性和透明性至关重要。通过构建数据血缘系统,我们能够实现对数据流转全过程的监控和管理,从而提高数据治理的效率和精确度。
-
数据血缘系统的建设有助于清晰地识别数据之间的依赖关系和影响范围。在数据出现问题时,可以快速定位问题源头,有效减少错误诊断和修复的时间,保证业务的连续性和数据的准确性。
-
数据血缘分析为数据管理提供了透明度,使得数据的利用更加合规,尤其是在遵守日益严格的数据保护法规(如 GDPR 或 CCPA)的背景下。
-
数据血缘系统通过详细记录数据的每一次处理和传输,增强了数据安全性,让我们能够对潜在的数据泄露和非授权访问进行有效预防。通过这种方式,数据血缘系统不仅提升了数据的可用性和可靠性,也增强了企业对数据资产的掌控能力,从而支撑了数据驱动决策的实施,提升了企业的竞争力。
二、技术选型
在深入的技术选型过程中,我们主要对比了两款领先的图数据库:Neo4j 和 NebulaGraph。两者都采用属性图数据模型,允许我们存储丰富的实体属性和关系信息。这种模型特别适合用于表现和查询复杂的数据关系,这是数据血缘追踪所必需的。
Neo4j 作为一款老牌图数据库,提供了强大的社区支持和成熟的技术生态,其查询语言 Cypher 也被广泛认可和使用。然而,Neo4j 在大规模数据处理和分布式扩展性方面存在一定的局限性。尽管最新的版本有所改进,但在面对极大规模数据时,其性能可能会受到影响。
相比之下,NebulaGraph 作为一款新兴的开源的分布式图数据库,展现出了在大规模数据集上的卓越性能。NebulaGraph 采用 shared-nothing 架构,提供了在线水平扩缩容的能力,这使得它在处理千亿节点和万亿条边的超大规模图时仍能保持低延迟的查询响应。
此外,NebulaGraph 的兼容性设计,如支持 openCypher 查询语言,使得在这方面的学习成本大大降低。
在综合考虑了性能、后续的扩展性、易用性以及成本效益之后,我们得出结论:NebulaGraph 更适合我们当前及未来的业务需求。
NebulaGraph 不仅在技术层面满足了我们对大规模图数据处理的需要,而且在成本控制和团队技能转移方面也显示出了明显的优势。
因此,我们选择 NebulaGraph 作为构建数据血缘系统的理想图数据库解决方案。
三、踩坑总结
Part.01 环境搭建阶段
问题:搭完环境尝试执行 insert 语句时报错:Error: Storage Error: RPC failure, probably timeout.
检查集群中各节点的状态,未发现任何异常


在每个节点上分别查看 NebulaGraph 的运行状态,发现有两个节点的服务没有正常启动。


进一步查看报错的执行日志,发现是接口被占用了,但 netstat 命令查看 占用接口的进程就是 Nebula。

解决方案:
手动终止进程,再重启 Nebula 服务,数据可以正常写入,并且各个节点状态正常。
因为我这个 Nebula 环境是卸载后重装的,推测是在卸载之前,原来的进程没有杀干净,导致占用了接口,新安装的无法正常启动。
NebulaGraph 一定要每个节点逐个关闭并卸载。
Part.02数据写入阶段
问题1:VID问题
在 NebulaGraph 中,点的唯一标识 VID,支持两种数据类型,分别是定长字符串 FIXED_STRING()和 INT64。其中整数 VID 通常比字符串类型更高效,因为整数的处理速度更快,占用空间更少。在本数据血缘项目中,由于是表级别的数据血缘,所以是库名+表名 唯一确定一张表,很明显这是字符串类型。
在测试环境下,由于预装了 Spark 环境,所以考虑借助 NebulaGraph 提供的 Spark 连接器完成数据写入。对于 VID 问题,由于希望实现幂等写入,因此不考虑雪花 ID 等实现方案,而是考虑借助 Java 中自带的 hashCode() 方法生成 VID。

上述方案在测试环境中能行得通,但是在正式环境下却无法实现,正式环境下并没有预装的 Spark 环境,因而在正式环境下,考虑使用 Python 连接器,拼接 insert 语句,批量将数据写入图库。最开始考虑与 Spark 环境下相同的方案生成 VID,但经测试发现,Python 中的生成 Hash ID 的方法多次执行,生成的 Hash ID 不一样(Python 3.3及以上版本引入了 hash 随机化机制)。
解决方案:
考虑仿照 Java 中 hashCode 的生成方式在 Python 中实现类似功能:
def hashCode(value):
h = 0
for c in value:
h = (31 * h + ord(c)) & 0xFFFFFFFF
return h if h < 0x80000000 else h - 0x100000000但执行上述代码发现,在 Python 中并没有类似 Java 中的截断机制,以上面生成的 ID 作为 VID 写入图库中时,会出现超出数据范围的错误。
最终,在正式环境下,将 VID 类型修改为定长字符串 FIXED_STRING(128),以 库名+表名的拼接作为 VID。

问题2:SQL拼接问题
使用拼接 insert 语句的方式进行数据写入时,最为关键的一环就是 SQL 语句的生成。在本系统中表的生成 SQL 将作为节点属性存入图库中,由于 SQL 中本身就会有一些特殊符号,如, " ' \ / $ 等等,这些特殊结构在 insert 语句的拼接过程中需要格外注意【PS:NebulaGraph 以后要是能多加一个 text 类型就好了,可以忽略字符串中本身存在的一些特殊格式,防止出现一些意外的错误】
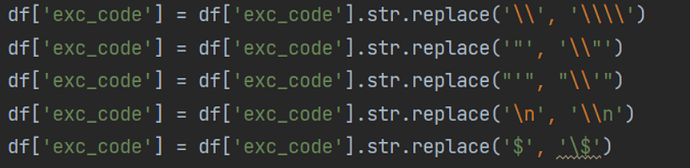
并且一些空值也要注意,Python 中的空值用 None 表示而在 NebulaGraph 则使用 NULL 表示,如果不进行转换,对于字符串类型的字段还是可以正常写入的,但是对于数字类型的则会报错。

一些特殊格式如 datetime 类型,不能以字符串格式直接写入,需要在写入时增加手动转换操作。

Part.03数据查询阶段
问题:后端反应图库查询速度慢
解决方案:增加针对常用查询字段的联合索引+优化查询语句,把多条查询压缩为一条查询。
最有效的优化方案 :增加针对常用查询字段的联合索引,增加之后查询速度提高了100多倍。
CREATE TAG INDEX IF NOT EXISTS database_index_0 on table_node(database_name(15), table_name(20));REBUILD TAG INDEX database_index_0;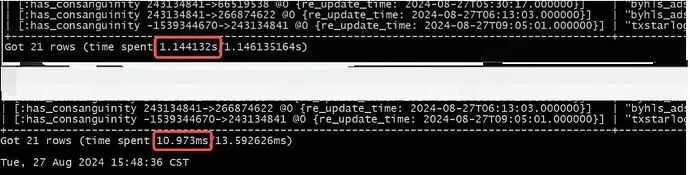
速度提升非常明显。
优化 nGQL 的写法,将多次查询优化为一条,如查询当前节点、当前节点的上游以及当前节点的下游,原来的三个查询可以压缩为一条查询,有效提高查询速度。
MATCH
// 查询指定节点及其属性
(n:table_node{database_name:"byhls_ods",table_name:"app_login_log"}) AS target_node,
// 查询该节点的所有上游节点(边的起始点)
(upstream:table_node)-[:has_consanguinity]->(n) AS upstream_nodes,
// 查询该节点的所有下游节点(边的终点)
(n)-[:has_consanguinity]->(downstream:table_node) AS downstream_nodes
RETURN
target_node.database_name AS database_name,
target_node.table_name AS table_name,
COLLECT(DISTINCT upstream) AS upstream_nodes,
COLLECT(DISTINCT downstream) AS downstream_nodes四、总结反思
目前项目处在起步阶段,很多功能还没有加,后续考虑应用 NebulaGraph 中自带的图计算功能,增加最优路径检索,核心度计算等功能,充分挖掘 NebulaGraph 的潜力。
✦
如果你觉得 NebulaGraph能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦