文章目录
- 论文总览
-
- [1. 创新点和突破点](#1. 创新点和突破点)
- [2. 技术实现与算法创新](#2. 技术实现与算法创新)
- [3. 架构升级](#3. 架构升级)
- [4. 概念补充](#4. 概念补充)
- [5. 总结](#5. 总结)
- Abstract
- Introduction
- Approach
-
- [Pre-training Data](#Pre-training Data)
- Architecture(架构)
- Optimizer(优化器)
- [Efficient implementation(高效实现)](#Efficient implementation(高效实现))
- 小结
- [Main results](#Main results)
-
- 零样本和小样本
- [Common Sense Reasoning (常识推理)](#Common Sense Reasoning (常识推理))
- [Closed-book Question Answering (闭卷问答)](#Closed-book Question Answering (闭卷问答))
- [Reading Comprehension (阅读理解)](#Reading Comprehension (阅读理解))
- [Mathematical Reasoning (数学推理)](#Mathematical Reasoning (数学推理))
- [Code Generation (代码生成)](#Code Generation (代码生成))
- [Massive Multitask Language Understanding (大规模多任务语言理解,MMLU)](#Massive Multitask Language Understanding (大规模多任务语言理解,MMLU))
- [Evolution of performance during training (性能随训练演变的表现)](#Evolution of performance during training (性能随训练演变的表现))
- 小结
- [Instruction Finetuning](#Instruction Finetuning)
- [Bias, Toxicity and Misinformation](#Bias, Toxicity and Misinformation)
- [Carbon Footprint](#Carbon Footprint)
- [Related Work](#Related Work)
- Conclusion
🍃作者介绍:双非本科大四网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发,目前开始人工智能领域相关知识的学习
🦅个人主页:@逐梦苍穹
📕所属专栏:🌩
专栏① :人工智能; 🌩专栏② :速通人工智能相关论文🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
论文总览
先总览一下这篇论文的创新点、突破点、技术实现、算法创新及架构升级,可以从以下几个方面进行详细分析。
1. 创新点和突破点
(1) 公开数据集的使用
- 创新 :LLaMA 模型的一个重要创新点是它完全基于公开数据集进行训练,而不是依赖任何专有或不可公开的数据。与 GPT-3、Chinchilla 和 PaLM 等其他大型语言模型不同,这些模型通常使用一些无法访问的专有数据集(例如社交媒体数据、付费的图书集等),而 LLaMA 则证明了只使用公开数据也能训练出与最先进模型竞争的基础模型。
- 突破:这种训练方式大大降低了模型训练的壁垒,增加了研究的透明性和可重复性,为研究界提供了一个可以共享和改进的基础。
(2) 小模型性能的突破
- 创新 :LLaMA-13B 模型虽然参数规模仅为 GPT-3 的十分之一,但在许多基准测试上表现超过了 GPT-3。作者证明了小模型也能通过适当的训练策略(如更多的数据和优化)实现与大模型相当甚至更好的性能。
- 突破:这表明不仅仅是模型规模决定了性能,训练过程中的优化和数据质量也是关键因素。这为模型的实际部署带来了更多可能性,因为小模型所需的计算资源远小于大模型,具有更高的应用性。
(3) 开源与资源共享
- 创新:LLaMA 的开源是该模型的另一个重要创新点。LLaMA 的开发者将不同参数规模的模型开放给研究社区(从7B到65B不等),使得研究人员可以直接利用这些模型,而无需从头开始训练大规模语言模型。
- 突破:这种资源的共享不仅有助于减少重复训练的碳排放(也有助于环境),还能够通过集体的努力进一步优化和改进模型,推动更广泛的语言模型研究。
2. 技术实现与算法创新
(1) Transformer架构的优化
- 实现:LLaMA 使用了经典的 Transformer 架构,但在多个方面进行了优化,例如预归一化(pre-normalization)、使用更高效的激活函数(SwiGLU),并引入了旋转位置嵌入(RoPE),替代了绝对位置嵌入。
- 创新:这些优化使得模型在处理长程依赖和训练稳定性方面得到了提升,同时提高了推理效率。尤其是 SwiGLU 激活函数,它比传统的 ReLU 函数在计算复杂任务时表现更好。
(2) 使用 AdamW 优化器
- 实现:LLaMA 使用了 AdamW 优化器,这在大型语言模型的训练中已经被证明是非常有效的。学习率的调度采用了余弦衰减,梯度裁剪设置为1.0,来保证模型的训练稳定性和效率。
- 创新:这种标准化的优化器及调度策略组合,通过合理控制学习率和梯度,保证了模型在不同数据规模和训练时间上的高效运行。
(3) 训练数据的处理与增强
- 实现:LLaMA 在预训练时使用了多种公开数据集,并且特别注重数据的去重和过滤,确保训练数据的多样性和质量。例如,CommonCrawl 数据集经过了详细的预处理,包括去重、语言识别和低质量内容过滤。
- 创新:这种细致的训练数据预处理策略,有效地提高了模型对噪声数据的鲁棒性,增强了其泛化能力。这在没有专有数据的情况下,是保证模型性能的关键。
3. 架构升级
(1) 高效的注意力机制
- 升级 :LLaMA 通过对自回归多头注意力机制的高效实现,减少了内存占用和计算成本。尤其是在训练和推理过程中,跳过了被掩盖的 key/query 计算,节省了大量计算资源。
- 创新:这种改进使得模型能够在处理长文本时表现得更加高效,同时减少了计算负担,适用于需要大量推理的任务场景。
(2) 模型规模的灵活性
- 升级:LLaMA 提供了从 7B 到 65B 不同规模的模型,适合不同的推理预算和计算能力。这种灵活性使得研究人员可以根据任务需求选择合适的模型,无需每次都使用超大规模的模型进行训练或推理。
- 创新:这种多规模模型的设计,为低资源环境或推理预算较低的场景提供了更多的选择,使得语言模型的应用场景更加广泛。
4. 概念补充
SwiGLU激活函数
SwiGLU(Swish-Gated Linear Unit)是一个结合了Swish激活函数 和 门控线性单元(GLU, Gated Linear Unit) 的激活函数。
在深度学习模型中,激活函数的作用是引入非线性,使得模型能够学习到更复杂的特征。
SwiGLU 是一种新的激活函数,它在 PaLM(Pathways Language Model)中首次提出,并被证明比传统的 ReLU 等激活函数在处理复杂任务时性能更好。
- SwiGLU的公式
SwiGLU 是由两个主要部分组成的,Swish 激活函数 和 GLU 门控机制。
它的公式如下: SwiGLU ( x ) = ( swish ( W 1 x ) ) ⋅ ( W 2 x ) \text{SwiGLU}(x) = (\text{swish}(W_1x)) \cdot (W_2x) SwiGLU(x)=(swish(W1x))⋅(W2x)
其中:
- W 1 W_1 W1和 W 2 W_2 W2是不同的权重矩阵。
- x x x是输入。
- Swish 激活函数 的表达式为: swish ( x ) = x ⋅ σ ( x ) \text{swish}(x) = x \cdot \sigma(x) swish(x)=x⋅σ(x)
其中, σ ( x ) \sigma(x) σ(x)是 Sigmoid 函数,即 σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1。
简而言之, SwiGLU 在执行计算时会对输入数据先通过一个 Swish 函数,然后再与另一个线性变换结果相乘。GLU 门控机制是用来控制哪些信息通过,哪些信息被屏蔽,从而提升模型的表现。
- SwiGLU 和 ReLU 的区别
- ReLU 激活函数 :
- 公式: ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)。
- 优点:计算简单,能够在很大程度上减轻梯度消失问题。
- 缺点:对于负值输入,ReLU直接输出0,这可能导致部分神经元"死亡"(即永远不会被激活)。
- SwiGLU 激活函数 :
- SwiGLU通过Swish函数引入了一种更平滑的非线性,并结合了GLU的门控机制,能够更好地选择和过滤信息。
- 相比ReLU,SwiGLU在处理复杂任务时可以更高效地捕捉到输入数据的特征,不会像ReLU那样截断负值,而是通过门控机制智能地过滤信息。
- SwiGLU 的优势
- 更平滑的非线性:与ReLU相比,Swish提供了更加平滑的非线性函数,特别是在负输入时,SwiGLU通过Swish激活函数不会直接将值变为0,而是保留了一定的信息。
- 提高信息筛选能力:GLU 门控机制可以自动控制哪些信息需要通过,哪些信息应该被屏蔽,从而使模型能更有效地学习到有用的特征。
- 计算效率提升:在PaLM模型的实验中,SwiGLU相比于ReLU和其他常见的激活函数,能够在更多的NLP任务中表现得更为优越。LLaMA 采用 SwiGLU 激活函数的目的是进一步提升模型在处理复杂任务时的计算效率和性能。
- 在LLaMA中的应用
LLaMA采用了SwiGLU来替代传统的ReLU激活函数,这样做的好处是:
- 提高了模型的非线性表示能力,特别是在复杂任务(例如长序列处理、跨任务泛化)上,能够更好地捕捉深层特征。
- Swish激活函数的平滑性可以使得梯度更加稳定,特别是在梯度消失问题上有更好的表现。
- GLU的门控机制则进一步增强了模型的选择性,使得模型能够自动决定哪些信息应该保留、哪些应该屏蔽。
在PaLM等模型中,SwiGLU已经证明了其优势,而LLaMA通过采用这一激活函数来提升模型的整体表现,尤其是在处理更大规模数据和更复杂任务时。
小结:
- SwiGLU 激活函数是 Swish 和 GLU 结合的结果,它相比传统的激活函数如 ReLU,提供了更平滑的非线性、门控机制以及更强的特征提取能力。
- 通过在LLaMA中应用SwiGLU,模型能够在处理复杂任务时表现更好,尤其是长程依赖和信息筛选的能力得到了极大提升。
AdamW
先放一张Adam的公式:

下面看看AdamW和Adam的区别
AdamW 通过将权重衰减与梯度更新解耦,解决了Adam在权重衰减方面的缺陷。它将权重衰减独立处理,而不再作为Adam优化器更新的一部分。这使得模型在参数更新时可以保持更高的稳定性,并且防止过拟合。
AdamW的参数更新公式如下:
- 动量和二阶矩的计算 (与Adam相同):
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2 - 参数更新 :
θ t = θ t − 1 − η ( m t ^ v t ^ + ϵ + λ θ t − 1 ) \theta_t = \theta_{t-1} - \eta \left(\frac{\hat{m_t}}{\sqrt{\hat{v_t}} + \epsilon} + \lambda \theta_{t-1}\right) θt=θt−1−η(vt^ +ϵmt^+λθt−1)
其中:
- m t ^ v t ^ + ϵ \frac{\hat{m_t}}{\sqrt{\hat{v_t}} + \epsilon} vt^ +ϵmt^是Adam的梯度更新部分。
- λ θ t − 1 \lambda \theta_{t-1} λθt−1是独立的权重衰减项,与梯度更新无关。
通过这种方式,AdamW能够更好地控制权重衰减,防止模型过拟合,而不影响优化器的动量和自适应学习率更新。
5. 总结
LLaMA 的主要创新点在于:
- 通过公开数据集训练出与最先进模型竞争的语言模型,减少了研究的资源和成本壁垒。
- 展示了小规模模型在适当优化和训练条件下可以超越大规模模型,打破了"规模决定性能"的传统观点。
- 通过开源模型,推动了研究的透明性、可复现性和集体优化的可能性。
技术上,LLaMA 的突破主要体现在:对 Transformer 架构的优化,数据预处理的高效策略,以及使用标准化的优化器和训练流程。同时,通过对不同规模模型的设计,使得其应用场景更具弹性和灵活性。
总体来看,LLaMA 展现了在资源受限的条件下,如何通过技术优化、开源共享和高效训练来推动大型语言模型的发展。
下面进入论文每一个部分的详细拆分讲解!
Abstract
论点拆分:
- LLaMA 模型的引入
- 观点:LLaMA 是一组从 7B 到 65B 参数的基础语言模型。这些模型展示了通过仅使用公开可用的数据集,可以训练出性能卓越的模型。
- 论文原文 :"We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters."
- LLaMA-13B 超越 GPT-3
- 观点:尽管 GPT-3 拥有 175B 的参数,但 LLaMA-13B 在大多数基准测试中表现更好。而 LLaMA-65B 在表现上与当前最好的模型 Chinchilla-70B 和 PaLM-540B 竞争力相当。
- 论文原文 :"LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B."
- 使用公开数据集
- 观点 :作者仅使用公开可用的数据集训练 LLaMA 模型,而不依赖任何专有或无法获取的数据。这使得 LLaMA 与其他模型相比,更加开放并且兼容开源。
- 论文原文 :"We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets."
- 开放模型供研究社区使用
- 观点:所有 LLaMA 模型都已经向研究社区开放,这将有助于推动大型语言模型的研究与开发。
- 论文原文 :"We release all our models to the research community."
小结:
LLaMA 是 Meta AI 推出的开源基础语言模型,参数范围从 7B 到 65B。该模型不使用专有数据,LLaMA-13B 在大多数基准上超越了 GPT-3。所有模型都已开放,旨在推动大型语言模型的研究。
Introduction
论点拆分:
- 大规模语言模型 (LLMs) 的发展与性能
- 观点 :LLMs 在海量文本上进行训练,已经表现出在新任务上的出色性能,尤其是在少量示例或指令的情况下。这种性能提升首次出现在模型规模扩大时,随后推动了进一步扩展模型规模的研究。然而,最近的研究表明,在相同计算预算下,性能最佳的不是最大的模型,而是那些较小但训练更多数据的模型。
- 论文原文:
- "Large Languages Models (LLMs) trained on massive corpora of texts have shown their ability to perform new tasks from textual instructions or from a few examples Brown et al."在大量文本语料库上训练的大型语言模型( LLMs )已经显示出它们根据文本指令或布朗等人的一些例子执行新任务的能力。
- "At the higher-end of the scale, our 65B-parameter model is also competitive with the best large language models such as Chinchilla or PaLM-540B."在规模的高端,我们的 65B 参数模型也可以与最好的大型语言模型(例如 Chinchilla 或 PaLM-540B)竞争。
- "( 2022) shows that, for a given compute budget, the best performances are not achieved by the largest models, but by smaller models trained on more data."
- 推理预算的关键性
- 观点:推理预算,即模型在推理时的计算成本,在部署大规模语言模型时至关重要。虽然大模型可能更快达到某一性能水平,但在推理时较小的模型训练时间更长,最终更具成本效益。
- 论文原文: " In this context, given a target level of performance, the preferred model is not the fastest to train but the fastest at inference, and although it may be cheaper to train a large model to reach a certain level of performance, a smaller one trained longer will ultimately be cheaper at inference."
- LLaMA模型的设计目标
- 观点:该论文的目标是训练一系列语言模型,在不同的推理预算下实现最佳性能。这些模型参数从7B到65B不等,具有与现有最好的LLMs竞争的性能,且LLaMA-13B在大多数基准上超越了GPT-3,尽管其参数规模只有GPT-3的十分之一。
- 论文原文 :"The focus of this work is to train a series of language models that achieve the best possible performance at various inference budgets, by training on more tokens than what is typically used. The resulting models, called LLaMA, ranges from 7B to 65B parameters with competitive performance compared to the best existing LLMs. For instance, LLaMA-13B outperforms GPT-3 on most benchmarks, despite being 10× smaller."这项工作的重点是训练一系列语言模型,通过训练比通常使用的标记更多的标记,在各种推理预算下实现最佳性能。 由此产生的模型称为LLaMA ,参数范围从 7B 到 65B,与现有最好的LLMs相比,其性能具有竞争力。 例如,LLaMA-13B 在大多数基准测试中都优于 GPT-3,尽管是 10 × 较小。
- 数据集的透明性和公开性
- 观点:与其他大型模型不同,LLaMA只使用公开的数据集进行训练,确保了与开源的兼容性。而其他许多模型依赖于无法获取的专有数据,如图书和社交媒体对话数据。
- 论文原文 :"Unlike Chinchilla, PaLM, or GPT-3, we only use publicly available data, making our work compatible with open-sourcing, while most existing models rely on data which is either not publicly available or undocumented."
小结:
这一部分介绍了大型语言模型的性能改进与LLaMA的设计目标,强调推理预算和公开数据集的重要性。通过训练参数范围在7B到65B的模型,LLaMA展示了在不使用专有数据的情况下也能达到先进的性能。
Approach
Pre-training Data
- 训练方法的基础
- 观点:LLaMA的训练方法与之前的工作类似,使用了大规模的transformer模型,并基于Chinchilla的缩放规律。训练时采用标准的优化器来处理大量的文本数据。
- 论文原文: "Our training approach is similar to the methods described in previous work Brown et al. ( 2020); Chowdhery et al. ( 2022), and is inspired by the Chinchilla scaling laws Hoffmann et al. ( 2022). We train large transformers on a large quantity of textual data using a standard optimizer."我们的训练方法类似于Brown 等人之前的工作中描述的方法。 ( 2020 );乔杜里等人。 ( 2022 ) ,受到Hoffmann 等人的 Chinchilla 缩放定律的启发。 ( 2022 ) 。我们使用标准优化器在大量文本数据上训练大型transformers。
- 预训练数据
- 观点:LLaMA模型的预训练数据集由多个公开可用的来源组成,这些数据覆盖了广泛的领域。所有数据源均为开源,以确保数据透明性和兼容性。
- 论文原文 :"Our training dataset is a mixture of several sources, reported in Table 1, that cover a diverse set of domains. For the most part, we reuse data sources that have been leveraged to train other LLMs, with the restriction of only using data that is publicly available, and compatible with open sourcing."
- 表1:
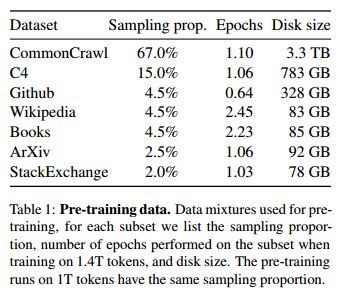
- 表1:预训练数据。用于预训练的数据混合,对于每个子集,我们列出了采样比例,在1.4T令牌上训练时在子集上执行的epoch数以及磁盘大小。在1T令牌上的预训练运行具有相同的采样比例
- 数据来源与比例
- 观点:主要的预训练数据来源包括English CommonCrawl(67%)、C4数据集(15%)、GitHub代码数据(4.5%)和Wikipedia(4.5%)。CommonCrawl数据集经过了去重和语言识别等预处理。
- 论文原文: "English CommonCrawl 67%. ""We preprocess five CommonCrawl dumps, ranging from 2017 to 2020, with the CCNet pipeline Wenzek et al. ( 2020). This process deduplicates the data at the line level, performs language identification with a fastText linear classifier to remove non-English pages and filters low quality content with an n-gram language model."
- C4 数据集的使用
- 观点:LLaMA团队还加入了C4数据集,该数据集的预处理过程与CommonCrawl类似,包含去重和语言识别步骤。C4的主要区别在于它的质量过滤方法,使用启发式规则来移除低质量内容。
- 论文原文: "During exploratory experiments, we observed that using diverse pre-processed CommonCrawl datasets improves performance. We thus included the publicly available C4 dataset (Raffel et al., 2020 ) in our data. The preprocessing of C4 also contains deduplication and language identification steps: the main difference with CCNet is the quality filtering, which mostly relies on heuristics such as presence of punctuation marks or the number of words and sentences in a webpage."在探索性实验中,我们观察到使用不同的预处理 CommonCrawl 数据集可以提高性能。因此,我们将公开可用的 C4 数据集(Raffel 等人, 2020 )纳入我们的数据中。 C4的预处理还包含 重复数据删除和语言识别步骤:与CCNet的主要区别在于质量过滤,其主要依赖于启发式方法,例如标点符号的存在或网页中的单词和句子的数量。
- GitHub 和 Wikipedia 数据的贡献
- 观点:GitHub数据(4.5%)主要来自公开项目,经过了质量过滤,并移除了重复内容。Wikipedia数据也占总数据的4.5%,主要使用了2022年6月至8月的维基百科快照。
- 论文原文: "We use the public GitHub dataset available on Google BigQuery. We only kept projects that are distributed under the Apache, BSD and MIT licenses. Additionally, we filtered low quality files with heuristics based on the line length or proportion of alphanumeric characters, and removed boilerplate, such as headers, with regular expressions."我们使用 Google BigQuery 上提供的公共 GitHub 数据集。我们只保留在 Apache、BSD 和 MIT 许可证下分发的项目。此外,我们根据行长度或字母数字字符的比例使用启发式过滤低质量文件,并使用正则表达式删除样板文件,例如标题。
- "We add Wikipedia dumps from the June-August 2022 period"我们添加了 2022 年 6 月至 8 月期间的维基百科转储
- 古腾堡和书籍3 4.5%。 我们将两个书本语料库纳入训练数据集:古腾堡项目,包含公共领域内的书籍;以及《堆栈》(Gao et al., 2020)中的书籍3部分,这是一个可用于训练大型语言模型的公开可用数据集。我们在书本级别进行去重,删除内容重叠度超过90%的书籍。"Gutenberg and Books3 4.5%. We include two book corpora in our training dataset: the Gutenberg Project, which contains books that are in the public domain, and the Books3 section of ThePile (Gao et al., 2020), a publicly available dataset for training large language models. We perform deduplication at the book level, removing books with more than 90% content overlap."
- arXiv 2.5%。 我们处理arXiv Latex文件,将科学数据添加到我们的数据集中。我们遵循Lewkowycz等人(2022)的做法,从每个文件中删除除第一个部分之外的所有内容,以及参考文献。我们还从.tex文件中删除注释,并对用户编写的内联扩展定义和宏进行标准化,以提高文档之间的一致性。ArXiv 2.5%. We process arXiv Latex files to add scientific data to our dataset. Following Lewkowycz et al. (2022), we removed everything before the first section, as well as the bibliography. We also removed the comments from the .tex files, and inline-expanded definitions and macros written by users to increase consistency across papers.
- Stack Exchange 2%。 我们包括Stack Exchange的一份数据集,这是一个包含高质量问题和答案的网站,涵盖了从计算机科学到化学等众多领域。我们保留了28个最大网站的数据,从文本中删除HTML标签,并按得分(从最高到最低)对答案进行排序。Stack Exchange 2%. We include a dump of Stack Exchange, a website of high quality questions and answers that covers a diverse set of domains, ranging from computer science to chemistry. We kept the data from the 28 largest websites, removed the HTML tags from text and sorted the answers by score (from highest to lowest).
- 分词器。 我们使用字节对齐编码(BPE)算法(Sennrich et al我们使用SentencePiece(Kudo和Richardson,2018)的实现,并将所有数字拆分为单独的数字,并在无法分解未知UTF-8字符时,转而使用字节进行分解。(2015年)Tokenizer. We tokenize the data with the bytepair encoding (BPE) algorithm (Sennrich et al., 2015), using the implementation from SentencePiece (Kudo and Richardson, 2018). Notably, we split all numbers into individual digits, and fallback to bytes to decompose unknown UTF-8 characters.
Architecture(架构)
- 架构基础
LLaMA 模型基于transformer架构,并结合了多个近年来提出的改进;
如 GPT-3 中使用的预归一化和PaLM 中的SwiGLU 激活函数。
该模型使用自我注意力机制来处理上下文信息。
- 预归一化(Pre-normalization)
- 观点:为了提高训练稳定性,LLaMA在每个transformer子层的输入上进行归一化,而不是像传统方式那样对输出进行归一化。归一化函数采用了RMSNorm。
- 论文原文 :"To improve the training stability, we normalize the input of each transformer sub-layer, instead of normalizing the output. We use the RMSNorm normalizing function, introduced by Zhang and Sennrich (2019)."
- SwiGLU 激活函数
- 观点 :LLaMA采用 SwiGLU激活函数替代ReLU ,以提升模型性能。这种激活函数在PaLM模型中首次提出,证明效果优越。
- 论文原文 :"We replace the ReLU non-linearity by the SwiGLU activation function, introduced by Shazeer (2020) to improve the performance."为了提高性能,我们用Shazeer(2020)引入的SwiGLU激活函数取代了ReLU非线性。
- 旋转嵌入(Rotary Embeddings)
- 观点:LLaMA去除了绝对位置嵌入,采用了RoPE旋转位置嵌入。这种方法更好地处理了位置编码问题。
- 论文原文 :"We remove the absolute positional embeddings, and instead, add rotary positional embeddings (RoPE), introduced by Su et al. (2021), at each layer of the network."我们删除了绝对位置嵌入,取而代之的是在网络的每一层添加由Su等人(2021)引入的旋转位置嵌入(RoPE)。
Optimizer(优化器)
- AdamW优化器
- 观点 :LLaMA使用 AdamW 优化器进行训练,并通过学习率余弦调度策略来控制训练过程中的学习率。此外,权重衰减和梯度剪裁也被用于确保训练的稳定性。
- 论文原文 :"Our models are trained using the AdamW optimizer (Loshchilov and Hutter, 2017), with the following hyper-parameters: β1 = 0:9; β2 = 0:95. We use a cosine learning rate schedule, such that the final learning rate is equal to 10% of the maximal learning rate."我们的模型使用AdamW优化器(Loshchilov and Hutter, 2017)进行训练,具有以下超参数:β1 = 0:9;β2 = 0:95。我们使用 余弦学习率调度 ,使得最终学习率等于最大学习率的10%。
- 梯度剪裁与权重衰减
- 观点 :为了防止梯度爆炸,LLaMA采用了梯度剪裁,并将剪裁值设置为1.0。与此同时,权重衰减设置为0.1,进一步控制模型的参数更新。
- 论文原文 :"We use a weight decay of 0.1 and gradient clipping of 1.0."
Efficient implementation(高效实现)
- 高效自回归注意力
- 观点:LLaMA对自回归多头注意力机制进行了高效实现,减少了内存占用和运行时间。通过不存储注意力权重,以及跳过被掩盖的key/query计算,节省了大量计算资源。
- 论文原文 :
- "we use an efficient implementation of the causal multi-head attention to reduce memory usage and runtime."我们使用因果多头注意的有效实现来减少内存使用和运行时间。
- "This is achieved by not storing the attention weights and not computing the key/query scores that are masked due to the causal nature of the language modeling task."这是通过不存储注意力权重和不计算由于语言建模任务的因果性质而被掩盖的键/查询分数来实现的。
- 检查点技术与并行化
- 观点:LLaMA通过检查点技术减少反向传播过程中需要重新计算的激活量,并手动实现反向传播函数以进一步优化内存和计算效率。
- 论文原文 :"To further improve training efficiency, we reduced the amount of activations that are recomputed during the backward pass with checkpointing. More precisely, we save the activations that are expensive to compute, such as the outputs of linear layers. This is achieved by manually implementing the backward function for the transformer layers, instead of relying on the PyTorch autograd."为了进一步提高训练效率,我们通过检查点减少了在向后传递过程中重新计算的激活量。更准确地说,我们节省了计算成本高的激活,比如线性层的输出。这是通过 手动实现transformer层的backward函数 来实现的,而不是依赖于PyTorch的autograd。
小结
- "Approach"部分详细讨论了LLaMA的架构设计、优化方法和高效实现,强调了基于Chinchilla缩放规律的训练策略。
- 他们使用了多种公开的预训练数据集,包括CommonCrawl、C4、GitHub和Wikipedia,确保了数据透明性与开源的兼容性.该模型基于transformer架构,结合了多种新颖的优化技术,如SwiGLU激活函数、RoPE嵌入和AdamW优化器。
- 通过高效的内存管理和计算策略,LLaMA在推理和训练中实现了较高的性能。
Main results
零样本和小样本
图中这部分主要分为以下几个方面:
- 零样本 (Zero-shot) 与小样本 (Few-shot) 任务
- 观点:LLaMA 模型被评估了在零样本和小样本任务上的表现,报告显示在20个基准任务上进行测试。零样本任务中,模型只提供了任务描述并生成答案;小样本任务则为模型提供了少量示例,数量从1到64个不等。
- 论文原文 :
- "We provide a textual description of the task and a test example. The model either provides an answer using open-ended generation, or ranks the proposed answers."我们提供了任务的文本描述和测试示例。该模型要么使用开放式生成提供答案,要么对建议的答案进行排序。
- "We provide a few examples of the task (between 1 and 64) and a test example. The model takes this text as input and generates the answer or ranks different options."我们提供了该任务的几个示例(在1到64之间)和一个测试示例。该模型将此文本作为输入,并生成答案或对不同选项进行排序。
- 与其他模型的比较
- 观点:LLaMA 模型与 GPT-3、Gopher、Chinchilla、PaLM 等大型语言模型在零样本和小样本任务上进行了对比。LLaMA-13B 在参数数量远少于 GPT-3 的情况下,在多数任务上表现优异,尤其是小样本任务中表现更为突出。
- 论文原文 :"We compare LLaMA with other foundation models, namely the non-publicly available language models GPT-3 (Brown et al., 2020), Gopher (Rae et al., 2021), Chinchilla (Hoffmann et al., 2022) and PaLM (Chowdhery et al., 2022), as well as the open-sourced OPT models (Zhang et al., 2022), GPT-J (Wang and Komatsuzaki, 2021), and GPTNeo (Black et al., 2022)."我们将LLaMA与其他基础模型进行比较,即非公开语言模型GPT-3 (Brown等人,2020)、Gopher (Rae等人,2021)、Chinchilla (Hoffmann等人,2022)和PaLM (Chowdhery等人,2022),以及开源的OPT模型(Zhang等人,2022)、GPT-J (Wang和Komatsuzaki, 2021)和GPTNeo (Black等人,2022)。
- 零样本与小样本的表现比较
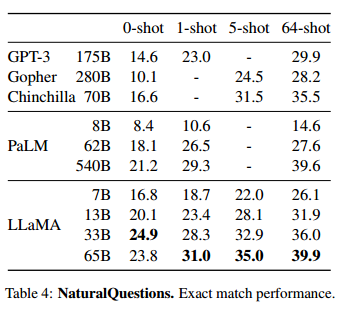
- 表格内容解读:表格显示了不同模型在 Natural Questions 数据集上的准确匹配表现。在零样本、1-shot、5-shot 和 64-shot 设置下,LLaMA 的表现逐步提升。尤其是 LLaMA-65B,在64-shot 设置下的表现接近了40%,超过了 PaLM 540B。
- 论文原文 :"We evaluate LLaMA on free-form generation tasks and multiple choice tasks. In the multiple choice tasks, the objective is to select the most appropriate completion among a set of given options, based on a provided context"我们在自由格式生成任务和多项选择任务上评估了LLaMA。在多项选择题中,目标是根据给定的上下文,从一组给定的选项中选择最合适的完成方式
- 表格解读 :
- GPT-3 175B 在 0-shot 时表现为 14.6%,在 64-shot 时提升到 29.9%;
- LLaMA-65B 在 0-shot 时表现为 23.8%,而在 64-shot 时提升到 39.9%,超越了 PaLM 和 GPT-3 的同等规模。
这部分总结了 LLaMA 模型在零样本和小样本任务中的表现。通过对多个基础模型的比较,LLaMA 在小样本任务中表现尤为突出,尤其是 LLaMA-65B 在 Natural Questions 数据集上达到了最先进的表现,与 PaLM-540B 和 GPT-3 等大规模模型相比具有明显优势。
Common Sense Reasoning (常识推理)
- 常识推理任务概述
- 观点:LLaMA 模型在常识推理任务上表现卓越,测试数据集包括 BoolQ、PIQA、SIQA、HellaSwag 和 WinoGrande 等。这些数据集评估了模型在零样本设置下理解并推理常识的能力。
- 论文原文 :"We consider eight standard common sense reasoning benchmarks: BoolQ (Clark et al., 2019), PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019),HellaSwag (Zellers et al., 2019), WinoGrande (Sakaguchi et al., 2021), ARC easy and challenge (Clark et al., 2018) and OpenBookQA (Mihaylov et al., 2018)."我们考虑了8个标准的常识推理基准:BoolQ (Clark等人,2019)、PIQA (Bisk等人,2020)、SIQA (Sap等人,2019)、HellaSwag (Zellers等人,2019)、WinoGrande (Sakaguchi等人,2021)、ARC easy and challenge (Clark等人,2018)和OpenBookQA (Mihaylov等人,2018)。
- LLaMA 在常识推理中的性能
- 观点 :LLaMA-65B 模型在常识推理基准测试中表现超越了 Chinchilla-70B,仅在 BoolQ 和 WinoGrande 两个数据集上略有不足。LLaMA-13B 尽管参数少,却也在多数任务上超过了 GPT-3。
- 论文原文 :"LLaMA-65B outperforms Chinchilla-70B on all reported benchmarks but BoolQ. LLaMA-13B model also outperforms GPT-3 on most benchmarks despite being 10× smaller."LLaMA-65B在除BoolQ以外的所有基准测试中都优于Chinchilla-70B。LLaMA-13B模型在大多数基准测试中也优于GPT-3,尽管体积小了10倍。
Closed-book Question Answering (闭卷问答)
- 闭卷问答任务概述
- 观点:闭卷问答任务要求模型在没有外部文档支持的情况下回答问题。LLaMA 参与的主要基准测试包括 Natural Questions 和 TriviaQA,这些任务要求模型准确地回答关于各种主题的问题。
- 论文原文 :"We compare LLaMA to existing large language models on two closed-book question answering benchmarks: Natural Questions and TriviaQA."
- LLaMA-65B 闭卷问答的最新性能
- 观点:LLaMA-65B 模型在闭卷问答任务中的表现达到了最先进水平,在零样本和小样本设置下均表现出色。LLaMA-13B 尽管体积小,但在多个任务上与 GPT-3 和 Chinchilla 竞争力相当。
- 论文原文 :"LLaMA-65B achieve state-of-the-art performance in the zero-shot and few-shot settings. More importantly, the LLaMA-13B is also competitive on these benchmarks with GPT-3 and Chinchilla, despite being 5-10× smaller."
Reading Comprehension (阅读理解)
- 阅读理解任务概述
- 观点:LLaMA 模型在阅读理解任务中的表现通过 RACE 基准测试进行评估。RACE 数据集测试模型在阅读理解方面的推理能力,数据集来源于中国中学和高中考试。
- 论文原文 :"We evaluate our models on the RACE reading comprehension benchmark. This dataset was collected from English reading comprehension exams designed for middle and high school Chinese students."
- LLaMA 模型在阅读理解任务中的表现
- 观点:LLaMA-65B 在 RACE 基准测试上表现接近 PaLM-540B,LLaMA-13B 也在此任务上超越了 GPT-3,展示了卓越的阅读理解和语言推理能力。
- 论文原文 :"On these benchmarks, LLaMA-65B is competitive with PaLM-540B, and, LLaMA-13B outperforms GPT-3 by a few percents."
Mathematical Reasoning (数学推理)
- 数学推理任务概述
- 观点 :LLaMA 模型在数学推理任务上进行了评估,主要使用的基准包括 MATH 和 GSM8k 数据集。MATH 数据集包含中学和高中的数学题目,GSM8k 则主要是小学水平的数学问题。
- 论文原文 :"We evaluate our models on two mathematical reasoning benchmarks: MATH (Hendrycks et al., 2021) and GSM8k (Cobbe et al., 2021). MATH is a dataset of 12K middle school and high school mathematics problems written in LaTeX. GSM8k is a set of middle school mathematical problems."我们在两个数学推理基准上评估我们的模型:MATH (Hendrycks等人,2021)和GSM8k (Cobbe等人,2021)。MATH是一个用LaTeX编写的12K初中和高中数学问题的数据集。GSM8k是一套中学数学习题。
- LLaMA 在数学推理中的表现
- 观点 :尽管 LLaMA 没有进行数学数据的微调,LLaMA-65B 在 GSM8k 数据集上的表现超过了经过数学微调的 Minerva-62B 模型,这展示了其在数学推理任务上的强大潜力。
- 论文原文 :"On GSM8k, we observe that LLaMA- 65B outperforms Minerva-62B, although it has not been fine-tuned on mathematical data."
Code Generation (代码生成)
- 代码生成任务概述
- 观点 :LLaMA 模型还在代码生成任务上进行了测试,基准包括 HumanEval 和 MBPP。模型通过自然语言描述生成 Python 代码,并基于输入输出示例进行验证。
- 论文原文 :"We evaluate the ability of our models to write code from a natural language description on two benchmarks: HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021)."我们在两个基准上评估了我们的模型根据自然语言描述编写代码的能力:HumanEval (Chen等人,2021)和MBPP (Austin等人,2021)。
- LLaMA 的代码生成能力
- 观点 :LLaMA 尤其是 13B 参数的模型,在代码生成任务中表现出色,甚至超过了 PaLM 和 LaMDA。这表明,尽管 LLaMA 并非为代码专门微调,但它在自然语言到代码的转换任务中表现出了较强的泛化能力。
- 论文原文 :"LLaMA with 13B parameters and more outperforms LaMDA 137B on both HumanEval and MBPP."具有13B及以上参数的LLaMA在HumanEval和MBPP上都优于LaMDA 137B。
Massive Multitask Language Understanding (大规模多任务语言理解,MMLU)
- MMLU任务概述
- 观点 :MMLU 测试了一系列多任务的语言理解能力,涵盖了人文、科学、社会科学等多个领域。测试采用 5-shot 设置,LLaMA-65B 模型表现出色,虽然在某些领域略低于 Chinchilla 和 PaLM。
- 论文原文 :"The massive multitask language understanding benchmark, or MMLU, introduced by Hendrycks et al. (2020) consists of multiple choice questions covering various domains of knowledge, including humanities, STEM and social sciences."Hendrycks等人(2020)引入的大规模多任务语言理解基准(MMLU)由多项选择题组成,涵盖了人文科学、STEM和社会科学等各个知识领域。
- LLaMA-65B 在 MMLU 中的表现
- 观点:LLaMA-65B 在 MMLU 基准上与 Chinchilla 和 PaLM 相比略有劣势,主要是因为其预训练数据中书籍和学术论文的数据量相对较少。然而,LLaMA 仍然展示了其在大规模多任务上的竞争力。
- 论文原文: "On this benchmark, we observe that the LLaMA-65B is behind both Chinchilla- 70B and PaLM-540B by a few percent in average, and across most domains."在这个基准测试中,我们观察到 LLaMA-65B在大多数领域平均落后于 Chinchilla70B和 PaLM-540B几个百分点。
Evolution of performance during training (性能随训练演变的表现)
- 训练过程中的性能变化
- 观点:LLaMA 团队在模型训练过程中,监控了模型在多个任务上的性能,包括问题回答和常识推理任务。大多数任务上的性能随着训练的进行而逐步提高,并且与模型的困惑度(perplexity)密切相关。然而,SIQA 和 WinoGrande 这两个基准测试的表现波动较大,表明这些基准的可靠性较低。
- 论文原文 :"During training, we tracked the performance of our models on a few question answering and common sense benchmarks, and report them in Figure 2. On most benchmarks, the performance improves steadily, and correlates with the training perplexity of the model (see Figure 1)."在训练期间,我们在一些问题回答和常识基准上跟踪了模型的性能,并在图2中报告了它们。在大多数基准测试中,性能稳步提高,并且与模型的训练困惑度相关(参见图1)。
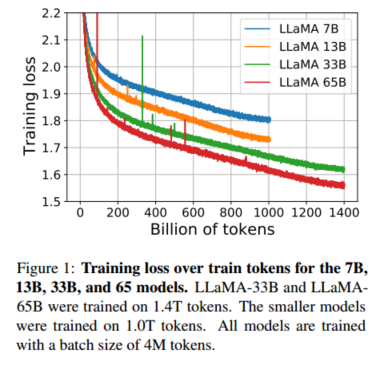
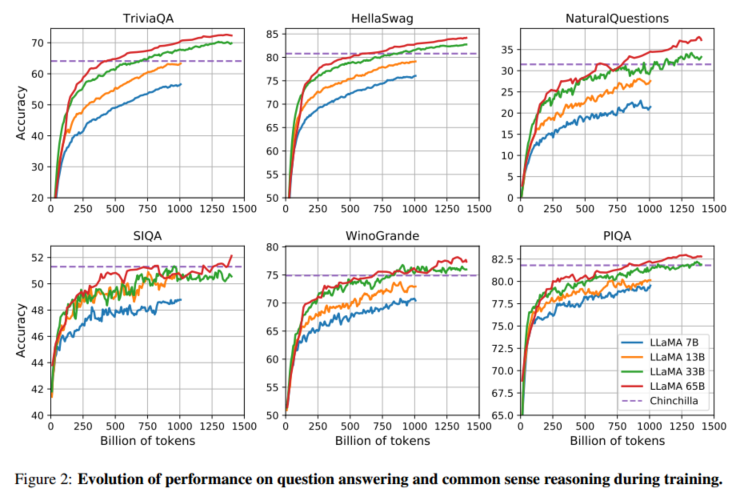
- WinoGrande 基准的表现差异
- 观点:尽管 LLaMA-33B 和 LLaMA-65B 在 WinoGrande 基准测试中的困惑度表现相似,但其任务表现却有所不同。这表明困惑度和任务表现的相关性在某些基准任务中较弱。
- 论文原文 :"On WinoGrande, the performance does not correlate as well with training perplexity: the LLaMA-33B and LLaMA-65B have similar performance during the training."在WinoGrande上,性能与训练困惑度不相关:LLaMA-33B和LLaMA-65B在训练过程中表现相似。
小结
- LLaMA模型在常识推理、闭卷问答和阅读理解三个任务上均展示了出色的表现。特别是在常识推理任务中,LLaMA-65B 超越了当前大多数领先的模型,并且在闭卷问答和阅读理解任务中也表现突出。
- LLaMA 在数学推理、代码生成和大规模多任务语言理解任务中的表现进一步展示了其强大的多领域泛化能力。尤其在数学推理和代码生成任务中,LLaMA-65B 的表现甚至超过了某些经过专门微调的模型。尽管在 MMLU 基准测试上略逊于 Chinchilla 和 PaLM,LLaMA 仍然展示了很强的任务理解和处理能力。
Instruction Finetuning
Instruction Finetuning :指令微调
- 指令微调的概述
- 观点 :LLaMA 模型在经过少量指令数据
微调后,性能有了显著提升,尤其是在 MMLU 基准测试上表现出色。虽然模型在没有微调的情况下已经能够执行基本的指令,但通过微调进一步改善了其执行复杂任务的能力。 - 论文原文 :"Although the non-finetuned version of LLaMA-65B is already able to follow basic instructions, we observe that a very small amount of finetuning improves the performance on MMLU, and further improves the ability of the model to follow instructions."虽然未经微调的LLaMA-65B版本已经能够遵循基本指令,但我们观察到,非常少量的微调提高了MMLU上的性能,并进一步提高了模型遵循指令的能力。
- 观点 :LLaMA 模型在经过少量指令数据
- LLaMA-I 的表现
- 观点:通过指令微调后生成的 LLaMA-I 模型在 MMLU 的 5-shot 测试中表现优异,甚至超过了同类经过指令微调的模型如 OPT-IML 和 Flan-PaLM。
- 论文原文 :"LLaMA-I (65B) outperforms on MMLU existing instruction finetuned models of moderate sizes, but are still far from the state-of-the-art"LLaMA-I (65B)在中等大小的MMLU现有指令微调模型上表现出色,但仍远未达到最先进的水平
- 实验结果与后续计划
- 观点:尽管作者只进行了简单的指令微调实验,但结果表明其效果非常显著。未来,作者计划对模型进行更大规模的指令数据集微调,以进一步提高模型的指令理解和执行能力。
- 论文原文 :"Since this is not the focus of this paper, we only conducted a single experiment following the same protocol as Chung et al. (2022) to train an instruct model, LLaMA-I."由于这不是本文的重点,我们只进行了一个实验,遵循与Chung等人(2022)相同的方案来训练一个指令模型LLaMA-I。
小结:
LLaMA 模型通过少量的指令数据进行微调后,其在复杂任务中的表现得到了显著改善,尤其是在 MMLU 基准测试中超越了大多数同类指令微调模型。
这表明即便在非专门设计的任务中,LLaMA 也具有很强的适应性和任务执行能力。
Bias, Toxicity and Misinformation
Bias, Toxicity and Misinformation: 偏见、有毒言论和虚假信息
- 偏见与有毒言论的潜在风险
- 观点:大型语言模型由于使用大量互联网上的数据进行训练,可能会学习并放大其中存在的偏见、毒性和错误信息。LLaMA 模型也不例外,为了评估其可能产生的有害内容,作者使用了多种标准基准来测试模型生成毒性和偏见内容的倾向。
- 论文原文 :"Large language models have been showed to reproduce and amplify biases that are existing in the training data" 大型语言模型已经被证明能够复制和放大存在于训练数据中的偏见。
- "To understand the potential harm of LLaMA-65B, we evaluate on different benchmarks that measure toxic content production and stereotypes detection."为了了解LLaMA-65B可能带来的危害,我们对其在衡量有毒内容生成和刻板印象检测等不同基准上的表现进行了评估。
- RealToxicityPrompts 测试结果
- 观点:RealToxicityPrompts 基准测试用于评估模型生成毒性语言的程度。LLaMA 模型在生成毒性语言时表现得与文献中的其他模型类似,随着模型的参数规模增加,毒性生成的概率也相应上升。
- 论文原文 :"We run a greedy decoder on the 100k prompts from this benchmark." 我们在这个基准测试的10万个提示上运行了一个贪婪解码器。
- "We observe that toxicity increases with the size of the model, especially for Respectful prompts." 我们观察到,模型的规模越大,毒性越高,尤其是在对"尊重性"提示的响应中。
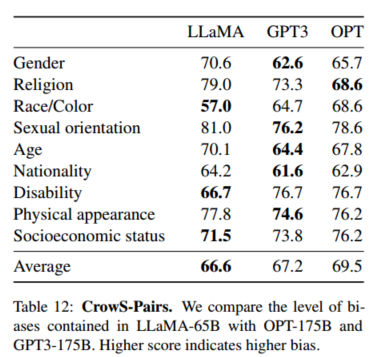
- CrowS-Pairs 测试偏见
- 观点:CrowS-Pairs 基准用于检测模型在性别、宗教、种族等九个类别上的偏见。LLaMA-65B 在偏见检测中的表现比 GPT-3 和 OPT-175B 略好,但在某些类别上(如宗教)表现出更高的偏见。
- 论文原文 :"We evaluate the biases in our model on the CrowS-Pairs" 我们在CrowS-Pairs数据集上评估了我们模型的偏差。
- "We compare with GPT-3 and OPT-175B in Table 12." 我们在表12中与GPT-3和OPT-175B进行了比较。
- " Our model is particularly biased in the religion category (+10% compared to OPT-175B), followed by age and gender" 我们的模型在宗教类别上的偏见特别明显(比OPT-175B高出10%),其次是年龄和性别。
- WinoGender 测试性别偏见
- 观点 :为了更深入地研究模型在性别上的偏见,作者使用了 WinoGender 数据集,该数据集通过共指消解任务检测模型是否会因性别而导致不正确的推断。LLaMA-65B 在处理"她/她/她的"和"他/他/他的"代词时的表现存在显著差异,说明模型可能使用了社会性别偏见来进行推断。
- 论文原文 :
- We evaluate the performance when using 3 pronouns: "her/her/she", "his/him/he" and "their/them/someone" (the different choices corresponding to the grammatical function of the pronoun. 我们观察到,我们的模型在处理"their/them/someone"这类代词的指代消解上明显优于"her/her/she"和"his/him/he"这些代词。
- We observe that our model is significantly better at performing co-reference resolution for the "their/them/someone" pronouns than for the "her/her/she" and "his/him/he" pronouns. 我们评估了在使用三种代词时的表现:"her/her/she"、"his/him/he"和"their/them/someone"(不同的选择对应于代词的语法功能)。
- TruthfulQA 测试误信息
- 观点:TruthfulQA 测试模型在回答问题时是否会生成虚假或错误的信息。LLaMA 模型的表现比 GPT-3 更好,但依然存在生成虚假答案的风险,尤其是在面对对抗性问题时。
- 论文原文 :"Compared to GPT-3, our model scores higher in both categories, but the rate of correct answers is still low, showing that our model is likely to hallucinate incorrect answers." 与GPT-3相比,我们的模型在这两个类别中的得分都更高,但正确答案的比例仍然较低,这表明我们的模型仍有可能生成错误的答案。
补充一个概念:对抗性问题
对抗性问题,这是对语言模型的一种特殊测试方式。
所谓对抗性问题,通常是指那些设计得非常具有挑战性或故意引导模型产生错误的问句,目的是测试模型在面对复杂、不确定或含有陷阱的问题时的应对能力。
具体来说:
- 对抗性问题:这些问题可能会利用模型训练数据中的潜在偏见或限制,让模型更容易生成虚假、错误或不准确的回答。这类问题通常设计精巧,意在测试模型能否分辨出常见的"陷阱"问题。
- 例子:假如给出一个模棱两可或误导性的问题,例如:"猫比地球重吗?"这种问题如果没有正确处理,可能会导致模型生成错误的回答。

在上文的这段话中,作者提到:
- LLaMA模型在应对对抗性问题时生成虚假答案的风险较高。这意味着虽然LLaMA在普通问题上表现较好,且比GPT-3的性能更高,但在面对更具挑战性的对抗性问题时,LLaMA仍然会倾向于产生错误或虚假的答案。
总结来说,"对抗性问题"是为了测试模型在复杂或欺骗性条件下的表现,LLaMA虽然总体表现优于GPT-3,但在这种特殊情况下依然存在明显的风险。
小结:
在"Bias, Toxicity and Misinformation"部分,LLaMA 模型展示了其在生成偏见、有毒言论和错误信息方面的潜在风险。
尽管与其他大型语言模型相比,LLaMA 的表现有所改善,但依然存在由于训练数据中的偏见而导致的问题,尤其是在性别和宗教等类别上表现较为明显。
作者强调,这些问题需要在未来的工作中进一步研究和解决。
Carbon Footprint
在"Carbon Footprint"这一部分,作者讨论了训练LLaMA模型过程中所消耗的能量以及由此产生的碳排放量。大规模语言模型的训练需要数百到数千的GPU计算小时,消耗了大量的电力。
因此,计算这些模型在训练过程中的碳排放量是非常重要的。
作者使用了公式,用来计算所消耗的电力(瓦特小时,Wh)和碳排放量(吨二氧化碳当量,tCO2eq)。
公式如下:
- W h = G P U - h × ( G P U power consumption ) × P U E Wh = GPU\text{-}h \times (GPU\text{ power consumption}) \times PUE Wh=GPU-h×(GPU power consumption)×PUE
其中,GPU-h是训练中GPU的使用时间,PUE(电源使用效率)取1.1,表示能量效率因素。 - t C O 2 e q = M W h × 0.385 tCO2eq = MWh \times 0.385 tCO2eq=MWh×0.385
这个公式用来计算碳排放量,0.385 kg CO2eq/KWh是美国国家平均的碳强度因子。
通过这些计算公式,作者估算了训练LLaMA模型所产生的碳排放量,并与其他模型(如BLOOM和OPT)进行了对比。
详解:
- 能源消耗的评估
- 观点:LLaMA模型的开发需要使用2048台A100-80GB GPU,训练时间大约为5个月。总共使用了约2638 MWh的电能,导致了1015吨二氧化碳当量的排放。通过将这些模型开源,作者希望减少未来类似模型开发过程中的碳排放。
- 论文原文 :"We estimate that we used 2048 A100-80GB for a period of approximately 5 months to develop our models. This means that developing these models would have cost around 2,638 MWh under our assumptions, and a total emission of 1,015 tCO2eq."
- 与其他模型的对比
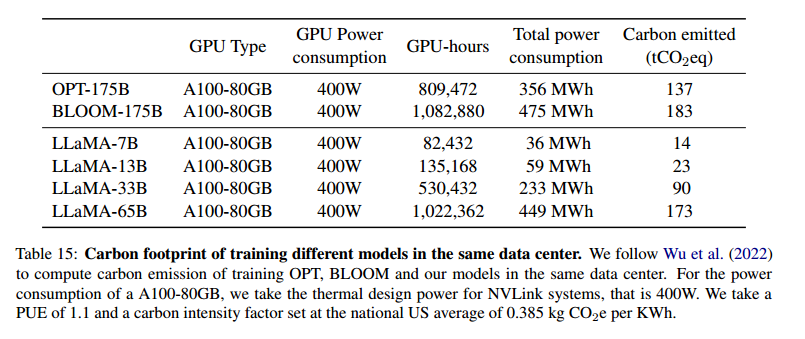
- 观点:表格列出了LLaMA模型与BLOOM、OPT模型在相同数据中心训练下的能量消耗和碳排放量对比。LLaMA-65B模型消耗了449 MWh的电能,排放了173吨二氧化碳当量,而LLaMA-7B模型仅消耗了36 MWh,排放了14吨二氧化碳当量。相比之下,BLOOM-175B模型的碳排放量更高,达到183吨。
- 论文原文 :"We follow Wu et al. (2022) to compute carbon emission of training OPT, BLOOM and our models in the same data center. For the power consumption of a A100-80GB, we take the thermal design power for NVLink systems, that is 400W."
- 未来的环境影响
- 观点:通过开源LLaMA模型,作者希望能够减少未来研究和开发过程中重复训练所带来的碳排放。由于部分LLaMA模型较小,可以在单台GPU上运行,因此也有助于减少能量消耗。
- 论文原文 :"We hope that releasing these models will help to reduce future carbon emission since the training is already done, and some of the models are relatively small and can be run on a single GPU."
表格解读:
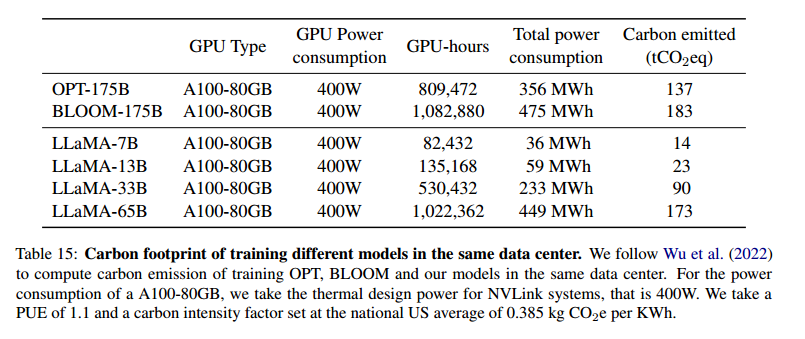
表格15展示了不同模型在相同数据中心的能量消耗和碳排放情况:
- LLaMA-65B:消耗了449 MWh,排放了173吨二氧化碳当量。
- LLaMA-7B:消耗了36 MWh,排放了14吨二氧化碳当量。
- BLOOM-175B:消耗了475 MWh,排放了183吨二氧化碳当量。
- OPT-175B:消耗了356 MWh,排放了137吨二氧化碳当量。
小结:
LLaMA模型的训练消耗了大量的电能,尤其是大规模模型如65B参数的模型。
通过使用GPU小时数、能量消耗公式,作者对LLaMA模型的碳排放进行了估算,并与BLOOM和OPT模型进行了比较。
Related Work
在"Related Work"部分,作者回顾了大型语言模型的发展历史,分析了从早期的基于统计的模型到神经网络模型的演变。
这部分的讨论包括 传统的n-gram模型、平滑技术、以及近年来广泛使用的神经网络架构(如Transformer)的应用。
此外,文章还重点回顾了语言模型的扩展性,如何通过增加模型参数和数据集规模来提高模型的性能,并引用了多个重要的相关研究成果。
详细讲解:
- 早期语言模型的演变
- 观点:语言模型最早以概率分布的方式被提出,基于词、标记或者字符的序列来预测下一个词。这种任务被称为"下一词预测",是自然语言处理中的核心问题之一。早期模型大多基于n-gram统计,并使用平滑技术来解决稀有事件的估计问题。
- 论文原文 :"Language models are probability distributions over sequences of words, tokens or characters (Shannon, 1948, 1951). This task, often framed as next token prediction, has long been considered a core problem in natural language processing" 语言模型是对词序列、标记或字符的概率分布(Shannon,1948,1951)。这一任务通常被表述为下一个标记的预测,一直被认为是自然语言处理中的核心问题。
- n-gram 模型及其平滑技术
- 观点:早期的语言模型主要依赖于n-gram统计,且为了改进对稀有事件的估计,提出了多种平滑技术,例如Katz平滑和Kneser-Ney平滑。这些技术帮助提高了模型在面对少见词汇时的表现。
- 论文原文 :"Traditionally, language models were based on n-gram count statistics (Bahl et al., 1983), and various smoothing techniques were proposed to improve the estimation of rare events (Katz, 1987; Kneser and Ney, 1995)." 传统上,语言模型是基于n元组计数统计(Bahl等人,1983),并提出了各种平滑技术来改善稀有事件的估计(Katz,1987;Kneser和Ney,1995)。
- 神经网络的应用
- 观点:自20世纪90年代以来,神经网络逐渐被应用于语言建模任务。开始是前馈神经网络,然后是递归神经网络(RNN)和LSTM。最近,Transformer架构基于自注意力机制的优势,使其在捕捉长程依赖方面取得了显著的改进,成为当前主流的语言建模方法。
- 论文原文 :"In the past two decades, neural networks have been successfully applied to the language modelling task, starting from feed forward models (Bengio et al., 2000), recurrent neural networks (Elman, 1990; Mikolov et al., 2010) and LSTMs (Hochreiter and Schmidhuber, 1997; Graves, 2013)." 在过去的二十年中,神经网络成功地应用于语言建模任务,从前馈模型(Bengio等人,2000)、循环神经网络(Elman,1990;Mikolov等人,2010)到长短期记忆网络(LSTM)(Hochreiter和Schmidhuber,1997;Graves,2013)。
- Transformer 的引入
- 观点:Transformer架构是近年来在语言建模任务上取得重要进展的模型,它基于自注意力机制,能够捕捉长程依赖。在许多自然语言处理任务中,Transformer的表现超过了早期的LSTM和RNN模型。
- 论文原文 :"More recently, transformer networks, based on self-attention, have led to important improvements, especially for capturing long range dependencies (Vaswani et al., 2017; Radford et al., 2018; Dai et al., 2019)." 最近,基于自注意力机制的Transformer网络带来了重要的改进,尤其是在捕捉长距离依赖方面(Vaswani等人,2017;Radford等人,2018;Dai等人,2019)。
- 语言模型的扩展性
- 观点 :语言模型的扩展性研究历史悠久,无论是模型规模还是数据集规模的扩展,都会带来性能的提升。Brants等人在2007年的研究中展示了使用 2万亿tokens 训练的语言模型对机器翻译质量的提升。近年来的大型语言模型如BERT、GPT-3、Megatron等都证明了这一点。
- 论文原文 :"Scaling. There is a long history of scaling for language models, for both the model and dataset sizes. Brants et al. (2007) showed the benefits of using language models trained on 2 trillion tokens, resulting in 300 billion n-grams, on the quality of machine translation." 扩展。语言模型在模型和数据集规模上都有着悠久的扩展历史。Brants等人(2007)展示了在机器翻译质量方面,使用在2万亿个标记上训练的语言模型(生成3000亿个n元组)的优势。
小结:
"Related Work"部分回顾了从早期基于统计的n-gram模型到现代神经网络模型的演变,重点介绍了语言模型的扩展性,以及如何通过增加数据集和模型规模来提高性能。特别是Transformer架构的引入,极大地推动了语言模型的发展,使其在多个NLP任务中取得了优异的表现。
Conclusion
在"Conclusion"部分,作者总结了LLaMA模型的主要贡献和发现,强调了其与其他主流大型语言模型的竞争优势。
作者指出,LLaMA通过仅使用公开数据进行训练,展示了达到最新水平的可能性,并且LLaMA-13B的性能超过了GPT-3,尽管其参数量远小于GPT-3。
这一部分还指出,LLaMA的开源有助于推进大型语言模型的研究,减少重复训练所带来的碳排放,并强调了模型指令微调的潜力。
详细讲解:
- LLaMA模型的主要贡献
- 观点:LLaMA系列语言模型是基于公开数据训练的,表现上与当前最先进的基础模型相比具有竞争力。LLaMA-13B超越了GPT-3,而LLaMA-65B与Chinchilla-70B和PaLM-540B表现相当。这表明使用公开数据可以达到最先进的性能,而不需要依赖私有数据集。
- 论文原文 :"In this paper, we presented a series of language models that are released openly, and competitive with state-of-the-art foundation models. Most notably, LLaMA-13B outperforms GPT-3 while being more than 10× smaller, and LLaMA-65B is competitive with Chinchilla-70B and PaLM-540B."
- 使用公开数据的优势
- 观点:与之前的研究不同,LLaMA通过仅使用公开的数据集进行训练,证明了在不依赖私有数据的情况下,也可以实现最先进的性能。通过开源LLaMA模型,作者希望能够加速大型语言模型的开发,帮助解决毒性和偏见等已知问题。
- 论文原文 :"Unlike previous studies, we show that it is possible to achieve state-of-the-art performance by training exclusively on publicly available data, without resorting to proprietary datasets. We hope that releasing these models to the research community will accelerate the development of large language models, and help efforts to improve their robustness and mitigate known issues such as toxicity and bias."
- 指令微调的潜力
- 观点:与Chung等人(2022)的研究相似,LLaMA的微调实验显示出通过指令微调可以显著提高模型的性能。LLaMA在指令任务上的潜力促使作者计划在未来进一步探索这一方向。
- 论文原文 :"Additionally, we observed like Chung et al. (2022) that finetuning these models on instructions lead to promising results, and we plan to further investigate this in future work."
- 未来发展方向
- 观点:作者计划未来发布在更大规模预训练数据上训练的更大模型,理由是随着模型和数据规模的扩展,性能会不断提升。
- 论文原文 :"Finally, we plan to release larger models trained on larger pretraining corpora in the future, since we have seen a constant improvement in performance as we were scaling."
小结:
LLaMA模型的设计展示了在使用公开数据集进行训练的情况下,也能够达到最先进的语言模型性能。
这一部分总结了LLaMA的主要贡献,并指出模型的开源将推动未来的研究发展。
作者也提到通过指令微调获得了令人鼓舞的结果,并计划在未来进一步研究该方向。