摘要:本文整理自阿里云高级研发工程师、Apache Flink Contributor 周云峰老师在 Apache Asia CommunityOverCode 2024中的分享。内容主要分为以下三个部分:
- 从流批一体到流批融合
- 流批融合的技术解决方案
- 社区进展及未来展望

一、从流批一体到流批融合
1.流批一体
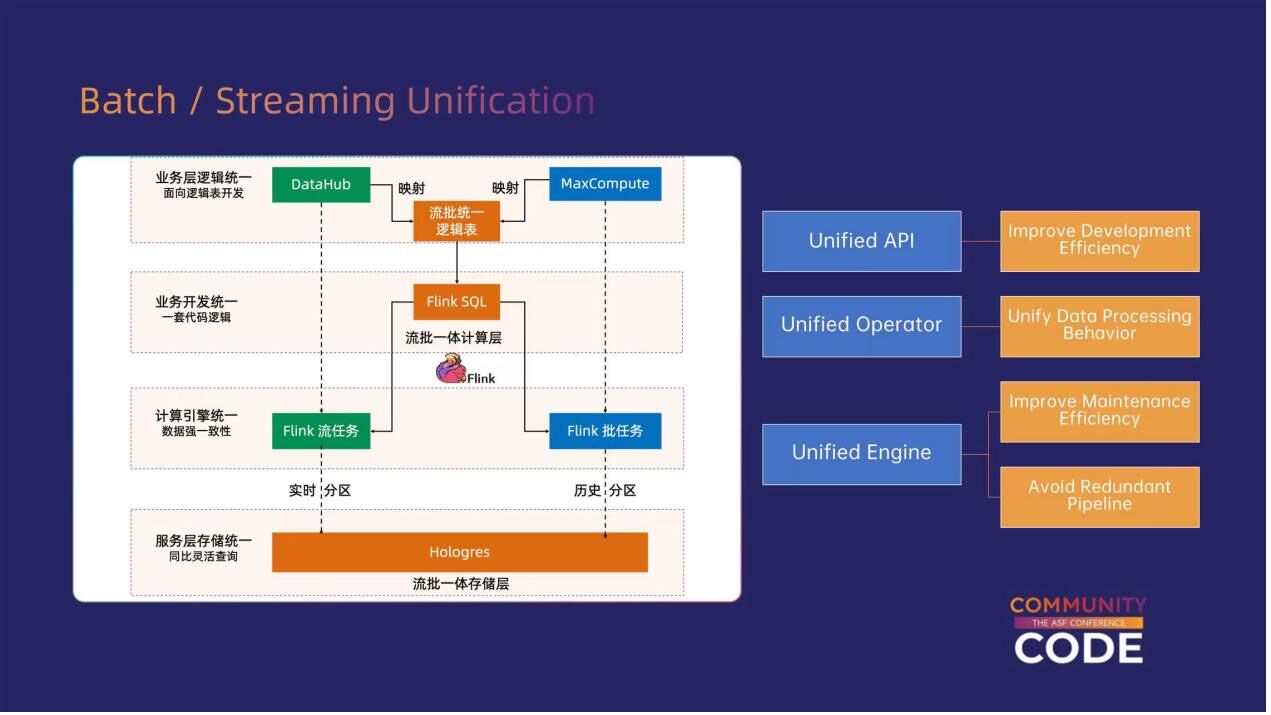
在流批融合之前,Flink 已经提出过流批一体的理念。流批一体主要体现在以下方面的统一:
(1)API 统一:Flink 通过提供统一的 DataStream 和 SQL API,使得用户在进行离线和在线作业时不需要开发两套代码,从而提升了开发效率。
(2)算子统一:在算子层面实现了统一,使用同一套算子既可以处理流作业,也可以处理批作业,确保流作业和批作业在数据处理逻辑、正确性和语义行为上保持一致。
(3)引擎统一:使用同一个引擎和同一套资源调度框架,避免了为流作业和批作业搭建不同工作流的需求,从而优化了运维效率。
这些都是 Flink 在流批一体方面已经取得的一些成果。然而,在现有流批一体的基础上,用户仍然需要配置一个作业是流作业还是批作业,并根据作业所在的离线或在线场景,采用不同的优化策略。这些配置策略仍然会一定程度上增加用户运维 Flink 作业的工作量。而这正是流批融合希望解决的问题。
2. 影响流批不同模式的前提条件

在流批融合的背景下,通过分析用户配置流模式和批模式的思路,我们发现流批两种模式,实际上是根据不同的前提条件采用不同的优化策略。这些前提条件主要包括以下两个方面:
(1)用户对性能的倾向性:在配置批作业时,用户通常倾向于追求高吞吐量或高资源利用率。而在流作业中,用户则期望低延迟、高数据新鲜度和实时性。
(2)对数据的先验知识:在批模式下,所有数据在一开始都是已准备好的,因此作业可以根据数据的一些统计信息进行相应的优化。而在流模式下,由于作业通常不知道未来会有哪些数据,因此需要对随机访问等领域进行优化,以提供更好的支持。
由于前提条件不同,Flink 在流模式和批模式下采取了不同的优化策略。这些策略主要体现在资源调度、状态访问和容错机制等方面:
(1)资源调度(Scheduling):
-
批作业:可以做到见缝插针式的资源使用方式。即使当前物理资源不满足所有算子同时执行的需求,也可以先利用现有资源执行一部分任务(task)。任务执行完后空出的资源可以调度下一批任务,从而提高资源利用率。
-
流作业:为了保证更好的实时性,流作业需要在一开始就申请好从源头(source)到终点(sink)的所有算子及其并发资源,以确保数据流的连续性和低延迟。
(2)状态访问(State Access):
-
批作业:可以只保存一个主键对应的状态,并连续处理该主键的所有数据。
-
流作业:由于无法预知下一个相同主键的数据何时到来,需要保存所有主键的状态,并对随机访问进行优化,以支持实时处理。
(3)容错机制(Fault Tolerance):
-
批作业:在每个任务执行完之后,Flink作业可以暂时将中间结果缓存下来,然后下一个任务可以接着消费这个中间结果。当某个任务失败时,只需重启该任务,并从之前保存的中间结果重新消费即可。
-
流作业:Flink引入了检查点(checkpoint)机制,通过定时对整个数据处理链路进行快照,实现容错。当某个任务失败时,可以从最近的检查点恢复,从而保证数据处理的连续性和一致性。
由于这些不同的前提条件,Flink在流模式和批模式下本质上采用了不同的优化策略,以满足各自的性能需求和操作特点。
3.前提条件的动态变化

在进一步的探索中,我们发现这些前提条件并不是在作业的整个生命周期中一成不变、而是可能会在运行时动态变化的。
-
在离线场景中,作业场景一般始终具有高吞吐量的倾向。
-
而在实时场景下,用户通常更注重低延迟、高实时性和高数据新鲜度。然而,当实时场景出现数据积压时,由于客观因素的限制,Flink 作业此时已经无法维持端到端的低延迟策略。这时,用户追求的是以最短时间消费完现有的数据积压、尽快恢复到实时状态,即高吞吐量策略。
-
在全增量一体化的场景中,这两种模式的区别进一步被细化为全量和增量的区别。在这两种状态下,除了对吞吐量和实时性的要求不同外,还有关于数据先验知识的变化。在同步一个全量数据库的场景下,所有数据之间的主键不会重复,是对整个数据库进行一次全面扫描。而在增量场景下,可能会出现更新操作,对已有的重复主键进行数据更新。
这些说明我们需要 Flink 能够根据作业运行时需求的动态变化,产生不同的优化策略。
4.流批融合的目标
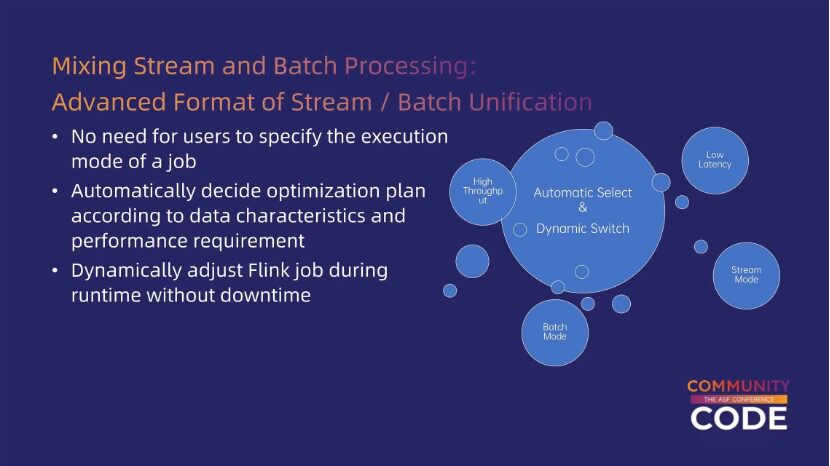
基于以上对前提条件和场景的分析,我们可以看到,流批融合想要实现的目标是使用户不再需要手动配置流模式或批模式,而是通过 Flink 框架自动检测用户在不同场景下(实时和离线)对吞吐量、延迟以及数据特征的需求,动态地进行相应的优化。这使得 Flink 能够根据用户对吞吐量和延迟的倾向性,以及数据特征的变化,自动调整优化策略。
二、实现流批融合的技术方案
下面介绍Flink是怎样实现这些目标的。
1.数据流批倾向性的定量指标

首先,我们将用户的倾向性或数据特征量化为两个指标。
第一个指标是 isProcessingBacklog,可以理解为用于判断当前是否存在数据积压。当出现数据积压时,作业需要在最短时间内处理这些积压数据。这时,作业可以通过牺牲延迟来优化,从而提高吞吐量。在没有数据积压的情况下,作业应该像现有的流模式那样,尽量保证低延迟和高数据新鲜度的目标。
第二个量化指标是 isInsertOnly,可以大致理解为全增量一体中全量场景和增量场景之间的区别。在 isInsertOnly 情况下,所有数据都会是 Insert 类型,而不是更新(update)或删除(delete)类型的数据。这些数据的主键也互不重复。
2.量化指标的收集
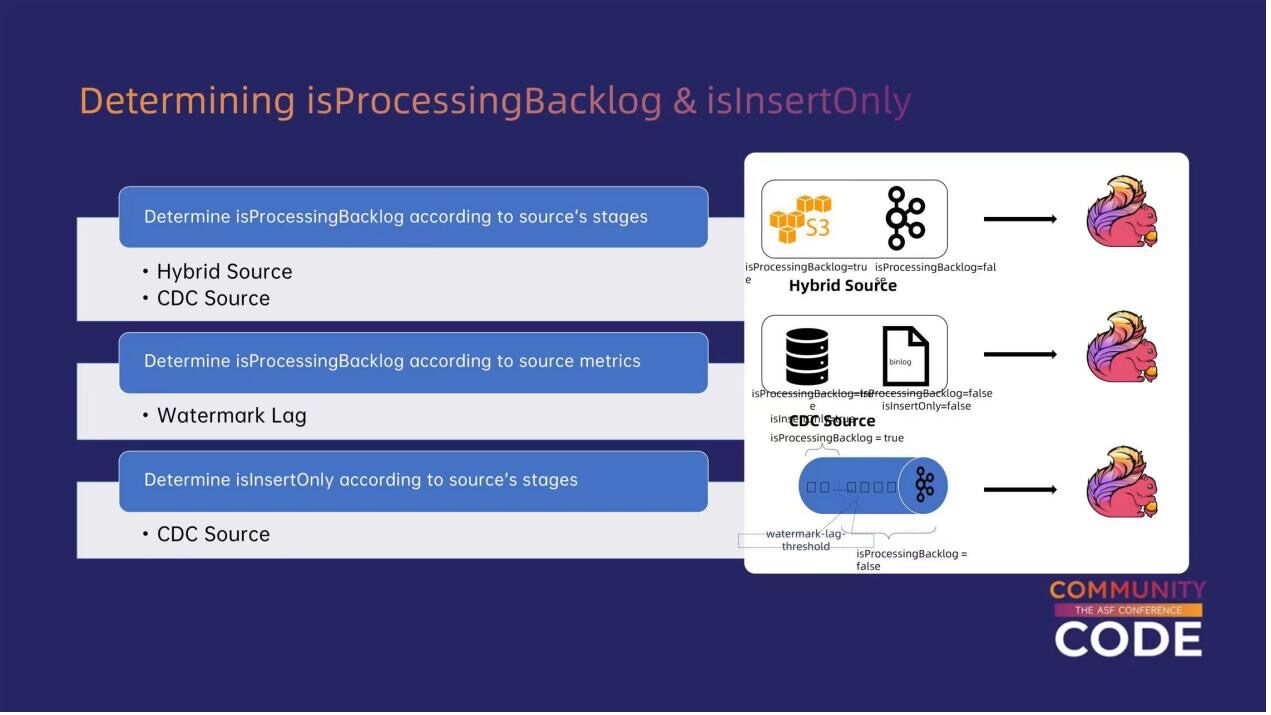
怎样去收集获取刚才提到的两个量化指标呢?一个主要的思路是从数据源(source)获取数据。
例如,对于有明确阶段的数据源(如Hybrid Source),它可能会先读取文件系统中的一个文件,将全量文件读取完毕后,再消费实时消息队列中的数据。在这种情况下,初始阶段消费文件时,作业总会存在数据积压,此时isProcessingBacklog = true;而在后续阶段消费消息队列时,isProcessingBacklog 才会从 true 变为 false。
对于 CDC source 也是类似。在全量场景下,isProcessingBacklog 等于 true,而在增量场景下则等于 false。
对于没有明确阶段的源(如普通的消息队列),作业可以根据 Flink 现有的一些指标(metrics)来判断是否存在数据积压,例如 Watermark 延迟。Watermark 代表作业数据时间的当前水位,其时间戳与系统时间之间的差异表现为 Watermark 延迟。当延迟高于一定阈值时,说明当前存在数据积压;反之,则没有数据积压。
前面介绍了判断 isProcessingBacklog 的方法。而对于判断 isInsertOnly 的方式,目前主要支持 CDC source。在全量阶段,isInsertOnly 等于 true,而在增量阶段,isInsertOnly 等于 false。
3.基于量化指标的优化策略
在收集到这些指标后,接下来要做的是在各个算子中根据当前这两个指标的状态,采用不同的优化策略。
(1)Processing Time Temporal Join

首先,对于 isProcessingBacklog,优化措施之一是更好地支持基于处理时间的临时连接(Processing Time Temporal Join)。这种 Join 不依赖于 Probe Side 和 Build Side 数据本身的时间因素,而是依赖于系统时间。当Probe Side数据到达Flink系统时,根据当前最新的 Build Side 数据做 Join 即可。
这种做法在语义上没有问题,但在实际操作中可能会遇到以下情况:当 Build Side 有数据积压时,有可能某条数据已经被更新到 Build Side 上游的服务中了,但由于数据积压,这条数据无法及时被Flink系统接收到。此时当 Probe Side 的一条数据过来进行 Join 时,就可能无法与这条数据进行匹配,从而导致Join结果不包含预期中的所有数据。
为了解决这个问题,Flink 采取的优化措施是: 当 Build Side 存在数据积压,即 isProcessingBacklog 等于 true 时,Join 算子先暂停消费 Probe Side 的数据。等作业追上 Build Side 的数据后,Join 算子再继续消费 Probe Side 的数据,从而避免之前提到的 Join 丢失情况。
(2)调整checkpoint时间间隔

第二个优化是调整 Flink 的 checkpoint 时间间隔。以 Paimon Sink 为例,Flink 的一些 Connector 能够保证数据 exactly-once 的语义,并且其 exactly-once 语义依赖于二阶段提交能力。而 Paimon Sink 二阶段提交的频率和 Flink 的 checkpoint 时间间隔保持一致。
因此,这里进行了一个优化:当 isProcessingBacklog 为 true 或 false 时,用户可以分别设置不同的 checkpoint 时间间隔。当数据积压时,用户可以配置一个较长的时间间隔,以尽量减少 Paimon Sink 执行二阶段提交的次数及其开销。通过这种方式,Paimon Sink 能够增加全量数据同步阶段的吞吐量。
(3)优化数据的处理顺序

另一个基于 isProcessingBacklog 的优化是对输入数据进行排序。前面提到,批处理作业相比于流处理作业的一个优势在于可以连续消费同一个主键的数据,在本地的 Flink 算子中只需要保存一个主键所对应的状态,不需要有随机访问 Key-Value Store的开销。受此启发,我们将这种优化应用到流处理作业上。
具体来说,当 isProcessingBacklog 为 true 时,下游算子会先暂停消费数据,然后对上游积压的数据进行排序。排序完成后,算子再对相同主键的数据进行连续消费。这样不仅不会明显增加数据延迟,还通过减少随机访问状态后端的开销,优化了作业的整体吞吐量。
(4)基于isInsertOnly优化Sink行为

关于 isInsertOnly 的优化,目前看到的主要应用在 Paimon sink 和 Hologres sink 上。首先,Paimon sink 除了更新数据本身以外,还支持生成变更日志(changelog)。在通常情况下,changelog 和数据文件之间的关系可以理解为:changelog 是原始的输入数据,而数据文件是对原始输入数据进行去重和更新后的结果。
在 isInsertOnly 为 true 的情况下,因为所有数据的主键都不同,我们可以认为 changelog 去重过程实际上并没有进行去重操作,changelog 和数据文件的内容是相同的。基于这一信息,Paimon sink 可以不需要独立地进行序列化、格式转换、分别写出 changelog 文件和数据文件;相反,Paimon sink 只需要写出一份数据文件,然后再拷贝一份作为 changelog 文件即可。这样做减少了 CPU 的开销。
类似的优化也可以应用在 Hologres sink上。在 isInsertOnly 为 true 的情况下,Hologres sink可以使用批量插入(batch insert)并避免预写日志(write-ahead logging)这些步骤。当写入一条数据时,作业不需要查询数据库中是否存在该主键的数据来决定是更新现有数据还是插入一条新数据,因为isInsertOnly 语义已经保证不会出现主键重复的情况。因此作业可以跳过这些查询和更新的开销,从而实现吞吐量的优化。
三、社区进展以及未来展望
最后介绍上面提到的这些优化,它们现在的一些进展以及未来展望。
1.isProcessingBacklog进展

首先,关于 isProcessingBacklog,目前社区已经完成了根据 source 的不同阶段生成 isProcessingBacklog 信号,并将这个信号传递到下游、用它来调控 Flink 的 checkpoint 时间间隔的部分。对于前面提到的对所有数据进行排序以减少状态开销、以及根据 watermark 的延迟来判断 isProcessingBacklog 的功能,它们已经在社区中提出讨论,但还没有最终完成。这里每个条目后都有对应的 Flink 设计文档编号,感兴趣的读者可以参考相关的具体设计文档。
2.isInsertOnly进展

关于 isInsertOnly,前面介绍到的内容,包括从 CDC(Change Data Capture)收集 isInsertOnly 信号,并利用该信号优化 Paimon Sink 和 Hologres Sink的部分,这些功能已经在阿里云商业化版本的 Flink 中完成,并预计将在下个版本发布。
另外,isInsertOnly 信号的语义与 Flink 社区的部分现有框架还存在一些冲突,相关冲突预计将在 Flink 2.0 支持 Generalized Watermark 机制后自然解决。因此,目前我们先在阿里云的商业化版本中实现了这些优化,待 Flink 2.0 支持相应的基础设施后,我们会将这些优化推向 Flink社区。
3.未来展望

未来,我们将进一步推进以下几个方面的工作:
(1)在 Flink 2.0 中推向社区的优化:我们计划将关于 isInsertOnly 的优化推向 Flink 社区。这些优化已经在阿里云商业化版本中完成,并预计将在 Flink 2.0 支持 Generalized Watermark 机制后逐步推向社区。
(2)动态修改 Flink 的算子流程结构(DAG 图):我们将探索根据用户在不同阶段的需求(流模式或批模式)动态修改 Flink 的算子流程结构(DAG 图)的支持,以更好地适应不同的应用场景。
(3)改进量化指标的切换机制:目前对于 isProcessingBacklog/isInsertOnly 信号,我们只支持一次性的切换,即对于需要追溯历史数据或同步全量数据的作业,目前支持在初始化阶段 isProcessingBacklog/isInsertOnly 设置为 true,在追上实时或增量数据后一次性切换为 false。在未来,我们希望即使在量化指标切换为 false 后,Flink作业仍然能够根据实际过程中偶尔出现的数据积压情况,再从false切换回true,重新应用批处理的优化。这将使系统更具灵活性和适应性。
以上就是我们未来的一些优化思路。欢迎大家加入阿里云的开源大数据团队,共同推动技术进步和创新。