目录
[1. 华为云X实例介绍及优势](#1. 华为云X实例介绍及优势)
[1.1 柔性算力](#1.1 柔性算力)
[1.2 vCPU和内存的灵活配比](#1.2 vCPU和内存的灵活配比)
[1.3 成本效益与性能](#1.3 成本效益与性能)
[2. 安装并运行 Docker](#2. 安装并运行 Docker)
[2.1 修改仓库配置文件](#2.1 修改仓库配置文件)
[2.2 安装 Docker](#2.2 安装 Docker)
[2.3 启动 Docker](#2.3 启动 Docker)
[3. 使用Docker部署Elasticsearch](#3. 使用Docker部署Elasticsearch)
[3.1 拉取Elasticsearch镜像](#3.1 拉取Elasticsearch镜像)
[3.2 启动Elasticsearch容器](#3.2 启动Elasticsearch容器)
[3.3 验证Elasticsearch](#3.3 验证Elasticsearch)
[4. 安装Apache Benchmark (ab) 工具](#4. 安装Apache Benchmark (ab) 工具)
[5. 使用 ab 工具对 Elasticsearch 进行评测](#5. 使用 ab 工具对 Elasticsearch 进行评测)
[5.1 运行 Elasticsearch 查询评测](#5.1 运行 Elasticsearch 查询评测)
[5.2 查看评测结果](#5.2 查看评测结果)
[5.3 调整并发请求和请求数](#5.3 调整并发请求和请求数)
[6. 总结](#6. 总结)
前言
随着数据量的不断增加,企业对高效搜索和数据分析的需求也在快速增长。Elasticsearch作为一款分布式的全文搜索引擎,因其高性能和可扩展性,广泛应用于大数据场景。在本篇文章中,我将介绍如何在华为云上通过Docker容器化部署Elasticsearch,并通过工具对其进行性能评测。整篇文章将涵盖从环境准备、部署、到性能评测的详细步骤和代码示例,帮助读者在华为云上快速搭建一个高效的Elasticsearch系统。
1. 华为云X实例介绍及优势
在选择云服务平台时,计算资源的弹性和性价比是关键考虑因素。华为云X实例是为用户提供高性价比和灵活资源调配能力的云计算服务,特别适合计算密集型任务,如大数据处理、AI训练以及像Elasticsearch这样的分布式搜索引擎。
1.1 柔性算力
华为云X实例采用了柔性算力的设计理念。所谓柔性算力,即用户可以根据具体的业务需求,在计算能力、存储容量和带宽等资源之间进行灵活调配。这意味着,用户在运行Elasticsearch等应用时,可以根据数据增长或查询量的变化,动态调整资源,确保性能需求得到满足。
1.2 vCPU和内存的灵活配比
X实例允许用户灵活配置vCPU与内存的比例,从而根据不同负载场景进行优化。例如,在Elasticsearch集群中,索引和搜索任务的负载不同,可能需要更高的内存或计算能力。通过在X实例中调整vCPU与内存的配比,用户可以避免资源浪费,提高成本效益。
1.3 成本效益与性能
在高性价比方面,华为云X实例提供了更具竞争力的价格,特别是对于那些对资源需求波动较大的工作负载,如Elasticsearch的动态索引和查询工作。结合弹性扩展能力,用户可以在不牺牲性能的前提下,大幅降低运行成本。此外,X实例支持不同的计费模式,用户可以按需付费或选择包年包月等多种付费方式,从而进一步提升云上计算资源的利用效率。
近期华为云推出了优惠活动,X实例服务器的折扣力度非常大,性能与性价比兼具,特别适合开发者进行各种项目部署和测试,欢迎大家抓住机会体验。

2. 安装并运行 Docker
在开始部署之前,确保您已经在华为云上创建了一个X实例服务器,并安装了Docker。以下是需要准备的内容:
| 配置项 | 详细信息 |
|---|---|
| 操作系统 | Huawei Cloud EulerOS 2.0 |
| 实例配置 | 4核CPU,12GB内存,100GB SSD |
| Elasticsearch 版本 | 7.16.2 |
| Docker 版本 | 20.10及以上 |
2.1 修改仓库配置文件
如果在添加 Docker 仓库时出现错误,需手动下载并修改仓库文件。执行以下命令下载仓库文件:
bash
wget https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo -P /usr/local/docker打开文件并将 $releasever 替换为 7:
bash
vi /usr/local/docker/docker-ce.repo
:%s/\$releasever/7/g重新添加仓库:
bash
yum-config-manager --add-repo /usr/local/docker/docker-ce.repo2.2 安装 Docker
安装 Docker 及相关组件:
bash
yum install -y docker-ce docker-ce-cli containerd.io2.3 启动 Docker
安装完成后,启动 Docker 服务:
bash
systemctl start docker使用以下命令确认 Docker 正常运行:
bash
systemctl status docker
3. 使用Docker部署Elasticsearch
部署Elasticsearch的方式有很多种,使用Docker可以方便地管理其容器化进程,并快速扩展。接下来我们将拉取Elasticsearch镜像,并通过Docker启动容器。
3.1 拉取Elasticsearch镜像
执行以下命令从Docker Hub上获取Elasticsearch官方镜像:
bash
docker pull elasticsearch:7.16.23.2 启动Elasticsearch容器
在启动容器之前,我们可以通过指定一些环境变量来配置Elasticsearch。以下是一个启动Elasticsearch的命令示例:
bash
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms4g -Xmx4g" \
-v es_data:/usr/share/elasticsearch/data \
elasticsearch:7.16.2上述命令解释:
- -p 9200:9200:将主机的9200端口映射到容器的9200端口(用于HTTP访问)。
- -p 9300:9300:将主机的9300端口映射到容器的9300端口(用于集群通信)。
- -e "discovery.type=single-node":指定Elasticsearch为单节点模式。
- -e "ES_JAVA_OPTS=-Xms4g -Xmx4g":设置JVM内存分配为4GB。
- -v es_data:/usr/share/elasticsearch/data:将Elasticsearch的数据存储映射到Docker卷es_data中。
启动后,您可以通过以下命令查看容器状态:
bash
docker ps如果Elasticsearch启动成功,您应该能够看到容器在运行。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 2f11d1ece355 elasticsearch:7.16.2 "/bin/tini -- /usr/l..." 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
3.3 验证Elasticsearch
您可以通过浏览器或curl命令访问Elasticsearch的REST API接口,验证其是否正常启动:
bash
curl -X GET "localhost:9200/"如果部署成功,您将得到类似以下的JSON响应:
{
"name" : "2f11d1ece355",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "ztjMH9OAQaKDErlBVHpgpg",
"version" : {
"number" : "7.16.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2b937c44140b6559905130a8650c64dbd0879cfb",
"build_date" : "2021-12-18T19:42:46.604893745Z",
"build_snapshot" : false,
"lucene_version" : "8.10.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
4. 安装Apache Benchmark (ab) 工具
Apache Benchmark(简称ab)是Apache HTTP Server附带的一个命令行工具,常用于对HTTP服务的性能进行测试。由于Elasticsearch的REST API是基于HTTP协议的,因此可以使用ab工具对其进行简单的压力测试。
大多数Linux系统自带ab工具,如果没有安装Apache,可以通过以下命令安装:
bash
sudo yum install httpd-tools安装完成后,可以通过以下命令验证ab是否安装成功:
bash
ab -V如果返回版本号,则表示安装成功。

5. 使用 ab 工具对 Elasticsearch 进行评测
ab (Apache Benchmark) 工具通过向指定 URL 发送多个 HTTP 请求,统计响应时间、吞吐量等性能指标,帮助评估服务器的性能。对于 Elasticsearch 集群,可以使用 ab 工具测试查询请求的性能,如数据检索的响应时间和吞吐量等。
5.1 运行 Elasticsearch 查询评测
以下是使用 ab 工具对 Elasticsearch 进行查询性能评测的步骤:
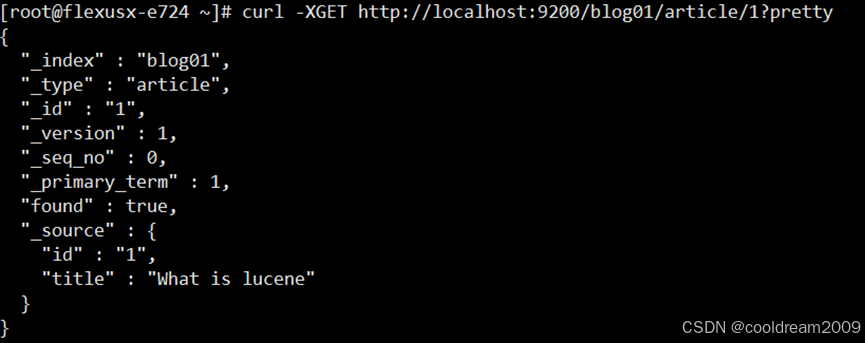
确定查询 URL 先确定需要测试的 Elasticsearch 查询请求。假设 Elasticsearch 运行在 localhost:9200,并且索引为 blog01,可以使用以下命令执行简单的搜索请求:
bash
curl -XGET http://localhost:9200/blog01/article/1?pretty这将返回 id 字段为 1 的文章数据。
运行 ab 测试 使用 ab 工具对上述 URL 进行压力测试,模拟多个并发查询请求。例如,以下命令发出 1000 个请求,允许最多 10 个并发请求:
bash
ab -n 1000 -c 10 http://localhost:9200/blog01/article/_search?q=id:1参数说明:
- -n 1000:总共发出 1000 个 HTTP 请求。
- -c 10:最多允许 10 个并发请求。
5.2 查看评测结果
ab 工具的评测结果包括以下关键指标:
- Requests per second:每秒处理的请求数,即吞吐量。
- Time per request:每个请求的平均处理时间(延迟)。
- Transfer rate:数据传输速度。
示例输出如下:
bash
Concurrency Level: 10
Time taken for tests: 0.720 seconds
Complete requests: 1000
Failed requests: 1
(Connect: 0, Receive: 0, Length: 1, Exceptions: 0)
Total transferred: 863001 bytes
HTML transferred: 280001 bytes
Requests per second: 1389.56 [#/sec] (mean)
Time per request: 7.197 [ms] (mean)
Time per request: 0.720 [ms] (mean, across all concurrent requests)
Transfer rate: 1171.09 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.0 0 0
Processing: 1 7 2.8 7 24
Waiting: 1 7 2.7 7 24
Total: 1 7 2.8 7 24分析:
- Requests per second (1389.56) 表示 Elasticsearch 服务器每秒处理约 1390 个请求,说明在 10 个并发请求下,系统的吞吐量较高。
- Time per request (7.197 ms) 表示平均每个请求处理时间约为 7 毫秒,说明延迟较低,系统能快速响应。
- Failed requests (1) 表示在 1000 次请求中只有 1 次失败,服务器在高并发下的稳定性较好。
5.3 调整并发请求和请求数
可以通过调整 -n 和 -c 参数,测试不同规模的压力场景。比如,以下命令模拟 100 个并发请求,共发出 5000 个请求:
bash
ab -n 5000 -c 100 http://localhost:9200/blog01/article/_search?q=id:1输出示例如下:
bash
Concurrency Level: 100
Time taken for tests: 1.628 seconds
Complete requests: 5000
Failed requests: 5
(Connect: 0, Receive: 0, Length: 5, Exceptions: 0)
Total transferred: 4315005 bytes
HTML transferred: 1400005 bytes
Requests per second: 3070.79 [#/sec] (mean)
Time per request: 32.565 [ms] (mean)
Time per request: 0.326 [ms] (mean, across all concurrent requests)
Transfer rate: 2587.99 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.2 0 2
Processing: 1 32 18.3 30 100
Waiting: 1 32 18.3 30 100
Total: 1 32 18.3 30 100分析:
- 在 100 并发请求下,Requests per second 达到 3070.79,说明系统在高并发场景下吞吐量显著提高。
- Time per request 增至 32 毫秒,说明在更高并发情况下,系统的响应时间有所增加,但仍在可接受范围内。
通过这种压力测试,可以了解 Elasticsearch 在不同并发请求下的性能表现,并为实际应用中的优化提供依据。
6. 总结
通过Apache Benchmark工具,您可以快速对Elasticsearch集群的查询性能进行压力测试。该工具简单易用,能够提供基本的吞吐量、延迟和失败请求等指标。它适用于对HTTP层的简单压力测试,帮助用户初步了解集群的性能状况。