在大数据时代,数据量呈爆炸性增长,传统的数据处理工具已难以满足需求。Hive作为一个开源的数据仓库工具,能够处理大规模数据集,提供了强大的数据查询和分析能力,是大数据学习中的关键工具。在全国职业院校技能大赛(大数据技术与应用赛项)中的平台搭建模块,hive的搭建也是经常考察的问题,今天大家随着小编一起来看一看如何才能避开所有坑,在CentOS7系统中完成Hive的搭建工作,帮助大家快速有效的备赛!!
首先因为hive是需要依赖Hadoop集群环境和MySQL的,所以大家先保证这两个是已经搭建完成的再来进行hive的搭建。以2023年国赛的软件版本为例,Hive使用的为3.1.3。而且小编也会给大家贴心的写出部分命令的解释,方便大家学习。
一、解压Hive安装包到指定目录
bash
tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module-
tar:这是执行打包和解包操作的命令。 -
-zxvf:这是tar命令的选项,用于指定tar命令的行为。z:表示通过gzip进行压缩或解压缩。这意味着tar命令将处理.tar.gz或.tgz格式的压缩包。x:表示解压缩。这是与打包(c选项)相对的操作,用于从压缩包中提取文件。v:表示在解压缩过程中显示详细信息,即列出正在被解压的文件。f:表示接下来要指定压缩包的文件名。这个选项告诉tar命令,接下来的参数是压缩包的文件名,而不是要打包或解包的文件列表。
-
-C /opt/module:这个选项(注意是大写的C,不是小写的c)用于指定解压缩后文件的目标目录。-C选项后面跟着的是目标目录的路径。
二、文件夹重命名
我们先进入到/opt/module文件夹下,然后执行下面的命令,这样做是为了后续配置变量等方便一点,当然了,大家也可以不改这一步。
bash
mv apache-hive-3.1.2-bin hive三、在hive的lib目录下放入MySQL驱动包
bash
mv mysql-connector-java-5.0.8.jar hive/lib四、配置环境变量
bash
vim /etc/profile随后在文件末尾处添加:
bash
# HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin启动环境变量
bash
source /etc/profile五、配置主要文件
首先进入到hive的conf目录下
bash
cd /opt/module/hive/conf/将副本拷贝成一份文件,这一步是为了大家写错之后有原本可以还原
bash
cp hive-env.sh.template hive-env.sh修改hive-env.sh环境的配置,在该文件末尾添加:
bash
export JAVA_HOME=/opt/module/jdk
export HADOOP_HOME=/opt/module/hadoop
export HIVE_HOME=/opt/module/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf将副本拷贝成一份文件:
bash
cp hive-default.xml.template hive-site.xml修改以下配置:
bash
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://你的虚拟机IP:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false</value>
<description> localhost虚拟机IP地址,hivedb数据库的名字(随意)createDatabaseIfNotExist 如果数据库不存在自动创建</description>
</property>
<!--配置数据库驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--配置数据库用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>你的用户(一般为root)</value>
</property>
<!--配置MySQL数据库root的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>你的密码</value>
</property>六、schema格式化
bash
schematool -dbType mysql -initSchema大家执行这个命令之后会报很多种错误,但是同学们别急,小编尽量贴出来所有错误,首先如果大家遇到这个错误:
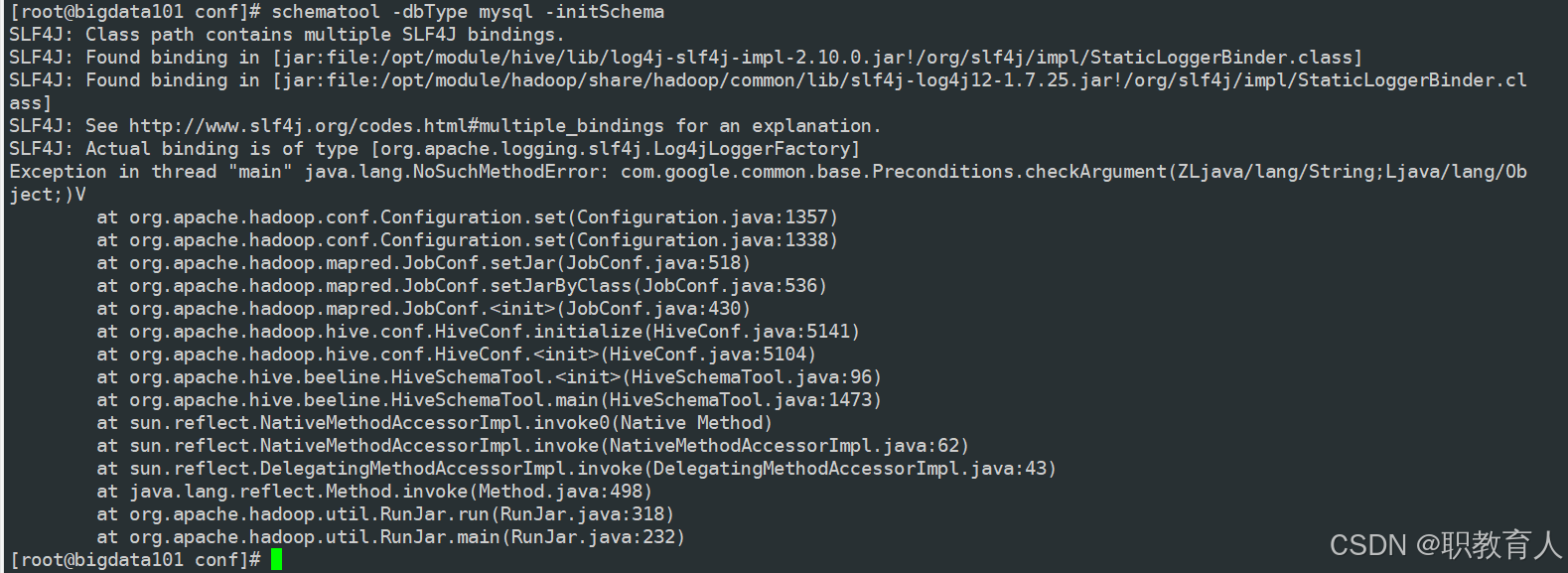
这个错误是由于hadoop3.x中的这个目录下"/opt/module/hadoop/share/hadoop/common/lib"的"guava-27.0-jre.jar"包与我们hive目录lib目录下"guava-19.0.jar"的版本冲突了,解决方法很简单,我们将hive目录下的jar包删除,随后将hadoop的这个包复制到hive的lib目录下即可了。
bash
rm -rf /opt/module/hive/lib/guava-19.0.jar
cp /opt/module/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/hive/lib/随后再次执行初始化命令,正当我们志得意满的时候,发现他又又报错了
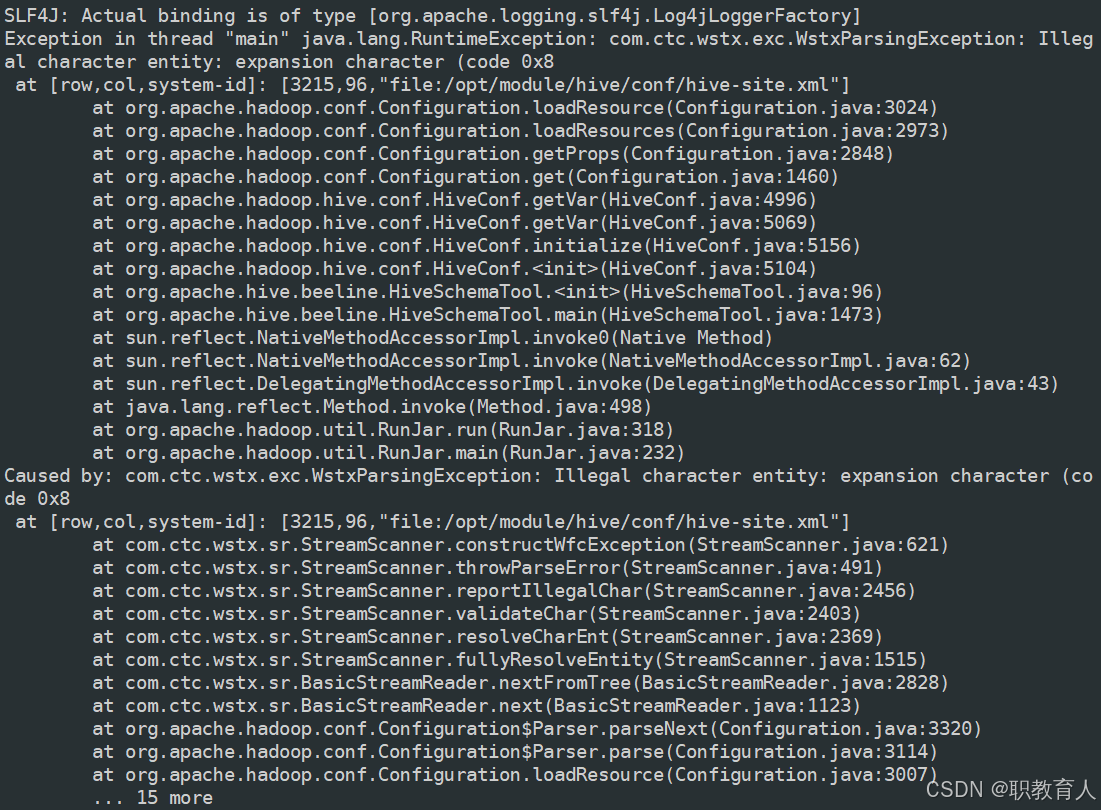
真是头大,但是还好报错写的很清楚,告诉我们是hive-size.sh文件中第3215行出现错误了,那我们就看看怎么个事。

大家可以看到,我的3215行明明是一个<description>标签,这个怎么会报错呢,其实眼尖的同学能看出来那个"for"的颜色不太对啊,为啥他那么独特,其实这是因为他是一个特殊字符,咱们最好还是将这一整段都删除掉比较保险。删除整个<description>标签的内容之后,我们再次执行初始化命令!
小编这里初始化成功了,当我以为万事大吉之后,他又又又报错了............(其实我知道他肯定会报错的,但是为了照顾同学们,嘿嘿......)

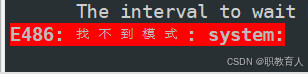
咱们就一步一步来,这个报错大家能看到"URI:{system:java.io.tmpdir%7D/%7Bsystem:user.name%7D"这一串吧,其实问题就出在这里,其实这里需要大家在hive-site.xml配置文件中需要配置system:java.io.tmpdir属性。但是我可不管三七二十一,我不配,咱们直接查找把所有"system:"删除掉,不是报错吗,我全删了看你还错不错了!!(在命令模式下按n可以进行下一个的查找)

直到全部删除即可,我们保持退出,随后再次启动hive
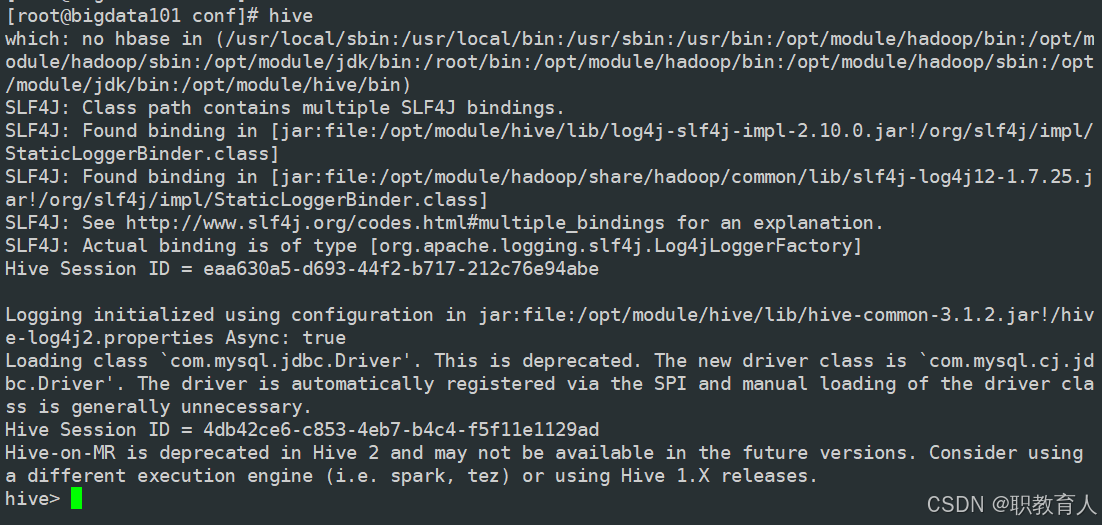
终于进来了,555555~~~,但是我告诉大家,除了我上面说的这些错误,还有很多复杂的问题大家在平时的练习中还会遇到,特别有一个大家应该也发现了,就是初始化的时候打印了大量的空白,这样在比赛中粘贴答案是肯定扣分的,这个问题其实是hive在初始化的时候打印了大量日志,但是咱们看不到,所以就是空白,大家研究一下怎么关闭日志就行,很简单的哦,大家在准备省赛或者国赛,有什么问题都可以关注这个账号私信哦。